
Just-In-Time Java Compilation for the Itanium Processor
22
www.intel.com/labs Just-In-Time Java Compilation for the Itanium Processor Tatiana Shpeisman Tatiana Shpeisman Guei-Yuan Lueh Guei-Yuan Lueh Ali-Reza Adl-Tabatabai Ali-Reza Adl-Tabatabai Intel Labs Intel Labs
description
Just-In-Time Java Compilation for the Itanium Processor. Tatiana Shpeisman Guei-Yuan Lueh Ali-Reza Adl-Tabatabai Intel Labs. Introduction. Itanium processor is statically scheduled machine Aggressive compiler techniques to extract ILP Just-In-Time (JIT) compiler must be fast - PowerPoint PPT Presentation
Transcript of Just-In-Time Java Compilation for the Itanium Processor

www.intel.com/labs
Just-In-Time Java Compilation for the Itanium Processor
Tatiana ShpeismanTatiana Shpeisman
Guei-Yuan LuehGuei-Yuan Lueh
Ali-Reza Adl-TabatabaiAli-Reza Adl-Tabatabai
Intel LabsIntel Labs

2 www.intel.com/labs
Introduction Itanium processor is statically scheduled machineItanium processor is statically scheduled machine
Aggressive compiler techniques to extract ILPAggressive compiler techniques to extract ILP
Just-In-Time (JIT) compiler must be fastJust-In-Time (JIT) compiler must be fast Must consider time & space efficiency of optimizationsMust consider time & space efficiency of optimizations
Balance compilation time with code qualityBalance compilation time with code quality
Light-weight compilation techniques Light-weight compilation techniques Use heuristics for modeling micro architectureUse heuristics for modeling micro architecture
Leverage semantics and meta data of JVMLeverage semantics and meta data of JVM

3 www.intel.com/labs
Outline IntroductionIntroduction
Compiler overviewCompiler overview
Register allocationRegister allocation
Code schedulingCode scheduling
Other optimizationsOther optimizations
ConclusionsConclusions
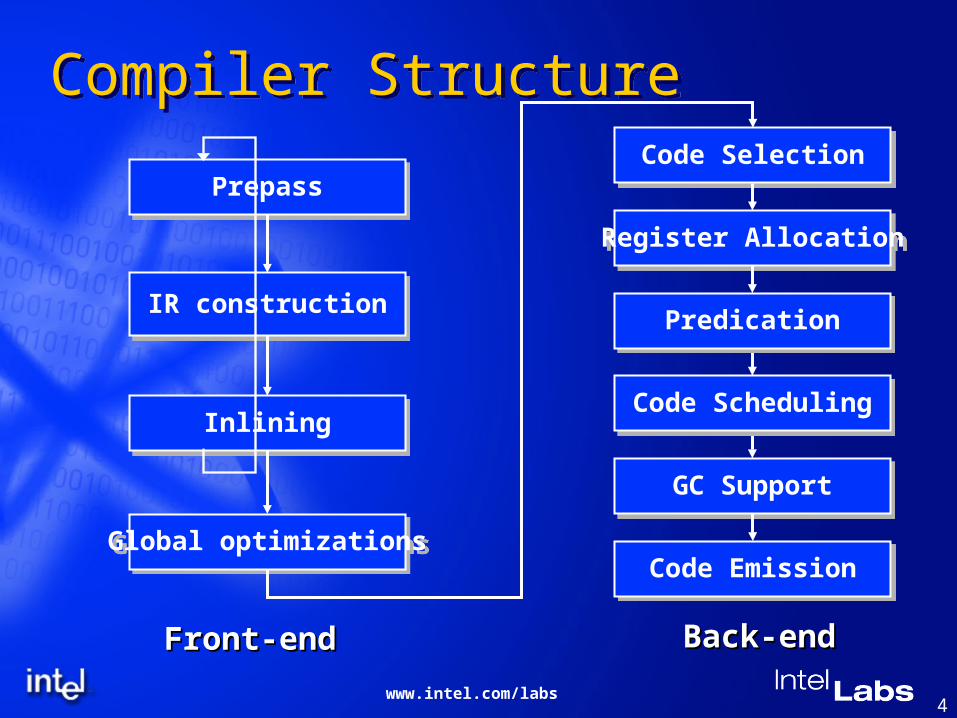
4 www.intel.com/labs
Compiler StructurePrepass
Inlining
Global optimizations
IR construction
Code Selection
Register Allocation
Code Emission
GC Support
Front-endFront-end Back-endBack-end
Code Scheduling
Predication

5 www.intel.com/labs
Register Allocation Compilation time vs. code quality tradeoffCompilation time vs. code quality tradeoff
IPF architecture has large register filesIPF architecture has large register files 128 integer, 128 floating-point, 64 predicate, 8 branch128 integer, 128 floating-point, 64 predicate, 8 branch
Register Stack Engine (RSE) provides 96 stack registers Register Stack Engine (RSE) provides 96 stack registers to each procedureto each procedure
Use linear scan register allocationUse linear scan register allocation ““Linear Scan Register AllocationLinear Scan Register Allocation” by Massimiliano Poletto ” by Massimiliano Poletto
and Vivek Sarkarand Vivek Sarkar

6 www.intel.com/labs
Live Range vs. Live Interval...
t1=t1=......
v =v = t1t1
...= v= v
B1
B2 B3
B4
t2=t2=......
v =v = t2t2
t1=t1=......
v =v = t1t1
t2=t2=......
v =v = t2 t2
...= v= v
...B1
B2
B4
B3
Live RangesLive Ranges Live IntervalsLive Intervals

7 www.intel.com/labs
Coalescing Algorithm Coalesce Coalesce vv and and tt in in v =v = tt iff iff
Live interval of Live interval of tt ends at ends at v = tv = t Live interval of Live interval of tt does not does not
intersect with live range of intersect with live range of vv
Requires one additional Requires one additional reverse pass over IRreverse pass over IR OO(N(NINSTINST + N + NVARVAR * N * NBBBB))
t1=t1=......
v =v = t1t1
t2=t2=......
v =v = t2 t2
...= v= v
...B1
B2
B4
B3

8 www.intel.com/labs
Coalescing Speedup
0
1
2
3
4
5
6
7%
spe
edup
ove
r no
coal
esci
ng

9 www.intel.com/labs
Code Scheduling Forward cycle-based list schedulingForward cycle-based list scheduling
Scheduling unit is extended basic blockScheduling unit is extended basic block Middle exits are due to run-time exceptionsMiddle exits are due to run-time exceptions
(p6,p7) = cmp.eq r35, 0(p6,p7) = cmp.eq r35, 0
(p6) br ThrowNullPointerException(p6) br ThrowNullPointerException
r10 = r35 + 16r10 = r35 + 16
r11 = ld8 [r10]r11 = ld8 [r10]

10 www.intel.com/labs
Type-based memory disambiguation Use JVM meta data to disambiguate memory Use JVM meta data to disambiguate memory
locationslocations Type Type
Integer, floating-point, object reference …Integer, floating-point, object reference …
Kind Kind Object field, array element, virtual table address …Object field, array element, virtual table address …
Field idField id putfield #10 vs. putfield #15putfield #10 vs. putfield #15

11 www.intel.com/labs
Type-Based Disambiguation
00.5
11.5
22.5
_201
_com
pre
ss
_202
_jes
s
_209
_db
_222
_mpe
gau
d
_227
_mtrt
_228
_jac
k %
spe
edup
ove
r no
disa
mbigu
ation

12 www.intel.com/labs
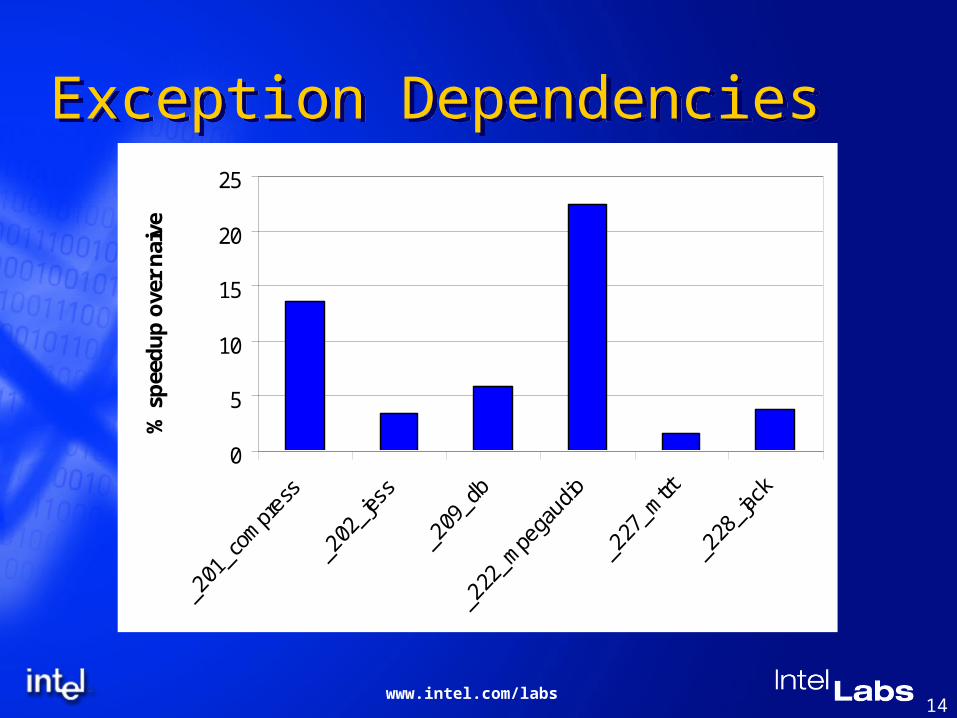
Exception Dependencies Java exceptions are preciseJava exceptions are precise
Naive approachNaive approach Exception checks end basic blocksException checks end basic blocks
Our approachOur approach Instruction depends on exception check iffInstruction depends on exception check iff
Its destination is live at the exception handler, orIts destination is live at the exception handler, or
It is an exception check for different exception typeIt is an exception check for different exception type
It is a memory reference that may be guarded by It is a memory reference that may be guarded by checkcheck

13 www.intel.com/labs
Exception Dependency Example
1:1: (p6, p0) = cmp.eq r16, 0(p6, p0) = cmp.eq r16, 0 2:2: (p6)(p6) brbr ThrowNullPointerExceptionThrowNullPointerException
6: 6: f8 = fld [r21]f8 = fld [r21] // load static// load static
5: 5: r21 = movl r21 = movl 0x000F14E320190000x000F14E32019000
4:4: r18 = ld [r17]r18 = ld [r17] // load field// load field
3:3: r17 = add r16, 8r17 = add r16, 8
14 www.intel.com/labs
Exception Dependencies
0
5
10
15
20
25%
spe
edup
ove
r nai
ve

15 www.intel.com/labs
IPF Architecture Execution (functional) unit type – M, I, F, B Execution (functional) unit type – M, I, F, B Instruction (syllable type) – M, A, I, F, B, ILInstruction (syllable type) – M, A, I, F, B, IL Bundles, templates Bundles, templates
.mii .mi;;i .mil .mmi .m;;mi .mfi .mmf .mib .mbb .bbb .mmb ..mii .mi;;i .mil .mmi .m;;mi .mfi .mmf .mib .mbb .bbb .mmb .mfbmfb
Instruction group – no WAR, WAW with some Instruction group – no WAR, WAW with some exceptionsexceptions
.mi;;i r10 = ld [r15]
r9 = add r8, 1 ;; // stop bit
r16 = shr r9, r32

16 www.intel.com/labs
Template Selection Pack instructions into bundlesPack instructions into bundles
Choose slot for each instructionChoose slot for each instruction Insert NOP instructions Insert NOP instructions Assign instructions to functional unitsAssign instructions to functional units
Problem: Problem:
Resource over subscription Resource over subscription
Inaccurate bypass latenciesInaccurate bypass latencies

17 www.intel.com/labs
Greedy slot assignmentGreedy slot assignment
Sort instruction by syllable typeSort instruction by syllable type M < F < IL < I < A < BM < F < IL < I < A < B
I1: r20 = sxt r14 (I-type)
I2: r21 = movl ADDR (IL-type)
I3: f15 = fadd f10, f11 (F-type)
Algorithm
NOP I1 NOP
NOP I2
NOP I3 NOP
Unsorted
NOP I3 I1
NOP I2
Sorted

18 www.intel.com/labs
Template Selection Heuristics
0
1
2
3
4
5
6
% s
peed
up o
ver g
reed
y st
rate
gy

19 www.intel.com/labs
Bypass Latency Accuracyr17 = add r16, 8
M-Unitr17 = add r16, 8
I-Unit
r18 = ld [r17]M-Unit1 2
Phase ordering of functional unit assignmentCode selection time is too early: underutilizes resources
Template selection time too late: inaccurate scheduling latencies
Solution: Assign to functional unit during scheduling Assign to M-Unit if available, else
Assign to I-Unit and increment latency

20 www.intel.com/labs
Modeling of Address Computation Latency
00.5
11.5
22.5
33.5
% s
peed
up o
ver i
gnor
ing
bypa
ss

21 www.intel.com/labs
Other optimizations PredicationPredication
Profitability depends on a benchmarkProfitability depends on a benchmark
Performance variations within 2%Performance variations within 2%
Branch hintsBranch hints Up to 50% speedup from using branch hintsUp to 50% speedup from using branch hints
Sign-extension eliminationSign-extension elimination 1% potential gain for our compiler1% potential gain for our compiler

22 www.intel.com/labs
Conclusions Light-weight optimizations techniques for ItaniumLight-weight optimizations techniques for Itanium
Considering micro architecture is importantConsidering micro architecture is important Cannot ignore bypass latenciesCannot ignore bypass latencies
Template selection should be resource sensitiveTemplate selection should be resource sensitive
Language semantics helps to improve ILPLanguage semantics helps to improve ILP Type-based memory disambiguationType-based memory disambiguation
Exception dependency eliminationException dependency elimination


















