
HPC with Multicore and GPUstomov/TAMU09.pdf · Allows for high parallelism Needs high bandwidth vs...
29
1/29 HPC with Multicore and GPUs Stanimire Tomov and Jack Dongarra Innovative Computing Laboratory University of Tennessee, Knoxville TAMU visit December 3-4 College Station, TX
Transcript of HPC with Multicore and GPUstomov/TAMU09.pdf · Allows for high parallelism Needs high bandwidth vs...

1/29
HPC with Multicore and GPUs
Stanimire Tomov and Jack DongarraInnovative Computing LaboratoryUniversity of Tennessee, Knoxville
TAMU visitDecember 34 College Station, TX

2/29
Outline
Introduction– Hardware to Software Trends
LAPACK to MAGMA / PLASMA Libraries– Challenges and approach
– Onesided and twosided factorizations
Performance Results
Conclusions

3/29
Speeding up Computer SimulationsBetter numerical methods
Exploit advances in hardware
http://www.cs.utk.edu/~tomov/cflow/
● Manage to use hardware efficiently for realworld HPC applications ● Match LU benchmark in performance !
e.g. a posteriori error analysis: solving for much less DOF but achieving the same accuracy

4/29

5/29

6/29

7/29
A multicore chip is a single chip (socket) that combines two or more independentprocessing units that provide independentthreads of control

8/29
Why GPUbased Computing ?
Hardware Trends
Processor speed improves 59% / year but memory bandwidth only by 23% latency by 5.5%

9/29
Scenemodel
Graphics pipelined computation
Finalimage
streams of data
Repeated fast over and over: e.g. TV refresh rate is 30 fps; limit is 60 fps
GPUs: excelling in graphics rendering
This type of computation: Requires enormous computational power Allows for high parallelism Needs high bandwidth vs low latency
( as low latencies can be compensated with deep graphics pipeline )
Obviously, this pattern of computation is common with many other applications
Evolution of GPUs
Currently, can be viewed as multithreaded multicore vector units

10/29
Current NVIDIA GPUs
(Source: “NVIDIA's GT200: Inside a Parallel Processor”)

11/29
HPC applications and high speedups reported using GPUs (from NVIDIA CUDA Zone homepage)
CUDA architecture & programming: A dataparallel approach that scales Similar amount of efforts on using CPUs vs GPUs by domain scientists demonstrate the GPUs' potential

12/29
Matrix Algebra on GPU and Multicore Architectures (MAGMA)
MAGMA: a new generation linear algebra (LA) libraries to achieve the fastest possible time to an accurate solution on hybrid/heterogeneous architectures, starting with current multicore+MultiGPU systemsHomepage: http://icl.cs.utk.edu/magma/
MAGMA & LAPACK
– MAGMA based on LAPACK and extended for hybrid systems (multiGPUs + multicore systems);
– MAGMA designed to be similar to LAPACK in functionality, data storage and interface, in order to allow scientists to effortlessly port any of their LAPACKrelying software components to take advantage of the new architectures
– MAGMA to leverage years of experience in developing open source LA software packages and systems like LAPACK, ScaLAPACK, BLAS, ATLAS as well as the newest LA developments (e.g. communication avoiding algorithms) and experiences on homogeneous multicores (e.g. PLASMA)
Support NSF, Microsoft, NVIDIA [ now CUDA Center of Excellence at UTK on the development of Linear Algebra Libraries for CUDAbased Hybrid Architectures ]
MAGMA developers
– University of Tennessee, Knoxville; University of California, Berkeley; University of Colorado, Denver

13/29
Challenges of using GPUs
Massive parallelismMany GPU cores, serial kernel execution [ e.g. 240 in the GTX280; up to 512 in Fermi – to have concurrent kernel execution ]
Hybrid/heterogeneous architecturesMatch algorithmic requirements to architectural strengths[ e.g. small, nonparallelizable tasks to run on CPU, large and parallelizable on GPU ]
Compute vs communication gapExponentially growing gap; persistent challenge[ Processor speed improves 59%, memory bandwidth 23%, latency 5.5% ][ on all levels, e.g. a GPU Tesla C1070 (4 x C1060) has compute power of O(1,000) Gflop/s but GPUs communicate through the CPU using O(1) GB/s connection ]

14/29
GPUs for HPC
Programmability Performance Hybrid computing

15/29
How to Code for GPUs?
Complex question– Language, programming model, user productivity, etc
Recommendations
– Use CUDA / OpenCL[already demonstrated benefits in many areas; databased parallelism; move to support taskbased]
– Use GPU BLAS[high level; available after introduction of shared memory – can do data reuse; leverage existing developments ]
– Use Hybrid Algorithms[currently GPUs – massive parallelism but serial kernel execution; hybrid approach – small nonparallelizable tasks on the CPU, large parallelizable tasks on the GPU ]
1000 2000 3000 4000 5000 6000 70000
50
100
150
200
250
300
350
400
GPU vs CPU GEMM
GPU SGEMM
GPU DGEMM
CPU SGEMM
CPU DGEMM
Matrix size
GFl
op/s
1000 2000 3000 4000 5000 6000 70000
10
20
30
40
50
60
70
GPU vs CPU GEMV
GPU SGEMV
GPU DGEMV
CPU SGEMV
CPU DGEMV
Matrix size
GFl
op/s
Typical order of acceleration: dense matrixmatrix O( 1) X dense matrixvector O( 10) X sparse matrixvector O(100) X

16/29
LAPACK to Multicore
“delayed update” to organizesuccessive Level 2 BLAS asa single Level 3 BLAS
Split BLAS into tasks and representalgorithms as DAGs; new algorithmswhere Level 2 BLAS panel factorizationsare now Level 3 BLAS

17/29
LAPACK to multicore+GPU (MAGMA)
1) Development of NEW LGORITHMS (parallelism, hybrid, optimal communication)
2) HYBRIDIZATION of LAPACK/new algorithms
Represent LAPACK/new algorithms as a collection of TASKS and DEPENDANCIES among them
Properly SCHEDULE the tasks' execution over the multicore and the GPU
3) Development of GPU BLAS KERNELS
4) AUTOTUNED implementations
Algorithms as DAGs (small tasks/tiles for homogeneous multicore)
Hybrid CPU+GPU algorithms(small tasks for multicores and large tasks for GPUs)

18/29
OneSided Dense Matrix Factorizations(LU, QR, and Cholesky)
Panels (Level 2 BLAS) are factored on CPU using LAPACK
Trailing matrix updates (Level 3 BLAS) are done on the GPU using “lookahead” (to overlap CPUs work on the critical path with the GPUs large updates)
Example: LeftLooking Hybrid Cholesky factorization

19/29
Onesided hybrid factorizations
1 2 3 4 5 6 7 8 9 100
40
80
120
160
200
240
280
320
MAGMAMKL 8 coresMKL 1 core
GPU : NVIDIA GeForce GTX 280 (240 cores @ 1.30GHz) GPU BLAS : CUBLAS 2.2, sgemm peak: 375 GFlop/s CPU : Intel Xeon dual socket quadcore (8 cores @2.33 GHz) CPU BLAS : MKL 10.0 , sgemm peak: 128 GFlop/s
1 2 3 4 5 6 7 8 9 100%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
OverheadCPUCPU+GPUGPU
Tim
e
GFl
op/s
QR factorization in single precision arithmetic, CPU interface Performance of MAGMA vs MKL MAGMA QR time breakdown
[ for more performance data, see http://icl.cs.utk.edu/magma ]
Matrix size x 1000 Matrix size x 1000

20/29
Twosided matrix factorizations
Twosided factorization, e.g. consider Hessenberg reduction Q A Q' = HH – upper Hessenberg, Q – orthogonal similarity transformation
Importance
Block algorithmQ – a product of n1 elementary reflectorsQ = H
1 H
2 ... H
n1, H
i = I –
i v
i v
i'
H1 ... H
nb = I – V T V' (WY transform; the bases for delayed update or block algorithm)
Can we accelerate it ?[similarly to the onesided using hybrid GPUbased computing][ to see much higher acceleration due to a removed bottleneck ]
Onesided factorizations bases for linear solvers
Twosided factorizations bases for eigensolvers

21/29
Homogeneous multicore acceleration?
CPU : Intel Xeon dual socket quadcore (8 cores @2.33 GHz) CPU BLAS : MKL 10.0 , dgemm peak: 65 GFlop/s
GFl
op/s
Hessenberg factorization in double precision arithmetic, CPU interface Performance of MAGMA vs MKL
1 2 3 4 5 6 7 80
1
2
3
4
5
6
MKL 8 coresMKL 1 core
Matrix size x 1000
There have been difficulties in accelerating it on homogeneous multicores
One core enough to saturate the busPerformance does not scale

22/29
Reduction times in seconds for N = 4,000 # cores 1 8 1+GPU 8+GPULevel 3 BLAS 25 (30%) / 4 3.5 (60%) / 2.7
Level 2 BLAS 59 (70%) / 59 2.3 (40%) / 2.3
The Bottleneck
No improvement

23/29
Hybrid computing acceleration?
Intuitively, yes, as matrixvector product is fast on GPUs
How to organize a hybrid computation ?
1 2 3 4 5 6 7 80
5
10
15
20
25
30
MAGMA BLASCUBLAS 2.3Multicore
Matrix size x 1,000
GPU : GeForce GTX 280 (240 Cores @ 1.30 GHz)
Bandwidth: Theoretical : 141 GB/s
GFl
op/s
Achieved > 100 GB/s
3x33 x
DGEMV Performance

24/29
Task Splitting & Task Scheduling

25/29
Performance
GPU : NVIDIA GeForce GTX 280 (240 cores @ 1.30GHz) GPU BLAS : CUBLAS 2.3, dgemm peak: 75 GFlop/s CPU : Intel Xeon dual socket quadcore (8 cores @2.33 GHz) CPU BLAS : MKL 10.0 , dgemm peak: 65 GFlop/s
GFl
op/s
Hessenberg factorization in double precision arithmetic, CPU interface Performance of MAGMA vs MKL
[ for more performance data, see http://icl.cs.utk.edu/magma ]
1 2 3 4 5 6 7 805
1015202530354045505560
Upper boundMAGMA
MAGMA 0.2MKL 8 coresMKL 1 core
Matrix size x 1000
Acceleration is much higherthan onesided ( O(10) x )due to removed bottleneck
26/29
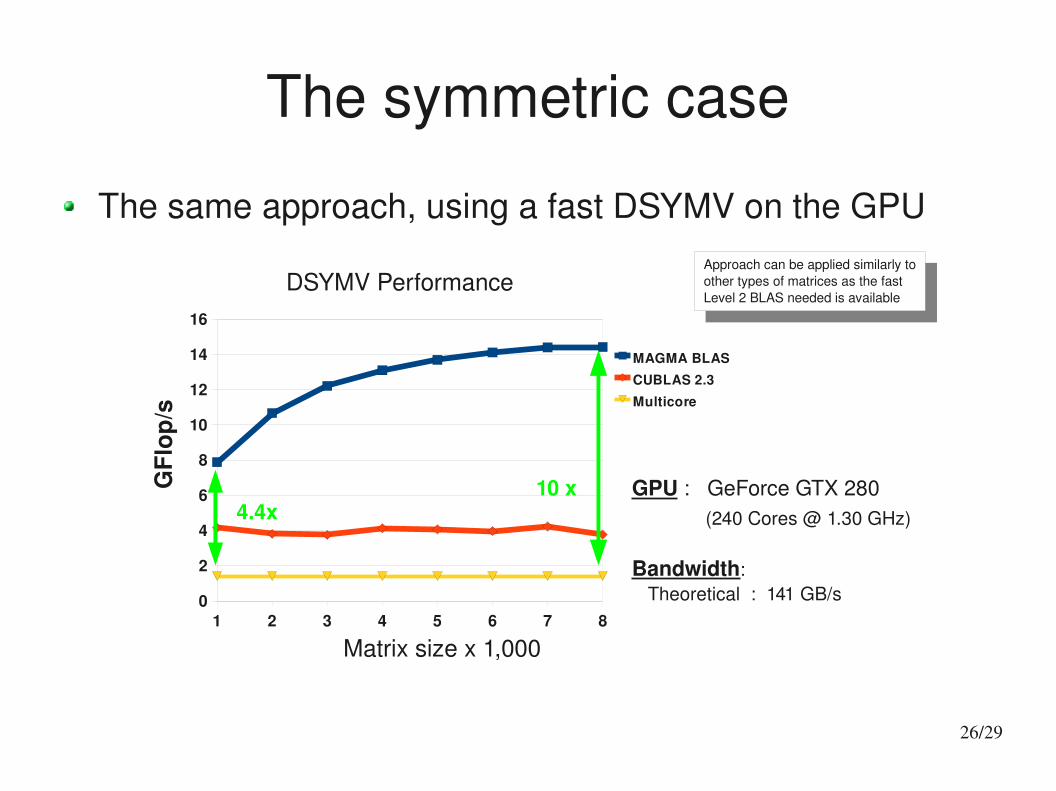
The symmetric case
1 2 3 4 5 6 7 80
2
4
6
8
10
12
14
16
MAGMA BLASCUBLAS 2.3Multicore
Matrix size x 1,000
GPU : GeForce GTX 280 (240 Cores @ 1.30 GHz)
Bandwidth: Theoretical : 141 GB/s
GFl
op/s
4.4x10 x
DSYMV Performance
The same approach, using a fast DSYMV on the GPUApproach can be applied similarly toother types of matrices as the fast Level 2 BLAS needed is available

27/29
Linear Solvers
0 1000 2000 3000 4000 5000 6000 7000 8000 90000
50
100
150
200
250
300
350
Solving Ax = b using LU factorization
Intel(R) Xeon(R)[email protected] / 8 Cores + GTX 280 @1.30GHz / 240 Cores
SP Factorization
SP Solve
MP Solve
DP Factorization
DP Solve
Matrix Size
GF
lop/
s
Direct solvers Factor and do triangular solves in the same, working precision Mixed Precision Iterative Refinement
Factor in single (i.e. the bulk of the computation in fast arithmetic) and use it as preconditioner in simple double precision iteration, e.g. x
i+1 = x
i + (LU
SP)1 P (b – A x
i)

28/29
Extension to Multicore and Multi GPUsCholesky factorization in SP Strong Scalability
HOST: 4x AMD Opteron core @1.8GHz GPUs: 4x C1060 (240 cores each @1.44GHz)
[ with Hatem Ltaief, Rajib Nath, Peng Du, and Jack Dongarra ]
Leveraging PLASMA developments: 2 level nested parallelism coarse: PLASMA tiled algorithm and static scheduling fine : tasks/tiles are redefined for hybrid 1 core+GPU computing Defining a “Magnum tiles approach”

29/29
Conclusions
Hybrid Multicore+GPU computing:
Architecture trends: towards heterogeneous/hybrid designs
Can significantly accelerate DLA [vs just multicores] ; for both one and twosided factorizations
Can significantly accelerate algorithms that are slow on homogeneous architectures


















