
Introduction to Apache Pig - ut · –Writing low level Mapreduce code slow ... Advantages of Pig...
27
Introduction to Apache Pig Pelle Jakovits 23 September, 2013, Tartu
Transcript of Introduction to Apache Pig - ut · –Writing low level Mapreduce code slow ... Advantages of Pig...

Introduction to Apache Pig
Pelle Jakovits
23 September, 2013, Tartu

Outline
• MapReduce recollection
• Why Pig? – Advantages
• Running pig
• Pig Latin
• Examples
• Architecture
• Disadvantages
Pelle Jakovits 2/18

You already know MapReduce
• MapReduce = Map, GroupBy, Sort, Reduce”
• Designed or huge scale data processing
• Provides – Distributed file system
– High scalability
– Automatic parallelisation
– Automatic fault recovery • Data is replicated
• Failed tasks are re-executed on other nodes
Pelle Jakovits 3/18

But is MapReduce enough?
• Hadoop MapReduce is one of the most used frameworks for large scale data processing
• However:
– Writing low level Mapreduce code slow
– Need a lot of expertise to optimize MapReduce code
– Prototyping is slow
– A lot of custom code required
• Even for the most simplest tasks
– Hard to manage more complex mapreduce job chains
Pelle Jakovits 4/18

Apache Pig
• A data flow framework on top of Hadoop MapReduce – Retains all its advantages
– And some of it’s disadvantages
• Models a scripting language – Fast prototyping
• Uses Pig Latin language
– Similiar to declarative SQL
– Easier to get started with
• Pig Latin statements are automatically translated into MapReduce jobs
Pelle Jakovits 5/18

Advantages of Pig
• Easy to Program – 5% of the code, 5% of the time required
• Self-Optimizing – Pig Latin statment optimizations – Generated MapReduce code optimizations
• Can manage more complex data flows – Easy to use and join multiple separate inputs,
transformations and outputs
• Extensible – Can be extended with User Defined Functions (UDF)
to provide more functionality
Pelle Jakovits 6/18

Running Pig
• Local mode – Everything installed locally on one machine
• Distributed mode – Everything runs in a MapReduce cluster
• Interactive mode – Grunt shell
• Batch mode – Pig scripts
Pelle Jakovits 7/18

Pig Latin
• Write complex MapReduce transformations using much simpler scripting language
• Not quite SQL, but similar
• Lazy evaluation
• Compiling is hidden from the user
Pelle Jakovits 8/18

Pig Latin Example
I = load ‘/mydata/images’ using ImageParser() as (id, image);
F = foreach I generate id, detectFaces(image);
store F into ‘/mydata/faces’;
• Input and output are HDFS folders or files – /mydata/images
– /mydata/faces
• I and F are relations
• Right hand side contains Pig expressions
Pelle Jakovits 9/18

Relations, Bags, Tuples, Fields
• Relation – Can have nested relations
– Similiar to a table in a relational database
– Consists of a Bag
• Bag – Collection of unordered tuples
• Tuple – An ordered set of fields
– Similiar to a row in a relational database
– Can contain any number of fields, does not have to match other tuples
• Fields – A piece of data
Pelle Jakovits 10/18

Fields
• Consists of either: – Data atoms - Int, long, float, double, chararray, boolean,
datetime, etc.
– Complex data - Bag, Map, Tuple
• Assigning types to fields – A = LOAD 'student' AS (name:chararray, age:int, gpa:float);
• Referencing Fields – By order - $0, $1, $2
– By name - assigned by user schemas • A = LOAD ‘in.txt‘ AS (age, name, occupation);
Pelle Jakovits 11/18

Complex data types
• Looking into complex, nested data
– client.$0
– author.age
Pelle Jakovits 12/18

Loading and storing data
• LOAD – A = LOAD ‘myfile.txt’ USING PigStorage(‘\t’) AS (f1:int,
f2:int, f3:int); – User defines data loader and delimiters
• STORE – STORE A INTO ‘output_1.txt’ USING PigStorage (‘,’); – STORE B INTO ‘output_2.txt’ USING PigStorage (‘*’);
• Other data loaders – BinStorage – PigDump – TextLoader – Or create a custom one.
Pelle Jakovits 13/18

FOREACH … GENERATE
• General data transformation statement
• Used to:
– Change the structure of data
– Apply functions to data
– Flatten complex data to remove nesting
• X = FOREACH C GENERATE FLATTEN (A.(a1, a2)), FLATTEN(B.$1);
Pelle Jakovits 14/18

Group .. BY
• A = load 'student' AS (name:chararray, age:int, gpa:float);
• DUMP A; – (John, 18, 4.0F)
– (Mary, 19, 3.8F)
– (Bill, 20, 3.9F)
– (Joe, 18, 3.8F)
• B = GROUP A BY age;
• DUMP B;
– (18, {(John, 18, 4.0F), (Joe, 18, 3.8F)})
– (19, {(Mary, 19, 3.8F)})
– (20, {(Bill, 20, 3.9F)})
Pelle Jakovits 15/18

JOIN
• A = LOAD 'data1' AS (a1:int,a2:int,a3:int);
• B = LOAD 'data2' AS (b1:int,b2:int);
• X = JOIN A BY a1, B BY b1;
Pelle Jakovits 16/18
DUMP A; (1,2,3) (4,2,1)
DUMP B;
(1,3) (2,7) (4,6)
DUMP X;
(1,2,3,1,3) (4,2,1,4,6)

Union
• A = LOAD 'data' AS (a1:int, a2:int, a3:int);
• B = LOAD 'data' AS (b1:int, b2:int);
• X = UNION A, B;
Pelle Jakovits 17/18
DUMP A; (1,2,3) (4,2,1)
DUMP A;
(2,4) (8,9)
DUMP X;
(1,2,3) (4,2,1) (2,4) (8,9)

Functions
• SAMPLE
– A = LOAD 'data' AS (f1:int,f2:int,f3:int);
– X = SAMPLE A 0.01;
– X will contain 1% of tuples in A
• FILTER
– A = LOAD 'data' AS (a1:int, a2:int, a3:int);
– X = FILTER A BY a3 == 3;
Pelle Jakovits 18/18

Functions
• DISTINCT – removes duplicate tuples
– X = DISTINCT A;
• LIMIT –
– X = LIMIT B 3;
• SPLIT –
– SPLIT A INTO X IF f1<7, Y IF f2==5, Z IF (f3<6 OR f3>6);
Pelle Jakovits 19/18

Pig Example 1
• A = LOAD 'student' USING PigStorage() AS (name, age, gpa);
• DUMP A;
– (John, 18, 4.0F)
– (Mary, 19, 3.8F)
– (Bill, 20, 3.9F)
– (Joe, 18, 3.8F)
• B = GROUP A BY age;
• C = FOREACH B GENERATE AVG(gpa)
Pelle Jakovits 20/18

Pig Example 2
• batting = load 'Batting.csv' using PigStorage(','); • runs = FOREACH batting GENERATE $0 as playerID, $1
as year, $8 as runs; • grp_data = GROUP runs by (year); • max_runs = FOREACH grp_data GENERATE group as
grp, MAX(runs.runs) as max_runs; • join_max_run = JOIN max_runs by ($0, max_runs), runs
by (year,runs); • join_data = FOREACH join_max_run GENERATE $0 as
year, $2 as playerID, $1 as runs; • dump join_data;
Pelle Jakovits 21/18

User Defined Functions (UDF)
• DEFINE alias function
–
• DEFINE alias command input output
– For streaming
Pelle Jakovits 22/18
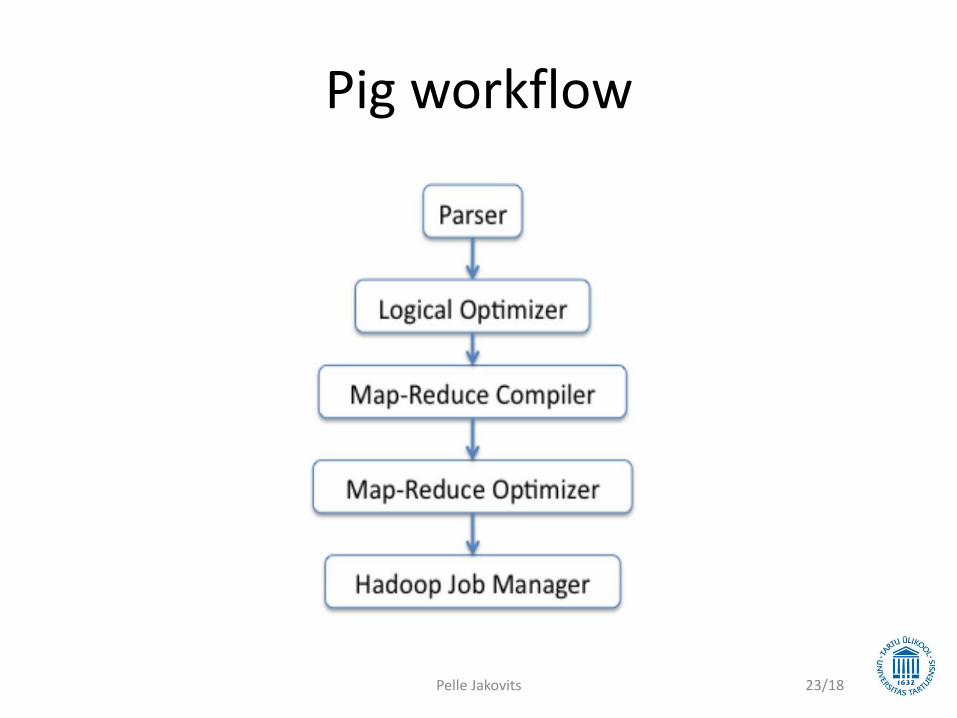
Pig workflow
Pelle Jakovits 23/18

Pelle Jakovits 24/18
Pig workflow

Pig disadvantages
• Slow start-up and clean-up of MapReduce jobs
– It takes time for Hadoop to schedule MR jobs
• Not suitable for interactive OLAP Analytics
– When results are expected in < 1 sec
• Complex applications may require many UDF’s
– Pig loses it’s simplicity over MapReduce
Pelle Jakovits 25/18

Other noteworthy Hadoop projects
• Hbase – Open-source distributed database ontop of HDFS
• Hive™ – A data warehouse infrastructure that provides data
summarization and ad hoc querying. – Developed by Facebook
• Mahout™ – A Scalable machine learning and data mining library.
• ZooKeeper™ – A high-performance coordination service for distributed
applications. – Centralised configuration and synchronization
Pelle Jakovits 26/18

Thats All
• This week`s practice session
– Processing data with Pig
– Similiar exercise as last week, but this time using Pig
• Next lecture: Hive
– What is Hive
– HiveQL language
– Hive vs Pig
Pelle Jakovits 27/18


















