
Introduction to Audio Coding - HAW Hamburgschmidt/tt/audio-coding.pdf · Introduction to Audio...
16
Thomas Schmidt schmidt@informatik. haw-hamburg.de Introduction to Audio Coding o Fundamentals of Sound o Sampling & Quantization o Compression o Coding Standards
-
Upload
phamnguyet -
Category
Documents
-
view
225 -
download
1
Transcript of Introduction to Audio Coding - HAW Hamburgschmidt/tt/audio-coding.pdf · Introduction to Audio...

Thomas Schmidtschmidt@informatik.
haw-hamburg.de
Introduction to Audio Coding
o Fundamentals of Soundo Sampling & Quantizationo Compressiono Coding Standards

Thomas Schmidtschmidt@informatik.
haw-hamburg.deThe Nature of Sound
o Conversion of energy into vibrations in the air (or some other elastic medium)
o Most sound sources vibrate in complex ways leading to sounds with components at several different frequencies
o Sound is characterized at a very small timescale
o Frequency spectrum – relative amplitudes of the frequency components
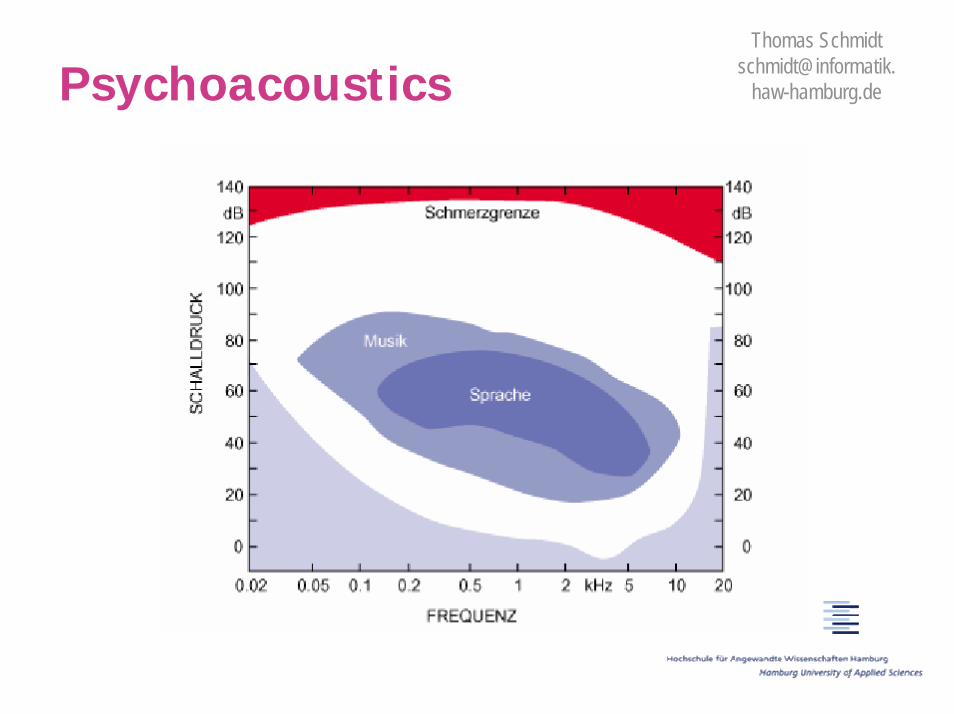
o Range of human hearing: roughly 20Hz–20kHz, falling off with age
Thomas Schmidtschmidt@informatik.
haw-hamburg.dePsychoacoustics

Thomas Schmidtschmidt@informatik.
haw-hamburg.deWaveforms
o Sounds change over time- e.g. musical note has attack and decay, speech changes constantly
o Frequency spectrum alters as sound changes
o Waveform is a plot of amplitude against time
- Provides a graphical view of characteristics of a changing sound
- Can identify syllables of speech, rhythm of music, quiet and loud passages, etc

Thomas Schmidtschmidt@informatik.
haw-hamburg.deDigitization – Sampling
o Audio timescale implies minimum rate of 40kHz to reproduce sound up to limit of hearing- CD: 44.1kHz
- Sub-multiples often used for low bandwidth
- e.g. 22.05kHz for Internet audio
- DAT: 48kHz
- (Hence mixing sounds from CD and DAT will require some resampling, best avoided)

Thomas Schmidtschmidt@informatik.
haw-hamburg.deDigitization – Quantization
o 16 bits, 65536 quantization levels, CD quality
o 8 bits: audible quantization noise, can only use if some distortion is acceptable, e.g. voice communication
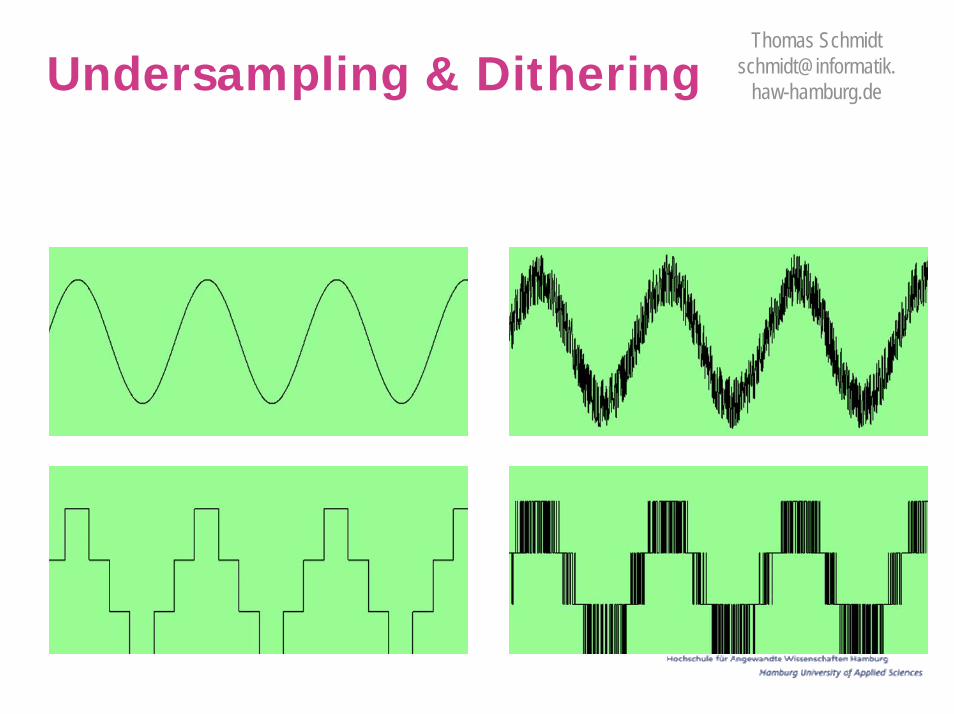
o Dithering – introduce small amount of random noise before sampling
- Noise causes samples to alternate rapidly between quantization levels, effectively smoothing sharp transitions
Thomas Schmidtschmidt@informatik.
haw-hamburg.deUndersampling & Dithering

Thomas Schmidtschmidt@informatik.
haw-hamburg.deData Size
o Sampling rate r is the number of samples per second, Sample size s bits
o Each second of digitized audio requires rs/8 bytes
o CD quality: r = 44100, s = 16, hence each second requires just over 86 kbytes (k=1024), each minute roughly 5Mbytes (mono)
o CD quality, stereo, 3-minute song requires over 25 Mbytes

Thomas Schmidtschmidt@informatik.
haw-hamburg.deCompression
o In general, lossy methods required because of complex and unpredictable nature of audio data
o Difference in perceiving sound and image means different approach from image compression:
+ Sampling & Quantization: PCM – DPCM – ADPCM
+ Special voice coding: Vocoders
+ Transform coding: DFT, DCT, MDCT
+ Perceptual coding
+ Entropy coding
Thomas Schmidtschmidt@informatik.
haw-hamburg.deCompanding
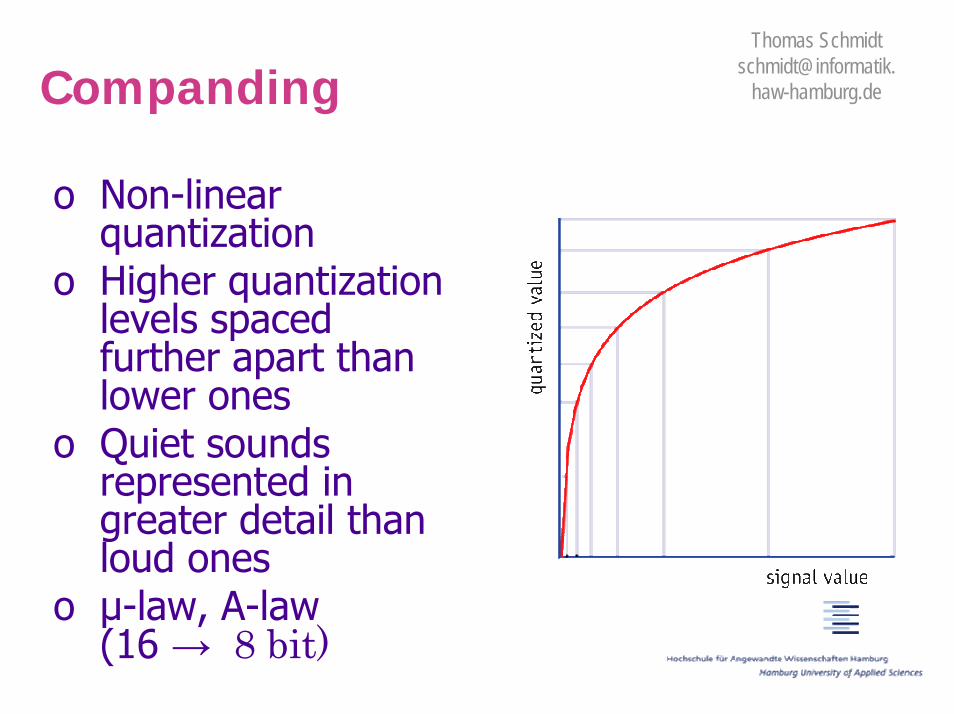
o Non-linear quantization
o Higher quantization levels spaced further apart than lower ones
o Quiet sounds represented in greater detail than loud ones
o µ-law, A-law (16 → 8 bit)

Thomas Schmidtschmidt@informatik.
haw-hamburg.deImproved Pulse Code Modulation
o Differential Pulse Code Modulation- Similar to video inter-frame compression
- Compute a predicted value for next sample, store the difference between prediction and actual value
o Adaptive Differential Pulse Code Modulation- Dynamically vary step size used to store quantized differences

Thomas Schmidtschmidt@informatik.
haw-hamburg.deSpeech Coders
There is a variety of well known ITU voice coders:
o G.711 – ‘the’ ISDN codec, µ / A-law companding, 8 bit@8kHz, (2:1)
o G.721, G.722, G.723
o G.726, G.727 – ADPCM with linear prediction, variable codewords 2 – 5 bit@8kHz (≤ 8:1)
o GSM 06.10 - ADPCM with linear prediction, 1,6bit@8kHz (10:1)
o Current compression values up to 50 : 1, 10 : 1 with decent quality (see www.speex.org)

Thomas Schmidtschmidt@informatik.
haw-hamburg.dePerceptually-Based Compression
o Identify and discard data that doesn't affect the perception of the signal- Needs a psycho-acoustical model, since ear and brain do not respond to sound waves in a simple way
o Threshold of hearing – sounds too quiet to hear
o Masking – sound obscured by some other sound

Thomas Schmidtschmidt@informatik.
haw-hamburg.deCompression by Masking
o Split signal into bands of frequencies using filters- Commonly use 32 bands
o Compute masking level for each band, based on its average value and a psycho-acoustical model
- i.e. approximate masking curve by a single value for each band
o Discard signal if it is below masking level
o Otherwise quantize using the minimum number of bits that will mask quantization noise
o Also: Temporal Masking

Thomas Schmidtschmidt@informatik.
haw-hamburg.deMPEG Audio Codingo MPEG Audio, Layer 3
o Three layers of audio compression in MPEG-1 (MPEG-2 essentially identical)
o Layer 1...Layer 3, encoding proces increases in complexity, data rate for same quality decreases
- Layer 2: temporal & frequency masking – Layer 3: MDCT + …
- e.g. Same quality 192kbps at Layer 1, 128kbps at Layer 2, 64kbps at Layer 3
o 10:1 compression ratio at high quality
o Variable bit rate coding (VBR)

Thomas Schmidtschmidt@informatik.
haw-hamburg.deReferences
• Z. Li, M. Drew: Fundamentals of Multimedia, Pearson Prentice Hall, 2004.• K. Rao, Z. Bojkovic, D. Milavanovic, Multimedia Communication Systems,
Prentice Hall, 2002. • N. Chapman, J. Chapman: Digital Multimedia, 2nd edition, Wiley,
Chichester, GB, 2004.


















