
Information Dynamics in Language : English-Hindi Anusaaraka Akshar Bharati LTRC, IIIT, Hyderabad...
45
Information Dynamics in Language : English-Hindi Anusaaraka Akshar Bharati LTRC, IIIT, Hyderabad [email protected] (20-04-09)
-
Upload
colleen-cooper -
Category
Documents
-
view
218 -
download
0
Transcript of Information Dynamics in Language : English-Hindi Anusaaraka Akshar Bharati LTRC, IIIT, Hyderabad...

Information Dynamics in Language : English-Hindi
Anusaaraka
Akshar Bharati
LTRC, IIIT, Hyderabad
(20-04-09)
u3Ld

Outline
Anusaaraka – What it is ?
Anusaaraka – How does it work ?
Information dynamics in language
English – From Paninian perspective
Machine Translation
Anusaaraka – An alternative approach
Anusaaraka Goals
Anusaaraka Philosophy
Summary – What Anusaaraka is

What is Anusaaraka?
Software that translates English text to Hindi.
Fusion of traditional Indian shastras and modern technology.
Collaborative endeavour of CIF, IIIT – Hyderabad and University of Hyderabad (Department of Sanskrit Studies).

How does Anusaaraka work?
User types in the text that needs to be translated.
Machine gives output (i.e. translation).
Option to view step-by-step translation.

Information Dynamics in Language (1/४4)
Languages encode information
cuuhe maarate haiM kutte
rats kill dogs
Hindi sentence is ambiguous
Possible interpretations :
Dogs kill rats
Rats kill dogs
However,

Information Dynamics in Language (2/4)
Ambiguity in Hindi is resolved if,
cuuhe maarate haiM kuttoM ko
rats kill dogs acc
English has information in positions Hindi in morphemes
Languages encode information differently

Information Dynamics in Language (3/4)
English pronouns he, she, it
Hindi vaha
He is going to Delhi vaha dilli jA rahaa hai
She is going to Delhi vaha dillii jA rahii hai
It broke vaha tuta ??
Information does not always map fully from one language into another. Conceptual worlds may be different.

Information Dynamics in Language (4/4)
This chair has been sat on
This chair has been used for sitting
X sat on this chair, and it is known
Language encodes information partially

English from Paninian View Point
ा�An Example:
Panini's 'sutra'
सु� सु�प्� तिङन्म्� प्दम्�
states
प्रा�तिप्दिदक+सु�प्�= सु�बन् प्दNom base+nom inflection=nominal word form
धा��+तिङ� =तिङन्verb root+verbal inflections=finite verb form
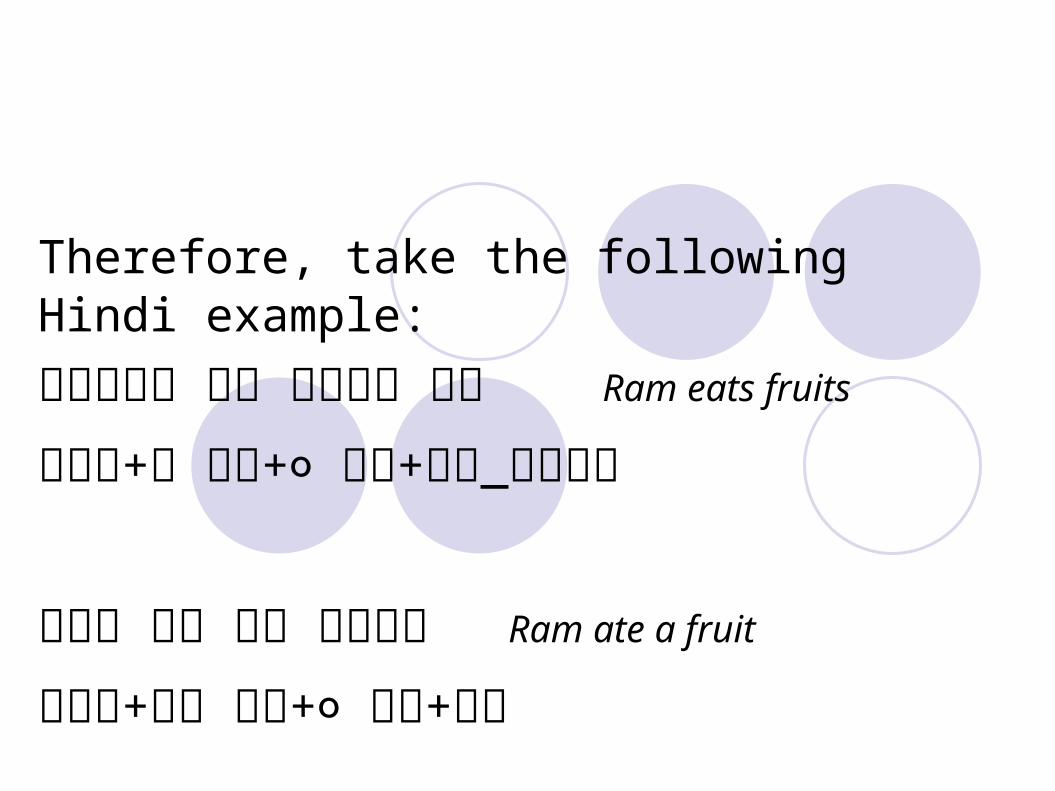
Therefore, take the following Hindi example:
रा� रा�म् फल खा�� है� Ram eats fruits
रा�म्+ ० फल+ ० खा�+�_है�है�
रा�म् ने� फल खा�या� Ram ate a fruit
रा�म्+ ने� फल+ ० खा�+या�

English from Paninian View Poinट
Interrogatives in English
To whom did you give the book ? who+to_m do+past you+0 give the book+0
Alternatively
Who did you give the book to ?Who do+past you+0 give the book+o to
Notionसुs of NP and PP are essential to Explain English structures where NP=प्प्रा�तिप्दिदक, PP= सु�बन् (प्द)
to+who = सु�बन्

Translation
Translation involves Transfer of information from one language
to anotherThis generates tension between
Faithfulness to the source Readability (naturalness) in the target
Translators normally sacrifice faithfulness in favour of readability

Machine Translation
Challenges and Problems
Language codes information only partially Tension between BREVITY and PRECISION Brevity wins leading to inherent ambiguity at
different levels

Ambiguity in Language
Can be at the structural level
Can be at the lexical level

Structural Ambiguity
Time flies like an arrow
Possible parses
1. Time flies like an arrow (time goes fast)
2. Time flies like an arrow (time-flies have a liking for an arrow)
3. Time flies like an arrow (time the flies just like you time the arrows) -flies are like an arrow
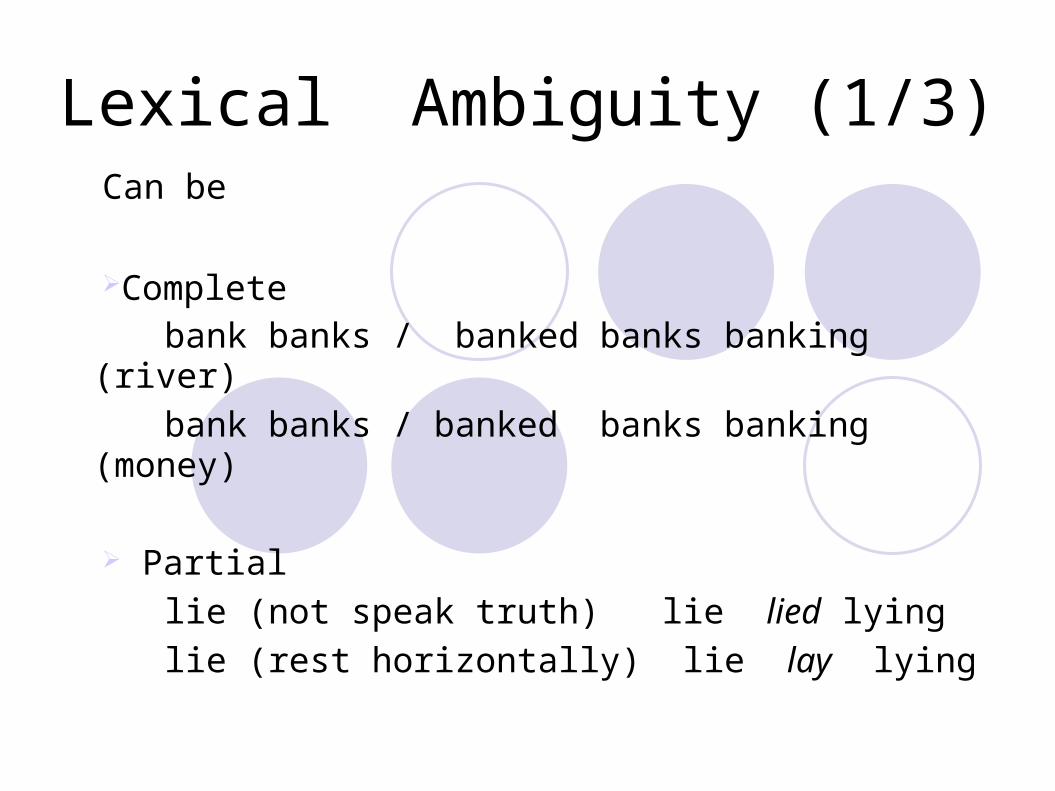
Lexical Ambiguity (1/3)
Can be
Complete bank banks / banked banks banking (river) bank banks / banked banks banking (money)
Partial lie (not speak truth) lie lied lying lie (rest horizontally) lie lay lying

Lexical Ambiguity (2/3)
Shelve
1. Shelve the books
Put the books on the shelf
2. The Institute has shelved the idea at least until next
year
Postponed the idea till the next year

Function words (1/2)
He bought a shirt with tiny collars.
usane chote kOlaroM vaalii kamiiza khariidii
He washed a shirt with soap.
usane saabuna se kamiiza dhoii
PP attachment is governing the choice of postposition in
Hindi

Function words (2/2)
Ram is sitting in the garden
raama bagiice meM baiThaa haiRam is running in the garden
raama bagice meM dODza rahaa hai
Verb root is governing the choice of TAM
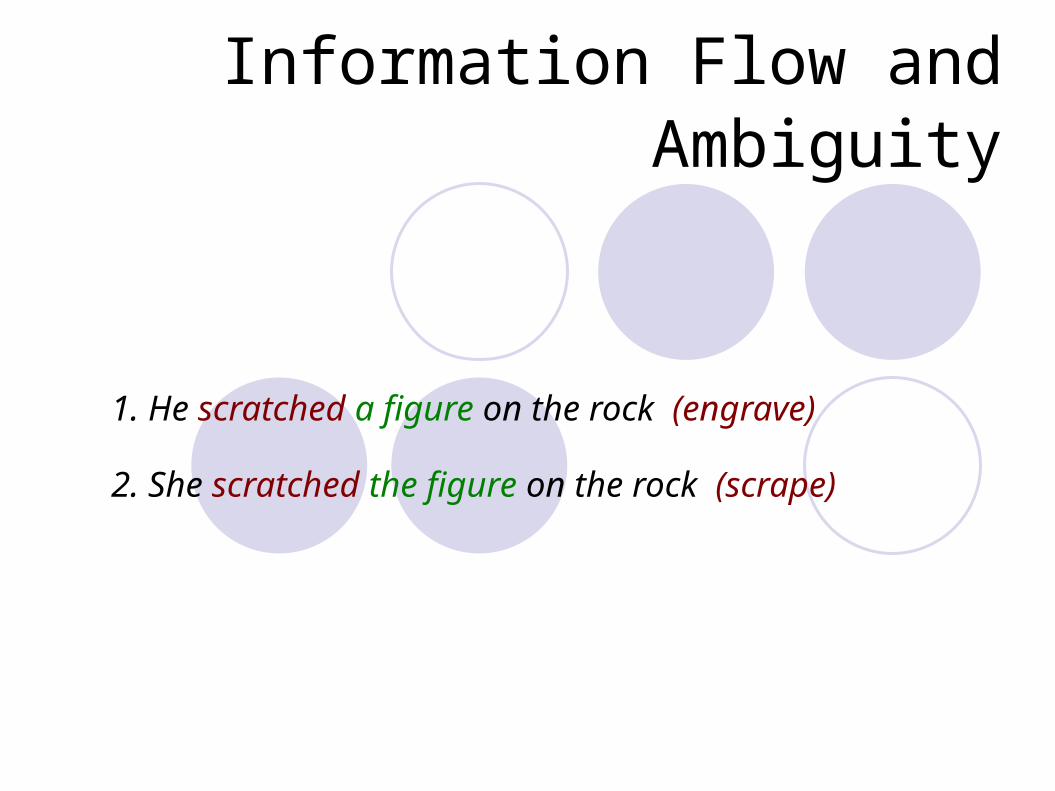
Information Flow and Ambiguity
1. He scratched a figure on the rock (engrave)
2. She scratched the figure on the rock (scrape)

Human beings use
World knowledge
Context
Cultural knowledge and
Language conventions
To resolve ambiguities. Can we provide all this knowledge to the machine ?

Machine Translation: Current Trends
Techniques being used: Statistical
Statistical methods: Inherent limitation
Can never give a 100% reliable system
End user can never be sure about the Correctness.
Current MT systems CAN NOT give a system for
users who want to ACCESS a text in other languages

Anusaaraka
An Incremental Machine Translation
Layered output
First layer a Language ACCESOR
Successive layers more and more close
to MT

What is an Accessor ?
Gist Terminal is a concrete example of SCRIPT ACCESSOR
(Developed by IIT Kanpur, and marketed by C-DAC)
One can access any text in any Indian script
through
-- enhanced Devanagari script.

For example, the following two Telugu words
Can be displayed in enhanced Devanagari script.

Salient Features Faithful representation
Reversibility
Anusaaraka tries to generalise and apply this
philosophy to the problem of language
conversion which is several order more
complex

Languages Differ
Script (For written language)
Vocabulary
Grammar
These differences can be considered
as a measure of language distance

Language Distance
Script -------------- Vocabulary----------Grammar Urdu-> Hindi
Telugu -> Hindi Telugu->Hindi
English -> Hindi English-> Hindi English->Hindi
Anusaaaraka follows the approach of gradually reducing the distance

Anusaaraka Solutions
Transliteration
Padasutra for Vocabulary substitution
WSD for word level ambiguity
Transfer Grammar

Transfer Grammar
Eng : This chair has been sat on
Transli : दिदसु चे�यारा है�ज़ ब ने सु�ट आने
Lexical substitution : याहै याहै क� सु" ब�ठा� जा� चे�क� है� प्रा
Transfer grammar :ि्िि्िा� इसु क� कक� सु" प्रा ब�ठा� जा� चे�क� है�

Padasutra (1/2)
Get the core meaning of a polysemous word State it in a formulaic formठातिहैसुThis appears in the first Write notes to show the relatedness of various senses The user can refer to it if required

Padasutra (2/2)English verb 'have' 1. She has tea in the morning
vaha(nom) subaha caaya piitii hai (drink)
2. She has bread in the morning
vaha(nom) subaha breda khaatii hai (eat)
3. She has fever
usako bukhaara hai (be)
4. She has my book
usake paasa merii pustaka hai (posses+be)
5. She has three children
usake tiina bacce haiM

Word Sense Disambiguation (WSD)
WSD is
Automatically selecting the appropriate sense in a given context
Requires linguistic Resources and Tools
Linguistic resources : dictionaries, thesauri, hand crafted rules etc Linguistic tools : POS tagger, Parser, MWE Identifier etc

WSD : Possible Solutions
Two major approachesManually crafted rules
Costly Fragile
Machine Learning/Statistical

Anusaaraka Solution to WSD (1/4)
Major bottleneck
Requires large number of disambiguation rules
Anusaaraka combines statistically generated rules with manually created rules
WSD rules can be revised/added over a period of time
Simplify the method for the above
Involve large number of people to prepare rules
Anusaarak uses 'clips' an Expert System Shell for developing rules

Anusaaraka Solution (2/4)
Divide the problem into small bite size with considerable time
Bite size – 4 pagesTime – Two years
Relevant in Indian conditions as we have large manpower

Anusaaraka Solution (3/4)
Use manually craftd rules for WSD
Which means developing WSD rules for approximately 10,000 words
Handling MWE in lakhs

Anusaarka Solution (4/4)
Use Cambridge Advanced Learners dictionary for distributing words to the rule developers
The dictionary has Approx 1600 pagesAllot 4 pages to one person
1600/4=400

Anusaaraka Goals
Provide an open source usable system to the users
The system should facilitate accessing another language
Show the usability of Indian traditional grammar system in the modern context Facilitate users to become developers

Anusaaraka Philosophy
No Loss of Information
No efforts should go wasted
Users contribute towards the
development

Anusaaraka is An application of concepts from Panini's
Ashtadhyayi to contemporary problems
• pravitti nimitta
• sannidhi (proximity)
• yogyataa (qualification)
• aakaaMkshaa (expectation)
• kaarakas (role-relations)
• etc

Anusaaraka is A tool for overcoming language barriers An application of concepts from Panini's ashtadhyayi to contemporary problems.
An exploration of the information dynamics in language
A better approach for building Machine Translation systems
A Workbench for NLP students An opportunity for the masses to be IT contributors rather than mere IT consumers
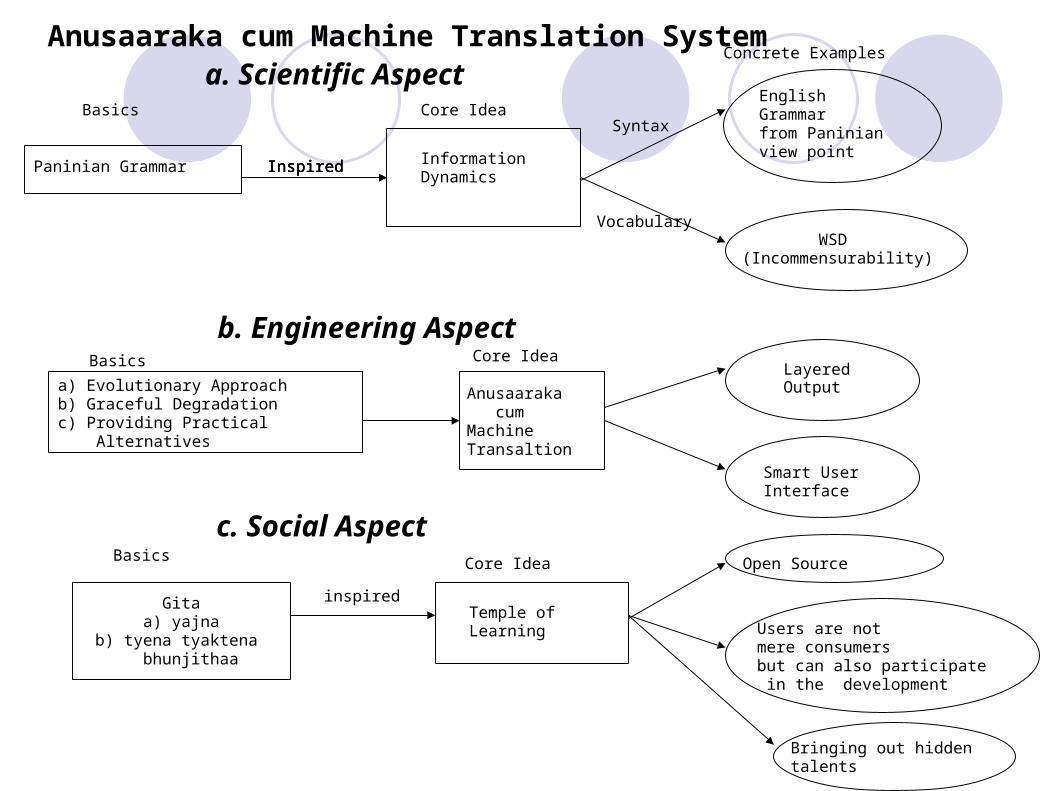
Paninian Grammar Inspired Information Dynamics
Basics Core IdeaSyntax
Vocabulary
EnglishGrammarfrom Paninianview point
WSD(Incommensurability)
Concrete ExamplesAnusaaraka cum Machine Translation System
a. Scientific Aspect
b. Engineering AspectBasics
a) Evolutionary Approachb) Graceful Degradationc) Providing Practical Alternatives
Anusaaraka cumMachine Transaltion
Core IdeaLayered Output
Smart UserInterface
c. Social AspectBasics
Gitaa) yajna
b) tyena tyaktena bhunjithaa
Temple of Learning
Core Idea
InspiredInspired
inspired
Open Source
Users are not mere consumersbut can also participate in the development
Bringing out hidden talents

What Next ?
Developing Anusaaraka as an NLP Workbench
Ideas are welcome on how to proceed on this
The Following discussion will focus on this


















