
Hypothesis Testing Based Model for Fingerprinting Localization Algorithms · Hypothesis Testing...
6
Hypothesis Testing Based Model for Fingerprinting Localization Algorithms Arash Behboodi * , Filip Lemic † , Adam Wolisz † † Institute for Theoretical Information Technology, RWTH Aachen University † Telecommunication Networks Group (TKN), Technische Universit¨ at Berlin Email: [email protected], {lemic,wolisz}@tkn.tu-berlin.de Abstract—Despite the popularity of Fingerprinting Localiza- tion Algorithms (FPS), general theoretical frameworks for their performance studies have rarely been discussed in the literature. In this work, after setting up an abstract model for the FPS, we show that a fingerprinting-based localization problem can be cast as a Hypothesis Testing (HT) problem and therefore various results from the HT literature can be used to provide insights, guidelines, and performance bounds for the FPS. This includes the scaling limits of error probability in terms of the number of measurements and the precise characterization of localization error. The provided results hold for the general FPS. Additionally, Received Signal Strength (RSS)-based fingerprinting algorithms are particularly considered from the theoretical viewpoint due to their widespread practical usage. Simulations and experimental results characterize numerically the findings of the theoretical framework and demonstrate its consistency with realistic local- ization scenarios. I. I NTRODUCTION Precise location of people and devices, both indoors and outdoors, is an essential information for future networks as an enabler of context-aware services, location-aware and pervasive computing, and ambient intelligence. For that rea- son, variety of localization solutions have been proposed and studied in the recent years. Radio-Frequency (RF)-based solutions are popular due to their low cost and availability. They leverage available technologies such as IEEE 802.11 (WiFi), IEEE 802.15.4 (ZigBee), IEEE 802.15 (Bluetooth), and Ultra-Wide Band (UWB). Different RF signal features can be used for localization including Time of Arrival, Angle of Arrival, Received Signal Strength, and the quality of RF transmission in digital communication channels (e.g. Link Quality Information, Bit-Error Ratio). Based on signal features processing, one can roughly distinguish three categories of localization algorithms, i.e. geometry-based, fingerprinting, and Bayesian-based ones [1]. RF fingerprinting algorithms are particularly attractive because they rely on available wireless infrastructures and therefore avoid a costly setup. These algo- rithms utilize specific signal features that are correlated with spatial characteristics of the environment. The idea is to use the observed feature at a location to construct an identification tag for that location which is called the fingerprint. A database is constructed, explicitly or implicitly, by gathering fingerprints of different locations. A pattern matching algorithm identifies the location by finding the most similar fingerprint in the database to the reported fingerprint from an unknown location. There are various works in the literature studying different aspects of fingerprinting algorithms [2]. A survey of WiFi- based fingerprinting algorithms is provided in [3] and variants of such algorithms are studied in e.g. [4], [5]. The main theoretical work on fingerprinting algorithms is [6], where the authors provide an analysis of the effect of the num- ber of visible Access Points (APs) and radio propagation parameters on the performance of fingerprinting algorithms. These results have been extended to a complexity analysis in [7]. The authors in [8] propose a probabilistic model RSS-based fingerprinting relating the location to RSS. The authors also discuss the performance of fingerprinting using likelihood-based detection algorithms and provide insights for fingerprinting design. The scalability of fingerprinting has been discussed in [9], where the authors suggest the scalability improvement by reducing a training database size. In [10], the authors discuss the robustness of fingerprinting to outliers and effects such as shadowing. However, various insights of fingerprinting, such as the scaling limits of errors probabilities or the characterization of localization error, have not been yet discussed from the theoretical perspective, despite the importance of such discussion for the optimal design of fingerprinting-based localization systems. In this paper, the signal feature is assumed to be a random variable with a probability distribution that varies with the location. The problem of localization then boils down to finding the probability distribution underlying the observed measurements, which essentially is a hypothesis testing prob- lem. Based on this observation, we prove series of theorems establishing fundamental limits of fingerprinting algorithms. This includes a proof for existence of a fingerprinting algo- rithm with completely accurate localization and also showing that the inaccuracy decays exponentially with the number of measurements. Kullback-Leibler (KL) divergence between probability distributions of a selected feature for fingerprint- ing at two different locations plays a central role in these results. Different consequences of these theorems for tuning the parameters of fingerprinting algorithms are discussed. The general framework is then instanced for the RSS-based algorithms, as these are the most established instances of fin- gerprinting algorithms. Finally, we show that the implications of the developed theory hold for realistic scenarios that do not necessarily adhere to the assumptions made in the framework. II. SYSTEM MODEL A. Fingerprint Fingerprinting algorithms are based on associating a finger- print to a location, which is later used for the identification of that location. A specific feature of environment is chosen as
Transcript of Hypothesis Testing Based Model for Fingerprinting Localization Algorithms · Hypothesis Testing...

Hypothesis Testing Based Model for FingerprintingLocalization Algorithms
Arash Behboodi∗, Filip Lemic†, Adam Wolisz††Institute for Theoretical Information Technology, RWTH Aachen University†Telecommunication Networks Group (TKN), Technische Universitat BerlinEmail: [email protected], {lemic,wolisz}@tkn.tu-berlin.de
Abstract—Despite the popularity of Fingerprinting Localiza-tion Algorithms (FPS), general theoretical frameworks for theirperformance studies have rarely been discussed in the literature.In this work, after setting up an abstract model for the FPS,we show that a fingerprinting-based localization problem can becast as a Hypothesis Testing (HT) problem and therefore variousresults from the HT literature can be used to provide insights,guidelines, and performance bounds for the FPS. This includesthe scaling limits of error probability in terms of the numberof measurements and the precise characterization of localizationerror. The provided results hold for the general FPS. Additionally,Received Signal Strength (RSS)-based fingerprinting algorithmsare particularly considered from the theoretical viewpoint due totheir widespread practical usage. Simulations and experimentalresults characterize numerically the findings of the theoreticalframework and demonstrate its consistency with realistic local-ization scenarios.
I. INTRODUCTION
Precise location of people and devices, both indoors andoutdoors, is an essential information for future networksas an enabler of context-aware services, location-aware andpervasive computing, and ambient intelligence. For that rea-son, variety of localization solutions have been proposedand studied in the recent years. Radio-Frequency (RF)-basedsolutions are popular due to their low cost and availability.They leverage available technologies such as IEEE 802.11(WiFi), IEEE 802.15.4 (ZigBee), IEEE 802.15 (Bluetooth),and Ultra-Wide Band (UWB). Different RF signal featurescan be used for localization including Time of Arrival, Angleof Arrival, Received Signal Strength, and the quality of RFtransmission in digital communication channels (e.g. LinkQuality Information, Bit-Error Ratio). Based on signal featuresprocessing, one can roughly distinguish three categories oflocalization algorithms, i.e. geometry-based, fingerprinting,and Bayesian-based ones [1]. RF fingerprinting algorithms areparticularly attractive because they rely on available wirelessinfrastructures and therefore avoid a costly setup. These algo-rithms utilize specific signal features that are correlated withspatial characteristics of the environment. The idea is to use theobserved feature at a location to construct an identification tagfor that location which is called the fingerprint. A database isconstructed, explicitly or implicitly, by gathering fingerprintsof different locations. A pattern matching algorithm identifiesthe location by finding the most similar fingerprint in thedatabase to the reported fingerprint from an unknown location.
There are various works in the literature studying differentaspects of fingerprinting algorithms [2]. A survey of WiFi-based fingerprinting algorithms is provided in [3] and variants
of such algorithms are studied in e.g. [4], [5]. The maintheoretical work on fingerprinting algorithms is [6], wherethe authors provide an analysis of the effect of the num-ber of visible Access Points (APs) and radio propagationparameters on the performance of fingerprinting algorithms.These results have been extended to a complexity analysisin [7]. The authors in [8] propose a probabilistic modelRSS-based fingerprinting relating the location to RSS. Theauthors also discuss the performance of fingerprinting usinglikelihood-based detection algorithms and provide insights forfingerprinting design. The scalability of fingerprinting has beendiscussed in [9], where the authors suggest the scalabilityimprovement by reducing a training database size. In [10],the authors discuss the robustness of fingerprinting to outliersand effects such as shadowing. However, various insights offingerprinting, such as the scaling limits of errors probabilitiesor the characterization of localization error, have not beenyet discussed from the theoretical perspective, despite theimportance of such discussion for the optimal design offingerprinting-based localization systems.
In this paper, the signal feature is assumed to be a randomvariable with a probability distribution that varies with thelocation. The problem of localization then boils down tofinding the probability distribution underlying the observedmeasurements, which essentially is a hypothesis testing prob-lem. Based on this observation, we prove series of theoremsestablishing fundamental limits of fingerprinting algorithms.This includes a proof for existence of a fingerprinting algo-rithm with completely accurate localization and also showingthat the inaccuracy decays exponentially with the numberof measurements. Kullback-Leibler (KL) divergence betweenprobability distributions of a selected feature for fingerprint-ing at two different locations plays a central role in theseresults. Different consequences of these theorems for tuningthe parameters of fingerprinting algorithms are discussed.The general framework is then instanced for the RSS-basedalgorithms, as these are the most established instances of fin-gerprinting algorithms. Finally, we show that the implicationsof the developed theory hold for realistic scenarios that do notnecessarily adhere to the assumptions made in the framework.
II. SYSTEM MODEL
A. Fingerprint
Fingerprinting algorithms are based on associating a finger-print to a location, which is later used for the identification ofthat location. A specific feature of environment is chosen as
flemic
Text Box
This is the authors' version of the work. It is posted here for your personal use, not for redistribution. This work has been accepted for publication at the 2017 IEEE 85th Vehicular Technology Conference (VTC-Spring'17).

basis for creating a fingerprint. We chose the term environmentto include multiplicity of possibilities whether a particularinfrastructure is assumed for localization purpose or not. Thesignal feature is denoted by S and belongs to the featurespace S. m consecutive observations of the signal featureS = (S1, . . . , Sm) ∈ Sm are used as a random variable relatedto the location u through the conditional probability PS|u. Ingeneral, the consecutive measurements of a signal feature canbe statistically correlated. Fingerprints are then constructedbased on observations S at different locations. Fingerprintsbelong to the space X , which may be different from S.
Definition 1 (Fingerprint): A fingerprint creating functionf is a mapping Sm → Xn that assigns to observations S anelement X called the fingerprint at the location u.For example, consider a FPS measuring RSS from an anchor.Let the fingerprint be a Gaussian distribution fitted to thevector of m measured RSS. The fingerprinting space is aspace of Gaussian probability distributions and the signalfeature is the received power. Since received power is functionof distance to the anchor, so are the fingerprints. There aresome requirements for a general fingerprint to be useful forlocalization. In general if the probabilities PX|u1
and PX|u2
are close enough, i.e., if d(PX|u1,PX|u2
) ≤ L where d isa metric, then u1 and u2 should also be close which is‖u1 − u2‖ ≤ s(L) where s(L) → 0 whenever L → 0. Wecall this spatial stability of the fingerprint. The quantitativecharacterization of stability depends on the metric chosen formeasuring closeness of probabilities. Fingerprints should alsobe robust in time. This means that fingerprints should notchange dramatically from training to measurement phase.
B. Fingerprinting Algorithm
After a signal feature and a fingerprint creating functionhave been selected, the next step is to design the finger-printing algorithm. The first step called the training phase isa process of constructing a database consisting of pairs oflocations and their fingerprints. Out of an uncountable set oflocations in the localization space, only a finite number oflocations can be chosen for direct measurement to constructthe database. The training database can be constructed throughextensive measurements, through simulation-based radio-mapconstruction [11], [12] or the combination of both. The setof training locations, called a training grid, is denoted byΛ ⊂ Rd. The region of nearest points to each traininglocation v ∈ Λ is called its Voronoi region denoted byVv. The training locations in Λ divide the localization spaceinto regions. After choosing the training locations, a specificfeature of environment is chosen for creating a fingerprint. Thetraining database is created by measuring the signal featureS at the training locations inside the training grid Λ. Ateach location v, multiple measurements are collected andfingerprints are constructed accordingly. The training databaseD, which consists of pairs like (v,X), is a subset of Λ×Xn.The next part consists of finding the location of a target node.The fingerprinting algorithm reports the estimated location ofthe target node based on the observed signal feature. A target
node placed at the location u measures the selected featurem′ times and creates a fingerprint Xu ∈ Xn
′. In general,
the number of measurements in the training phase and inthe localization phase can be different, although we assumen′ = n. After acquiring the fingerprint, a pattern matchingfunction g is used to estimate the target node’s location ubased on the acquired fingerprint Xu and fingerprints in thetraining database. The function g is a mapping from Xnto the localization space R. The pattern matching functioncan be regarded as a composition of multiple functions. Forinstance, a similarity kernel function can first find the mostsimilar fingerprints in the database. Then, one can additionallyuse k−nearest neighbor methods to average between the kclosest training locations, rather than declaring single traininglocation. The average can be weighted or not, adaptive or non-adaptive [13]. In any case, k−NN methods will have a set ofestimated locations Λe, which is not equal to the original setof training locations Λ.
Based on the previous discussion, we can finally specifywhat a fingerprinting algorithm is.
Definition 2 (Fingerprinting algorithm): A fingerprintingalgorithm for a localization space R consists of:• A set of training locations Λ;• A fingerprint creating function f : Sm → Xn, mapping
a measured signal feature S to a fingerprint X in Xn;• A training database Λ× Xn consisting of pairs of loca-
tions and their fingerprints;• A pattern matching function g : Xn → R reports the
final location by comparing the target node’s fingerprintto the ones from the training database.
The advantage of this abstraction, as it can be seen later, is itsapplicability in various scenarios. Usage of this abstraction forthe RSS-based fingerprinting is discussed later in the paper.
C. Performance of Fingerprinting Algorithms
In this section, we introduce a framework for evaluatingthe performance limit of fingerprinting algorithms. The mainperformance metric for a localization algorithm is the local-ization error. Let u be the output of the FPS for a targetnode located at u ∈ R. The localization error is definedas ∆(u) = ‖u − u‖. Similar to the definition of error ininformation theory and statistics, it is possible to define themaximum and average localization error for all u’s denotedby ∆max and ∆. Because we have assumed that the feature isa random variable, the localization error ∆(u) can also be arandom variable and so can ∆max and ∆. An important goalin localization is to reliably guarantee a given accuracy andthe following definition formalizes this goal.
Definition 3 (Achievable localization error): The maximumlocalization error of δ is achievable with probability 1 − ε ifthere is a FPS such that Pr(∆max > δ) ≤ ε. In the same waythe achievable average localization error can be defined.The definition assumes the theoretical limits δ and ε. Nextsection establishes that (δ, ε) can be made arbitrarily small byincreasing the number of training points and measurements.

III. FINGERPRINTING AS HYPOTHESIS TESTING PROBLEM
In this section, we consider a general FPS and providebounds on its performance. The only assumption for theconditional distribution PX|u is that the measurements areindependent and identically distributed. Let us assume a simplelocalization scenario where the target node is located eitherat u1 or at u2. Two kinds of errors can be defined and theaim is to minimize both of these probabilities. α(u1,u2) andβ(u1,u2) are the probabilities of incorrect identification.
α(u1,u2) = P(g(X) = u2| Target node is at u1)
β(u1,u2) = P(g(X) = u1| Target node is at u2).
The problem of localization is then to decide betweentwo probability distributions PX|u1
and PX|u2based on the
observation X and subject to constraints on α(u1,u2) andβ(u1,u2). The problem is related to statistical hypothesistesting [14] where the goal is to decide between PX|u1
andPX|u2
based on n samples. The decision is made using atest T on sample data. The errors α(u1,u2) and β(u1,u2)are respectively called missed detection and false alarm. Thisconnection enable us to regard a fingerprinting design problemas a hypothesis testing problem and benefit from abundantresearch materials in that area. As the first step, the followingtheorem provides fundamental limits on the performance oftwo-points fingerprinting algorithms. D(.‖.) is KL-divergence.
Theorem 3.1: Consider a fingerprinting algorithm with fin-gerprints X ∈ Xn consisting of n i.i.d. fingerprints fromconditional distribution as PX|u. If the distribution PX|u isknown to the fingerprinting algorithm, then for large enoughn, there is a pattern matching function g, such that for eachpair of locations (u1,u2) and for any 0 < ε < 1,
α(u1,u2) ≤ ε (1)
limn→∞
1
nlog β(u1,u2) = −D(PX|u1
‖PX|u2). (2)
Proof: Consider two points u1 and u2 in localizationspace. The theorem is equivalent to find bounds on misseddetection and false alarm in a hypothesis testing scenario. Theequivalent hypothesis testing problem is Stein’s lemma and theproof is well known (for instance [15], [16]) and the sketch ofproof is only provided here. For the known probabilities PX|u1
and PX|u2, the typical set Anε′(X) is defined as Anε′(X) ={
x ∈ Xn :
∣∣∣∣∣ 1nn∑i=1
logPX|u2
(xi)
PX|u1(xi)
+D(PX|u1‖PX|u2
)
∣∣∣∣∣ ≤ ε′}.
If the observed features belong to the typical set, thenthe location u1 is the correct location. Therefore the patternmatching function is nothing but the characteristic function ofAnε′(X). For large enough n, law of large numbers impliesα(u1,u2) = PX|u1
(X /∈ Anε′(X)) ≤ ε. Indeed, Anε′(X) actsas a decision region for PX|u1
and the preceding inequalityguarantees that one can correctly identify u1 based on themeasured fingerprint X with probability bigger than 1− ε. Tobound β(u1,u2), suppose that the samples are obtained at u2.
β(u1,u2) can be bounded as follows:
β(u1,u2) ≤ exp(−n(D(PX|u1‖PX|u2
)− ε′))β(u1,u2) ≥ (1− ε) exp(−n(D(PX|u1
‖PX|u2) + ε′)). (3)
By taking the logarithm from both sides and tending n toinfinity, the theorem is proved.
Theorem 3.1 states that the localization error can be madezero with an overwhelming probability when the number ofmeasurements goes to infinity. The theorem also provides thescaling limit of error probability. If D(PX|u1
‖PX|u2) is non-
zero, then the probability of error β(u1,u2) asymptoticallydecays exponentially with D(PX|u1
‖PX|u2). It can also be
shown that this is the best exponent one can get under thefirst constraint on α(u1,u2) [14]. If the KL-divergence of twoprobability distributions is small, this means that the error de-cays with smaller exponent and therefore more measurementsare needed to guarantee a fast decay in error. In other words,n should be increased to compensate for small divergenceand reduce the error. The previous theorem provides alsoguidelines for choosing of a signal feature and a fingerprint.
One can also infer the optimal fingerprint constructionusing insights from hypothesis testing problem. The optimalfingerprint is related to the notion of sufficient statistics andpattern matching functions are related to statistical tests. It isknown that Neyman-Pearson tests are optimal tests in the sensethat keeping one of the error fixed, they achieve the minimumpossible value for the other error. A Neyman-Pearson test findsthe observed likelihood, or log-likelihood ratio and compare itwith a threshold. In other words, based on the observationsX, if Tn, defined as 1
n logPX|u1
PX|u2
is bigger than γ, u1 isannounced as the location and otherwise, u2 is announced.This basically shows that Tn is a good candidate for finger-print and a comparison function for pattern matching. For aNeyman-Pearson test, there are lot of results characterizing theasymptotic and non-asymptotic behavior of the errors in (1)and (2). One particularly relevant parallel can be establishedwhen an a priori probability of the target node presence atdifferent locations is known. This is an example of a map-aware localization. Knowing the map means that one knowsa priori the probability that a target node is present at eachlocation. The localization problem is equivalent to finding thebest Bayes probability of error defined as:
P (e)n = P(u1)α(u1,u2) + P(u2)β(u1,u2).
Interestingly, Neyman-Pearson test with = 0 is the optimaltest. It can be proven that there is a map-aware fingerprinting
algorithm such that lim infn→∞
1
nlogP (e)
n = −I0(0) where I0(0)is called the Chernoff information of the probabilities PX|u1
and PX|u2and is defined as:
I0(0) = − log inft∈R
E(exp
(t log
PX|u2
PX|u1
))and the expectation is with respect to PX|u1
. The proof is anexact replication of the equivalent hypothesis testing problemand follows from large deviation theory analysis, as discussed

in [15]. The important insight is that map-aware localizationcan be done using Tn with the threshold zero and the errordecays exponentially with n and with the Chernoff informationI0(0). These are some examples of interesting insights thatcan be derived from the hypothesis testing analogy. So far,a two-point localization scenario has been considered. Thiscan be easily extended to a localization scenario with finitecandidate locations. Basically, the FPS can reliably and ac-curately localize a target node within finite possible locationsusing enough large number of measurements. When possiblelocations are uncountable, the localization space is dividedinto multiple regions and the equivalent HT problem aimsat finding in which region the target node is located. Theseregions are indeed related to the training grid. This formulationenables us to reformulate the above results. Mainly, the FPScan reliably locate the target node at its respective regionswith overwhelming probability and with enough large numberof measurements. The maximum error is then dependent onthe size of regions. Although FPS can successfully find thetarget node’s region, the number of required measurementsfor reliable localization increases when the sizes of regionsdecrease. Intuitively, finer localization comes with the price ofhigher latency. Another issue is the strong assumption that analgorithm knows the conditional probability distribution PX|u.Fortunately this assumption is not necessarily since it can beshown, using large deviation theory results, that the probabilitydistribution can be learned during the training phase at eachlocation. We refer to [15] for further discussions.
A. RSS-based Fingerprinting AlgorithmsIn this part, the previous results are considered for RSS-
based fingerprinting algorithms. Suppose that some dedicatedanchors are used for localization and wi is the location ofthe anchor i and u is the location of target node. The anchori’s signal is denoted by x(i)(t). The received signal can bemodeled as follows [17]:
y(i)(u, t) =∑
a(i)j (t)x(i)(t− τ (i)j (t)) + z(i)(t)
where a(i)j (t) and τ
(i)j (t) are the channel gain and delay of
j’th multipath component. One option is to consider statisticalchannel model and take a
(i)j [n] = a
(i)j (nT ) as Rayleigh
distributed (T is sampling period). Moreover, for simplicitywe consider only one dominant channel tap, which is a(i)1 [n]
and a(i)j [n] = 0 for j > 1 . a(i)1 [n]’s are in general correlatedin time, their variation depends on the coherence time of thechannel and they incorporate the path loss. In this work, it isassumed that the power is calculated over a long period andtherefore they are stable in time. Therefore, a(i)1 [n] is assumedto be 1
‖wi−u‖αi/2. For example, WiFi RSSI values vary slightly
in time, mainly due to quantization noise. Using this model,the fingerprint X(i)
u is the received power, obtained as:
X(i)u = P (i)(u) =
P(i)T
‖wi − u‖α+N +Ni,
where α is the path loss exponent, N is the additive noisepower, Ni is a Gaussian random variable of variance Ni
to account for small changes in RSS values. The finger-print at the point u is then Xu = (X
(1)u , . . . , X
(K)u ).
Based on the results of previous section, the KL-divergenceD(PX|u1
‖PX|u2) is adopted as the main metric of interest.
This metric is inversely related with the latency of localization.Bigger KL-divergence indicates fewer measurements requiredfor localization. The metric D(PX|u1
‖PX|u2) is evaluated as∑
j(P
(j)T )2
2Nj
(1
‖wj−u1‖α −1
‖wj−u2‖α
)2.
Figure 1: Level curves of localization latency
From this, some insights can be directly derived. First,increasing the number of anchors can improve KL-divergenceand thereby reduce the number of required measurements forlocalization, i.e. which can be interpreted as latency. This issubject to proper placement of anchor points. Note that theworst performance are obtained at the points with smallestKL-divergence and therefore new anchors should be placed insuch a way to increase the KL-divergence exactly for thosepoints. To see this, define `(u, e) = D(PX|u‖PX|u+e) whichis latency of distinguishing two points of distance ‖e‖. Figure1 shows level curves of `(u, e) for e = (0.1, 0.1). It canbe seen that the small value of `(u, e), which indicates badlocalization performance, corresponds to an oval surroundingthe anchors and particularly to points between the anchors.This observation suggests that a new anchor should be placedon those curves containing the localization area. One methodof finding the position of new anchors is to consider Voronoiregions of current anchors and place a new anchor on theintersection of Voronoi regions. In this way, KL-divergence isincreased by installing nearby anchors to compensate the effectof far anchors. An analytical explanation of this phenomenoncan be given by using mean value theorem for several vari-ables:
D(PX|u1‖PX|u2
) ≤∑j
α2(P(j)T )2
2Nj
(‖u1 − u2‖2
‖uj −wj‖2α+2
)where uj is a location on the line between u1 and u2.For enough far points from all anchors, all uj can be ap-proximated as equal and one can use the function ˜(u) =∑j
1
‖u−wj‖2α+2for evaluating the effect of anchor place-
ments on localization performance. First, for enough small orenough large path loss exponent α, the distance between twofingerprints is arbitrarily small. Moreover, the level curves of˜(.) approximate well that of `(.) for far points from anchors.

IV. SIMULATION AND EXPERIMENTAL RESULTS
In this section, numerical simulations are used to char-acterize quantitatively the findings of the proposed theorywithin a model close to our theoretical assumptions and yetmore complex with a finite number of training locations andmeasurements per location. Our experimental setup is thenemployed to show that our theoretical guidelines still hold fora realistic environment for the same algorithm. As a fingerprintat each location, we select the vector of average RSS valuesobserved from different WiFi APs, which is a well-knownand often used fingerprint selection method [13]. The patternmatching function is the Euclidean distance between vectors,which is also a standard method [18].
A. Simulation Results
In a simulation environment, we define a set of APs’ relatedparameters, i.e. their locations and transmit powers. RSS val-ues obtained from each AP at a targeted node at an unknownlocation are modeled using the COST 231 multi-wall modelfor indoor radio propagation [19]. The applicability of themodel has been demonstrated for localization purposes [20]and the model has been extensively used (e.g. [21]). The modelaccounts for the type and number of walls, floors or obstaclesin an environment, as well as for the locations of APs. Thefirst attenuation contribution in the model is a well-knownone-slope term that relates the received power to distance.Two parameters influence the attenuation in this term: theconstant l0 (the path-loss at 1 m distance and at the centerfrequency of 2.45 GHz) and the path-loss exponent α. Thesecond attenuation contribution is a linear wall attenuationterm. The number of walls in the direct path between an APand a target node is counted and for each wall an attenuationcontribution is assumed. The model outputs RSS values fromthe defined APs at a target node’s location.
For the simulation and later experimental examination en-vironment we selected the TWIST testbed [22]. The TWISTtestbed environment is an office building, with its outline givenin Figure 6. In the model parameterization, we used measure-ments from the TWIST testbed and leveraged a least squarefitting procedure that allows minimizing the cost functionbetween the measured received power and the modeled one.The parameters that are given to the model are the constantlc related to the least square fitting procedure, the path-lossexponent α, and the wall attenuation factor lw. Additionally, azero-mean Gaussian noise with standard deviation σ has beenadded to the obtained RSS values, which a standard procedurein simulation of RSS-based localization systems. For derivingour simulation results we used lc =53.73, α =1.64, lw =4.51,σ =2. The transmit power of each AP was set to 20 dBm. Inour simulation, we defined a set of 4 AP with their locationsindicated in Figure 6. A target’s node location has beenselected randomly, its location has been estimated using theselected fingerprinting algorithm, and the localization error,i.e. an offset from the true location has been calculated. Theprocedure has been repeated 10000 times and the results havebeen reported in a regular box-plot fashion.
First, we evaluate the statement given in Theorem 3.1 con-cerning the number of observations at both training locationsand in the runtime phase of fingerprinting. Therefore, we fixedthe training grid to a hexagonal one of 105 training locations.Furthermore, we increase the number of observations from 1to 9 with a step of 3 in both phases of fingerprinting. Theresults are depicted in Figure 2. As visible from the figure, incomparison to the basic case where only one measurement istaken in both training and runtime phase, an increase in thenumber of measurements significantly reduces the localizationerror. Furthermore, the reduction of errors is higher for theincrease in the number of measurements in both phases, incontrast to increasing this number in only one of them. Forexample, the error is in average reduced by roughly 15% incase of the increase in the number of measurements from 1 to9 in one phase only. For the same increase, but in both phases,the average error is reduced by more than 25%.
Second, we evaluate the statement given in previous section,concerning the number and locations of APs. We start fromthe basic scenario with 4 APs (AP1, AP2, AP3, AP4) depictedin Figure 3. We then introduce two additional APs (AP5 andAP6 in Figure 3) in the environment, where their locationsare selected either randomly or based on Voronoi vertices.Voronoi vertices-based selection places new APs at locationsthat are the farthest from the locations of the existing ones.Furthermore, based on the locations of, at this point, 6 APs, weintroduced additional 4 APs, both randomly and, as depicted inFigure 3, based on Voronoi vertices. The localization errors forsuch scenarios are depicted in Figure 4. As visible in the figure,the increase in the number of APs generally notably improvesthe performance of fingerprinting. Secondly, in comparison to5 different random sections, both in case of 6 and 10 APs,Voronoi vertices-based selection generally yields more than15% better performance. In other words, selection of APs ina way that they are the farthest from the locations of existingAPs significantly outperforms other selections. In conclusion,the results derived by simulation with a higher level of realismare consistent with the developed theory.
B. Experimental Results
The TWIST testbed is specifically designed for the perfor-mance evaluation of indoor localization solutions. It featuresautomated experimentation capabilities, accurate ground-truthpositioning, minimization and monitoring of external influ-ences (e.g. interference), and immediate calculation and stor-age of the performance results [23] along the well-establishedguidelines for evaluation of localization solutions [24]. Atraining database has been created by collecting 40 RSS valuesfrom four APs at 41 locations, as indicated in Figure 6a). Theused evaluation locations are shown in Figure 6b).
We evaluate the statement that the main benefit of usingmultiple APs is a reduction of the far anchors effect. In otherwords, localization errors increase as the distance betweenan AP and a target node increases. Figure 5 presents spatialdistributions of errors for three situations distinguished by thenumber of APs used for localization. As visible in Figure 5a,
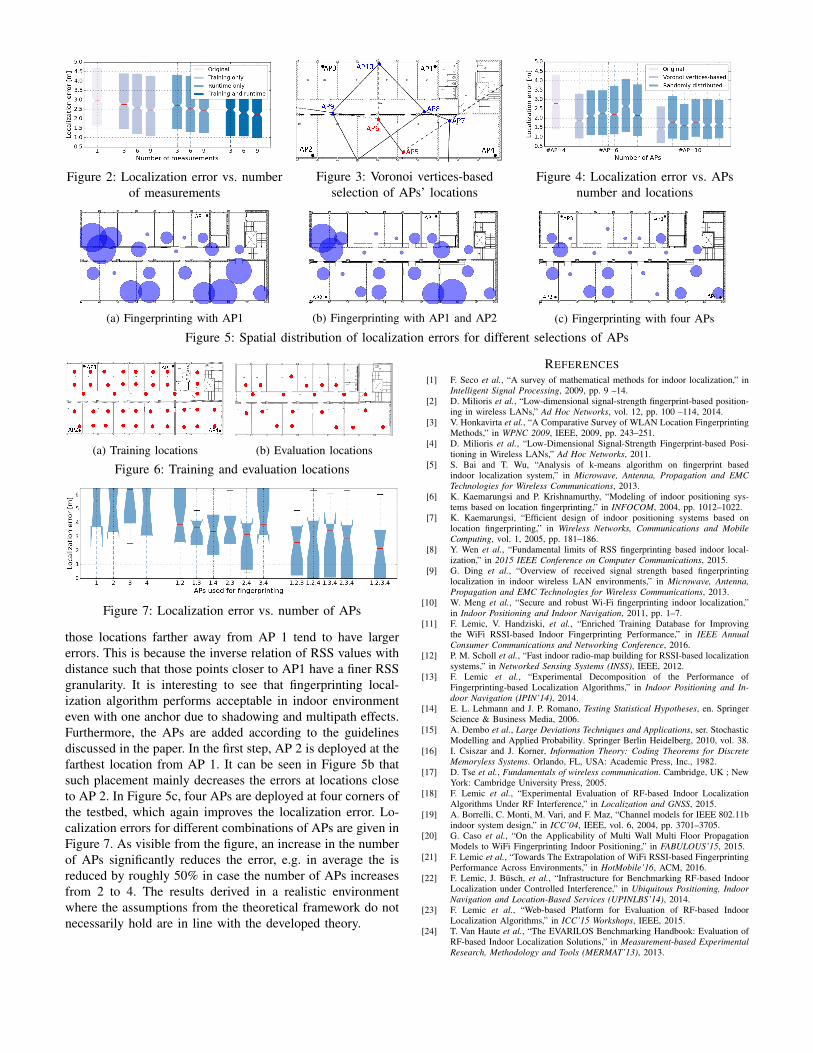
Figure 2: Localization error vs. numberof measurements
Figure 3: Voronoi vertices-basedselection of APs’ locations
Figure 4: Localization error vs. APsnumber and locations
(a) Fingerprinting with AP1 (b) Fingerprinting with AP1 and AP2 (c) Fingerprinting with four APs
Figure 5: Spatial distribution of localization errors for different selections of APs
(a) Training locations (b) Evaluation locations
Figure 6: Training and evaluation locations
Figure 7: Localization error vs. number of APs
those locations farther away from AP 1 tend to have largererrors. This is because the inverse relation of RSS values withdistance such that those points closer to AP1 have a finer RSSgranularity. It is interesting to see that fingerprinting local-ization algorithm performs acceptable in indoor environmenteven with one anchor due to shadowing and multipath effects.Furthermore, the APs are added according to the guidelinesdiscussed in the paper. In the first step, AP 2 is deployed at thefarthest location from AP 1. It can be seen in Figure 5b thatsuch placement mainly decreases the errors at locations closeto AP 2. In Figure 5c, four APs are deployed at four corners ofthe testbed, which again improves the localization error. Lo-calization errors for different combinations of APs are given inFigure 7. As visible from the figure, an increase in the numberof APs significantly reduces the error, e.g. in average the isreduced by roughly 50% in case the number of APs increasesfrom 2 to 4. The results derived in a realistic environmentwhere the assumptions from the theoretical framework do notnecessarily hold are in line with the developed theory.
REFERENCES[1] F. Seco et al., “A survey of mathematical methods for indoor localization,” in
Intelligent Signal Processing, 2009, pp. 9 –14.[2] D. Milioris et al., “Low-dimensional signal-strength fingerprint-based position-
ing in wireless LANs,” Ad Hoc Networks, vol. 12, pp. 100 –114, 2014.[3] V. Honkavirta et al., “A Comparative Survey of WLAN Location Fingerprinting
Methods,” in WPNC 2009, IEEE, 2009, pp. 243–251.[4] D. Milioris et al., “Low-Dimensional Signal-Strength Fingerprint-based Posi-
tioning in Wireless LANs,” Ad Hoc Networks, 2011.[5] S. Bai and T. Wu, “Analysis of k-means algorithm on fingerprint based
indoor localization system,” in Microwave, Antenna, Propagation and EMCTechnologies for Wireless Communications, 2013.
[6] K. Kaemarungsi and P. Krishnamurthy, “Modeling of indoor positioning sys-tems based on location fingerprinting,” in INFOCOM, 2004, pp. 1012–1022.
[7] K. Kaemarungsi, “Efficient design of indoor positioning systems based onlocation fingerprinting,” in Wireless Networks, Communications and MobileComputing, vol. 1, 2005, pp. 181–186.
[8] Y. Wen et al., “Fundamental limits of RSS fingerprinting based indoor local-ization,” in 2015 IEEE Conference on Computer Communications, 2015.
[9] G. Ding et al., “Overview of received signal strength based fingerprintinglocalization in indoor wireless LAN environments,” in Microwave, Antenna,Propagation and EMC Technologies for Wireless Communications, 2013.
[10] W. Meng et al., “Secure and robust Wi-Fi fingerprinting indoor localization,”in Indoor Positioning and Indoor Navigation, 2011, pp. 1–7.
[11] F. Lemic, V. Handziski, et al., “Enriched Training Database for Improvingthe WiFi RSSI-based Indoor Fingerprinting Performance,” in IEEE AnnualConsumer Communications and Networking Conference, 2016.
[12] P. M. Scholl et al., “Fast indoor radio-map building for RSSI-based localizationsystems,” in Networked Sensing Systems (INSS), IEEE, 2012.
[13] F. Lemic et al., “Experimental Decomposition of the Performance ofFingerprinting-based Localization Algorithms,” in Indoor Positioning and In-door Navigation (IPIN’14), 2014.
[14] E. L. Lehmann and J. P. Romano, Testing Statistical Hypotheses, en. SpringerScience & Business Media, 2006.
[15] A. Dembo et al., Large Deviations Techniques and Applications, ser. StochasticModelling and Applied Probability. Springer Berlin Heidelberg, 2010, vol. 38.
[16] I. Csiszar and J. Korner, Information Theory: Coding Theorems for DiscreteMemoryless Systems. Orlando, FL, USA: Academic Press, Inc., 1982.
[17] D. Tse et al., Fundamentals of wireless communication. Cambridge, UK ; NewYork: Cambridge University Press, 2005.
[18] F. Lemic et al., “Experimental Evaluation of RF-based Indoor LocalizationAlgorithms Under RF Interference,” in Localization and GNSS, 2015.
[19] A. Borrelli, C. Monti, M. Vari, and F. Maz, “Channel models for IEEE 802.11bindoor system design,” in ICC’04, IEEE, vol. 6, 2004, pp. 3701–3705.
[20] G. Caso et al., “On the Applicability of Multi Wall Multi Floor PropagationModels to WiFi Fingerprinting Indoor Positioning,” in FABULOUS’15, 2015.
[21] F. Lemic et al., “Towards The Extrapolation of WiFi RSSI-based FingerprintingPerformance Across Environments,” in HotMobile’16, ACM, 2016.
[22] F. Lemic, J. Busch, et al., “Infrastructure for Benchmarking RF-based IndoorLocalization under Controlled Interference,” in Ubiquitous Positioning, IndoorNavigation and Location-Based Services (UPINLBS’14), 2014.
[23] F. Lemic et al., “Web-based Platform for Evaluation of RF-based IndoorLocalization Algorithms,” in ICC’15 Workshops, IEEE, 2015.
[24] T. Van Haute et al., “The EVARILOS Benchmarking Handbook: Evaluation ofRF-based Indoor Localization Solutions,” in Measurement-based ExperimentalResearch, Methodology and Tools (MERMAT’13), 2013.
![WiFi fingerprinting - Indoor Localization (582747), …...Haeberlen [2] (very shortly) Discretize building into cells (one per room) Collect roughly 100 scans per cell Build graph](https://static.fdocuments.us/doc/165x107/5e6e550ba2b7f9767d650d38/wifi-fingerprinting-indoor-localization-582747-haeberlen-2-very-shortly.jpg)
















