
MIS2502: Data Analytics MySQL and SQL Workbench David Schuff [email protected] .
Upload
jared-ellisCategory
view
214download
0
Improving the Speed and Quality of Architectural Performance Evaluation
Vijay S. Pai
with contributions from: Derek Schuff, Milind Kulkarni
Electrical and Computer EngineeringPurdue University

Outline
•Intro to Reuse Distance Analysis▫Contributions
•Multicore-Aware Reuse Distance Analysis▫Design▫Results
•Sampled Parallel Reuse Distance Analysis▫Design: Sampling, Parallelisim▫Results▫Application: selection of low-locality code
2

Reuse Distance Analysis•Reuse Distance Analysis (RDA):
architecture-neutral locality profile▫Number of distinct data referenced
between use and reuse of data element▫Elements can be memory pages, disk
blocks, cache blocks, etc•Machine-independent model of locality
▫Predicts hit ratio in any size fully-associative LRU cache
▫Hit ratio in cache with X blocks = % of references with RD < X
3

Reuse Distance Analysis
•Applications in performance modeling, optimization▫Multiprogramming/scheduling
interaction, phase prediction▫Cache hint generation, restructuring
code, data layout
4

Reuse Distance Profile Example5

Reuse Distance Measurement
•Maintain stack of all previous data addresses
•For each reference:▫Search stack for referenced address▫Depth in stack = reuse distance
If not found, distance = ∞▫Remove from stack, push on top
6

Example
7
A
A
BA
∞
CB
A
C
B
A
C
B
A A
Address
Distance
B C C B A
∞ ∞ 0 1 2
B
C

RDA Applications•VM page locality [Mattson 1970]•Cache performance prediction [Beyls01,
Zhong03]•Cache hinting [Beyls05]•Code restructuring [Beyls06], data layout
[Zhong04]•Application performance modeling [Marin04]•Phase prediction [Shen04]•Visualization, manual optimization
[Beyls04,05,Marin08]•Modeling cache contention
(multiprogramming) [Chandra05,Suh01,Fedorova05,Kim04]
8

Measurement Methods
•List-based stack algorithm is O(NM)•Balanced binary trees or splay trees
O(NlogM)▫[Olken81, Sugumar93]
•Approximate analysis (tree compression) O(NloglogM) time and O(logM) space [Ding03]
9

Contributions
•Multicore-Aware Reuse Distance Analysis▫First RDA to include sharing and invalidation▫Study different invalidation timing strategies
•Acceleration of Multicore RDA▫Sampling, Parallelization▫Demonstration of application: selection of
low-locality code▫Validation against full analysis, hardware
•Prefetching model in RDA▫Hybrid analysis
10

Outline
•Intro to Reuse Distance Analysis▫Contributions
•Multicore-Aware Reuse Distance Analysis▫Design▫Results
•Sampled Parallel Reuse Distance Analysis▫Design: Sampling, Parallelisim▫Results▫Application: selection of low-locality code
11

Extending RDA to Multicore
•RDA defined for single reference stream▫No prior work accounts for multithreading
•Multicore-aware RDA accounts for invalidations and data sharing▫Models locality of multi-threaded programs▫Targets multicore processors with private
or shared caches
12

Multicore Reuse Distance
•Invalidations cause additional misses in private caches▫2nd order effect: holes can be filled without
eviction•Sharing affects locality in shared caches
▫Inter-thread data reuse (reduces distance to shared data)
▫Capacity contention (increases distance to unshared data)
13

Invalidations
14
A
A
BA
∞
CB
A
C
B
A
C
(hole) (hole)
Address
Distance (unaware)B C C B A
∞ ∞ 0 1 ∞
B
C
C
B
A
ARemote write
(hole)
A
∞ ∞ ∞ 0 1 2
B

Invalidation Timing
•Multithreaded interleaving is nondeterministic▫If no races, invalidations can be propagated
between write and next synchronization•Eager invalidation – immediately at write•Lazy invalidation – at next synchronization
▫Could increase reuse distance•Oracular invalidation – at previous sync.
▫Data-race-free (DRF) → will not be referenced by invalidated thread
▫Could decrease reuse distance
15

Sharing
16
A
A
BA
∞
CB
A
C
B
A
Address
Distance (unaware)B C C B A
∞ ∞ 0 2 1
ARemote write
∞ ∞ ∞ 0 1 2
2
A
C
B
B
A
C
B
A
C

17
MCRD Results

18

19
Impact of Inaccuracy

20

Summary So Far
•Compared Unaware and Multicore-aware RDA to simulated caches▫Private caches: Unaware 37% error, aware
2.5%▫Invalidation timing had minor affect on
accuracy▫Shared caches: Unaware 76+%, aware
4.6%•Made RDA viable for multithreaded
workloads
21

Problems with Multicore RDA
•RDA is slow in general▫Even efficient implementations require
O(log M) time per reference•Multi-threading makes it worse
▫Serialization▫Synchronization (expensive bus-locked
operations on every program reference)•Goal: Fast enough to use by programmers
in development cycle
22

Accelerating Multicore RDA
•Sampling
•Parallelization
23

Reuse Distance Sampling
•Randomly select individual references▫Select count before sampled reference
Geometric distribution, expect 1/n sampled references n = 1,000,000
▫Fast mode until target reference is reached
24
References
Fast mode

Reuse Distance Sampling
•Monitor all references until sampled address is reused (Analysis mode)▫Track unique addresses in distance set▫RD of the reuse reference is size of distance set
Return to fast mode until next sample
25
References
Fast mode Analysis mode

Reuse Distance Sampling
•Analysis mode is faster than full RDA▫Full stack tracking not needed▫Distance set implemented as hash table
26
References
Fast mode Analysis mode

RD Sampling of MT Programs
•Data Sharing•Invalidation
▫Invalidation of tracked address▫Invalidation of address in the distance set
27

RD Sampling of MT programs•Data Sharing
▫Analysis mode sees references from all threads▫Reuse reference can be on any thread
28
Fast mode Analysis mode
Tracking thread
Remote thread

RD Sampling of MT programs
•Invalidation of tracked address▫∞ distance
29
Fast mode Analysis mode
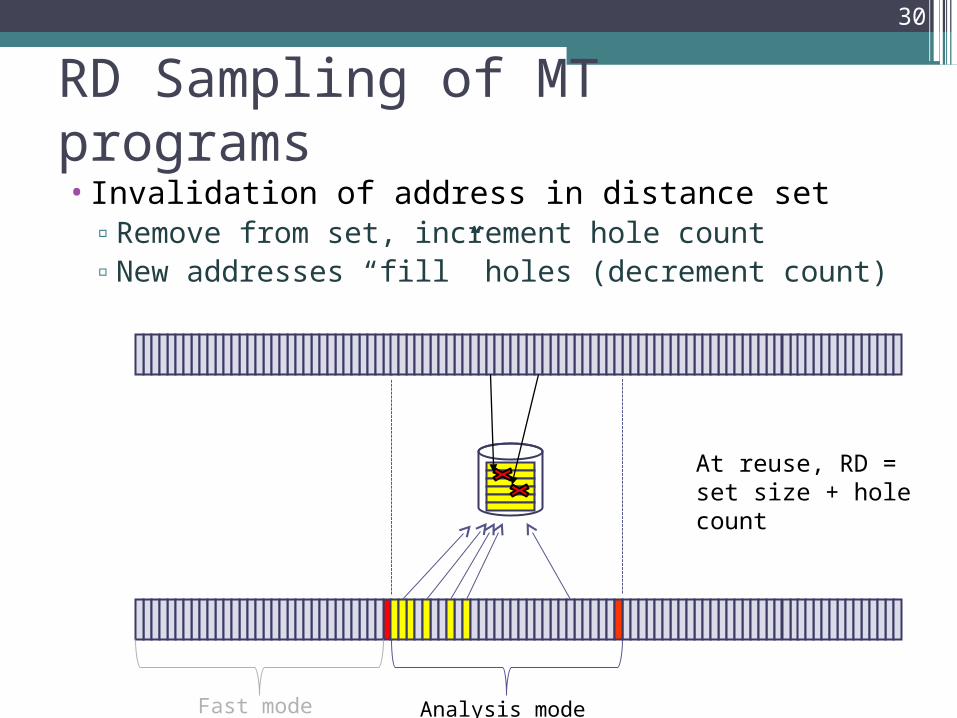
RD Sampling of MT programs
• Invalidation of address in distance set▫Remove from set, increment hole count▫New addresses “fill” holes (decrement count)
30
Fast mode Analysis mode
At reuse, RD = set size + hole count

Parallel Measurement
•Goals: Get parallelism in analysis, eliminate per-ref synchronization
•2 properties facilitate▫Sampled analysis only tracks distance set,
not whole stack Allows separation of state
▫Exact timing of invalidations not significant Allows delayed synchronization
31

Parallel Measurement
•Data Sharing▫Each thread has its own distance set▫All sets merged on reuse
32
Fast mode Analysis mode
Tracking thread
Remote thread
At reuse, RD = set size

Parallel Measurement• Invalidations
▫Other threads record write sets▫On synchronization, write set contents invalidated
from distance set
33
Fast mode Analysis mode
Tracking thread
Remote thread

Pruning
•Analysis mode stays active until reuse▫What if address is never reused?▫Program locality determines time
spent in analysis mode•Periodically prune (remove & record)
the oldest sample▫If its distance is large enough, e.g. top
1% of distances seen so far▫Size-relative threshold allows different
input sizes
34

Results
•Comparison with full analysis▫Histograms▫Accuracy metric
•Performance▫Slowdown from native
35

Example RD Histograms
36
Reuse distance (64-byte blocks) Reuse distance (64-byte blocks)

Example RD Histograms
37
Reuse distance (64-byte blocks) Reuse distance (64-byte blocks)
Slowdown of full analysis perturbs execution of spin-locks, inflates 0-distance bin in histogram

Example RD Histograms
38
Reuse distance (64-byte blocks) Reuse distance (64-byte blocks)

Results: Private Stacks
•Error metric used by previous work:▫Normalize histogram bins▫Error E = ∑i(|fi - si|)
▫Accuracy = 1 – E / 2•91%-99% accuracy (avg 95.6%)•177x faster than full analysis•7.1x-143x slowdown from native (avg
29.6x)▫Fast mode: 5.3x▫80.4% of references in fast mode
39

Results: Shared Stacks
•Shared reuse distances depend on all references by other threads▫Not just to shared data▫Relative execution rate matters▫More variation in measurements and
in real execution•Compare fully-parallel sample
analysis mode to serialized sample analysis mode▫Round-robin ensures threads progress
at same rate as in non-sampled analysis
40

Accuracy Slowdown
Parallel Sampling 74.1% 80
Sequential Sampling
88.9% 265
41
FT Histogram
Reuse distance (64-byte blocks)

Performance Comparison
• Single-thread sampling [Zhong08]▫ Instrumentation 2x-4x (compiler), 4x-10x
(Valgrind) ▫ Additional 10x-90x with analysis• Approximate non-random sampling
[Beyls04]▫ 15x-25x (single-thread, compiler)• Valgrind, our benchmarks▫ Instrumentation 4x-75x, avg 23x▫ Memcheck avg 97x
42

Low-locality PC Selection
•Application: Find code with poor locality to assist programmer optimization▫e.g. n PCs account for y% of misses at cache
size C•Select C such that miss ratio is 10%, find
enough PCs to cover 75/80/90/95% of misses•Use weight-matching to compare selection
against full analysis•Selection accuracy 91% - 92% for private
and shared caches▫In spite of reduced accuracy in parallel-shared
43

Smarter Multithreaded Replacement• Shared cache management is challenging
▫Benefits of demand multiplexing▫Cost of performance interference
• Most work addresses multi-programming▫Destructive interference only▫Per-benchmark performance targets
• Multi-threading presents opportunities and challenges▫Constructive interference, process performance
target▫Reuse distance profiles can help understand
needs▫Work in progress!
44

Conclusion•Two techniques to accelerate multicore-
aware reuse distance analysis▫Sampled analysis▫Parallel analysis▫Private caches: 96% accuracy, 30x native▫Shared caches: 74/89% accuracy, 80/265x
native•Demonstrate effectiveness for selection of
code with low locality▫91% weight-matched coverage of PCs
•Other applications in progress•Validated against hardware caches
▫7-16% average error in miss prediction
45

Questions?
46


















