

- · PDF file Connecting Hadoop with Oracle Database Sharon Stephen ... Oracle Database, and...
35
Transcript of - · PDF file Connecting Hadoop with Oracle Database Sharon Stephen ... Oracle Database, and...


<Insert Picture Here>
Connecting Hadoop with Oracle Database
Sharon Stephen Senior Curriculum Developer
Server Technologies Curriculum

The following is intended to outline our general product direction.
It is intended for information purposes only, and may not be
incorporated into any contract. It is not a commitment to deliver
any material, code, or functionality, and should not be relied upon
in making purchasing decisions. The development, release, and
timing of any features or functionality described for Oracle’s
products remains at the sole discretion of Oracle.

Agenda
Introduction to Oracle Big Data
Phases of processing Oracle Big Data
Overview of the Oracle Big Data Connectors
Methods of connecting Hadoop to an Oracle Database
Summary

What Is Big Data?
Big data is defined as voluminous unstructured data from
many different sources…….
Social networks
Banking and financial services
E-commerce services
Web-centric services
Internet search indexes
Scientific searches
Document searches
Medical records
Weblogs

Big Data: “Big Goals”
Discover Intelligent data
Understand ecommerce behavior
Derive sentiment
Support interactions
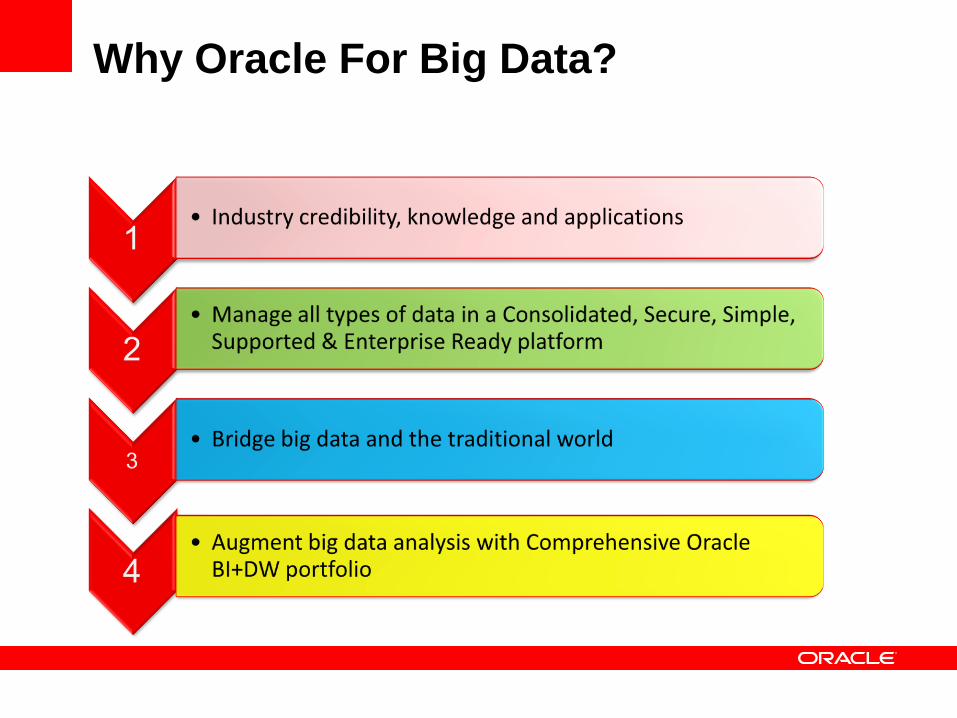
Why Oracle For Big Data?
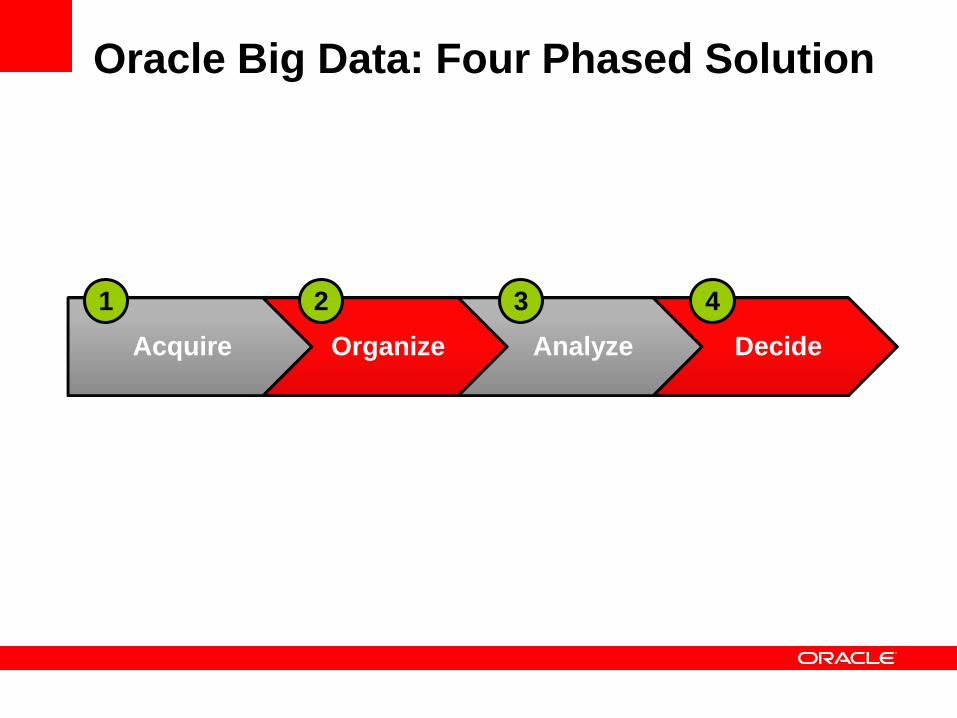
Oracle Big Data: Four Phased Solution
Acquire Organize Analyze Decide
1 2 3 4
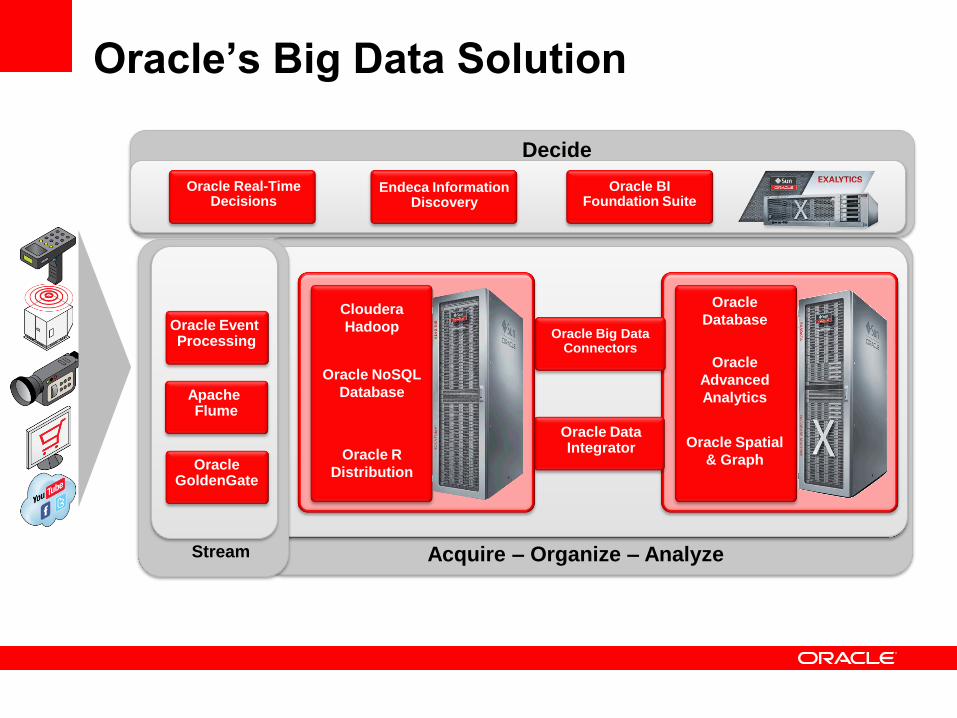
Oracle’s Big Data Solution
Stream Acquire – Organize – Analyze
Oracle BI Foundation Suite
Oracle Real-Time Decisions
Endeca Information Discovery
Decide
Oracle Event Processing
Oracle Big Data Connectors
Oracle Data Integrator
Oracle
Advanced
Analytics
Oracle
Database
Oracle Spatial
& Graph
Apache Flume
Oracle GoldenGate
Oracle NoSQL
Database
Cloudera
Hadoop
Oracle R
Distribution

Apache Hadoop
Apache Hadoop is a framework for executing applications on large
clusters built of commodity hardware. It operates by batch processing.
• Hadoop consists of two components:
• Hadoop Distributed File System
• MapReduce

Oracle Big Data Connectors
• Facilitate data access to data stored in a Hadoop
cluster.
• Can be licensed for use on either Oracle Big Data
Appliance or a Hadoop cluster running on commodity
hardware.
Acquire – Organize – Analyze
Oracle Big Data Connectors
Oracle Data Integrator
Oracle
Advanced
Analytics
Oracle
Database
Oracle Spatial
& Graph
Oracle NoSQL
Database
Cloudera
Hadoop
Oracle R
Distribution

Usage Scenarios
• Bulk loading of large volumes of data
Example: Historical data; daily uploads of data gathered during
the day
• Loading at regular frequency
Example: 24/7 monitoring of log feeds
• Loading at irregular frequency
Example: Monitoring of sensor feeds
• Accessing data files in place on HDFS

Installation Details
• You can download connectors from either of the
following locations:
• Oracle Technology Network
http://www.oracle.com/technetwork/bdc/big-data-
connectors/downloads/index.html
• Oracle Software Delivery Cloud
https://edelivery.oracle.com/

Oracle Big Data Connectors Licensed together
• Oracle Loader for Hadoop
• Oracle SQL Connector for HDFS
• Oracle Data Integrator Application Adapter for
Hadoop
• Oracle R Connector for Hadoop
• Oracle Xquery for Hadoop

Oracle Loader for Hadoop
• Efficient and high-performance loader for fast movement
of data from any Hadoop cluster into a table in Oracle
Database
• Allows you to use Hadoop MapReduce processing
• Partitions the data and transforms it into an Oracle-
ready format
• Can be operated in two modes
• Online mode
• Offline mode
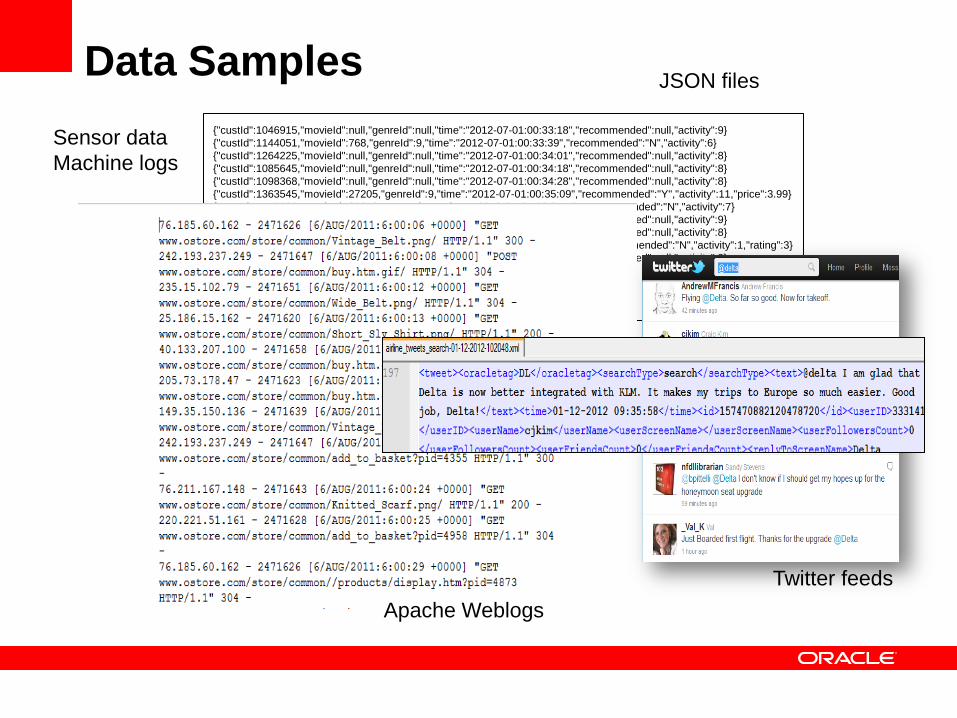
Data Samples
{"custId":1046915,"movieId":null,"genreId":null,"time":"2012-07-01:00:33:18","recommended":null,"activity":9}
{"custId":1144051,"movieId":768,"genreId":9,"time":"2012-07-01:00:33:39","recommended":"N","activity":6}
{"custId":1264225,"movieId":null,"genreId":null,"time":"2012-07-01:00:34:01","recommended":null,"activity":8}
{"custId":1085645,"movieId":null,"genreId":null,"time":"2012-07-01:00:34:18","recommended":null,"activity":8}
{"custId":1098368,"movieId":null,"genreId":null,"time":"2012-07-01:00:34:28","recommended":null,"activity":8}
{"custId":1363545,"movieId":27205,"genreId":9,"time":"2012-07-01:00:35:09","recommended":"Y","activity":11,"price":3.99}
{"custId":1156900,"movieId":20352,"genreId":14,"time":"2012-07-01:00:35:12","recommended":"N","activity":7}
{"custId":1336404,"movieId":null,"genreId":null,"time":"2012-07-01:00:35:27","recommended":null,"activity":9}
{"custId":1022288,"movieId":null,"genreId":null,"time":"2012-07-01:00:35:38","recommended":null,"activity":8}
{"custId":1129727,"movieId":1105903,"genreId":11,"time":"2012-07-01:00:36:08","recommended":"N","activity":1,"rating":3}
{"custId":1305981,"movieId":null,"genreId":null,"time":"2012-07-01:00:36:27","recommended":null,"activity":8}
Apache Weblogs
JSON files
Twitter feeds
Sensor data
Machine logs
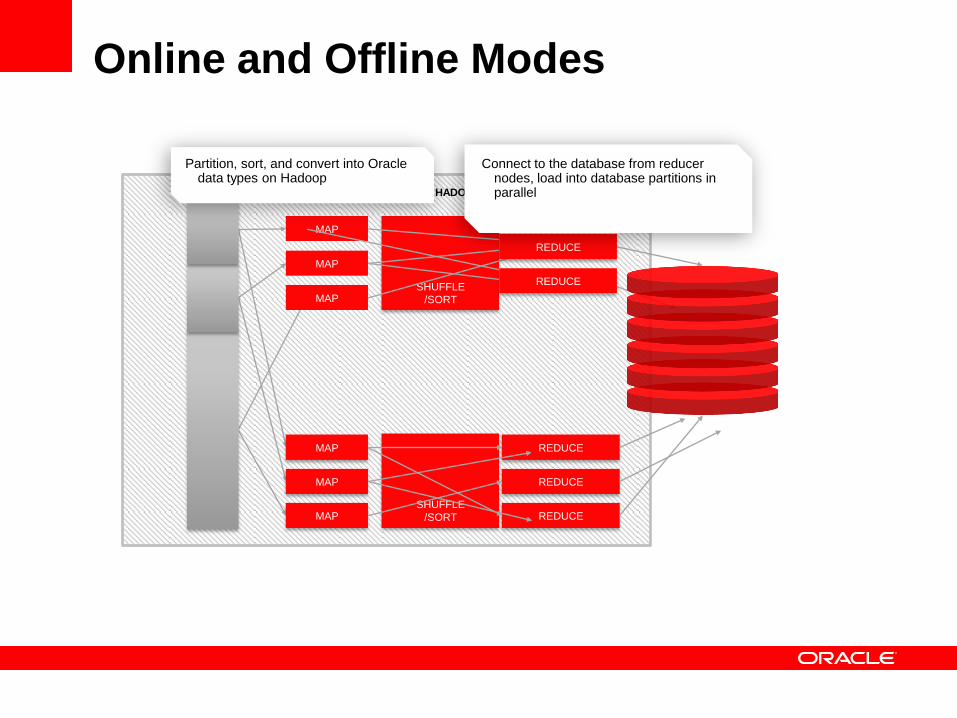
Online and Offline Modes
SHUFFLE
/SORT
SHUFFLE
/SORT
REDUCE
REDUCE
REDUCE
MAP
MAP
MAP
MAP
MAP
MAP
REDUCE
REDUCE
ORACLE LOADER FOR HADOOP
Connect to the database from reducer nodes, load into database partitions in parallel
Partition, sort, and convert into Oracle data types on Hadoop

Choosing Output Mode in OLH
OUTPUT MODE USE CASE CHARACTERISTICS
Online load with JDBC Simplest, can load into for
nonpartitioned tables
Online load with Direct Path Fast online load for partitioned
tables
Offline load with Data Pump
files
Fastest load method for external
tables

OLH: Advantages
• OLH offloads database server processing to Hadoop by:
• Converting the input data to final database format
• Computing the table partition for a row
• Sorting rows by primary key within a table partition
• Generating binary Data Pump files
• Balancing partition groups across reducers

Oracle SQL Connector for HDFS
• Oracle SQL Connector for HDFS (OSCH) is a connector
that facilitates read access from HDFS to Oracle
Database using external tables.
• It uses the ORACLE_LOADER access driver.
• It enables you to:
• Access big data without loading the data
• Access the data stored in HDFS files
• Access CSV (comma-separated value) files and Data Pump
files generated by Oracle Loader for Hadoop
• Load data extracted and transformed by Oracle Data
Integrator
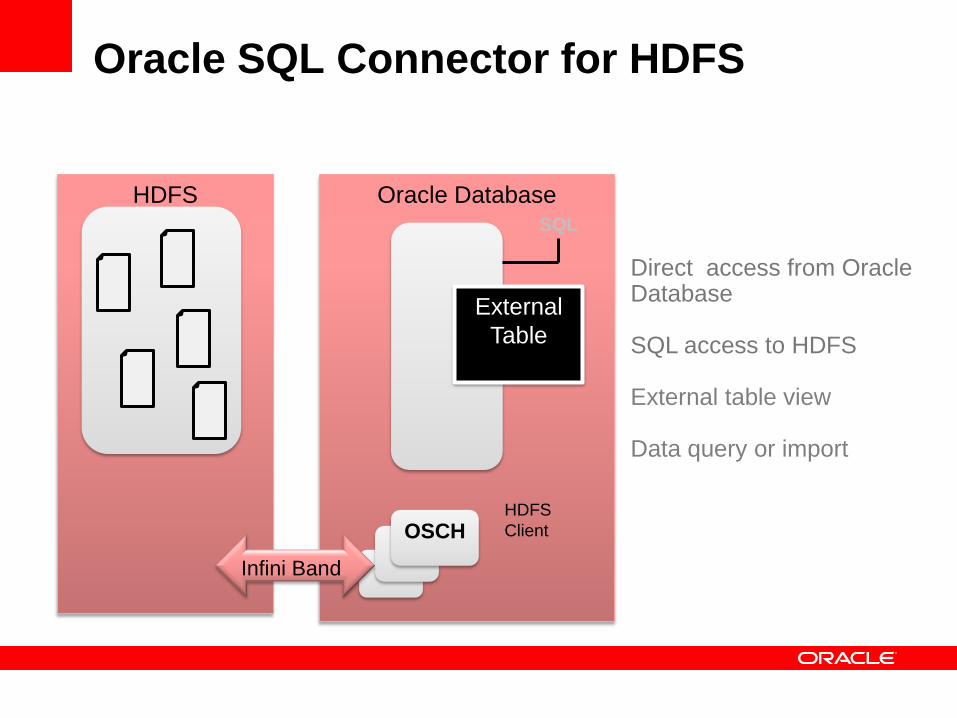
Oracle Database SQL
Query
HDFS
Oracle SQL Connector for HDFS
External
Table
Infini Band
HDFS
Client OSCH
Direct access from Oracle Database SQL access to HDFS External table view Data query or import

OSCH: Three Simple Steps
1.Create an external table.
2.Run the OSCH utility to publish HDFS content to the external
table.
3.Access and load into the database using SQL.
>hadoop jar \
$ODCH_HOME/jlib/orahdfs.jar \
oracle.hadoop.hdfs.extab.ExternalTable\
-conf MyConf.xml \
-publish

OSCH: Features
• Access and analyze data in place on HDFS via external tables.
• Query and join data on HDFS with database-resident data.
• Load into the database using SQL (if required).
• Automatic load balancing to maximize performance.
• DML operations and indexes cannot be created on external
tables.
• Data files can be text files or Oracle Data Pump files.
• Parallelism is controlled by the external table definition.
• Data files are grouped to distribute load evenly across PQ
slaves.

Choosing Connectors
Oracle Loader for Hadoop Oracle SQL Connector for HDFS
Load into Oracle Database. Access directly from Hive, HDFS, or
load into Oracle Database.
Input data can be delimited text,
data from Hive tables (Oracle-
supported Input Formats), or any
other format, for example, binary
format (by creating your own input
format).
Input data can be delimited text or
Oracle Data Pump files only.
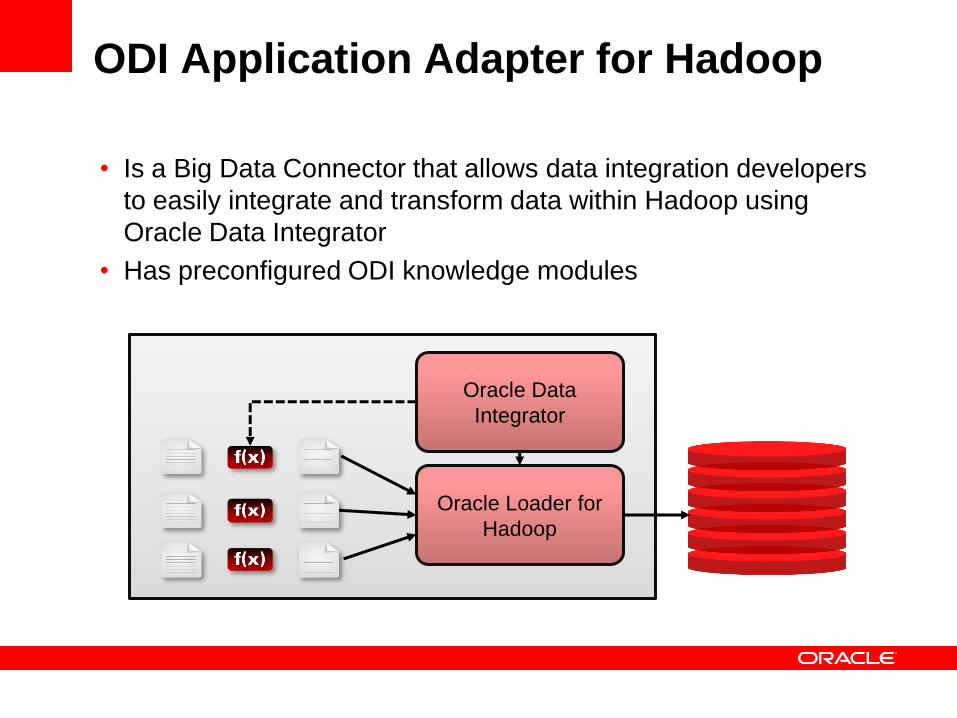
ODI Application Adapter for Hadoop
• Is a Big Data Connector that allows data integration developers
to easily integrate and transform data within Hadoop using
Oracle Data Integrator
• Has preconfigured ODI knowledge modules
Oracle Loader for
Hadoop
Oracle Data
Integrator

Oracle R Connector for Hadoop
• Oracle R Connector for Hadoop (ORCH) is an R package that
provides an interface between the local R environment, Oracle
Database, and Cloudera CDH.
• Using simple R functions, you can:
• Sample data in HDFS
• Copy data between Oracle Database and HDFS
• Schedule R programs to execute as MapReduce jobs
• Return the results to Oracle Database or to your laptop
Oracle R
Enterprise (ORE)
Cloudera CDH
Oracle R Connector for
Hadoop (ORCH)

Word Count: Example Without ORCH import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import
org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class WordMapper extends MapReduceBase
implements Mapper<LongWritable, Text, Text,
IntWritable> {
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable>
output, Reporter reporter)
throws IOException {
String s = value.toString();
for (String word : s.split("\\W+")) {
if (word.length() > 0) {
output.collect(new Text(word), new
IntWritable(1));
}
}
}
}
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import
org.apache.hadoop.mapred.OutputCollector;
import
org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class SumReducer extends MapReduceBase
implements
Reducer<Text, IntWritable, Text,
IntWritable> {
public void reduce(Text key,
Iterator<IntWritable> values,
OutputCollector<Text, IntWritable>
output, Reporter reporter)
throws IOException {
int wordCount = 0;
while (values.hasNext()) {
IntWritable value = values.next();
wordCount += value.get();
}
output.collect(key, new
IntWritable(wordCount));
}
}
Mapper Reducer

Word Count: Example with ORCH
input <- hdfs.put(corpus)
wordcount <- function (input, output = NULL, pattern = " ") {
res <- hadoop.exec(dfs.id = input,
mapper = function(k,v) {
lapply( strsplit(x = v, split = pattern)[[1]],
function(w) orch.keyval(w,1)[[1]])
},
reducer = function(k,vv) {
orch.keyval(k, sum(unlist(vv)))
},
config = new("mapred.config",
job.name = "wordcount",
map.output = data.frame(key=0, val=''),
reduce.output = data.frame(key='', val=0) )
)
res
}
Oracle
Database
Acquire – Organize – Analyze
Oracle Big Data Connectors
Oracle Data Integrator
Oracle Loader
for Hadoop
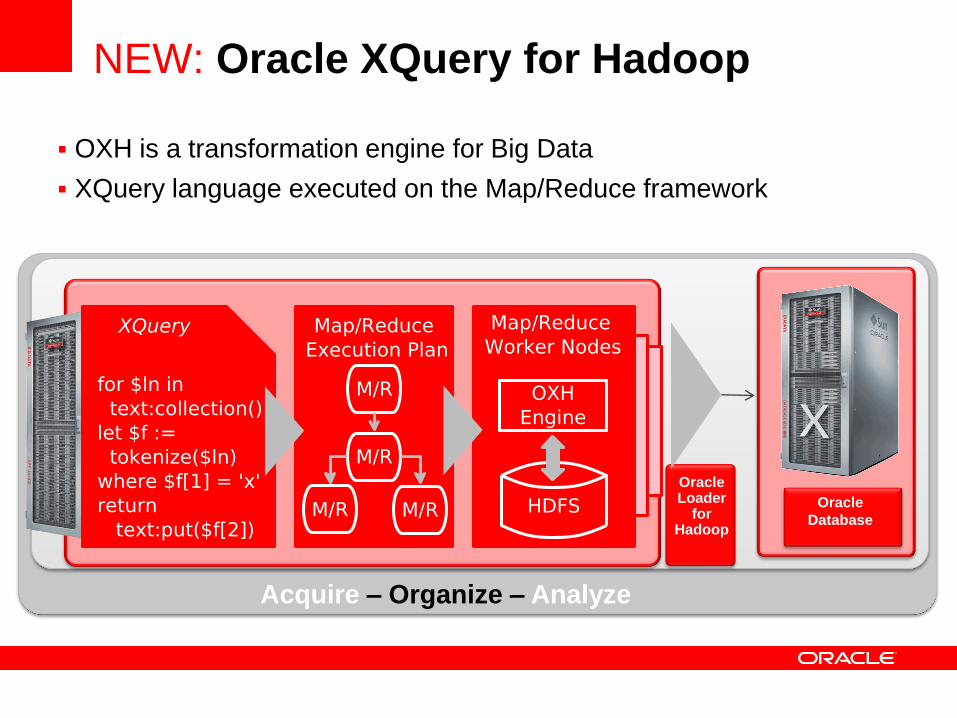
OXH is a transformation engine for Big Data
XQuery language executed on the Map/Reduce framework
XQuery
for $ln in
text:collection()
let $f :=
tokenize($ln)
where $f[1] = 'x'
return
text:put($f[2])
Map/Reduce
Execution Plan
M/R
M/R
M/R
M/R
Map/Reduce
Worker Nodes
HDFS
OXH
Engine
NEW: Oracle XQuery for Hadoop

Performance
• 15 TB / hour
• 25 times faster than third party
products
• Reduced database CPU usage in
comparison
Connectors: Engineered to Leverage
All Data
ODI Application
Adapter for
Hadoop
Oracle Loader for
Hadoop
Oracle Direct
Connector for
HDFS
Oracle R
Connector for
Hadoop
Oracle Xquery for
Hadoop

Summary
• Oracle Big Data Connectors are products for high speed
loading from Hadoop to Oracle Database
Cover a range of use cases
Several input sources
Flexible, easy-to-use, developed and supported by Oracle
• The fastest load option loads at 15 TB/hour

Further References
• http://www.oracle.com/us/products/database/big-data-
appliance/overview/index.html
• http://www.oracle.com/us/products/database/exadata/overview/inde
x.html
• http://www.oracle.com/technetwork/bdc/big-data-
connectors/downloads/index.html
• https://blogs.oracle.com/bigdataconnectors/



















