
Universal DNA Arrays Ion Mandoiu Computer Science & Engineering Department.
date post
20-Dec-2015Category
view
215download
1
Improved Tag Set Design and Multiplexing Algorithms
for Universal Arrays
Ion Mandoiu
Claudia Prajescu
Dragos TrincaComputer Science & Engineering Department
University of Connecticut

Overview
Universal DNA Tag Arrays Tag Set Design Problem Tag Assignment Problem Conclusions

Watson-Crick Complementarity
• Four nucleotide types: A,C,T,G
• A’s paired with T’s (2 hydrogen bonds)
• C’s paired with G’s (3 hydrogen bonds)

Microarray Applications
• Gene expression (transcription analysis)
• Genomic-based microorganism identification
• Single Nucleotide Polymorphism (SNP) genotyping
• Molecular diagnosis/susceptibility to disease

Microarray Technologies• Arrays of cDNAs
– Obtained by reverse transcription from Expressed Sequence Tags (ESTs)
• Oligonucleotide arrays– Short (20-60bp) synthetic DNA strands
• Limitations– cDNA arrays are inexpensive, but limited to
measuring gene expression– Oligonucleotide arrays are flexible, but
expensive unless produced in large quantities

Universal DNA Tag Arrays
• [Brenner 97, Morris et al. 98] “Programmable” oligonucleotide arrays – Array consisting of application independent
oligonucleotides called tags– Two-part “reporter” probes: aplication specific primers
ligated to antitags – Detection carried by a sequence of reactions separately
involving the primer and the antitag part of reporter probes

Universal Tag Array Experiment
+

Universal Tag Array Advantages
• Cost effective– Same array used in many analyses economies of scale
• Easy to customize– Only need to synthesize new set of reporter probes
• Reliable– Solution phase hybridization better understood than
hybridization on solid support

Overview
Universal DNA Tag Arrays Tag Set Design Problem Tag Assignment Problem Conclusions

Tag Set Requirements• Hybridization constraints
(H1) Antitags hybridize strongly to complementary tags
(H2) No antitag hybridezes to a non-complementary tag
(H3) Antitags do not cross-hybridize to each other
t1t1 t2t2 t1 t2t1

Complementary Oligo Hybridization
• Melting temperature Tm: temperature at which 50% of duplexes are in hybridized state
• 2-4 rule
Tm = 2 #(As and Ts) + 4 #(Cs and Gs)
• More accurate models exist, e.g., the near-neighbor model

Non-Complementary Oligo Hybridization Models
• Hamming distance– Assumes DNA is rigid strand
• Longest Common Subsequence/Edit Distance– Assumes DNA is infinitely elastic
• Near-neighbor with mismatches – Resulting thermodynamic alignment problem is
NP-Hard

C-token Hybridization Model
• Proposed by [Ben-Dor et al. 00]
• Based on nucleation complex theory– Duplex formation between non-complementary
oligos starts with the formation of a nucleation complex between perfectly complementary substrings
– The nucleation complex must be sufficiently stable, i.e., must have weight c, where weight(A)=weight(T)=1, weight(C)=weight(G)=2

c-h Code Problem
• c-token: left-minimal DNA string of weight c, i.e.,– w(x) c
– w(x’) < c for every proper suffix x’ of x
• A set of tags is called c-h code if(C1) Every tag has weight h
(C2) Every c-token is used at most once
• c-h code problem: given c and h, find largest c-h code– [Ben-Dor et al.00] algorithm based on DeBruijn sequences

Extended c-h Codes
• Antitag-to-antitag hybridization– Formalization in c-token hybridization model:
(C3) No two tags contain complementary substrings of weight c
• Tag length constraints– Industry designs (e.g. Affymetrix GenFlex Arrays) require
that tags have fixed length (20 nucleotides)

c-Token Counting
• W=weight 1 nucleotide, S=weight 2 nucleotide
• Gn = #strings of weight n:G1 = 2; G2 = 6; Gn = 2Gn-2 + 2Gn-1
• [Ben-Dor et al.00] c-tokens in a tag have tail weight h-c+1
At most (2Gc-1 +6Gc-2+8Gc-3)/(h-c+1) tags in a valid c-h code
Token type Max #tokens Max Tail Weight
<c-2>S 2 Gc-2 4 Gc-2
S<c-3>S 4 Gc-3 8 Gc-3
<c-1>W 2 Gc-1 2 Gc-1
S<c-2>W 2 Gc-2 2 Gc-2
Total 2Gc-1 +4Gc-2+4Gc-3 2Gc-1 +6Gc-2+8Gc-3

Upperbounds for Extended c-h Codes
• Theorem: The number of tags in a feasible extended c-h-l code is at most
for odd c, and at most
for even c

Algorithms
• Alphabetic tree search algorithm
- Enumerate candidate tags in lexicographic order, save tags whose c-tokens are not used by previously selected tags
- Easily modified to handle various combinations of constraints
• [MT 05] Optimum c-h codes can be computed in practical time for small values of c by using integer programming
• Maximum integer flow problem w/ set capacity constraints

Experimental Results

Periodic Tags
• c-token uniqueness constraint in c-h code formulation is too strong– c-tokens should not appear in different tags, but is
OK to repeat a c-token in the same tag– Periodic tags make best use of available c-tokens
• [MT05] Tag set design can be cast as a maximum vertex-disjoint cycle packing problem
• Allowing periodic tags yields ~40% more tags

c-token factor graph, c=4 (incomplete)
CC
AAG AAC
AAAA
AAAT

Overview
Background on DNA Microarrays Universal DNA Tag Arrays Tag Set Design Problem Tag Assignment Problem Conclusions

More Possible Mis-Hybridizations
What can be done:
• Leave some tags unassigned
• Distribute primers over multiple arrays
Here we focus on avoiding case (a), primer-to-tag hybridization

Constraints on tag assignment
• If primer p hybridizes with tag t, then either p or t must be left un-assigned, unless p is assigned to t
p
t
t’
p’

Characterization of Assignable Sets
• [Ben-Dor 04] Set P is assignable to T iff X+Y |P|, where, in the hybridization graph induced by P+T – X = number of primers incident to a degree 1 tag
– Y = number of degree 0 tags
Y=2
X=1

MAPS Problem
• Maximum Assignable Primer Set (MAPS) Problem: given primer set P and tag set T, find maximum size assignable subset of P
• [Ben-Dor 04] Greedy deletion heuristic: repeatedly delete primer of maximum weight from P until it becomes assignable, where– Potential of tag t is 2-|P(t)|
– Potential of primer p is sum of potentials of conflicting tags

Universal Array Multiplexing Problem
• Multiplexing Problem: given primer set P and tag set T, find partition of P into minimum number of assignable sets
• [Ben-Dor 04] Repeatedly find approximate MAPS

Integration with Probe Selection
• In practice, several primer candidates with equivalent functionality– In SNP genotyping, can pick primer from either forward and
reverse strand
– In gene expression/identification applications, many primers have desired length, Tm, etc.

Pooled Array Multiplexing Problem
• Given set of primer pools P and tag set T, find a primer from each pool and a partition of selected primers into minimum number of assignable sets

X+Y Characterization no Longer Holds

Pooled Multiplexing Algorithms1. Primer-Del = greedy deletion for pools similar to
[Ben-Dor et al 04]

Pooled Multiplexing Algorithms
2. Primer-Del+ = same, but never delete last primer from pool unless no other choice
3. Min-Pot = select primer with min potential from each pool, then run Primer-Del
4. Min-Deg = select primer with min conflict degree, then run Primer-Del
1. Primer-Del = greedy deletion for pools similar to [Ben-Dor et al 04]

Results: GenFlex Tags, c=8
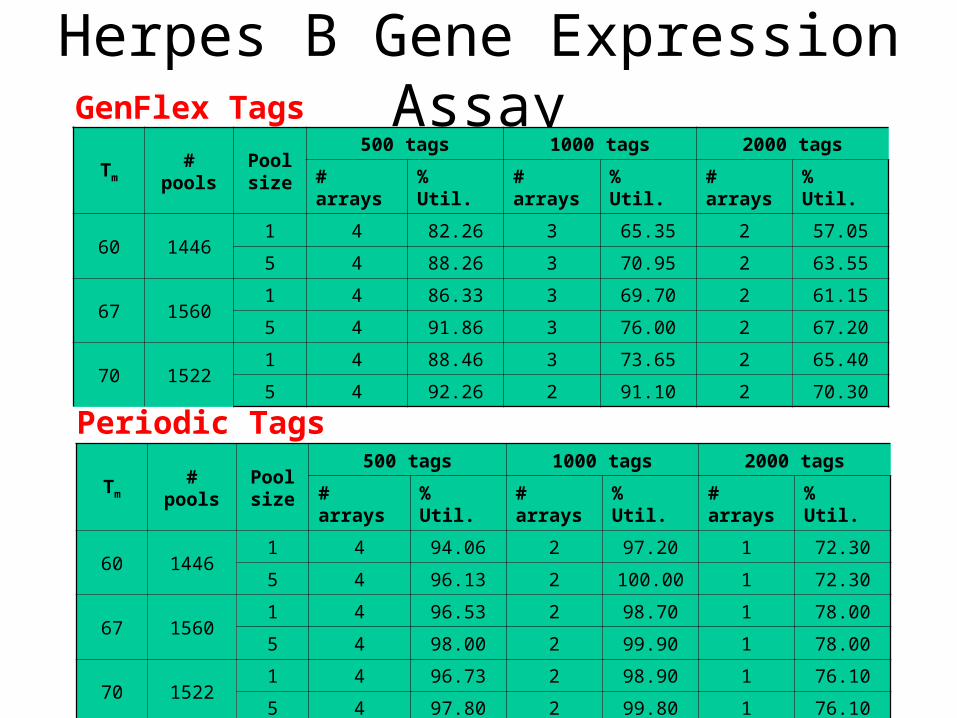
Herpes B Gene Expression Assay
Tm # poolsPool size
500 tags 1000 tags 2000 tags
# arrays % Util. # arrays % Util. # arrays % Util.
60 14461 4 94.06 2 97.20 1 72.30
5 4 96.13 2 100.00 1 72.30
67 15601 4 96.53 2 98.70 1 78.00
5 4 98.00 2 99.90 1 78.00
70 15221 4 96.73 2 98.90 1 76.10
5 4 97.80 2 99.80 1 76.10
Tm # poolsPool size
500 tags 1000 tags 2000 tags
# arrays % Util. # arrays % Util. # arrays % Util.
60 14461 4 82.26 3 65.35 2 57.05
5 4 88.26 3 70.95 2 63.55
67 15601 4 86.33 3 69.70 2 61.15
5 4 91.86 3 76.00 2 67.20
70 15221 4 88.46 3 73.65 2 65.40
5 4 92.26 2 91.10 2 70.30
GenFlex Tags
Periodic Tags

Overview
Background on DNA Microarrays Universal DNA Tag Arrays Tag Set Design Problem Tag Assignment Problem Conclusions

Conclusions
• New techniques for tag set design and tag assignment lead to significantly improved multiplexing rates and more reliable assays
• Other applications of universal tags: – Lab-on-chip, DNA-mediated assembly (e.g., carbon nano-
tubes), DNA computing [Brenneman&Condon 02]
• Other applications of partition/assignment techniques:– Genotyping by mass-spectroscopy [Aumann et al 05]
– Genotyping using l-mer arrays

Acknowledgments
• UCONN Research Foundation


















