
Eastern Progress - 11 May 1929 - Eastern Kentucky University
Upload
nguyendangCategory
view
216download
1
IBM ATS Deep Computing
© 2007 IBM Corporation
HPC Workshop – University of KentuckyMay 9, 2007 – May 10, 2007
Balaji Veeraraghavan, Ph. D.Andrew Komornicki, Ph. D.Gregory Verstraeten

IBM ATS Deep Computing
© 2007 IBM Corporation
Agenda
Introduction
Intel Cluster Architecture
Single Core Optimization
Software Tools
Parallel Programming
Power5+ Environment vs Intel
(Some) User Environment
Wrap-up

IBM ATS Deep Computing
© 2007 IBM Corporation
Software Priorities to Keep in Mind
Correctness
Numerical Stability
(Frequently) Accurate Discretization
Flexibility
Performance or Efficiency (Memory and Speed)

IBM ATS Deep Computing
© 2007 IBM Corporation
Generic Look at CPU Industry
Clock Speed, execution optimization, Cache size
Physical Limitation
Moore’s Law Over?
Hyper-threading, Multi-core, Cache, Memory subsystem, I/O subsystem
Concurrency
Intel CPU / wikipedia

IBM ATS Deep Computing
© 2007 IBM Corporation
Does Dual core mean 2x Speed?

IBM ATS Deep Computing
© 2007 IBM Corporation
Going Forward
Performance Optimization is a High Priority
But what does Performance Optimization mean?– Serial vs Parallel
– Awareness to the Operating Environment
– Portability vs Fine Tuning
– Rethinking/Re-Engineering Algorithms and Data Structures

IBM ATS Deep Computing
© 2007 IBM Corporation
Performance
Hardware
Software Algorithm
Hardware: CPU, Memory, I/O, Network
Software: O/S, Compilers, Libraries
Algorithm: Data structures, Data Locality, procedures

IBM ATS Deep Computing
© 2007 IBM Corporation
Current Architecture at University of Kentucky
Hardware Layer

IBM ATS Deep Computing
© 2007 IBM Corporation
HPC Server Environment Architecture Existing UKY User Network
16 CPU @ 1.9 GHz128 GB memory2 disks @74 GB
~260 lines
x3650StorageNode 1
16 CPU @ 1.9 GHz128 GB memory2 disks @74 GB
16 CPU @ 1.9 GHz64 GB memory
2 disks @74 GB
16 CPU @ 1.9 GHz64 GB memory
2 disks @74 GB
16 CPU @ 1.9 GHz64 GB memory
2 disks @74 GB
...
x3650Management
server
p520Q management
serverUser Login
Blade 1User Login
Blade 2
...
DS4800
EXP810
EXP810
EXP810
EXP810
EXP810
x3650StorageNode 1
x3650StorageNode 1
x3650StorageNode 1
HS21: 9 Racks, 25 9U Chasses, 340 BladesEach blade: 4 w'crest cores, 3.0 GHz, 8 GB, 73 GB SAS
p575: 8 systems
1 DS48005 EXP81080 500 GB/7.2K SATADirect fiber ch'al attached
InfiniBand Switch (Voltaire 9288, 288 ports) InfiniBand Switch (Voltaire 9288, 288 ports)
~80 lines
2 Force10 GbE Switchs - 1 used for admin, 1 used for GPFS and other user activities
9 lines

IBM ATS Deep Computing
© 2007 IBM Corporation
Cluster Basic Building Block: IBM HS21 Bladecenter system
IBM
HS21 Bladecenter
Processors 4 cores @ 3.0 GHzIntel Woodcrest
Memory 8 GB per blade
OS Linux: SuSE SLES V9
Integrated Network
1 Gbit Ethernet, andInfiniband 4X
Application supported All Applications
Compiler Intel C and C++ V8.0Intel Fortran V9.0
A single HS21 blade
An HS21 Bladecenter ChaseContains 14 blades
UKY installed 25 Chassis with 340 blades

IBM ATS Deep Computing
© 2007 IBM Corporation
SMP Building Block: IBM p5-575 Server
Single IBM p5-575+ System
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
Installed at UKY8 p575 Systems
128 total processors
p575+ System
Processors 16 X 1.9 Ghz POWER5+
Memory 64 or 128 GB
Integrated Network
1 Gbit Ethernet, and InfiniBand
OS Linux: SuSE SLES V9
Compilers IBM xlf Fortran, c and C++
Application supported
Gaussian andother apps that need large
Memory or SMP

IBM ATS Deep Computing
© 2007 IBM Corporation
Intel Subsystem

IBM ATS Deep Computing
© 2007 IBM Corporation
Basic Layout (Blade level)
2 Sockets / Blade
2 Cores / Socket
4 MB L2 Cache / Socket
1333 MHz Front-side Bus
8 GB RAM Fully-Buffered DIMM
Front Side System Bus
Memory
Core 0 Core 1 Core 0 Core 1

IBM ATS Deep Computing
© 2007 IBM Corporation
Xeon 5100 Series (Woodcrest) DP Architecture

IBM ATS Deep Computing
© 2007 IBM Corporation
Processor Subsystem

IBM ATS Deep Computing
© 2007 IBM Corporation
What is important to Software Performance As far as CPU is concerned?
CPU Speed
L1/L2 cache size
L1/L2 Latency
Execution rate (keeping the processor busy)
Taking advantage of the Instruction Set
Support for Threading

IBM ATS Deep Computing
© 2007 IBM Corporation
Intel Core Micro-Architecture From: http://www.intel.com/technology/architecture/coremicro/#anchor2
First in Xeon 5100 Series (Woodcrest) then Tigerton MP processors (later)– Major change from NetBurst (Current XeonDP and XeonMP)– NetBurst – Socket F 604, Core Processors - LGA 771
• Dempsey/Tulsa are the last of the NetBurst processor family– Completely new core based on both NetBurst and Mobile Cores– Key Features
• Wide Dynamic Execution• Advanced Smart Cache• Smart Memory Access• Advanced Digital Media Boost• Intelligent Power Capability

IBM ATS Deep Computing
© 2007 IBM Corporation
Wide Dynamic Execution From:http://www.intel.com/technology/architecture/coremicro/#anchor2
Executes 4 instructions per clock cycle compared to 3 instructions per cycle for NetBurst
Net Burst
Core Microarchitecture

IBM ATS Deep Computing
© 2007 IBM Corporation
Xeon vs. Core™ Dual-Core Design (Smart Cache)Cache to cache data sharing is now done through shared cache
Cache to cache data sharing was done through bus interface (slow)
Intel Core™ Architecture
CPU0 CPU1
4 MB Shared Cache
BusInterface
CPU0
2MB L2 Cache
Intel Xeon Dual-Core Architecture
CPU1
2MB L2 Cache
BusInterface
In Xeon 5100 Series (Woodcrest) L2 Cache can be dynamically shared so if one processor needs all cache it can be used, or it can be shared equally

IBM ATS Deep Computing
© 2007 IBM Corporation
Smart Memory AccessFrom:http://www.intel.com/technology/architecture/coremicro/#anchor2
Improved Prefetch: Cores can speculatively load data for all instructions even before previous store instructions are flushed– In NetBurst speculation or prefetch cannot progress if previous store is in
the pipeline because the logic did not know if that store was in conflict

IBM ATS Deep Computing
© 2007 IBM Corporation
Advanced Digital Media BoostFrom:http://www.intel.com/technology/architecture/coremicro/#anchor2
Enables 128bit SSE Instructions to be executed in one clock cycle– SSE is Streaming SIMD instructions used in multi-media and array computation

IBM ATS Deep Computing
© 2007 IBM Corporation
Intelligent Power CapabilityFrom:http://www.intel.com/technology/architecture/coremicro/#anchor2
Intelligent Power management uses ultra-fine grained chip control to power down areas of the chip which are not active and turn them back on in an instant when needed for execution

IBM ATS Deep Computing
© 2007 IBM Corporation
Hyper-Threading
To improve Single Core performance of– Multi-threaded Application
– Multi-threaded Operating System
– Single-threaded Application in Multi-tasking environment

IBM ATS Deep Computing
© 2007 IBM Corporation
core
AS
core
AS AS
Physical Logical
AS - Architectural State

IBM ATS Deep Computing
© 2007 IBM Corporation
Memory Subsystem

IBM ATS Deep Computing
© 2007 IBM Corporation
Memory Operation – Bandwidth vs. Latency
Memory bandwidth is the sustainable throughput of a memory configuration for a particular workload– Usually measured under ideal and optimal conditions
• Sequential cache-line reads as rapidly as possible with no I/O– aka STREAM Benchmark
Unloaded memory latency usually called “memory latency” refers to the time it takes to read memory when the system is idle– Unloaded latencies are typically bandied about by technical experts– Usually expressed in nSec for the fastest possible access supported by
the memory configuration• Typical x64 unloaded memory latencies are 50 – 200nSec

IBM ATS Deep Computing
© 2007 IBM Corporation
Loaded memory latency is the average time to read and write memory while the system is running a particular applicationo Loaded memory latency is critically important to systems performance
o Loaded latency depends upon application workload
• Sensitive to read/write, cache hit and local/remote memory ratios
• Usually measured running Application workloads
It is important to appreciate how these characteristics correlate to system level performance
So let’s first learn how memory works!

IBM ATS Deep Computing
© 2007 IBM Corporation
Basic Memory Read - Overview
CPU
MemoryController
ADDRESS
ROW ADDESS STROBE
RAS to CAS LATENCY
COLUMN ADDRESS STROBEDATA TRANSFER
DIMMS
Data
DECODE LATENCYCAS LATENCYReview: Steps To Access Memory
1. Memory Controller Decode Latency2. RAS Latency3. RAS to CAS Latency4. CAS Latency5. Data Transfer6. Pre-charge *

IBM ATS Deep Computing
© 2007 IBM Corporation
Basic Memory Read Continued Sequential Access
CPU
MemoryController
COLUMN ADDRESS STROBE
CAS LATENCY
DATA TRANSFER
DIMMS
Data1

IBM ATS Deep Computing
© 2007 IBM Corporation
Basic Memory Read Continued Sequential Access
CPU
MemoryController
COLUMN ADDRESS STROBE
CAS LATENCY
DATA TRANSFER
DIMMS
Data2

IBM ATS Deep Computing
© 2007 IBM Corporation
Basic Memory Read Continued Sequential Access
CPU
MemoryController
COLUMN ADDRESS STROBE
CAS LATENCY
DATA TRANSFER
DIMMS
Data3

IBM ATS Deep Computing
© 2007 IBM Corporation
Sequential Memory Operation Overview
CPU
MemoryController
CAS LATENCY
DIMMS
Data3Data Data1 Data2
Data7Data4 Data5 Data6
DataBData8 Data9 DataA
DataFDataC DataD DataE
Potential BandwidthBottleneck !!!

IBM ATS Deep Computing
© 2007 IBM Corporation
Random Memory Operation Overview
CPU
MemoryController
RAS LATENCYRAS to CAS LATENCY
CAS LATENCYDATA TRANSFER
PRECHARGE
DIMMS
Data3Data Data1 Data2
Data7Data4 Data5 Data6
DataBData8 Data9 DataA
DataFDataC DataD DataE
Memory LatencyBottleneck !!!

IBM ATS Deep Computing
© 2007 IBM Corporation
Summary of Memory OperationSequential memory accesses are very fast and can saturate the bandwidth of the processor to memory interface– No Row Address Latency (which is a long time)– Only fast Column Address Latency (which is usually short)– Very low memory decode latency for N+1 address
• Just increment address– Data Transfer
But each new random address must incur long latency– Full memory controller decode latency– Row Address Latency– RAS to CAS latency – CAS Latency– Data Transfer– Pre-charge*
• This was omitted to simplify the discussion– Pre-charge is time to close a row (or page) and prepare a new row for reading

IBM ATS Deep Computing
© 2007 IBM Corporation
Memory Bandwidth ObservationsAs the number of threads or cores increase…– The randomness of memory accesses tend to also increase
– So for systems with greater numbers of processors random loaded memory latency often has a greater affect on systems performance than DIMM bandwidth
But for applications that utilize few threads that access memory sequentially the sustainable bandwidth of the system has a greater affect on performance than memory latency

IBM ATS Deep Computing
© 2007 IBM Corporation
CPU Bottleneck Performance Fundamentals
Core Intensive - Processor is executing instructions as fast as CPU core can process
Latency Intensive - Processor is executing instructions as fast as memory latency allows
Bandwidth Intensive - Processor is executing instructions as fast as memory bandwidth allows
Potential Processor Bottlenecks
Core Intensive
Bandw
idth
Inte
nsive
Latency
Intensive

IBM ATS Deep Computing
© 2007 IBM Corporation
Xeon vs. Opteron Performance Fundamentals
Potential Processor Bottlenecks
Core Intensive
Bandw
idth
Inte
nsive
Latency
Intensive
Woodcrest and Tulsa WinBy as much as 20+%
Woodcrest and Opteron
About the same
Opter
on W
ins by
as m
uch
As 2X

IBM ATS Deep Computing
© 2007 IBM Corporation
Question: Which Design Has The Lower Unloaded Latency?
2 ChannelMemory
Controller
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
4 ChannelMemory
Controller
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
CPU
CPU
ADDR
RAS LatencyRAS to CAS Latency
CAS LatencyData TransferPre-Charge
Data
85 nSeconds Total 100 nSeconds TotalExtra 15nSec Latency For Decode of 4 Channels
ADDR
Data
RAS LatencyRAS to CAS Latency
CAS LatencyData TransferPre-Charge

IBM ATS Deep Computing
© 2007 IBM Corporation
But Which Design Has The Lower Loaded Latency?
2 ChannelMemory
Controller
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
4 ChannelMemory
Controller
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
CPU
CPU
ADDR
RAS LatencyRAS to CAS Latency
CAS LatencyData TransferPre-Charge
Data
2 Transfer in 90 nSecAvg. Loaded Latency = 45nSec
4 Transfers in 115 nSecAvg. Loaded Latency = 29nSec!
ADDR
Data
RAS LatencyRAS to CAS Latency
CAS LatencyData TransferPre-Charge
Data
Data
Data
Data

IBM ATS Deep Computing
© 2007 IBM Corporation
As Memory Gets Faster There is Another Challenge: Capacity vs. Clock Speed
Memory capacity is limited by the number of DIMMs designers can economically engineer into the system
But with most memory technologies sustainable clock speed of thememory decreases as the number of DIMMs on a memory channel increase– Due to capacitance loading of each successive DIMM installed
The evolution to solve this problem has been…– SDRAM evolves to DDR
– DDR evolves to DDR2
– DDR2 evolves to FBD

IBM ATS Deep Computing
© 2007 IBM Corporation
And We Still Have The Capacity vs. Speed Trade-offDDR2 DIMMs add electrical loading to memory bus– This means that as memory clock speed increases the number of
DIMMs that can be supported on the memory channel decreases because of electrical loading
MemoryController Memory Bus
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
400 MHzMemory
Controller Memory Bus
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
533 MHz
667 MHz
MemoryController Memory Bus
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
Not representative of any particular systemDiagram is intended to illustrate speed and DIMM count limitations

IBM ATS Deep Computing
© 2007 IBM Corporation
FBDIMM Solves This Problem With Serial Memory Bus And On-DIMM Advanced Memory Buffer (AMB)
Serial Address Bus
Serial Data BusMemoryController
Same DDR2 DRAM Technology

IBM ATS Deep Computing
© 2007 IBM Corporation
FBDIMM Serial Bus Add Latency Due to Hops
Serial Address Bus
Serial Data BusMemoryController
Address
Data

IBM ATS Deep Computing
© 2007 IBM Corporation
FB-DIMMs2 Channels
DDR2 DIMMs1 Channel
FBDIMM Serial Interface Reduces Wiring Complexity Which Enables Greater Number of Memory Channels
DIMM Connectors DIMM
Connectors
Memory Controller
Memory Controller

IBM ATS Deep Computing
© 2007 IBM Corporation
Additional Memory Channels = Greater Capacity And Greater Throughput Which Offsets Additional Latency Under Load
DDR2 MemoryController
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
FBD MemoryController
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
DRAM
Greater MemoryBandwidth
Less MemoryBandwidth

IBM ATS Deep Computing
© 2007 IBM Corporation
Additional Memory Channels = Greater Capacity And Greater Throughput Which Offsets Additional Latency Under Load
Source: Intel

IBM ATS Deep Computing
© 2007 IBM Corporation
Measured DDR2 vs. FBD Memory Throughput
39% In
creas
e
2.8x I
ncreas
e
Memory Throughput for DDR2 vs. FBD
0
1000
2000
3000
4000
5000
6000
Sequential Reads Random Reads
Mem
ory
Thro
ughp
ut B
ytes
/Sec
3.2GHz Xeon DDR23.0GHz Woodcrest FBD
39% In
creas
e
2.8x I
ncreas
eSource – Systems x Performance Lab

IBM ATS Deep Computing
© 2007 IBM Corporation
Memory SummaryExisting DDR2 memory employs multi-drop parallel bus– Electrical loadings increase as DIMMs are added to the bus
• This limits the speed of the memory bus– Parallel bus limits number of memory channels in system
• Physical wiring space limits number of memory channels on planar boards• Memory controller pin-count too great with more than two channels
FBDIMM solves problem by placing an Advanced Memory Buffer (AMB) on DDR2 DIMM and employs a serial memory bus– Serial bus greatly reduces wiring requirements and enables greater number of
memory buses supported in a system• This increases capacity and throughput
– Serial AMB adds latency & increases DIMM power consumption• ~5 Watt /DIMM
– Expect second generation AMB tol consume even lower power• But greater throughput results in LOWER average latency when under load, improving
performance

IBM ATS Deep Computing
© 2007 IBM Corporation
So What Does It Mean?
FBD Memory is a technical solution to the problems encountered by using standard DDR1 or DDR2 DIMMS which require a parallel bus– FBD adds an Advance Memory Buffer (AMB) to the standard DDR2 DIMM
to enable a serial interface• This adds HW to the DIMM that consumes additional power
– About 3 – 5Watts per DIMM• By using less board space compared to the serial interface of DDR
– FBD enables 4 channels of memory vs. 2 channels (standard DDR1 or 2)
– FBD enables full-duplex operation (concurrent reads and writes)• DDR is half-duplex (either a read OR a write)
– Four channels and concurrent reads/writes translate to much higher memory performance, especially for random workload
Bottom line – FBD has nearly 3x higher throughput for multi-threaded applications but consumes slightly greater power and adds some latency

IBM ATS Deep Computing
© 2007 IBM Corporation
HPC Application Spectrum
Bandwidth and processor compute capability assessed
– Applications span the spectrum
– No single industry accepted metric exists
Bandwidth Limited
CoreLimited
~1 Byte per Flop
SparseMV SPECfp2000 LinpackDGEMM
Simple FluidDynamicsOcean Models
Petro ReservoirAuto NVH
Auto CrashWeather
SeismicComp Chem
StreamDAXPYDDOT
Increasing Xeon LeadershipIncreasing Opteron Leadership

IBM ATS Deep Computing
© 2007 IBM Corporation
Relative HPC Benchmark Results HPC Workloads - Memory Bandwidth Constrained???
1.31 1.26 1.19
1.4 1.461.32
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
ABAQUASSTD
Fluent LS Dyna 3 Car SEISM CPMD 64Atom
CHARMm
All 2 Socket Configurations
Relative Performance Gain of 3.0GHz WoodcrestCompared to 2.4GHz Opteron

IBM ATS Deep Computing
© 2007 IBM Corporation
I/O (local) SubSystem
SAS drives
73 GB
10K RPM
We will look at GPFS later

IBM ATS Deep Computing
© 2007 IBM Corporation
Serial SCSI (SAS) vs Parallel SCSI
Parallel SCSI320 MB/s Half-duplex
Race condition on bits
Serial SCSI600 MB/s Full-duplex
No bit race
Deferential Signal Pair
Each direction @
300 MB/s
320 MB/s
Half-duplex
Shared bus
300 MB/s
Full-duplex
Point-to-point

IBM ATS Deep Computing
© 2007 IBM Corporation
SATA, SAS, FC Comparison

IBM ATS Deep Computing
© 2007 IBM Corporation
Network Subsystem

IBM ATS Deep Computing
© 2007 IBM Corporation
PCI-E Bus
Point-to-Point, Serial, Low-Voltage Interconnect
Low-latency communications to maximize data throughput and efficiency
Uses chip-to-chip or board-to-board (cabling) interconnect
Scalable performance via aggregate Lanes
Data Integrity and Error-handling focus

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation
Node Communication Considerations
Protocol– MPI – TCP & UDP– RDMA– Multicast
Traffic Patterns (hierarchical and non-hierarchical)Packet Size Distribution of messages (large vs small)

IBM ATS Deep Computing
© 2007 IBM Corporation
Node-to-Node Interconnect options
Ethernet– Ubiquitous, low cost, low complexity– High message latency
Optimized Ethernet– RDMA, TCP offload engines– Optimal for single server - multi-clinet
Specialized Interconnect– Low Latency and High bandwidth – E.g., Myrinet, Infiniband, Quadrics
Voltaire Infiniband 9288 – 10 Gb/s

IBM ATS Deep Computing
© 2007 IBM Corporation
Infiniband Characteristics
Standards-based
Optimized for HPC
Supports Server and Storage attachments
Built-in RDMA capabilities
Bandwidth for 4x (SDR) is 10 Gb/s – (measured: 8Gb/s)
RDMA
Socket
Layer
Application
Hardware
TCP/IP
Transport
Driver
Kernel
user
Trad
ition
al
Ker
nel b
y-pa
ss

IBM ATS Deep Computing
© 2007 IBM Corporation
IB Protocols
Fiber-Channel SAN attachmentSCSI RDMA Protocol (SRP)
RDMA flexible programming API (Oracle RAC)
Direct Access Programming Library (uDAPL)
Accelerates socket-based applications that use RC or RDMA
Sockets Direct Protocol (SDP)
HPC applications – low latencyMPI
Enables IP-based applications over IB
IP over IB (IPoIB)

IBM ATS Deep Computing
© 2007 IBM Corporation
Voltaire IB Performance

IBM ATS Deep Computing
© 2007 IBM Corporation
Software Layer 1 (Operating System)

IBM ATS Deep Computing
© 2007 IBM Corporation
Remember: Users typically do not have root access

IBM ATS Deep Computing
© 2007 IBM Corporation
Linux
Monolithic-kernel but modular like Micro-kernelDynamic Loading of kernel modulesPreemptive SMP supportedThreads are just like any other processesoo device modelEliminates Unix features that are considered poorFree
System Call Interface
Device Drivers
Kernel Subsystem
App. 2App. 1 App. 3
Hardware
Ker
nel s
pace
Use
r spa
ce
Source: Linux Kernel Development by Robert Love

IBM ATS Deep Computing
© 2007 IBM Corporation
Some Kernel parameters relevant to HPC users - 1
The kernel parameters can be set in /etc/sysctl.conf, run “sysctl -p” to apply them.
Shared memory
– SHMMAX: define the maximum size (in bytes) for a shared memory segment• kernel.shmmax = 2147483648 (default: 33554432)
– SHMMNI: define the maximum number of shared memory segments system wide• kernel.shmmni = 4096 (default)
– SHMALL: define the total amount of shared memory (in pages) that can be used at one time on the system. To be set at least “to ceil(SHMMAX/PAGE_SIZE)”

IBM ATS Deep Computing
© 2007 IBM Corporation
Some Kernel parameters relevant to HPC users - 2Semaphores– SEMMSL: control the maximum number of semaphores per
semaphore set.– SEMMNI: control the maximum number of semaphore sets on
the entire Linux system.– SEMMNS: control the maximum number of semaphores (not
semaphore sets) on the entire Linux system.– SEMOPM: control the number of semaphore operations that
can be performed per semop system call.
cat /proc/sys/kernel/sem250 256000 32 1024
SEMMSL SEMMNI SEMMNS SEMOPM
kernel.sem="250 32000 100 128"

IBM ATS Deep Computing
© 2007 IBM Corporation
Some Kernel parameters relevant to HPC users - 3
Large pages
vm.nr_hugepages = 1000
vm.disable_cap_mlock = 1
Maximum number of open files
fs.file-max=65536
Other parameters: I/O scheduler, network receive/send buffers,………

IBM ATS Deep Computing
© 2007 IBM Corporation
User Limits/etc/security/limits.conf<domain> <type> <item> <value>
Items:core - limits the core file size (KB)data - max data size (KB)fsize - maximum filesize (KB)memlock - max locked-in-memory address space (KB)nofile - max number of open filesrss - max resident set size (KB)stack - max stack size (KB)cpu - max CPU time (MIN)nproc - max number of processesas - address space limitmaxlogins - max number of logins for this usermaxsyslogins - max number of logins on the systempriority - the priority to run user process withlocks - max number of file locks the user can holdsigpending - max number of pending signalsmsgqueue - max memory used by POSIX message
queues (bytes)nice - max nice priority allowed to raise tortprio - max realtime priority

IBM ATS Deep Computing
© 2007 IBM Corporation
ulimit – user command to control limits

IBM ATS Deep Computing
© 2007 IBM Corporation
IPCS and IPCRM – Interprocess communication
ipcs -a shows all the active message queues, semaphores, shared memory segments
ipcs -q for active message queues
ipcs -m for active shared memory segments
ipcs -s for active semaphores
ipcrm [-q msgid | -m shmid | -s semid] to delete the particular identifier

IBM ATS Deep Computing
© 2007 IBM Corporation
Server Performance Indicators
CPU
Memory
Storage IONetwork IO
Application
internalsApplication
performance

IBM ATS Deep Computing
© 2007 IBM Corporation
CPU - /proc/cpuinfo
cat /proc/cpuinfo
processor : 0vendor_id : GenuineIntelcpu family : 6model : 14model name : Intel(R) Xeon(TM) CPU 000 @ 2.00GHzstepping : 8cpu MHz : 2000.361cache size : 2048 KBphysical id : 0siblings : 2core id : 0cpu cores : 2fdiv_bug : nohlt_bug : nof00f_bug : nocoma_bug : nofpu : yesfpu_exception : yescpuid level : 10wp : yesflags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe constant_tsc pni monitor vmx est tm2 xtprbogomips : 4005.92

IBM ATS Deep Computing
© 2007 IBM Corporation76
CPU - monitoring the utilization
vmstat:show the vmstat output with an interval of 10sec:vmstat 10procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----r b swpd free buff cache si so bi bo in cs us sy id wa1 0 327308 11552 10860 138800 2 2 24 35 17 81 10 2 87 20 0 327308 11428 10876 138800 12 0 12 84 1160 1514 10 2 85 30 0 327308 10428 10892 138800 28 0 28 128 1134 1563 12 9 76 30 0 327308 10056 10896 139048 72 0 328 0 1164 1534 15 14 61 10
sar:-collect the system statistics every 10s, 1000 times and store them in file.sarsar -A -o file.sar 10 1000
-show the CPU utilisation for the recorded periodsar -u -f file.sar- show the processes queue length and load averagessar -B -f file.sar

IBM ATS Deep Computing
© 2007 IBM Corporation77
Memory - /proc/meminfo
meminfo
cat /proc/meminfo MemTotal: 8309276 kBMemFree: 6550956 kBBuffers: 182356 kBCached: 1484032 kBSwapCached: 0 kBActive: 760512 kBInactive: 915900 kBHighTotal: 7470784 kBHighFree: 5969668 kBLowTotal: 838492 kBLowFree: 581288 kBSwapTotal: 4192956 kBSwapFree: 4192956 kBDirty: 4 kBWriteback: 0 kBMapped: 21592 kBSlab: 62376 kBCommitLimit: 8347592 kBCommitted_AS: 68376 kBPageTables: 600 kBVmallocTotal: 112632 kBVmallocUsed: 5516 kBVmallocChunk: 106524 kBHugePages_Total: 0HugePages_Free: 0HugePages_Rsvd: 0Hugepagesize: 2048 kB

IBM ATS Deep Computing
© 2007 IBM Corporation78
Memory -monitoring the utilizationvmstat:procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----r b swpd free buff cache si so bi bo in cs us sy id wa1 0 327308 11552 10860 138800 2 2 24 35 17 81 10 2 87 20 0 327308 11428 10860 138800 0 0 0 0 1202 1573 9 3 88 00 0 327308 11428 10876 138800 12 0 12 84 1160 1514 10 2 85 3
sar:- show the paging activity for the recorded period
sar -B -f file.sar- show the memory and swap space utilization statistics
sar -r -f file.sar

IBM ATS Deep Computing
© 2007 IBM Corporation79
IO -monitoring the utilizationvmstat:procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----r b swpd free buff cache si so bi bo in cs us sy id wa1 0 327308 11552 10860 138800 2 2 24 35 17 81 10 2 87 20 0 327308 11428 10860 138800 0 0 0 0 1202 1573 9 3 88 00 0 327308 11428 10876 138800 12 0 12 84 1160 1514 10 2 85 3
sar:- show the IO activity globally for the system
sar -b -f file.sar- show the IO activity for each devices (sector=512 bytes)
sar -d -f file.sar
iostat:avg-cpu: %user %nice %sys %iowait %idle
0.03 0.00 0.01 0.02 99.94Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtnsda 0.26 0.58 5.36 2932784 26939926sdb 0.06 1.45 7.44 7293650 37386696sdc 0.00 0.00 0.00 8182 0sdd 0.00 0.00 0.00 8182 0

IBM ATS Deep Computing
© 2007 IBM Corporation80
Network - monitoring the utilization
sar:- show the paging activity for the recorded period
sar -n DEV -f file.sar
01:00:01 PM IFACE rxpck/s txpck/s rxbyt/s txbyt/s rxcmp/s txcmp/s01:10:01 PM lo 0.00 0.00 0.00 0.00 0.00 0.0001:10:01 PM eth0 2.33 0.00 186.47 0.00 0.00 0.0001:10:01 PM eth1 0.00 0.00 0.00 0.00 0.00 0.0001:10:01 PM eth2 0.00 0.00 0.00 0.00 0.00 0.00Average: lo 0.00 0.00 0.10 0.10 0.00 0.00Average: eth0 2.36 0.02 187.89 3.02 0.00 0.00Average: eth1 0.00 0.00 0.00 0.00 0.00 0.00Average: eth2 0.00 0.00 0.00 0.00 0.00 0.00

IBM ATS Deep Computing
© 2007 IBM Corporation81
Network - monitoring the utilizationNtop provides detailed and graphical network statistics
www.ntop.org

IBM ATS Deep Computing
© 2007 IBM Corporation
NMON Performance Tool
CPU Utilization
Memory Use
Kernel Statistics and run queue information
Disk I/O information
Network I/O information
Paging space and rate
etc
http://www-128.ibm.com/developerworks/aix/library/au-analyze_aix/index.html
http://www-941.haw.ibm.com/collaboration/wiki/display/WikiPtype/nmon

IBM ATS Deep Computing
© 2007 IBM Corporation
Process affinitytaskset
usage: taskset [options] [mask | cpu-list] [pid | cmd [args...]]set or get the affinity of a process
-p, --pid operate on existing given pid-c, --cpu-list display and specify cpus in list format-h, --help display this help-v, --version output version information
The default behavior is to run a new command:taskset 03 sshd -b 1024
You can retrieve the mask of an existing task:taskset -p 700
Or set it:taskset -p 03 700
List format uses a comma-separated list instead of a mask:taskset -pc 0,3,7-11 700
Ranges in list format can take a stride argument:e.g. 0-31:2 is equivalent to mask 0x55555555

IBM ATS Deep Computing
© 2007 IBM Corporation
Process schedulingChrt
usage: chrt [options] [prio] [pid | cmd [args...]]
manipulate real-time attributes of a process
-f, --fifo set policy to SCHED_FF-p, --pid operate on existing given pid-m, --max show min and max valid priorities-o, --other set policy to SCHED_OTHER-r, --rr set policy to SCHED_RR (default)-h, --help display this help-v, --verbose display status information-V, --version output version information
You must give a priority if changing policy.

IBM ATS Deep Computing
© 2007 IBM Corporation
GPFS – General Parallel File System
Parallel Cluster File System Based on Shared Disk (SAN) Model
Cluster – fabric-attached nodes (IP, SAN, …)
Shared disk - all data and metadata on fabric-attached disk
Parallel - data and metadata flows from all of the nodes to all of the disks in parallel.
GPFS File System Nodes
Switching fabric(System or storage area network)
Shared disks(SAN-attached or network
block device)
IBM ATS Deep Computing
© 2007 IBM Corporation
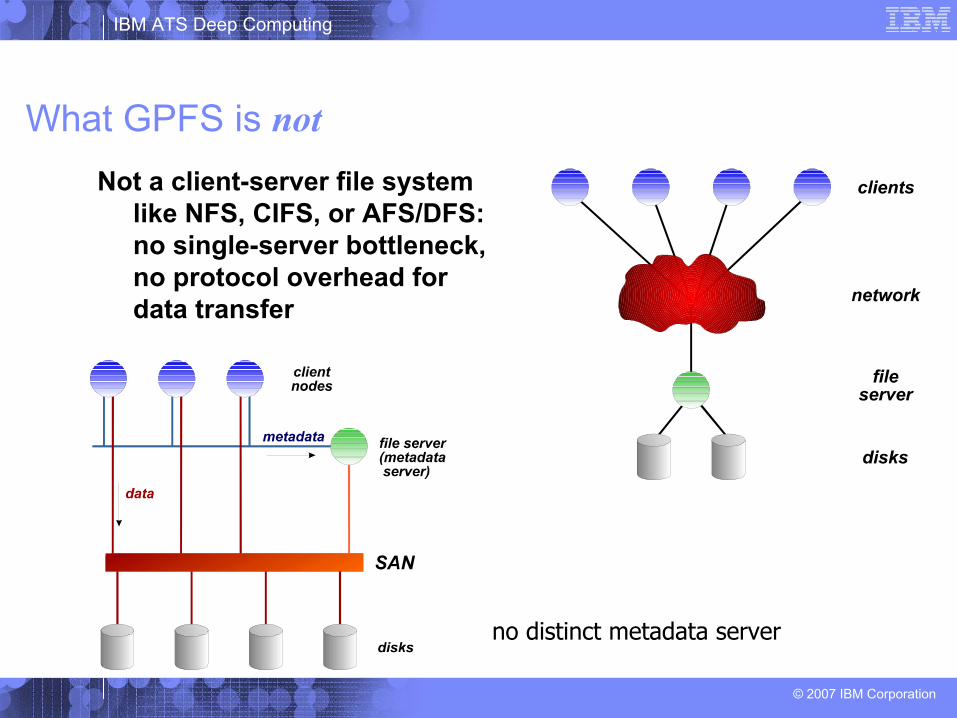
What GPFS is notNot a client-server file system
like NFS, CIFS, or AFS/DFS: no single-server bottleneck, no protocol overhead for data transfer
no distinct metadata server

IBM ATS Deep Computing
© 2007 IBM Corporation
Why is GPFS needed?Clustered applications impose new requirements on the file system
Parallel applications need fine-grained access within a file from multiple nodesSerial applications dynamically assigned to processors based on load
– need high-performance access to their data from wherever they run
Both require good availability of data and normal file system semantics
GPFS supports this via:
uniform access – single-system image across clusterconventional Posix interface – no program modificationhigh capacity – multi-TB files, petabyte file systemshigh throughput – wide striping, large blocks, many GB/sec to one fileparallel data and metadata access – shared disk and distributed lockingreliability and fault-tolerance - node and disk failuresonline system management – dynamic configuration and monitoring

IBM ATS Deep Computing
© 2007 IBM Corporation
Parallel File Access from Multiple NodesGPFS allows parallel applications on multiple nodes to access non-overlapping ranges of file with no conflict
Byte-range locks serialize access to overlapping ranges of a file
GPFS File
node0 node1 node2 node3
Node 2 and 3 areboth trying to accessthe same section of the file
Concurrency achieved by token based distributed lock manager

IBM ATS Deep Computing
© 2007 IBM Corporation
Large File Block Size
GPFS is designed assuming that most files in the file system are large and need to be accessed quickly
Conventional file systems store data in small blocks to pack data more densely and use disk more efficiently
GPFS uses large blocks (256 KB default) to optimize disk transfer speed
This means that realized file-system performance can be much better.
This also means that GPFS does not store small files efficiently

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation
Sequential Access patterns are best
Advice:
Access records sequentially
Multi-node: make every process responsible for a 1/n contiguous chunk of the file

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation
GPFS Usage Model
Naïve ModelIgnore that it is a parallel file system – treat it like any other
For Sequential I/O, this is okay
Standard Posix ModelUse standard Posix file functions (open, lseek, write, close, etc.,)
Low level, Great performance using direct-access files
MPI-IO (MPI-2) ModelFull Parallel I/O featured – best suited for HPC applications

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation

IBM ATS Deep Computing
© 2007 IBM Corporation
MPI-IO Models (some)
Node 0 gathers and writes sequential Posix I/O files
Each node independently and in parallel doing sequential posix I/O to separate files
Each node independently and in parallel doing MPI-IO to separate files
Each node independently and in parallel doing MPI-IO to a single file
Reading using individual file pointers using MPI version of lseek
Collective IO

IBM ATS Deep Computing
© 2007 IBM Corporation
For Efficient use of GPFS:
Make friends with System administrators to fine tune GPFS parameters
Block Size
Stripe Method
Indirect Block Size
(just the basic parameters you need to know)

IBM ATS Deep Computing
© 2007 IBM Corporation
GPFS ResourcesWebsites
– Main GPFS website:• http://www-1.ibm.com/servers/eserver/clusters/software/gpfs.htm
– GPFS Documentation:• http://publib.boulder.ibm.com/infocenter/clresctr/topic/com.ibm.cluster.gpfs.doc/gpfsbo
oks.html– GPFS FAQs:
• http://publib.boulder.ibm.com/infocenter/clresctr/index.jsp?topic=/com.ibm.cluster.gpfs.doc/gpfs_faqs/gpfs_faqs.html
– Clusters Literature:• http://www-03.ibm.com/servers/eserver/clusters/library/wp_aix_lit.html• http://www.broadcastpapers.com/asset/IBMGPFS01.htm


















