
Douglas Pharmaceuticals Ltd Graeme Douglas Managing Director.
Upload
shawna-sainsburyCategory
view
217download
1
Information Extraction:What It Is
How to Do ItWhere It’s Going
Douglas E. Appelt
Artificial Intelligence Center
SRI International

Some URLs to Visit
http://www.ai.sri.com/~appelt/ie-tutorial/» ANLP-97 tutorial on information extraction» Many WWW links
– Research sites and literature– Resources for building systems
http://www.ai.sri.com/~appelt/TextPro/» An IE System for Power PC Macintoshes» Uses TIPSTER technology
– TIPSTER architecture– Common Pattern Specification Language– It’s free
» Comes with a complete English name recognizer

Information Extraction:Situating IE
Text Manipulation: grep Information Retrieval Information Extraction Text Understanding

Text Understanding
No predetermined specification of semantic or communicative areas of interest
No clearly defined criteria of success Representation of meaning must be sufficiently
general to capture all of the meaning of the text and the author’s intentions.

Information Extraction
Information of interest is delimited and pre-specified Fixed, predefined representation of information Clear criteria of success are at least possible Corollary Features
» Small portion of text is relevant» Often, only a portion of a relevant sentence is relevant» Targeted at relatively large corpora

Applications
Information Retrieval (routing queries) Indexing for Information Retrieval Filter for IR Output Direct Presentation to the User: highlighting Summarization Construction of data bases and knowledge
bases

Evaluation Metrics
MUC Evaluations Precision and Recall
» Recall: percentage possible found» Precision: percentage provided that is correct» F-measure: weighted, geometric mean of recall
and precision
Is there a F-60 barrier?

A Bare BonesExtraction System
Tokenizer
Morphological andLexical Processing
Parsing
Domain Semantics
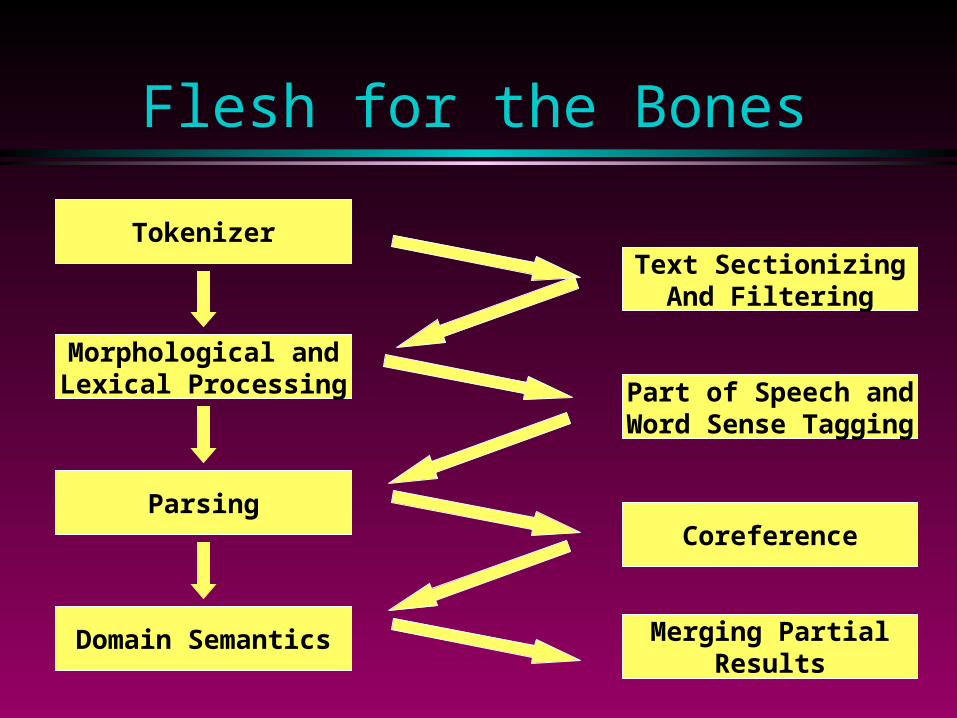
Flesh for the Bones
Tokenizer
Morphological andLexical Processing
Parsing
Domain Semantics
Text SectionizingAnd Filtering
Part of Speech andWord Sense Tagging
Coreference
Merging PartialResults

The IE Approach - KISS
Keep it Simple, Stupid» Finite-state language models» Fragment processing» Simple semantics
– Propositional– Small number of propositions– Often represented by templates
Use heuristics» Missing Information» Make favorable recall/precision tradeoffs

Two Approaches to Extraction Systems
Knowledge Engineering Approach» Grammars constructed by hand» Domain patterns discovered by introspection and
corpus examination» Laborious tuning and hill-climbing
Learning and Statistical Approach» Apply statistical methods where possible» Learn rules from annotated corpora» Learn from interaction with user

Knowledge Engineering Approach
Advantages» Skilled computational linguists can build good
systems quickly» Best performing practical systems have so far
been handcrafted.
Disadvantages» Very laborious development process» Difficult to port systems to new domains» Requires expertise

Learning-Statistical Approach
Advantages» Domain portability is straightforward» Minimal expertise required for customization» Rule acquisition is data driven - complete coverage
of examples
Disadvantages» Training data may not exist and may be difficult or
expensive to obtain» Highest performing systems are still hand-crafted

A Combined Approach
Use statistical methods on modules where training data exists, and high accuracy can be achieved
» Part-of-speech tagging» Name recognition» Coreference
Use knowledge engineering when training data is sparse and human ingenuity required
» Domain Processing

Lexical Processing:Named Entity Recognition
Named Entities are targets of extraction in many domains
» Companies» Other organizations» People» Locations» Dates, times, currency
Impossible or impractical to list all possible named entities in a lexicon

The List Fallacy
Comprehensive lexical resources do not necessarily result in improved extraction performance
» Some entities are so new they’re not on any lists» Rare senses cause problems - “has been” as a noun» Names often overlap with other names and ordinary words
– “Dallas” can be the name of a person– “Dollar” is the name of a town
Solutions» Part-of-speech tagging» Recognition from context

Knowledge Engineeringvs. Statistical Models
Knowledge Engineering» SRI, SRA, Isoquest» Performance
– 1996: F 96.42– 1998: F 93.69
Statistical Models» BBN, NYU (1998)» Performance
– 1997: F 93– 1998: F 90.44
Hand-coding reduces the error rate by 50%.

Knowledge EngineeringName Recognition
Identify some names explicitly in lexicon Identify parts of names with lexical features Write rules that recognize names
» Use capitalization in English» Recognize names based on internal structure
– “Mumble Mumble City” Location– “Mumble Mumble GmbH” Company
» Exceptions for common “gotchas”– “Yesterday IBM announced…”– “General Electric” is a company, not a general
Many complex rules are the result

Statistical ModelName Recognition
Hidden Markov Models
Start End
Name
Not-a-name

Statistical ModelName Recognition
Transitions are probabilistic Training
» Annotate a corpus» Estimate transition probabilities given words (and/or their
features)
» P(si | si-1, wi)
Application» Compute the maximum-likelihood path through the network
for the input text.» The Viterbi algorithm

Training Data
The amount of data needed is not onerous (diminishing returns at 100,000 words)
Annotation can be done by non-linguist native speakers
Training also works (with some degradation) for upper-case-only and punctuation-free texts.

Interesting Aside
NYU trained a statistical model using as word “features” whether various other name recognition systems tagged that word as part of a name.
Result: Better than human performance!» System achieved F 97.12» Experienced humans: F 96.95 97.60

Parsing in IE Systems
Some IE Systems have attempted full parsing» NYU Pre-1996 Proteus System» SRI Tacitus System
Attempts to adapt to the IE task» Fragment interpretation» Limitation of search
Statistical Parsing?» No real systems exist yet

Problems with Full Parsing
The search space becomes prohibitively large for long sentences.
» The system is slow. Rapid development and testing of rules becomes impossible.
“Full Parse” heuristic» It is often possible with a comprehensive grammar to span
the sentence with a highly improbable parse when the actual analysis is outside of the grammar, or lost in the search space.

The IE Approach to Parsing
Analyze sentences as simple constituents that can be described with a finite-state grammar
» Noun Groups, Verb Groups, Particles» Ignore prepositional attachment» Ignore clause boundaries
Parser consists of one or more finite-state transducers mapping words into simple constituents

A Finite-State Fragment Parse
A. C. Nielson Co.NG saidVG George Garrick,NG 40years old, presidentNG of Information Resources,Inc.NG 's London-based European InformationServices operationNG will becomeVG presidentNG
and chief operating officerNG of Nielson MarketingResearch USANG a unitNG of Dun & Bradstreet.NG

Handling Difficult Cases
Relative Clauses» Use nondeterminism to connect single subject to multiple
clauses
VP Conjunction» Use nondeterminism to connect single subject to multiple
verb phrases
Appositives» Handle only domain-relevant cases
Prepositional Attachment» Handle only domain-relevant cases

An Application Domain
Identify domain-relevant objects Identify properties of those objects Identify relationships among domain-relevant
objects Identify relevant events involving domain
objects

The Molecular Approach
Standard approach High precision, low recall approach
» Read texts» Identify common, domain relevant patterns
signaling properties, events, and relationships» Build rules to cover those» Move to less frequent, less reliable patterns

The Atomic Approach
Aims for high recall, low precision» Determine features of application-relevant entity types» Determine features of application-relevant event and relation
types» Every occurrence of a phrase with the relevant feature
triggers a candidate event/relation» Merge candidate relations to obtain more fully instantiated
event/relation descriptions» Filter using application-specific criteria

Appropriateness
Appropriate when» Relevant entities have easily determined types» Only one or a small number of relations can hold of an entity
with a given type» Relevant events and relations are symmetrical.
Examples» Labor negotiations» MUC-5 Microelectronics
Heavy reliance on merging of partial information (even within sentence)

Is There a Barrier?
0
20
40
60
80
100
0 50 100
Recall
MUC 3
MUC 4
MUC 5
MUC 6
F 60
Human

Where is the Upper Bound?
Experience suggests that, for a MUC-like task with MUC scoring, it is unrealistic to expect to achieve more than about F 65 on a blind test. (F 70 on training data)
About 75% of human performance.

Reasons for the Limits
There is a long tail of increasingly rare domain-relevant expressions
A barrier of inherently hard linguistic phenomena» Complex coordination» Collective-distributive reference» Multiple interacting phenomena in the same
sentence» Hard inferences required
Limits of heuristic tradeoffs are reached

Improve Information Retrieval
Routing task:» Build a quick extraction system for a topic.» IR system picks 2000 texts» Rescore by using extraction system to evaluate the
text for relevance» Return the 1000 top texts
Results: 12 improve, 4 same, 5 worse Best results when training data is sparse More testing and evaluation needed.

Topic Oriented Summarization
Extract information of interest Generate NL summary of extracted data Generation can be in a different
language, enabling cross-language access to key information.

Process Many Documents Quickly
Exploit redundancy in corpora to get higher recall from merging of multiple descriptions of the same event.
» Analyze data from multiple news feeds
Annotating text for training language models» Need to identify names in speech (broadcast news)» Train class bigram on 100 million words of training data.» Because automatic name annotation is almost as good as
human annotation, automatic annotation of training data is feasible.

Make Limits More Quickly Attainable
Automatic learning of rules from examples Application of "open domain" extraction
systems» Build general rules for a very broad domain, like
"business and economic news"» Quickly customize rules from library for a specific
application» Used a prototype to generate extraction systems
for routing queries in a half-day.


















