
Carnegie Mellon Universitycschafer/cmspbs.pdf · 2009. 2. 26. · Carnegie Mellon University

Human-Robot Mutual Adaptation in Shared Autonomy
Stefanos NikolaidisCarnegie Mellon University
Yu Xiang ZhuCarnegie Mellon University
National University ofSingapore
Siddhartha SrinivasaCarnegie Mellon University
ABSTRACTShared autonomy integrates user input with robot auton-omy in order to control a robot and help the user to com-plete a task. Our work aims to improve the performanceof such a human-robot team: the robot tries to guide thehuman towards an effective strategy, sometimes against thehuman’s own preference, while still retaining his trust. Weachieve this through a principled human-robot mutual adap-tation formalism. We integrate a bounded-memory adapta-tion model of the human into a partially observable stochas-tic decision model, which enables the robot to adapt to anadaptable human. When the human is adaptable, the robotguides the human towards a good strategy, maybe unknownto the human in advance. When the human is stubborn andnot adaptable, the robot complies with the human’s prefer-ence in order to retain their trust. In the shared autonomysetting, unlike many other common human-robot collabora-tion settings, only the robot actions can change the physicalstate of the world, and the human and robot goals are notfully observable. We address these challenges and show in ahuman subject experiment that the proposed mutual adap-tation formalism improves human-robot team performance,while retaining a high level of user trust in the robot, com-pared to the common approach of having the robot strictlyfollowing participants’ preference.
1. INTRODUCTIONAssistive robot arms show great promise in increasing the
independence of people with upper extremity disabilities [1–3]. However, when a user teleoperates directly a roboticarm via an interface such as a joystick, the limitation ofthe interface, combined with the increased capability andcomplexity of robot arms, often makes it difficult or tediousto accomplish complex tasks.
Shared autonomy alleviates this issue by combining directteleoperation with autonomous assistance [4–8]. In recentwork by Javdani et al., the robot estimates a distribution of
Permission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full cita-tion on the first page. Copyrights for components of this work owned by others thanACM must be honored. Abstracting with credit is permitted. To copy otherwise, or re-publish, to post on servers or to redistribute to lists, requires prior specific permissionand/or a fee. Request permissions from [email protected].
HRI ’17, March 06-09, 2017, Vienna, Austriac© 2017 ACM. ISBN 978-1-4503-4336-7/17/03. . . $15.00
DOI: http://dx.doi.org/10.1145/2909824.3020253
𝑎"
𝑥"$ = 𝑇(𝑥",𝑎")𝑥"$
α
1-α
𝑎*
Figure 1: Table clearing task in a shared autonomy setting.The user operates the robot using a joystick interface andmoves the robot towards the left bottle, which is a subopti-mal goal. The robot plans its actions based on its estimate ofthe current human goal and the probability α of the humanswitching towards a new goal indicated by the robot.
user goals based on the history of user inputs, and assiststhe user for that distribution [9]. The user is assumed to be

Figure 2: The user guides the robot towards an unstable grasp, resulting in task failure.
always right about their goal choice. Therefore, if the as-sistance strategy knows the user’s goal, it will select actionsto minimize the cost-to-go to that goal. This assumption isoften not true, however. For instance, a user may choose anunstable grasp when picking up an object (Fig. 2), or theymay arrange items in the wrong order by stacking a heavyitem on top of a fragile one. Fig. 1 shows a shared autonomyscenario, where the user teleoperates the robot towards theleft bottle. We assume that the robot knows the optimal goalfor the task : picking up the right bottle is a better choice, forinstance because the left bottle is too heavy, or because therobot has less uncertainty about the right bottle’s location.Intuitively, if the human insists on the left bottle, the robotshould comply; failing to do so can have a negative effect onthe user’s trust in the robot, which may lead to disuse of thesystem [10–12]. If the human is willing to adapt by align-ing its actions with the robot, which has been observed inadaptation between humans and artifacts [13,14], the robotshould insist towards the optimal goal. The human-robotteam then exhibits a mutually adaptive behavior, where therobot adapts its own actions by reasoning over the adaptabil-ity of the human teammate.
Nikolaidis et al. [15] proposed a mutual adaptation for-malism in collaborative tasks, e.g., when a human and arobot work together to carry a table out of the room. Therobot builds a Bounded-memory Adaptation Model (BAM)of the human teammate, and it integrates the model into apartially observable stochastic process, which enables robotadaptation to the human: If the user is adaptable, the robotwill disagree with them, expecting them to switch towardsthe optimal goal. Otherwise, the robot will align its actionswith the user policy, thus retaining their trust.
A characteristic of many collaborative settings is that hu-man and robot both affect the world state, and that dis-agreement between the human and the robot impedes taskcompletion. For instance, in the table-carrying example, ifhuman and robot attempt to move the table in opposingdirections with equal force, the table will not move and thetask will not progress. Therefore, a robot that optimizes thetask completion time will account for the human adaptabil-ity implicitly in its optimization process: if the human isnon-adaptable, the only way for the robot to complete thetask is to follow the human goal. This is not the case ina shared-autonomy setting, since the human actions do notaffect the state of the task. Therefore, a robot that solelymaximizes task performance in that setting will always movetowards the optimal goal, ignoring human inputs altogether.
In this work, we propose a generalized human-robot mu-tual adaptation formalism, and we formulate mutual adap-tation in the collaboration and shared-autonomy settings asinstances of this formalism.
We identify that in the shared-autonomy setting (1) tasksmay typically exhibit less structure than in the collabora-tion domain, which limits the observability of the user’s in-tent, and (2) only robot actions directly affect task progress.We address the first challenge by including the operatorgoal as an additional latent variable in a mixed-observabilityMarkov decision process (MOMDP) [16]. This allows therobot to maintain a probability distribution over the usergoals based on the history of operator inputs. We also takeinto account the uncertainty that the human has on therobot goal by modeling the human as having a probabil-ity distribution over the robot goals (Sec. 3). We addressthe second challenge by proposing an explicit penalty fordisagreement in the reward function that the robot is max-imizing (Sec. 4). This allows the robot to infer simultane-ously the human goal and the human adaptability, reasonover how likely the human is to switch their goal based onthe robot actions, and guide the human towards the optimalgoal while retaining their trust.
We conducted a human subject experiment (n = 51) withan assistive robotic arm on a table-clearing task. Resultsshow that the proposed formalism significantly improvedhuman-robot team performance, compared to the robot fol-lowing participants’ preference, while retaining a high levelof human trust in the robot.
2. PROBLEM SETTINGA human-robot team can be treated as a multi-agent sys-
tem, with world state xworld ∈ Xworld, robot action ar ∈ Ar,and human action ah ∈ Ah. The system evolves according toa stochastic state transition function T : Xworld×Ar×Ah →Π(Xworld). Additionally, we model the user as having a goal,among a discrete set of goals g ∈ G. We assume access to astochastic joint policy for each goal, which we call modal pol-icy, or mode m ∈M . We call mh the modal policy that thehuman is following at a given time-step, and mr the robotmode, which is the [perceived by the human] robot policytowards a goal. The human mode, mh ∈M is not fully ob-servable. Instead, the robot has uncertainty over the user’spolicy, that can modeled as a Partially Observable MarkovDecision Process (POMDP). Observations in the POMDPcorrespond to human actions ah ∈ Ah. Given a sequenceof human inputs, we infer a distribution over user modalpolicies using an observation function O(ah|xworld,mh).
Contrary to previous work in modeling human intention [17]and in shared autonomy [9], the user goal is not static.Instead, we define a transition function Tmh : M × Ht ×Xworld×Ar → Π(M), where ht is the history of states, robotand human actions
(x0world, a
0r, a
0h, . . . , x
t−1world, a
t−1r , at−1
h
). The
function models how the human mode may change over time.At each time step, the human-robot team receives a real-

valued reward that in the general case also depends on thehuman mode mh and history ht: R(mh, ht, xworld, ar, ah).The reward captures both the relative cost of each goalg ∈ G, as well as the cost of disagreement between the hu-man and the robot. The robot goal is then to maximize theexpected total reward over time:
∑∞t=0 γ
tR(t), where thediscount factor γ ∈ [ 0, 1) gives higher weight to immediaterewards than future ones.
Computing the maximization is hard: Both Tmh and Rdepend on the whole history of states, robot and human ac-tions ht. We use the Bounded-memory Adaptation Model [15]to simplify the problem.
2.1 Bounded-Memory Adaptation ModelNikolaidis et al. [15] proposed the Bounded-memory Adap-
tation Model (BAM). The model is based on the assump-tion of “bounded rationality” was proposed first by HerbertSimon: people often do not have the time and cognitive ca-pabilities to make perfectly rational decisions [18]. In gametheory, bounded rationality has been modeled by assumingthat players have a “bounded memory” or “bounded recall”and base their decisions on recent observations [19–21].
The BAM model allows us to simplify the problem, bymodeling the human as making decisions not on the wholehistory of interactions, but on the last k interactions with therobot. This allows us to simplify the transition function Tmh
and reward function R defined in the previous section, sothat they depend on the history of the last k time-steps only.Additionally, BAM provides a parameterization of the tran-sition function Tmh , based on the parameter α ∈ A, whichis the human adaptability. The adaptability represents one’sinclination to adapt to the robot. With the BAM assump-tions, we have Tmh : M × A × Hk × Xworld × Ar → Π(M)and R : M ×Hk ×Xworld ×Ar ×Ah → R. We describe theimplementation of Tmh in Sec. 3 and of R in Sec. 4.
2.2 Shared AutonomyThe shared autonomy setting allows us to further simplify
the general problem: the world state consists only of therobot configuration xr ∈ Xr, so that xr ≡ xworld. A robotaction induces a deterministic change in the robot configu-ration. The human actions ah ∈ Ah are inputs through ajoystick interface and do not affect the world state. There-fore, the transition function of the system is deterministicand can be defined as: T : Xr ×Ar → Xr.
2.3 CollaborationWe include the collaboration setting formalism for com-
pleteness. Contrary to the shared-autonomy setting, bothhuman and robot actions affect the world state, and thetransition function can be deterministic or stochastic. Inthe deterministic case, it is T : Xworld×Ar ×Ah → Xworld.Additionally, the reward function does not require a penaltyfor disagreement between the human and robot modes; in-stead, it can depend only on the relative cost for each goal,so that R : Xworld → R. Finally, if the task exhibits consid-erable structure, the modes may be directly observed fromthe human and robot actions. In that case, the robot doesnot maintain a distribution over modal policies.
3. HUMAN AND ROBOT MODE INFERENCEWhen the human provides an input through a joystick in-
terface, the robot makes an inference on the human mode. In
GL GR
S
GL GR
S
Figure 3: (left) Paths corresponding to three different modalpolicies that lead to the same goal GL. We use a stochasticmodal policy mL to compactly represent all feasible pathsfrom S to GL. (right) The robot moving upwards from pointS could be moving towards either GL or GR.
the example table-clearing task of Fig. 1, if the robot movesto the right, the human will infer that the robot follows amodal policy towards the right bottle. Similarly, if the hu-man moves the joystick to the left, the robot will considermore likely that the human follows a modal policy towardsthe left bottle. In this section, we formalize the inferencethat human and robot make on each other’s goals.
3.1 Stochastic Modal PoliciesIn the shared autonomy setting, there can be a very large
number of modal policies that lead to the same goal. Weuse as example the table-clearing task of Fig. 1. We letGL represent the left bottle, GR the right bottle, and Sthe starting end-effector position of the robot. Fig. 3-leftshows paths from three different modal policies that lead tothe same goal GL. Accounting for a large set of modes canincrease the computational cost, in particular if we assumethat the human mode is partially observable (Section 5).
Therefore, we define a modal policy as a stochastic joint-policy over human and robot actions, so that m : Xr×Ht →Π(Ar)×Π(Ah). A stochastic modal policy compactly repre-sents a probability distribution over paths and allows us toreason probabilistically about the future actions of an agentthat does not move in a perfectly predictable manner. Forinstance, we can use the principle of maximum entropy tocreate a probability distribution over all paths from start tothe goal [22,23]. While a stochastic modal policy representsthe uncertainty of the observer over paths, we do not requirethe agent to actually follow a stochastic policy.
3.2 Full Observability AssumptionWhile mr, mh can be assumed to be observable for a vari-
ety of structured tasks in the collaboration domain [15], thisis not the case for the shared autonomy setting because ofthe following factors:Different policies invoke the same action. Assume twomodal policies in Fig. 3, one for the left goal shown in redin Fig. 3-left, and a symmetric policy for the right goal (notshown). An agent moving upwards (Figure 3-right) couldbe following either of the two with equal probability. Inthat case, inference of the exact modal policy without anyprior information is impossible, and the observer needs tomaintain a uniform belief over the two policies.Human inputs are noisy. The user provides its inputsto the system through a joystick interface. These inputs arenoisy: the user may “overshoot” an intended path and cor-rect their input, or move the joystick in the wrong direction.In the fully observable case, this would result in an incor-

rect inference of the human mode. Maintaining a belief overmodal policies allows robustness to human mistakes.
This leads us to assume that modal policies are partiallyobservable. We model how the human infers the robot mode,as well as how the robot infers the human mode, in thefollowing sections.
3.3 Robot Mode InferenceThe bounded-memory assumption dictates that the hu-
man does not recall the whole history of states and actions,but only a recent history of the last k time-steps. The hu-man attributes the robot actions to a robot mode mr.
P (mr|hk, xtr, atr) = P (mr|xt−k+1r , at−k+1
r , ..., xtr, atr)
= η P (at−k+1r , ..., atr|mr, x
t−k+1r , ..., xtr)
(1)
In this work, we consider modal policies that generateactions based only on the current world state, so that M :Xr → Π(Ah)×Π(Ar).
Therefore Eq. 1 can be simplified as follows, wheremr(xtr, a
tr)
denotes the probability of the robot taking action ar at timet, if it follows modal policy mr:
P (mr|hk, xtr, atr) = η mr(xt−k+1r , at−k+1
r )...mr(xtr, a
tr) (2)
P (mr|hk, xtr, atr) is the [estimated by the robot] humanbelief on the robot mode mr.
3.4 Human Mode InferenceTo infer the human mode, we need to implement the dy-
namics model Tmh that describes how the human modeevolves over time, and the observation function O that al-lows the robot to update its belief on the human mode fromthe human actions.
In Sec. 2 we defined a transition function Tmh , that indi-cates the probability of the human switching from mode mh
to a new mode m′h, given a history hk and their adaptabilityα. We simplify the notation, so that xr ≡ xtr, ar ≡ atr andx ≡ (hk, xr):
Tmh(x, α,mh, ar,m′h) = P (m′h|x, α,mh, ar)
=∑mr
P (m′h,mr|x, α,mh, ar)
=∑mr
P (m′h|x, α,mh, ar,mr)× P (mr|x, α,mh, ar)
=∑mr
P (m′h|α,mh,mr)× P (mr|x, ar)
(3)
The first term gives the probability of the human switch-ing to a new mode m′h, if the human mode is mh and therobot mode is mr. Based on the BAM model [15], the hu-man switches to mr, with probability α and stays at mh
with probability 1 − α. Nikolaidis et al. [15] define α asthe human adaptability, which represents their inclinationto adapt to the robot. If α = 1, the human switches to mr
with certainty. If α = 0, the human insists on their modemh and does not adapt. Therefore:
P (m′h|α,mh,mr) =
α m′h ≡ mr
1− α m′h ≡ mh
0 otherwise(4)
The second term in Eq. 3 is computed using Eq. 2, and itis the [estimated by the human] robot mode.
Eq. 3 describes that the probability of the human switch-ing to a new robot mode mr depends on the human adapt-ability α, as well as on the uncertainty that the human hasabout the robot following mr. This allows the robot to com-pute the probability of the human switching to the robotmode, given each robot action.
The observation function O : Xr ×M → Π(Ah) defines aprobability distribution over human actions ah. This distri-bution is specified by the stochastic modal policy mh ∈ M .Given the above, the human mode mh can be estimated bya Bayes filter, with b(mh) the robot’s previous belief on mh:
b′(m′h) =η O(m′h, x′r, ah)
∑mh∈M
Tmh(x, α,mh, ar,m′h)b(mh)
(5)
In this section, we assumed that α is known to the robot.In practice, the robot needs to estimate both mh and α. Weformulate this in Sec. 5.
4. DISAGREEMENT BETWEEN MODESIn the previous section we formalized the inference that
human and robot make on each other’s goals. Based on that,the robot can infer the human goal and it can reason overhow likely the human is to switch goals given a robot action.
Intuitively, if the human insists on their goal, the robotshould follow the human goal, even if it is suboptimal, inorder to retain human trust. If the human is willing tochange goals, the robot should move towards the optimalgoal. We enable this behavior by proposing in the robot’sreward function a penalty for disagreement between humanand robot modes. The intuition is that if the human is non-adaptable, they will insist on their own mode throughoutthe task, therefore the expected accumulated cost of dis-agreeing with the human will outweigh the reward of theoptimal goal. In that case, the robot will follow the humanpreference. If the human is adaptable, the robot will movetowards the optimal goal, since it will expect the human tochange modes.
We formulate the reward function that the robot is maxi-mizing, so that there is a penalty for following a mode thatis perceived to be different than the human’s mode.
R(x,mh, ar) =
Rgoal : xr ∈ GRother : xr /∈ G
(6)
If the robot is at a goal state xr ∈ G, a positive rewardassociated with that goal is returned, regardless of the hu-man mode mh and robot mode mr. Otherwise, there is apenalty C < 0 for disagreement between mh and mr, in-duced in Rother. The human does not observe mr directly,but estimates it from the recent history of robot states andactions (Sec. 3.3). Therefore, Rother is computed so that thepenalty for disagreement is weighted by the [estimated bythe human] probability of the robot actually following mr:
Rother =∑mr
Rm(mh,mr)P (mr|x, ar) (7)

where Rm(mh,mr) =
0 : mh ≡ mr
C : mh 6= mr
(8)
5. HUMAN-ROBOT MUTUAL ADAPTATIONFORMALISM
5.1 MOMDP FormulationIn Section 3.4, we showed how the robot estimates the hu-
man mode, and how it computes the probability of the hu-man switching to the robot mode based on the human adapt-ability. In Section 4, we defined a reward function that therobot is maximizing, which captures the trade-off betweengoing to the optimal goal and following the human mode.Both the human adaptability and the human mode are notdirectly observable. Therefore, the robot needs to estimatethem through interaction, while performing the task. Thisleads us to formulate this problem as a mixed-observabilityMarkov Decision Process (MOMDP) [16]. This formulationallows us to compute an optimal policy for the robot thatwill maximize the expected reward that the human-robotteam will receive, given the robot’s estimates of the humanadaptability and of the human mode. We define a MOMDPas a tuple X,Y,Ar, Tx, Tα, Tmh , R,Ω, O:• X : Xr × Akr is the set of observable variables. These
are the current robot configuration xr, as well as thehistory hk. Since xr transitions deterministically, weonly need to register the current robot state and robotactions at−k+1
r , ..., atr.
• Y : A×M is the set of partially observable variables.These are the human adaptability α ∈ A, and the hu-man mode mh ∈M .
• Ar is a finite set of robot actions. We model actionsas transitions between discrete robot configurations.
• Tx : X × Ar −→ X is a deterministic mapping from arobot configuration xr, history hk and action ar, to asubsequent configuration x′r and history h′k.
• Tα : A × Ar −→ Π(A) is the probability of the hu-man adaptability being α′ at the next time step, if theadaptability of the human at time t is α and the robottakes action ar. We assume the human adaptability tobe fixed throughout the task.
• Tmh : X × A ×M × Ar −→ Π(M) is the probabilityof the human switching from mode mh to a new modem′h, given a history hk, robot state xr, human adapt-ability α and robot action ar. It is computed usingEq. 3, Sec. 3.4.
• R : X ×M ×Ar −→ R is a reward function that givesan immediate reward for the robot taking action argiven a history hk, human mode mh and robot statexr. It is defined in Eq. 6, Sec. 4.
• Ω is the set of observations that the robot receives. Anobservation is a human input ah ∈ Ah (Ω ≡ Ah).
• O : M × Xr −→ Π(Ω) is the observation function,which gives a probability distribution over human ac-tions for a mode mh at state xr. This distribution isspecified by the stochastic modal policy mh ∈M .
5.2 Belief UpdateBased on the above, the belief update for the MOMDP
is [16]:
b′(α′,m′h) = ηO(m′h, x′r, ah)
∑α∈A
∑mh∈M
Tx(x, ar, x′)
Tα(α, ar, α′)Tmh(x, α,mh, ar,m
′h)b(α,mh)
(9)
We note that since the MOMDP has two partially ob-servable variables, α and mh, the robot maintains a jointprobability distribution over both variables.
5.3 Robot PolicyWe solve the MOMDP for a robot policy π∗r (b) that is
optimal with respect to the robot’s expected total reward.The stochastic modal policies may assign multiple actions
at a given state. Therefore, even if mh ≡ mr, ar may notmatch the human input ah. Such disagreements are unneces-sary when human and robot modes are the same. Therefore,we let the robot actions match the human inputs, if the robothas enough confidence that robot and human modes (com-puted using Eq. 2, 5) are identical in the current time-step.Otherwise, the robot executes the action specified by theMOMDP optimal policy. We leave for future work addinga penalty for disagreement between actions, which we hy-pothesize it would result in similar behavior.
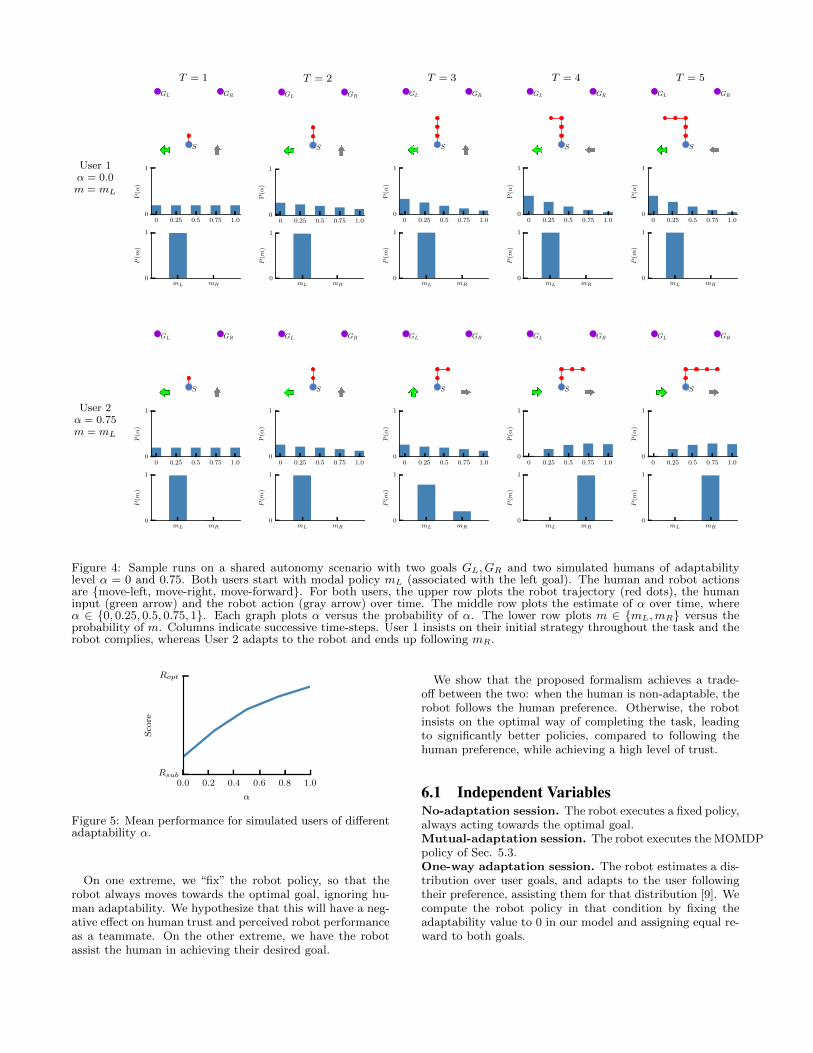
5.4 SimulationsFig. 4 shows the robot behavior for two simulated users,
one with low adaptability (User 1, α = 0.0), and one withhigh adaptability (User 2, α = 0.75) for a shared auton-omy scenario with two goals, GL and GR, corresponding tomodal policies mL and mR respectively. Both users startwith modal policy mL (left goal). The robot uses the hu-man input to estimate both mh and α. We set a bounded-memory of k = 1 time-step. If human and robot disagree andthe human insists on their modal policy, then the MOMDPbelief is updated so that smaller values of adaptability αhave higher probability (lower adaptability). It the humanaligns its inputs to the robot mode, larger values becomemore likely. If the robot infers the human to be adaptable,it moves towards the optimal goal. Otherwise, it complieswith the human, thus retaining their trust.
Fig. 5 shows the team-performance over α, averaged over1000 runs with simulated users. We evaluate performanceby the reward of the goal achieved, where Ropt is the rewardfor the optimal and Rsub for the sub-optimal goal. We seethat the more adaptable the user, the more often the robotwill reach the optimal goal. Additionally, we observe thatfor α = 0.0, the performance is higher than Rsub. This is be-cause the simulated user may choose to move forward in thefirst time-steps; when the robot infers that they are stub-born, it is already close to the optimal goal and continuesmoving to that goal.
6. HUMAN SUBJECT EXPERIMENTWe conduct a human subject experiment (n = 51) in a
shared autonomy setting. We are interested in showing thatthe human-robot mutual adaptation formalism can improvethe performance of human-robot teams, while retaining highlevels of perceived collaboration and trust in the robot in theshared autonomy domain.
User 1α = 0.0m = mL
T = 1
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
T = 2
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
T = 3
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
T = 4
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
T = 5
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
User 2α = 0.75m = mL
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
GL GR
S
0 0.25 0.5 0.75 1.00
1
P(α
)
mL mR0
1
P(m
)
Figure 4: Sample runs on a shared autonomy scenario with two goals GL, GR and two simulated humans of adaptabilitylevel α = 0 and 0.75. Both users start with modal policy mL (associated with the left goal). The human and robot actionsare move-left, move-right, move-forward. For both users, the upper row plots the robot trajectory (red dots), the humaninput (green arrow) and the robot action (gray arrow) over time. The middle row plots the estimate of α over time, whereα ∈ 0, 0.25, 0.5, 0.75, 1. Each graph plots α versus the probability of α. The lower row plots m ∈ mL,mR versus theprobability of m. Columns indicate successive time-steps. User 1 insists on their initial strategy throughout the task and therobot complies, whereas User 2 adapts to the robot and ends up following mR.
0.0 0.2 0.4 0.6 0.8 1.0
α
Rsub
Ropt
Sco
re
Figure 5: Mean performance for simulated users of differentadaptability α.
On one extreme, we “fix” the robot policy, so that therobot always moves towards the optimal goal, ignoring hu-man adaptability. We hypothesize that this will have a neg-ative effect on human trust and perceived robot performanceas a teammate. On the other extreme, we have the robotassist the human in achieving their desired goal.
We show that the proposed formalism achieves a trade-off between the two: when the human is non-adaptable, therobot follows the human preference. Otherwise, the robotinsists on the optimal way of completing the task, leadingto significantly better policies, compared to following thehuman preference, while achieving a high level of trust.
6.1 Independent VariablesNo-adaptation session. The robot executes a fixed policy,always acting towards the optimal goal.Mutual-adaptation session. The robot executes the MOMDPpolicy of Sec. 5.3.One-way adaptation session. The robot estimates a dis-tribution over user goals, and adapts to the user followingtheir preference, assisting them for that distribution [9]. Wecompute the robot policy in that condition by fixing theadaptability value to 0 in our model and assigning equal re-ward to both goals.

6.2 HypothesesH1 The performance of teams in the No-adaptation condi-tion will be better than of teams in the Mutual-adaptationcondition, which will in turn be better than of teams in theOne-way adaptation condition. We expected teams in theNo-adaptation condition to outperform the teams in theother conditions, since the robot will always go to the opti-mal goal. In the Mutual-adaptation condition, we expecteda significant number of users to adapt to the robot andswitch their strategy towards the optimal goal. Therefore,we posited that this would result in an overall higher reward,compared to the reward resulting from the robot followingthe participants’ preference throughout the task (One-wayadaptation).H2 Participants that work with the robot in the One-wayadaptation condition will rate higher their trust in the robot,as well as their perceived collaboration with the robot, com-pared to working with the robot in the Mutual-adaptationcondition,. Additionally, participants in the Mutual-adaptationcondition will give higher ratings, compared to working withthe robot in the No-adaptation condition. We expected usersto trust the robot more in the One-way adaptation con-dition than in the other conditions, since in that condi-tion the robot will always follow their preference. In theMutual-adaptation condition, we expected users to trust therobot more and perceive it as a better teammate, comparedwith the robot that executed a fixed strategy ignoring users’adaptability (No-adaptation). Previous work in collabora-tive tasks has shown a significant improvement in humantrust, when the robot had the ability to adapt to the humanparter [15,24,25]
6.3 Experiment Setting: A Table Clearing TaskParticipants were asked to clear a table off two bottles
placed symmetrically, by providing inputs to a robotic armthrough a joystick interface (Fig. 1). They controlled therobot in Cartesian space by moving it in three different di-rections: left, forward and right. We first instructed them inthe task, and asked them to do two training sessions, wherethey practiced controlling the robot with the joystick. Wethen asked them to choose which of the two bottles theywould like the robot to grab first, and we set the robot pol-icy, so that the other bottle was the optimal goal. Thisemulates a scenario where, for instance, the robot would beunable to grasp one bottle without dropping the other, orwhere one bottle would be heavier than the other and shouldbe placed in the bin first. In the one-way and mutual adap-tation conditions, we told them that “the robot has a mindof its own, and it may choose not to follow your inputs.” Par-ticipants then did the task three times in all conditions, andthen answered a post-experimental questionnaire that useda five-point Likert scale to assess their responses to workingwith the robot. Additionally, in a video-taped interview atthe end of the task, we asked participants that had changedstrategy during the task to justify their action.
6.4 Subject AllocationWe recruited 51 participants from the local community,
and chose a between-subjects design in order to not bias theusers with policies from previous conditions.
6.5 MOMDP ModelThe size of the observable state-space X was 52 states.
We empirically found that a history length of k = 1 inBAM was sufficient for this task, since most of the sub-jects that changed their preference did so reacting to theprevious robot action. The human and robot actions weremove-left, move-right, move-forward. We specified twostochastic modal policies mL,mR, one for each goal. Weadditionally assumed a discrete set of values of the adapt-ability α : 0.0, 0.25, 0.5, 0.75, 1.0. Therefore, the total sizeof the MOMDP state-space was 5 × 2 × 52 = 520 states.We selected the reward so that Ropt = 11 for the optimalgoal, Rsub = 10 for the suboptimal goal, and C = −0.32for the cost of mode disagreement (Eq. 8). We computedthe robot policy using the SARSOP solver [26], a point-based approximation algorithm which, combined with theMOMDP formulation, can scale up to hundreds of thou-sands of states [17].
7. ANALYSIS
7.1 Objective MeasuresWe consider hypothesis H1, that the performance of teams
in the No-adaptation condition will be better than of teamsin the Mutual-adaptation condition, which in turn will bebetter than of teams in the One-way adaptation condition.
Nine participants out of 16 (56%) in the Mutual-adaptationcondition guided the robot towards the optimal goal, whichwas different than their initial preference, during the finaltrial of the task, while 12 out of 16 (75%) did so at one ormore of the three trials. From the participants that changedtheir preference, only one stated that they did so for reasonsirrelevant to the robot policy. On the other hand, only twoparticipants out of 17 in the One-way adaptation conditionchanged goals during the task, while 15 out of 17 guided therobot towards their preferred, suboptimal goal in all trials.This indicates that the adaptation observed in the Mutual-adaptation condition was caused by the robot behavior.
We evaluate team performance by computing the meanreward over the three trials, with the reward for each trialbeing Ropt if the robot reached the optimal goal and Rsubif the robot reached the suboptimal goal (Fig. 6-left). Asexpected, a Kruskal-Wallis H test showed that there wasa statistically significant difference in performance amongthe different conditions (χ2(2) = 39.84, p < 0.001). Pair-wise two-tailed Mann-Whitney-Wilcoxon tests with Bonfer-roni corrections showed the difference to be statistically sig-nificant between the No-adaptation and Mutual-adaptation(U = 28.5, p < 0.001), and Mutual-adaptation and One-wayadaptation (U = 49.5, p = 0.001) conditions. This supportsour hypothesis.
7.2 Subjective MeasuresRecall hypothesis H2, that participants in the Mutual-
adaptation condition would rate their trust and perceivedcollaboration with the robot higher than in the No-adaptationcondition, but lower than in the One-way adaptation condi-tion. Table I shows the two subjective scales that we used.The trust scales were used as-is from [27]. We additionallychose a set of questions related to participants’ perceivedcollaboration with the robot.
Both scales had good consistency. Scale items were com-bined into a score. Fig. 6-center shows that both partici-pants’ trust (M = 3.94, SE = 0.18) and perceived collab-oration (M = 3.91, SE = 0.12) were high in the Mutual-

Trust PerceivedCollaboration
1
2
3
4
5
Rati
ngs
Rsub
Ropt
Sco
re
Rsub Ropt
Score
1
5
Tru
st
Figure 6: Findings for objective and subjective measures.
adaptation condition. One-way ANOVAs showed a statis-tically significant difference between the three conditions inboth trust (F (2, 48) = 8.370, p = 0.001) and perceived col-laboration (F (2, 48) = 9.552, p < 0.001). Tukey post-hoctests revealed that participants of the Mutual-adaptationcondition trusted the robot more, compared to participantsthat worked with the robot in the No-adaptation condition(p = 0.010). Additionally, they rated higher their perceivedcollaboration with the robot (p = 0.017). However, therewas no significant difference in either measure between par-ticipants in the One-way adaptation and Mutual-adaptationconditions. We attribute these results to the fact that theMOMDP formulation allowed the robot to reason over its es-timate of the adaptability of its teammate; if the teammateinsisted towards the suboptimal goal, the robot respondedto the input commands and followed the user’s preference. Ifthe participant changed their inputs based on the robot ac-tions, the robot guided them towards the optimal goal, whileretaining a high level of trust. By contrast, the robot in theNo-adaptation condition always moved towards the optimalgoal ignoring participants’ inputs, which in turn had a neg-ative effect on subjective measures.
8. DISCUSSIONIn this work, we proposed a human-robot mutual adapta-
tion formalism in a shared autonomy setting. In a humansubject experiment, we compared the policy computed withour formalism, with an assistance policy, where the robothelped participants to achieve their intended goal, and witha fixed policy where the robot always went towards the op-timal goal.
As Fig. 6 illustrates, participants in the one-way adapta-tion condition had the worst performance, since they guidedthe robot towards a suboptimal goal. The fixed policy achievedmaximum performance, as expected. However, this came tothe detriment of human trust in the robot. On the otherhand, the assistance policy in the One-way adaptation con-dition resulted in the highest trust ratings — albeit not sig-nificantly higher than the ratings in the Mutual-adaptationcondition — since the robot always followed the user prefer-ence and there was no goal disagreement between human androbot. Mutual-adaptation balanced the trade-off betweenoptimizing performance and retaining trust: users in thatcondition trusted the robot more than in the No-adaptationcondition, and performed better than in the One-way adap-tation condition.
Fig. 6-right shows the three conditions with respect totrust and performance scores. We can make the MOMDPpolicy identical to either of the two policies in the end-points,
Table I: Subjective Measures
Trust α = .851.I trusted the robot to do the right thing at the righttime.2.The robot was trustworthy.Perceived Collaboration α = .811.I was satisfied with ADA and my performance.2.The robot and I worked towards mutually agreedupon goals.3.The robot and I collaborated well together4.The robot’s actions were reasonable.5.The robot was responsive to me.
by changing the MOMDP model parameters. If we fix in themodel the human adaptability to 0 and assign equal costsfor both goals, the robot would assist the user in their goal(One-way adaptation). If we fix adaptability to 1 in themodel (or we remove the penalty for mode disagreement),the robot will always go to the optimal goal (fixed policy).
The presented table-clearing task can be generalized with-out significant modifications to tasks with a large number ofgoals, human inputs and robot actions, such as picking goodgrasps in manipulation tasks (Fig. 2): The state-space sizeincreases linearly with (1/dt), where dt a discrete time-step,and with the number of modal policies. On the other hand,the number of observable states is polynomial to the numberof robot actions (O(Akr )), since each state includes historyhk: For tasks with large |Ar| and memory length k, we couldapproximate hk using feature-based representations.
Overall, we are excited to have brought about a better un-derstanding of the relationships between adaptability, per-formance and trust in a shared autonomy setting. We arevery interested in exploring applications of these ideas be-yond assistive robotic arms, to powered wheelchairs, remotemanipulators, and generally to settings where human inputsare combined with robot autonomy.
AcknowledgmentsWe thank Michael Koval, Shervin Javdani and Henny Admoni for
the very helpful discussion and advice.
FundingThis work was funded by the DARPA SIMPLEX program through
ARO contract number 67904LSDRP, National Institute of Health
R01 (#R01EB019335), National Science Foundation CPS (#1544797),
and the Office of Naval Research. We also acknowledge the Onas-
sis Foundation as a sponsor.

9. REFERENCES[1] M. Hillman, K. Hagan, S. Hagan, J. Jepson, and
R. Orpwood, “The weston wheelchair mountedassistive robot the design story,” Robotica, vol. 20,no. 02, pp. 125–132, 2002.
[2] S. D. Prior, “An electric wheelchair mounted roboticarm a survey of potential users,” Journal of medicalengineering & technology, vol. 14, no. 4, pp. 143–154,1990.
[3] J. Sijs, F. Liefhebber, and G. W. R. Romer,“Combined position & force control for a roboticmanipulator,” in 2007 IEEE 10th InternationalConference on Rehabilitation Robotics. IEEE, 2007,pp. 106–111.
[4] J. Kofman, X. Wu, T. J. Luu, and S. Verma,“Teleoperation of a robot manipulator using avision-based human-robot interface,” IndustrialElectronics, IEEE Transactions on, vol. 52, no. 5, pp.1206–1219, 2005.
[5] A. D. Dragan and S. S. Srinivasa, “A policy-blendingformalism for shared control,” The InternationalJournal of Robotics Research, vol. 32, no. 7, pp.790–805, 2013.
[6] W. Yu, R. Alqasemi, R. Dubey, and N. Pernalete,“Telemanipulation assistance based on motionintention recognition,” in Robotics and Automation,2005. ICRA 2005. Proceedings of the 2005 IEEEInternational Conference on. IEEE, 2005, pp.1121–1126.
[7] P. Trautman, “Assistive planning in complex, dynamicenvironments: a probabilistic approach,” in Systems,Man, and Cybernetics (SMC), 2015 IEEEInternational Conference on. IEEE, 2015, pp.3072–3078.
[8] D. Gopinath, S. Jain, and B. D. Argall,“Human-in-the-loop optimization of shared autonomyin assistive robotics,” IEEE Robotics and AutomationLetters, vol. 2, no. 1, pp. 247–254, 2017.
[9] S. Javdani, S. Srinivasa, and J. A. D. Bagnell, “Sharedautonomy via hindsight optimization,” in Proceedingsof Robotics: Science and Systems, Rome, Italy, July2015.
[10] P. A. Hancock, D. R. Billings, K. E. Schaefer, J. Y.Chen, E. J. De Visser, and R. Parasuraman, “Ameta-analysis of factors affecting trust in human-robotinteraction,” Human Factors, 2011.
[11] M. Salem, G. Lakatos, F. Amirabdollahian, andK. Dautenhahn, “Would you trust a (faulty) robot?:Effects of error, task type and personality onhuman-robot cooperation and trust,” in HRI, 2015.
[12] J. J. Lee, W. B. Knox, J. B. Wormwood, C. Breazeal,and D. DeSteno, “Computationally modelinginterpersonal trust,” Front. Psychol., 2013.
[13] Y. Xu, K. Ueda, T. Komatsu, T. Okadome,T. Hattori, Y. Sumi, and T. Nishida, “Wozexperiments for understanding mutual adaptation,” Ai& Society, vol. 23, no. 2, pp. 201–212, 2009.
[14] T. Komatsu, A. Ustunomiya, K. Suzuki, K. Ueda,K. Hiraki, and N. Oka, “Experiments toward a mutualadaptive speech interface that adopts the cognitivefeatures humans use for communication and inducesand exploits users’ adaptations,” International Journalof Human-Computer Interaction, vol. 18, no. 3, pp.243–268, 2005.
[15] S. Nikolaidis, A. Kuznetsov, D. Hsu, and S. Srinivasa,“Formalizing human-robot mutual adaptation: Abounded memory model,” in The EleventhACM/IEEE International Conference on HumanRobot Interation. IEEE Press, 2016, pp. 75–82.
[16] S. C. Ong, S. W. Png, D. Hsu, and W. S. Lee,“Planning under uncertainty for robotic tasks withmixed observability,” IJRR, 2010.
[17] T. Bandyopadhyay, K. S. Won, E. Frazzoli, D. Hsu,W. S. Lee, and D. Rus, “Intention-aware motionplanning,” in WAFR. Springer, 2013.
[18] H. A. Simon, “Rational decision making in businessorganizations,” The American economic review, pp.493–513, 1979.
[19] R. Powers and Y. Shoham, “Learning againstopponents with bounded memory.” in IJCAI, 2005.
[20] D. Monte, “Learning with bounded memory in games,”GEB, 2014.
[21] R. J. Aumann and S. Sorin, “Cooperation andbounded recall,” GEB, 1989.
[22] B. D. Ziebart, N. Ratliff, G. Gallagher, C. Mertz,K. Peterson, J. A. Bagnell, M. Hebert, A. K. Dey, andS. Srinivasa, “Planning-based prediction forpedestrians,” in IROS, 2009.
[23] B. D. Ziebart, A. L. Maas, J. A. Bagnell, and A. K.Dey, “Maximum entropy inverse reinforcementlearning.” in AAAI, 2008, pp. 1433–1438.
[24] J. Shah, J. Wiken, B. Williams, and C. Breazeal,“Improved human-robot team performance usingchaski, a human-inspired plan execution system,” inHRI, 2011.
[25] P. A. Lasota and J. A. Shah, “Analyzing the effects ofhuman-aware motion planning on close-proximityhuman–robot collaboration,” Hum. Factors, 2015.
[26] H. Kurniawati, D. Hsu, and W. S. Lee, “Sarsop:Efficient point-based pomdp planning byapproximating optimally reachable belief spaces.” inRSS, 2008.
[27] G. Hoffman, “Evaluating fluency in human-robotcollaboration,” in HRI workshop on human robotcollaboration, vol. 381, 2013, pp. 1–8.












