
Introduction to Parallel Computing - Marquette University · Introduction to Parallel Computing...
55
Introduction to Parallel Computing Xizhou Feng Information Technology Services Marquette University MUGrid Bootcamp, 2010 Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 1 / 55
Transcript of Introduction to Parallel Computing - Marquette University · Introduction to Parallel Computing...

Introduction to Parallel Computing
Xizhou Feng
Information Technology ServicesMarquette University
MUGrid Bootcamp, 2010
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 1 / 55

Outline
1 Overview of Parallel ComputingWhat is Parallel Computing?Parallel Computing HardwareParallel Programming ParadigmsParallel Algorithm Design
2 Parallel Computing with MPI (Message Passing Interface)BackgroundGetting StartedMPI Programs and EnvironmentsPoint-to-point CommunicationCollective CommunicationOther Topics
3 Parallel Computing with OpenMP
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 2 / 55
Announcement
If you are a Marquette user, you may send the Pere account requestform to [email protected] to have your account activated on pere.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 3 / 55

Parallelism is Universal
DefinitionSequential processes are those that occur in strict order, where it isnot possible to the next step until the current one is completed.
Professor teaches classesPlayer plays chessChild play violin
DefinitionParallel processes are those in which many events can happensimultaneously or exhibit concurrencies.
Students take classesPlayers play footballMusicians perform orchestra
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 4 / 55

What is Parallel Computing?
Parallel computing is the simultaneous use of multiple computeresources to solve a computational problemA parallel computer platform can be:
A single computer with multiple processing elements (PEs);An arbitrary number of computers connected by a network;A combination of both
The computational problem exhibits large degree of parallelismCan be decomposed into concurrent discrete pieces of work;Can execute multiple program instructions at any moment;Can run much faster when using multiple compute resources.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 5 / 55

Uses of Parallel Computing
Parallel computing is usually target at applications that performcomputations on large datasets or large equations, examples include:
Meteorologists: Weather predictionBiologists: DNA sequences analysisPharmaceutical companies: Drug designOil companies: Seismic explorationWall Street: financial marketsNASA: aerospace vehicle designEntertainment industry: special effects in movies and commercials
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 6 / 55

Flynn’s Taxonomy of Computer
Flynn’s taxonomy categorizes computers by how streams ofinstructions interact with streams of data.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 7 / 55

SIMD and MIMD
SIMD (Single Instruction, Multiple Data)All PEs execute the same instruction at any given clock cycleEach PE can operate on a different data elementMost modern processors supports SIMD operations
MIMD (Multiple Instruction, Multiple Data)The most common type of modern parallel computers.Every processor may be executing a different instruction stream.Every processor may be working with a different data stream
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 8 / 55

The Memory Model of MIMD Computers
Shared Memory (UMA and NUMA)Distribute MemoryHybrid Distributed-Shared Memory
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 9 / 55

Comparison of Different Memory Models
Shared memoryEasy to programFast data sharingLack of scalabilityMemory conflictsExpensive
Distributed memoryScalableFast local memory accessCost effectivenessHard to programNon-uniform memory access
Hybrid distributed shared memoryCombine pros/cons of shared memory and distributed memoryMap modern parallel computer architecture
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 10 / 55

Parallel Programming Paradigms
Exists as an abstraction above hardware and memory architectureParallel programming paradigms in common use
Message PassingData parallelShared memoryPartitioned global memory spaceThreads
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 11 / 55

Parallel Programming ParadigmsMessage Passing Model
Programs create multiple tasks;Each task has its local data and is identified by a unique name;Task interact by send and receive message to and from othernamed tasks.MPI is the de facto standard that implements message passingmodel
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 12 / 55

Parallel Programming ParadigmsData Parallel Model
Exploits the concurrency that exits in performing the sameoperation to multiple elements of a data structure;Multiple tasks work collectively on the same data structure, buteach task works on a different partitionFortran 90/95 and HPF (High Performance Fortran) support dataparallel model
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 13 / 55

Parallel Programming ParadigmsShared Memory Model
Tasks share a common global address space, which they readand write asynchronously;Various mechanisms (e.g., lock and semaphores) control howtask access to the shared memory;OpenMP implements both shared memory model and threadsmodel.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 14 / 55

Parallel Programs DesignConsiderations
EfficiencyScalabilityLocalityLoad-balancingCommunication cost and latency hiding
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 15 / 55

Parallel Programs DesignThe PCAM method (Foster 1996)
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 16 / 55

Parallel Programs DesignProgram Patterns
Data-ParallelTask GraphWork PoolMaster-SlavePipeline/Producer-ConsumerMap-ReduceHybrid
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 17 / 55

What is MPI
DefinitionMPI is a message-passing library specification that was designed to bea portable, efficient, and flexible standard for writing parallel programsusing message passing.
1 Specification, not an implementation2 Library, not a language3 Classical message-passing model
Defined in 1994 by MPI Forum.Supported by vendors on all parallel machines.Free, portable implementations. (MPICH, LAM, and OpenMPI)
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 18 / 55

Features of MPIIncluded in MPI-1
Thread safetyUser-defined Datatypes and PackingCollective operationsProcess groups and communication domainsPoint-to-point communicationApplication-oriented process topologiesProfiling interfaceEnvironmental management and inquiryBinings for Fortran, C
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 19 / 55

Features of MPIAdded in MPI-2
Dynamic process managementParallel I/ORemote memory operationsBindings for C++ and Fortran90
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 20 / 55

MPI Resources
The StandardMPI Forum http://www.mpi-forum.org/docs/docs.htmlMPI official releases, in both form of html and postscript
The documents of the implementations (MPICH/OpenMPI/LAMMPI/Vendor-provided MPI)Books
Gropp et al, Using MPI: Portable Parallel Programming with theMessage-Passing Interface (1994)Foster, Designing and Building Parallel Programs (1995)Snir et al. MPI: The Complete Reference (1996)Pacheco, Parallel Programming with MPI (1997)Quinn, Parallel Programming in C with MPI and OpenMP, McGraw(2003)Grama et al, Introduction to Parallel Computing (2003)
Tutorials: Google ”MPI Tutorial”
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 21 / 55

Why and When to Use MPI?
MPI is the only ”standard” for message passing libraryMPI is supported on virtually all HPC platformsWrite portable parallel codes across platformsExploit high performance of the applicationsDeal with irregular or dynamic data structure
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 22 / 55

When Not to Use MPI?
You can use HPF or a parallel Fortran 90You don’t need parallelism at allYou can use libraries which may be written in MPIYou can use other computing paradigm (e.g. multiple threading orjob level parallelism)
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 23 / 55

Is MPI Large or Small?
MPI is large. MPI-1 has 128 functions. MPI-2 has 152 functions.MPI extensive functionality requires many functionsNumber of functions not necessarily a measure of complexity
MPI is small (6 functions)Many parallel programs can be written with just 6 basic functions.
MPI_InitMPI_Comm_sizeMPI_Comm_rankMPI_SendMPI_RecvMPI_Finalize
MPI is just rightOne can access flexibility when it is required.One need not master all parts of MPI to use it.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 24 / 55

Writing MPI Programs
1 #include "mpi.h"2 #include <stdio.h>34 int main( int argc, char *argv[] )5 {6 MPI_Init( &argc, &argv );7 printf( "Hello world\n" );8 MPI_Finalize();9 return 0;10 }
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 25 / 55

Compiling MPI Programs
Method 1: Using MPI compiler wrapper1 mpicc: for C code2 mpicxx/mpic++/mpiCC: for C++ code3 mpif77/mpif90: for FORTRAN code4 Example:
mpicc -o hello hello.c
Method 2: Using standard compilers and MPI library1 MPI is just a library, so you can link the library to your code to get
the executables.2 Example:
gcc -o ping ping.c \-I/usr/mpi/gcc/openmpi-1.2.8/include \-L/usr/mpi/gcc/openmpi-1.2.8/lib64 -lmpi
3 Method 3: Vendor-specific compilers (PGI compilers, Intelcompilers, etc)
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 26 / 55

Compiling MPI ProgramsUsing a Makefile
Makefile files and the make utility enable automatically buildsexecutable programs and libraries from source codeExample:CC = mpiccCLINKER = mpiccCFLAGS = -O3MATH_LIB = -lm
hello: hello.o$(CLINKER) -o hello hello.o $(MATH_LIB)
.c.o:$(CC) $(CFLAGS) -c $<
clean:rm -f *.o hello
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 27 / 55

Running MPI jobs with PBSUsing multiple nodes
#!/bin/sh
#PBS -N bootcamp-1#PBS -l nodes=2:ppn=8#PBS -l walltime=12:00:00#PBS -q batch#PBS -j oe#PBS -o $PBS_JOBNAME-$PBS_JOBID.log
cd $PBS_O_WORKDIRmodule load openmpi/gcc/1.2.8PROG=helloNP=16mpiexec -np $NP $PROG
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 28 / 55

Running MPI jobs with PBSUsing a fixed set of hosts
#!/bin/sh
#PBS -N bootcamp-2#PBS -l nodes=cn47:ppn=8+cn48:ppn=8#PBS -l walltime=12:00:00#PBS -q batch#PBS -j oe#PBS -o $PBS_JOBNAME-$PBS_JOBID.log
cd $PBS_O_WORKDIRmodule load openmpi/gcc/1.2.8PROG=helloNP=16mpiexec -np $NP $PROG
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 29 / 55

Commonly Used PBS Commands
qsub: submit a job toqsub job-scripts : submit a single jobqsub -t id1,id2-id3 job-scripts: submit an array of jobs
qstat: get status on the system, queue and jobsqstat -a: list all jobs on the systemqstat job-id: list a specific jobsqstat -f job-id: list all information on a specific jobs
qdel: delete a batch jobpbsnode: show current node status
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 30 / 55
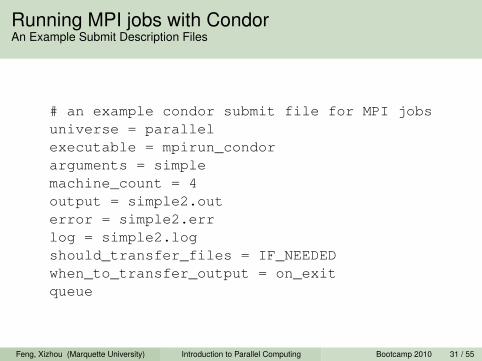
Running MPI jobs with CondorAn Example Submit Description Files
# an example condor submit file for MPI jobsuniverse = parallelexecutable = mpirun_condorarguments = simplemachine_count = 4output = simple2.outerror = simple2.errlog = simple2.logshould_transfer_files = IF_NEEDEDwhen_to_transfer_output = on_exitqueue
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 31 / 55

Explanations of the Condor Submit Description Files
1 Use the parallel universe2 Use an mpirun wrapper for condor executable3 Make the original executable and arguments as the new
arguments4 Specify the number of hosts needed to run the job5 Add options to instruct how to transfer files
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 32 / 55

Exercise 1: Compiling and Running MPI ProgramsUsing PBS
1 Copy the example files to your home directory$ rsync -av /group/hpc-bootcamp/2010Summer/Session4 .$ cd Session4/openmpi/example1$ ls
2 Compile an MPI executable$ module load openmpi/gcc/1.2.8$ makempicc -o hello hello.c
3 Submit the job to the queue$ qsub mpi.qsub$ qstat
4 View the output after the program finished$ more *.out
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 33 / 55

Exercise 2: Compiling and Running MPI ProgramsUsing Condor
1 Copy the example files to your home directory$ cd Session4/mpi/example2$ ls
2 Compile an MPI executable$ makempicc -o hello hello.c
3 Submit the job to the queue$ condor_submit mpi.condor$ condor_q
4 View the output after the program finished$ more *.out
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 34 / 55

The Basic Structure of MPI programs
1 Include MPI header file#include "mpi.h"
2 Declarations, prototypes3 Program Begin4 Serial code5 Initialize MPI environment
MPI_Init(&argc, &argv);
6 Compute and make message passings7 Terminate MPI environment
MPI_Finalize();
8 Serial code9 Program Ends
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 35 / 55

Format of MPI Calls
MPI loosely follow an object oriented designMost MPI routines act on MPI objectsC-binding format
rc = Class_Action(parameters)rc = Class_Action_subset(parameters);
C++-binding formatrc = MPI::Class::Action_subset(parameters);rc = MPI::Action_subset(parameters);
Fortran-binding formatCLASS_ACTION_SUBSET(parameters, rc);CLASS_ACTION(parameters, rc);
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 36 / 55
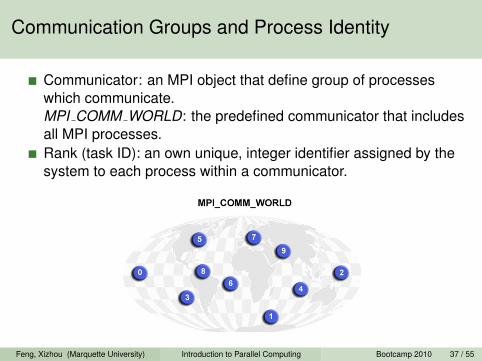
Communication Groups and Process Identity
Communicator: an MPI object that define group of processeswhich communicate.MPI COMM WORLD: the predefined communicator that includesall MPI processes.Rank (task ID): an own unique, integer identifier assigned by thesystem to each process within a communicator.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 37 / 55

Some Environment Management Routines
MPI Init - Initializes the MPI execution environmentMPI Comm size - Determines the number of processes in thegroup associated with a communicatorMPI Comm rank - Determines the rank of the calling processwithin the communicator.MPI Finalize - Terminates the MPI execution environment.MPI Abort - Terminates all MPI processes associated with thecommunicator.MPI Wtime() - Returns an elapsed wall clock time in seconds(double precision) on the calling processor.
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 38 / 55
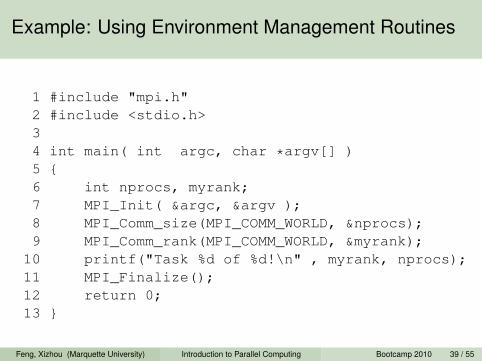
Example: Using Environment Management Routines
1 #include "mpi.h"2 #include <stdio.h>34 int main( int argc, char *argv[] )5 {6 int nprocs, myrank;7 MPI_Init( &argc, &argv );8 MPI_Comm_size(MPI_COMM_WORLD, &nprocs);9 MPI_Comm_rank(MPI_COMM_WORLD, &myrank);10 printf("Task %d of %d!\n" , myrank, nprocs);11 MPI_Finalize();12 return 0;13 }
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 39 / 55

Exercise 3: Embarrassingly ParallelParallel Processing many files
The ProblemWrite an MPI program to process a large number of data filesThe Solution
1 Implement a processFile function2 Get filename and number of files from arguments3 Assign files to process a round-robin order
Implement the solution as a programTest and use the program
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 40 / 55

Exercise 3: Embarrassingly ParallelThe Solution
1 #include "mpi.h"2 #include <stdio.h>3 #include <string.h>45 #define MAX_FILENAME_LEN 12767 int nprocs, myrank;8 void processFile(char *filename) {9 printf("Processing %s by task %d\n",
filename, myrank);10 }11
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 41 / 55

Exercise 3: Embarrassingly ParallelThe Solution
12 int main( int argc, char *argv[] )13 {14 int numFiles;15 char filename[MAX_FILENAME_LEN+1];16 char currentFile[MAX_FILENAME_LEN+1];1718 MPI_Init( &argc, &argv );19 MPI_Comm_size(MPI_COMM_WORLD, &nprocs);20 MPI_Comm_rank(MPI_COMM_WORLD, &myrank);21 if ( argc <= 2 ) {22 if (myrank==0) {23 printf("usage: %s data_file num_files\n", argv[0]);24 }25 MPI_Abort(MPI_COMM_WORLD, -1);26 } else {
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 42 / 55

Exercise 3: Embarrassingly ParallelThe Solution
26 } else {27 strncpy(filename, argv[1], MAX_FILENAME_LEN);28 filename[MAX_FILENAME_LEN]=’\0’;29 numFiles = strtol(argv[2]);30 }3132 int i;33 for(i=myrank; i<numFiles; i+=nprocs) {34 sprintf(currentFile, "%s-%d", filename, i);35 processFile(currentFile);36 }3738 MPI_Finalize();39 return 0;40 }41Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 43 / 55
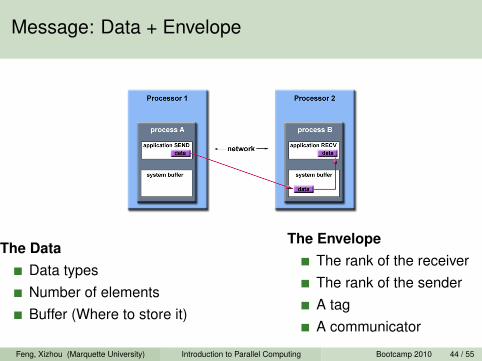
Message: Data + Envelope
The DataData typesNumber of elementsBuffer (Where to store it)
The EnvelopeThe rank of the receiverThe rank of the senderA tagA communicator
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 44 / 55

Point-to-Point Communication
Blocking message passingMPI SendMPI RecvMPI SendrecvMPI WaitMPI Probe...Non-Blocking message passingMPI IsendMPI IrecvMPI TestMPI Iprobe ...
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 45 / 55

Exercise 4: Messaging Passing in a Ring
The ProblemThe tasks is organized as a ring topologyEach task has an initial keyAt each time step, it passes the key to its right neighbor andreceives a key from its left neighborThe program terminates after N time steps
The CommunicationsTask i send key to task (i + 1) mod P, P is the number of tasksTask i receive key to task (i − 1 + P) mod P
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 46 / 55

Exercise 4: Messaging Passing in a RingThe Solution
19 int key, key_received;20 key = myrank;21 int step;22 source = (myrank - 1 + nprocs) % nprocs;23 dest = (myrank + 1 ) % nprocs;2425 for (step=0; step<nprocs; step++) {26 printf("step=%d task=%d key=%d\n",
step, myrank, key);27 MPI_Send(&key, 1, MPI_INT,
dest, tag, MPI_COMM_WORLD);28 MPI_Recv(&key_received, 1, MPI_INT,
source, tag, MPI_COMM_WORLD, &status);29 key = key_received;30 }
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 47 / 55

Collective Communications
Collective communications involve all processes in the scope of acommunicator.Types of collective communication
Synchronization: processes wait all members reach thesynchronization pointData movement: broadcast, scatter/gather, all-to-allCollective computation (reduction)
Collective operations are blockingCan only be used with MPI predefined types
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 48 / 55

Collective Communications Routines
MPI BarrierMPI BcastMPI ScatterMPI GatherMPI ReduceMPI AllgatherMPI AllreduceMPI Alltoall...
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 49 / 55

Other MPI Topics
User-defined DatatypesApplication-oriented process topologiesProfiling interfaceParallel I/OBinings for Fortran, C++Debugging MPI programs
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 50 / 55

What is OpenMP (Open Multi-Processing)?
An Application Program Interface (API) that may be used toexplicitly direct multi-threaded, shared memory parallelismComprised of three primary API components:
1 Compiler Directives2 Runtime Library Routines3 Environment Variables
Portable and Standardized
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 51 / 55

The Fork-Join Model)?
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 52 / 55

Sample OpenMP programsan OpenMP version of Hello
1 #include <omp.h>2 #include <stdio.h>34 int main (int argc, char *argv[]) {5 int th_id, nthreads;6 #pragma omp parallel private(th_id)7 {8 th_id = omp_get_thread_num();9 printf("Hello World from thread %d\n", th_id);10 #pragma omp barrier11 if ( th_id == 0 ) {12 nthreads = omp_get_num_threads();13 printf("There are %d threads\n",nthreads);14 }15 }16 return 0;17 }
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 53 / 55

Sample OpenMP programsParallel Matrix Multiplication
62 #pragma omp parallel for private(tmp, i, j, k)63 for (i=0; i<Ndim; i++){64 for (j=0; j<Mdim; j++){65 tmp = 0.0;6667 for(k=0;k<Pdim;k++){68 /* C(i,j) = sum(over k) A(i,k) * B(k,j) */69 tmp += *(A+(i*Ndim+k)) * *(B+(k*Pdim+j));70 }71 *(C+(i*Ndim+j)) = tmp;72 }73 }
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 54 / 55

Exercise 5: Running OpenMP Jobs on Pere
1 Copy the example files to your home directory$ rsync -av /group/hpc-bootcamp/2010Summer/Session4 .$ cd Session4/openmp/example1$ ls
2 Compile an openMP executable$ makegcc44 -O3 -fopenmp -o hello hello.c
3 Submit the job to the queue$ qsub openmp.qsub$ qstat
4 View the output after the program finished$ more test*.out
Feng, Xizhou (Marquette University) Introduction to Parallel Computing Bootcamp 2010 55 / 55


















