
icsp98_1
5
Printed and Handwritten Digits Recognition Using Neural Networks Daniel Cruces Álvarez, Fernando Martín Rodríguez, Xulio Fernández Hermida. Departamento de Tecnologías de las Comunicaciones. Universidad de Vigo. E.T.S.I.T. Ciudad Universitaria S/N.36200 Vigo. SPAIN. Phone: +34-986-812131. Fax: +34-986-812121. E-mail: [email protected], [email protected], [email protected]. ABSTRACT: In this paper, we show a scheme for recognition of handwritten and printed numerals using a multilayer and clustered neural network trained with the back- propagation algorithm. Kirsch masks are adopted for extracting feature vectors and a three-layer clustered neural network with five independent subnetworks is developed for classifying numerals efficiently. The neural network was trainned with a handwritten numeral dabase of more than 9000 patterns of differents writers and differents styles of type. We obtain correct recognition rates of about 96.2 %. Finally, we show how to construct a r efi nem ent stage to improve, even more, the results. 1 .- INTRODUCTION: In this paper, we study the automatic classification of handwritten numerals (the recognizer developed is also valid for printed numerals, printing is simply another writting style). The application field is very wide, for example: postal code recognition, numbers written on bank cheques... We can find the patterns shifted, scaled, distorted, with some skew and even overwritten. Our method is based in a multilayer neural network [1] trained with the classical ‘ Backpropagation’ [2] algorithm. The strucutre of the paper is: - The creation of the database and the information representation model. - The prepocessing used to compute the feature vectors that will be applied to the network. - The structure and training details of our neural net. - The results we have obtained. - A method for improving the results building a refinement neural net. 2 .- DATABASE AND INFORMATION REPRESENTATION: We use a database consisting of 9300 handwritten digits provided by 90 writters of different ages and with many different sizes and writting styles. Writers provide their numbers inside a template, in this way we have an easy segmentation of the patterns. Besides, we have a balanced database (the number of samples per class is the same for all 10 classes). The election of an adequate data representation is a key point in pattern recognition. Using a low-level representation we will need a very large training set (generalization will be more difficult, because the neural net will tend to learn the noise). That’s why it is better to use a high-level representation. We have to design carefully the preprocessing stage (this stage will convert the low-level data into high-level). Besides, there are other factors that influence the preprocessing design, such as the need for high computing speed or hardware limitations. That’s why we will choose representations with low computing costs. Digits (both printed and handwritten) are essentially draws made of lines, id est: one-dimensional structures in a two- dimensional space. So detecting line segments present in the image seems a good method. For each image zone, the information about the presence of a line
-
Upload
parshu-ram -
Category
Documents
-
view
217 -
download
0
Transcript of icsp98_1

8/3/2019 icsp98_1
http://slidepdf.com/reader/full/icsp981 1/5

8/3/2019 icsp98_1
http://slidepdf.com/reader/full/icsp981 2/5
segment and its concrete orientation isextracted and introduced in a feature map.
With this representation we achieve anon very complex structure, with a goodpreprocessing speed and an adequate high-
level representation.
3 .- PREPROCESSING:As we already said before, digits are
written inside a template (a mesh of black straight lines) to make easier thesegmentation process. The sheet is scannedin bi-level (black and white) mode. Theresolution is 300 dpi’s and the result is agraphic file (TIFF format) ready to
preprocess. We extract a 100x100 imagefrom each box of the mesh. Then, we refinethe segmentation extracting the minimal boxthat contains the character. We also removethe isolated points due to noise.
The pattern that we obtain in thismanner has an unpredictable size, that’s whyit is necessary a normalization (or scaling)that makes sure the recognizer is sizeinvariant. The pattern is also centeredbecause when we scale we keep the initialaspect ratio (this condition avoids adeformation of the pattern). We alwaysobtain images of size 16x16, these imagesare not bi-level because of the scalingprocess.
The problem now is to extract somefeatures so that we transform them from a(low-level) pixel representation to a higherlevel. We must retain only the key features of the character and remove all redundant
information. We must extract feature mapstht contain information about the linesegments, its position and orientation. Thefirst order differential axis detectors aresuitable for this task. Besides, they are fast tocompute. There are several axis detectors of this kind: Freichen, Kirsch, Prewitt, Sobel...The most accurate finding the fourdirectional axis: horizontal, vertical, rightdiagonal and left diagonal is the Kirschdetector (this is the only one that uses theeight point neighbourhood of each pixel).
Kirsch [4] defines an algorithm that usesthe following notation:
A0
A1
A2
A7
(i, j) A3
A 6 A5 A 4
Fig. 1: Notation for the neighbours of pixel (i,j).
The equations are:
[ ]{ }G(i. j ) = max 1, max 5S - 3Tk=0
7
k k (1)
where G(i,j) is the gradient for the pixel (i,j),and:
S = A A Ak k k +1 k +2+ +
T = A A A A Ak k +3 k +4 k +5 k+6 k +7+ + + +
Subindexes of A are evaluated “modulus 8”
We can base ourselves in theseequations to compute feature maps in thefour directions: horizontal (H), vertical(V),right diagonal (R) and left diagonal (L).
In this way, we obtain four local featuremaps, to obtain a global feature map weinclude the original pattern with no gradientoperator applied. The set of feaure maps isso made by five patterns of size 16x16 (4local + 1 global). Figure 2.
The last preprocessing stage is acompression of the 16x16 Kirsch patterns.They are coverted to size 4x4 via a lineardecimation. In this manner we reduce theinput space dimension for a factor of 16.This is very important to make sure theneural net will learn without a very big
number of training samples.

8/3/2019 icsp98_1
http://slidepdf.com/reader/full/icsp981 3/5
Fig. 2: Preprocessing consisting of normalizationto size 16x16, feature extraction (4 Kirsch
components) and compression to 4x4.
4 .- MULTI-LAYER NEURAL NET:
One of the purposes of the work withneural networks is the minimization of the
mean square error (MSE) between the actualoutput and the desired one. Thisminimization is peformed via gradientalgorithms. Backpropagation [2] is anefficient and very classical method. In ournetwork there exists a trade off about thenumber of conections (or weights). If thenumber of weights is too low the net will notbe able to learn. Otherwise, if that number istoo big, we can have “overtraining” (the netcan learn “even the noise”) [2].
4.1 .- NETWORK STRUCTURE:The network structure used is shown in
figure 3. The input layer consists of fivemaps of 4x4 units each. Four of these mapscorrespond to local characteristics (one foreach direction) and the fifth one retains theglobal characteristic of the input pattern.Each of these five input maps make up fullyconnected groups with their corresponding
maps in the hidden layer. So we have fiveindependent subnets. In the output layer, we
have 10 units fully connected with all units inthe hidden layer. Each output unit representsone class. When we introduce a pattern thatbelongs to class 'i', the trained output will be1 for the i th output unit and 0 for the others.
This network has 170 units and 2080 links(2170 weights).
This structure has the advantage tomake possible the correct pattern recognitioneven when some of the subnets findsambiguity (the other subnets can cancel theefect of that ambiguity).
Fig. 3: Network Structure.
4.2 .- NETWORK TRAINING:Each of the subnets between the input
and the hidden layer is initialized withrandom weights and trained with differentfeature maps. All the connections in the netare of adaptive nature and are trained withthe "Backpropagation" algorithm. Thelearning coefficient that is the only freeparameter in this method is set up before thetraining and is not changed during it.
In figure 4 we see that the maximumrecognition rate is achieved about 200training iteractions (the maximum rate is96.2%). After that, the rate remains almostconstant. That’s why we do not use any
escpecial criterion to stop the algorithm. Therates are measured using the cross-validationmethod. Id est: The training set and the testone have no common elements. That’s whywe are not affected by “over-training” efects.

8/3/2019 icsp98_1
http://slidepdf.com/reader/full/icsp981 4/5
Fig. 4: Correct recognizing rate versus number of training epochs.
5 .- EXPERIMENTAL RESULTS:
We have made some experiments to findthe parameters which yield the best results.
We used our own database (9300 patterns)for all of them.
In our first experiment, we made 32partitons of the database. We trained thenetwork with 31 of them and then tested itwith the remaining partition. We repeatedthis process for the 32 possibilities. This is awell known cross-validation method, itsname in the literature is 'Leave one out'. Wehave averaged the recognition rates to find aglobal accuracy measure.
In some applications is interesting toallow some rejection rate, id est: the network refuses to recognize the more ambiguouspatterns. Those patterns should be passed toa human operator for revision (the network output in this case can be used as a hint). Wecan apply this idea defining an ambiguouspattern as follows: “A pattern is ambiguous if either the maximum output of the net is lessthan some threshold close to 1 (t 1) or if some
of the non maximum outputs is more thansome threshold close to 0 (t 2)”. Choosingadequate values for the thresholds, we got arejection rate of 9%, and a correctclassification rate (only over the non rejectedpatterns, of course) of 99%. With norejection our correct recognition rate is96.2%.
Other experiment was to face ournetwork with some “strange” (almostpatological) patterns. Table 2 shows patternexamples that were correctly classified (thisproves the network generalization power, as
the net had never seen before digits like theseones).
Table 3 shows patterns that wereincorrectly classified. The reader can see thatare very ambiguous, even for the human eye.
Table 1: “Strange” patterns classified correctly.
1 / 9 4/9 4/1 7/3 4/9
7/2 5/1 3/5 4/9 5/6
Table 2: Patterns incorrectly classified.
6 .- REFINEMENT STAGE:
We decided to improve even more theresults using a second neural classifier. This“refinement network” acts only on theambiguous patterns that were rejected by thefirst network.
To consider that a pattern is ambiguouswe must have the following situation: thepattern was rejected by the first network (using the previously stated criterion), twooutputs must clearly dominate over theothers (we choose a treshold to assure this)and the distance between those twodominant outputs is small (we also choose athreshold to assure this).
This refinement network is made by 45neurons. Each of them is trained to distingishbetween a pair of numerals (there are 45combinations of two different digits:
10
2 10 245
!
!( )!−
= ). The ambiguous patterns are
applied only to the neuron designed todistinguish between the two contendingcandidates (the two dominant ones in thefirst stage).
Each of the 45 neurons receives as inputa feature vector very similar to the one used
8/3/2019 icsp98_1
http://slidepdf.com/reader/full/icsp981 5/5
in the first stage. The difference here is thatthe 4 Kirsch components are compressed toa size of 8x8 (instead of 4x4). The reason forthat is to pay more attention to local detailsthat may be very important to distinguish
between the contending candidates. Theglobal component is removed here for thesame reason.
Fig 5. Structure of the refinement network.
These neurons were again trainedwith our database and with the‘ Backpropagation’algorithm. Each neuron
takes a binary decision, id est: a value of 0decides for one digit and a 1 decides for theother. We can set thresholds to decide whenthe output is “in the middle”. In these casesthe second network rejects the pattern (thiswill occur with very ambiguous patterns).
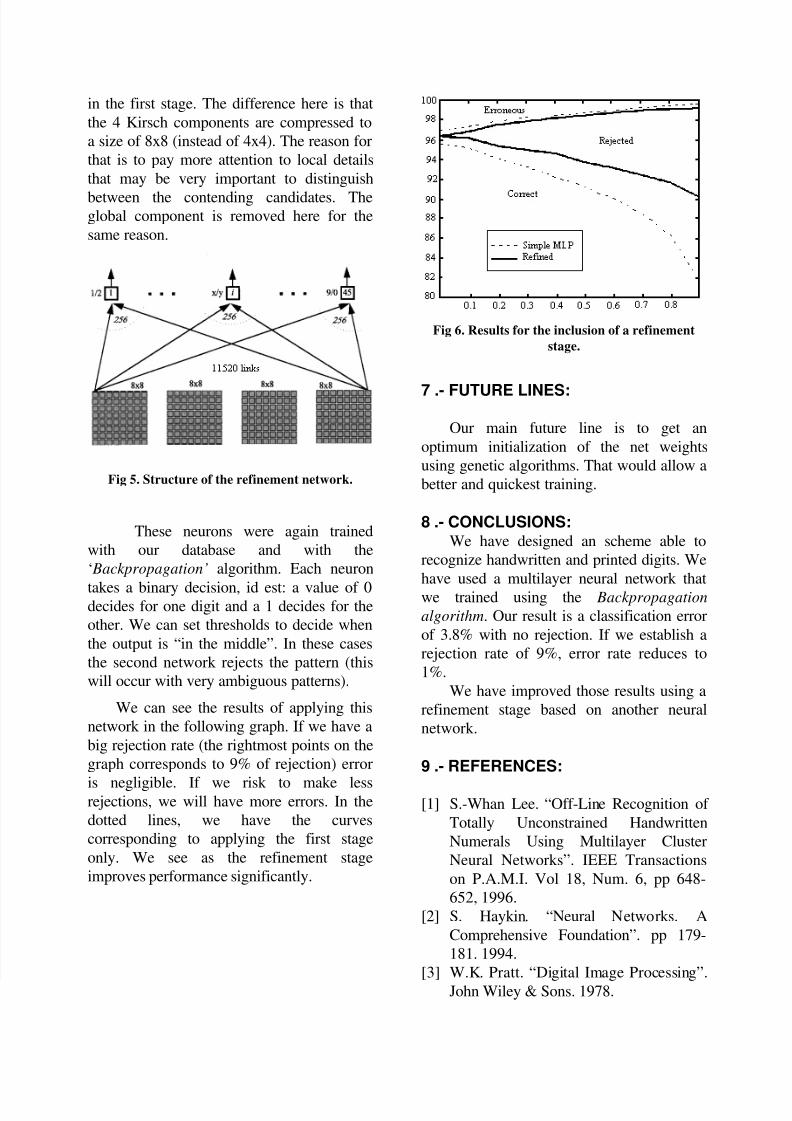
We can see the results of applying thisnetwork in the following graph. If we have abig rejection rate (the rightmost points on thegraph corresponds to 9% of rejection) error
is negligible. If we risk to make lessrejections, we will have more errors. In thedotted lines, we have the curvescorresponding to applying the first stageonly. We see as the refinement stageimproves performance significantly.
Fig 6. Results for the inclusion of a refinementstage.
7 .- FUTURE LINES:
Our main future line is to get anoptimum initialization of the net weightsusing genetic algorithms. That would allow abetter and quickest training.
8 .- CONCLUSIONS:We have designed an scheme able to
recognize handwritten and printed digits. Wehave used a multilayer neural network thatwe trained using the Backpropagationalgorithm. Our result is a classification errorof 3.8% with no rejection. If we establish arejection rate of 9%, error rate reduces to1%.
We have improved those results using arefinement stage based on another neuralnetwork.
9 .- REFERENCES:
[1] S.-Whan Lee. “Off-Line Recognition of Totally Unconstrained HandwrittenNumerals Using Multilayer ClusterNeural Networks”. IEEE Transactionson P.A.M.I. Vol 18, Num. 6, pp 648-652, 1996.
[2] S. Haykin. “Neural Networks. AComprehensive Foundation”. pp 179-181. 1994.
[3] W.K. Pratt. “Digital Image Processing”.John Wiley & Sons. 1978.


















