



IIML Talk_23012016
63
A talk delivered at IIM Lucknow 24/01/2016 EXTRACT. LOAD. VISUALIZE Becoming a data ninja
-
Upload
manas-ranjan-kar -
Category
Documents
-
view
191 -
download
2
Transcript of IIML Talk_23012016

A talk delivered atIIM Lucknow 24/01/2016
EXTRACT. LOAD. VISUALIZEBecoming a data ninja



• INTRODUCTION
• WEB CRAWLING – THE DESIGN
• DIY – WEB CRAWLING
• TEXT ANALYTICS– THE DESIGN
• CASE STUDY
• DIY – TEXT ANALYTICS
• SOME UNSOLICITED ADVICE? – BUILDING YOUR FIRM
WE WILL TALK OF….

Who are we ?
We are a data science company, founded in 2009– with special interest in making the world an intelligent place to live in.
We identify data and bring it to light, making it visible, cohesive, comparable and easy to understand so that it really does support YOU in making the right decisions.
Who am I ?
I am a Practice Lead at JSM for Natural Language Processing & Machine Learning. I have architected multiple solutions in the area of text analytics for multiple industries like finance, healthcare, food & beverages & hospitality.

AREAS WE WORK ON
PHARMA
Sales Pitch Analysis
RETAIL
Predictive + IoT
FINANCE
Competitive Intelligence
F&B
Customer Insights
MR
Scoping and Product Evaluation
SaaS
NLP, ML, Text

WHAT DO CLIENTS WANT

TOOLS WE PLAY WITH
OPEN SOURCE
Inexpensive
DATABASES
Fast & Scalable
INSIGHTS
Python, R
TECHNIQUES
Latest yet tested
VISUALIZATIONS
D3, GCharts, Tableau
MANAGEMENT
Basecamp

Low Cost Data Collection
+
Comprehensive Analytics

PART 1
Scraping data from the web

HTML PAGES

• HTML pages are like textbooks – content, titles, subtitles, paragraphs and so on
•Javascript adds interactivity to the HTML pages
HTML PAGES

A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index.
The major search engines on the Web all have such a program, which is also known as a "spider" or a "bot."
OVERVIEW– WEB CRAWLING

BUT, YOU ARE MANAGERS.
DO YOU NEED THIS ?

YES !
You don’t need to write a code, promise.*
* T&Cs apply

Tool 1
Import.io

• BEST of the lot
• Gives great flexibility – just click and extract
• Most of the sites are compatible
• Easy CSV/Google Docs Export
• Provides APIs for regular data updates
• Low training time
INTRODUCTION

USE CASES
You want to monitor feedbackhttp://www.consumercomplaints.in/snapdeal-com-b100038

USE CASES
You want to create pricing strategy
http://www.shopclues.com/mobiles/unboxed-mobiles.html

Tool 2
webscraper.io

• Works where Import.io fails
• Bit buggy, but does a god job of providing flexible choices of data extraction
• Most of the sites are compatible
• Easy CSV Export
• NO APIs for regular data updates
• Moderate learning curve
INTRODUCTION

LET’S GET OUR HANDS DIRTY

• Don’t scrape too fast or you will get banned
• Respect robots.txt
• Extract only what you need
• Don’t overload their servers
• Don’t take data what’s not yours – only the data in public domain
PRECAUTIONS

TEXT ANALYTICSMine gold from mountain heaps

As a brand owner with significant investments in social media, the usual questions you might have in mind…
• Is the brand exuding same attributes I intended it to be?
• Is my internet presence helping me ?
• Can I measure my ROI for the money I spent?• What are the measurable metrics for effective social media management?
• When can I exploit emerging trends for my brand?
• How can I understand my customers better?
26
WHAT WOULD YOU WANT?

27
WHAT WOULD YOU WANT TO TARGET?
TRANSACTIONAL CONVERSATIONS
Users talk about current, events, share cat videos and engage in trivial gossip
INFORMATIONAL CONVERSTIONS
Users engage with the brand to air appreciation or
complaints.

28
DATA SOURCES
Social Media
Comments
Brand Website
BlogsCustomer
Emails
Customer Surveys
News Websites

For a brand, say X, there would be thousands of conversations on blogs, websites and social media revolving around X.
Several hundred blog posts are published that contain the keywords “X” This company needs to know:
- How many of these posts are relevant and actually expressing opinions about X?
- How many relevant posts are negative, and how many are positive?
- What particular aspects and features of X are being praised or criticized?
- For all of the above, what is the trend for the past few time periods?
- How is my brand perceived among people demographics?
- How is my brand faring against my competitors?
29
QUESTIONS TO ANSWER

BRIEF TERMINOLOGY
You build an algorithm, machine learns patterns, machine predicts, rinse & repeat.
MACHINE LEARNING
TEXT ANALYTICS
Analyzing unstructured text, assign structure, load into a BI/program to visualize

CASE STUDY
HOW WE HELPED A RESTAURANT SERVE THEIR CUSTOMERS BETTER

PROBLEM STATEMENT
The client had thousands of customer reviews which they wanted to analyse - to understand customer feedback and identify improvement opportunities.
The broad questions we focused on;
What did they say about the restaurant?
Keywords & topics of discussion across the comments
What elements of the restaurant would they want improved? – service, staff behaviour, ambience etc.
When did the customer visit the store?
How is client’s traffic distributed over time?
Ticket sizes across multiple customer dimensions – age, gender, ratings, location, time of visit etc.
Overall customer sentiments & views about UCH
PRIMARY FOCUS AREAS SECONDARY FOCUS AREAS

FOCUS AREAS
TOPICS KEYWORDS SENTIMENT POINT OF SALES

APPROACH
Extract data and validate
Corpus from social media
Tokenise and remove stop
words
Initiate ML models , NER , parsers &
topic algorithms
Initiate detection rules for topics, keywords,
gender, sentiment and multi-word concept
detection
Final Output
PRE - PROCESSING PARSING & ANALYSIS
OUTPUT
Part of Speech (POS)
Tagger

Author Value Type Sentiment
Duncan Riley Samsung Galaxy S6 Entity Positive
Duncan Riley Apple Entity Negative
Duncan Riley LoopPay Entity Neutral
Duncan Riley mobile payments Keyword Positive
Duncan Riley point of sales Keyword Positive
Structuring data from free flowing text is easy to use by existing reporting and business intelligence software. Insights from the final reports can now be used for decision-making by the PR firm and their client
Actual blog post parsed through our SmartText Engine

RATINGS – HOW MUCH IS BETTER ?
Increasing scope of differentiating operational improvements
Decreasing scope of customer loyalty

OUR PLATFORM
7.7 Mn 92.6 K 62.6 K16reviews restaurants user profilestopics
As on 28th October, 2015

LUNCHBOX - SCREENSHOTS & MOCKUPS

Lunchbox – Search Screen
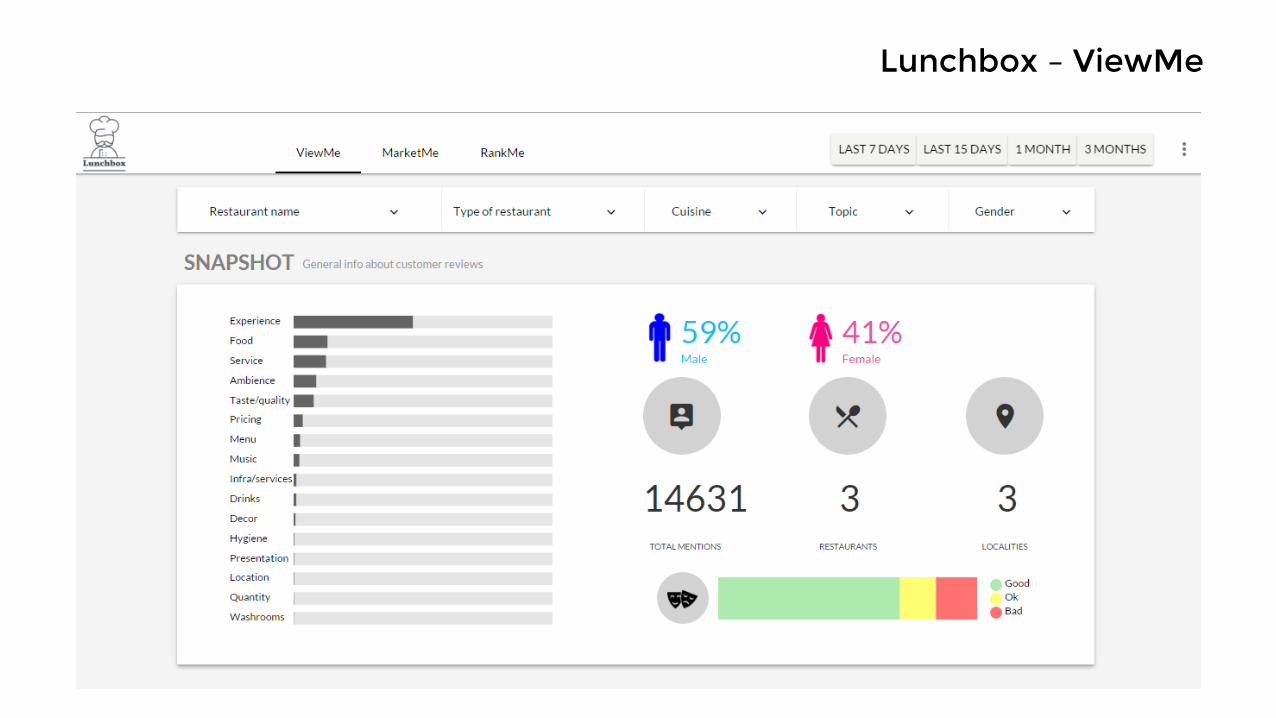
Lunchbox – ViewMe
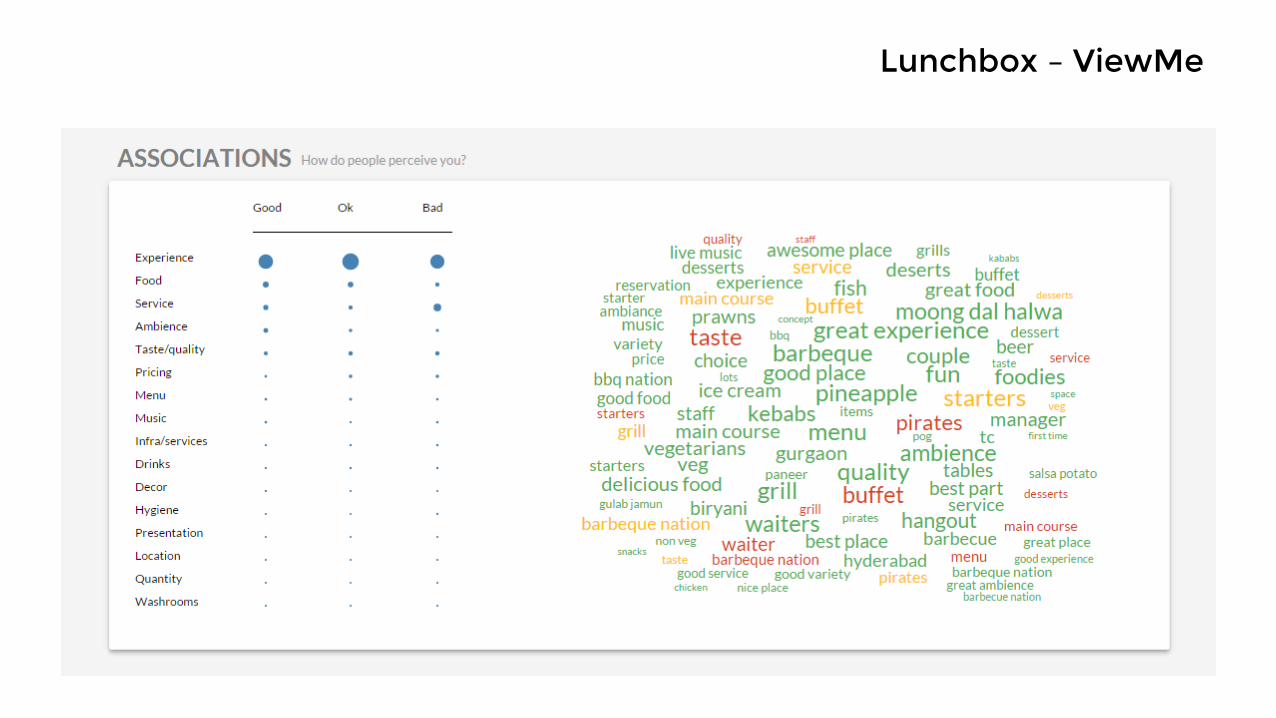
Lunchbox – ViewMe

Lunchbox – RankMe

Lunchbox – MarketMe

BUT HEY ! THIS NEEDS ME TO WRITE A CODE.
YOU LIAR !

SCRAPE > VOSVIEWER > GEPHI > TABLEAU

Scrape the web !
Excel

= ISNUMBER(SEARCH($N$1,H2))

VOSViewer

Gephi
Tableau

LET’S GET OUR HANDS DIRTY, AGAIN !

SOME UNSOLICITED ADVICE ?


• Purse strings WILL be tightened
• Fewer ‘unicorn-level’ valuations
• No investment without revenue or clients
• MVP with traction – a must have
• Acquire or be acquired – or be a acquisition target
• Needs > Wants – solve a problem, but scope it out
•Bootstrapped startups will win, not the valuation-hungry
PREDICTIONS

Don't sell what you do - disguise it
Ex. Create marketing strategy, not analytics/Tableau
Nugget 1

A product that promotes laziness or transfers laziness from seller to buyer will sell
Nugget 2

Is it something that Google/FB provides or can do? Even if it's partial, danger is real.
Nugget 3

The product should be IP-able, scalable and monetize-able -atleast 2/3 must be met
Nugget 4

Read Read Readtechcruch, recode, crunchbase, yourstory, nextbigwhat,
vccircle
Nugget 5

QUESTIONS ?











![IIML 3 4 Probability and Statistics a Review [Compatibility Mode]](https://static.fdocuments.us/doc/165x107/5449d960af795988188b463a/iiml-3-4-probability-and-statistics-a-review-compatibility-mode.jpg)






