
InfoSphere BigInsights - Analytics power for Hadoop - field experience
33
InfoSphere BigInsights Analytics power for Hadoop – field experience Wilfried Hoge IT Architect Big Data @wilfriedhoge Stephan Reimann IT Specialist Big Data @stereimann
-
Upload
wilfried-hoge -
Category
Technology
-
view
715 -
download
0
Transcript of InfoSphere BigInsights - Analytics power for Hadoop - field experience

InfoSphere BigInsights Analytics power for Hadoop – field experience
Wilfried Hoge IT Architect Big Data
@wilfriedhoge
Stephan Reimann IT Specialist Big Data
@stereimann

© 2015 International Business Machines Corporation 2
IBM BigInsights – Open Source and IBM Value Adds
Real-time Analytics InfoSphere Streams
Enterprise Performance Adaptive Map Reduce & Big SQL
Storage Integration GPFS POSIX Distributed Filesystem
Data Governance and Security Data Click, LDAP and Secured Cluster
Search BigIndex and Data Explorer
Data Exploration BigSheets “schema-on-read” tooling
MapReduce HDFS HBase Flume
Pig
Lucene
Jaql ZooKeeper Oozie Hive
Sqoop
HCatalog
100% based on Apache Open Source Hadoop Components
Predictive Modeling BigR scalable data mining” on R
Text Analytics Text processing with AQL
Application Tooling Toolkits and accelerators
ANSI SQL BigSQL Optimized SQL support

© 2015 International Business Machines Corporation 3
Key Differentiators for BigInsights
Enterprise Performance & Integration Analytics Usability
& Productivity
• Workload / performance optimization
• GPFS
• Security
• Key integrations & Connectors with Enterprise Ecosystem
• Text analytics
• Social Data Analytics Accelerators
• Machine Data Analytics Accelerators
• Execute R in an integrated application
• Big SQL
• BigSheets
• Development Tools
• Web Console

© 2015 International Business Machines Corporation 4
Field experience – analyzing binary data The challenge
• Use case – Enable users to analyze data that is provided in binary format without the
need to run scripts
• Challenges – Binary to csv transformation – Access csv data on HDFS to directly analyze content – Access csv data from BI tools through SQL
– Possibility to analyze the data for technical business users – Flexible automation capabilities (scheduling)

© 2015 International Business Machines Corporation 5
Field experience – analyzing binary data The binary file – direct analysis not possible

© 2015 International Business Machines Corporation 6
Running Applications on Big Data
• Browse available applications • Deploy published applications
(administrators only) • Launch (or schedule for launch) a
deployed application • Monitor job (application) execution
status
• Predefined applications • Import & Export Data
• Database & Files • Web and Social
• Analyze and Query • Predictive Analytics • Text Analytics • SQL/Hive, Jaql, Pig, Hbase
• Accelerators

© 2015 International Business Machines Corporation 7
7
Editors • A workflow editor that greatly simplifies the
creation of complex Oozie workflows with a consumable interface
• A Pig/Jaql Editor with content assist and syntax highlighting that enables users to create and execute new applications using Pig or Jaql in local or cluster mode from the Eclipse IDE
Application development & deployment • Enablement of BigSheets macro
and BigSheets reader development • Text Analytics development,
including support for modular rule sets
• Publish new application: BigSheets Macro, BigSheets Reader, AQL module, Jaql module
Tools for Developers 1. Sample your
Data 2. Develop your application using BigInsights tools
3. Test your application
4. Package and publish your application
5. Deploy your application on the cluster

© 2015 International Business Machines Corporation 8
Field experience – analyzing binary data Developing and publishing a transformation application

© 2015 International Business Machines Corporation 9
Field experience – analyzing binary data The transformation application – user can convert binary data to csv

© 2015 International Business Machines Corporation 10
BigSheets to analyze and visualize
• Model “big data” collected from various sources in spreadsheet-like structures
• Filter and enrich content with
built-in functions
• Combine data in different workbooks
• Visualize results through
spreadsheets, charts
• Export data into common formats (if desired)
No programming knowledge needed!
© 2015 International Business Machines Corporation 11
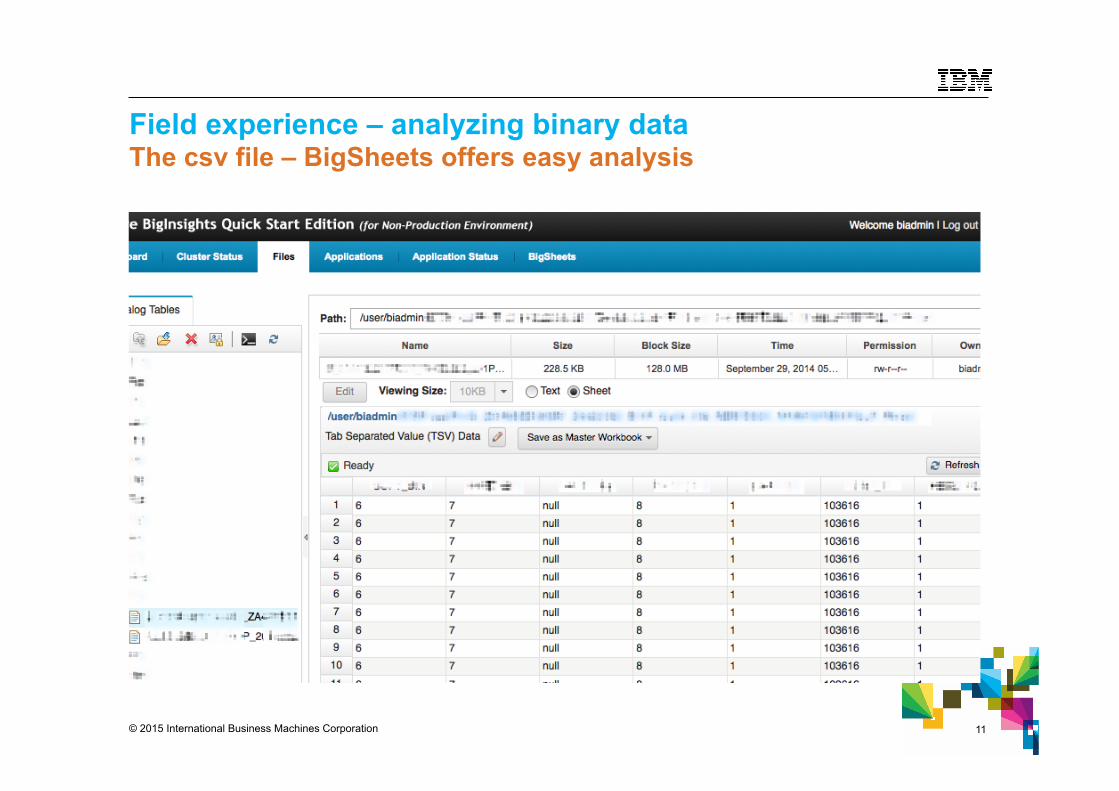
Field experience – analyzing binary data The csv file – BigSheets offers easy analysis

© 2015 International Business Machines Corporation 12
Field experience – analyzing binary data An analytical result with BigSheets
© 2015 International Business Machines Corporation 13
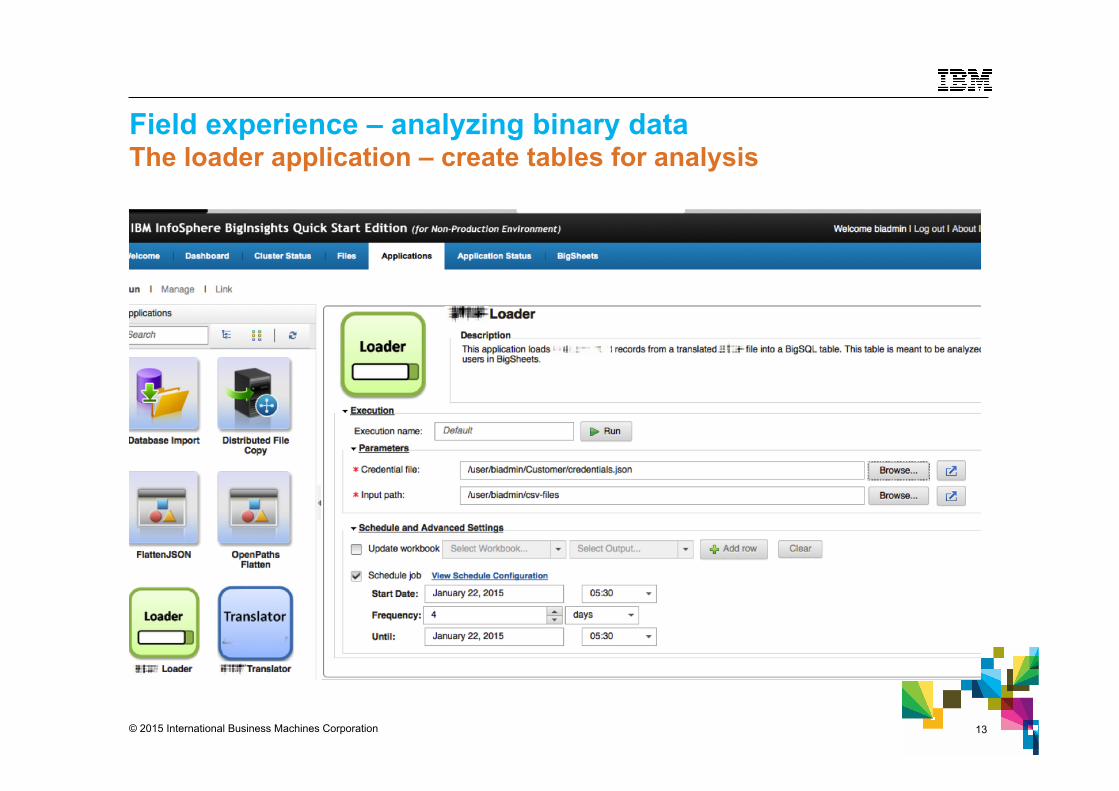
Field experience – analyzing binary data The loader application – create tables for analysis
© 2015 International Business Machines Corporation 14
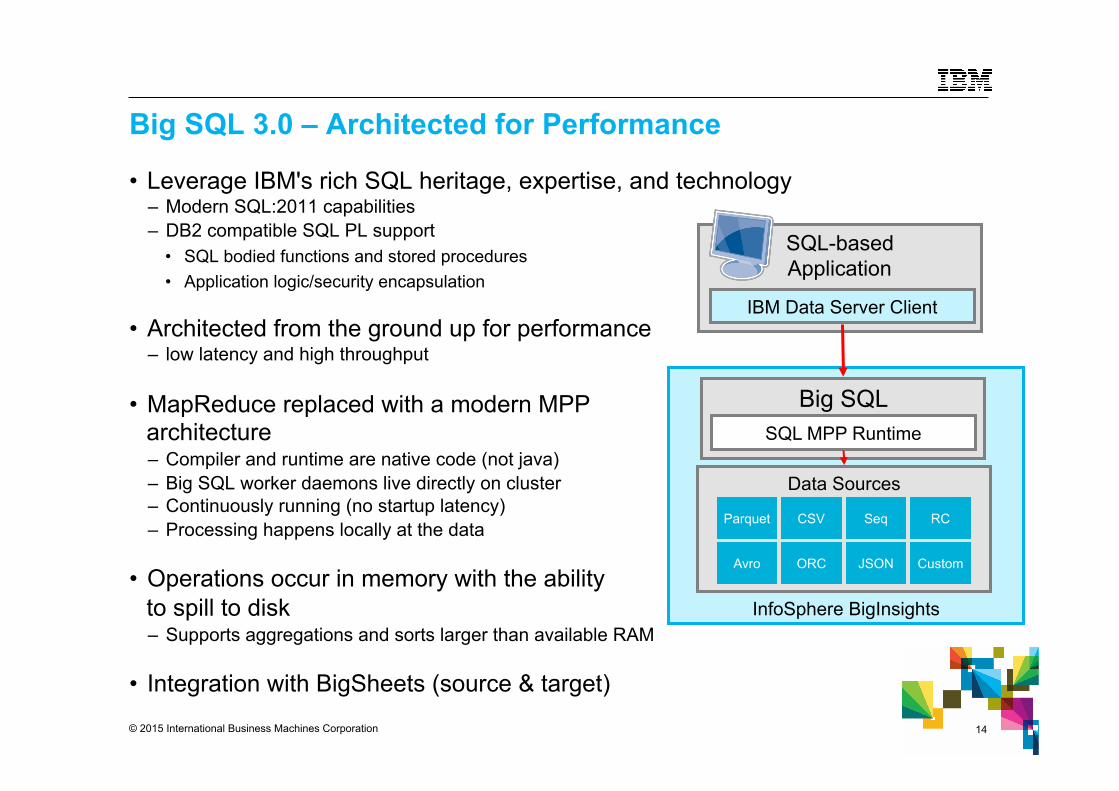
Big SQL 3.0 – Architected for Performance
• Leverage IBM's rich SQL heritage, expertise, and technology – Modern SQL:2011 capabilities – DB2 compatible SQL PL support
• SQL bodied functions and stored procedures • Application logic/security encapsulation
• Architected from the ground up for performance
– low latency and high throughput
• MapReduce replaced with a modern MPP architecture – Compiler and runtime are native code (not java) – Big SQL worker daemons live directly on cluster – Continuously running (no startup latency) – Processing happens locally at the data
• Operations occur in memory with the ability
to spill to disk – Supports aggregations and sorts larger than available RAM
• Integration with BigSheets (source & target)
InfoSphere BigInsights
Big SQL SQL MPP Runtime
Data Sources
Parquet CSV Seq RC
Avro ORC JSON Custom
SQL-based Application
IBM Data Server Client

© 2015 International Business Machines Corporation 15
Big SQL 3.0 – Architecture cont.
• Head (coordinator / management) node – Listens to the JDBC/ODBC connections and compiles / optimizes the query – Coordinates the execution of the query – Optionally store user data in traditional RDBMS table (single node only)
• Big SQL worker processes reside on compute nodes (some or all) • Worker nodes stream data between each other as needed • Workers can spill large data sets to local disk if needed
– Allows Big SQL to work with data sets larger than available memory
Mgmt Node
Big SQL
Mgmt Node
Hive Metastore
Mgmt Node
Name Node
Mgmt Node
Job Tracker •••
Compute Node
Task Tracker
Data Node
Compute Node
Task Tracker
Data Node
Compute Node
Task Tracker
Data Node
Compute Node
Task Tracker
Data Node ••• Big
SQL Big SQL
Big SQL
Big SQL
GPFS/HDFS

© 2015 International Business Machines Corporation 16
Big SQL 3.0 – Features
Data shared with Hadoop ecosystem Comprehensive file format support
Superior enablement of IBM software Enhanced by Third Party software
Modern MPP runtime Powerful SQL query rewriter
Cost based optimizer Optimized for concurrent user throughput
Results not constrained by memory
Distributed requests to multiple data sources within a single SQL statement
Main data sources supported: DB2 LUW, DB2/z, Teradata, Oracle, Netezza
Advanced security/auditing Resource and workload management
Self tuning memory management Comprehensive monitoring
Comprehensive SQL Support IBM SQL PL compatibility
Application Portability & Integration
Federation
Performance
Enterprise Features
Rich SQL

© 2015 International Business Machines Corporation 17
Field experience – analyzing binary data Run complex SQL on generated tables
INSERT INTO Sites (Counter,Tested,Site1,Site_num1,Number_of_xxxx_tested, XA1,Percentage_of_xxxx_per_yyyy, Counter_plus_one,Pass,Site2,Site_num2,Number_of_pass_xxxx, ZB2,xxxxx_of_site_num,xxxx_file_name) SELECT 12000 + ROW_NUMBER() OVER () * 10,'Tested','Site’,tab1.Site_num,
(SELECT sum(tab2.piece_count) FROM tab2 WHERE tab2.site_num=tab1.site_num) as num_xxxx_tested, 'PA',(SELECT sum(tab2.piece_count) FROM tab2 WHERE tab2.site_num=tab1.site_num and tab2.head_num=255), 34000 + ROW_NUMBER() OVER () * 10 + 1,'Pass','Site',tab1.site_num, (SELECT COUNT(*) FROM tab1 as tab12 WHERE tab1.site_num=tab12.site_num and tab1.piece_Flg=0) as num_xxxx_passed, 'PA',((SELECT sum(tab2.piece_count) FROM tab2 WHERE tab2.site_num=tab1.site_num) / NULLIF(0.001,(SELECT COUNT(*) FROM tab1 as tab12 WHERE tab1.site_num=tab12.site_num and tab1.piece_Flg=0))), tab1.xxxx_file_name
FROM tab1 as tab1, tab2 as tab2 GROUP BY tab1.site_num, tab1.piece_Flg, tab1.xxxx_file_name;
rank function
subselects

© 2015 International Business Machines Corporation 18
Application linking and interfaces to build new apps • Compose new
applications from existing applications and BigSheets
• Invoke analytics applications from the web console, including integration within BigSheets
• REST data source App that enables users to load data from any data source supporting REST APIs into BigInsights, including popular social media services
• Sampling App that enables users to sample data for analysis • Subsetting App that enables users to subset data for data analysis
18

© 2015 International Business Machines Corporation 19
Field experience – analyzing binary data User builds his/her own application flow

© 2015 International Business Machines Corporation 20
Field experience – analyzing binary data What was achieved 1/2
– Conversion from binary to csv (Transformation App) • Customer provided Java classes that read binary file and produced csv output • Developer embedded java code in an BigInsights application • User can provide source and target path • User can provide filters if not the whole data set should be extracted • User can schedule the application (with parameters) • Application automatically has a REST interface for external scheduling • Application uses map/reduce for scaling if larger number of files have to be
transformed
– User can analyze the csv files with BigSheets

© 2015 International Business Machines Corporation 21
Field experience – analyzing binary data What was achieved 2/2
– Create SQL tables from csv (Loader App) • Developer embedded necessary SQL in App • User can create tables from csv files
– User can run complex SQL on tables with preferred Front-End tool
– User can combine Apps and create his/her own flow

© 2015 International Business Machines Corporation 22
IBM BigInsights brings efficient integration of R with Big R
• R as a big data query language – Outside-in execution
• R as a statistical language for deep computing – Inside-out execution – Partitioning of large data (“divide”) – Parallel cluster execution of pushed
down R code (“conquer”) – Almost any R package can run in
this environment
• R as the gateway to scalable machine learning – A scalable ML engine that provides
canned algorithms, and an ability to author new ones, all via R
R Clients
Scalable ML
Engine
Data Sources
Embedded R Execution
R Packages
R Packages
Pull data (summaries) to
R client
Or, push R functions right
on the data

© 2015 International Business Machines Corporation 23
SystemML – Declarative high-level language
SystemML
tokens
docu
men
ts
1 1 0.10 1 2 0.30 1 3 0.22 1 4 1.24 : : : : : :
W
H
K to
pics
tokens K topics
docu
men
ts
1 1 0.10 1 2 0.30 : : :
Topic Detection in Social Media
§ Modeled after R syntax and semantics
§ Expressivity – Express a wide class of algorithms: Descriptive
statistics, linear & logistic regression, decision trees, SVM, MCMC simulation, etc.
§ Productivity – Enable programmer productivity: algorithm developer
does not have to worry about scalability, numeric stability and optimizations
§ Performance and Scalability – Optimizer to generate low-level executions plans
• Cost-based operator selection based on − data characteristics (dimensions, sparsity) − cluster characteristics (memory, parallelism)
• Generation of runtime execution plan
§ Big Data – Sparsity-driven data representation and operator
implementations for data sets with Billions of non-zero values

© 2015 International Business Machines Corporation 24 * Requires Service Engagement
ISV Partner Solution Type
BigInsight Version Certified
ISV Partner Solution Type
BigInsight Version Certified
Data Integration
2.1 (3.0 in process 4Q) Reporting 2.1 & 3.0
Data Security 2.1.2 Customer Analytics 2.1.2
Cluster Mgt 3.0 Analytics 2.1.2 (3.0 in
process)
Data Vis 2.1 (3.0 in process)
Visual Reporting 2.1 & 3.0 Data Virtual-
ization 2.1.2 & 3.0
TDHC 3.0 Analytics 2.1.2&3.0
Aster 3.0 *
Data Integration
2.1 (3.0 in process 3Q)
Backup & Recovery 2.1.2
IBM Product Solution Type
BigInsight Version Certified
IBM Product Solution Type
BigInsight Version Certified
Business Intelligence
2.1.2 (3.0 end of Nov’14)
Predictive Analytics
2.1.2 (3.0 mid4Q)
InfoSphere InformationServer v11.3
Data Integration 3.0
SPSS v10.2.1 AS v1.0.1
BigInsights Certifications

© 2015 International Business Machines Corporation 25
lHelium SW
BigInsights ISV Partner Ecosystem

© 2015 International Business Machines Corporation 26
Get started with BigInsights
• Hadoop Dev: links to videos, white papers, lab, . . . . http://developer.ibm.com/hadoop/ • BigInsights Trials http://ibm.com/software/data/infosphere/hadoop/trials.html

IBM big data • IBM big data • IBM big data
IBM big data • IBM big data • IBM big data
IBM
big
dat
a
• IB
M b
ig d
ata
IBM
big data • IBM
big data
THINK
© 2015 International Business Machines Corporation 28
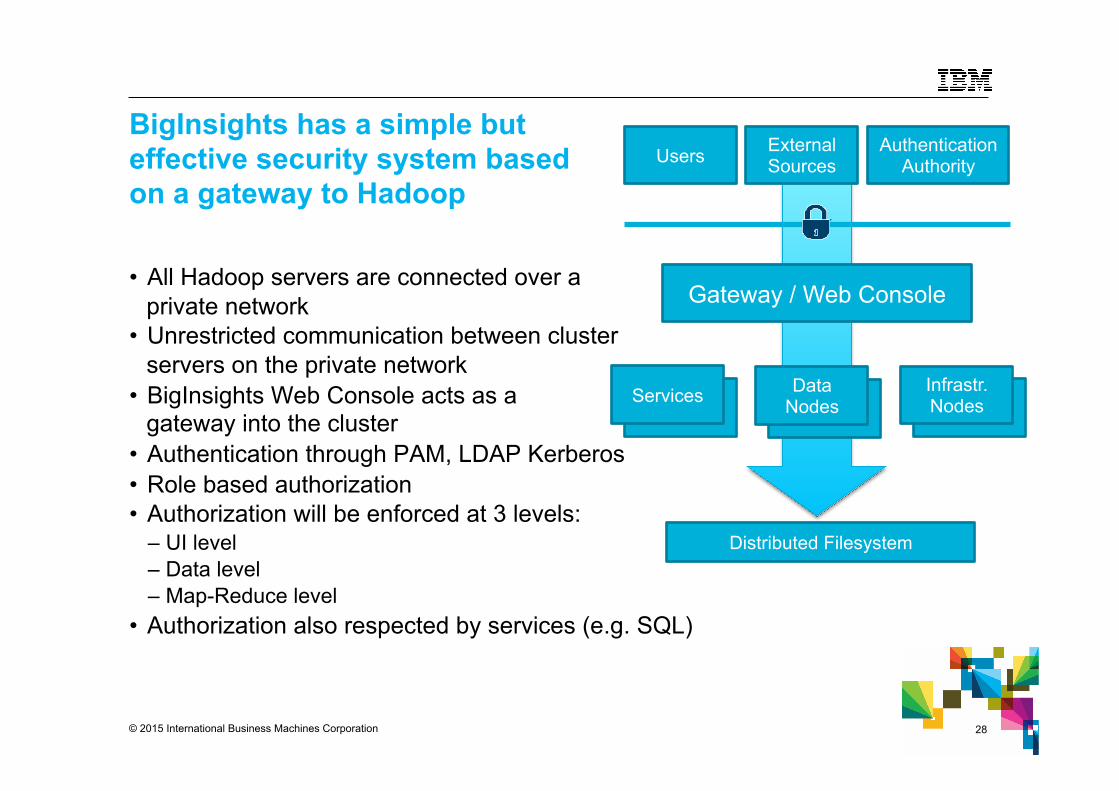
BigInsights has a simple but effective security system based on a gateway to Hadoop
• All Hadoop servers are connected over a private network
• Unrestricted communication between cluster servers on the private network
• BigInsights Web Console acts as a gateway into the cluster
• Authentication through PAM, LDAP Kerberos • Role based authorization • Authorization will be enforced at 3 levels:
– UI level – Data level – Map-Reduce level
• Authorization also respected by services (e.g. SQL)
Authentication Authority
Gateway / Web Console
External Sources Users
Services Data Nodes
Infrastr. Nodes
Distributed Filesystem
© 2015 International Business Machines Corporation 29
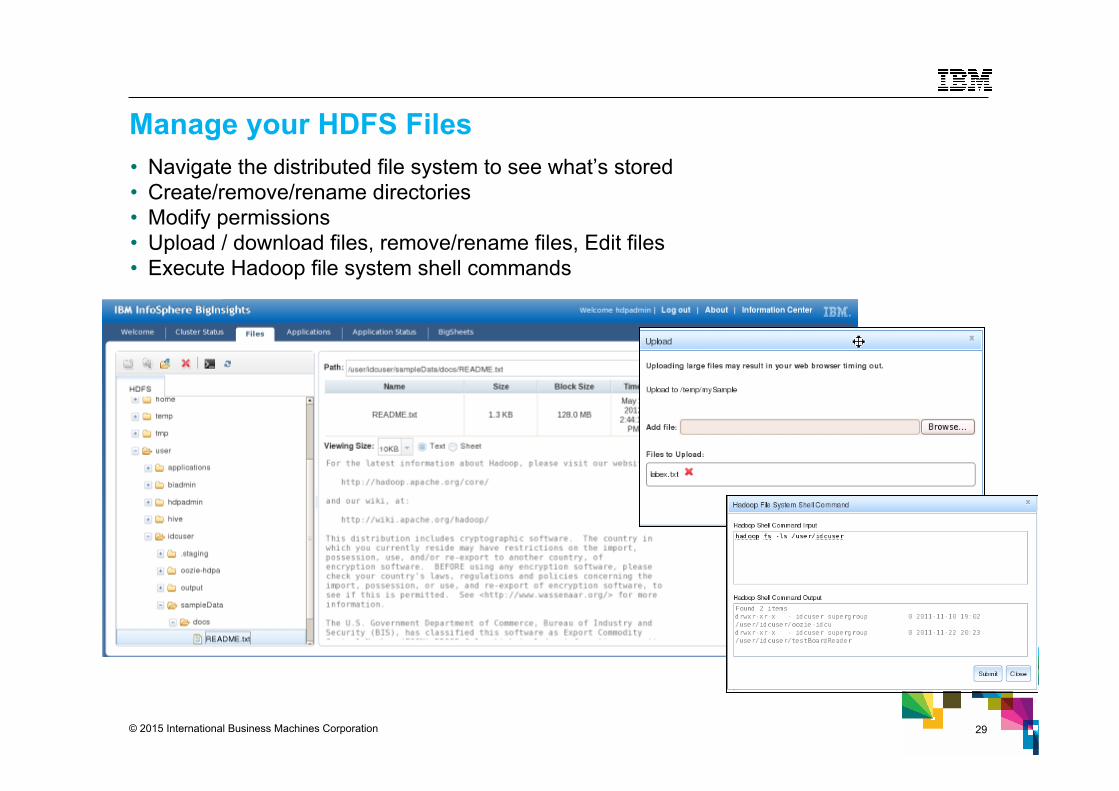
Manage your HDFS Files • Navigate the distributed file system to see what’s stored • Create/remove/rename directories • Modify permissions • Upload / download files, remove/rename files, Edit files • Execute Hadoop file system shell commands

© 2015 International Business Machines Corporation 30
About the Hadoop-DS Benchmark
§ Created by IBM § The Big Data Decision Support Benchmark (Hadoop-DS) is inspired
by, and is highly compliant with TPC-DS - Fully complies with the TPC-DS schema requirement - Uses all 99 queries - Meets the multi-user requirement - Has been audited by a TPC-DS auditor but as a non-TPC benchmark
§ Select deviations from TPC-DS due to Hadoop limitations: - No data maintenance operations, referential integrity enforcement, or ACID
property validation as these are not feasible with HDFS - Additional statistics used - Metric adjustments - No price/performance measures included - Not an official TPC benchmark result

© 2015 International Business Machines Corporation 31
IBM Big SQL – Runs 100% of the TPC-DS queries
Key points § With competing solutions, many
queries needed to be re-written, some significantly
§ Owing to various restrictions, some queries could not be re-written or failed at run-time
§ Re-writing queries in a benchmark scenario where results are known is one thing – doing this against real databases in production is another
Competitive environments require significant effort

© 2015 International Business Machines Corporation 32
IBM Big SQL – Leading performance
0
2.000
4.000
6.000
8.000
10.000
12.000
14.000
16.000
18.000
Big SQL Impala Hive
Power run (single-stream) - seconds As measured across the subset of queries that Impala and Hive can both run
3.6x FASTER!!
48:29
2:55:35
4:30:35
3.6x faster than Impala, 5.6x faster than Hive
* Subject to findings of TPC auditor – full disclosure report expected late October 2014

© 2015 International Business Machines Corporation 33
IBM Big SQL – Leading performance
0
10.000
20.000
30.000
40.000
50.000
60.000
70.000
Big SQL Impala Hive
Throughput run – (four streams) - seconds As measured across the subset of queries that Impala and Hive can both run
1:54:02
4:08:39
16:32:12
2.2x FASTER!!
2.2x faster than Impala, 4x faster than Hive
* Subject to findings of TPC auditor – full disclosure report expected late October 2014


















