

Pubcon Vegas 2017 You're Going To Screw Up International SEO - Patrick Stox
Upload
barry-adamsCategory
view
2.758download
1
#pubcon@badams
JavaScript & SEO
Presented by:Barry Adams
Polemic Digital
#pubcon@badams
Barry Adams Doing SEO since 1998 Founder of Polemic Digital Co-Chief at State of Digital

#pubcon@badams
JavaScript

#pubcon@badams
Two Types of JS*
• JavaScript that enhances HTML and CSS;– Adds functionality, improves user experience– Little to no impact on SEO
• JavaScript that replaces HTML and CSS;– Turns webpages in to web apps– Destructive for SEO
*According to me

#pubcon@badams
How Search Engines Work

#pubcon@badams
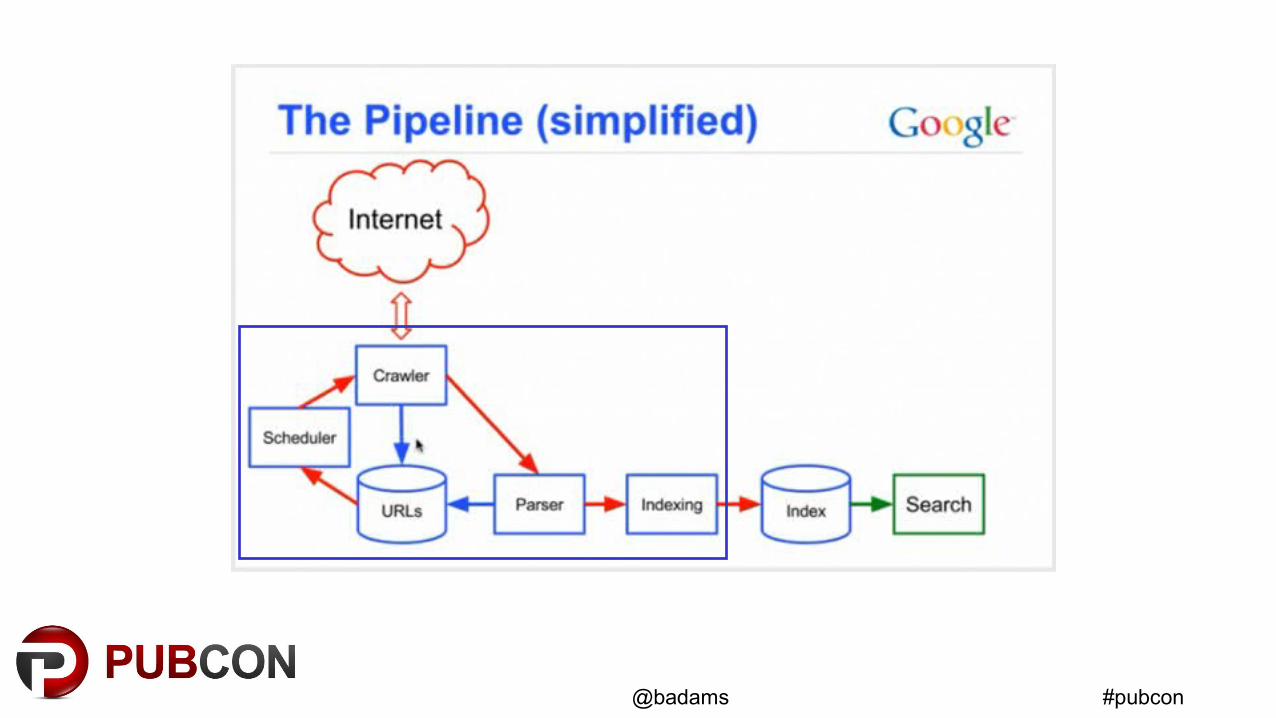
Web Search Engines
Three distinct processes:
1. Crawler 2. Indexer 3. Query Engine
Technical SEO
#pubcon@badams

#pubcon@badams
JavaScript & Crawling

#pubcon@badams
Web Crawler (Googlebot)
• Spiders the web;
– URLs from previous crawls and XML sitemaps
• Extracts hyperlinks and adds to crawl queue
• Retrieves new and changed content
• Access can be restricted with robots.txt

#pubcon@badams
Elements of a Web Crawler
• Crawl ‘Politeness’– How fast can we crawl a site?
• URL Importance– How often do we need to recrawl a URL?
• HTML Parser– Can we find links in the crawled URL?

#pubcon@badams
Crawler: HTML Parser

#pubcon@badams
URLs are Sacred
• Search Engines don’t crawl, index, rank pages or content…
• They crawl, index, and rank URLs.
• One piece of content = one URL– Many JS platforms ignore this foundational aspect of the web

#pubcon@badams
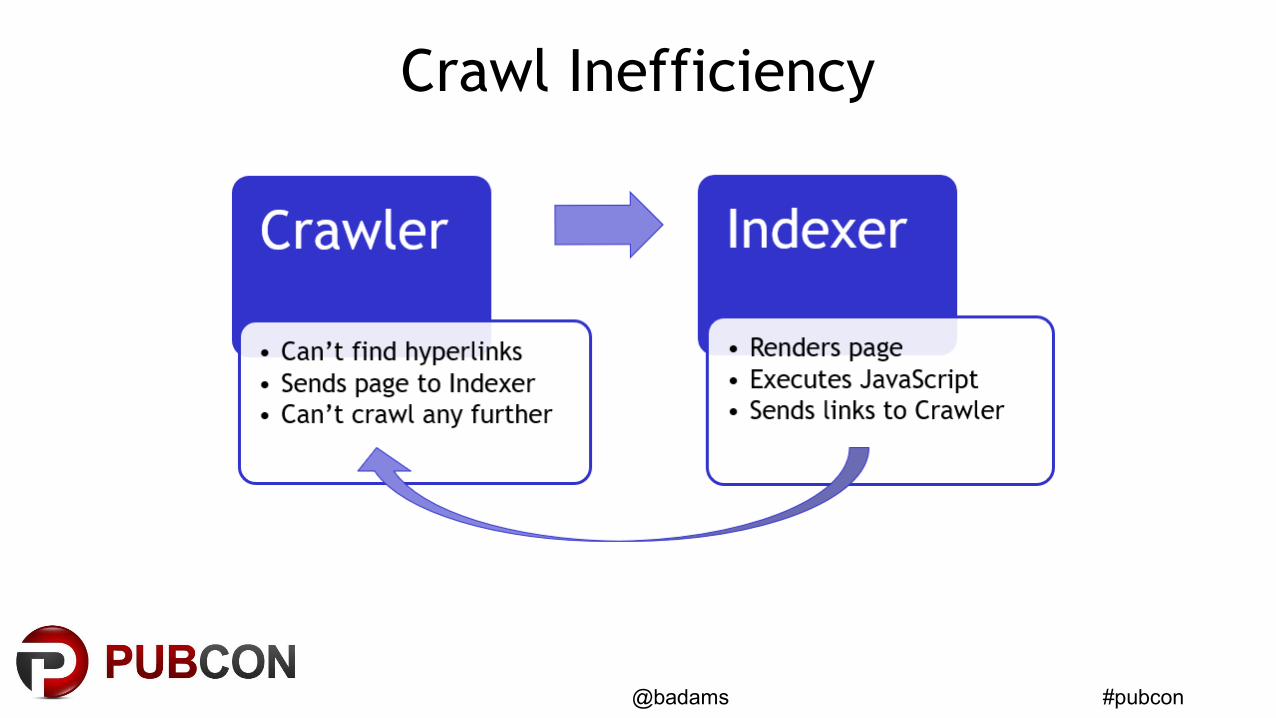
JavaScript & Crawling
• Googlebot does not render webpages– The indexer (Caffeine) does
• JavaScript is not executed by the Googlebot crawler– Any links embedded in JavaScript are not found by the
crawler

#pubcon@badams
JavaScript & Crawling
No Hyperlinks!
#pubcon@badams
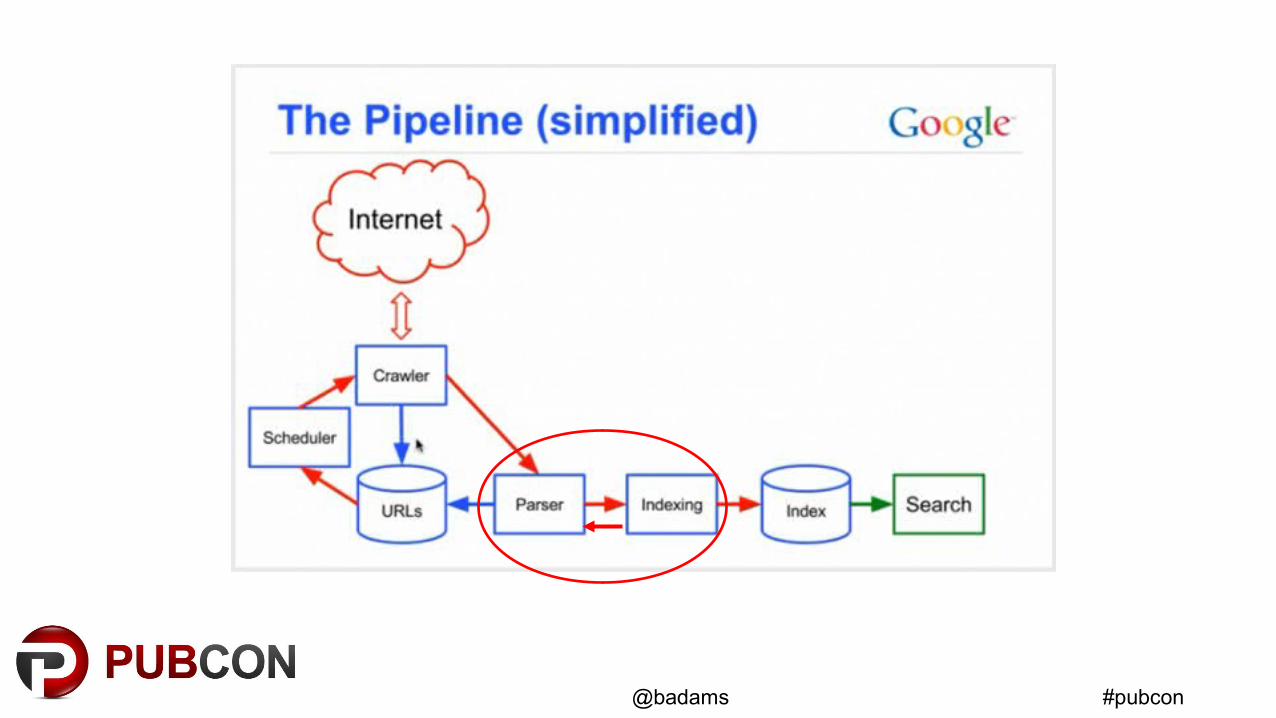
Crawl Inefficiency
#pubcon@badams

#pubcon@badams
JavaScript & Indexing

#pubcon@badams
Indexer (Caffeine)
• Analyses content
• Analyses links
• Analyses webpage layout
• Can be influenced with robots meta tags

#pubcon@badams
Elements of the Indexer
• Canonicalisation– Determines the canonical URL
• Web Rendering Service– Renders webpages as a browser would (Chrome 41)
• PageRanker– Calculates a URL’s PageRank

#pubcon@badams
Web Rendering Service
https://developers.google.com/search/docs/guides/rendering

#pubcon@badams
Web Rendering Service
• Rendering engine: Chrome 41
• Stateless (no cookies)
• Does not perform any actions

#pubcon@badams
PageRanker
• Calculates each canonical page’s PageRank;– Links, links, links– Internal and external links both count– PageRank Damping factor
• Feeds back to the crawler;– High PR = high crawl priority

#pubcon@badams
JavaScript & Indexing
• Google will index content embedded in JavaScript– Only if no action required!
• Links embedded in JS can be extracted– Processed within Caffeine– Added to the Crawler’s queue

#pubcon@badams
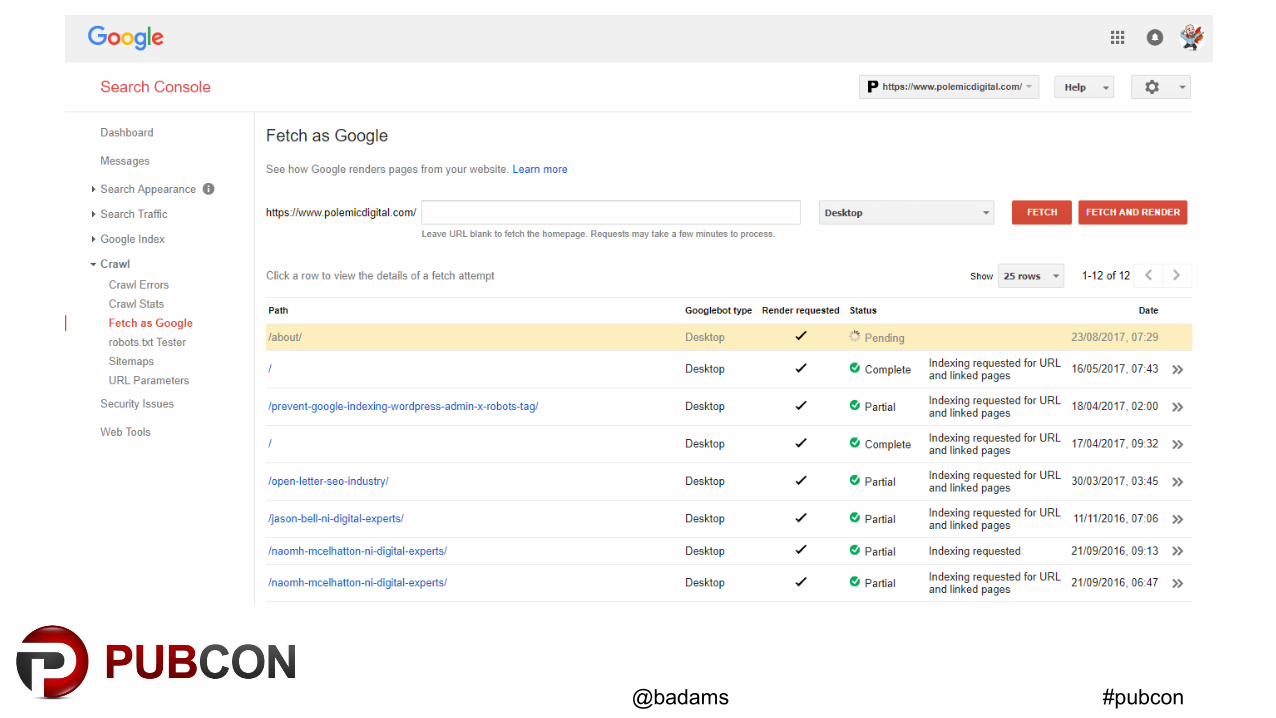
#pubcon@badams
Fetch & Render

#pubcon@badams
Fetch
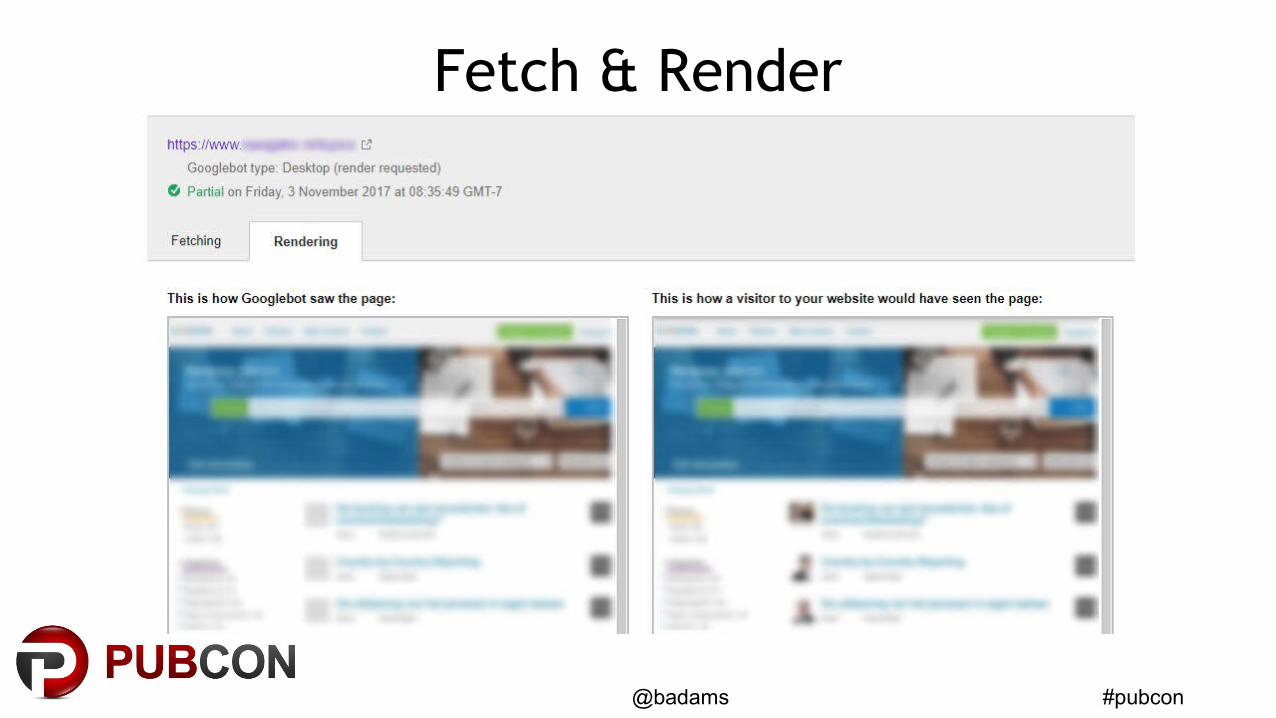
#pubcon@badams
Fetch & Render

#pubcon@badams
Fetch & Render
• Fetch = Googlebot (crawler)
• Fetch & Render = Caffeine (indexer)
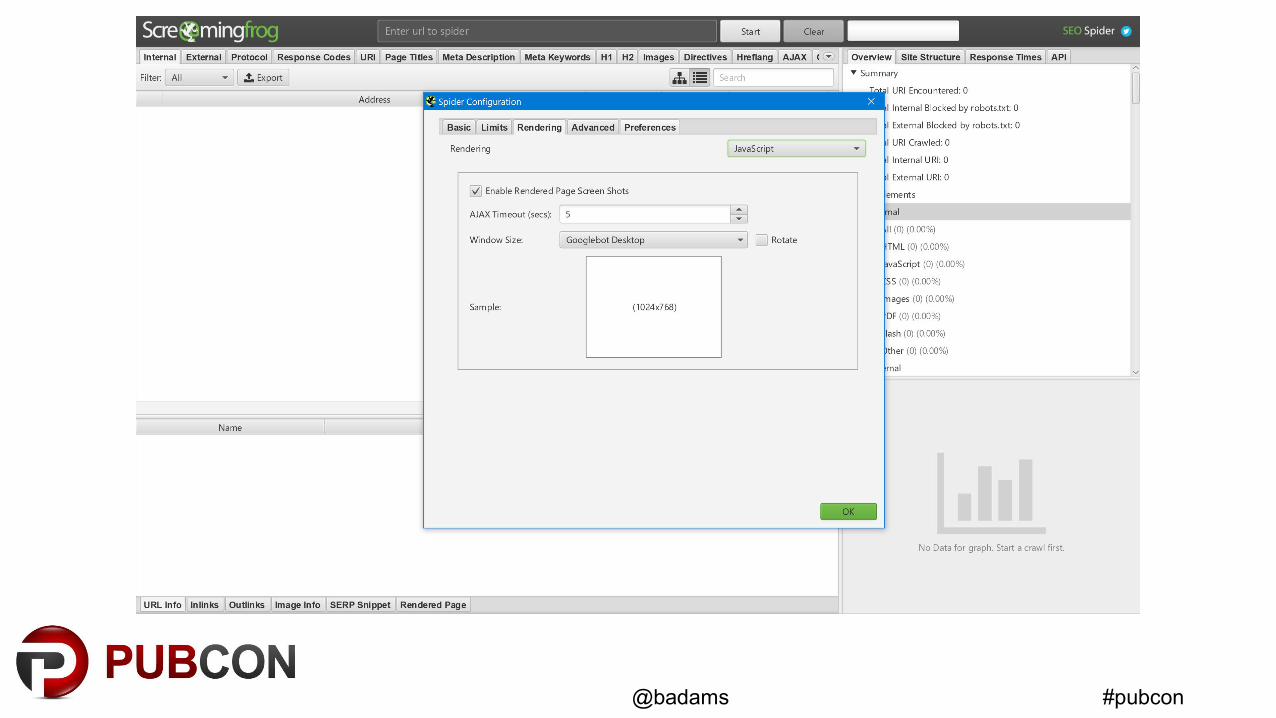
#pubcon@badams

#pubcon@badams
https://goralewicz.com/blog/javascript-seo-experiment/

#pubcon@badams
https://moz.com/blog/search-engines-ready-for-javascript-crawling
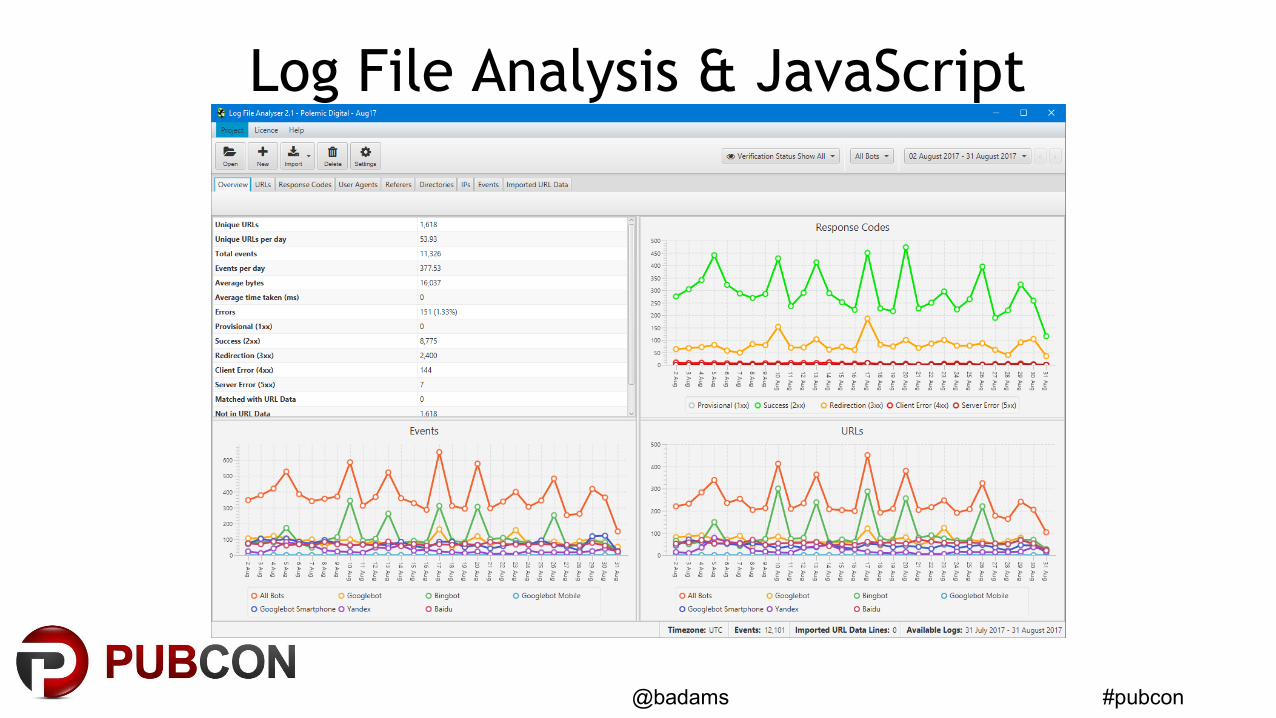
#pubcon@badams
Log File Analysis & JavaScript

#pubcon@badams
Log File Analysis & JavaScript
• Find pages that are rarely/never crawled– Improve internal linking with plain <a href> links
• Compare URLs crawled by Googlebot vs Bingbot– Bingbot doesn’t render JavaScript (much)

#pubcon@badams
Summarised: JavaScript & SEO

#pubcon@badams
Summarised: JavaScript & SEO
• Googlebot (crawler) doesn’t crawl JavaScript
• Caffeine (indexer) executes and indexes JavaScript
Further reading:http://www.stateofdigital.com/javascript-seo-crawling-indexing/

#pubcon@badams
Summarised: JavaScript & SEO
• JavaScript should *enhance* HTML & CSS– Never replace it
• Links embedded in JavaScript do pass PageRank– Crawl inefficiency = low crawl rate
• Pages relying on JS don’t rank well– Compared to pages that don’t rely on JS












![[Pubcon 2011] 10 Ways to Maintain Your eCommerce SEO Rankings Through a Redesign](https://static.fdocuments.us/doc/165x107/555ab3bdd8b42a405b8b4f86/pubcon-2011-10-ways-to-maintain-your-ecommerce-seo-rankings-through-a-redesign.jpg)





