
Intel® Cloud Builders Guide to Cloud Design and Deployment ... · Operation of a Hadoop Cluster...
34
Intel® Cloud Builders Guide to Cloud Design and Deployment on Intel® Platforms Apache* Hadoop* Audience and Purpose This reference architecture is for companies who are looking to build their own cloud computing infrastructure, including both enterprise IT organizations and cloud service providers or cloud hosting providers. The decision to use a cloud for the delivery of IT services is best done by starting with the knowledge and experience gained from previous work. This reference architecture gathers into one place the essentials of a Apache* Hadoop* cluster build out complete with benchmarking using TeraSort workload. This paper defines easy to use steps to replicate the deployment at your data center lab environment. The installation is based on Intel®-powered servers and creates a multi node, optimized Hadoop environment. The reference architecture contains details on the Hadoop topology, hardware and software deployed, installation and configuration steps, and tests for real-world use cases that should significantly reduce the learning curve for building and operating your first Hadoop infrastructure. It is not expected that this paper can be used “as-is.” For example, adapting to an existing network and identifying specific management requirements are out of scope for this paper. Therefore, it is expected that the user of this paper will make significant adjustments as required to the design presented in order to meet their specific requirements of their own data center or lab environment. This paper also assumes that the reader has basic knowledge of computing infrastructure components and services. Intermediate knowledge of Linux* operating system, Python*, Hadoop framework and basic system administration skills is assumed. February 2012 Intel® Cloud Builders Guide Intel® Xeon® Processor-based Servers Apache* Hadoop* Intel® Xeon® Processor 5600 Series
Transcript of Intel® Cloud Builders Guide to Cloud Design and Deployment ... · Operation of a Hadoop Cluster...

Intel® Cloud Builders Guide to Cloud Design and Deployment on Intel® PlatformsApache* Hadoop*
Audience and PurposeThis reference architecture is for companies who are looking to build their own cloud computing infrastructure, including both enterprise IT organizations and cloud service providers or cloud hosting providers. The decision to use a cloud for the delivery of IT services is best done by starting with the knowledge and experience gained from previous work. This reference architecture gathers into one place the essentials of a Apache* Hadoop* cluster build out complete with benchmarking using TeraSort workload. This paper defines easy to use steps to replicate the deployment at your data center lab environment. The installation is based on Intel®-powered servers and creates a multi node, optimized Hadoop environment. The reference architecture contains details on the Hadoop topology, hardware and software deployed, installation and configuration steps, and tests for real-world use cases that should significantly reduce the learning curve for building and operating your first Hadoop infrastructure.
It is not expected that this paper can be used “as-is.” For example, adapting to an existing network and identifying specific management requirements are out of scope for this paper. Therefore, it is expected that the user of this paper will make significant adjustments as required to the design presented in order to meet their specific requirements of their own data center or lab environment. This paper also assumes that the reader has basic knowledge of computing infrastructure components and services. Intermediate knowledge of Linux* operating system, Python*, Hadoop framework and basic system administration skills is assumed.
February 2012
Intel® Cloud Builders GuideIntel® Xeon® Processor-based ServersApache* Hadoop*
Intel® Xeon® Processor 5600 Series

2
Intel® Cloud Builders Guide: Apache* Hadoop*
Table of Contents
Executive Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Hadoop* Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Hadoop System Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Operation of a Hadoop Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
TeraSort Workload . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
TeraSort Workflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Test Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Intel® Benchmark Install and Test Tool (Intel® BITT) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Intel BITT Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Configuring the Setups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Running TeraSort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .24
Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .33

Executive SummaryMap reduce technology is gaining popularity among enterprises for a variety of large-scale data intensive jobs. Map reduce based on Apache* Hadoop* is rapidly emerging as a technology preferred for big data processing and management. Enterprises are deploying commodity standard server clusters and using business intelligence tools along with Apache Hadoop to obtain high performing solutions for their large scale data processing requirements. Motivation to deploy Hadoop comes from the fact that enterprises are gathering huge unstructured data sets generated by their business processes, which enterprises are looking to exploit to get the most value out of this data to help them in the decision making process. Hadoop infrastructure moves data closer to compute to achieve high processing throughput. In this paper we tried to create a small commodity server cluster based on an Apache Hadoop distribution and ran sort benchmark to get data on how fast the cluster can process data. This reference architecture will give
an understanding on how to set up the cluster, tune parameters, and run sort benchmark. This reference architecture provides a blue print for building a cluster with Intel® Xeon® processor based standard server platforms and the open source Apache Hadoop distribution. The paper further describes parameters for tuning and execution of sort benchmark to measure performance.
Hadoop* OverviewApache Hadoop is a framework for running applications on large cluster built using standard hardware. The Hadoop framework transparently provides applications both reliability and data motion. Hadoop implements a computational paradigm named MapReduce, where the application is divided into many small fragments of work, each of which may be executed or re-executed on any node in the cluster. In addition, it provides a distributed file system that stores data on the compute nodes, providing very high aggregate bandwidth across the cluster. Both MapReduce and the Hadoop Distributed
File System (HDFS) are designed so that node failures are automatically tolerated by the framework.
Hadoop framework consists of three major components:
• Common: Hadoop Common is a set of utilities that support the Hadoop subprojects. Hadoop Common includes FileSystem, RPC, and serialization libraries.
• HDFS: The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS can stream file system data.
• MapReduce: MapReduce was first developed by Google to process large datasets. MapReduce has two functions, map and reduce, and a framework for running a large number of instances of these programs on commodity hardware. The map function reads a set of records from an input file, processes these records, and outputs a set of intermediate records. As part of the map function, a split function distributes the intermediate records across many buckets using a hash function. The reduce function then processes the intermediate records. The MapReduce Framework consists of a single master JobTracker and one slave TaskTracker per cluster node. The master is responsible for scheduling the jobs' component tasks on the slaves, monitoring them, and re-executing the failed tasks. The slaves execute the tasks as directed by the master.
Figure 1: Hadoop* stack
3
Intel® Cloud Builders Guide: Apache* Hadoop*
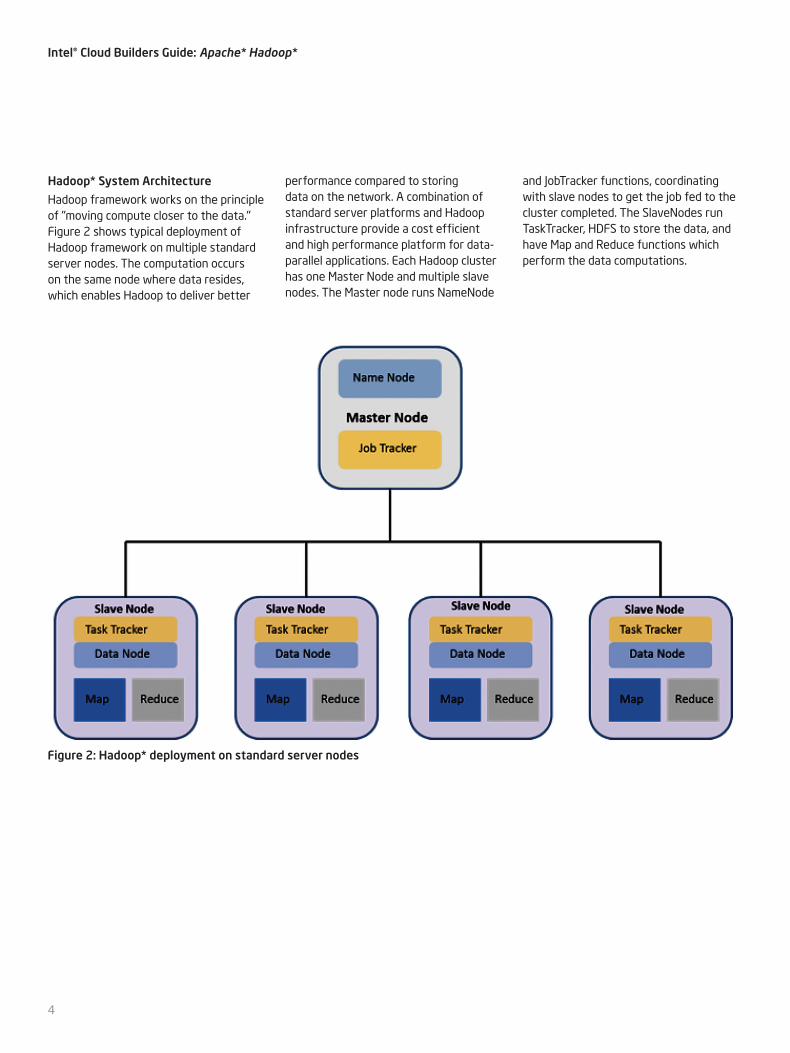
Figure 2: Hadoop* deployment on standard server nodes
Hadoop* System Architecture
Hadoop framework works on the principle of "moving compute closer to the data." Figure 2 shows typical deployment of Hadoop framework on multiple standard server nodes. The computation occurs on the same node where data resides, which enables Hadoop to deliver better
performance compared to storing data on the network. A combination of standard server platforms and Hadoop infrastructure provide a cost efficient and high performance platform for data-parallel applications. Each Hadoop cluster has one Master Node and multiple slave nodes. The Master node runs NameNode
and JobTracker functions, coordinating with slave nodes to get the job fed to the cluster completed. The SlaveNodes run TaskTracker, HDFS to store the data, and have Map and Reduce functions which perform the data computations.
4
Intel® Cloud Builders Guide: Apache* Hadoop*
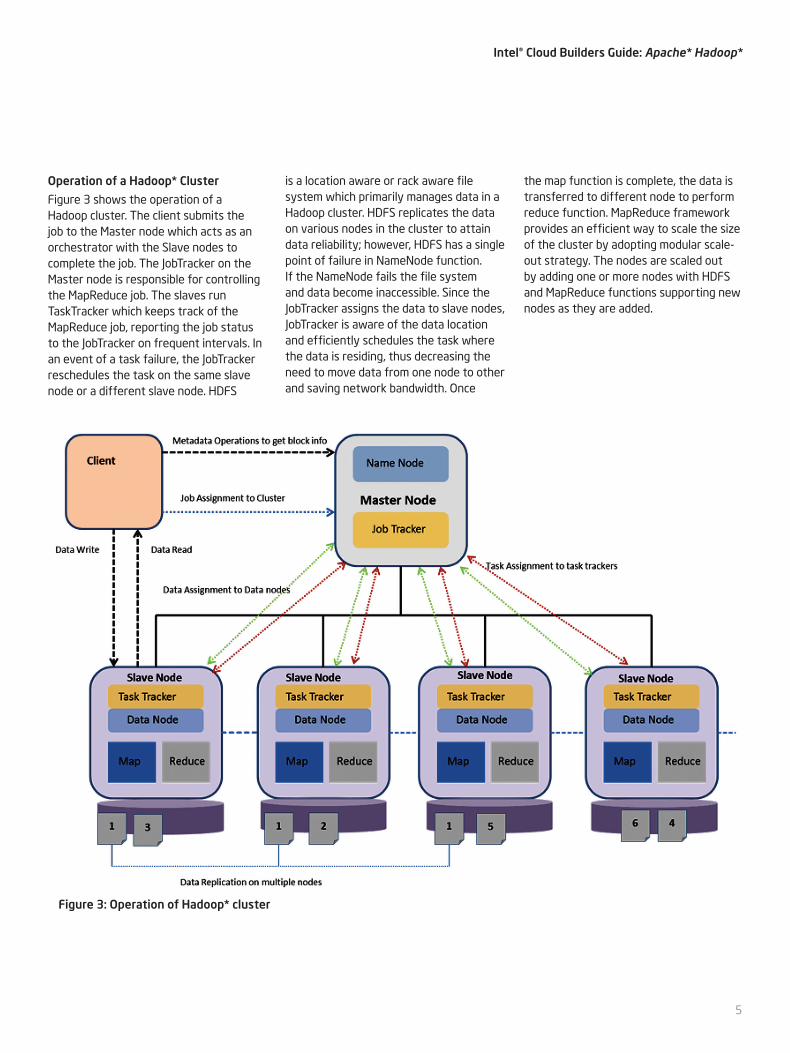
Operation of a Hadoop* Cluster
Figure 3 shows the operation of a Hadoop cluster. The client submits the job to the Master node which acts as an orchestrator with the Slave nodes to complete the job. The JobTracker on the Master node is responsible for controlling the MapReduce job. The slaves run TaskTracker which keeps track of the MapReduce job, reporting the job status to the JobTracker on frequent intervals. In an event of a task failure, the JobTracker reschedules the task on the same slave node or a different slave node. HDFS
is a location aware or rack aware file system which primarily manages data in a Hadoop cluster. HDFS replicates the data on various nodes in the cluster to attain data reliability; however, HDFS has a single point of failure in NameNode function. If the NameNode fails the file system and data become inaccessible. Since the JobTracker assigns the data to slave nodes, JobTracker is aware of the data location and efficiently schedules the task where the data is residing, thus decreasing the need to move data from one node to other and saving network bandwidth. Once
the map function is complete, the data is transferred to different node to perform reduce function. MapReduce framework provides an efficient way to scale the size of the cluster by adopting modular scale-out strategy. The nodes are scaled out by adding one or more nodes with HDFS and MapReduce functions supporting new nodes as they are added.
Figure 3: Operation of Hadoop* cluster
5
Intel® Cloud Builders Guide: Apache* Hadoop*

Cluster hardware setup:
• Total 17 nodes in the cluster. One Master node and 16 Slave nodes.
• Data Network: Arista 7124 switch connected to Intel® Ethernet Server Adapter X520-DA2 dual 10GbE NIC on every node.
• Each server has an internal private Intel® dual 1GbE NIC connected to a top-of-rack switch that is used for management tasks.
• Each node has a disk enclosure populated with SATA II 7.2K, 2TB hard disk drives for a total of 24TBs of raw storage per hard disk enclosure.
• Dual socket Intel® 5520 Chipset platform.
• Two Intel® Xeon® processor X5680 at 3.33GHz, 12MB cache.
• 48GB 1333MHz DDR3 memory
• Red Hat Enterprise Linux* 6.0 (RHEL 6.0)(Kernel: 2.6.32-71.el6..x86_64)
• Hadoop* Framework v0.20.1
Figure 4: Cluster hardware setup
6
Intel® Cloud Builders Guide: Apache* Hadoop*
TeraSort WorkloadTeraSort is a popular Hadoop benchmarking workload. The 1TB limit is not a hard-set limit since TeraSort allows the user to sort any size of dataset by changing various parameters. TeraSort benchmark tests HDFS and MapReduce functions in the Hadoop cluster. TeraSort is part of the Hadoop framework and is part of the standard Apache Hadoop installation package.
TeraSort is widely used to benchmark and tune large Hadoop clusters with hundreds of nodes.
TeraSort works in two steps:
• TeraGen: This generates random data based on the dataset size set by the user. This dataset is used as input data for the sort benchmark.
• TeraSort: TeraSort sorts the input data generated by TeraGen and stores the output data on HDFS.
An optional third step, called TeraValidate, allows validation of the sorted data. This paper does not discuss this optional third step.
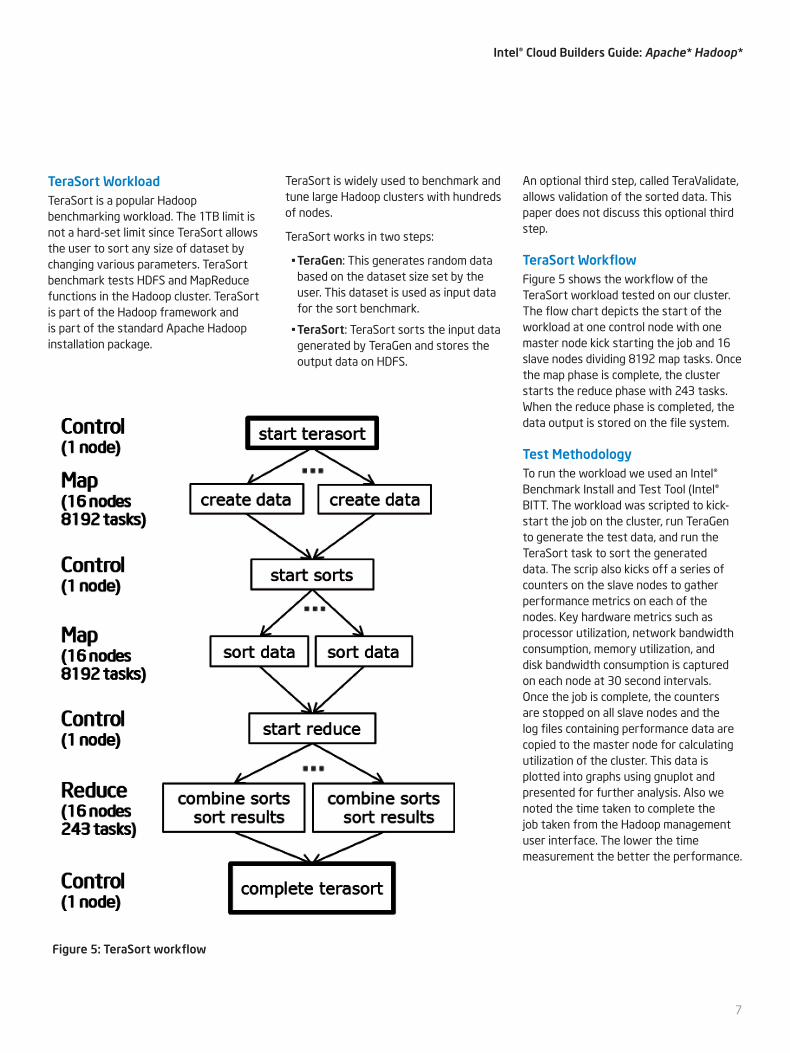
TeraSort WorkflowFigure 5 shows the workflow of the TeraSort workload tested on our cluster. The flow chart depicts the start of the workload at one control node with one master node kick starting the job and 16 slave nodes dividing 8192 map tasks. Once the map phase is complete, the cluster starts the reduce phase with 243 tasks. When the reduce phase is completed, the data output is stored on the file system.
Test MethodologyTo run the workload we used an Intel® Benchmark Install and Test Tool (Intel® BITT. The workload was scripted to kick-start the job on the cluster, run TeraGen to generate the test data, and run the TeraSort task to sort the generated data. The scrip also kicks off a series of counters on the slave nodes to gather performance metrics on each of the nodes. Key hardware metrics such as processor utilization, network bandwidth consumption, memory utilization, and disk bandwidth consumption is captured on each node at 30 second intervals. Once the job is complete, the counters are stopped on all slave nodes and the log files containing performance data are copied to the master node for calculating utilization of the cluster. This data is plotted into graphs using gnuplot and presented for further analysis. Also we noted the time taken to complete the job taken from the Hadoop management user interface. The lower the time measurement the better the performance.
Figure 5: TeraSort workflow
7
Intel® Cloud Builders Guide: Apache* Hadoop*

Intel® Benchmark Install and Test ToolIntel Benchmark Install and Test Tool (Intel BITT) provides tools to install, configure, run, and analyze benchmark programs on small test clusters. The “installCli” tool is used to install tar files on a cluster. “monCli” is used to monitor performance of the cluster nodes and provides options to start monitoring, stop monitoring, and generate CPU, disk I/O, memory, and network performance plots for the nodes and cluster. “hadoopCli” provides an automated Hadoop test environment. The Intel BITT templates enable configurable plot generation. Intel BITT command scripts enable configurable scripts to control monitoring actions. Benchmark configuration is implemented by using XML files. Configurable properties include the location of installation, monitoring directories, monitoring sampling duration, the list of the cluster nodes, and the list of the tar files that need to be installed. Intel BITT is implemented by using Python* and uses gnuplot to generate performance plots. Intel BITT currently runs on Linux*.
Intel® BITT Features
Intel Benchmark Install and Test Tool provides the following tools:
• installCli: Used to install a specified list of tar files to a specified list of nodes
• monCli: Used to monitor performance metrics locally and/or remotely. It can be used to monitor the performance of a cluster. The tool currently supports sar and iostat monitoring tools.
• hadoopCli: Used to install, configure, and test Hadoop clusters.
Intel BITT is implemented in an object oriented fashion. It can be extended to support other performance monitoring tools such as vmstat and mpstat if it is needed. The toolkit includes the following building blocks:
• XML parser: Parses the XML properties including name, value, and description fields. The install and monitor configuration is defined by using XML properties. Tool specific options are passed through command line options.
cmdconfsamplesscriptstemplates
• Log file parser: Log files in the form of tables which contains rows and columns are parsed and CSV files are generated for each column. The column items on each row are separated using whitespace. The column header names are used to create CSV file names.
• Plot generator: gnuplot is used to plot the contents of the CSV files by using templates. The templates define the list of CSV files that are used as inputs to generate the plots. The templates also define labels and titles of the plots.
• Sar monitoring tool
• Iostat monitoring tool
• VTuneTM monitoring tool
• Emon monitoring tool
• installCli is used to install Intel BITT
• monCli is used to monitor local or cluster nodes
• hadoopCli is implemented by using the building blocks defined above and it is used to create and test Hadoop clusters
Configuring the SetupWe installed RHEL 6.0 on all 17 nodes with the default configuration and configured passphraseless SSH access between the nodes to enable them to communicate without having to login with a password every time there is a transaction between them.
1. Install Intel BITT tar file
Cd mkdir bittcp bitt-1.0.tar bittcd bitt/bitt-2.0
The following is the list of subdirectories under Intel BITT home:
8
Intel® Cloud Builders Guide: Apache* Hadoop*

2. Create a release directory under Intel BITT home to copy tar files.
mkdir –p bitt/bitt-1.0/releasecp bitt-1.0.tar bitt/bitt-1.0/release
You can also download and copy the Hadoop tar file to the release directory as well if you are planning to test Hadoop.
cp hadoop-0.21.0.tar.gz ~/bitt/bitt-1.0/release
3. Download jdk and create a tar file from the installed jdk tar.
For example:
mkdir jdk cp jdk-6u23-linux-x64.bin jdkcd jdkchmod +x jdk-6u23-linux-x64.bin ./jdk-6u23-linux-x64.bin rm jdk-6u23-linux-x64.bintar -cvf ~/bitt/bitt-1.0/release/jdk1.6.0_23.tar
4. Download gnuplot and create a tar file from the installed gnuplot tree.
For example:
mkdir myinstallcp gnuplot-4.4.0-rc1.tar myinstallcd myinstall/tar -xvf gnuplot-4.4.0-rc1.tar mkdir –p install/ gnuplot-4.4.0cd gnuplot-4.4.0-rc1./configure --prefix=/home/<user>/myinstall/install/ gnuplot-4.4.0makemake installcd ../installtar -cvf ~/bitt/bitt-1.0/release/gnuplot-4.4.0.tar.
5. Download Python and create a tar file from the installed python tar for your platform.
For example:
mkdir myinstallcp Python-3.1.3.tgz myinstallcd myinstall/tar -xvf Python-3.1.3.tgzmkdir –p install/ Python-3.1.3cd Python-3.1.3./configure --prefix=/home/<user>/myinstall/install/ Python-3.1.3makemake installcd ../installtar -cvf ~/bitt/bitt-1.0/release/ Python-3.1.3.tar .
9
Intel® Cloud Builders Guide: Apache* Hadoop*

6. Run TeraSort.
Run “terasort.sh”. You need to update the corresponding configuration files as described below.
For example:
cd ~/bitt/bitt-1.0/confinstall gnuplot on your client systeminstall python on your client systemMake sure python3 and gnuplot are on your path on the client systemcd ~/bitt/bitt-1.0/scripts./terasort.sh
7. Configuration file edits. All configuration files are found under ~/bitt/bitt-1.0/conf
a. hadoopNodeList: Configuration file which contains cluster nodes. Any addition or removal of nodes from the cluster should register here to be recognized by the load generator tool.
b. hadoopTarList: Configuration file where the executable are installed.
../release/bitt-1.0.tar.gz
../release/Python-3.2.tar.gz
../release/jdk1.6.0_25.tar.gz
../release/hadoop-0.20.2.tar.gz
../release/gnuplot-4.4.3.tar.gz
node1.domain.com
node2.domain.com
node3.domain.com
node4.domain.com
.
.
node17.domain.com
10
Intel® Cloud Builders Guide: Apache* Hadoop*

c. hadoop-env.sh: Main Hadoop environment configuration file.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=
# The maximum amount of heap to use, in MB. Default is 1000.
# export HADOOP_HEAPSIZE=2000
# Extra Java runtime options. Empty by default.
# export HADOOP_OPTS=-server
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTS"
export HADOOP_BALANCER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS"
export HADOOP_JOBTRACKER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_JOBTRACKER_OPTS"
11
Intel® Cloud Builders Guide: Apache* Hadoop*

d. hadoopCloudConf.xml: Custom XML configuration file used to define key parameters on how the test is executed and where the data is stored.
<?xml version="1.0" encoding="UTF-8" ?> <configuration><property> <name>cloudTemplateLoc</name> <value>/home/Hadoop/bitt/bitt-1.0/conf</value> <description>cloud conf template file location</description></property><property> <name>cloudTemplateVars</name> <value>all</value> <description>the list of template variables to copy</description></property><property> <name>jobTrackerPort</name> <value>8021</value> <description>jobtracker port</description></property><property> <name>nameNodePort</name> <value>8020</value> <description>jobtracker port</description></property><property> <name>cloudConfDir</name> <value>/tmp/hadoopConf</value> <description>generated cloud conf file</description></property><property> <name>cloudTmpDir</name> <value>hadoop-${user.name}</value> <description>cloud tmp dir</description></property><property> <name>cloudInstallDir</name> <value>/usr/local/hadoop/install</value> <description>cloud install dir</description></property><property> <name>cloudNodeList</name> <value>/home/Hadoop/bitt/bitt-1.0/conf/hadoopNodeList</value> <description>cluster nodes</description></property><property> <name>monNodeList</name> <value>/home/Hadoop/bitt/bitt-1.0/conf/hadoopMonNodeList</value>
12
Intel® Cloud Builders Guide: Apache* Hadoop*

<description>cluster monitor nodes</description></property><property> <name>cloudTarList</name> <value>/home/Hadoop/bitt/bitt-1.0/conf/hadoopTarList</value> <description>cluster nodes</description></property><property> <name>monInterval</name> <value>30</value> <description>sampling duration</description></property><property> <name>monCount</name> <value>0</value> <description>number of samples</description></property><property> <name>monResults</name> <value>/tmp/monHadRes</value> <description>cloud monitor log files location</description></property><property> <name>monSummary</name> <value>/tmp/monHadSum</value> <description>cloud monitor log files location</description></property><property> <name>monDir</name> <value>/tmp/monHadLoc</value> <description>cloud monitor log files location</description></property><property> <name>gnuCmd</name> <value>/usr/local/hadoop/install/gnuplot-4.4.3/bin/gnuplot</value> <description>none</description></property></configuration>
13
Intel® Cloud Builders Guide: Apache* Hadoop*

e. hdfs-site-template.xml: Hadoop configuration file where HDFS parameters are set. Please note the optimizations values we used to run the test are shown in bold font.
<?xml version="1.0" encoding="UTF-8" ?>
<!-- Put site-specific property overrides in this file. --><configuration>
<property> <name>dfs.replication</name> <value>3</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description></property>
<property> <name>dfs.datanode.max.xcievers</name> <value>655360</value> <description>number of files Hadoop serves at one time</description></property>
<property> <name>dfs.data.dir</name>
<value>/mnt/disk1/hdfs/data,/mnt/disk2/hdfs/data,/mnt/disk3/hdfs/data,/mnt/disk4/hdfs/data,/mnt/disk5/hdfs/data,/mnt/disk6/hdfs/data,/mnt/disk7/hdfs/data,/mnt/disk8/hdfs/data,/mnt/disk9/hdfs/data,/mnt/disk10/hdfs/data,/mnt/disk11/hdfs/data,/mnt/disk12/hdfs/data</value> <description>Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored. </description></property>
<property> <name>dfs.block.size</name> <value>134217728</value> <description>The default block size for new files.</description></property>
<property> <name>io.file.buffer.size</name> <value>131072</value> <description> </description></property>
14
Intel® Cloud Builders Guide: Apache* Hadoop*

<property> <name>ipc.server.tcpnodelay</name> <value>true</value> <description> </description></property>
<property> <name>ipc.client.tcpnodelay</name> <value>true</value> <description> </description></property>
<property> <name>dfs.namenode.handler.count</name> <value>40</value> <description> </description></property>
<property> <name>io.sort.factor</name> <value>100</value> <description> </description></property>
<property> <name>io.sort.mb</name> <value>220</value> <description> </description></property>
</configuration>
15
Intel® Cloud Builders Guide: Apache* Hadoop*

f. mapred-site-template.xml: Hadoop configuration file which defines key MapReduce parameters. Values used in our testing are highlighted in bold font.
<?xml version="1.0" encoding="UTF-8" ?>
<!-- Put site-specific property overrides in this file. --><configuration>
<property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>24</value> <description>The maximum number of map tasks that will be run simultaneously by a task tracker. </description></property>
<property> <name>io.sort.record.percent</name> <value>0.3</value> <description>added as per ssg reco </description></property>
<property> <name>io.sort.spill.percent</name> <value>0.9</value> <description>addded as per ssg reco </description></property>
<property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>12</value> <description>The maximum number of reduce tasks that will be run simultaneously by a task tracker. </description></property>
<property> <name>mapred.reduce.tasks</name> <value>64</value> <description>The default number of reduce tasks per job. Typically set to a prime close to the number of available hosts. Ignored when mapred.job.tracker is "local". Assume 10 nodes, 10*2 - 2 </description></property>
<property> <name>mapred.local.dir</name>
<value>/mnt/disk1/hdfs/mapred,/mnt/disk2/hdfs/mapred,/mnt/disk3/hdfs/mapred,/mnt/disk4/hdfs/mapred,/mnt/disk5/hdfs/mapred,/mnt/disk6/hdfs/mapred,/mnt/disk7/hdfs/mapred,/mnt/disk8/hdfs/mapred,/mnt/disk9/hdfs/mapred,/mnt/disk10/hdfs/mapred,/mnt/disk11/hdfs/mapred,/mnt/disk12/hdfs/
16
Intel® Cloud Builders Guide: Apache* Hadoop*

mapred</value> <description>The local directory where MapReduce stores intermediate data files. May be a comma-separated list of directories on different devices in order to spread disk i/o. Directories that do not exist are ignored. </description></property>
<property> <name>mapred.child.java.opts</name> <value>-Xmx2048m -Djava.net.preferIPv4Stack=true</value> <description>Java opts for the task tracker child processes. The following symbol, if present, will be interpolated: @taskid@ is replaced by current TaskID. Any other occurrences of '@' will go unchanged. For example, to enable verbose gc logging to a file named for the taskid in /tmp and to set the heap maximum to be a gigabyte, pass a 'value' of: -Xmx1024m -verbose:gc -Xloggc:/tmp/@[email protected] The configuration variable mapred.child.ulimit can be used to control the maximum virtual memory of the child processes. </description></property>
<property> <name>mapred.output.compress</name> <value>false</value> <description>Should the job outputs be compressed? </description></property>
<property> <name>mapred.compress.map.output</name> <value>false</value> <description>Should the outputs of the maps be compressed before being sent across the network. Uses SequenceFile compression. </description></property>
<property> <name>mapred.output.compression.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>If the job outputs are compressed, how should they be compressed? </description></property>
<property> <name>mapred.map.output.compression.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>If the job outputs are compressed, how should they be compressed? </description></property>
17
Intel® Cloud Builders Guide: Apache* Hadoop*

<property> <name>mapred.map.tasks.speculative.execution</name> <value>true</value> <description> </description></property>
<property> <name>mapred.reduce.tasks.speculative.execution</name> <value>true</value> <description> </description></property>
<property> <name>mapred.job.reuse.jvm.num.tasks</name> <value>1</value> <description> </description></property>
<property> <name>mapred.reduce.parallel.copies</name> <value>20</value> <description> </description></property>
<property> <name>mapred.min.split.size</name> <value>65536</value> <description> </description></property>
<property> <name>mapred.reduce.copy.backoff</name> <value>5</value> <description> </description></property>
<property> <name>mapred.job.shuffle.merge.percent</name> <value>0.7</value> <description> </description></property>
<property> <name>mapred.job.shuffle.input.buffer.percent</name> <value>0.66</value> <description> </description></property>
<property> <name>mapred.job.reduce.input.buffer.percent</name> <value>0.90</value> <description> </description></property></configuration>
18
Intel® Cloud Builders Guide: Apache* Hadoop*

g. hadoop-terasort.xml: Intel BITT configuration file from which the parameters are read before the test runs. Parameters in this configuration file override values in the other configuration files mentioned above. This configuration file helps to quickly change the parameter values for different test runs without editing individual configuration files.
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<property> <name>mapred.map.tasks</name> <value>8192</value> <description> Total Map task number </description></property>
<property> <name>mapred.reduce.tasks</name> <value>243</value> <description> Total Reduce task number </description></property>
<property> <name>dfs.replication</name> <value>3</value> <description> Number of copies to replicate </description></property>
<property> <name>mapred.compress.map.output</name> <value>true</value> <description> compress map output </description></property>
<property> <name>mapred.job.shuffle.input.buffer.percent</name> <value>0.66</value> <description> none </description></property>
<property> <name>dataSetSizeSmall</name> <value>100000000</value> <description> Total Record Number about 1T data. 1 record has 100 bytes </description></property>
<property> <name>dataSetSize</name> <value>10000000000</value> <description> Total Record Number about 1T data. 1 record has 100 bytes </description></property>
19
Intel® Cloud Builders Guide: Apache* Hadoop*

<property> <name>dataSetName</name> <value>tera</value> <description> none </description></property>
<property> <name>outputDataName</name> <value>tera-sort2</value> <description> none </description></property>
<property> <name>jarFile</name> <value>hadoop-0.20.2-examples.jar</value> <description> none </description></property>
</configuration>
20
Intel® Cloud Builders Guide: Apache* Hadoop*

Running TeraSortTeraSort can be started by running terasort.sh. The script runs various commands involved in starting the test, starting performance counters, ending the test, and gathering performance counter data for analysis. Below is the list of commands executed when the script is running, and a brief explanation on what the command does.
#!/usr/bin/env bash
###########################################################
#Intel Benchmark Install and Test Tool (BITT) Use Cases
#Typical sequence for hadoop terasort benchmark:
###########################################################
echo "START: terasort benchmark..............................."
date
# Stop any current running test on the cluster.
../scripts/hadoopCli -a stop -c ../conf/hadoopCloudConf.xml
# Kill Java* processes on the nodes
./runkill.sh
# Install fresh copy of executables on the slave nodes.
../scripts/hadoopCli -a install -c ../conf/hadoopCloudConf.xml
# Format the HDFS to store the data
../scripts/hadoopCli -a format -c ../conf/hadoopCloudConf.xml
# Start Java processes on all slave nodes.
../scripts/hadoopCli -a start -c ../conf/hadoopCloudConf.xml
# 2 minutes delay to get the processes started on the slave nodes.
sleep 120
# Generate 1TB of data which will be used for sorting.
../scripts/hadoopCli -a data -c ../conf/hadoopCloudConf.xml
# Create monitoring directories.
../scripts/monCli -r clean -c ../conf/hadoopCloudConf.xml
# Start iostat utility to monitor disk usage on the slave nodes.
../scripts/monCli -m iostat -a run -c ../conf/hadoopCloudConf.xml -s run_iostat.sh
21
Intel® Cloud Builders Guide: Apache* Hadoop*

# Start sar utility on all the slave nodes to monitor CPU, network, and memory utilization
../scripts/monCli -m sar -a run -c ../conf/hadoopCloudConf.xml -s run_sar2.sh
# Start the sort activity on the 1TB data generated in the earlier step.
../scripts/hadoopCli -a run -c ../conf/hadoopCloudConf.xml
# Stop sar monitoring utility.
../scripts/monCli -m sar -a kill -s run_sar_kill.sh -c ../conf/hadoopCloudConf.xml
# Stop sar monitoring utility.
../scripts/monCli -m sar -a kill -s run_sar_kill.sh -c ../conf/hadoopCloudConf.xml
# Stop iostat utility.
../scripts/monCli -m iostat -a kill -s run_iostat_kill.sh -c ../conf/hadoopCloudConf.xml
# Convert iostat generated data to CSV file format.
../scripts/monCli -m iostat -a csv -c ../conf/hadoopCloudConf.xml
# Convert data generated from sar utility to CSV format.
../scripts/monCli -m sar -a csv -c ../conf/hadoopCloudConf.xml -s run_sar_gen.sh
# Using gnuplot to generate image containing graph of iostat data.
../scripts/monCli -m iostat -a plot -t iostat -c ../conf/hadoopCloudConf.xml
# Using gnuplot to generate image containing CPU graph from sar data.
../scripts/monCli -m sar -a plot -t cpu -c ../conf/hadoopCloudConf.xml
# Using gnuplot to generate image containing memory graph from sar data.
../scripts/monCli -m sar -a plot -t mem -c ../conf/hadoopCloudConf.xml
# Using gnuplot to generate image containing network graph from sar data.
../scripts/monCli -m sar -a plot -t nw -c ../conf/hadoopCloudConf.xml
# Archive logfiles on all the slave nodes.
../scripts/monCli -r tar -c ../conf/hadoopCloudConf.xml
22
Intel® Cloud Builders Guide: Apache* Hadoop*

# Copy archived logfiles from slave nodes to master node.
../scripts/monCli -r collect -c ../conf/hadoopCloudConf.xml
# Stop running processes on slave nodes.
../scripts/hadoopCli -a stop -c ../conf/hadoopCloudConf.xml
# Creates folder called cluster in head node /tmp/monHadSum.
../scripts/monCli -r cluster -c ../conf/hadoopCloudConf.xml
# Calculate average CPU utilization of the cluster.
../scripts/monCli -r average -m sar -t cpu -c ../conf/hadoopCloudConf.xml
# Calculate average memory throughput of the cluster.
../scripts/monCli -r throughput -m sar -t mem -c ../conf/hadoopCloudConf.xml
# Calculate average network utilization for the cluster.
../scripts/monCli -r throughput -m sar -t nw -c ../conf/hadoopCloudConf.xml
# Calculate average disk throughput of the cluster.
../scripts/monCli -r throughput -m iostat -t iostat -c ../conf/hadoopCloudConf.xml
# Copy contents of hadoopconf folder.
cp -r /tmp/hadoopConf /tmp/monHadSum
# Copy contents of hadoopconf folder.
cp -r /tmp/hadoopConf /tmp/monHadSum
# Copy performance data gathering templates.
cp -r ../templates /tmp/monHadSum
# Create archive with all the logfiles and graph images.
tar -cvf /tmp/baselineMapRtera.tar /tmp/monHadSum
# End script.
echo "END: terasort benchmark..............................."
date
23
Intel® Cloud Builders Guide: Apache* Hadoop*
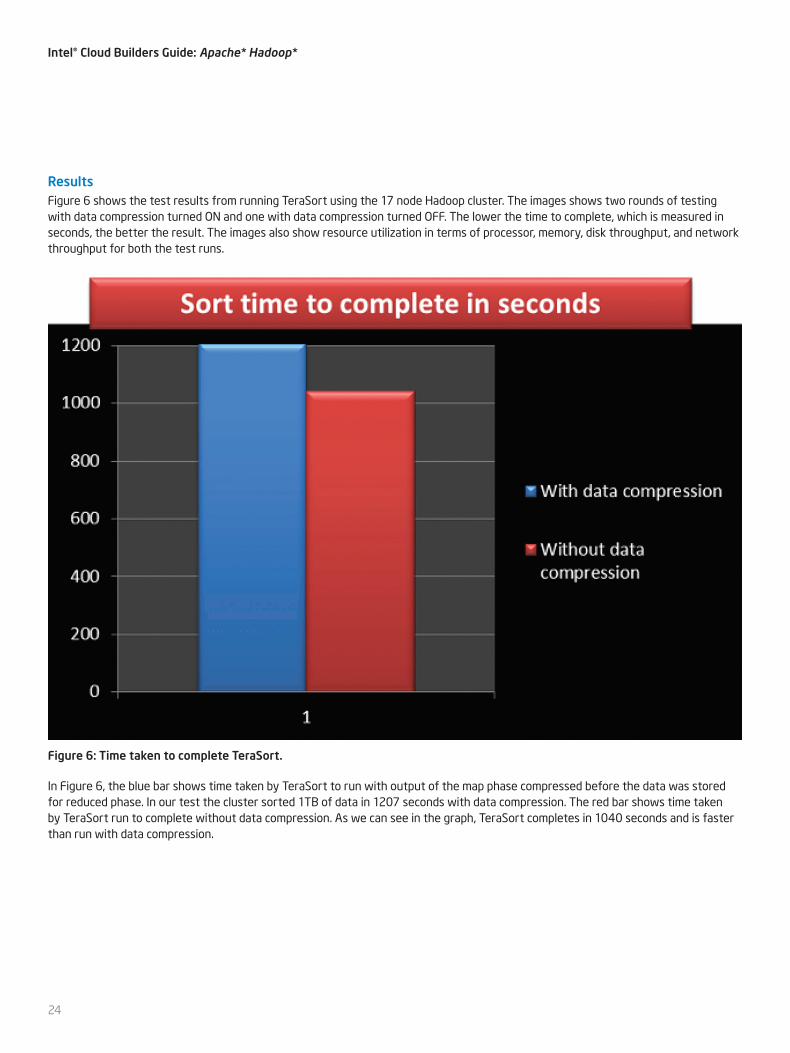
ResultsFigure 6 shows the test results from running TeraSort using the 17 node Hadoop cluster. The images shows two rounds of testing with data compression turned ON and one with data compression turned OFF. The lower the time to complete, which is measured in seconds, the better the result. The images also show resource utilization in terms of processor, memory, disk throughput, and network throughput for both the test runs.
Figure 6: Time taken to complete TeraSort.
In Figure 6, the blue bar shows time taken by TeraSort to run with output of the map phase compressed before the data was stored for reduced phase. In our test the cluster sorted 1TB of data in 1207 seconds with data compression. The red bar shows time taken by TeraSort run to complete without data compression. As we can see in the graph, TeraSort completes in 1040 seconds and is faster than run with data compression.
24
Intel® Cloud Builders Guide: Apache* Hadoop*
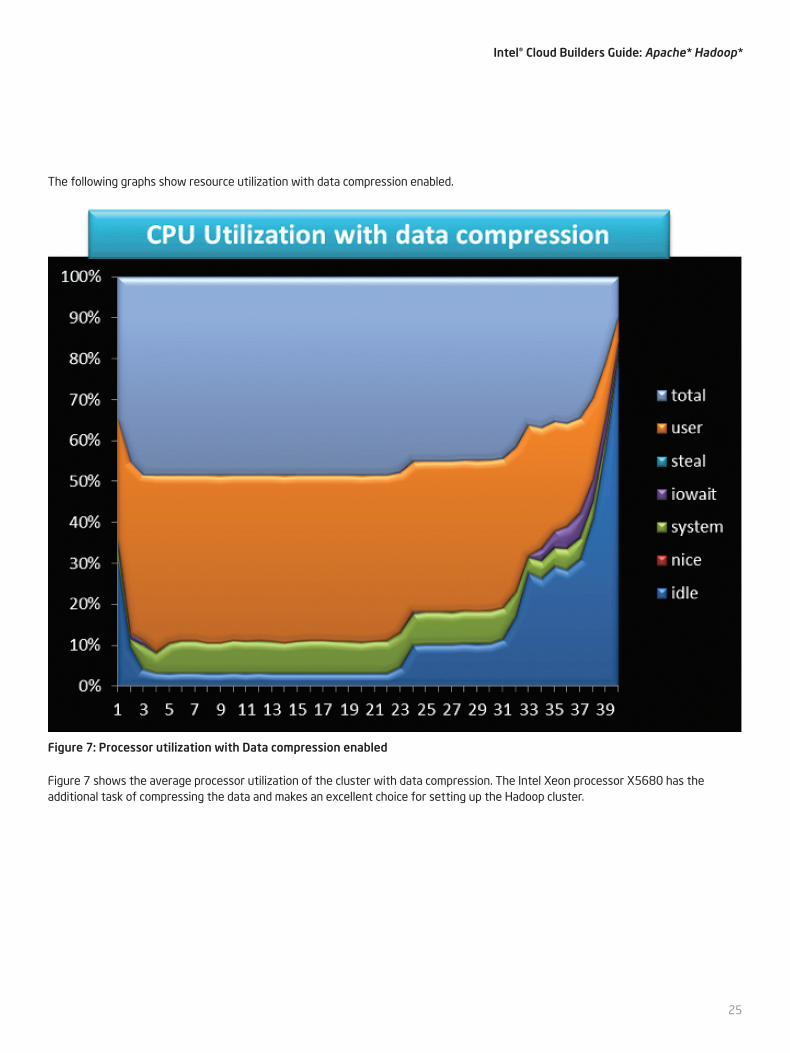
The following graphs show resource utilization with data compression enabled.
Figure 7: Processor utilization with Data compression enabled
Figure 7 shows the average processor utilization of the cluster with data compression. The Intel Xeon processor X5680 has the additional task of compressing the data and makes an excellent choice for setting up the Hadoop cluster.
25
Intel® Cloud Builders Guide: Apache* Hadoop*
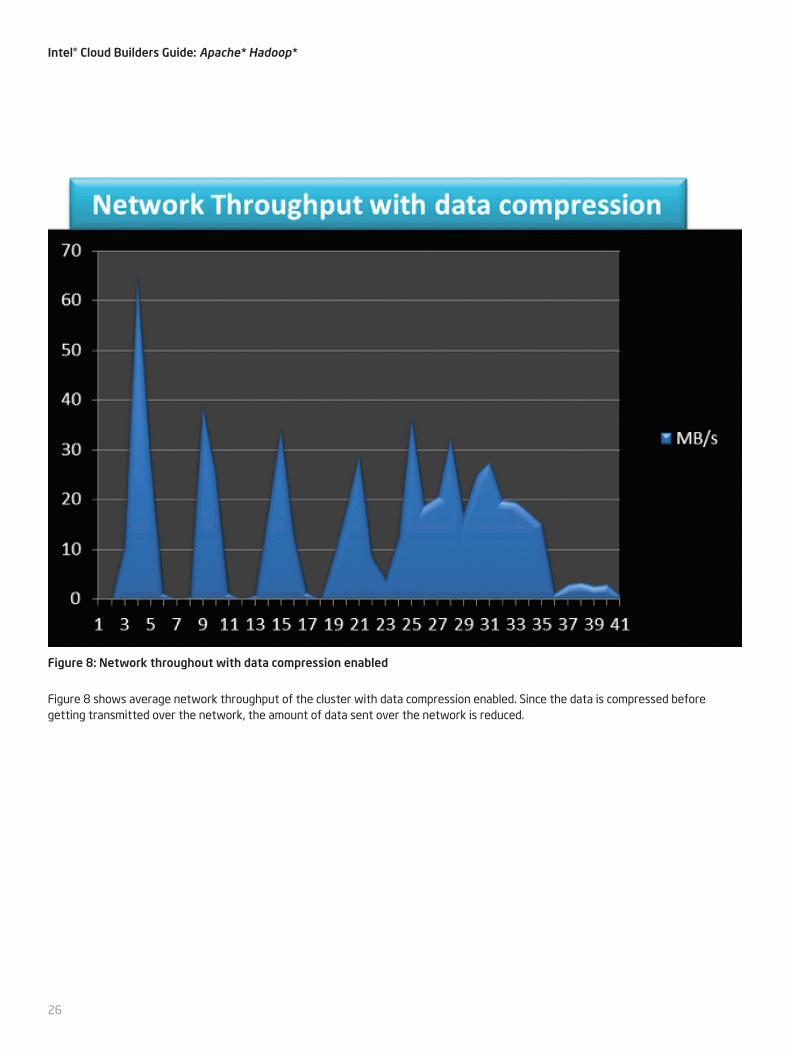
Figure 8 shows average network throughput of the cluster with data compression enabled. Since the data is compressed before getting transmitted over the network, the amount of data sent over the network is reduced.
Figure 8: Network throughout with data compression enabled
26
Intel® Cloud Builders Guide: Apache* Hadoop*
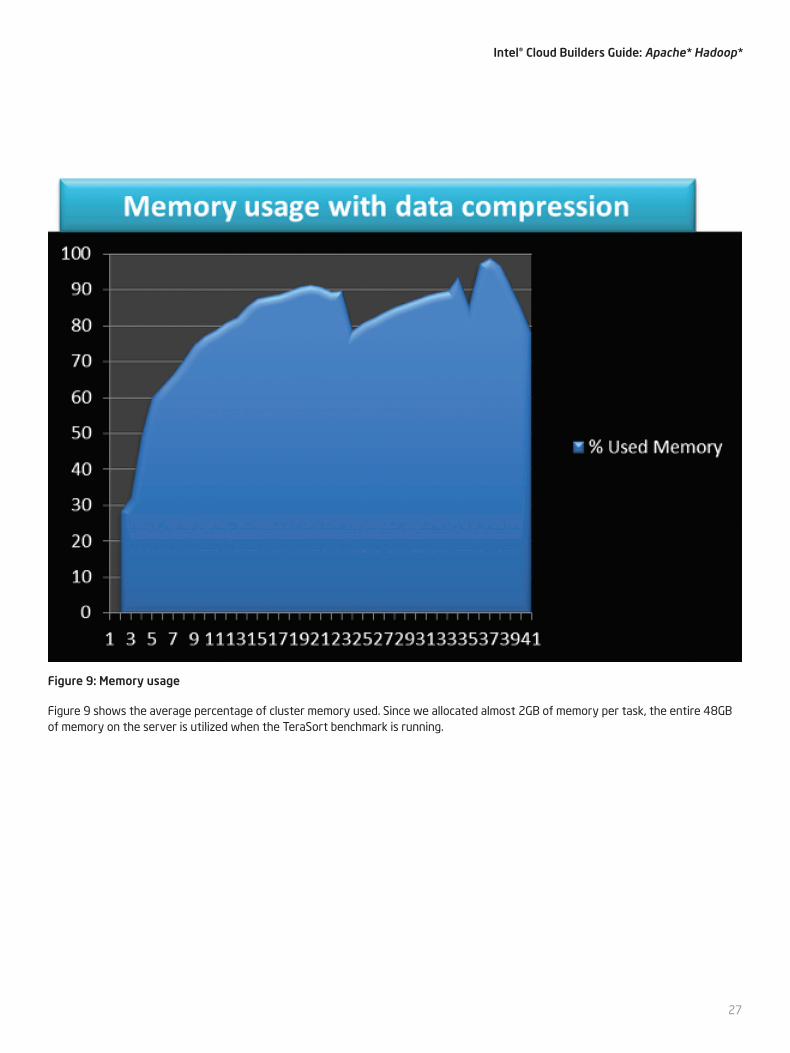
Figure 9 shows the average percentage of cluster memory used. Since we allocated almost 2GB of memory per task, the entire 48GB of memory on the server is utilized when the TeraSort benchmark is running.
Figure 9: Memory usage
27
Intel® Cloud Builders Guide: Apache* Hadoop*

Figure 10 shows the average disk throughput of the cluster. Since the data is compressed, the writes are minimal during the map phase and peak to nearly 600Mb/s when the sorted data is committed to the disk.
Figure 10: Disk throughput with data compression enabled
28
Intel® Cloud Builders Guide: Apache* Hadoop*
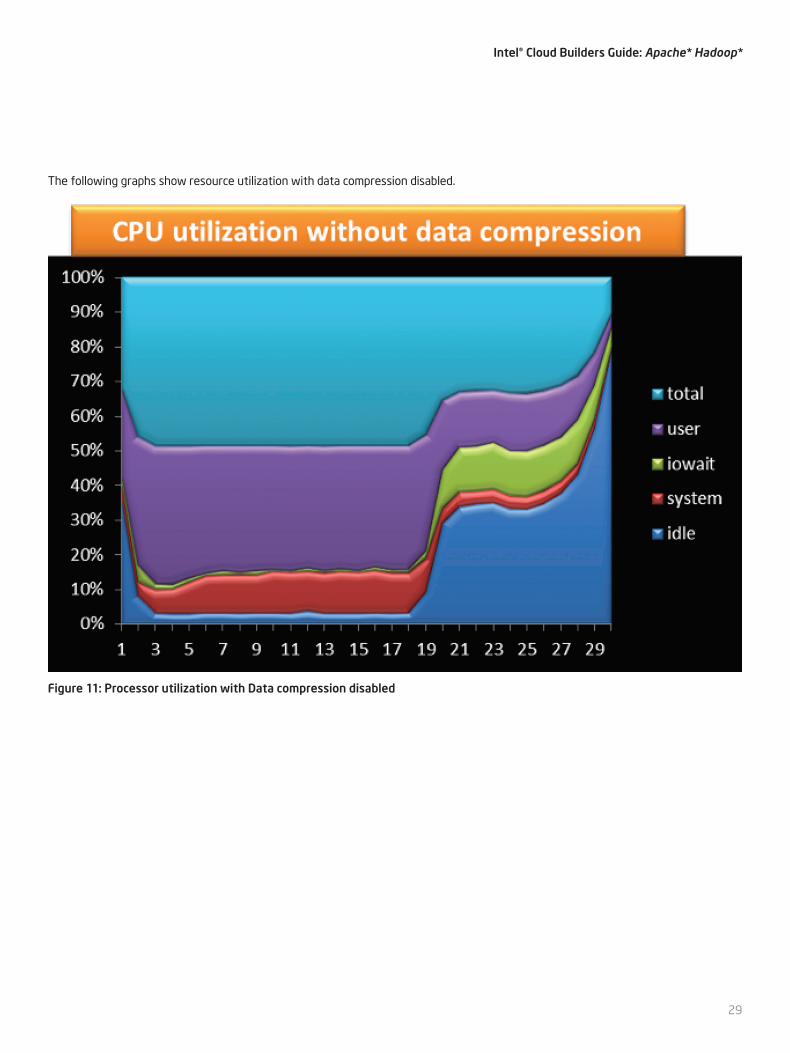
The following graphs show resource utilization with data compression disabled.
Figure 11: Processor utilization with Data compression disabled
29
Intel® Cloud Builders Guide: Apache* Hadoop*
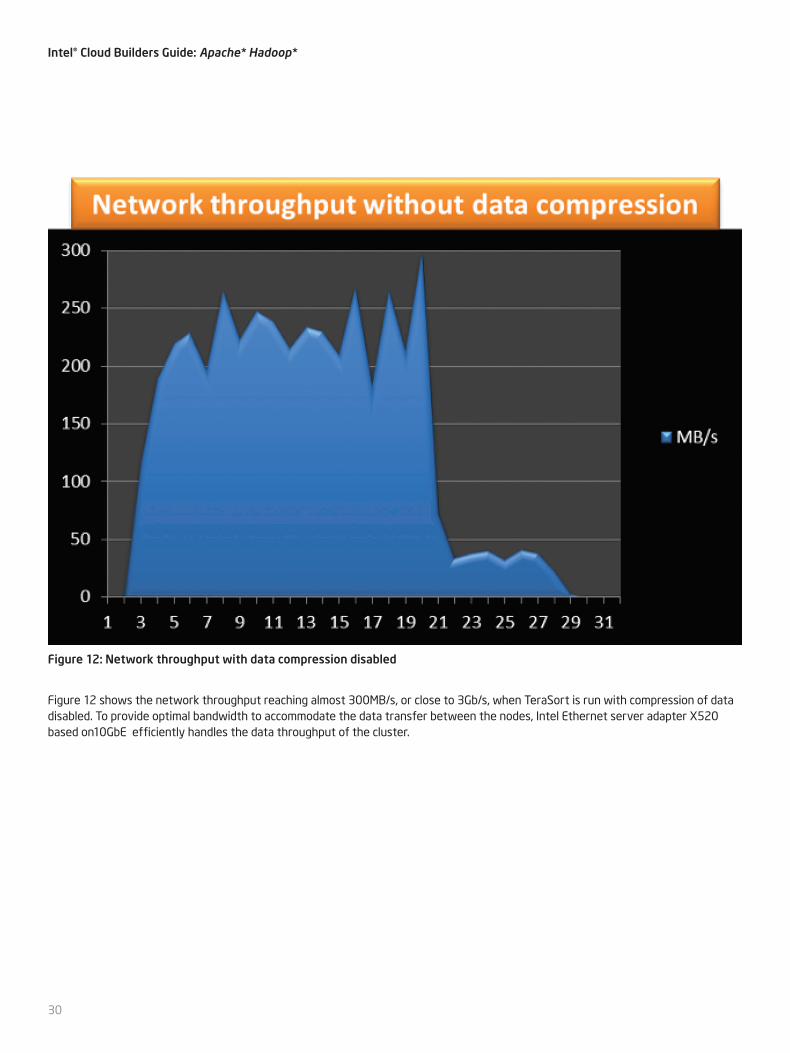
Figure 12: Network throughput with data compression disabled
Figure 12 shows the network throughput reaching almost 300MB/s, or close to 3Gb/s, when TeraSort is run with compression of data disabled. To provide optimal bandwidth to accommodate the data transfer between the nodes, Intel Ethernet server adapter X520 based on10GbE efficiently handles the data throughput of the cluster.
30
Intel® Cloud Builders Guide: Apache* Hadoop*
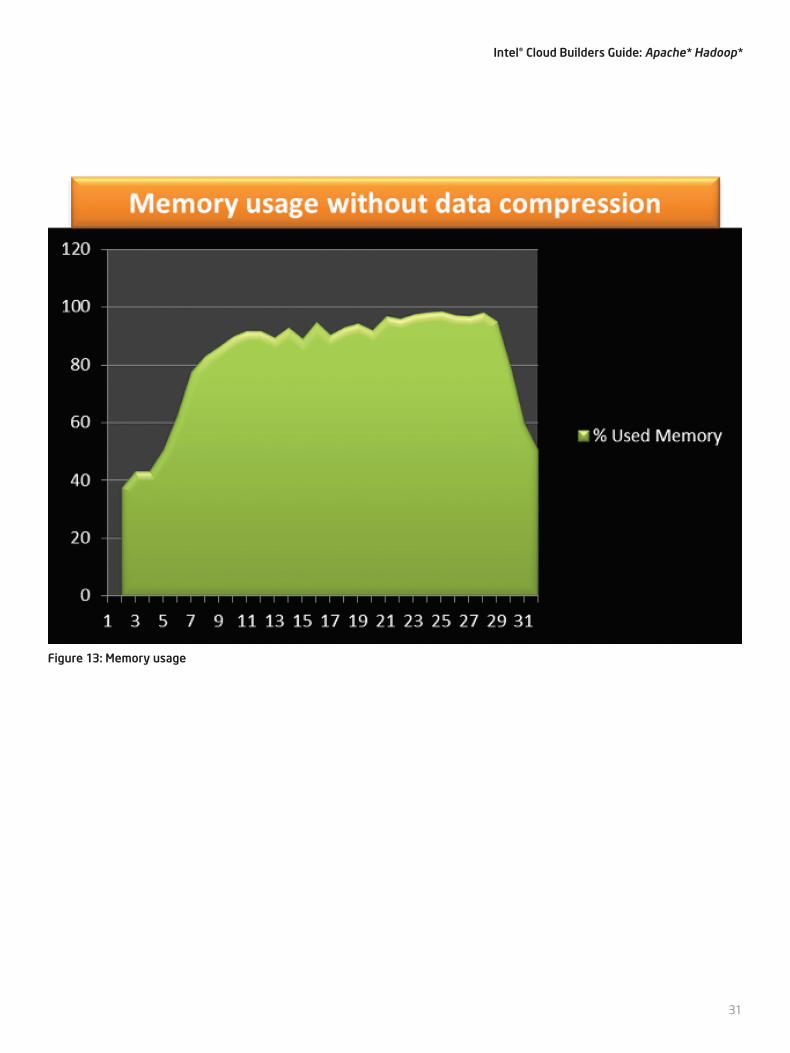
Figure 13: Memory usage
31
Intel® Cloud Builders Guide: Apache* Hadoop*
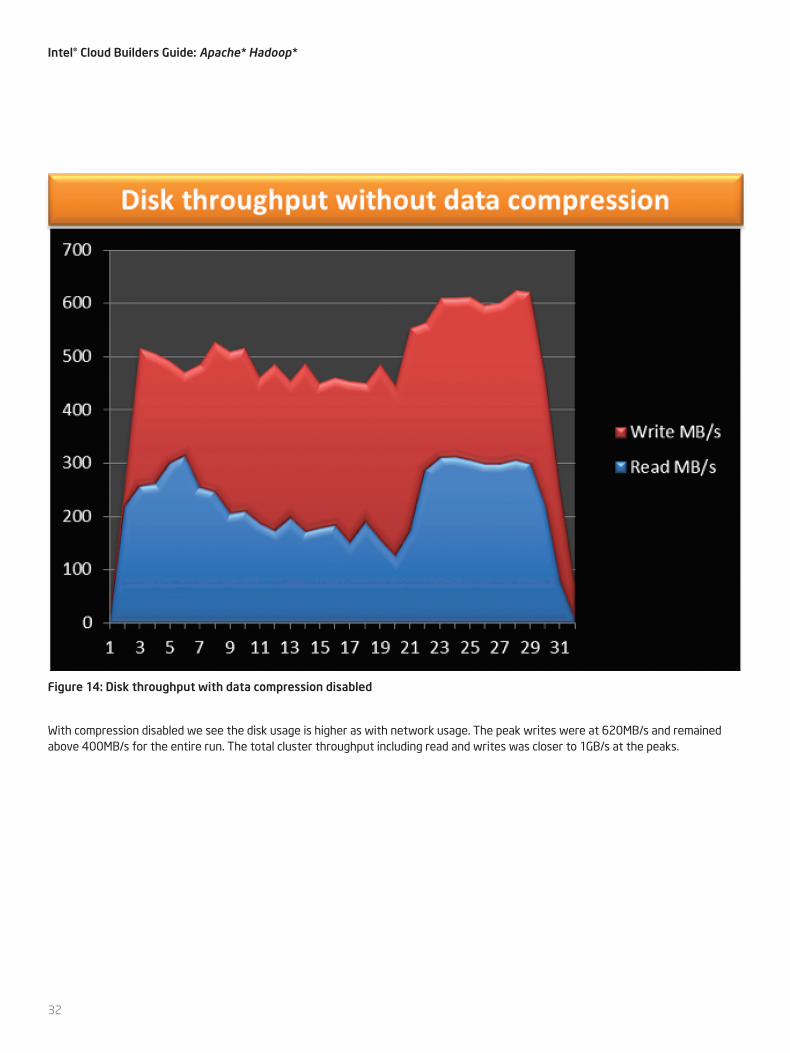
Figure 14: Disk throughput with data compression disabled
With compression disabled we see the disk usage is higher as with network usage. The peak writes were at 620MB/s and remained above 400MB/s for the entire run. The total cluster throughput including read and writes was closer to 1GB/s at the peaks.
32
Intel® Cloud Builders Guide: Apache* Hadoop*

ConclusionHadoop clusters benefit a great deal from servers based on Intel Xeon processor 5680; the dual socket servers are optimal for any Hadoop deployment ranging from a few nodes to hundreds of nodes. In our test runs we were able to put the cluster to its maximum utilization. With the cluster being 100 percent utilized, jobs complete faster, making way for other job sets to run on the cluster. With data centers aiming to get the most out of performance per watt, having an energy efficient Intel Xeon processor 5600 series provides cost benefits on a per node basis. In distributed workloads it is key to have high throughput network connections to handle workloads with large datasets. In the test, Intel Ethernet server adapters X520-DA2 based on 10GbE were able to achieve data rates of 3Gb/s during the workload execution. While compressing the data has advantages of substantial reduction in data transfer over the network, the time to complete increases compared to test runs without data being compressed. System administrators and application developers have to make the decision whether to enable data compression based on their specific requirements. Intel has published a set of guidelines on tuning Hadoop clusters which can be found at http://software.intel.com/file/31124. Using LZO based compression codecs may alleviate some of the bottlenecks found with default Zlib compression codecs.
33
Intel® Cloud Builders Guide: Apache* Hadoop*

Disclaimers∆ Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor family, not across different processor families. See www.intel.com/
products/processor_number for details.INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROP-
ERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR.
Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The infor-mation here is subject to change without notice. Do not finalize a design with this information.
The products described in this document may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized er-rata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. Copies of documents which
have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1-800-548-4725, or by visiting Intel’s Web site at www.intel.com.Copyright © 2012 Intel Corporation. All rights reserved. Intel, the Intel logo, Xeon, Xeon inside, and Intel Intelligent Power Node Manager are trademarks of IntelCorporation in the U.S. and other countries. *Other names and brands may be claimed as the property of others.
For more information:
http://hadoop.apache.org/common/docs/r0.20.1/
http://software.intel.com/file/31124/
http://software.intel.com/en-us/articles/intel-benchmark-install-and-test-tool-intel-bitt-tools/
www.intel.com/cloudbuilders
Intel® Cloud Builders Guide: Apache* Hadoop*















![Automated Hadoop cluster deployment on clouds with … · Automated Hadoop cluster deployment on clouds with Occopus Enikő Nagy József Kovács Róbert Lovas [robert.lovas@sztaki.mta.hu]](https://static.fdocuments.us/doc/165x107/5afa1b407f8b9a19548d843c/automated-hadoop-cluster-deployment-on-clouds-with-hadoop-cluster-deployment.jpg)


