
Insight Data Engineering project
13
Crawling for names A search through 150 terabytes of data
-
Upload
hoa-nguyen -
Category
Engineering
-
view
358 -
download
0
Transcript of Insight Data Engineering project

Crawling for namesA search through 150 terabytes of data

Common Crawl
Large repository of archival web page data on the Internet
November 2015 crawl has more than 150 terabytes of data (150,000,000,000,000 bytes, 1.2 billion URLs)
Used to broadly gauge brand awareness, name recognition?
➔ Cons: False positives (e.g., same name, different person)➔ Pros: Dataset is large and fairly complete

Data pipeline
Common Crawl on

Goals
Functional:
● Parse through data, counting websites that mention Donald Trump, Ted Cruz, Hillary Clinton, Bernie Sanders
Engineering:
● Do this as fast and efficiently as possible on the entire corpus● Learn Scala

Challenges
● 35,700 zipped text files of modest sizes on Amazon S3
● Each file on average holds data from 34,000 URIs
● Data from one URI (one record) spans multiple lines
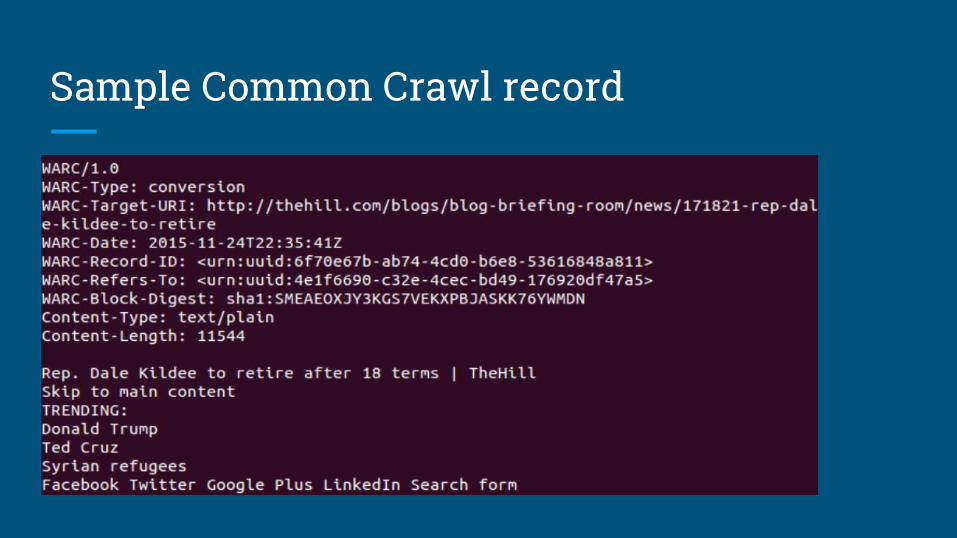
Sample Common Crawl record

Parsing Common Crawl text file
Header / URI
Find these names

Coding challenges
1. Spark prefers to ingest files in which one record spans single line
➔ sc.textFile(filename)
2. For multi-line records, must use
➔ config.set(“textinputformat.record.delimiter”, “WARC-Target-URI: “)➔ ingestMe = sc.newAPIHadoopFile(filename, classOf[TextInputFormat],
classOf[LongWritable], classOf[Text], config)
First method allows bulk loading of files; second method limited to single file at one time

How much time?
Original estimate: 21 days
Helpful Not so helpful✔ Eliminate debug printlns
✔ Limit “filter”, “map” functions
✔✔ Union RDD (data sets) triggered distributed computing
❗ Pool database calls (Must use sparingly)
❌ Multiple Spark-Submit jobs (Held promise but resource
intensive; crashed JVM)
Revised estimate: 18-35 hours

Results: How the candidates stack up
Check out which candidate got the most mentions:
http://namecrawler.xyz

About me
Most recently news reporter.
Background in computer science
Avid cook, baker

What else would have helped boost speed
● Amp up cluster computing power○ Upgrade from m4large (8GB RAM) to r3large (15.25GB) or r3xlarge (30.5GB)
● Concatenate files prior to processing○ Eliminates having to manually join datasets
○ Pros: Java libraries exist to do so
○ Cons: Must make room for 150 terabytes of files
● Split batch processing into multiple jobs

Optimizations: Union data
// Grab file off Amazon's S3val hdFile = sc.newAPIHadoopFile(fullCrawlName, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], localConfig)
// Hold on to file until there are enough for a triohdFiles(i-1) = hdFile
if (i % 3 == 0) { // Act only on batches of three RDDsval hdFile = hdFiles(i-3).union(hdFiles(i-2).union(hdFiles(i-1)))
// Send the three-large RDD for saving
saveCrawlData(crawlFileID, hdFile)
// Reset batch counter i=0}


















