
Insight Data Engineering - Week 4 - Andrew Mo
19
TRACKING LIVE WIKIPEDIA CHANGES [email protected] Insight Data Engineering Week 4 - January 2015 WIKIWATCH . ANDREWMO . COM
-
Upload
andrew-mo -
Category
Technology
-
view
236 -
download
1
Transcript of Insight Data Engineering - Week 4 - Andrew Mo

TRACKING LIVE WIKIPEDIA [email protected]
Insight Data Engineering Week 4 - January 2015
WIKIWATCH . ANDREWMO . COM

MOTIVATION• Raw dumps of Wikipedia data are available for analysis on a monthly basis, but…
What about changes between these intervals?
• Data Collection:Live edits for Wikimedia projects are broadcast to nearly 882 IRC channels
• Goals: Collect, filter, format, transform and produce information from live edit data
nowdata datawhy wait?what happened?

DATA PIPELINE ENGINEERINGCapture + Fusion + Analysis
Kafka Storm MySQL APIIRC
MapReduce HBaseHDFS

CAPTUREUp to 882 Simultaneous Channels
~660 events/min avg across all channels

INGESTKafka + Hadoop
Kafka#de logBot
Topic
Topic
Topic#fr
#en
HDFS

–Andrew Mo
We tried Spark Streaming.Scala, it’s not you - It’s me.
Next sprint, maybe?

STREAM PROCESSING
Multiple Topologies(10 sec, 1min, 10 min, 1 hr)
Multiple Metrics(events, size, new pages, topics, users)
Python + Storm (Pyleus)MySQL

API ACCESSTime Series Summary Metrics
for Multiple Windows
New Pages
Detailed User Activity
Detailed Topic Activity
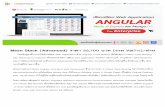
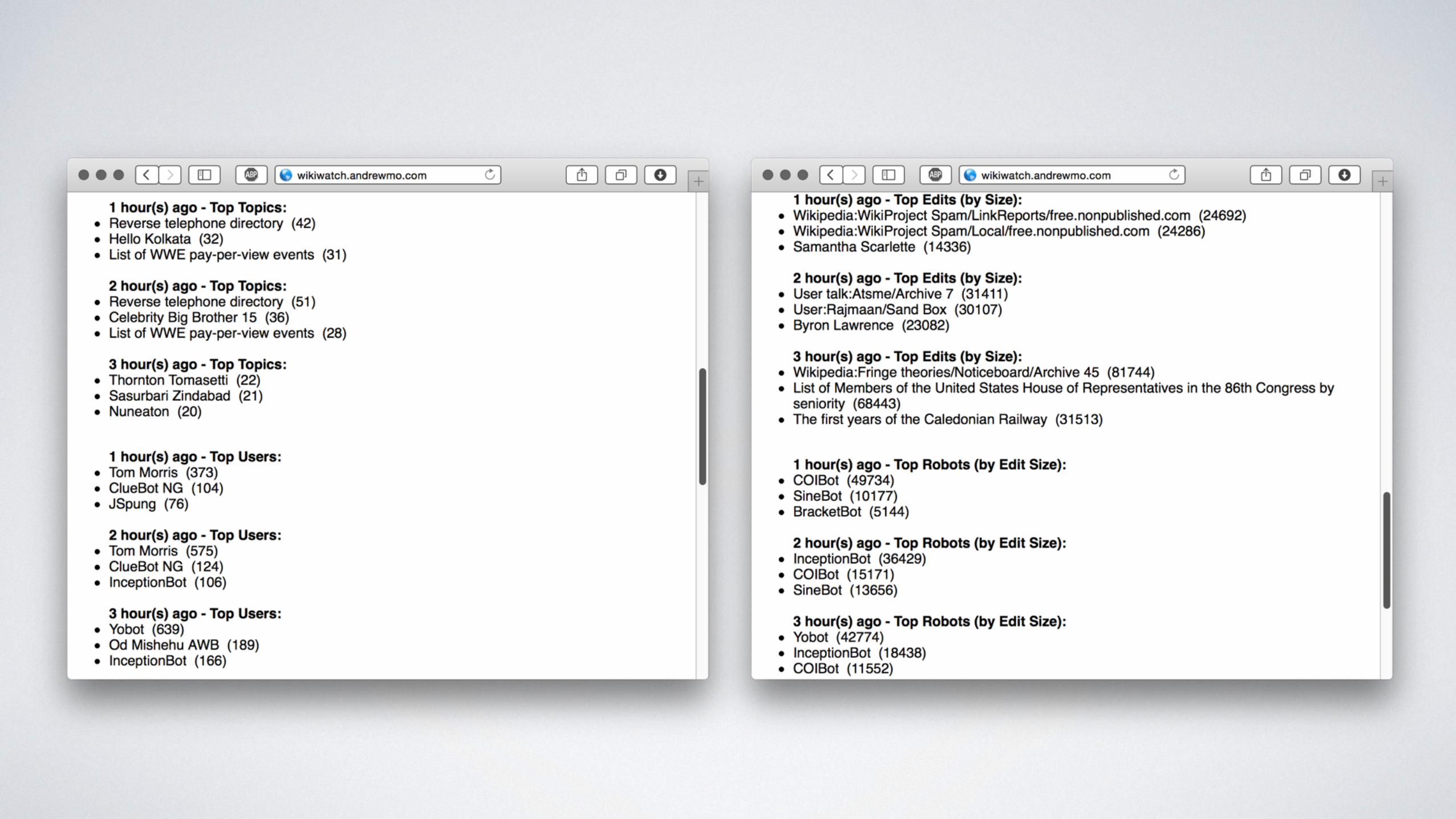
Top Topics, Top Users, Top Bots, etc

Thanks
Apache Software FoundationWikimedia FoundationInsight Data Science
LinkedIn (Kafka)Twitter (Storm)
Yelp (Pyleus)

ABOUT MOA Project Manager that Writes Code !
Worked at RAND Corporation Booz Allen Hamilton
Studied at Pardee RAND Graduate School UC San Diego - Electrical Engineering
Alphabet SoupPMP, PMI-ACP, CISSP, ISSEP, CSEP, CSEP-ACQ [email protected] GitHub: https://github.com/moandcompanyLinkedIn: http://linkedin.com/in/andrewmo

BONUS CHARTS

BATCHPROCESSING
Map Reduce+Pig
HiveMR Job
Hadoop Streaming…
Parser
Log
Pig Hive
Spark
HBase

DEDUPE IN THE BATCH LAYER
• Parse all files and send to a Pig batch process
• All log files go into a directory consumed by pig (‘LOAD’)
• Apply ‘DISTINCT’ criteria to all rows in LOAD before computing metrics
HDFS#en logBot
#en
#en
logBot
logBot

FIREHOSEMultiplex all sensors to a firehose topic
Kafka#de logBot Omnichannel
#fr
#en
logBot
logBot

VELOCITY AND OUR NEXT SPRINTSprint 1 (MVP Development)
18 Jan - 31 Jan 2015
Address the need + Simplify
API-query elicitation and discovery
Novel feature focus: Realtime
Maximize common-code (Python)
Sprint 2 (MVP Validation)
Context Enrichment Features
API enhancement
Batch Integration
NoSQL Optimization
Preempt Technical Debt - Refactoring
Velocity Chart

TECHNOLOGY TO EVALUATE• Presto
• Luigi
• Samza
• Hive + Tez
• Kafka on YARN (KOYA)
• Kafka Security (Authentication)
• Spark + Spark Streaming (1.2+ Python)

FAILURE MODES AND FAULT TOLERANCE
• Implement Sensor Diversity (need de-dupe/false replay rejection)
• The system cannot collect data if the IRC network is down
• Define loss tolerance thresholds
• Use logs as the ultimate source of truth






![[Andrew J. Hanson] Visualizing Quaternions (the Mo(BookZZ.org)](https://static.fdocuments.us/doc/165x107/55cf85ad550346484b906bb7/andrew-j-hanson-visualizing-quaternions-the-mobookzzorg.jpg)











