
Inspecting Under the Hood of Autodesk Vault Inspecting Under the Hood of Autodesk Vault
Upload
vachagan-balayanCategory
view
111download
8
JavaUnder the hood

Javac and JVM optimizations
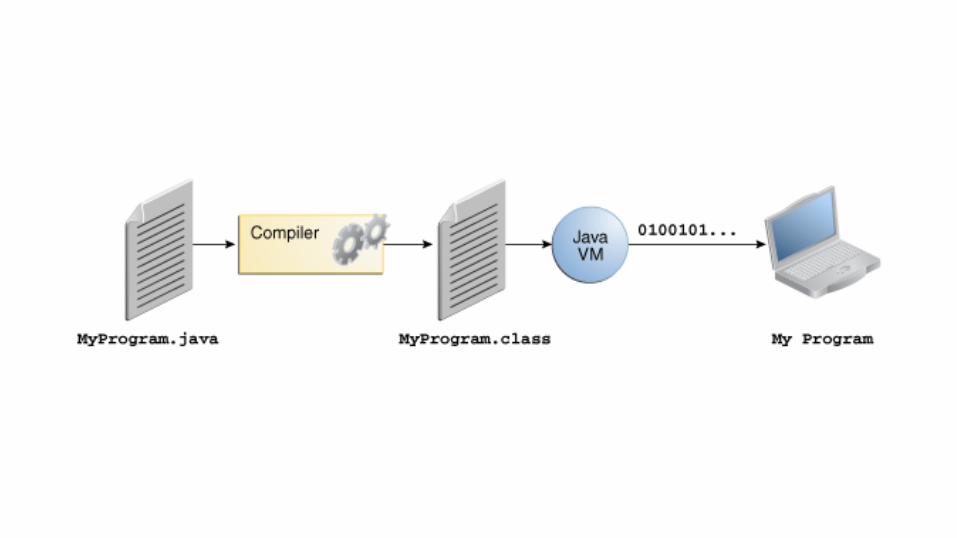

Agenda● Javac and JVM optimizations
○ JIT (Just In Time Compilation) ■ Profiling, Method Binding, Safepoints
○ Method Inlining, ○ Loop Unrolling, ○ Lock Coarsening○ Lock Eliding, ○ Branch Prediction, ○ Escape Analysis○ OSR (On Stack Replacement)○ TLAB (Thread Local Allocation Buffers)
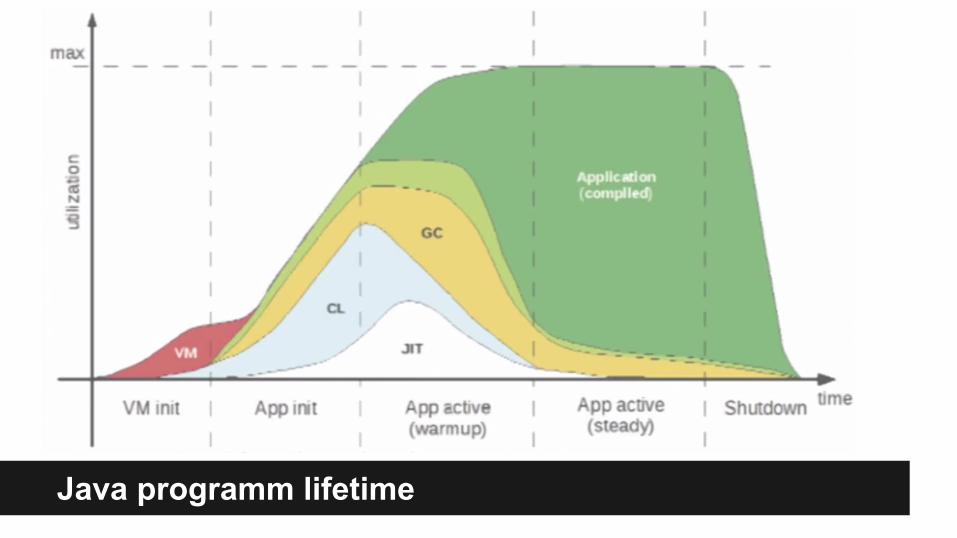
Java programm lifetime

JIT Compilation
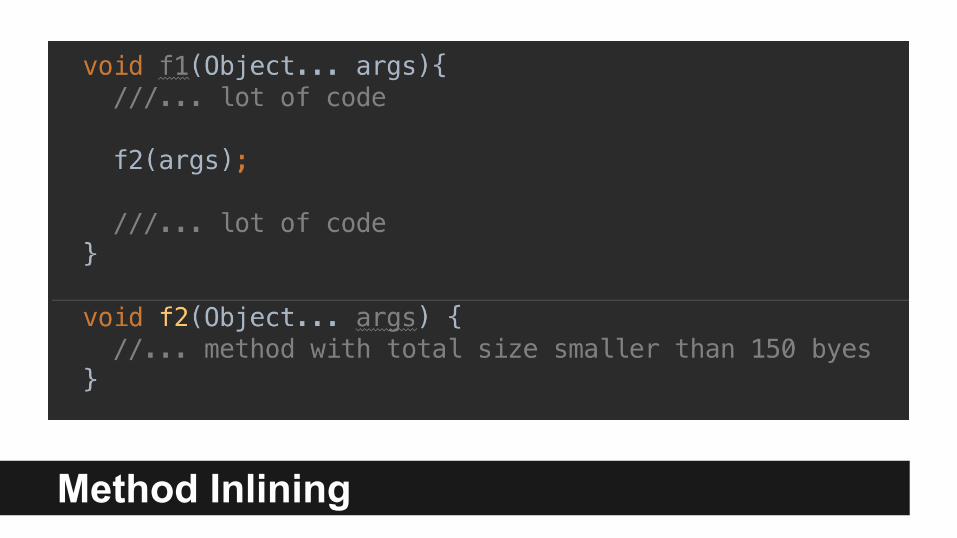
Method Inlining
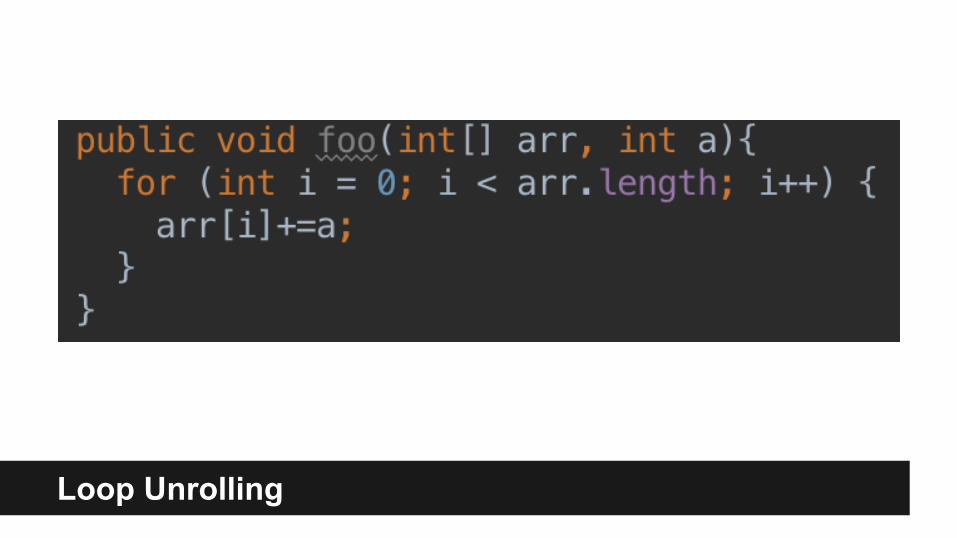
Loop Unrolling
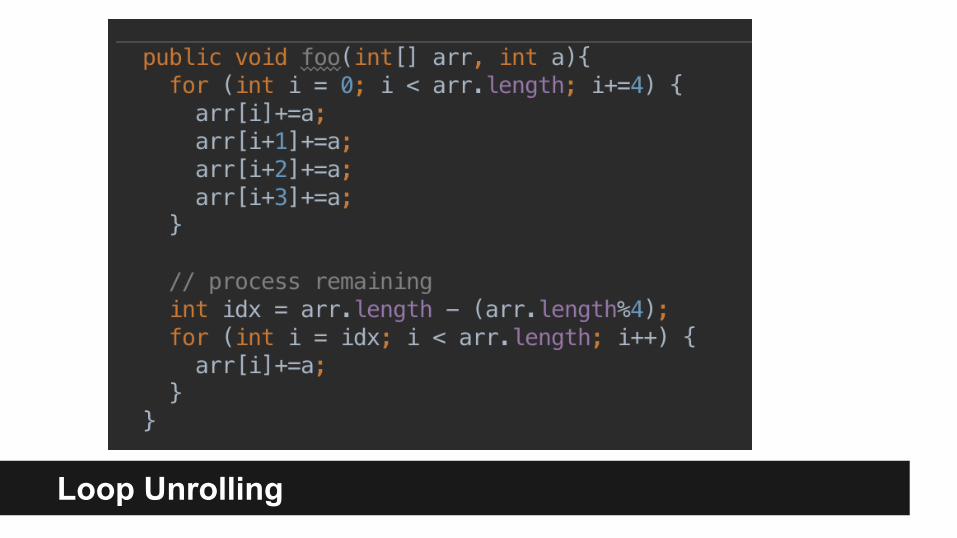
Loop Unrolling
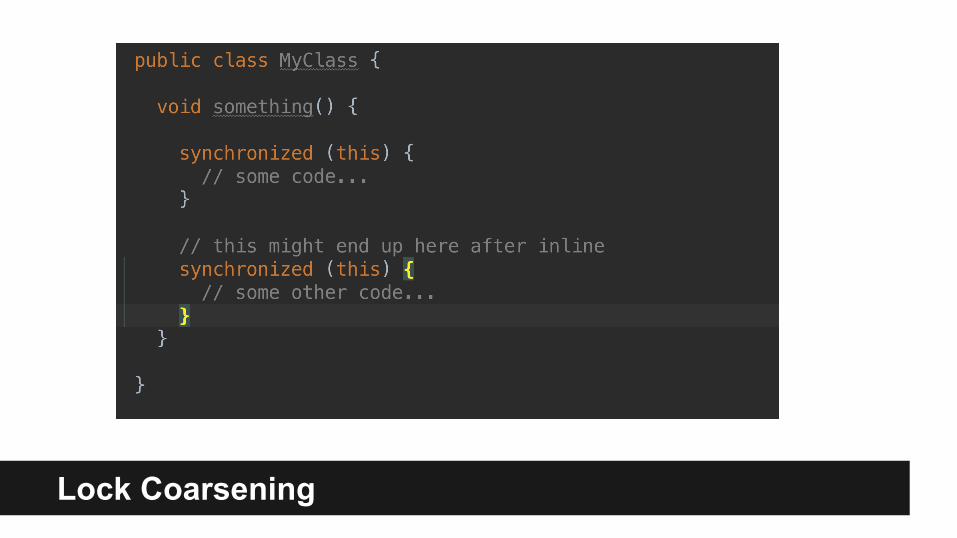
Lock Coarsening
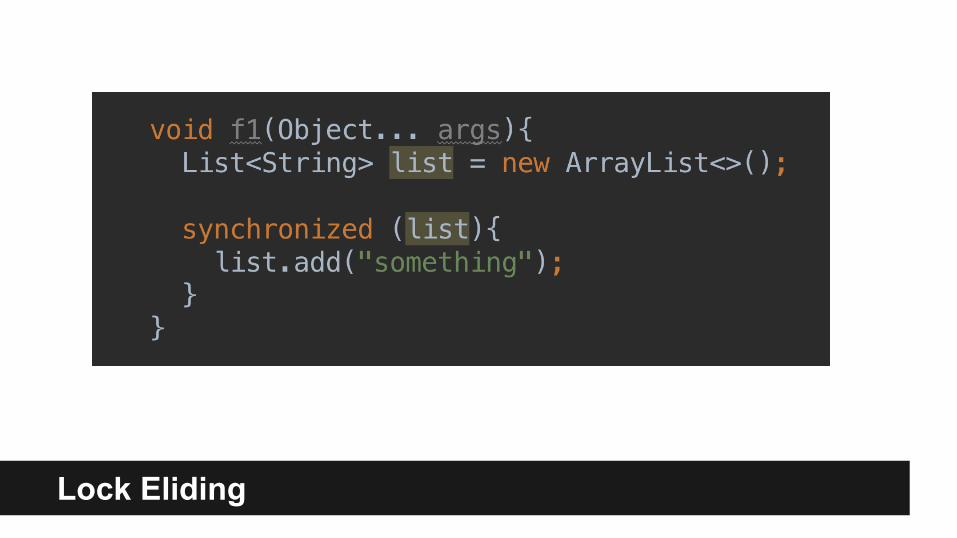
Lock Eliding
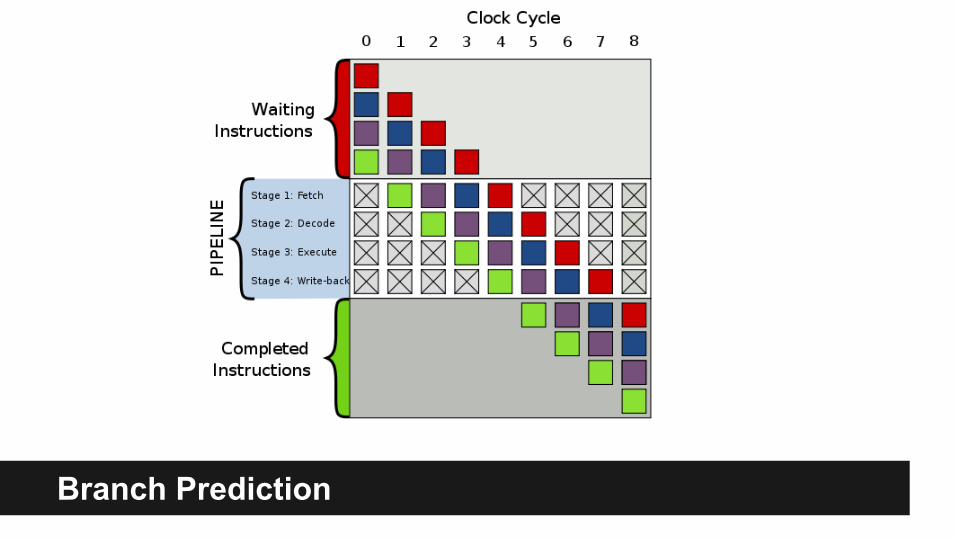
Branch Prediction
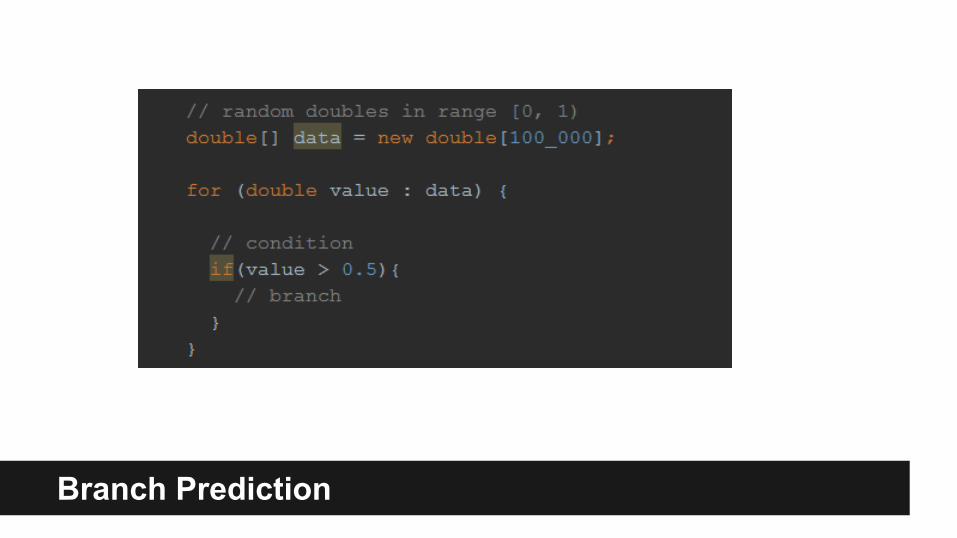
Branch Prediction

Branch Prediction
● Performance of an if-statement depends on whether its condition has a predictable pattern.
● A “bad” true-false pattern can make an if-statement up to six times slower than a “good” pattern!

Doing string concatenation in one scope will be picked by javac and replaced with StringBuilder equivalent.
String concatenation example
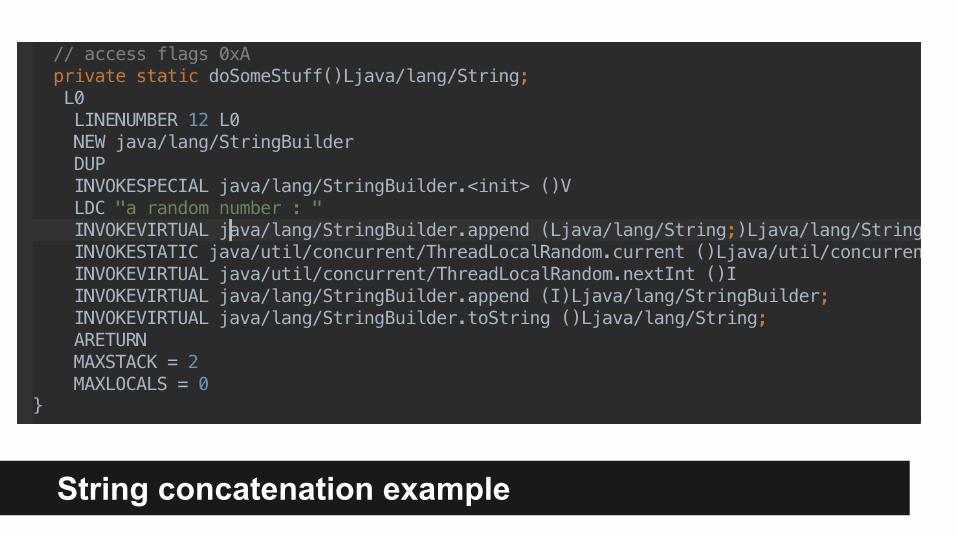
String concatenation example

Intrinsics
Intrinsics are methods KNOWN to JIT. Bytecodes of those are ignored and native most performant versions for target platform is used...
● System::arraycopy● String::equals● Math::*● Object::hashcode● Object::getClass● Unsafe::*

Escape Analysis
Any object that is not escaping its creation scope MAY be optimized to stack allocation.
Mostly Lambdas, Anonymous classes, DateTime, String Builders, Optionals etc...
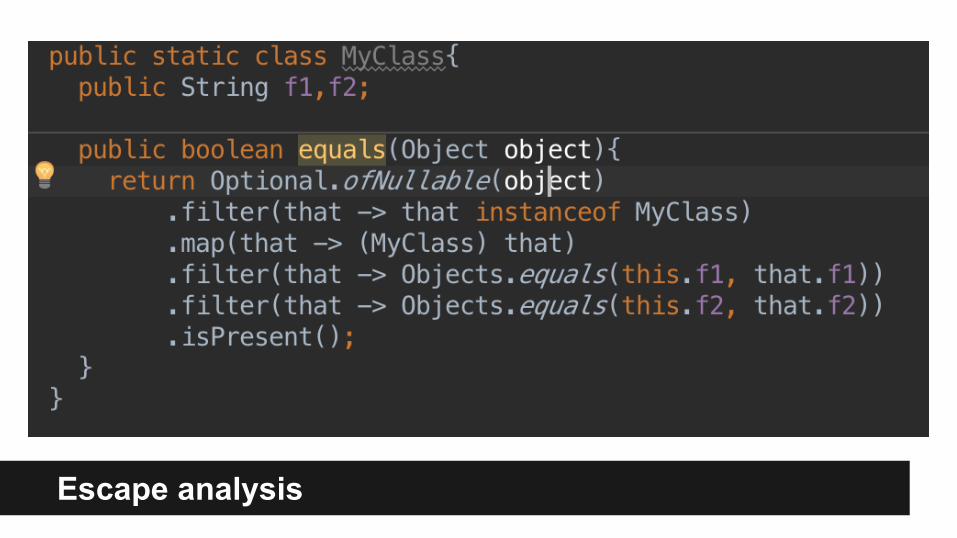
Escape analysis
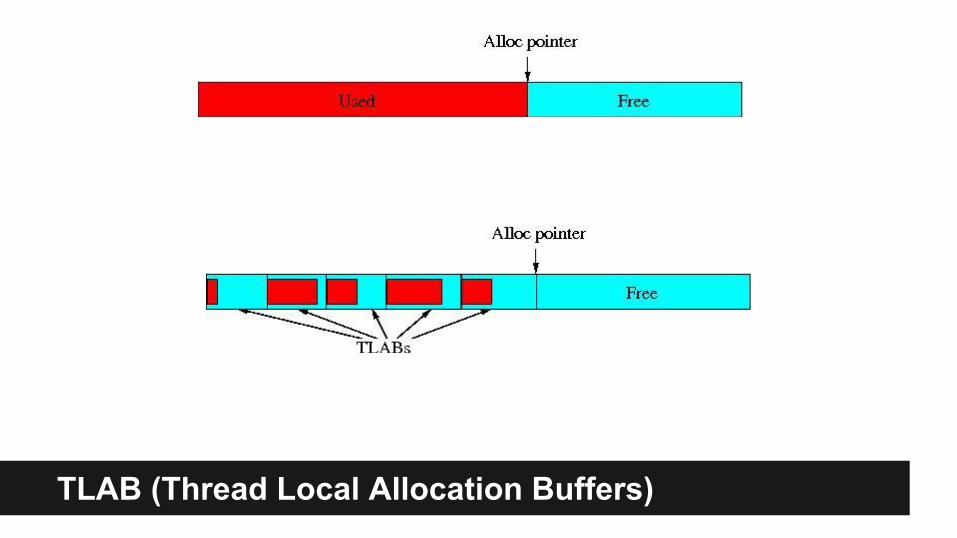
TLAB (Thread Local Allocation Buffers)
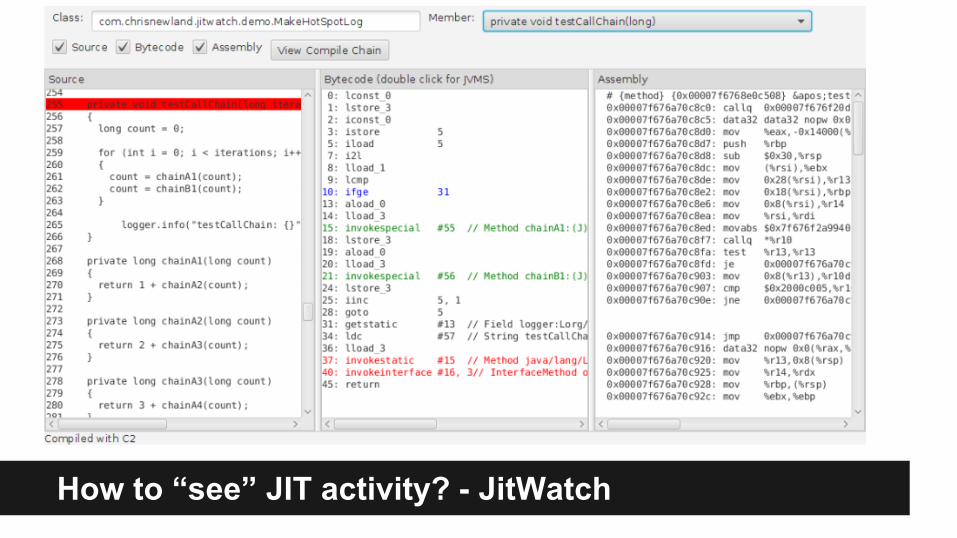
How to “see” JIT activity? - JitWatch

Conclusion
Before attempting to “optimize” something in low level, make sure you understand what the environment is already optimizing for you…
Dont try to predict the performance (especially low-level behavior) of your program by looking at the bytecode. When the JIT Compiler is done with it, there will not be much similarities left.

Questions?

Concurrency : Level 0

Agenda● Concurrency : Hardware level
○ CPU architecture evolution○ Cache Coherency Protocols○ Memory Barriers○ Store Buffers○ Cachelines○ volatiles, monitors (locks, synchronization), atomics
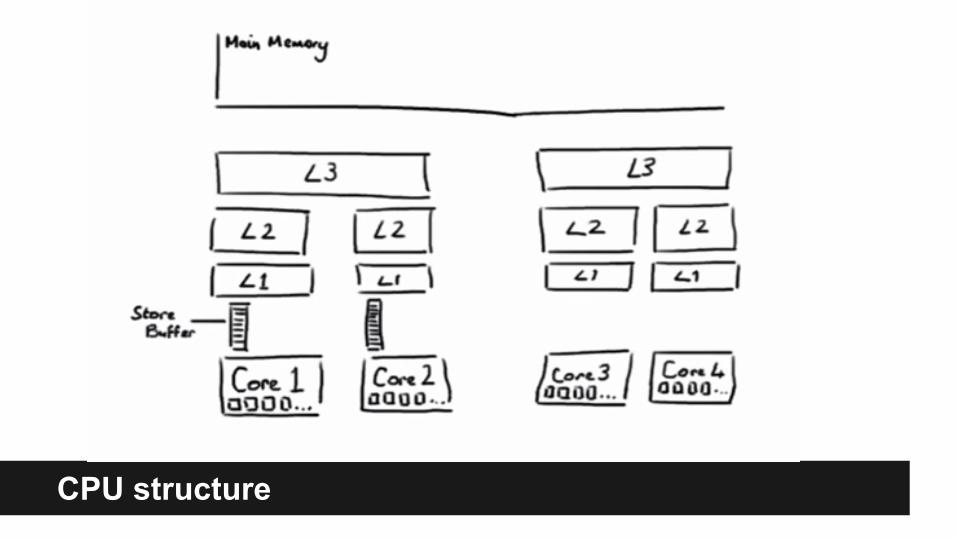
CPU structure

Cache access latencies
CPUs are getting faster not by frequency but by lower latency between L caches, better cache coherency protocols and smart optimizations.

Why Concurrency is HARD?Problem 1 : VISIBILITY!
● Any processor can temporarily store some values to L caches instead of Main memory, thus other processor might not see changes made by first processor…
● Also if processor works for some time with L caches it might not see changes made by other processor right away...

Why Concurrency is HARD?Problem 2 : Reordering
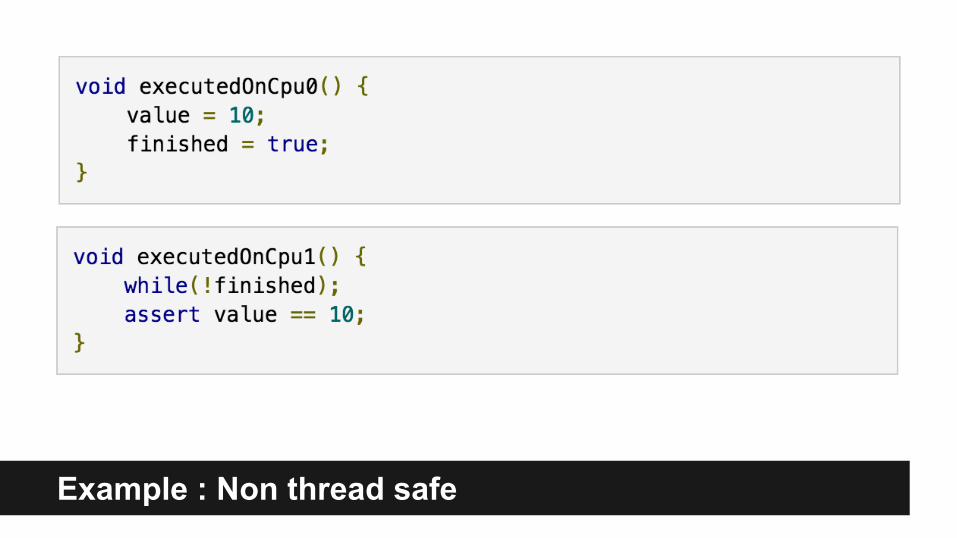
Example : Non thread safe

JMM (Java Memory Model)Java Memory model is set of rules and guidelines which allows Java programs to behave deterministically across multiple memory architecture, CPU, and operating systems.

Thread safe version (visibility + reordering both solved)
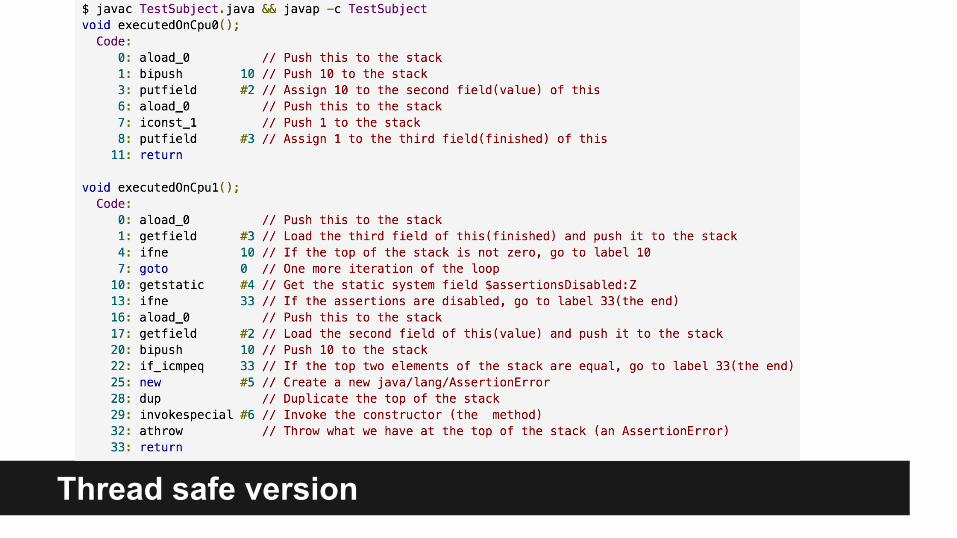
Thread safe version
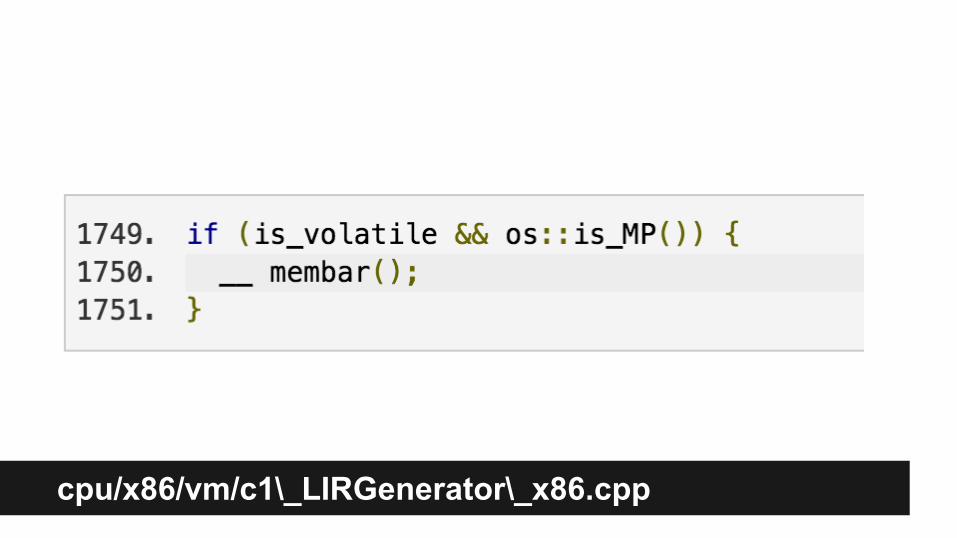
cpu/x86/vm/c1\_LIRGenerator\_x86.cpp
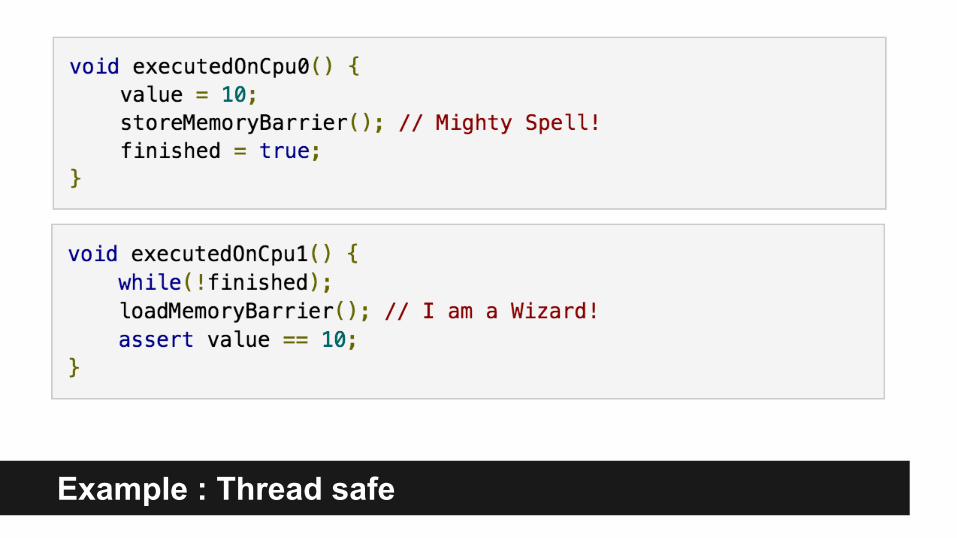
Example : Thread safe
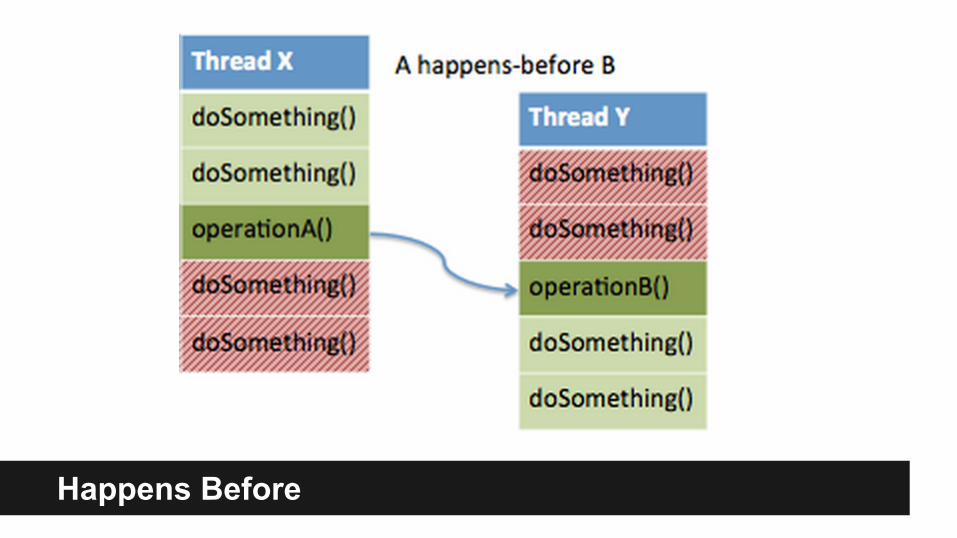
Happens Before
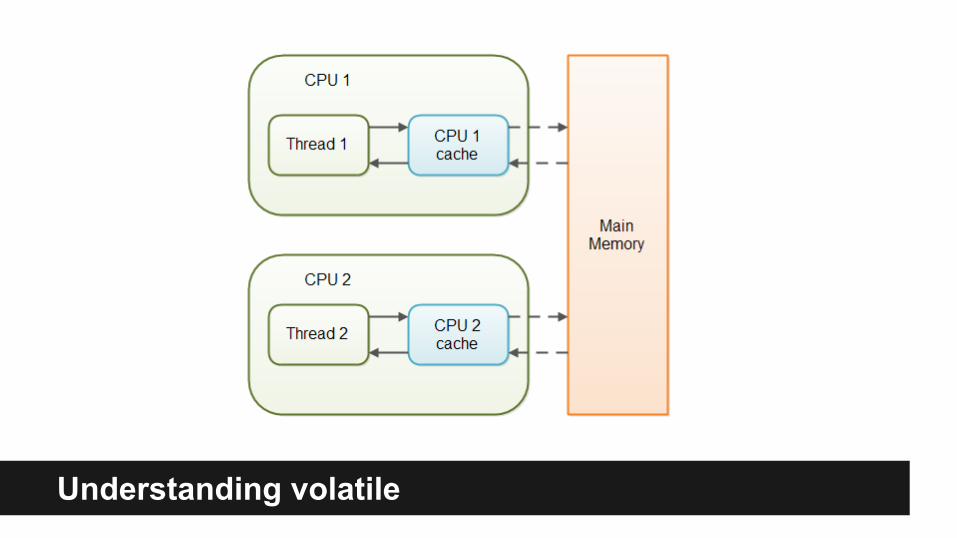
Understanding volatile

Conclusions on Volatile
● Volatile guarantees that changes made by one thread is visible to other thread.
● Guarantees that read/write to volatile field is never reordered (instructions before and after can be reordered).
● Volatile without additional synchronization is enough if you have only one writer to the volatile field, if there are more than one you need to synchronize...
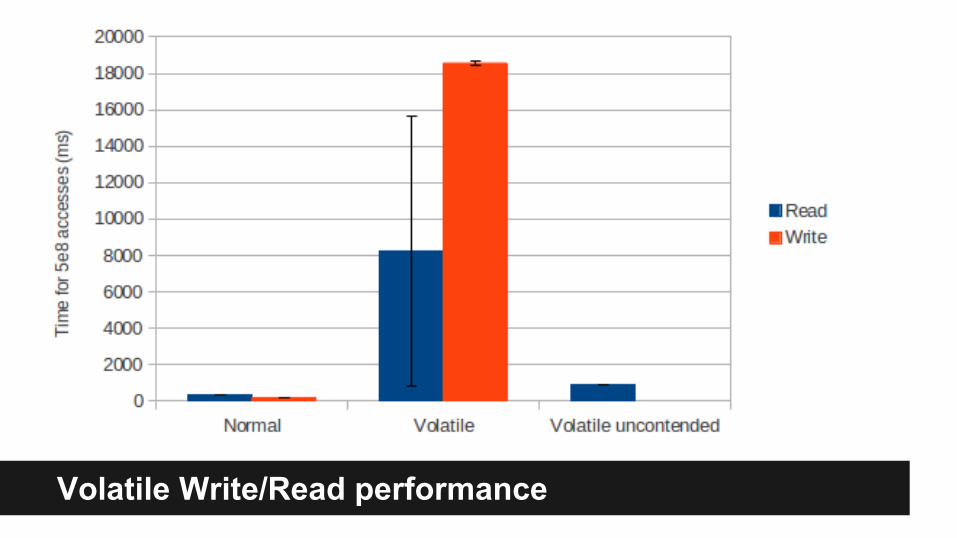
Volatile Write/Read performance
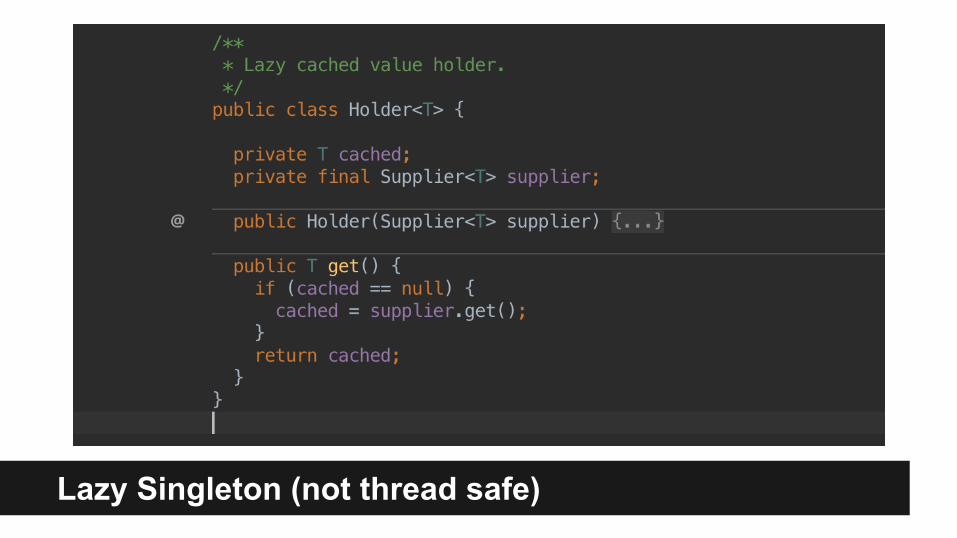
Lazy Singleton (not thread safe)
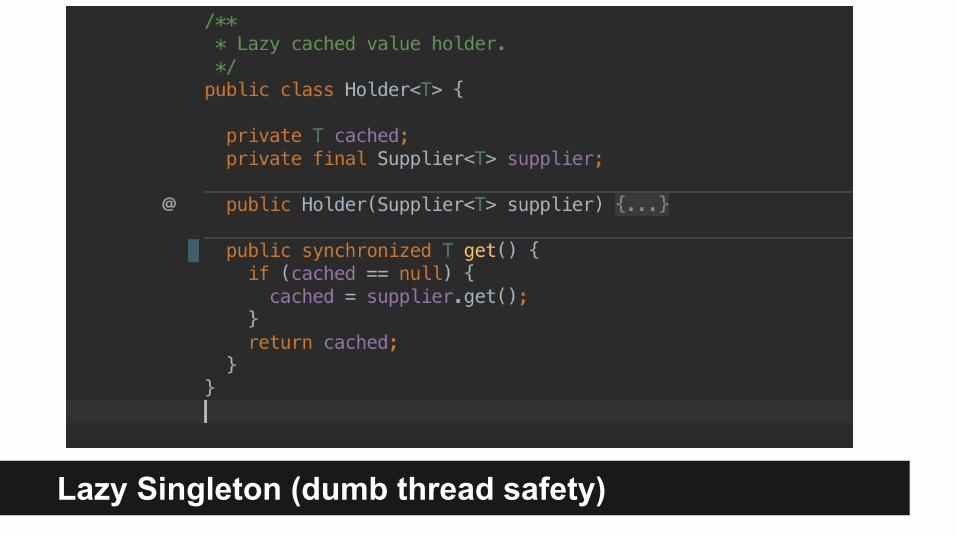
Lazy Singleton (dumb thread safety)
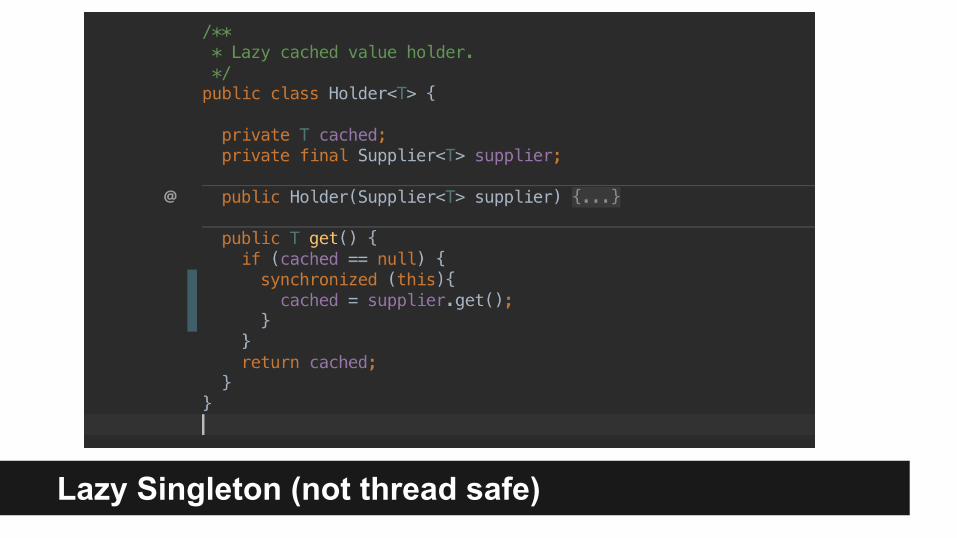
Lazy Singleton (not thread safe)
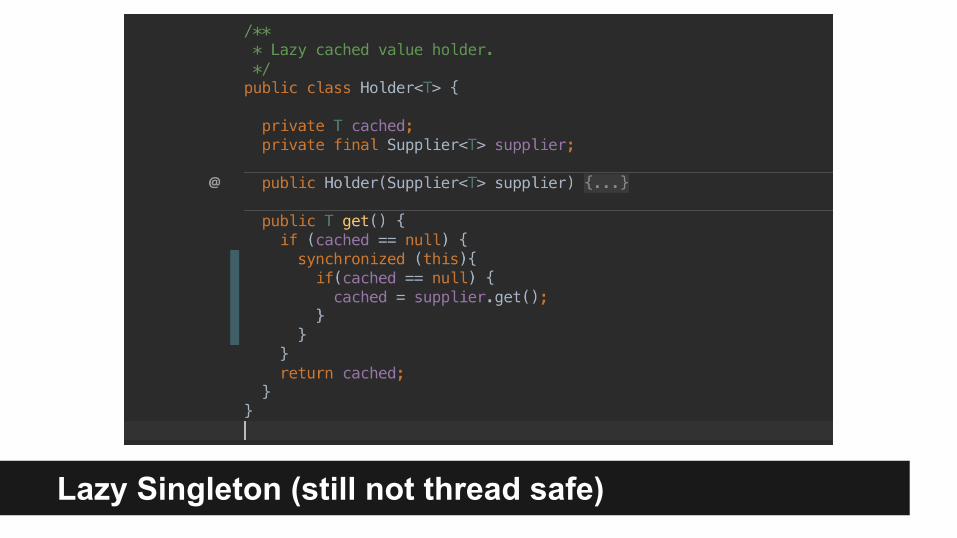
Lazy Singleton (still not thread safe)
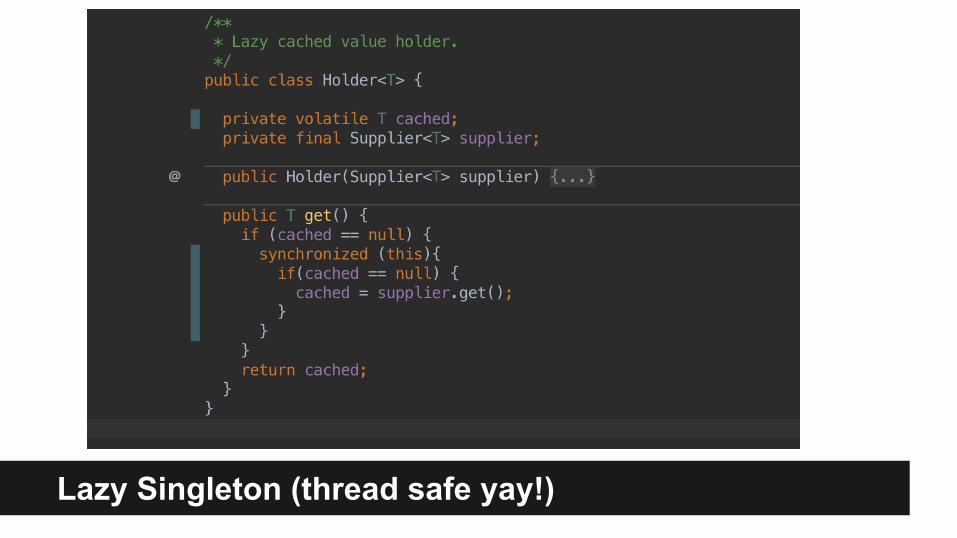
Lazy Singleton (thread safe yay!)
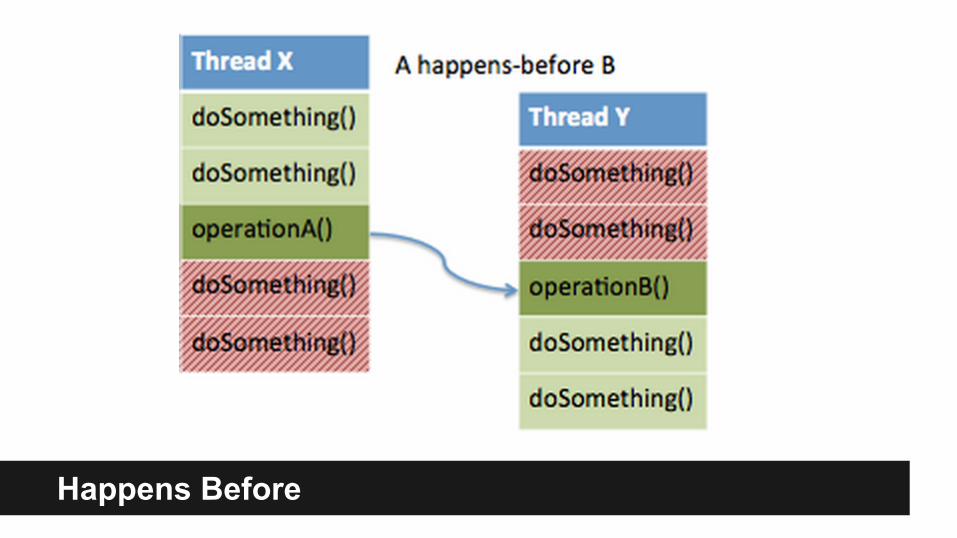
Happens Before
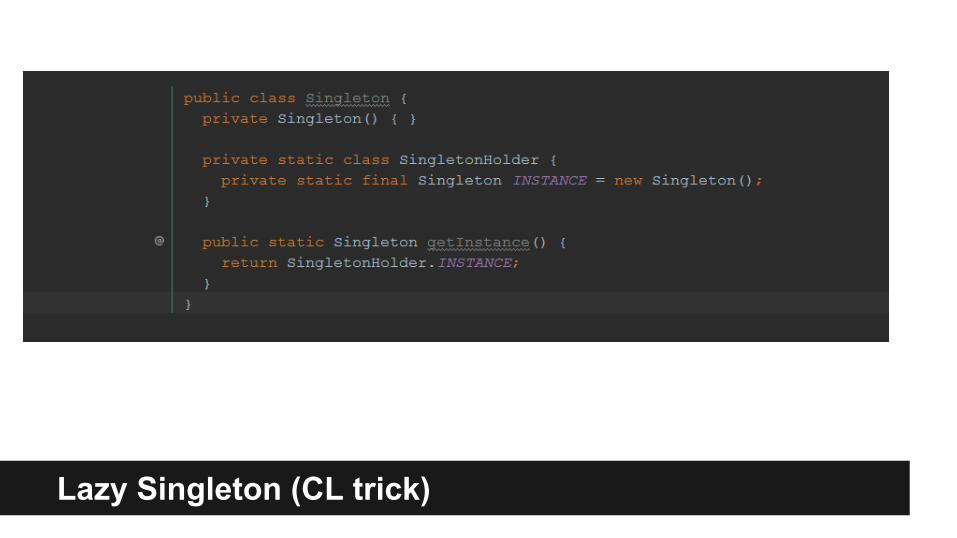
Lazy Singleton (CL trick)
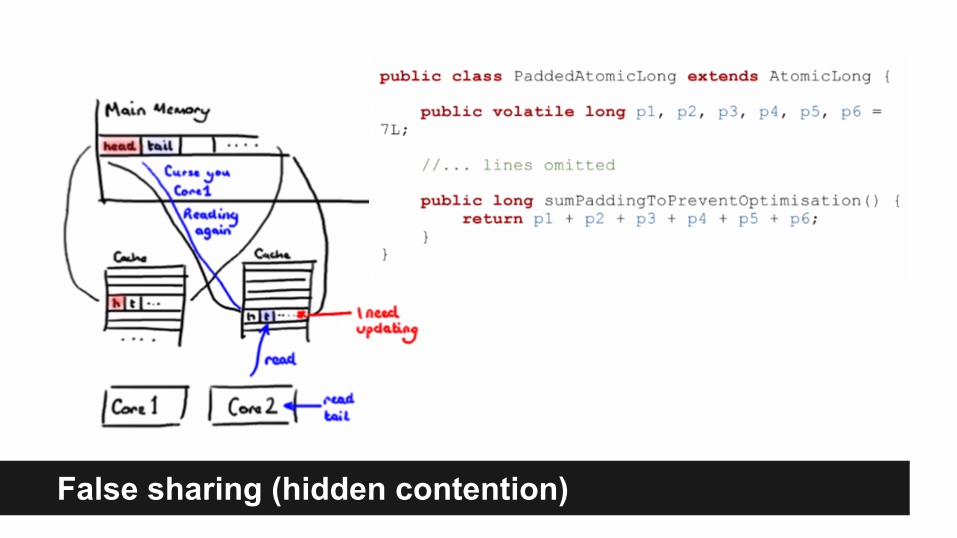
False sharing (hidden contention)
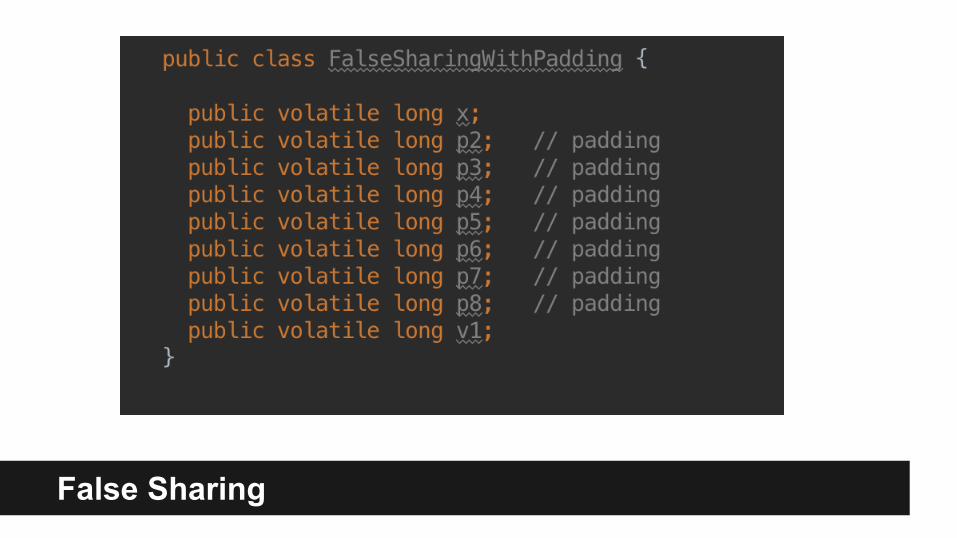
False Sharing
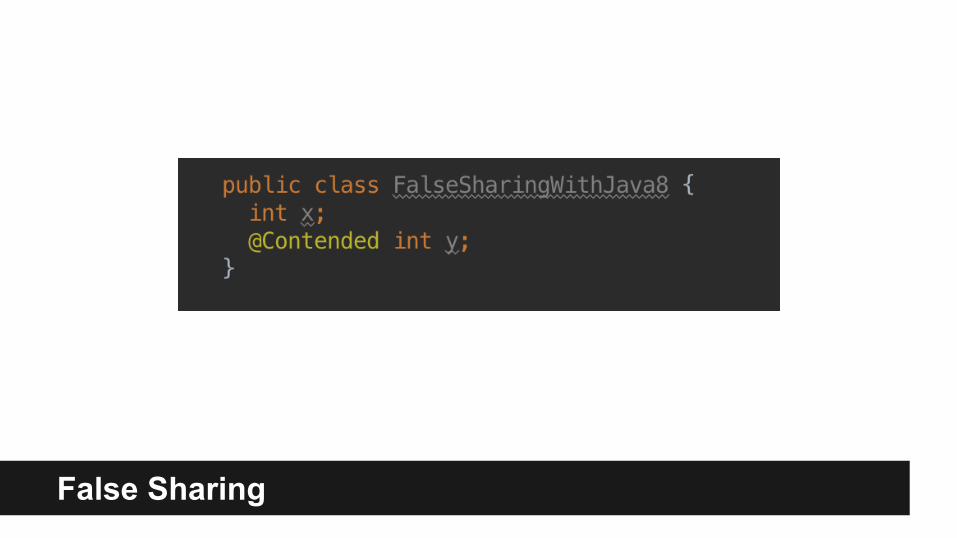
False Sharing

Monitors
Monitor Operations :● monitorenter● monitorexit● wait● notify/notifyAll
Monitor States :● init● biased● thin● fat (inflated)

Cost of Contention

Conclusion
● Volatile reads are not that bad● Avoid sharing state● Avoid writing to shared state● Avoid Contention

Tools
● JMH OpenJDK tool to write correct benchmarks● JMH Samples● Jcstress tool to test critical sections of concurrent code● JOL (Java Object Layout) helps to measure sizes of objects
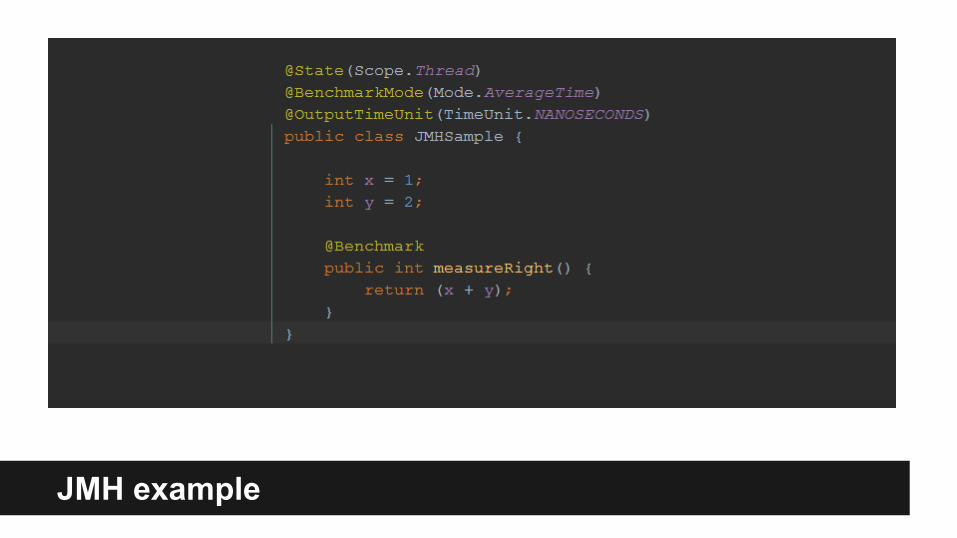
JMH example
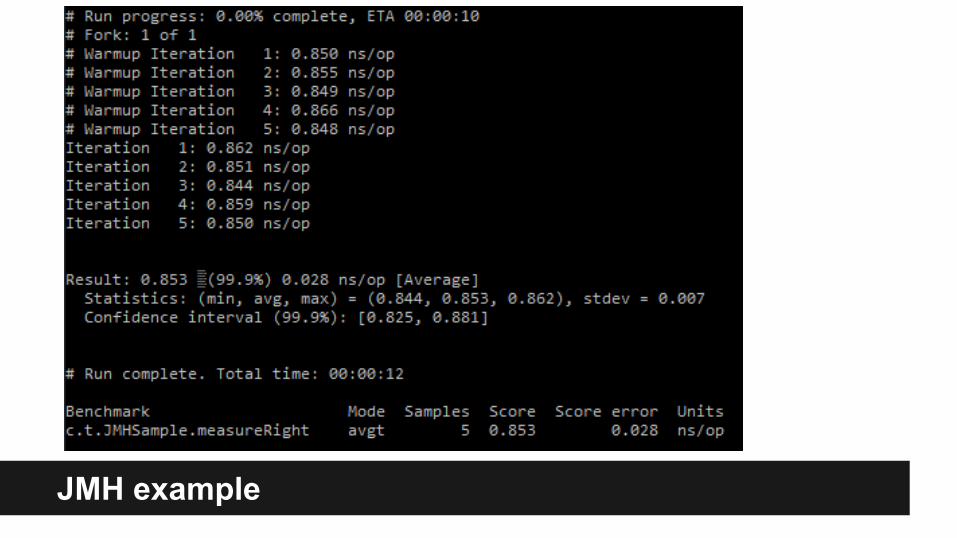
JMH example
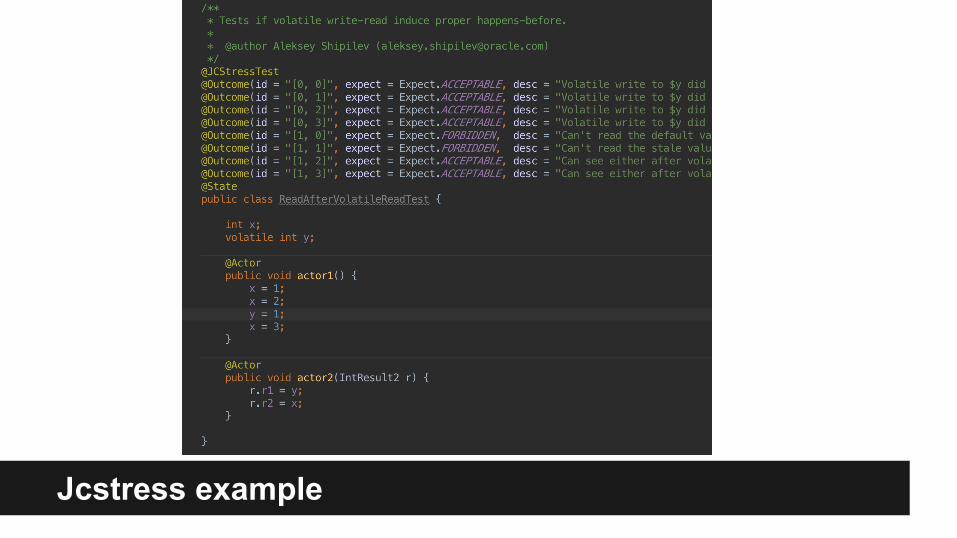
Jcstress example
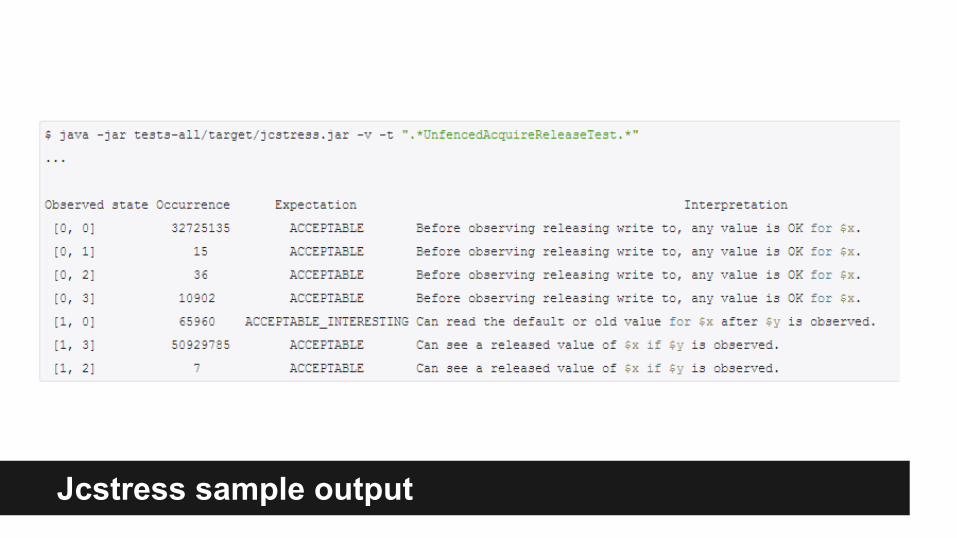
Jcstress sample output

IMPORTANT!
Sometimes horizontal scaling is cheaper. Developing hardware friendly code is hard, it breaks easy if new developer does not understand existing code base or new version of JVM does some optimizations you never expect (happens a lot), it's hard to test, If your product needs higher throughput, you either make it more efficient or scale. When cost of scaling is too high then it makes perfect sense to make the system more efficient (assuming you don't have fundamentally inefficient system).
If you’re scaling your product and a single node on highest load utilizes low percentage of its resources (CPU, Memory etc…) then you have a not efficient system.
Developing hardware friendly code is all about efficiency, on most systems you might NEVER need to go low level, but knowledge of low level semantics of your environment will enable you to write more efficient code by default.
And most important NEVER EVER optimize without BENCHMARKING!!!
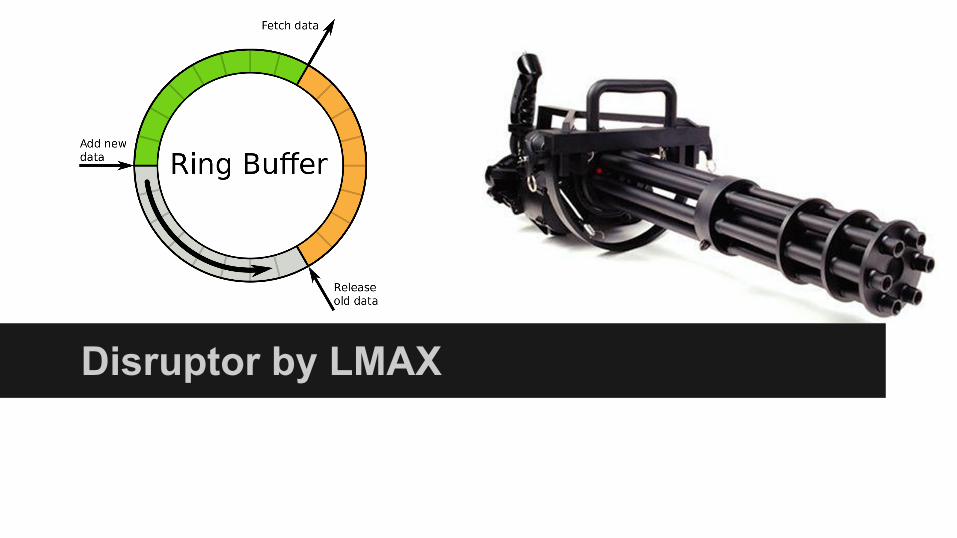
Disruptor by LMAX
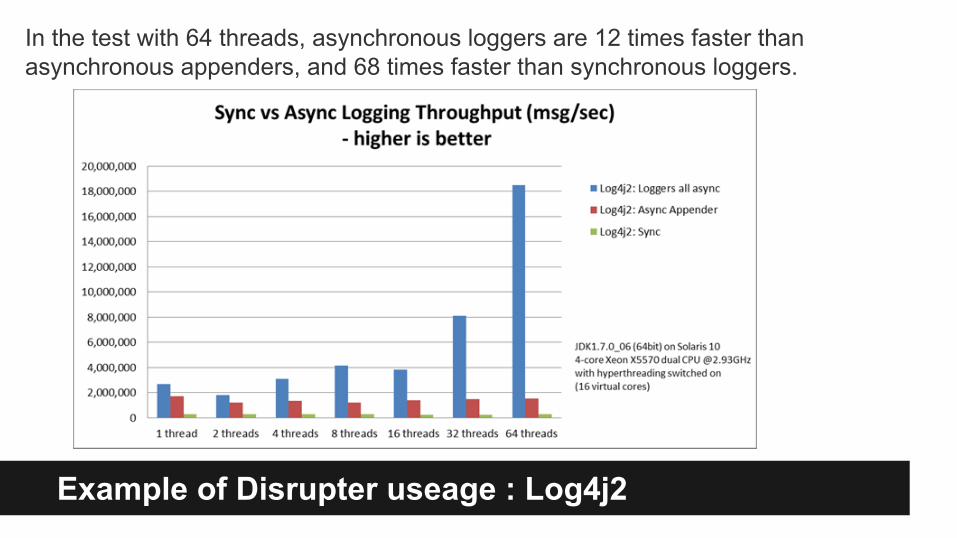
Example of Disrupter useage : Log4j2
In the test with 64 threads, asynchronous loggers are 12 times faster than asynchronous appenders, and 68 times faster than synchronous loggers.

Why?
● Generally any traditional queue is in one of two states : either its filling up, or it’s draining.
● Most queues are unbounded : and any unbounded queue is a potential OOM source.
● Queues are writing to the memory : put and pull… and writes are expensive. During a write queue is locked (or partially locked).
● Queues are best way to create CONTENTION! thats what often is the bottleneck of the system.
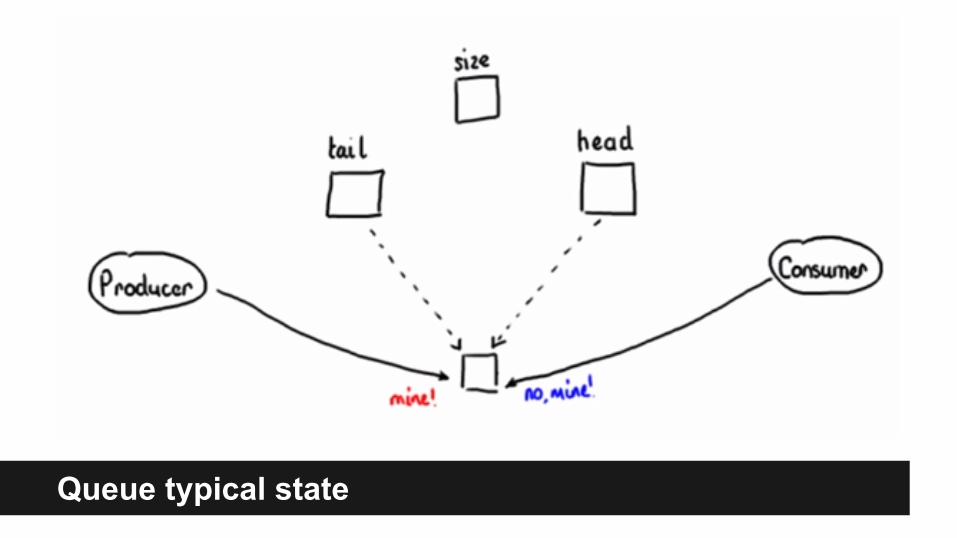
Queue typical state

What is it all about Disruptor?
● Non blocking. A write does not lock consumers, and consumers work in parallel, with controlled access to data in the queue, and without CONTENTION!
● GC Free : Disruptor does not create any objects at all, instead it pre allocates all the memory programmatically predefined for it.
● Disruptor is bounded.
● Cache friendly. (Mechanical sympathy)
● Its hardware friendly. Disruptor uses all the low level semantics of JMM to achieve maximum performance/latency.
● One thread per consumer.
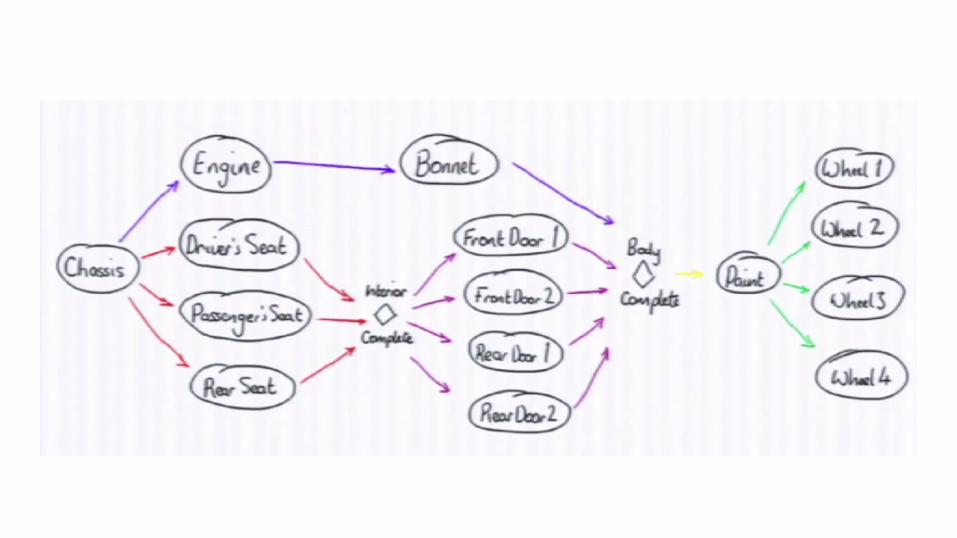
Theory : understanding disruptor
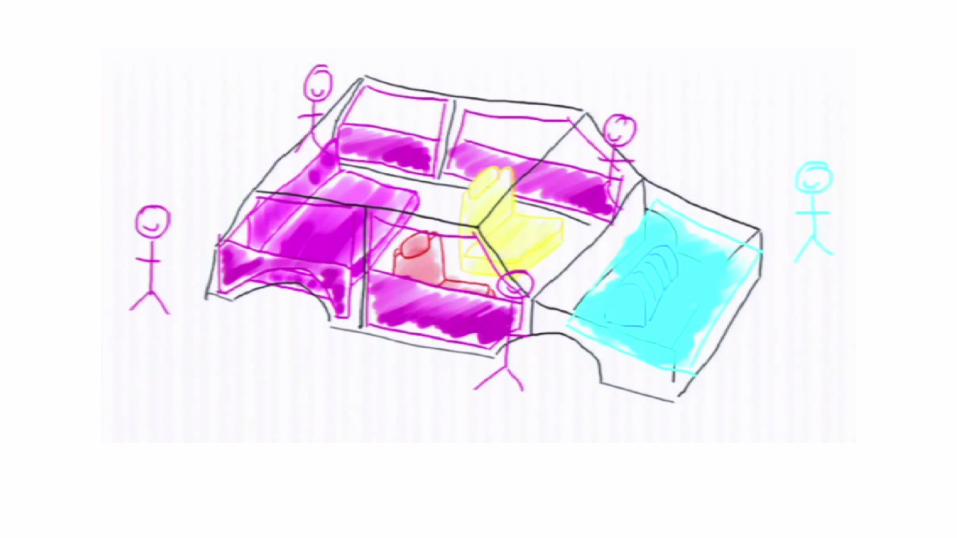
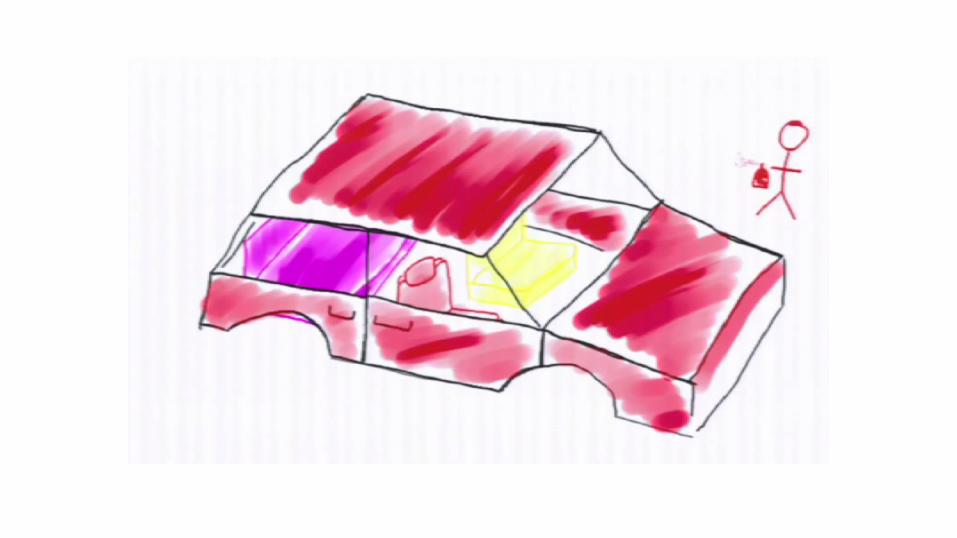
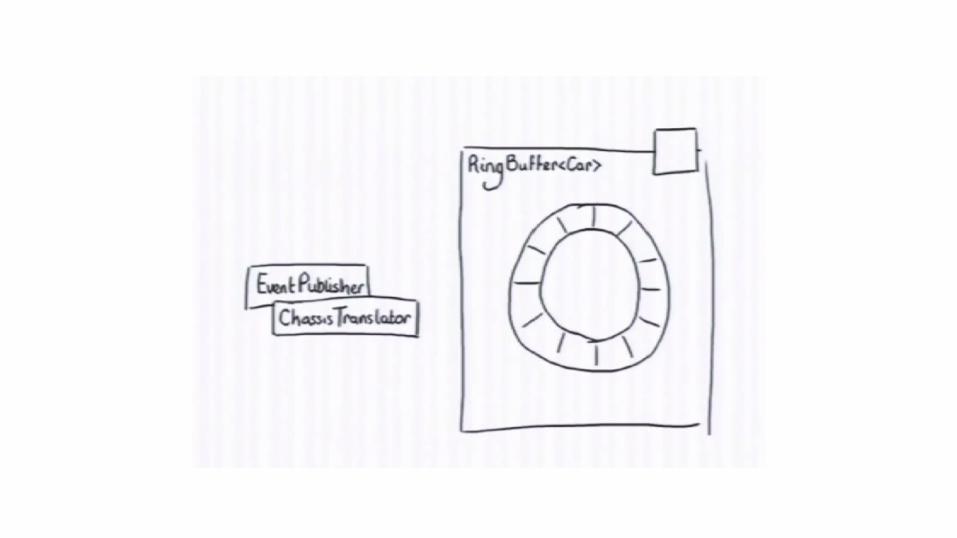
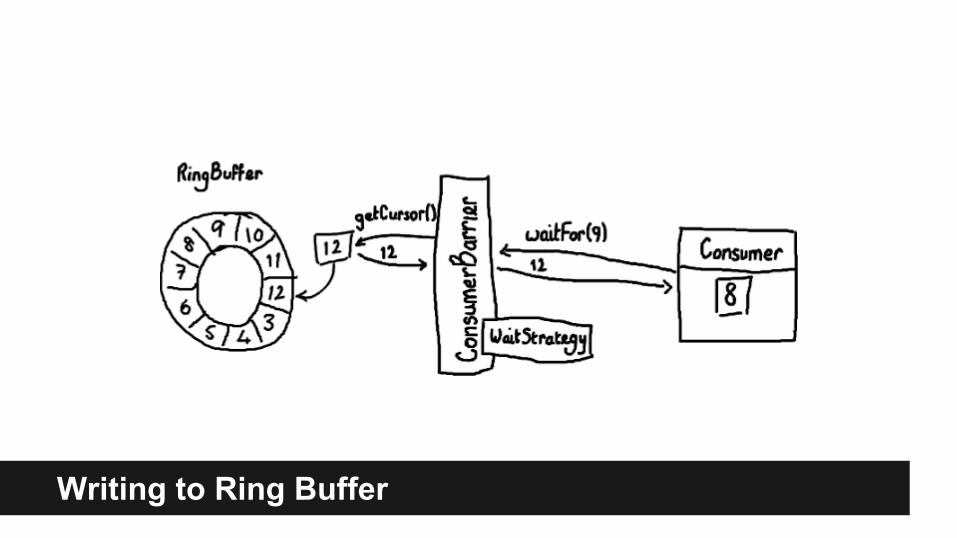
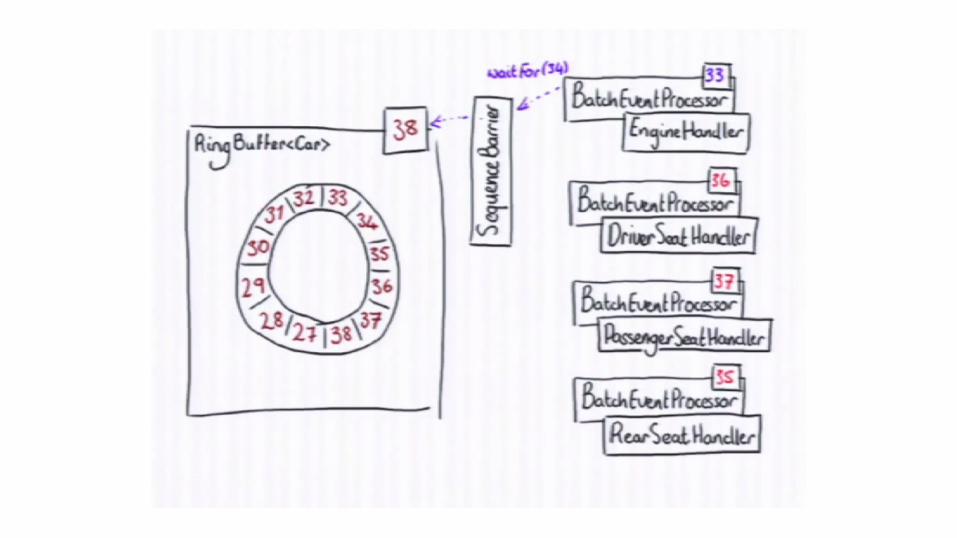
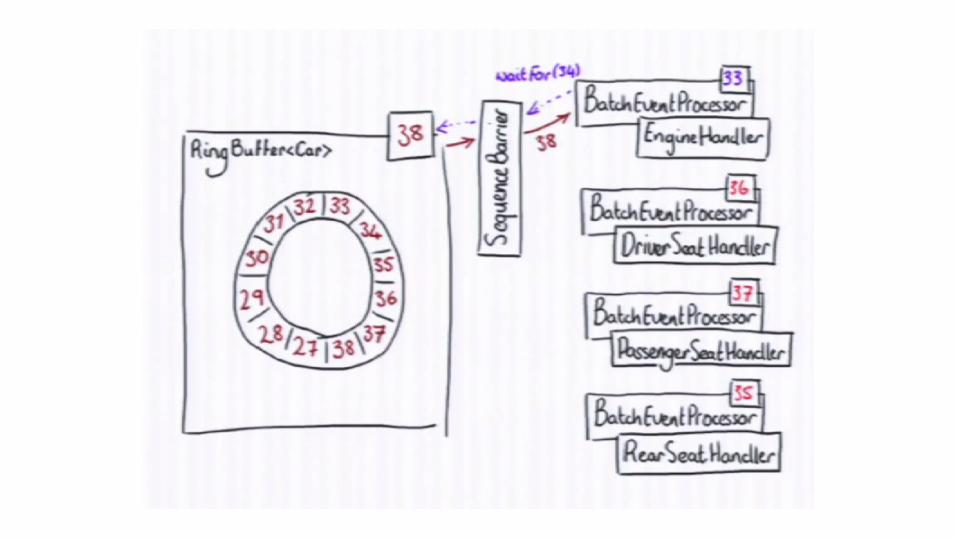
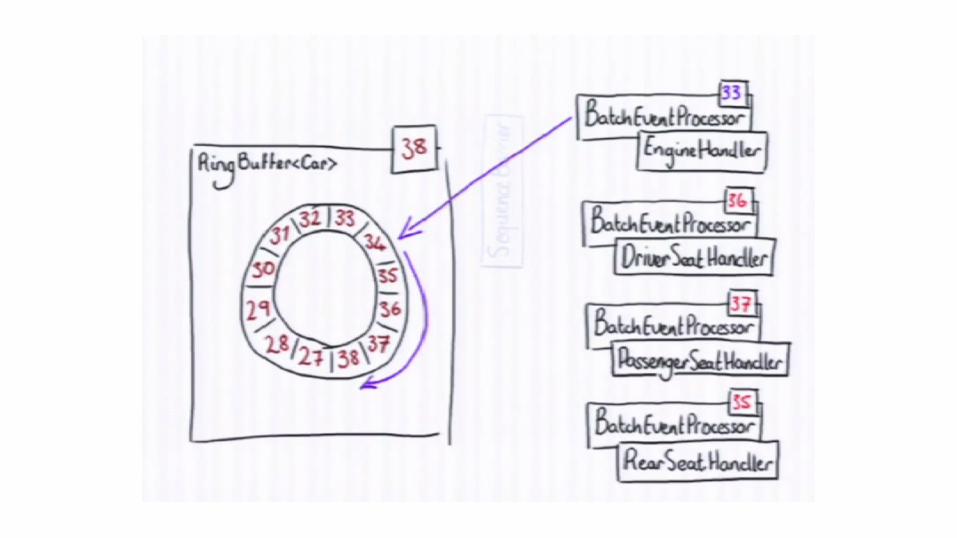
Writing to Ring Buffer
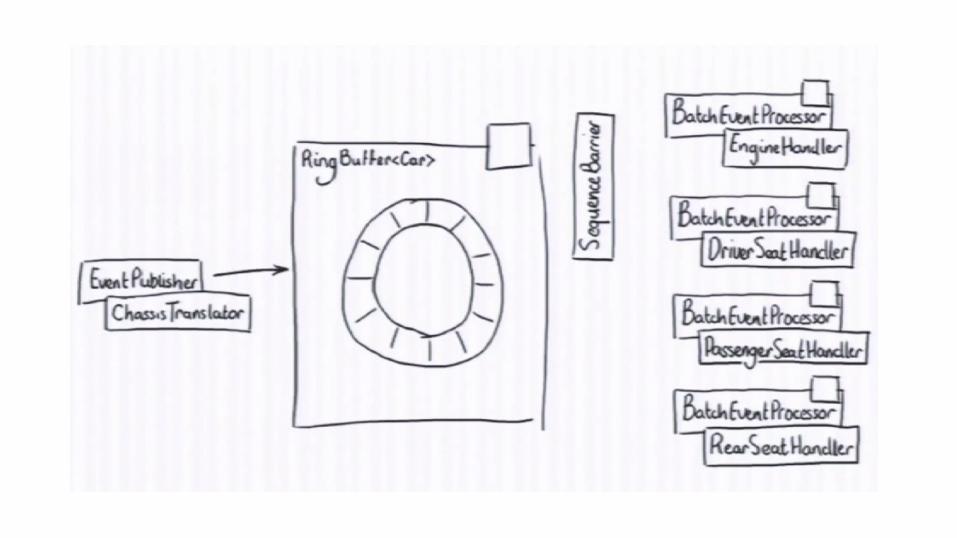
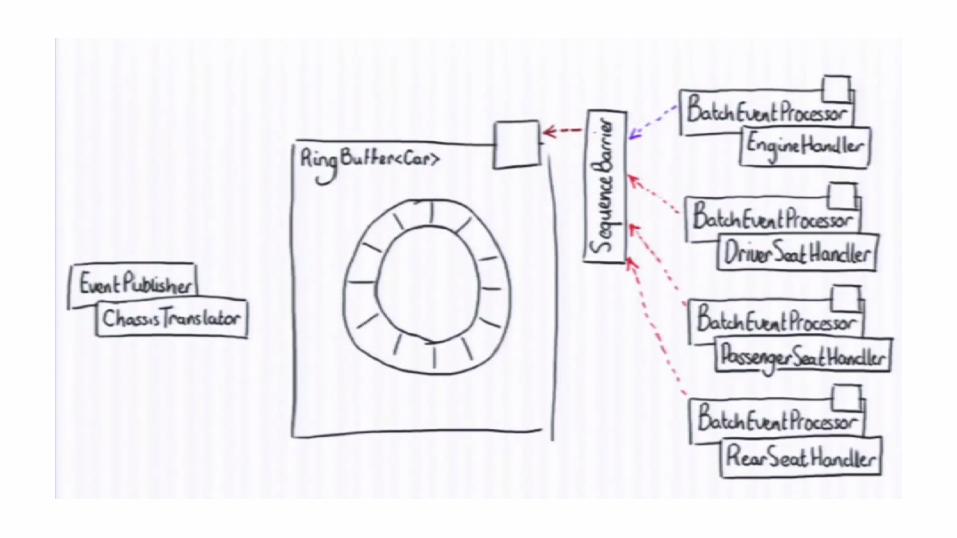
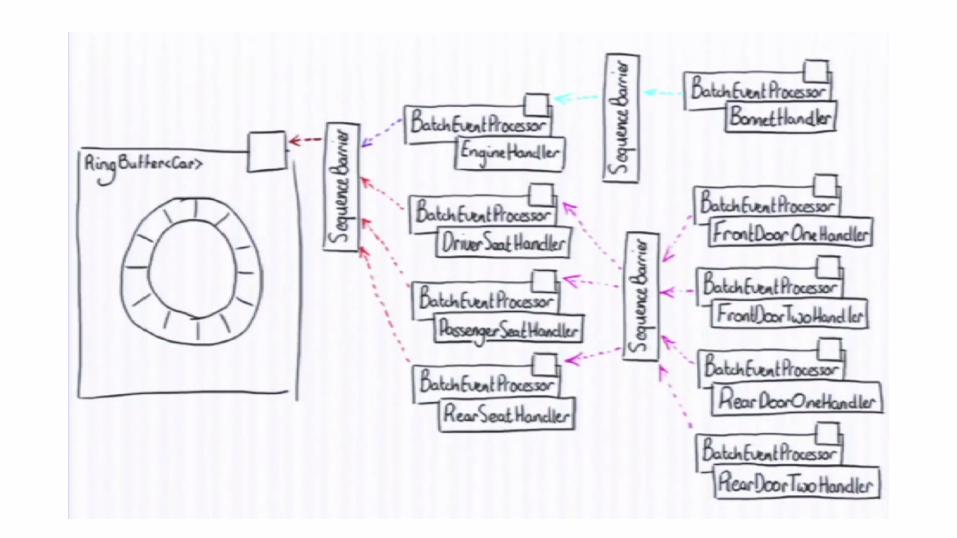
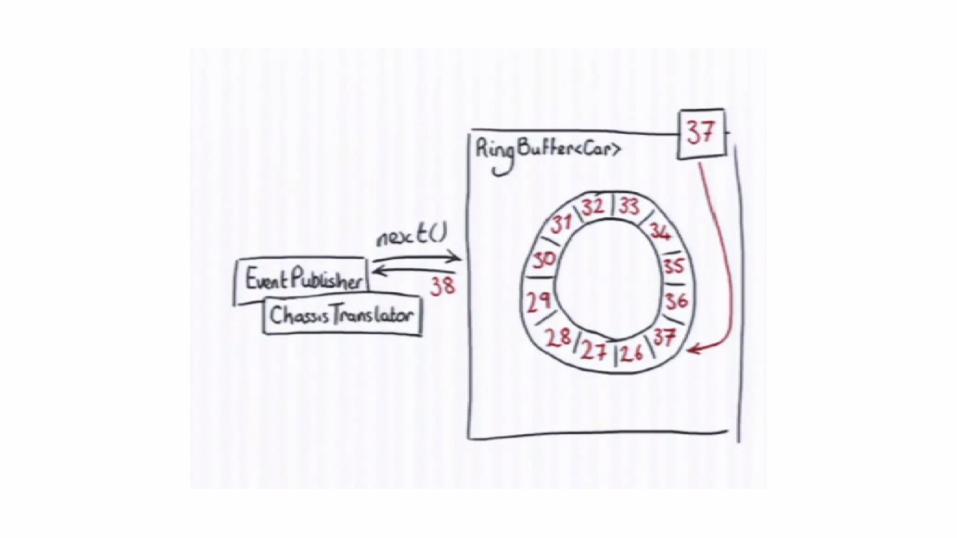
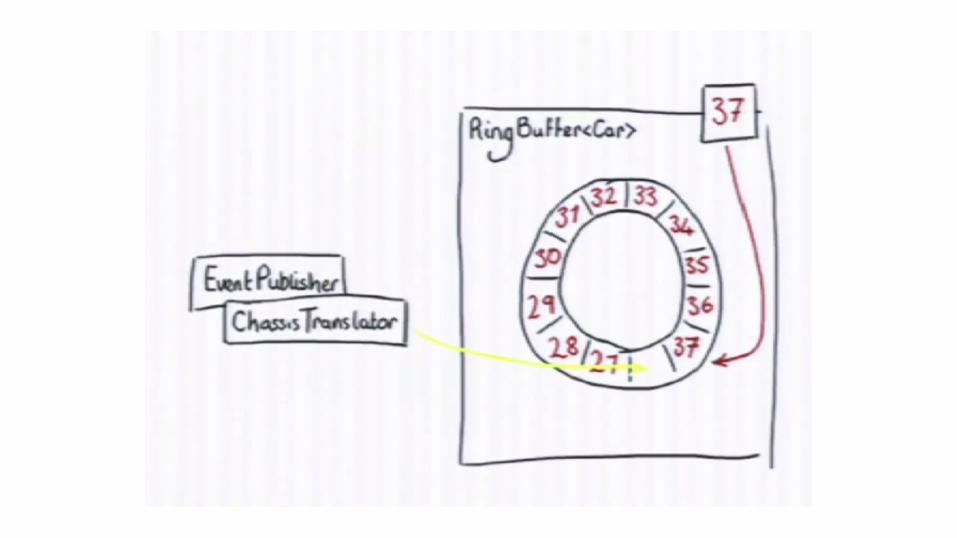
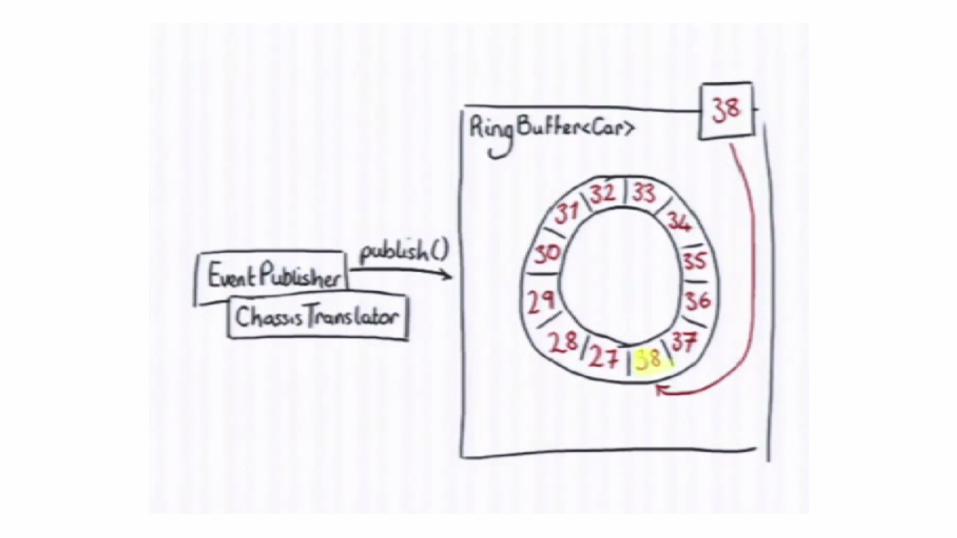
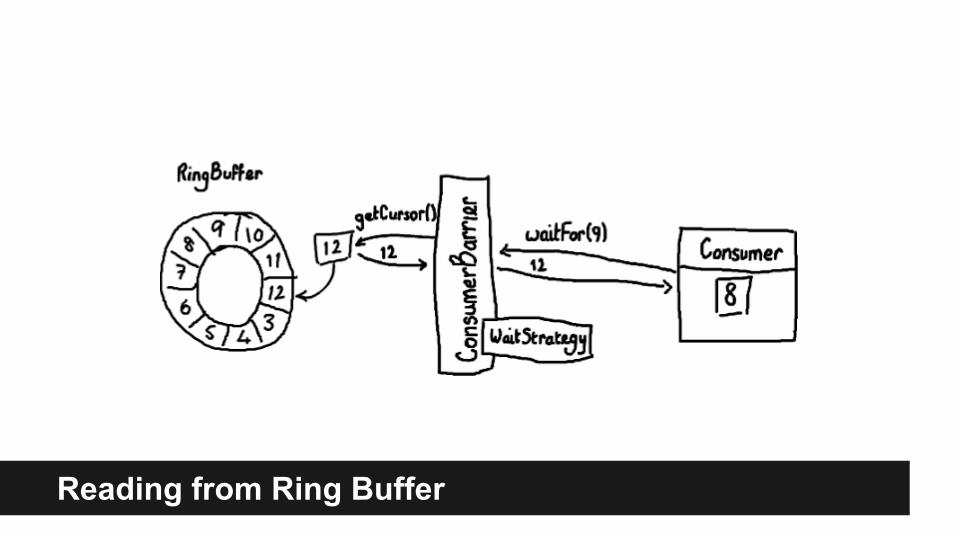
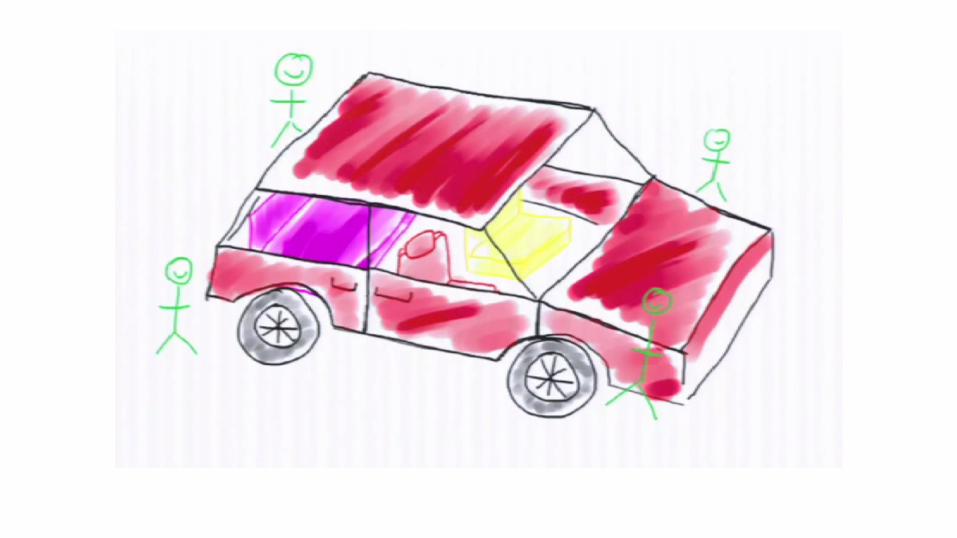
Reading from Ring Buffer
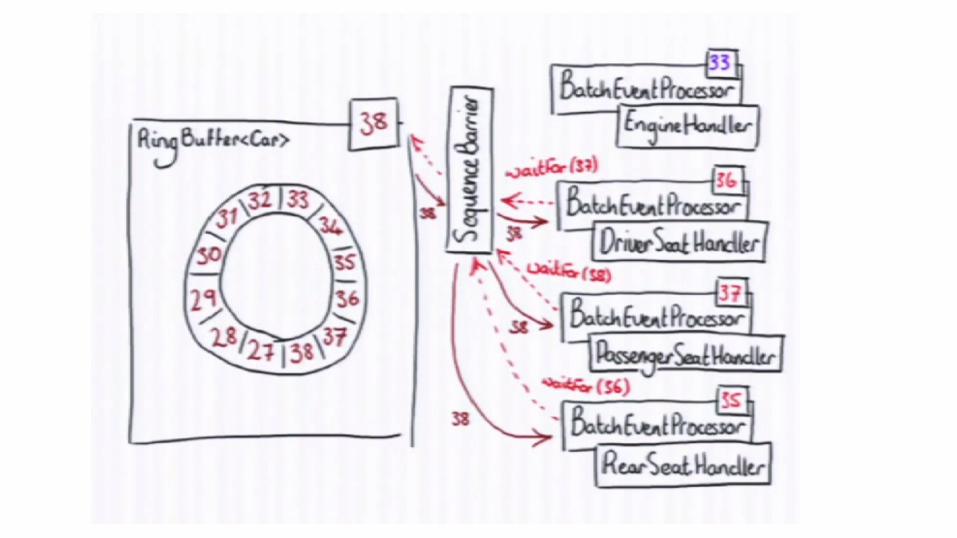
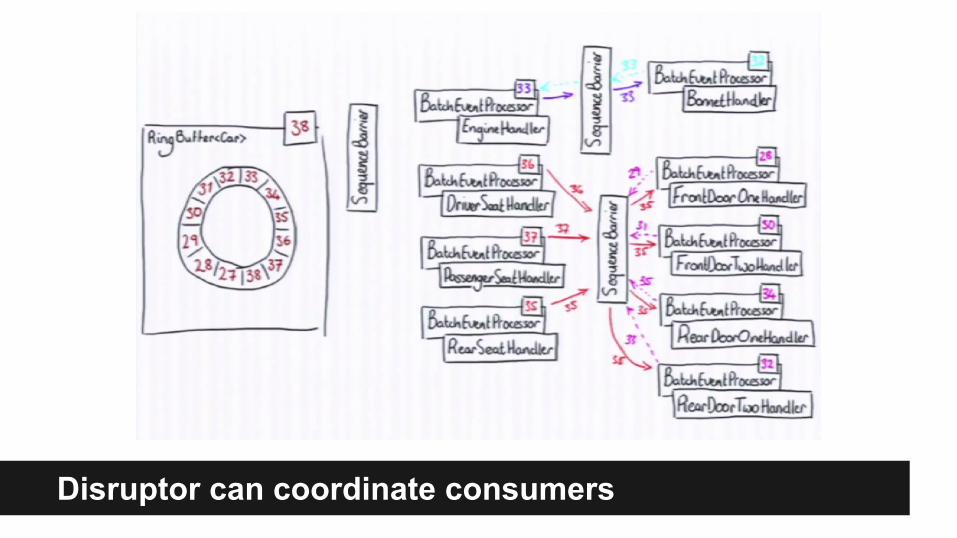
Disruptor can coordinate consumers
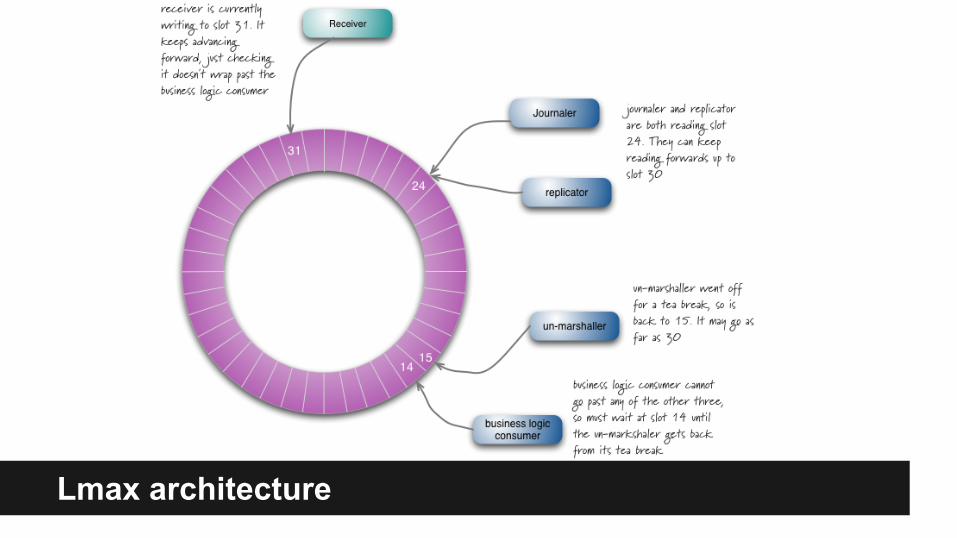
Lmax architecture

Disruptor (Pros)● Performance of course● Holly BATCHING!!!● Mechanical Sympathy● Optionally GC Free● Prevents False Sharing● Easy to compose dependant consumers (concurrency)● Synchronization free code in consumers● Data Structure (not a frickin framework!!!)● Fits werry well with CQRS and ES

Disruptor (Pros)
● Thread affinity (for more performance/throughput) ● Different strategies for Consumers (busy spin, sleep)● Single/Multiple producer strategy
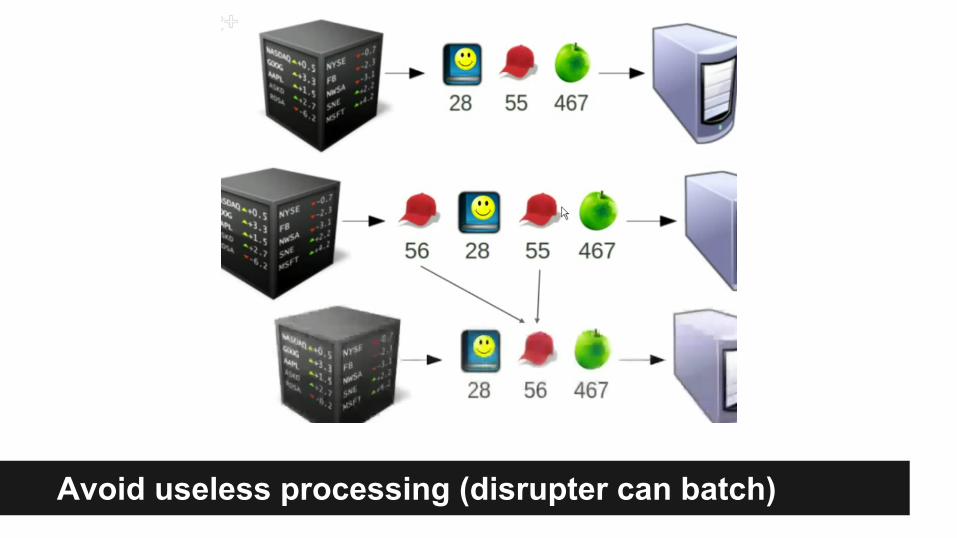
Avoid useless processing (disrupter can batch)

Disruptor (Cons)
● Not as trivial as ABQ (or other queues)● Reasonable limit for busy threads (consumers)● Not a drop in replacement, it different approach to queues

Disruptor Implementation (simplified : single writer)

No locks at all ( Atomic.lazySet )

Why power of 2?

Ring Buffer customizations
● Producer strategies○ Single producer○ Multiple producer
● Wait Strategies○ Sleeping Wait○ Yielding Wait○ Busy Spin



Resources
JitWatchPeter Lawrey blogAleksey Shipilyov stuffAbout TLABAbout MonitorsAbout Memory Barriers

And some stuff about high performance Java code
● https://www.youtube.com/watch?v=NEG8tMn36VQ● https://www.youtube.com/watch?v=t49bfPLp0B0● http://www.slideshare.net/PeterLawrey/writing-and-testing-high-frequency-trading-engines-in-java● https://www.youtube.com/watch?v=ih-IZHpxFkY

Links for LMAX Disruptor
● https://www.youtube.com/watch?v=DCdGlxBbKU4● https://www.youtube.com/watch?v=KrWxle6U10M● https://www.youtube.com/watch?v=IsGBA9KEtTM● https://www.youtube.com/watch?v=o_nXgoTxBsQ● http://martinfowler.com/articles/lmax.html● https://www.youtube.com/watch?v=eTeWxZvlCZ8

Coming next
Concurrency : Level 1Concurrency primitives provided by language SDK. Everything that provides manual control over concurrency.
- package java.util.concurrent.*- Future- CompletableFuture- Phaser- ForkJoinPool (in Java 8), ForkJoinTask, CountedCompleters
Concurrency : Level 2High level approach to concurrency, when library or framework handles concurrent execution of the code... (will cover only RxJava although there is a bunch of other good stuff)
- Functional Programming approach (high order functions)- Optional- Streams- Reactive Programming (RxJava)


















