
InfiniDB Overview - MariaDB.org - Supporting continuity …€¦ · PPT file · Web view ·...
31
InfiniDB Overview
Transcript of InfiniDB Overview - MariaDB.org - Supporting continuity …€¦ · PPT file · Web view ·...

InfiniDB Overview

What is InfiniDB?
• Massively Parallel MySQL Storage Engine for Fast
Analytics• Linear scale to handle exponential growth• Open-Source• Runs on premise, on AWS cloud or Hadoop HDFS
cluster• Standard ANSI SQL compliance• First MySQL storage engine to support ANSI SQL11-
compliant windowing functionsCopyright © 2014 InfiniDB. All Rights Reserved.

3
Custom Handler Class
InfiniDB Server
User Module
Performance Module(s)
Storage
User Connections
MySQL----------------------- InfiniDB ExeMgr
MySQL Functions• MySQL Client• MySQL Connectivity (JDBC, ODBC)• MySQL Security• Initial SQL Statement Parsing• Initial SQL Optimization
< Custom Handler Class >• Execute final sort and final limit • Display final results
--------------------------------------------------------------------- InfiniDB ExeMgr Functions
• SQL Optimization• Distribute work for scan, filter, join,
functions, expressions, group by, aggregation, etc. to the all available Performance Modules to be run in parallel.
• Collect the results returned by the Performance Modules
• Return the final results to MySQL for display

4
InfiniDB Design Principles®
Scalable
Fast Simple

InfiniDB Parallelism
User Module – Processes SQL Requests Performance Module – Executes the Queries
or
Single Server MPP
Copyright © 2014 InfiniDB. All Rights Reserved.

6
Tiered MPP Building BlocksModule Process Functionality Value
MySQL• Hosts MySQL • Connection management• SQL parsing & optimization
Familiar DBMS interface Leverages existing partner integrations Delivers full SQL syntax support
Extent Map• Abstracts physical and logical
storage• Metadata store
Enables shared nothing and shared everything storage
Enables partition elimination Built-in failover
ExeMgr• Work distribution• Final results management and
aggregation
Independent scalability and tunable concurrency
Multi-threaded to take advantage of multi-core HW platforms
SQL

7
Tiered MPP Building BlocksModule Process Functionality Value
PrimProc
• Scale-out cache management• Distributed scan, filter, join and
aggregation operations• Resource management
Independent scalability and tunable performance
Multi-threaded to take advantage of multi-core HW platforms
Data• High Speed Bulk Load• Transactional DML and DDL• Online schema extensions
Enables concurrent reads and writes, non-blocking read enabled
Multi-threaded to take advantage of multi-core HW platforms
Data Blocks

InfiniDB Foundation - Parallelism
8
• Purpose-built C++ engine• Parallelism is at the thread level• Example: 12 PM Servers with 8 cores each
yields 96 parallel processing engines. • SQL is translated into thousands or tens of
thousands of discrete jobs or “primitives”.• The UM sends primitives to the processing
engines.

InfiniDB Parallelism – Fixed Thread Pool
Copyright © 2014 InfiniDB. All Rights Reserved.
Single Server MPP
Local disk / EBS GlusterFS / HDFS
Primitives are issued into a thread queue within each performance module.
• User Module – Processes SQL Requests• Performance Module – Executes the Queries

10
Architectural DifferentiationGreenplum, Netezza, etc
Database Layer 1- Executing SQL
Database Layer 2- Executing SQL
Database Layer- Executing SQL
Block Processing Layer- Custom DoW
ParentProcess
ParentProcess
WorkerProcess
WorkerProcess
WorkerProcess

11
Architectural Differentiation
Threads operate from queue, dedicated for a fraction of a second.
Threads dedicated for the duration of a query.
ParentProcess
ParentProcess
WorkerProcess
WorkerProcess
WorkerProcess
Greenplum, Netezza, etc

12
InfiniDB Design Principles®
Scalable
Fast Simple
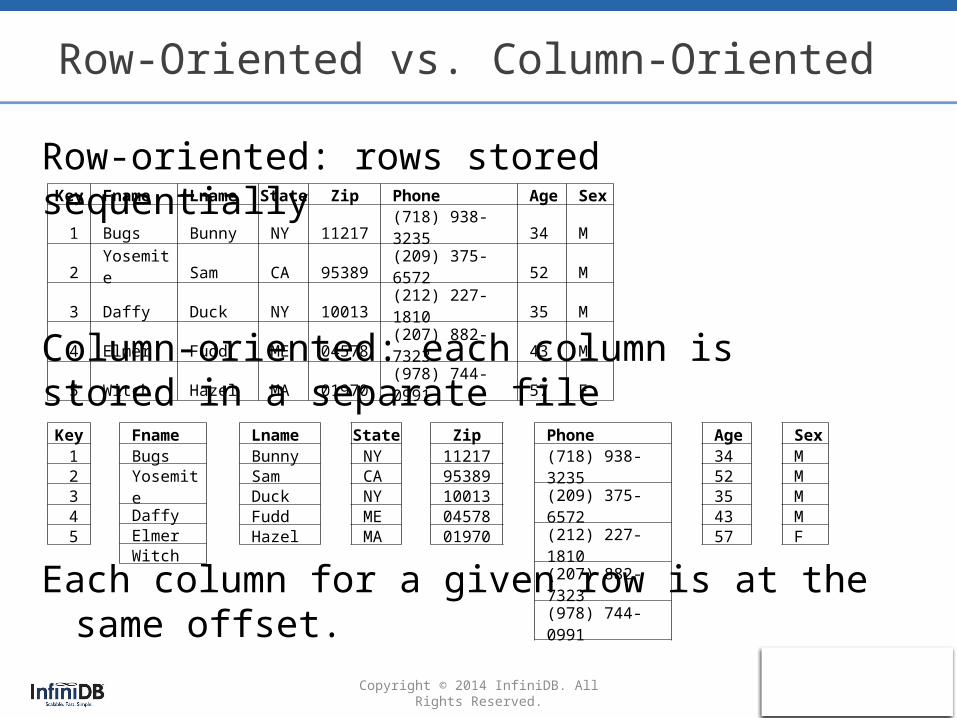
Row-Oriented vs. Column-Oriented
Copyright © 2014 InfiniDB. All Rights Reserved.
Row-oriented: rows stored sequentially
Column-oriented: each column is stored in a separate file
Each column for a given row is at the same offset.
Key Fname Lname State Zip Phone Age Sex1 Bugs Bunny NY 11217 (718) 938-3235 34 M2 Yosemite Sam CA 95389 (209) 375-6572 52 M3 Daffy Duck NY 10013 (212) 227-1810 35 M4 Elmer Fudd ME 04578 (207) 882-7323 43 M5 Witch Hazel MA 01970 (978) 744-0991 57 F
Key12345
FnameBugsYosemiteDaffyElmerWitch
LnameBunnySamDuckFuddHazel
StateNYCANYMEMA
Zip1121795389100130457801970
Phone(718) 938-3235(209) 375-6572(212) 227-1810(207) 882-7323(978) 744-0991
Age3452354357
SexMMMMF

2-Dimensional Data Partitioning
Copyright © 2014 InfiniDB. All Rights Reserved.
• Vertical Partitioning by Columno Not Column-Family (no relation to HBase) o Only do I/O for columns requested
• Horizontal Partitioning by range of rowso Meta-data stored within in-memory structure
• 10 TB of data maps to ~150k-300k discrete files.

15
Column Restriction and Projection
• Automatic Vertical Partitioning + Horizontal Partitioning• Just-In-Time Materialization
|-------------- Colum
n # Four ---------------|
|-------------- Colum
n # Six ---------------|
Extent # 5
|-------- Colum
n # Seventeen -----------|
Extent # 27
Filter 1
Filter 2
Filter 3
Projection Projection

16
InfiniDB Design Principles®
Scalable
Fast Simple

17
Simplicity – Automated Everything Column storageCompression /compression typeNo index build or maintenance requiredExtent Map partitioning – Vertical/
HorizontalDistribution of data across server/disk
resourcesDistribution of workAd-hoc performance

18
InfiniDB What’s New®
Scalable
Fast Simple• Open Source – GPL v2• New Company Name• Funding• InfiniDB for Hadoop• Windowing Analytic Functions

What is InfiniDB for Hadoop? Fast SQL for Hadoop offering for real-time and
ad-hoc reporting and analytics Non-map/reduce engine for real-time SQL 40x to 100x faster than Hive
SQL in Hadoop Reads and writes directly to HDFS/GPFS
Best of breed SQL in Hadoop Superior ad-hoc usage, syntax vs. Impala/Presto
MySQL Compatibility InfiniDB presents Hadoop as MySQL data source

20
InfiniDB Background – InfiniDB for Hadoop InfiniDB is a non-map/reduce engine Reads and writes natively to HDFS
Map ReduceHBase
InfiniDBfor
Hadoop
Hadoop Distributed File System
Pig/Hive

Value Proposition For InfiniDB for Hadoop
Enables access to Hadoop data via familiar interface
Response to competitive challenge from Cloudera Impala
Complete the Hadoop Checklist Cost-effective storage Robust transforms via map/reduce Real-time SQL for analytics with InfiniDB for
Hadoop

Benchmark Hive, Presto, Impala, InfiniDB
Copyright © 2014 InfiniDB. All Rights Reserved.
http://infinidb.co/system/files/RadiantAdvisors_Benchmark_SQL-on-Hadoop_2014Q1.pdf

PARTITION and FRAME For each row, calculation for an aggregation is done over a FRAME
of rows The PARTITION of a row is the group of rows that have a value for
a specific column same as the current row FRAME for each row is a subset of a PARTITION for the row SELECT x,y,sum(x) OVER (PARTITION BY y RANGE BETWEEN
CURRENT ROW AND UNBOUNDED FOLLOWING) FROM a
23
Row Number X Y PARTITION FRAME FRAME FRAME FRAME
1 1 1 Partition for rows 1 to 4
Frame for row 1
sum(x) =22
Frame for row 2sum(x) = 21
Frame for row 3sum(x) = 17
Frame for row 4sum(x) = 10
2 4 1
3 7 1
4 10 1
5 2 2 Partition for rows 5 to 7
Frame for row 5
sum(x) = 15
Frame for row 6sum(x) =
13
Frame for row 7sum(x) = 8
6 5 2
7 8 2
8 3 3 Partition for rows 8 to 10
Frame for row 8
sum(x) = 18
Frame for row 9sum(x) =
15
Frame for row 10sum(x) = 9
9 6 3
10 9 3

24
InfiniDB Use Cases®
Scalable
Fast Simple
• Who is using it?• When to use it?

InfiniDB Customers
Copyright © 2014 InfiniDB. All Rights Reserved.

InfiniDB’s place in the Big Data world
• Designed for high performance analytics• Provides flexibility for ad hoc queries
Not suited for OLTP, NoSQL, KeyValue
Copyright © 2014 Calpont. All Rights Reserved.

Workload – Query Vision/Scope
General DBMS missed the target(dated database technology generally suboptimal)
Copyright © 2014 Calpont. All Rights Reserved.
1 100 10,000 1,000,000 100,000,000 10,000,000,000
Query Vision/Scope
OLTP/NoSQL Workloads Analytic Workloads

28
What is your typical query?
1 100 10,000 1,000,000 100,000,000 10,000,000,000
Query Vision/Scope
OLTP/NoSQL Workloads Analytic Workloads
• There is no “average” query.• The challenges are at the extremes:
o The challenge of high concurrency levels with OLTP/NoSQL.o The challenge of latency for very large queries.
• Most use cases imply multiple data technologies.
29
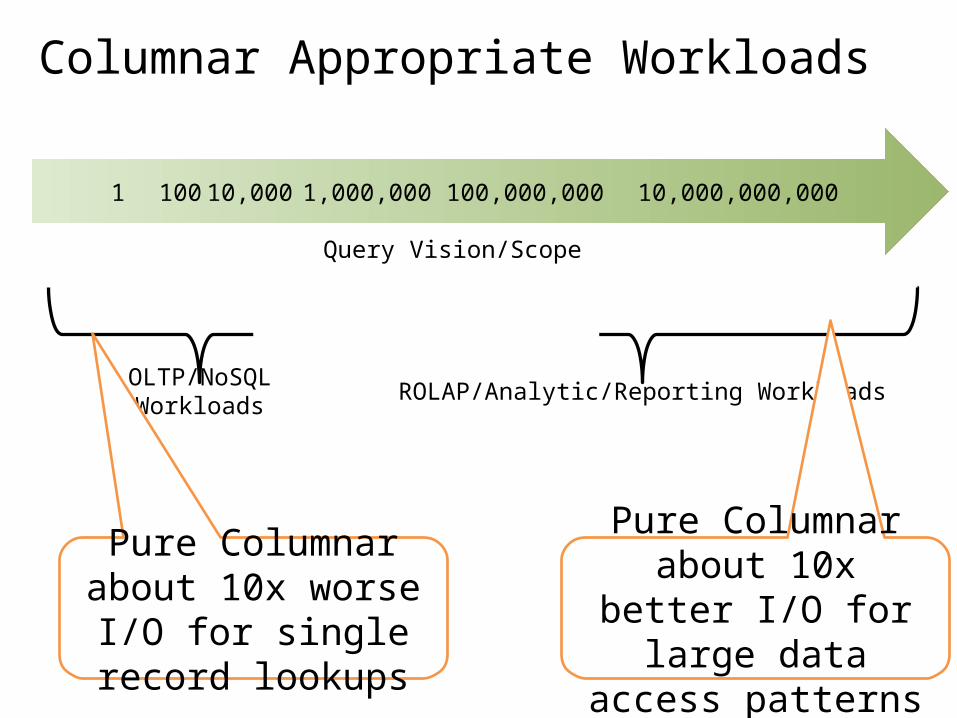
Columnar Appropriate Workloads
1 100 10,000 1,000,000 100,000,000 10,000,000,000
Query Vision/Scope
OLTP/NoSQL Workloads ROLAP/Analytic/Reporting Workloads
Pure Columnar about 10x worse I/O for
single record lookups
Pure Columnar about 10x better I/O for large
data access patterns

Benefits of InfiniDB
30
Real-time, Consistent Query Performance
Linear Scale for Massive Data
Removes Limits to Dimensions and Granularity
Easy to Deploy and Maintain

Core Features of InfiniDB
Scalable MPP architecture Performant ad hoc analysis Consistent query response time Simplified data administration Analytic window functions Native MySQL® driver support Open source license Deployable on premise, in the cloud, &
on Apache Hadoop™ Optional Enterprise support subscription
Copyright © 2014 Calpont. All Rights Reserved.


















