
Java and the GPU - Everything You Need To Know
89
JAVA AND THE GPU EVERYTHING YOU NEED TO KNOW Adam Roberts
-
Upload
adam-roberts -
Category
Software
-
view
172 -
download
4
Transcript of Java and the GPU - Everything You Need To Know

JAVA AND THE GPU EVERYTHING YOU NEED TO KNOW
Adam Roberts

Important disclaimersCopyright © 2017 by International Business Machines Corporation (IBM). No part of this document may be reproduced or transmitted in any form without written permission from IBM.
U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM.
Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. THIS document is distributed "AS IS" without any warranty, either express or implied. In no event shall IBM be liable for any damage arising from the use of this information, including but not limited to, loss of data, business interruption, loss of profit or loss of opportunity. IBM products and services are warranted according to the terms and conditions of the agreements under which they are provided.
Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice.
Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary.
References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in which IBM operates or does business. Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or their specific situation. It is the customer’s responsibility to insure its own compliance with legal requirements and to obtain advice of competent legal counsel as to the identification and interpretation of any relevant laws and regulatory requirements that may affect the customer’s business and any actions the customer may need to take to comply with such laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer is in compliance with any law.
Information within this presentation is accurate to the best of the author's knowledge as of the 14th of May 2017

Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products in connection with this publication and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM does not warrant the quality of any third-party products, or the ability of any such third-party products to interoperate with IBM’s products. IBM expressly disclaims all warranties, expressed or implied, including but not limited to, the implied warranties of merchantability and fitness for a particular purpose.
The provision of the information contained herein is not intended to, and does not, grant any right or license under any IBM patents, copyrights, trademarks or other intellectual property right.
IBM, the IBM logo, ibm.com, Bluemix, Blueworks Live, CICS, Clearcase, DOORS®, Enterprise Document Management System™, Global Business Services ®, Global Technology Services ®, Information on Demand, ILOG, LinuxONE™, Maximo®, MQIntegrator®, MQSeries®, Netcool®, OMEGAMON, OpenPower, PureAnalytics™, PureApplication®, pureCluster™, PureCoverage®, PureData®, PureExperience®, PureFlex®, pureQuery®, pureScale®, PureSystems®, QRadar®, Rational®, Rhapsody®, SoDA, SPSS, StoredIQ, Tivoli®, Trusteer®, urban{code}®, Watson, WebSphere®, Worklight®, X-Force® and System z® Z/OS, are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners: oher names mentioned here include AMD, Nvidia, Tensorflow. Aparapi, Jcuda, cuDNN, cuBLAS, Project Sumatra, OpenJDK, CERN, Geant, AlphaGo, Oak Ridge, Titan, Lenovo, Tesla, Netflix, Rice University, Devoxx, DeepLearning4j. A current list of IBM trademarks is available on the Web at "Copyright and trademark information" at: www.ibm.com/legal/copytrade.shtml.Databricks is a registered trademark of Databricks, Inc. Apache Spark, Apache Cassandra, Apache Hadoop, Apache Maven, Spark, Apache, any other Apache project mentioned here and the Apache product logos including the Spark logo are trademarks of The Apache Software Foundation.

Stick around for...● Sharing observations and our progress● How to get started● The good and the bad● Interesting related projects● Plenty of code to show you● Tips for avoiding common problems

1) No liability accepted for any of the code I'll be sharing today and providing with this presentation at the end – to be used at your own risk! My sample code isn't for production use – I've skimmed on plenty of application hardening techniques (checking error codes, using final, correct visibility modifiers etc)
2) Experiments with lots of threads meaning potentially lots of problems -really- don't run the parallel example trying to use 50,000+ CPU threads coming up – and if we make it to the end, don't run the “kernelception” program either
3) Messing around with graphics drivers on your work laptop isn't a good idea unless you have a good backup in place (my laptop was a headless server for a few days), I changed BIOS settings and made a few mistakes along the way – you have been warned!

✗ In-depth look at alternatives: talking about Nvidia's CUDA + IBM's SDK for Java mainly
✗ In-depth debugging and profiling✗ Real impressive applications – I'll be talking about how to get started to give you
ideas: GPUs may be a useful fit for that simple processing task with lots of data✗ Java basics – assuming you know about Java options, building and running and
you're now interested in doing lots of operations at once as fast as possible
What I won't be covering today...

z13
BigInsights
Who's using Java?

How many operations can I run at once on my laptop with
JUST the CPUs in Java?

● Stackoverflow post titled “custom thread pool in Java 8 parallel stream”● http://stackoverflow.com/questions/21163108/custom-thread-pool-in-java-8-par
allel-stream● Involves a parallel().forEach and
java.util.concurrent.ForkJoinPool.common.parallelism● See how many threads I can run with before the JVM crashes

numThreads = 5
Finishes OK – no problems

Finishes instantly – no problems
numThreads = 50

Faster, constant output, still no problems, laptop getting noisy now...
numThreads = 1,000

numThreads = 50,000?

● Laptop preparing to take off from my desk● No native memory to create new threads● Unable to terminate the process in my shell - ^C's – they do nothing!● Mouse stuttering around...can't...click...the x...now curious what happens● JVM trying to create coredumps, javacores repeatedly: trying to eat up my disk space - no
memory to create those anyway● LibreOffice crashes, lost unsaved work (past experiments needing to be redone)● Still can't ctrl-c to stop everything● Can't launch any new processes (no chance of launching system monitor)● Wanted to get a printscreen – no memory available, rebooted.

We'll struggle trying to run thousands of threads at once in one JVM (using a single machine and a single CPU with many cores), but using GPUs can sometimes be of use
Use cases for GPUs share typically share these common themes, we want to:● Achieve results fast● Execute many threads to quickly process data for my “easily parallelisable” operations● Handle large amounts of data● Great for machine learning: quickly compute and store models to use later
Reaching out to GPUs for more processing power from Java

AlphaGo beating a Go champion:1,202 CPUs, 176 GPUsTitan: 18,688 GPUs, 18,688 CPUsCERN: reported to be using GPUsOak Ridge, IBM “the world's fastest supercomputers by 2017”: two, $325mDatabricks: recent blog post mentions deep learning with GPUs
Who's using GPUs already? Only public knowledge provided here, certainly
many more than this!

● Recent AI vs Poker win (from top500: “bridges-supercomputer” articlehere: mentions using 64 Nvidia P100 GPUs!
● Recent Amazon cloud offering: GPUs as a service● Even more recent: Nvidia cloud
Nvidia email as part of the accelerated computing newsletter mentions…● Deep learning to combat asteroids● Detecting road lanes with deep learning● Algorithm to identify skin cancer● Lip reading AI more accurate than humans● Life-changing wearable for the blind
Lots more success stories – what makes a GPU useful?
How can you get involved?

GPUs excel at executing many of the same operations at once (Single Instruction Multiple Data programming)
We'll program using CUDA or OpenCL – like C and C++ but not quite the same (nuances like <<< and >>> for kernels in CUDA) and we can write JNI code to access data in our Java world using the GPU
We'll run code on computers that are shipped with graphics cards, there are free CUDA drivers for x86-64 Windows, Linux, and IBM's Power LE, OpenCL drivers, SDK and source also widely available
GPU CPU

“What types of GPUs can I get?Does it make a difference?”

● “Graphics adapters” you can plug a monitor into● 2 to 4 GB~ GDDR5 memory● < a thousand processing cores● Clock speed ~ 1250 mhz● Typical in laptops, desktop gaming computers● For this presentation, experiments (unless otherwise stated) were performed on my Lenovo p50 laptop (discrete graphics mode set in the BIOS, CUDA 7.5, RHEL 7.3, 32 GB RAM, M1000M Quadro GPU, 8 core Intel(R) Core(TM) i7-6820HQ CPU @ 2.70GHz processor, ext4 filesystem)

● HPC cards like the Tesla series● GDDR5 memory - typically 8G to 24G● 1-5 thousand processing cores● Offering teraflops of performance● ~500 GB/sec max memory bandwidth*● Remember you're going to be limited by the PCIe bus if it's between CPU and GPU, for CUDA devices, use deviceQuery, bandwidthTest applications)● 300W~ thermal design power rating

“How about bandwidth? I've got to transfer my data to the
GPU right?”

[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: Quadro M1000M
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 12152.3
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 12225.6
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 66464.2
Device to device is quick but the host and device interchange is far
slower
Compare this to direct memory access…

Data
We can process lots of primitive types at once● ints, longs, doubles, shorts, floats – perhaps used in...
● Matrix multiplication (dot product for ML?)● Simple transforms (change our masses of longs by a known offset amount?)● Find a pattern in the data: count occurrences of a certain string from Wikipedia dumps
Operations
Keep it simple – without branching and complexity● Great for arithmetic ops (very fast floating point ops...)
Workloads a GPU can excel at

Data
The data we need isn't “self contained” – we can't send down one whole block of data and get meaningful results as we depend on data elsewhere...lots of copying back and forth will be slow
Operations● Non-arithmetic based – code that touches files, uses the network, manipulates
objects...stick to the maths● Involves new object creation or throwing exceptions● Using threads for different instructions simultaneously
● try to keep it simple without lots of if/elses
Not so good when...

1) Declare a regular C style int array in a .cu file
2) Declare a new variable of the same type e.g. int* myDataOnGPU
3) Allocate space on the GPU (device side) using cudaMalloc passing in the address of myDataOnGPU and how many bytes to reserve as a parameter (e.g. cudaMalloc(&myDataOnGPU), 400)
4) Copy myData from the host to your allocated space (myDataOnGPU) using cudaMemcpyHostToDevice
5) Process your data on the GPU in a kernel (we use <<< and >>>)
6) Copy the result back (what's at myDataOnGPU replaces myData on the host) using cudaMemcpyDeviceToHost
How can we use a GPU? Basic principles

“What is a kernel?!”

__global__ void addingKernel(int* array1, int* array2){ array1[threadIdx.x] += array2[threadIdx.x]; }
__global__ : it's a function we can call on the host (CPU), it's available to be called from everywhere. __device__ and __host__ also exist
How is the data arranged and how can I access it?Sequentially, a kernel runs on a grid (numBlocks X numThreads) and this is how we can run many threads that work on different parts of the data
int* is a regular pointer to integers we've copied to the GPU
threadIdx.x: built-in variable inside of kernels an index to our array, remember lots of threads run on the GPU, this can be our way to access each unique item – if we run a kernel <<<1, 256>>>, that means one block and 256 threads will run on the GPU each time you call the kernel

Multiprocessors (also known as streaming multiprocessors or stream processors): these execute one or more thread blocks
CUDA core: they execute the threads themselves
Threads on a GPU: many more are available than with CPUs and these are organised into the blocks
Kernel: a function we'll run on the GPU
How many threads can I really run at once?
Multiprocessor count X their limit
e.g. 4 * 2048 with 512 CUDA cores for me
A Tesla K80m has 26 multiprocessors and 4992 CUDA cores (2496 per GPU), 2048 threads per multiprocessor also. Other threads wait to be executed
More stuff to know...

“How much do I need to know?”

Kernels must be launched with grid dimensions specified
Grid: logical 3d representation of how threads can be run on a given GPU – a kernel runs on a grid. This grid has potentially many blocks with threads organised “inside” each block (actually get run on the MP)
Our GPU functions (kernels) run on one of these grids and the dimensions include how many blocks and threads a kernel should run
The nvidia-smi command tells you about your GPU's limits – know these to prevent launch configuration problems
A good starting point is to pick 512 for the number of threads and the number of blocks varies depending on your problem size – then launch multiple kernels in a tight loop modifying the offset to operate on different portions of the data
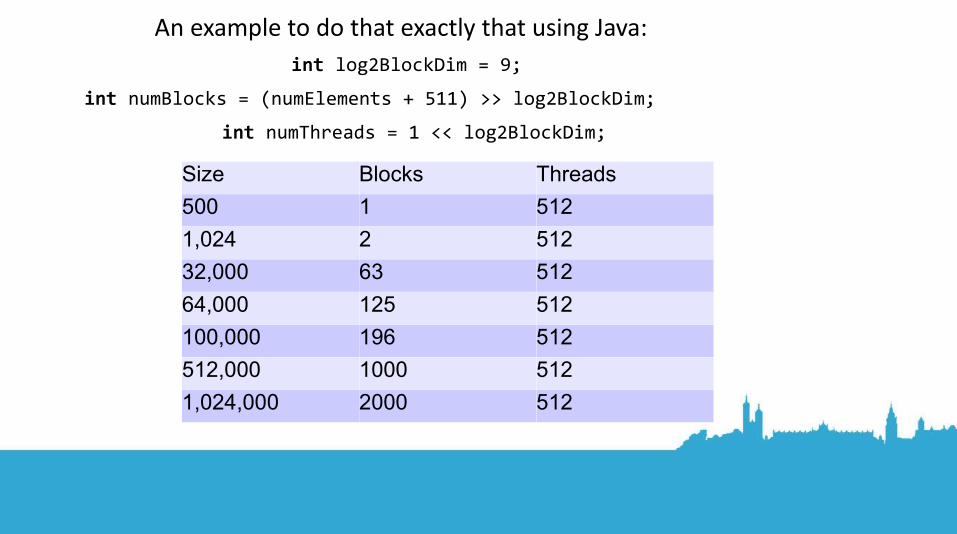
An example to do that exactly that using Java: int log2BlockDim = 9;
int numBlocks = (numElements + 511) >> log2BlockDim;
int numThreads = 1 << log2BlockDim;
Size Blocks Threads
500 1 512
1,024 2 512
32,000 63 512
64,000 125 512
100,000 196 512
512,000 1000 512
1,024,000 2000 512

“I need to see an example...”

#include <cuda.h>#include <stdio.h>
const int NUM_ELEMENTS = 5;
__global__ void addToMe(int* someInts, int amountToAdd) { someInts[threadIdx.x] += amountToAdd;}
// This is in foo.cu → nvcc foo.cu → ./a.outint main() { int* myHostInts = (int*) malloc(sizeof(int) * NUM_ELEMENTS);
for (int i = 0; i < NUM_ELEMENTS; i++) { myHostInts[i] = i; }
int* myDeviceInts; const int numBytes = NUM_ELEMENTS * sizeof(int); cudaMalloc(&myDeviceInts, numBytes); cudaMemcpy(myDeviceInts, myHostInts, numBytes, cudaMemcpyHostToDevice); int numBlocks = (NUM_ELEMENTS / 256) + 1; addToMe<<<numBlocks, 256>>>(myDeviceInts, 5);
cudaMemcpy(myHostInts, myDeviceInts, numBytes, cudaMemcpyDeviceToHost); // Tidy up after ourselves as good practice cudaFree(myDeviceInts); return EXIT_SUCCESS;}
No bounds checking! Not required but can lead to problems laterPrinting threadIdx.x here will print 0 to 255
Blocks = a group of threads, work out how many we needI'll use a 2D grid (just lots of blocks/threads) in this presentation
Look at our kernel dimensions
numBlocks will be 1256 is the number of threads
CUDA code (inside a .cu file)

●
●
● [Java] We have an integer array on the Java heap: myData – we want to process it somehow using a GPU
● [Java] Create a native method (Java/Scala): no body required● [JNI] Write .cpp or .c code with a matching signature for your native method (use javah on your built
Java class as a starting point), in this native code, use JNI methods to get a pointer to your data, with this pointer, we can figure out how much memory we need. Call your method that's in a .cu file that you're about to create...
● [CUDA] Allocate space on the GPU (device side) using cudaMalloc● [CUDA] Copy myData to your allocated space (myDataOnTheGPU) using cudaMemcpyHostToDevice● [CUDA] Process your data on the GPU in a kernel (look for <<< and >>>)● [CUDA] Copy the result back (what's now at myDataOnTheGPU replaces myData on the host) using
cudaMemcpyDeviceToHost● [JNI] Release the elements (updating your JNI pointer so the data in our JVM heap is now the result)● [Java] Interact with your data normally as you're back in the Java world
Calling this from Java (conventionally)...

You'd need to do all of this work...

Java code (notice the empty native method)
(“Geecon.so”)

You'll need a header file (javah on .class)

C++ code (matching the method signature)

CUDA code with a simple kernel

And after all of that...we can add ten to some ints on the GPU!

objdump mysharedlibrary.so -t | grep yourmethodname is very useful for unsatisfied link errors...
[aroberts@geecon withjava]$ objdump lib/devoxx.so -t | grep "addX"00000000000053c4 g F .text 000000000000005f _Z28Java_SimpleJava_addXToMyIntsP7JNIEnv_P7_jclassP10_jintArrayi
Name mangling can occur (use “extern C {} blocks” in your .cpp and .cu code)
[aroberts@geecon withjava]$ ./BuildAndRun.sh Unhandled exceptionType=Segmentation error vmState=0x00000000
Unsafe world now – check your memory accesses - ensure all of your pointers are still valid, printfs and gdb for debugging, Nsight/cuda-gdb/cuda-memcheck for CUDA specific help
Pitfalls to look out for

printf statements added for looking into that segv...
[aroberts@geecon withjava]$ ./BuildAndRun.sh getting elementsgot em!launching kernel...addToMe+0x20 (0x00007F48441B630F [geecon.so+0x530f])Java_SimpleJava_addXToMyInts+0x5c (0x00007F48441B6440 [geecon.so+0x5440])(0x00007F4854264F9B [libj9vm28.so+0x8ff9b])Unhandled exception
^^ Check your memory accesses!
● Remember to call your kernel with the <<< and >>> syntax (in a .cu file)● Remember to use your device pointer variable as the parameter in your kernel (not the host one) - or you won't be able to modify your data (it'll act on nothing – the kernel will still launch but your data will remain unchanged)● You can add printf statements inside of your kernels (printing threadIdx.x which you're likely using as an index into an array is a good idea)● Yes, you should add bounds checking inside of your kernels● Yes, you should check return codes and use cudaError_t

“There must be an easier way”

Yes – we can stick to Java as much as possible● Lots of Java projects we want to use● Error checking● Type safety● Debugging tools (core dumps, javacores, system dumps, GCMV, MAT)...● Profiling tools (Healthcenter, jprof)...● JIT compiler and a garbage collector● Portability (kind of- until you “go native”, mix byte-ordering across machines while using
sun.misc.unsafe, use other internal APIs relying on field names, find there's no JRE available – you will need the toolkit to work on the platform Java runs!)
The approaches we've taken: making it easier to try GPUs● Java Class Library changes● Just-In-Time Compiler changes ● CUDA4J API● Apache Spark changes (runs in JVMs)

-Dcom.ibm.gpu.enable/enforce/disable/verboseInts sorted per second
Java class library changes: Arrays.java (sort)

-Xjit:enableGPU=”{default, verbose”} Can be forced with “{enforce”}
• Supports CUDA 7.5 currently (API change for NVVM in CUDA 8)
Using three arrays of randomly generated doubles:
output, firstArray, secondArray [size ROWS]
Run this inside a loop for an easily
reproducible example – JIT must be hot to make an
impact
IBM JIT compiler changes

[IBM GPU JIT]: Device Number 0: name=Quadro M1000M, ComputeCapability=5.0Setting up our arrays, size is 2048x2048Done setting up!Starting the GPU enabled lambda, running GPU enabled lambda, parallelism: 1End time: 42575.864909 msecStarting the GPU enabled lambda, running GPU enabled lambda, parallelism: 1End time: 41080.132863 msecStarting the GPU enabled lambda, running GPU enabled lambda, parallelism: 1[IBM GPU JIT]: [time.ms=1489774852380]: Launching parallel forEach in com/ibm/MatMultiExample/MatMulti.runGPULambda()V at line 139 on GPU[IBM GPU JIT]: [time.ms=1489774853402]: Finished parallel forEach in com/ibm/MatMultiExample/MatMulti.runGPULambda()V at line 139 on GPUEnd time: 1042.93 msec
With no JIT options provided, over 100 iterations (instead of just five) I still achieve a best time of 42 seconds. With more threads (setting it to 8 or 32, not 1 by modifying the fork join common property parallelism) my best time is 32 seconds – still much slower
Performance results on my laptop

Measured performance improvement with a GPU using four programs
1-CPU-thread sequential execution160-CPU-thread parallel execution
Experimental environment usedIBM Java 8 Service Release 2 for PowerPC Little Endian
Two 10-core 8-SMT IBM POWER8 CPUs at 3.69 GHz with 256GB memory (160 hardware threads in total) with one NVIDIA Kepler K40m GPU (2880 CUDA cores in total) at 876 MHz with 12GB global memory (ECC off)
Any other benchmarks?


This shows GPU execution time speedup amounts compared to what's in blue (1 CPU thread) and yellow (160 CPU threads)
The higher the bar, the bigger the speedup!

bytecodes
intermediaterepresentation
optimizer
CPU GPU
code generator code generator
PTX ISACPU native
As the JIT compiles a stream expression we can identify candidates for GPU off-loading● Data copied to and from the device implicitly● Java operations mapped to GPU kernel operations● JIT takes care of GPU data alignment, cache management● Optimizes data transfer● Manages multiple devices
● Reuses standard Java idioms, so no new API is required● Preserves standard Java semantics● No knowledge of GPU programming model required by the application developer● Takes care of low level details: GPU devices capabilities, etc.● Chooses optimal execution mode: CPU, GPU, or SIMD● Future performance improvements in the JIT do not require application changes!
Advantages with this approach

JVM: Class loading Method resolution Object creation and GC Exception handling
Java array
CPU
Redirection to CPU(at compile or runtime)
Copy over PCIeGPU copy of Java array
• Optimized lambda code executed by multiple threads in a data parallel manner• Exception detection
GPUGPU memory isn't an extension of the Java heap
Limitations

The JIT compiler will check that the lambda expression satisfies the following criteria:● Only accesses primitive types, and one-dimensional arrays of primitive types ● No access to static scalar variables: only locals, parameters, or instance variables● No unresolved or native methods● No creating new heap Objects (new ...), exceptions, (throw …) or instanceof● Intermediate stream operations like map or filter are not supported
Writing a GPU eligible lambda

• JIT applies various performance heuristics to determine execution mode of the lambda expression (sequential, fork-join, GPU, or SIMD)
• Heuristics depend on numerous factors and may change in the future to become more accurate, to deal with new architecture characteristics, etc
• Currently, they are relatively conservative• We will work on new heuristics based on customer feedback
• To observe if forEach was sent to GPU use –Xjit:enableGPU={verbose}• To override performance heuristics use –Xjit:enableGPU={enforce}• For combining options: -Xjit:enableGPU=”enforce|verbose” will work: the quotes are important
lest your bash shell interpret | as a pipe!• Give it a go for yourself keeping the criteria for code to be eligible in mind• We are using NVVM IR
Performance heuristics

Beyond Java options...

Production ready and supported by IBM – used to manipulate GPU devicesCompared to Jcuda: no arbitrary and unrestricted use of Pointer(long), feels more like Java instead of C
Write your CUDA kernel (yes, the hard part!) and compile it into a fat binary
nvcc --fatbin AdamKernel.cu
Add your Java code
import com.ibm.cuda.*;
import com.ibm.cuda.CudaKernel.*;
Load your fat binary (module loading code at the end of this presentation)
module = new Loader().loadModule("AdamDoubler.fatbin",device);
Build and run as you would any other Java application
CUDA4J API

CudaDevice a CUDA capable GPU device
CudaStream a sequence of operations on the GPU
CudaBuffer a region of memory on the GPU
CudaModule user library of kernels to load into GPU
CudaKernel launching a device function
CudaFunction a kernel's entry point
CudaEvent timing and synchronization
CudaException when something goes wrong
● We developed an API that reflects the concepts familiar in CUDA programming● Makes use of Java exceptions, automatic resource management, etc.● Handles copying data to/from the GPU, flow of control from Java to GPU and back● Ability to invoke existing GPU module code from Java applications e.g. Thrust
CUDA4J class mapping
When you want low level GPU control...

Only doubling integers; could be any use case where we're doing the same operation to lots of elements at once
Full code listing at the end, Javadocs: search IBM Java 8 API com.ibm.cuda* Tip: offsets are byte offsets, so you'll want your index in Java * the size of the object!
module = new Loader().loadModule("AdamDoubler.fatbin", device); kernel = new CudaKernel(module, "Cuda_cuda4j_AdamDoubler_Strider"); stream = new CudaStream(device);
numElements = 100; myData = new int[numElements]; Util.fillWithInts(myData); CudaGrid grid = Util.makeGrid(numElements, stream); buffer1 = new CudaBuffer(device, numElements * Integer.BYTES); buffer1.copyFrom(myData);
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements); kernel.launch(grid, kernelParams);
buffer1.copyTo(myData);
If our dynamically created grid dimensions are too big we need to break down the problem and use the slice* API: doChunkingProblem() Our kernel, compiles into AdamDoubler.fatbin

Integrating CUDA GPU offloading support into your existing Java applications without needing to worry about JNI, makefiles, managing GPU memory and writing C++ code (you still need to write your kernel)● Identify your most commonly used functions as candidates (simple
manual profiling or using tools such as Healthcenter for method profiling)
● Tinker with heuristics and benchmark new capabilities● Be wary of the GPU limitations (e.g device memory amount, max grid
size – may need to chunk up your problem)
Where would this be useful?

Improving existing projects

Open source project (the most active for big data) offering distributed...● Machine learning● Graph processing● Core operations (map, reduce, joins)
● SQL syntax with DataFrames/Datasets
● Many input formats supported e.g Parquet, JSON, files stored on HDFS you can parse trivially, CSV with a Databricks package
● Interoperability with Kafka, Hive, many more (see Apache Bahir also)
● Compression codecs and automatic usage, fast serialization with Kryo
● Offers scalability and resiliency
● Lots of Scala – so runs in JVMs (exploits sun.misc.unsafe heavily)
● Python, R, Scala and Java APIs● Eligible for our Java based optimisations
Ask after the talk for more details on Apache Spark
Improving Apache Spark

Alternating Least Squares
K-means (unsupervised learning (no labels, cheap))
Classifcation algorithms such as
Clustering algorithms such as● Produce n clusters from data to determine which cluster a new item can be categorised as● Identify anomalies: transaction fraud, erroneous data
Recommendation algorithms such as
● Movie recommendations on Netflix?● Recommended purchases on Amazon? ● Similar songs with Spotify?● Recommended videos on YouTube?
Logistic regression● Create model that we can use to predict where to plot the next item in a sequence (above or
below our line of best fit)● Healthcare: predict adverse drug reactions based on known interactions with similar drugs● Spam filter (binomial classification)● Naive Bayes
Which algorithms might be of use?

An example: we have the following .csv file for bands..
<username, band name, band genre (a feature), rating>Adam,ACoolBand1,AGenre,5
Adam,ACoolBand2,AGenre,5
Adam,ACoolBand3,AGenre,5
George,ACoolBand1,AGenre,5
George,ACoolBand2,AGenre,5
George,ACoolBand3,AGenre,5
George,ACoolBand4,AGenre,5
If we were to guess if Adam likes ACoolBand4 as well, the score would be very close to 5 – we can infer it based on already known observations
Very much simplified, ALS works by factorizing the rating matrix and minimising the loss on observed
ratings (our ratings matrix will be sparse and we want to complete it – see “CuMF: Large-Scale Matrix
Factorization on Just One Machine with GPUs. Nvidia GTC 2016 talk” by Wei Tan for an excellent summary
Alternating Least Squares

● Under the covers optimisation, set the spark.mllib.ALS.useGPU property● Full paper: http://arxiv.org/abs/1603.03820● Full implementation for raising issues and giving it a try for yourself:
https://github.com/IBMSparkGPU, with 1.5 gb of a Netflix dataset:
Our implementation is open source and cited above, we used:2x Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz, 16 cores in the machine (SMT-2), 256 GB RAM vs 2x Nvidia Tesla
K80Ms. Also available for IBM Power LE
Our approach for Apache Spark

Implemented the vanilla C++/Java/CUDA way so this would work with any JDK (tiny amount of C++ code and lots of CUDA for Spark – we only override one function)
● modified the existing ALS (.scala) implementation's computeFactors method● added code to check if spark.mllib.ALS.useGPU is set● if set we'll then call our native method written to ue JNI (.cpp)● our JNI method calls native CUDA (.cu) method● CUDA kernel → JNI → back to Java heap
Bundled with our Spark distribution and the shared library is includedRequires the CUDA runtime (libcudart) and a CUDA capable GPU
ALS.scala computeFactors
CuMFJNIInterface.cpp
ALS.cu libGPUALS.so

We can send generated code to GPUs and alter the code that's generated to conform to certain characteristics...
Input: user application using Spark DataFrame or Dataset API (SQL-like syntax, perform queries on data stored in tables)
✔ Spark with Tungsten. Uses UnsafeRow and, sun.misc.unsafe, idea is to bring Spark closer to the hardware than previously, exploit CPU caches, improved memory and CPU efficiency, reduce GC times, avoid Java object overheads – good deep dive here
✔ Spark with Catalyst. Optimiser for Spark SQL APIs, good deep dive here, transforms a query plan (abstraction of a user's program) into an optimised version, generates optimised code with Janino compiler
✔ Spark with our changes: Java and core Spark class optimisations, optimised JIT
Pervasive GPU opportunities

Output: generated code able to leverage auto-SIMD and GPUs
Remember! We want generated code that:✔ has a counted loop, e.g. one controlled by an automatic induction
variable that increases from a lower to an upper bound✔ accesses data in a linear fashion✔ has as few branches as possible (simple for the GPU's kernel)✔ does not have external method calls or contains only calls that can be
easily inlined
These help a JIT to either use auto-SIMD capabilities or GPUs

Problems1) Data representation of columnar storage (CachedBatch with Array[Byte]) isn't commonly used
2) Compression schemes are specific to CachedBatch, limited to just several data types
3) Building in-memory cache involves a long code path -> virtual method calls, conditional branches
4) Generated whole-stage code -> unnecessary conversion from CachedBatch or ColumnarBatch to UnsafeRow
Solutions1) Use ColumnarBatch format instead of CachedBatch for the in-memory cache generated by the cache() method.
ColumnarBatch and ColumnVector are commonly used data representations for columnar storage
2) Use a common compression scheme (e.g. lz4) for all of the data types in a ColumnVector
3) Generate code at runtime that is simple and specialized for building a concrete instance of the in-memory cache
4) Generate whole-stage code that directly reads data from columnar storage
(1) and (2) increase code reuse, (3) improves runtime performance of executing the cache() method and (4) improves performance of user defined DataFrame and Dataset operations

We propose a new columnar format: CachedColumnarBatch, that has a pointer to ColumnarBatch (used by Parquet reader) that keeps each column as OnHeapUnsafeColumnVector instead of OnHeapColumnVector.
Not yet using GPUS!
● [SPARK-13805], merged into 2.0, performance improvement: 1.2xGet data from ColumnVector directly by avoiding a copy from ColumnVector to UnsafeRow when a program reads data in parquet format
● [SPARK-14098] targeted for Spark 2.2, performance improvement: 3.4xGenerate optimized code to build CachedColumnarBatch, get data from a ColumnVector directly by avoiding a copy from the ColumnVector to UnsafeRow, and use lz4 to compress ColumnVector when df.cache() or ds.cache is executed
● [SPARK-15962], merged into 2.1, performance improvement: 1.7xRemove indirection at offsets field when accessing each element in UnsafeArrayData, reduce memory footprint of UnsafeArrayData

● [SPARK-15985], merged into 2.1, performance improvement: 1.3xEliminate boxing operations to put a primitive array into GenericArrayData when a Dataset program with a primitive array is ran
● [SPARK-16213], merged into 2.2, performance improvement: 16.6xEliminate boxing operations to put a primitive array into GenericArrayData when a DataFrame program with a primitive array is ran
● [SPARK-17490], merged into 2.1, performance improvement: 2.0xEliminate boxing operations to put a primitive array into GenericArrayData when a DataFrame program with a primitive array is used

“What does it mean for me as a developer?”

Another way to make exploiting GPUs easier for those who aren't yet experts on GPU programming
● We know how to build GPU based applications● We can figure out if a GPU is available● We can figure out what code to generate● We can figure out which GPU to send that code to● All while retaining Java safety features such as exceptions, bounds
checking, serviceability, tracing and profiling hooks...
Assuming you have the hardware, add an option and watch performance improve: this is ongoing work that can likely be applied to other projects

We want developers to be aware of these so we can work together● Restricted by PCIe speed (less so with IBM hardware, Nvlink on Power)● Writing a decent kernel is hard
● Optimum use of different memory types (global, shared, texture, registers), debugging (lots of seg faults, you're in the CUDA world now!), limited functions you can use in a kernel, maintaining contiguous access where possible
● Not many GPU developers out there relative to other language pros: want developers that know machine learning, know Java, know CUDA, know how to debug and profile
● Watch lots of videos and experiment – breaking things as you go and learning; need to achieve max parallelism, avoid seg faults, good fun
● Big changes to the CUDA SDK itself: this is for CUDA 7.5 and I learned with CUDA 5.5, likely lots of new features I'm not exploiting
Challenges for GPU programming

● Profling – many variables to tweak (and therefore many opportunities for benchmarking fun, I did not touch on shared memory/advanced kernels)
● More pitfalls than Java (unless you're using sun.misc.unsafe or JNI)● CUDA was initially a problem to set up on my laptop (wanting to keep
my desktop, use the Nvidia driver, use the CUDA toolkit AND a projector…)
● Debugging in a massively multithreaded environment...be careful of race conditions
● Ideally developers can focus on the kernel logic and design principles instead of how to write GPU code and how to manage things like scheduling and partitioning strategies

“What else is out there for me?”

OpenCL● Low level framework simplifies development for devices such as GPUs,
FPGAs, works on AMD cards too, maintained by Khronos Group
TensorFlow● Java, C++, Python APIs, built for machine learning, researchers, data
scientists, open source (mainly developed by Google) – features offloading to CUDA devices (requiring the toolkit/driver/cuDNN)
SystemML● IBM open-sourced project (now an Apache incubator), recently
committed GPU support (yet to try) – write code in DML, easily scale out once ready

Jcuda● Alternative to CUDA4J (no IBM Java requirement) – more like C than Java, plenty of
bindings for Nvidia libraries available and open source
DeepLearning4j● The most popular open source deep-learning framework for the JVM – mentions
built-in GPU support; anything making GPU exploitation easier is welcome, lots of useful features that makes GPU programming + ML easier
Nvidia libraries such as ● cuDNN
● Deep neural network library for CUDA devices● cuBLAS
● Basic linear algebra subroutines on the GPU● Thrust
● Precanned algorithms for HPC on CUDA devices (e.g. sorting)

Aparapi● Excellent video by AMD Runtimes team on it (very few views on YouTube, highly
recommended)● Java API for the GPU – also Java styled like CUDA4J● Converts Java code to OpenCL● Requires overloading the run routine in a kernel class already (like you would for
java.lang.Thread)● jar file and shared libraries with JNI (so no JVM changes)
Project Sumatra● OpenJDK initiative for GPU support as part of the Java SDK● Excellent video: “Sumatra OpenJDK Project Update” with < 120 views on YouTube!● Details their approach to optimising forEach and reduce using GPUs● Not tried this – mentions building Graal and Sumatra to get a “HSA enabled Graal-based JDK”,
would be interesting to either collaborate/compare findings, and to look into Wholly Graal (another good video on YouTube about this – again with very few views)

● Easy way to get the latest IBM SDK for Java for free (optionally with Apache Spark): want to know about your workloads we can improve the JDK for
● Great if you know CUDA already – but not required● GPUs don't need to be expensive – but the server ones will be● Useful for certain operations – not the “be all and end all” that's guaranteed to give you a
boost, but why not make use of it if you have it● Lots of projects out there combining Java and GPUS! We're especially interested in delivering
runtime improvements with minimal to no code changes required – partially by improving the IBM J9 VM itself (look out for OpenJ9)
http://ibm.biz/spark-kit
Takeaways Contact me directly: [email protected]

Questions?

CUDA4J example code beyond this point

CUDA4J sample, part 1 of 3import com.ibm.cuda.*;import com.ibm.cuda.CudaKernel.*;
public class Sample { private static final boolean PRINT_DATA = false; private static int numElements; private static int[] myData; private static CudaBuffer buffer1; private static CudaDevice device = new CudaDevice(0); private static CudaModule module; private static CudaKernel kernel; private static CudaStream stream;
public static void main(String[] args) { try { module = new Loader().loadModule("AdamDoubler.fatbin", device); kernel = new CudaKernel(module, "Cuda_cuda4j_AdamDoubler_Strider"); stream = new CudaStream(device); doSmallProblem(); doMediumProblem(); doChunkingProblem(); } catch (CudaException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } }
private final static void doSmallProblem() throws Exception { System.out.println("Doing the small sized problem"); numElements = 100; myData = new int[numElements]; Util.fillWithInts(myData); CudaGrid grid = Util.makeGrid(numElements, stream); System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>"); buffer1 = new CudaBuffer(device, numElements * Integer.BYTES); buffer1.copyFrom(myData); Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements); kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[myData.length]; System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length); buffer1.copyTo(myData); Util.checkArrayResultsDoubler(myData, originalArrayCopy); }

private final static void doMediumProblem() throws Exception { System.out.println("Doing the medium sized problem");
numElements = 5_000_000; myData = new int[numElements]; Util.fillWithInts(myData); // This is only when handling more than max blocks * max threads per kernel // Grid dim is the number of blocks in the grid // Block dim is the number of threads in a block // buffer1 is how we'll use our data on the GPU buffer1 = new CudaBuffer(device, numElements * Integer.BYTES); // myData is on CPU, transfer it buffer1.copyFrom(myData); // Our stream executes the kernel, can launch many streams at once CudaGrid grid = Util.makeGrid(numElements, stream); System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>"); Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements); kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[myData.length]; System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length); buffer1.copyTo(myData); Util.checkArrayResultsDoubler(myData, originalArrayCopy); }
CUDA4J sample, part 2 of 3

private final static void doChunkingProblem() throws Exception { // I know 5m doesn't require chunking on the GPU but this does System.out.println("Doing the too big to handle in one kernel problem");
numElements = 70_000_000; myData = new int[numElements]; Util.fillWithInts(myData); buffer1 = new CudaBuffer(device, numElements * Integer.BYTES); buffer1.copyFrom(myData); CudaGrid grid = Util.makeGrid(numElements, stream); System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
// Check we can actually launch a kernel with this grid size try { Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements); kernel.launch(grid, kernelParams); int[] originalArrayCopy = new int[numElements]; System.arraycopy(myData, 0, originalArrayCopy, 0, numElements); buffer1.copyTo(myData); Util.checkArrayResultsDoubler(myData, originalArrayCopy); } catch (CudaException ce) {
if (ce.getMessage().equals("invalid argument")) { System.out.println("it was invalid argument, too big!");
int maxThreadsPerBlockX = device.getAttribute(CudaDevice.ATTRIBUTE_MAX_BLOCK_DIM_X); int maxBlocksPerGridX = device.getAttribute(CudaDevice.ATTRIBUTE_MAX_GRID_DIM_Y);
long maxThreadsPerGrid = maxThreadsPerBlockX * maxBlocksPerGridX;
// 67,107,840 on my Windows box System.out.println("Max threads per grid: "+ maxThreadsPerGrid); long numElementsAtOnce = maxThreadsPerGrid; long elementsDone = 0;
grid=new CudaGrid(maxBlocksPerGridX,maxThreadsPerBlockX, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>"); while (elementsDone < numElements) { if ( (elementsDone + numElementsAtOnce) > numElements) { numElementsAtOnce = numElements - elementsDone; } long toOffset = numElementsAtOnce + elementsDone; // It's the byte offset not the element index offset CudaBuffer slicedSection = buffer1.slice(elementsDone * Integer.BYTES, toOffset * Integer.BYTES); Parameters kernelParams = new Parameters(2).set(0, slicedSection).set(1, numElementsAtOnce); kernel.launch(grid, kernelParams); elementsDone += numElementsAtOnce; }
int[] originalArrayCopy = new int[myData.length]; System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length); buffer1.copyTo(myData); Util.checkArrayResultsDoubler(myData, originalArrayCopy); } else { System.out.println(ce.getMessage()); }}
}

CUDA4J kernel#include <stdint.h>#include <stdio.h>
/** * 2D grid so we can have 1024 threads and many blocks * Remember 1 grid -> has blocks/threads and one kernel runs on one grid * In CUDA 6.5 we have cudaOccupancyMaxPotentialBlockSize which helps */ extern "C" __global__ void Cuda_cuda4j_AdamDoubler(int* toDouble, int numElements){ int index = blockDim.x * threadIdx.x + threadIdx.y; if (index < numElements) { // Don't go out of bounds toDouble[index] *= 2; // Just double it }}
extern "C" __global__ void Cuda_cuda4j_AdamDoubler_Strider(int* toDouble, int numElements){ int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < numElements) { // don't go overboard toDouble[i] *= 2; }}

Utility methods, part 1 of 2package com.ibm.CUDA4JExample;import com.ibm.cuda.*;
public class Util { protected final static void fillWithInts(int[] toFill) { for (int i = 0; i < toFill.length; i++) { toFill[i] = i; } }
protected final static void fillWithDoubles(double[] toFill) { for (int i = 0; i < toFill.length; i++) { toFill[i] = i; } } protected final static void printArray(int[] toPrint) { System.out.println(); for (int i = 0; i < toPrint.length; i++) { if (i == toPrint.length - 1) { System.out.print(toPrint[i] + "."); } else { System.out.print(toPrint[i] + ", "); } } System.out.println(); }
protected final static CudaGrid makeGrid(int numElements, CudaStream stream) { int numThreads = 512; int numBlocks = (numElements + (numThreads - 1)) / numThreads; return new CudaGrid(numBlocks, numThreads, stream); }

/* * Array will have been doubled at this point */ Protected final static void checkArrayResultsDoubler(int[] toCheck, int[] originalArray) { long errorCount = 0; // Check result, data has been copied back here
if (toCheck.length != originalArray.length) { System.err.println("Something's gone horribly wrong, different array length"); } for (int i = 0; i < originalArray.length; i++) { if (toCheck[i] != (originalArray[i] * 2) ) { errorCount++; /* System.err.println("Got an error, " + originalArray[i] + " is incorrect: wasn't doubled correctly!" + " Got " + toCheck[i] + " but should be " + originalArray[i] * 2); */ } else { //System.out.println("Correct, doubled " + originalArray[i] + " and it became " + toCheck[i]); } } System.err.println("Incorrect results: " + errorCount); }}
Utility methods, part 2 of 2

CUDA4J module loaderpackage com.ibm.CUDA4JExample;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream;
import com.ibm.cuda.CudaDevice;import com.ibm.cuda.CudaException;import com.ibm.cuda.CudaModule;
public final class Loader { private final CudaModule.Cache moduleCache = new CudaModule.Cache(); final CudaModule loadModule(String moduleName, CudaDevice device) throws CudaException, IOException { CudaModule module = moduleCache.get(device, moduleName); if (module == null) { try (InputStream stream = getClass().getResourceAsStream(moduleName)) { if (stream == null) { throw new FileNotFoundException(moduleName); } module = new CudaModule(device, stream); moduleCache.put(device, moduleName, module); } } return module; }}


















