
Introduction to CUDA Programming CUDA Programming Introduction Andreas Moshovos Winter 2009 Some...
89
Introduction to CUDA Programming CUDA Programming Introduction Andreas Moshovos Winter 2009 Some slides/material from: UIUC course by Wen-Mei Hwu and David Kirk UCSB course by Andrea Di Blas Universitat Jena by Waqar Saleem NVIDIA by Simon Green
-
Upload
miranda-hancock -
Category
Documents
-
view
244 -
download
3
Transcript of Introduction to CUDA Programming CUDA Programming Introduction Andreas Moshovos Winter 2009 Some...

Introduction to CUDA ProgrammingCUDA Programming Introduction
Andreas MoshovosWinter 2009
Some slides/material from:UIUC course by Wen-Mei Hwu and David Kirk
UCSB course by Andrea Di BlasUniversitat Jena by Waqar Saleem
NVIDIA by Simon Green

Understanding Semiconductor Technology Limitations
• Computation– Calculations
• A + B, decide what to do next
– Data communication/Storage
Tons of Compute Engines
Tons of Storage
Unlimited BandwidthZero/Low Latency

Calculation capabilities• How many calculation units can be built?• Today’s silicon chips
– About 1B+ transistors– 30K transistors for a 52b multiplier
• ~30K multipliers
– 260mm^2 area (mid-range)– 112microns^2 for FP unit (overestimated)
• ~2K FP units
• Frequency ~ 3Ghz common today– TFLOPs possible
• Disclaimer: back-on-the-envelop calculations – take with a grain of salt
• Can build lots of calculation units
Tons of Compute Engines?

How about Communication/Storage• Need data feed and storage
– The larger the slower– Takes time to get there and back– Multiple cycles even on the same die
Tons of Compute Engines
Tons of Slow Storage
Unlimited BandwidthZero/Low Latency
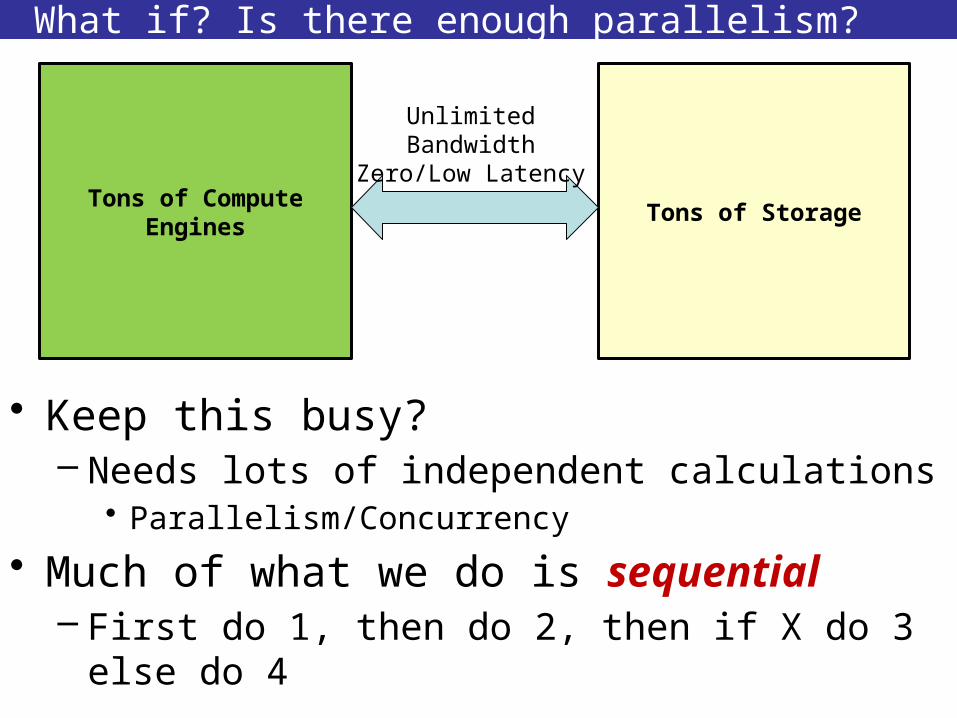
What if? Is there enough parallelism?
• Keep this busy?– Needs lots of independent calculations
• Parallelism/Concurrency
• Much of what we do is sequential– First do 1, then do 2, then if X do 3 else do 4
Tons of Compute Engines
Tons of Storage
Unlimited BandwidthZero/Low Latency
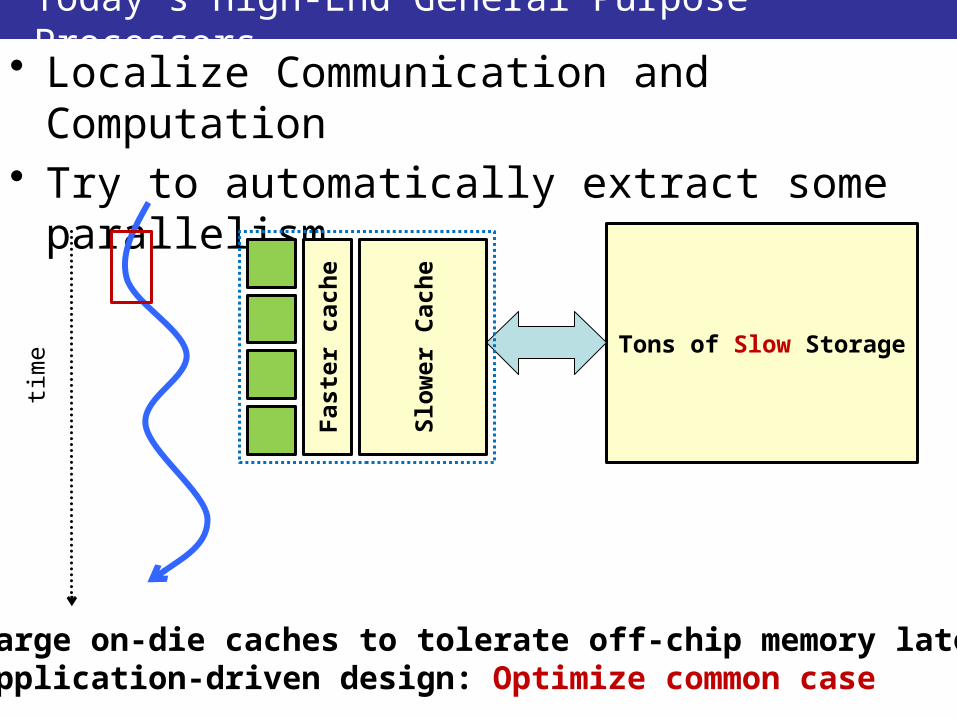
Today’s High-End General Purpose Processors• Localize Communication and Computation• Try to automatically extract some parallelism
time
Tons of Slow StorageF
aste
r ca
che
Slo
wer
Cac
he
Large on-die caches to tolerate off-chip memory latencyApplication-driven design: Optimize common case

Some things are naturally parallel

Sequential Execution Model
int a[N]; // N is largefor (i =0; i < N; i++)a[i] = a[i] * fade;
time
Flow of control / ThreadOne instruction at the timeOptimizations possible at the machine level

Data Parallel Execution Model / SIMD
int a[N]; // N is largefor all elements do in parallela[i] = a[i] * fade;
time
This has been tried before: ILLIAC III, UIUC, 1966http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4038028&tag=1http://ed-thelen.org/comp-hist/vs-illiac-iv.html

Single Program Multiple Data / SPMD
int a[N]; // N is largefor all elements do in parallelif (a[i] > threshold) a[i]*= fade;
time
Code is statically identical across all threadsExecution path may differThe model used in today’s Graphics Processors

CPU vs. GPU overview• CPU:
– Handles sequential code well• Latency optimized: do all very fast
– Can’t take advantage of massively parallel code– Off-chip bandwidth lower– Peak Computation capability lower
• GPU:– Requires massively parallel computation
• Bandwidth optimized: do lots concurrently
– Handles some control flow– Higher off-chip bandwidth– Higher peak computation capability
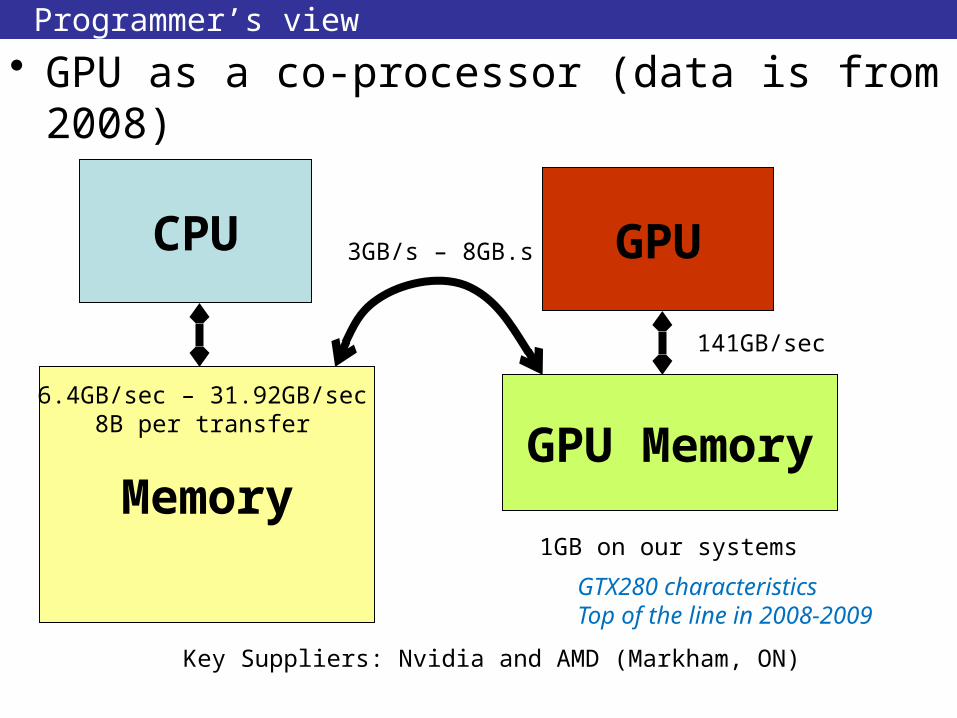
Programmer’s view
• GPU as a co-processor (data is from 2008)
CPU
Memory
GPU
GPU Memory
1GB on our systems
3GB/s – 8GB.s
6.4GB/sec – 31.92GB/sec8B per transfer
141GB/sec
Key Suppliers: Nvidia and AMD (Markham, ON)
GTX280 characteristicsTop of the line in 2008-2009

But what about performance?
• Focus on PEAK performance first:– What the manufacturer guarantees you’ll never
exceed• Two Aspects:
– Data Access Rate Capability • Bandwidth
– Data Processing Capability • How many ops per sec

Data Processing Capability– Focus on floating point data
• GFLOPS– Billion Floating-Point Operations per Second– Caveat: FOPs can be different
• But today things are not as bad as before
• High-End CPU today– 3.4Ghz x 8 FOPS/cycle = 27 GFLOPS– Assumes SSE
• High-End GPU today (2008) / GTX280– 933.1 GFLOPS or 34x capability

Data Access Capability
• High-End CPU Today (2008)– 31.92 GB/sec (nehalem) - 12.8 GB/sec
(hapertown)– Bus width 64-bit
• GPU / GTX280 (2008-2009)– 141.7 GB/sec– Bus width 512-bit– 4.39x – 11x

• GPU vs. CPU

• GPU vs. CPU

Target Applications
int a[N]; // N is largefor all elements of a computea[i] = a[i] * fade
• Lots of independent computations– CUDA threads need not be independent
Kernel
THREAD

Programmer’s View of the GPU
• GPU: a compute device that:– Is a coprocessor to the CPU or host– Has its own DRAM (device memory)– Runs many threads in parallel
• Data-parallel portions of an application are executed on the device as kernels which run in parallel on many threads

Why are threads useful? Parallelism
• Concurrency: – Do multiple things in parallel
– Uses more hardware Gets higher performance– Application must have parallelism
Needs more functional units

Why are threads useful #2 – Tolerating stalls
• Often a thread stalls, e.g., memory accessMultiplex the same functional unitGet more performance at a fraction of the cost
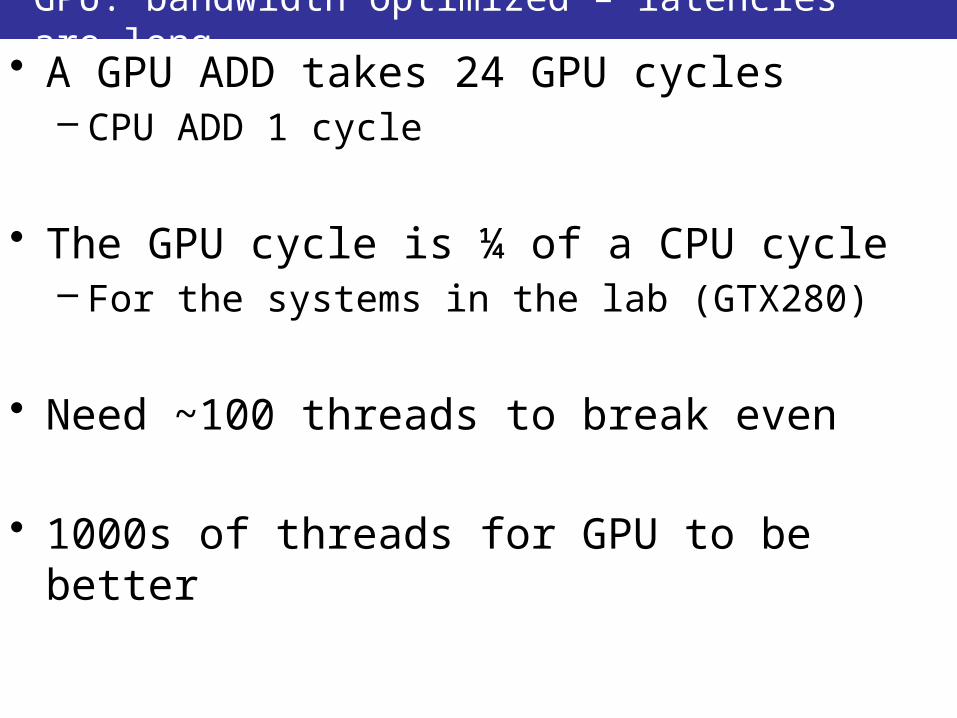
GPU: bandwidth optimized – latencies are long• A GPU ADD takes 24 GPU cycles
– CPU ADD 1 cycle
• The GPU cycle is ¼ of a CPU cycle– For the systems in the lab (GTX280)
• Need ~100 threads to break even
• 1000s of threads for GPU to be better

GPU vs. CPU Threads
• GPU threads are extremely lightweight• Very little creation overhead• In the order of microseconds• All done in hardware
• GPU needs 1000s of threads for full efficiency• Multi-core CPU needs only a few

Execution Timeline
time
1. Copy to GPU mem
2. Launch GPU Kernel
GPU / Device
2’. Synchronize with GPU
3. Copy from GPU mem
CPU / Host

Programmer’s view
• First create data on CPU memory
CPU
Memory
GPU
GPU Memory

Programmer’s view
• Then Copy to GPU
CPU
Memory
GPU
GPU Memory
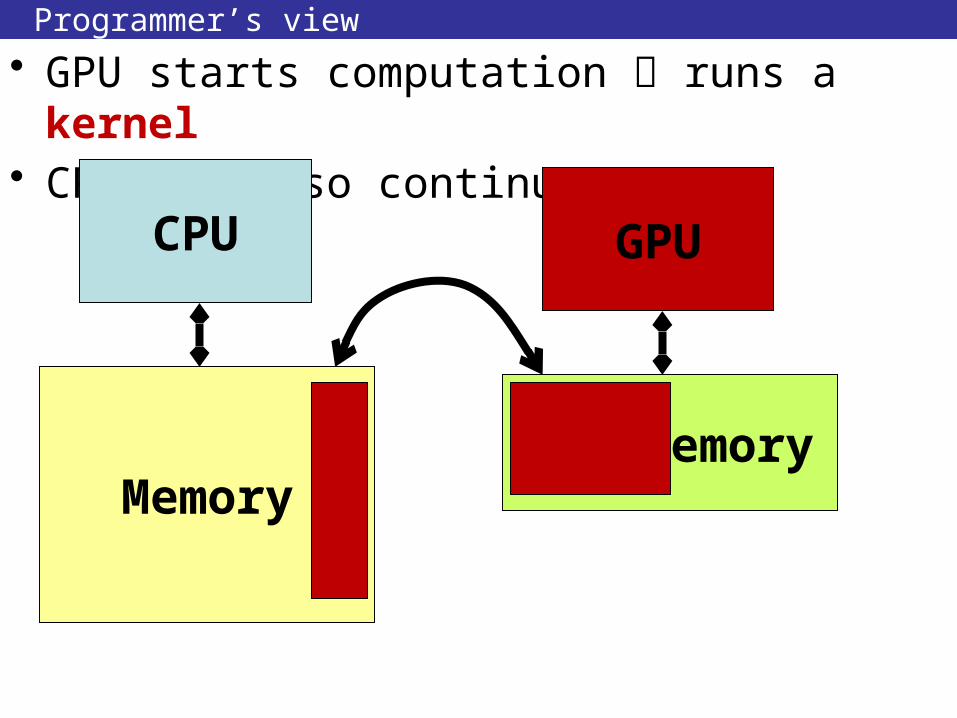
Programmer’s view
• GPU starts computation runs a kernel• CPU can also continue
CPU
Memory
GPU
GPU Memory
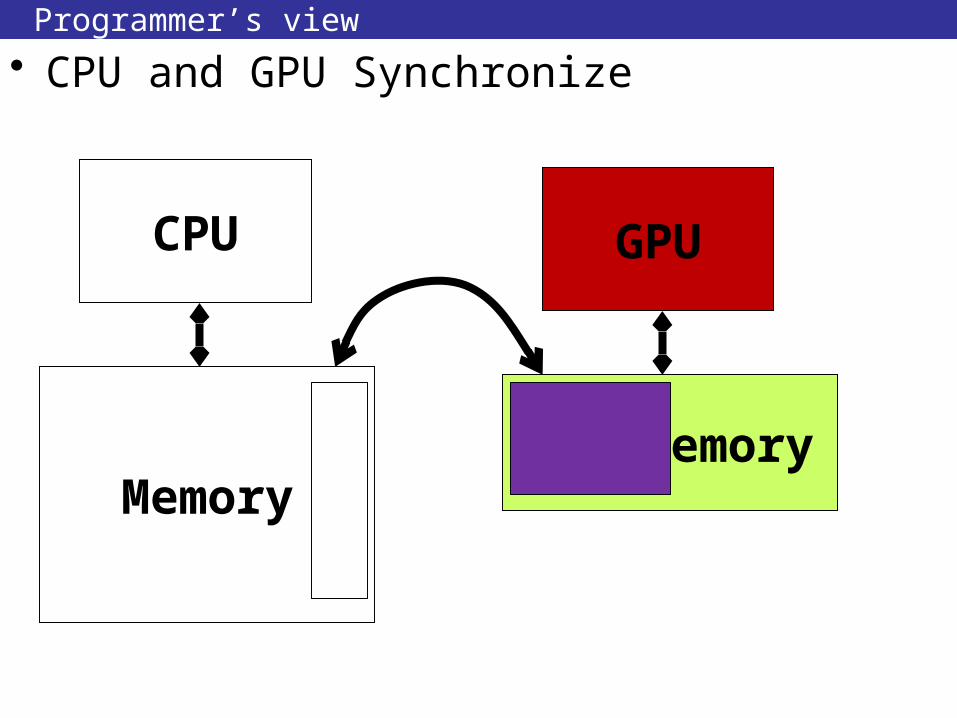
Programmer’s view
• CPU and GPU Synchronize
CPU
Memory
GPU
GPU Memory

Programmer’s view
• Copy results back to CPU
CPU
Memory
GPU
GPU Memory

Programming Languages• CUDA
– NVidia– Has market lead
• OpenCL– Many including Nvidia– CUDA superset– Somewhat different syntax– Can target many different devices– Fairly new
• We’ll focus on CUDA for now• Both are evolving

Computation partitioning: • At the highest level:
– Think of computation as a series of loops:
• for (i = 0; i < big_number; i++)– a[i] = some function
• for (i = 0; i < big_number; i++)– a[i] = some other function
• for (i = 0; i < big_number; i++)– a[i] = some other function
Kernels

Computation Partitioning -- Kernel• CUDA exposes the hardware to the programmer• Programmer must manually partition work appropriately
• Programmers view is hierarchical:– Think of data as an array

Per Kernel Computation Partitioning• Computation Grid: 2D Case
• Threads within a block can communicate/synchronize– Run on the same multiprocessor
• Threads across blocks can’t communicate– Shouldn’t touch each others data– Behavior undefined
Block
thread

GBT: Grids of Blocks of Threads
Why? Realities of integrated circuits: need to cluster computation and storageto achieve high speeds
Programmers view of data and computation partitioning
Tim
e

Programmer’s view: Memory Model

Grids of Blocks of Threads: Dimension Limits
• Grid of Blocks 1D or 2D– Max x: 65535– Max y: 65535
• Block of Threads: 1D, 2D, or 3D– Max number of threads: 512– Max x: 512– Max y: 512– Max z: 64
• Limits apply to Compute Capability 1.0, 1.1, 1.2, and 1.3
– GTX280 = 1.3– Fermi Architeture: 2.0 and 2.1
• We’ll talk about these at the end

Block and Thread IDs
• Threads and blocks have IDs– So each thread can decide
what data to work on– Block ID: 1D or 2D– Thread ID: 1D, 2D, or 3D
• Simplifies memoryaddressing when processingmultidimensional data– Convenience not necessity
Device
Grid 1
Block(0, 0)
Block(1, 0)
Block(2, 0)
Block(0, 1)
Block(1, 1)
Block(2, 1)
Block (1, 1)
Thread(0, 1)
Thread(1, 1)
Thread(2, 1)
Thread(3, 1)
Thread(4, 1)
Thread(0, 2)
Thread(1, 2)
Thread(2, 2)
Thread(3, 2)
Thread(4, 2)
Thread(0, 0)
Thread(1, 0)
Thread(2, 0)
Thread(3, 0)
Thread(4, 0)
• IDs and dimensions are accessible through predefined “variables”, e.g., blockDim.x and threadIdx.x

Thread Batching• A kernel is executed as a grid
of thread blocks– All threads share data memory space
• A thread block: • Threads that can cooperate
with each other by:– Synchronizing their execution
• For hazard-free shared memory accesses
– Efficiently sharing data through a low latency shared memory
• Two threads from two different blocks cannot cooperate
Host
Kernel 1
Kernel 2
Device
Grid 1
Block(0, 0)
Block(1, 0)
Block(2, 0)
Block(0, 1)
Block(1, 1)
Block(2, 1)
Grid 2
Block (1, 1)
Thread(0, 1)
Thread(1, 1)
Thread(2, 1)
Thread(3, 1)
Thread(4, 1)
Thread(0, 2)
Thread(1, 2)
Thread(2, 2)
Thread(3, 2)
Thread(4, 2)
Thread(0, 0)
Thread(1, 0)
Thread(2, 0)
Thread(3, 0)
Thread(4, 0)

Thread Coordination Overview
• Race-free access to data
Only across threads within the same blockNo communication across blocks
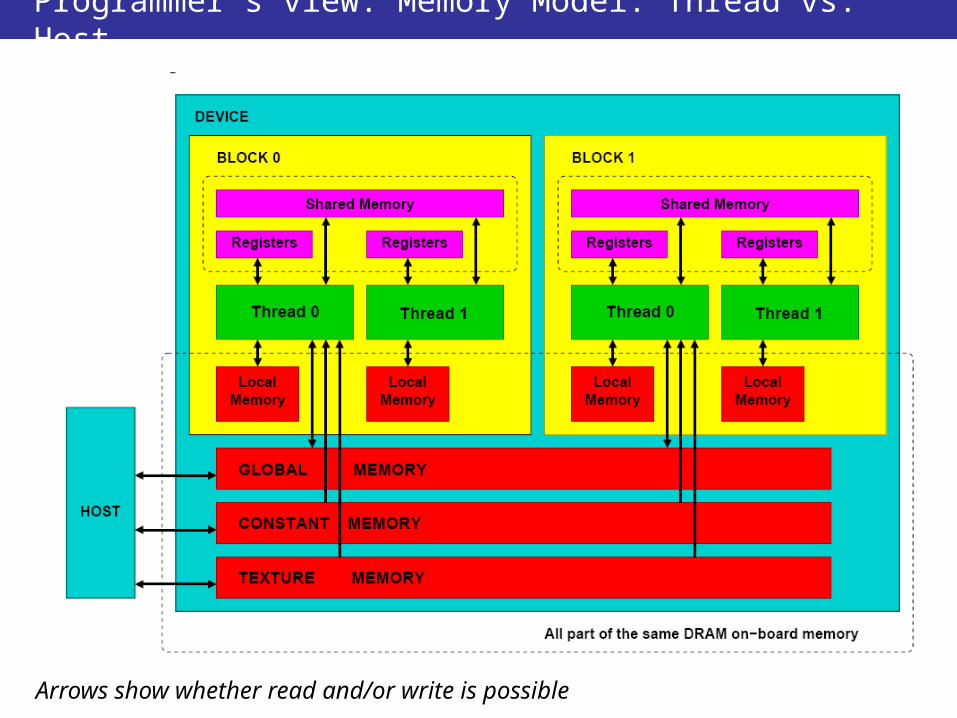
Programmer’s view: Memory Model: Thread vs. Host
Arrows show whether read and/or write is possible

Programmer’s View: Memory Detail – Thread and Host
• Each thread can:– R/W per-thread registers– R/W per-thread local memory– R/W per-block shared memory– R/W per-grid global memory– Read only per-grid constant memory– Read only per-grid texture memory
• The host can R/W: – global, constant, and texture memories

Memory Model: Global, Constant, and Texture Memories
• Global memory– Main means of communicating R/W Data between
host and device– Contents visible to all threads– Not cached (GTX280)
• Texture and Constant Memories– Constants initialized by host – Contents visible to all threads– Cached (GTX280)

Memory Model Summary
Memory Location Cached Access Scope
Local off-chip No R/W thread
Shared on-chip N/A R/W all threads in a block
Global off-chip No R/W all threads + host
Constant off-chip Yes RO all threads + host
Texture off-chip Yes RO all threads + host
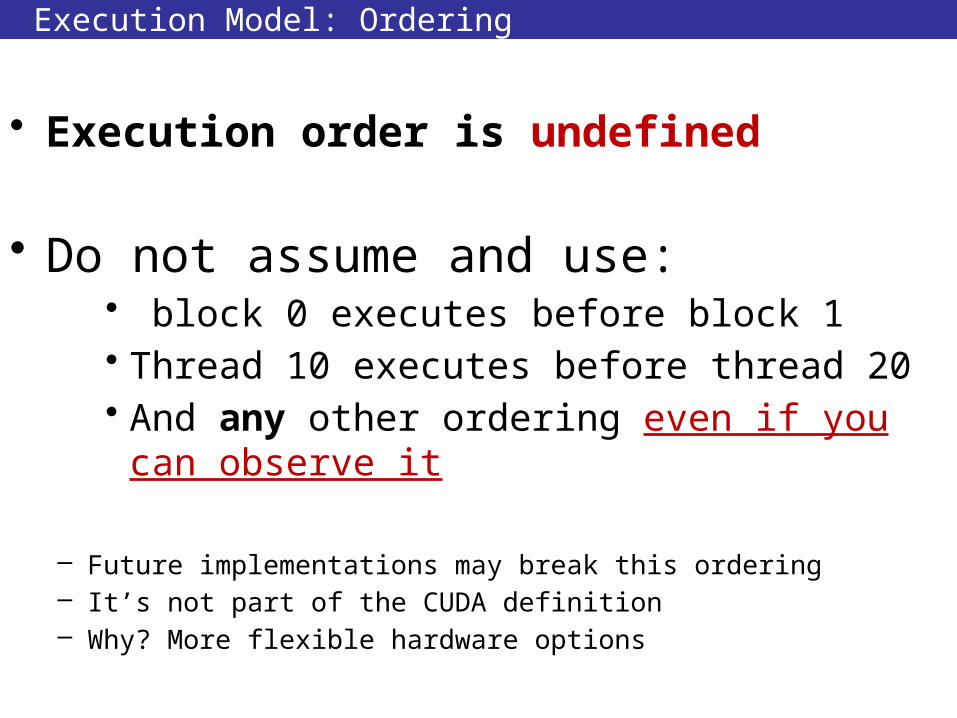
Execution Model: Ordering
• Execution order is undefined
• Do not assume and use:• block 0 executes before block 1• Thread 10 executes before thread 20• And any other ordering even if you can observe it
– Future implementations may break this ordering– It’s not part of the CUDA definition– Why? More flexible hardware options

CUDA Software Architecture
cuda…()
cu…()
e.g., fft()

Reasoning about CUDA call ordering
• GPU communication via cuda…() calls and kernel invocations– cudaMalloc, cudaMemCpy
• Asynchronous from the CPU’s perspective
– CPU places a request in a “CUDA” queue– requests are handled in-order
• Streams allow for multiple queues– Order within each queue honored– No order across queues
– More on this much later on

Execution Model Summary (for your reference)• Grid of blocks of threads
– 1D/2D grid of blocks– 1D/2D/3D blocks of threads
• All blocks are identical: – same structure and # of threads
• Block execution order is undefined • Same block threads:
– can synchronize and share data fast (shared memory)• Threads from different blocks:
– Cannot cooperate– Communication through global memory
• Threads and Blocks have IDs– Simplifies data indexing– Can be 1D, 2D, or 3D (threads)
• Blocks do not migrate: execute on the same processor• Several blocks may run over the same processor

CUDA API: Example
int a[N]; for (i =0; i < N; i++)a[i] = a[i] + x;
1. Allocate CPU Data Structure2. Initialize Data on CPU3. Allocate GPU Data Structure4. Copy Data from CPU to GPU5. Define Execution Configuration6. Run Kernel7. CPU synchronizes with GPU8. Copy Data from GPU to CPU9. De-allocate GPU and CPU memory

My first CUDA Program
__global__ void arradd (float *a, float f, int N) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < N) a[i] = a[i] + float;}
int main(){ float h_a[N]; float *d_a; cudaMalloc ((void **) &a_d, SIZE);
cudaMemcpy (d_a, h_a, SIZE, cudaMemcpyHostToDevice));
arradd <<< n_blocks, block_size >>> (d_a, 10.0, N);
cudaThreadSynchronize (); cudaMemcpy (h_a, d_a, SIZE, cudaMemcpyDeviceToHost)); CUDA_SAFE_CALL (cudaFree (a_d));}
GPU
CPU

1. Allocate CPU Data
float *ha;
main (int argc, char *argv[]){ int N = atoi (argv[1]); ha = (float *) malloc (sizeof (float) * N); ...
}No memory allocated on the GPU side
• Pinned memory allocation results in faster CPU to/from GPU copies• But pinned memory cannot be paged-out• cudaMallocHost (…)

2. Initialize CPU Data (dummy)
float *ha;
int i;
for (i = 0; i < N; i++)ha[i] = i;

3. Allocate GPU Data
float *da;
cudaMalloc ((void **) &da, sizeof (float) * N);
• Notice: no assignment side– NOT: da = cudaMalloc (…)
• Assignment is done internally:– That’s why we pass &da
• Space is allocated in Global Memory on the GPU

GPU Memory Allocation
• The host manages GPU memory allocation:– cudaMalloc (void **ptr, size_t nbytes)– Must explicitly cast to (void **)
• cudaMalloc ((void **) &da, sizeof (float) * N);
– cudaFree (void *ptr);• cudaFree (da);
– cudaMemset (void *ptr, int value, size_t nbytes);• cudaMemset (da, 0, N * sizeof (int));
• Check the CUDA Reference Manual

4. Copy Initialized CPU data to GPU
float *da;float *ha;
cudaMemCpy ((void *) da, // DESTINATION
(void *) ha, // SOURCE
sizeof (float) * N, // #bytes cudaMemcpyHostToDevice); //
DIRECTION
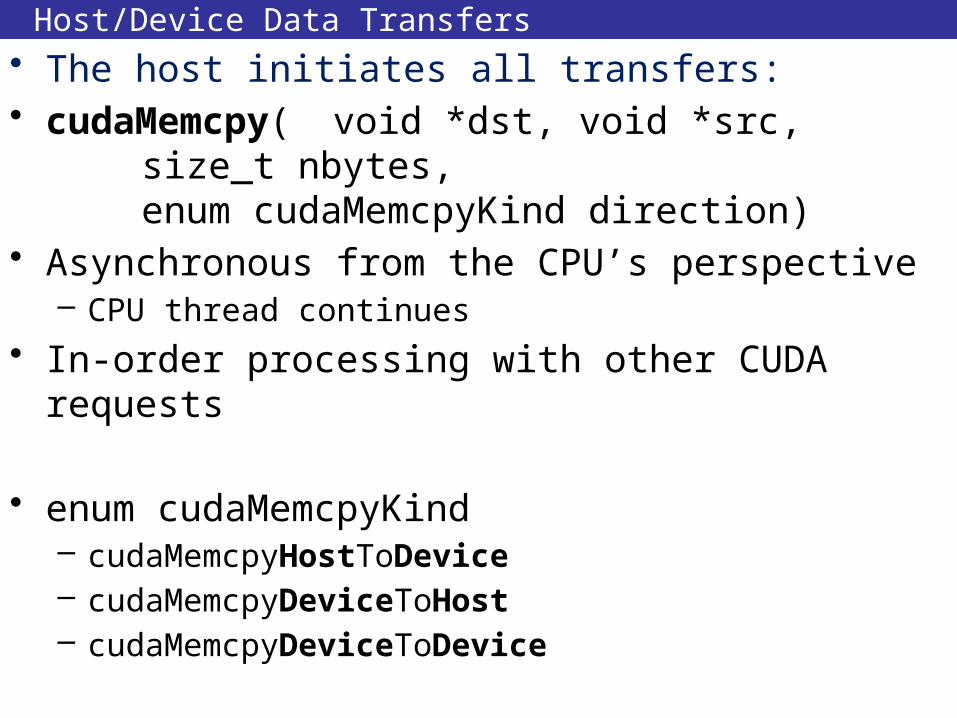
Host/Device Data Transfers
• The host initiates all transfers:• cudaMemcpy( void *dst, void *src,
size_t nbytes, enum cudaMemcpyKind direction)
• Asynchronous from the CPU’s perspective– CPU thread continues
• In-order processing with other CUDA requests
• enum cudaMemcpyKind– cudaMemcpyHostToDevice– cudaMemcpyDeviceToHost– cudaMemcpyDeviceToDevice

5. Define Execution Configuration
• How many blocks and threads/block
int threads_block = 64;int blocks = N / threads_block;if (blocks % N != 0) blocks += 1;
• Alternatively:
blocks = (N + threads_block – 1) / threads_block;

6. Launch Kernel & 7. CPU/GPU Synchronization
• Instructs the GPU to launch blocks x threads_block threads:
darradd <<<blocks, threads_block>> (da, 10f, N);
cudaThreadSynchronize (); // forces CPU to wait
• darradd: kernel name• <<<…>>> execution configuration
• (da, x, N): arguments– 256 – 8 byte limit / No variable arguments

CPU/GPU Synchronization
• CPU does not block on cuda…() calls– Kernel/requests are queued and processed in-order– Control returns to CPU immediately
• Good if there is other work to be done– e.g., preparing for the next kernel invocation
• Eventually, CPU must know when GPU is done• Then it can safely copy the GPU results
• cudaThreadSynchronize ()– Block CPU until all preceding cuda…() and kernel requests
have completed

8. Copy data from GPU to CPU & 9. DeAllocate Memory
float *da;float *ha;
cudaMemCpy ((void *) ha, // DESTINATION
(void *) da, // SOURCE
sizeof (float) * N, // #bytes cudaMemcpyDeviceToHost); //
DIRECTION
cudaFree (da);// display or process results herefree (ha);

The GPU Kernel
__global__ darradd (float *da, float x, int N){ int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) da[i] = da[i] + x;}
• BlockIdx: Unique Block ID.– Numerically asceding: 0, 1, …
• BlockDim: Dimensions of Block = how many threads it has– BlockDim.x, BlockDim.y, BlockDim.z– Unused dimensions default to 0
• ThreadIdx: Unique per Block Index– 0, 1, … – Per Block

Array Index Calculation Example
int i = blockIdx.x * blockDim.x + threadIdx.x;
a[0] a[63] a[64] a[127]a[128] a[191]a[192]
blockIdx.x = 0 blockIdx.x = 1 blockIdx.x = 2
thre
adId
x.x
0
thre
adId
x.x
63th
read
Idx.
x 0
thre
adId
x.x
63th
read
Idx.
x 0
thre
adId
x.x
63th
read
Idx.
x 0
i = 0 i = 63 i = 64 i = 127 i = 128 i = 191 i = 192
Assuming blockDim.x = 64

Generic Unique Thread and Block Index Calculations #1
• 1D Grid / 1D Blocks:
UniqueBlockIndex = blockIdx.x;UniqueThreadIndex = blockIdx.x * blockDim.x + threadIdx.x;
• 1D Grid / 2D Blocks:
UniqueBlockIndex = blockIdx.x;UniqueThreadIndex = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
• 1D Grid / 3D Blocks:
UniqueBockIndex = blockIdx.x;UniqueThreadIndex = blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
• Source: http://forums.nvidia.com/lofiversion/index.php?t82040.html

Generic Unique Thread and Block Index Calculations #2
• 2D Grid / 1D Blocks:
UniqueBlockIndex = blockIdx.y * gridDim.x + blockIdx.x;UniqueThreadIndex = UniqueBlockIndex * blockDim.x + threadIdx.x;
• 2D Grid / 2D Blocks:
UniqueBlockIndex = blockIdx.y * gridDim.x + blockIdx.x;UniqueThreadIndex =UniqueBlockIndex * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
• 2D Grid / 3D Blocks:
UniqueBlockIndex = blockIdx.y * gridDim.x + blockIdx.x;UniqueThreadIndex = UniqueBlockIndex * blockDim.z * blockDim.y * blockDim.x + threadIdx.z * blockDim.y * blockDim.z + threadIdx.y * blockDim.x + threadIdx.x;
• UniqueThreadIndex means unique per grid.

CUDA Function Declarations
• __global__ defines a kernel function– Must return void– Can only call __device__ functions
• __device__ and __host__ can be used together– Two difference versions generated
Executed on the:
Only callable from the:
__device__ float DeviceFunc() device device
__global__ void KernelFunc() device host
__host__ float HostFunc() host host

__device__ Example
• Add x to a[i] multiple times
__device__ float addmany (float a, float b, int count){
while (count--) a += b;return a;
}
__global__ darradd (float *da, float x, int N){ int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) da[i] = addmany (da[i], x, 10);}

Kernel and Device Function Restrictions• __device__ functions cannot have their address taken
– e.g., f = &addmany; *f(…);
• For functions executed on the device:– No recursion
• darradd (…){
darradd (…)}
– No static variable declarations inside the function• darradd (…){
static int canthavethis;}
– No variable number of arguments• e.g., something like printf (…)

My first CUDA Program
__global__ void arradd (float *a, float f, int N) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < N) a[i] = a[i] + float;}
int main(){ float h_a[N]; float *d_a; cudaMalloc ((void **) &a_d, SIZE);
cudaThreadSynchronize (); cudaMemcpy (d_a, h_a, SIZE, cudaMemcpyHostToDevice));
arradd <<< n_blocks, block_size >>> (d_a, 10.0, N);
cudaThreadSynchronize (); cudaMemcpy (h_a, d_a, SIZE, cudaMemcpyDeviceToHost)); CUDA_SAFE_CALL (cudaFree (a_d));}
GPU
CPU

How to get high-performance #1• Programmer managed Scratchpad memory
– Bring data in from global memory– Reuse– 16KB/banked– Accessed in parallel by 16 threads– “shared memory”
• Programmer needs to:– Decide what to bring and when– Decide which thread accesses what and when– Coordination paramount

How to get high-performance #2• Global memory accesses
– 32 threads access memory together– Can coalesce into a single reference– E.g., a[threadID] works well
• Control flow– 32 threads run together– If they diverge there is a performance penalty
• Texture cache– When you think there is locality

Numerical Accuracy• Can do FP
– Mostly OK some minor discrepancies• Can do DP
– 1/8 the bandwidth
• Mixed methods– Break numbers into two single-precision values
• Must carefully check for stability/correctness
• Will get better w/ next generation hardware

Are GPUs really that much faster than CPUs• 50x – 200x speedups typically reported
• Recent work found– Not enough effort goes into optimizing code for
CPUs– Intel paper (ISCA 2010)
• http://portal.acm.org/ft_gateway.cfm?id=1816021&type=pdf
• But:– The learning curve and expertise needed for CPUs
is much larger

Predefined Vector Datatypes• Can be used both in host and in device code.
– [u]char[1..4], [u]short[1..4], [u]int[1..4], [u]long[1..4], float[1..4]
• Structures accessed with .x, .y, .z, .w fields
• default constructors, “make_TYPE (…)”: – float4 f4 = make_float4 (1f, 10f, 1.2f, 0.5f);
• dim3– type built on uint3– Used to specify dimensions– Default value is (1, 1, 1)

Execution Configuration
• Must specify when calling a __global__ function:
<<< Dg, Db [, Ns [, S]] >>>• where:
– dim3 Dg: grid dimensions in blocks– dim3 Db: block dimensions in threads– size_t Ns: per block additional number of shared
memory bytes to allocate • optional, defaults to 0• more on this much later on
– cudaStream_t S: request stream(queue)• optional, default to 0. • Compute capability >= 1.1

Built-in Variables
• dim3 gridDim– Number of blocks per grid, in 2D (.z always 1)
• uint3 blockIdx– Block ID, in 2D (blockIdx.z = 1 always)
• dim3 blockDim– Number of threads per block, in 3D
• uint3 threadIdx– Thread ID in block, in 3D

Execution Configuration Examples
• 1D grid / 1D blocks
dim3 gd(1024)
dim3 bd(64) akernel<<<gd, bd>>>(...)
gridDim.x = 1024, gridDim.y = 1,blockDim.x = 64, blockDim.y = 1,
blockDim.z = 1 • 2D grid / 3D blocks
dim3 gd(4, 128)
dim3 bd(64, 16, 4) akernel<<<gd, bd>>>(...)
gridDim.x = 4, gridDim.y = 128,blockDim.x = 64, blockDim.y = 16,
blockDim.z = 4

Error Handling
• Most cuda…() functions return a cudaError_t– If cudaSuccess: Request completed without a problem
• cudaGetLastError():– returns the last error to the CPU– Use with cudaThreadSynchronize():
cudaError_t code;cudaThreadSynchronize ();code = cudaGetLastError ();
• char *cudaGetErrorString(cudaError_t code);– returns a human-readable description of the error code

Error Handling Utility Function
void cudaDie (const char *msg){cudaError_t err;cudaThreadSynchronize ();err = cudaGetLastError();
if (err == cudaSuccess) return; fprintf (stderr, "CUDA error: %s: %s.\n",
msg, cudaGetErrorString (err));
exit(EXIT_FAILURE);}• adapted from: http://www.ddj.com/hpc-high-performance-computing/207603131

Error Handling Macros
• CUDA_SAFE_CALL ( some cuda call )
CUDA_SAFE_CALL (cudaMemcpy (a_h, a_d, arr_size, cudaMemcpyDeviceToHost) );
• Prints error and exits on error
• Must define #define _DEBUG– No checking code emitted when undefined: Performance
• Use make dbg=1 under NVIDIA_CUDA_SDK

Measuring Time -- gettimeofday• Unix-based:#include <sys/time.h>#include <time.h>
struct timeval start, end;
gettimeofday (&start, NULL);WHAT WE ARE INTERESTED INgettimeofday (&end, NULL);
timeCpu = (float)(end.tv_sec - start.tv_sec);if (end.tv_usec < start.tv_usec){
timeCpu -= 1.0;timeCpu += (double)(1000000.0 + end.tv_usec - start.tv_usec)/1000000.0;
} elsetimeCpu += (double)(end.tv_usec - start.tv_usec)/1000000.0;

Using CUDA clock ()• clock_t clock ();• Can be used in device code• returns a counter value
– One per multiprocessor / incremented every clock cycle
• Sample at the beginning and end of the code• upper bound since threads are time-sliced• uint start = clock();
... compute (less than 3 sec) ....uint end = clock();if (end > start) time = end - start;else
time = end + (0xffffffff - start) • Look at the clock example under projects in SDK• Using takes some effort
– Every thread measures start and end– Then must find min start and max end– Cycle accurate

Using cutTimer…() library calls
#include <cuda.h>#include <cutil.h>unsigned int htimer;
cutCreateTimer (&htimer);CudaThreadSynchronize ();cutStartTimer(htimer);WHAT WE ARE INTERESTED INcudaThreadSynchronize ();cutStopTimer(htimer);printf (“time: %f\n", cutGetTimerValue(htimer));

Code Overview: Host side#include <cuda.h>#include <cutil.h>unsigned int htimer;float *ha, *da;main (int argc, char *argv[]) { int N = atoi (argv[1]); ha = (float *) malloc (sizeof (float) * N); for (int i = 0; i < N; i++) ha[i] = i; cutCreateTimer (&htimer); cudaMalloc ((void **) &da, sizeof (float) * N); cudaMemCpy ((void *) da, (void *) ha, sizeof (float) * N,
cudaMemcpyHostToDevice); blocks = (N + threads_block – 1) / threads_block; cudaThreadSynchronize (); cutStartTimer(htimer); darradd <<<blocks, threads_block>> (da, 10f, N) cudaThreadSynchronize (); cutStopTimer(htimer); cudaMemCpy ((void *) ha, (void *) da, sizeof (float) * N,
cudaMemcpyDeviceToHost); cudaFree (da); free (ha); printf (“processing time: %f\n", cutGetTimerValue(htimer));}

Code Overview: Device Side__device__ float addmany (float a, float b, int count){
while (count--) a += b;return a;
}
__global__ darradd (float *da, float x, int N){ int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) da[i] = addmany (da[i], x, 10);}

Variable Declarations – Will revisit next time
• __device__– stored in device memory (large, high latency, no cache)– Allocated with cudaMalloc (__device__qualifier implied)– accessible by all threads– lifetime: application
• __constant__– same as __device__, but cached and read-only by GPU– written by CPU via cudaMemcpyToSymbol(...) call– lifetime: application
• __shared__– stored in on-chip shared memory (very low latency)– accessible by all threads in the same thread block– lifetime: kernel launch
• Unqualified variables:– scalars and built-in vector types are stored in registers– arrays of more than 4 elements or run-time indices stored in device memory

Measurement Methodology• You will not get exactly the same time
measurements every time– Other processes running / external events (e.g.,
network activity)– Cannot control – “Non-determinism”
• Must take sufficient samples– say 10 or more– There is theory on what the number of samples
must be• Measure average• Will discuss this next time or will provide a
handout online

Handling Large Input Data Sets – 1D Example• Recall gridDim.[xy] <= 65535• Host calls kernel multiple times: float *dac = da; // starting offset for current kernel
while (n_blocks) { int bn = n_blocks; int elems; // array elements processed in this kernel if (bn > 65535) bn = 65535; elems = bn * block_size; darradd <<<bn, block_size>>> (dac, 10.0f, elems); n_blocks -= bn; dac += elems; }

Course Structure• Lectures:
– Sept – end of Nov.• Assignments
– 2-3 starting next week• Project:
– Propose by the end of first week of Nov.– Finish by second week of Dec.– Give presentation:
• If not too many – in class – otherwise in my office • Report:
– up to 10 pages• Must deliver: presentation, report, and code by the end of
the course

Project• Ideal scenario
– Team up:• People with interesting compute problems• People with strong computer eng./sci. background
– Algorithm/App. that has not been converted already– Or, try existing solutions and re-create results
ideally improve• Emphasis is on learning and reporting the
experience:– What went well– What didn’t and why

Material• Programming Massively Parallel
Processors: A Hands-on Approach – D. Kirk and W.-M. Hwu– http://www.elsevierdirect.com/morgan_kaufmann/kirk/
• The OpenCL Programming Book: Parallel Programming for MultiCore CPU and GPU, R. Tsuchiyama, T. Nakamura, and T. Lizuka, – http://www.fixstars.com/en/company/books/opencl/
• We’ll cover CUDA for GTX280 • At the end we’ll talk about the newest Fermi architecture and AMD’s
offerings


















