
How to host and manage enterprise customers on AWS: …awsmedia.s3.amazonaws.com/ARC213.pdf · How...
41
Kazutaka Goto - Evangelist, cloudpack Ken Tamagawa - Sr. Manager, Solutions Architecture, Amazon Web Services How to host and manage enterprise customers on AWS: TOYOTA, Nippon Television, UNIQLO use cases November 15, 2013
-
Upload
truongnhan -
Category
Documents
-
view
223 -
download
2
Transcript of How to host and manage enterprise customers on AWS: …awsmedia.s3.amazonaws.com/ARC213.pdf · How...

Kazutaka Goto - Evangelist, cloudpack
Ken Tamagawa - Sr. Manager, Solutions Architecture, Amazon Web Services
How to host and manage enterprise customers on AWS:
TOYOTA, Nippon Television, UNIQLO use cases
November 15, 2013

Japan Market
• Tokyo region opened in March 2011
• Tokyo region was the fastest growing AWS
region in its first year
• There are more than 20,000 AWS accounts in
Japan

• Launched in 2010 as a managed hosting service
provider
• Systems integrator for enterprise companies
• Premier Consulting Partner for 2013 & 2014

cloudpack Manages AWS Accounts for 300+ Clients

Focus of Today’s Session:
Second Screen
Disaster Recovery
Real world use cases in Japan
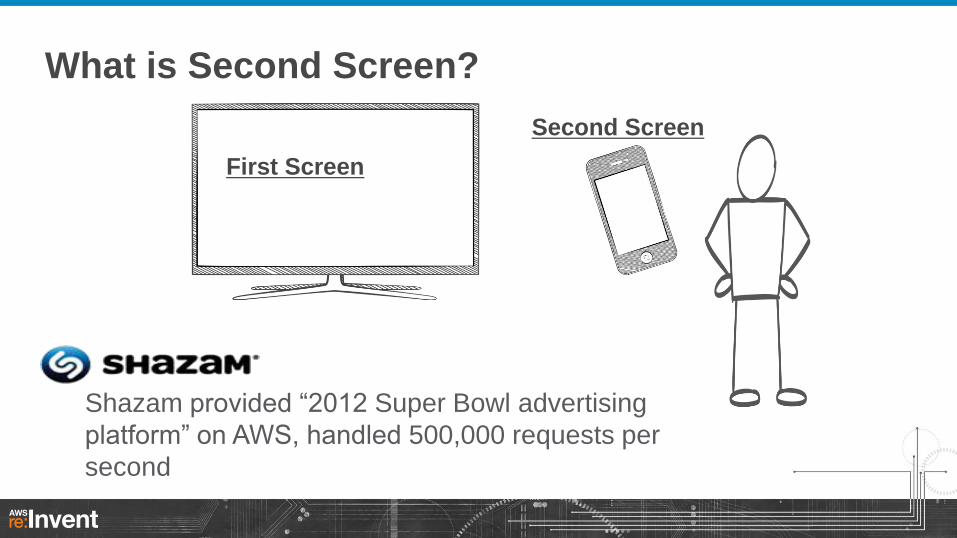
What is Second Screen?
Shazam provided “2012 Super Bowl advertising
platform” on AWS, handled 500,000 requests per
second
First Screen
Second Screen

• Interactive communication
service by Nippon Television
Network, one of Japan’s
largest broadcasting
companies
• Combines TV and Internet
into a unified experience
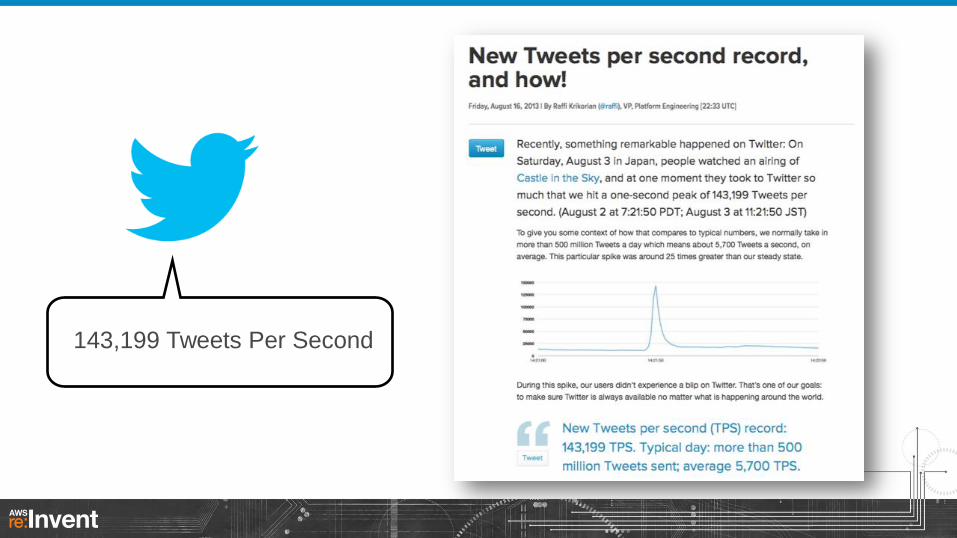
143,199 Tweets Per Second
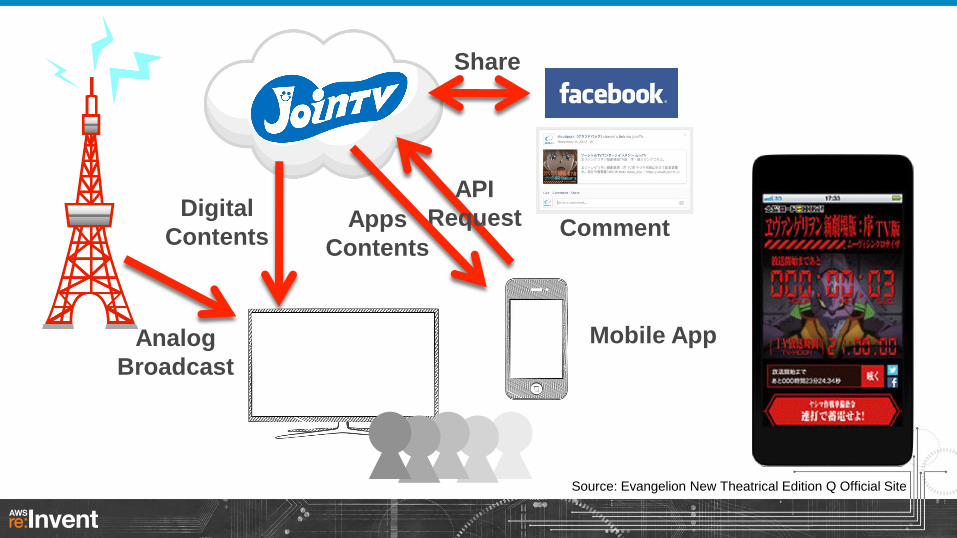
Source: Evangelion New Theatrical Edition Q Official Site
Analog
Broadcast
Digital
Contents
Mobile App
Comment
API
Request
Share
Apps
Contents

Requirements from JoinTV
• Handle sudden access surges
• Share across social networks with little delay
• Build a scalable system for the above
requirements

Our Approach
• Determine minimum resources to handle traffic
surges with on-demand load testing service
“neuster” – Configure load testing setting
– Set up the console and run load testing repeatedly
– Optimize application and identify minimum resources
• Minimize delay by desynchronizing feed
requests to social networks
Batch Batch
Auto Scaling
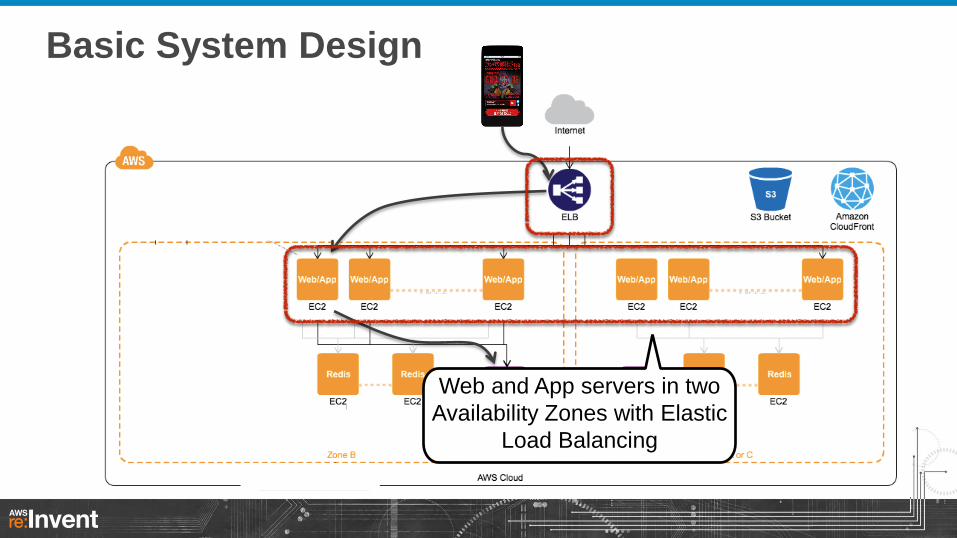
Web and App servers in two
Availability Zones with Elastic
Load Balancing
Basic System Design
Batch Batch
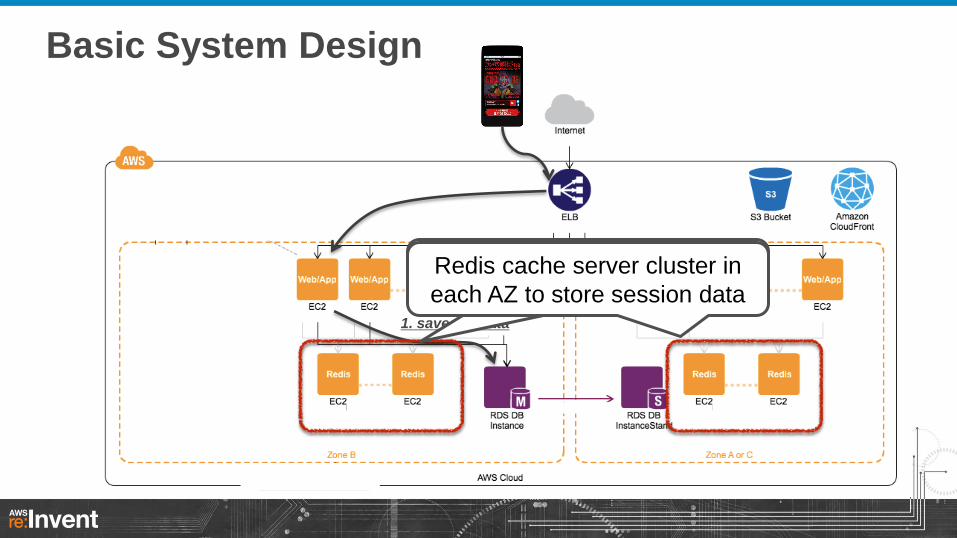
Auto Scaling 1. save the data
Redis cache server cluster in
each AZ to store session data Redis cache server cluster in
each AZ to store session data
Basic System Design
Batch Batch
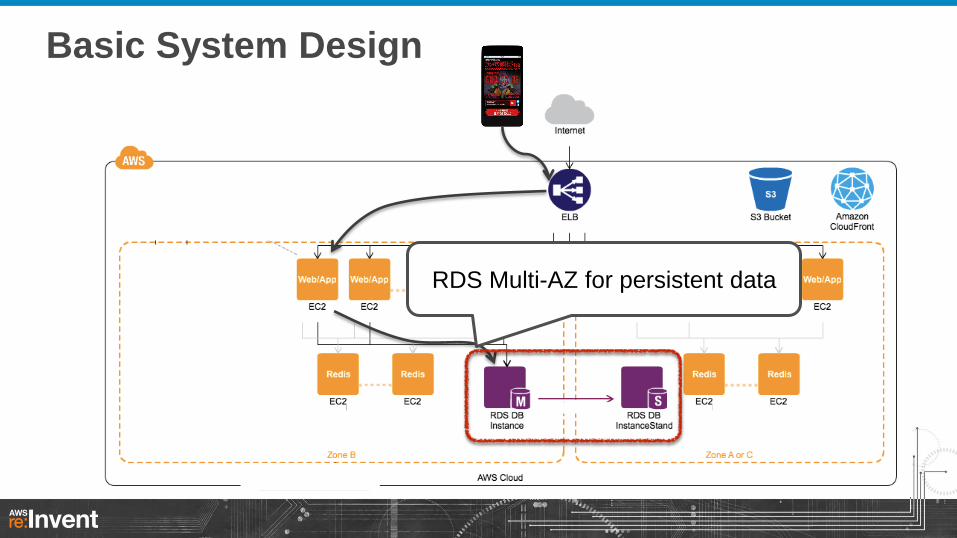
Auto Scaling
RDS Multi-AZ for persistent data
Basic System Design
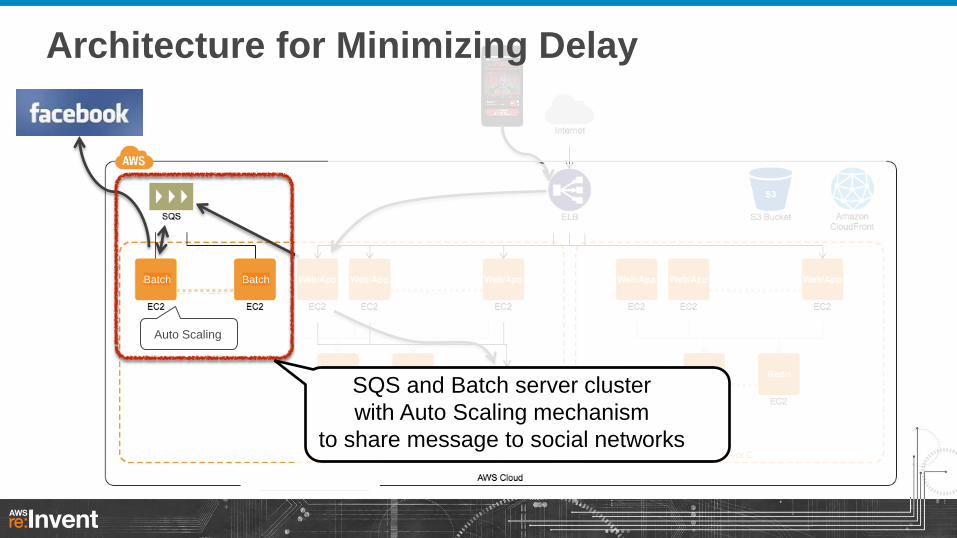
Batch Batch
Auto Scaling
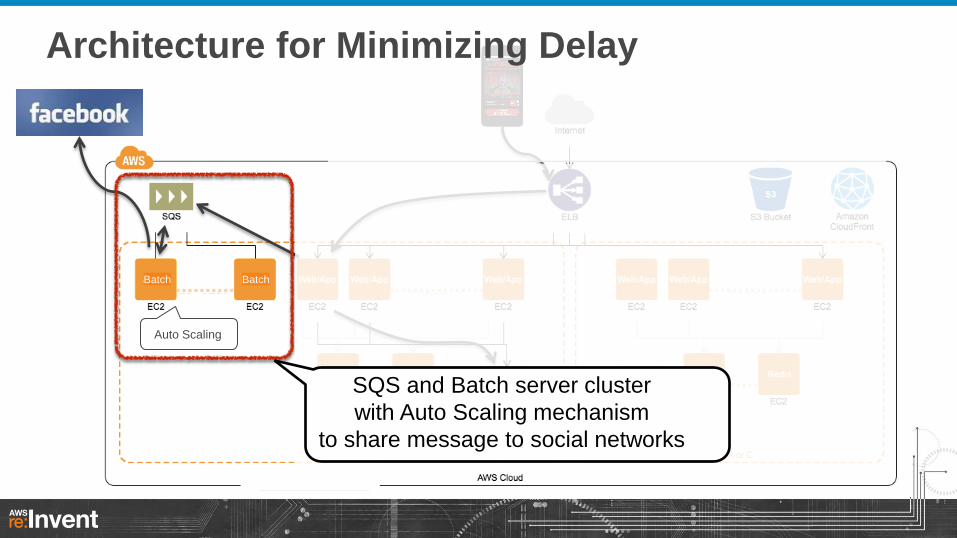
SQS and Batch server cluster
with Auto Scaling mechanism
to share message to social networks
Architecture for Minimizing Delay

Traffic War Room
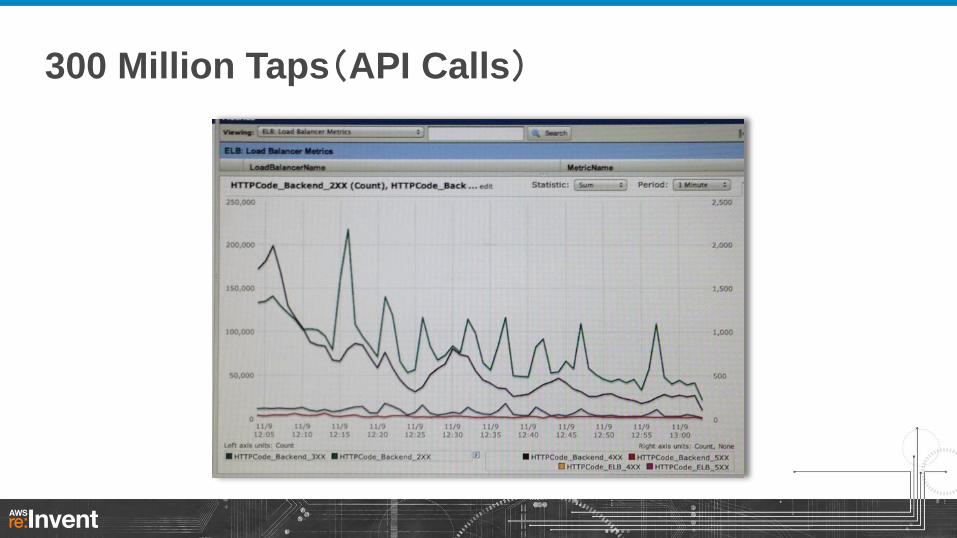
300 Million Taps(API Calls)
Batch Batch
Auto Scaling
SQS and Batch server cluster
with Auto Scaling mechanism
to share message to social networks
Architecture for Minimizing Delay
19
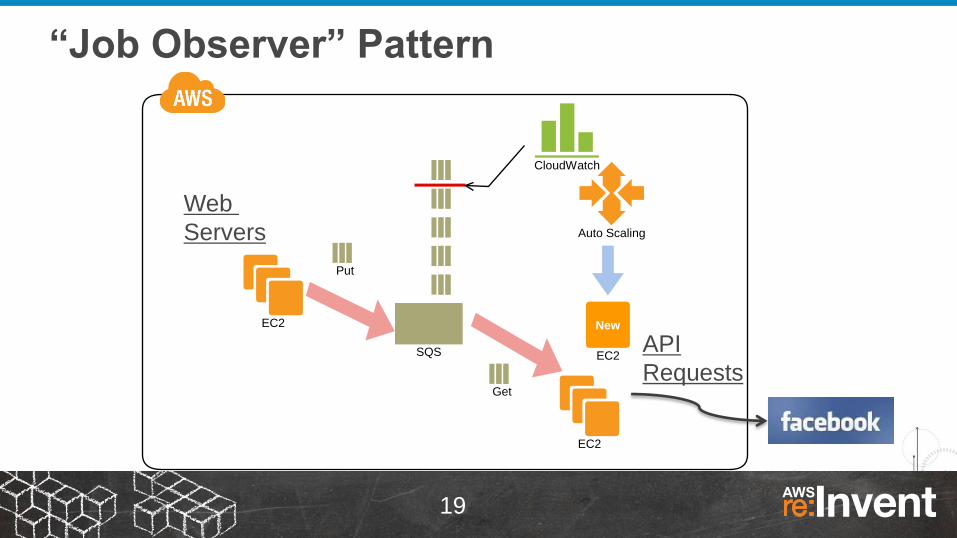
“Job Observer” Pattern
SQS
EC2
EC2
Get
Put
CloudWatch
EC2
New
Auto Scaling
Web
Servers
API
Requests

AWS Cloud Design Pattern
CDP
It might be similar to…
“This allows builders to create advanced model with simple parts”
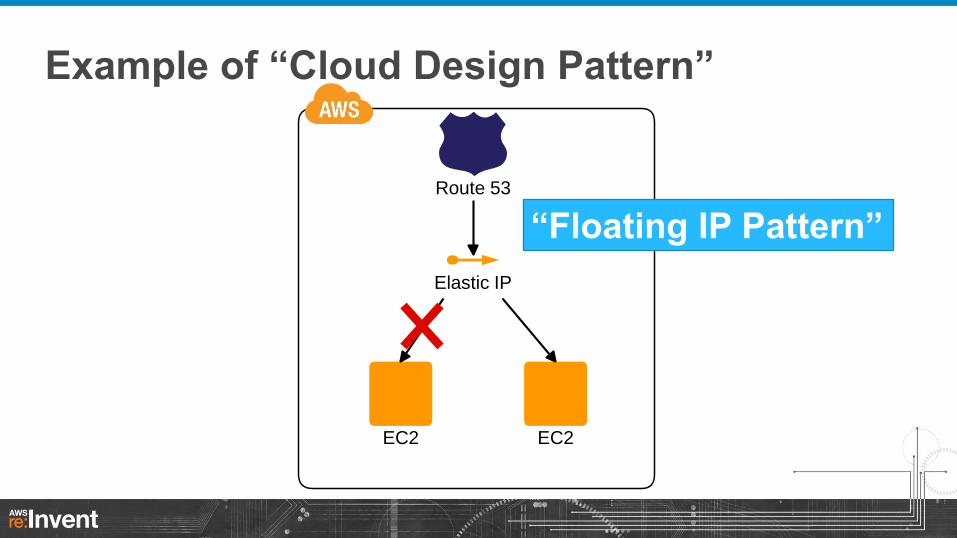
Example of “Cloud Design Pattern”
EC2 EC2
Elastic IP
Route 53
“Floating IP Pattern”

Floating AC Adaptor
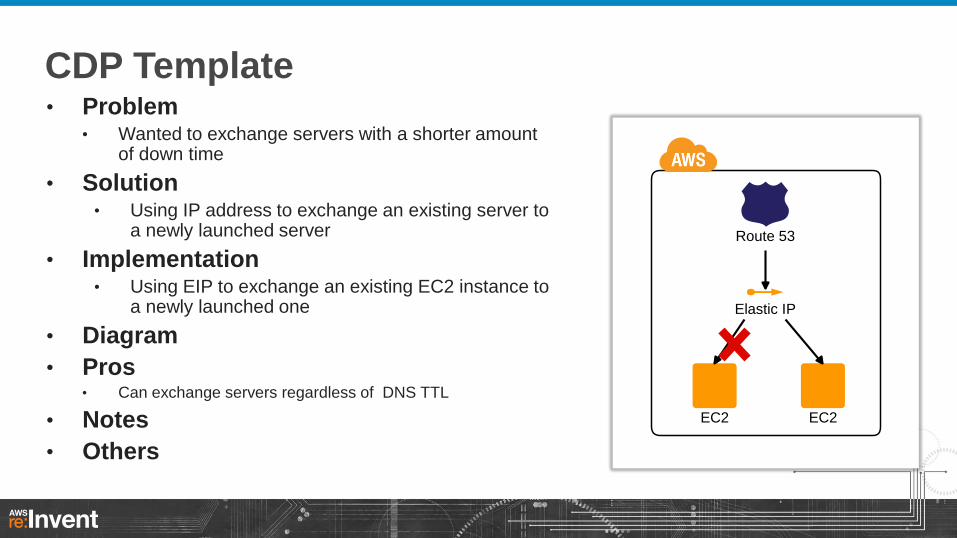
CDP Template • Problem
• Wanted to exchange servers with a shorter amount of down time
• Solution • Using IP address to exchange an existing server to
a newly launched server
• Implementation • Using EIP to exchange an existing EC2 instance to
a newly launched one
• Diagram
• Pros • Can exchange servers regardless of DNS TTL
• Notes
• Others
EC2 EC2
Elastic IP
Route 53

CDP Categories Basic Snapshot
Stamp
Scale Up
On-demand Disk
Availability Multi-Server
Multi-Datacenter
Floating IP
Deep Health Check
Scaling Scale Out
Clone Server
NFS Sharding
NFS Replica
State Sharing
URL Rewriting
Rewrite Proxy
Cache Proxy
Scheduled Scale Out
Static Contents Web Storage
Direct Hosting
Private Distribution
Cache Distribution
Rename Distribution
Data Uploading Write Proxy
Storage Index
Direct Object Upload
Relational Database DB Replication
Read Replica
In-memory DB Cache
Sharding Write
Batch Processing Queuing Chain
Priority Queue
Job Observer
Scheduled Auto Scaling
Maintenance Bootstrap
Cloud DI
Stack Deployment
Server Swapping
Monitoring Integration
Web Storage Archive
Networking On-demand NAT
Backnet
Functional Firewall
Operational Firewall
Multi Load Balancer
WAF Proxy
CloudHub
Cloud Design Pattern wiki http://en.clouddesignpattern.org
26

• Global auto manufacturer
(US$ 221B annual rev.)
• 20 websites
• 100M Page Views (PVs)
TOYOTA Official Websites
100 million PV 4.5 billion hits / month; Access tripled at new model announcement

Requirements from TOYOTA
• Large-scale migration into AWS for 20 websites
experiencing traffic surges – Those sites need to interact with their on-premises system
• A system for prompt multi-regional disaster
recovery

Our Approach
• Build an environment able to handle traffic larger than requested by TOYOTA (100-300 million PVs/month)
• Design disaster recovery process across regions in short time – Identify the order of processes
– Prepare OS images (AMIs)
– Write configuration for AWS CloudFormation template
– Import latest data from their data center
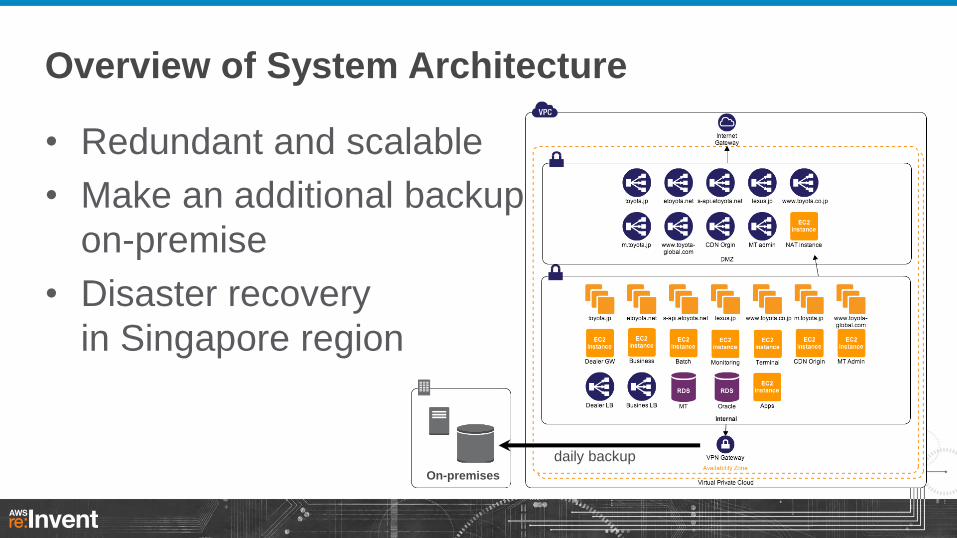
Overview of System Architecture
• Redundant and scalable
• Make an additional backup
on-premise
• Disaster recovery
in Singapore region
daily backup
On-premises
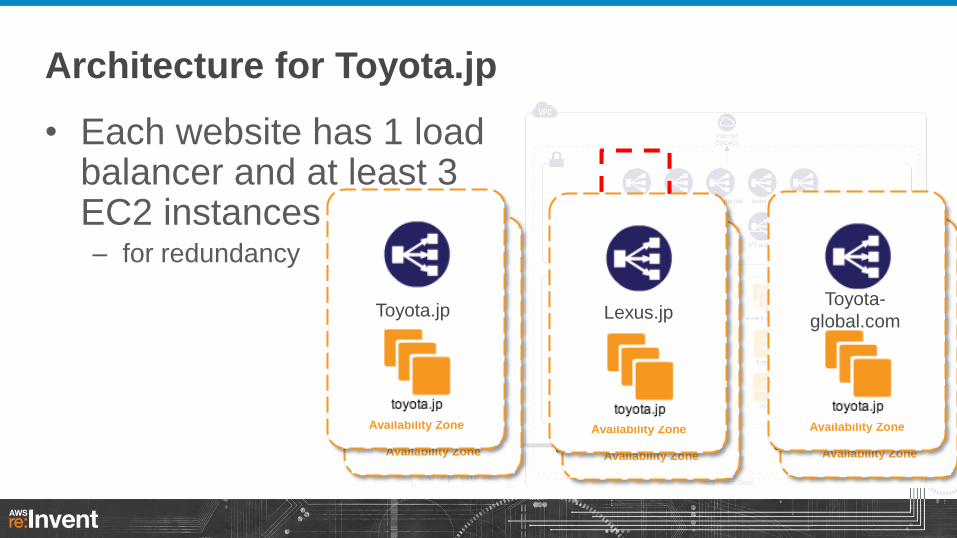
Architecture for Toyota.jp
• Each website has 1 load balancer and at least 3 EC2 instances – for redundancy
On-premise
Availability Zone
Availability Zone
Toyota.jp
daily backup Availability Zone
Availability Zone
Lexus.jp
daily backup Availability Zone
Availability Zone
Toyota-
global.com
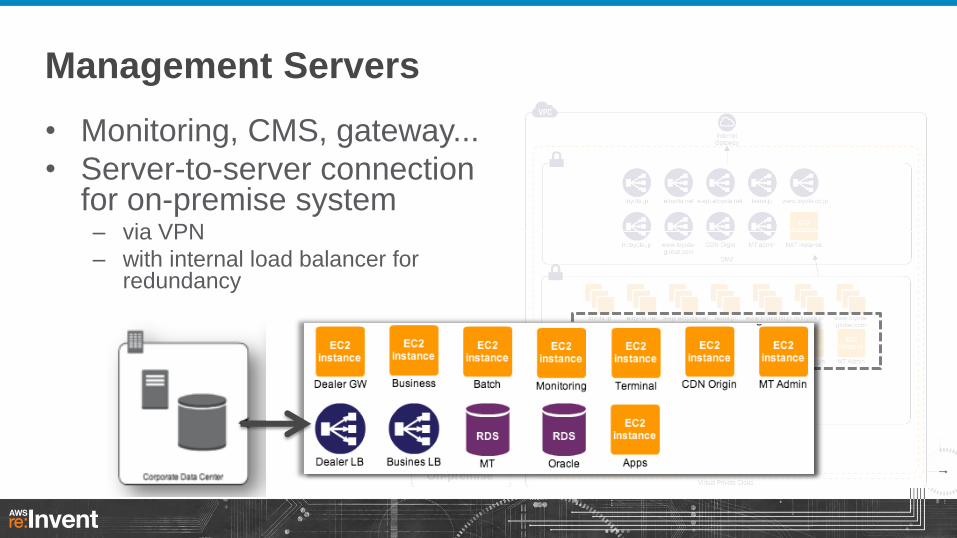
Management Servers
daily backup
On-premise
• Monitoring, CMS, gateway...
• Server-to-server connection for on-premise system – via VPN
– with internal load balancer for redundancy

Backup strategy
daily backup
On-premise
daily backup
• Make an additional backup
on-premises – also have original backup in AWS
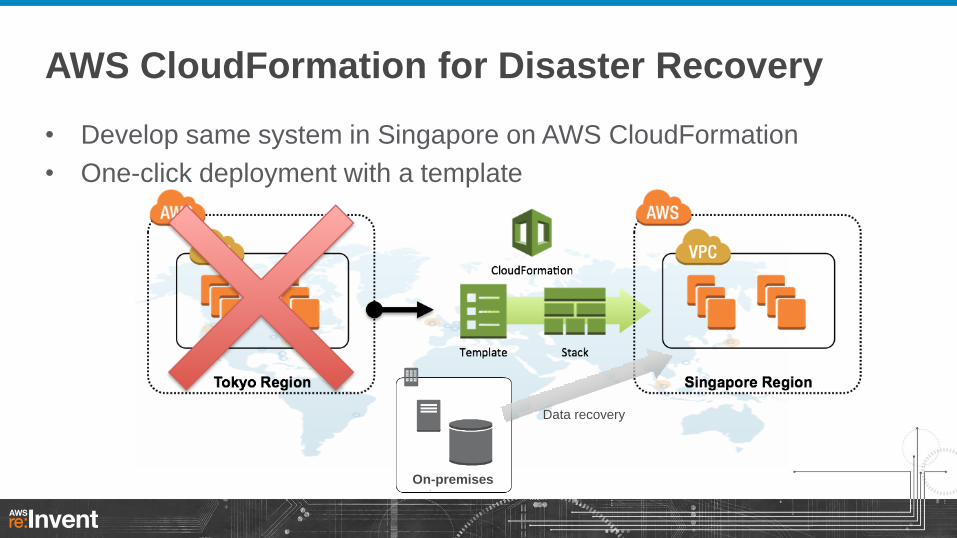
AWS CloudFormation for Disaster Recovery
• Develop same system in Singapore on AWS CloudFormation
• One-click deployment with a template
On-premises
Data recovery
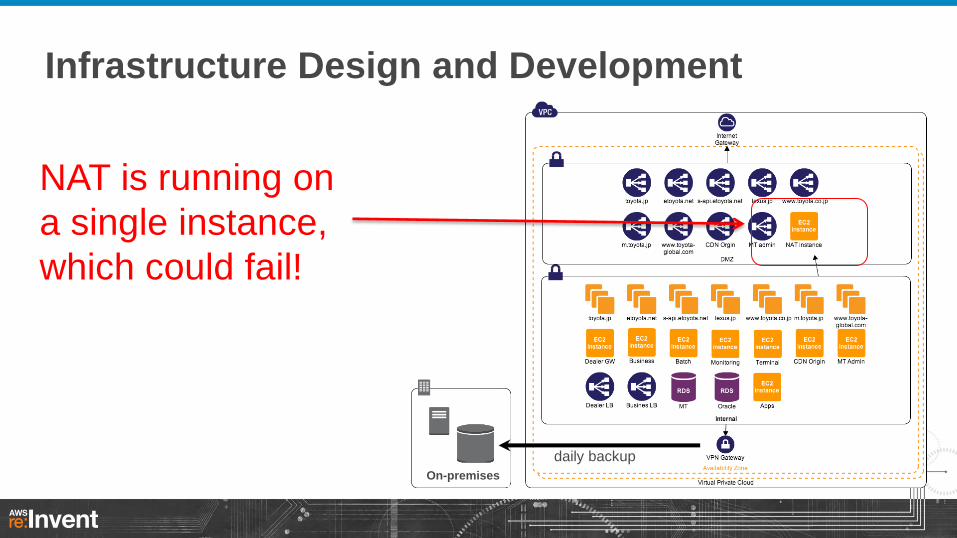
Infrastructure Design and Development
daily backup
On-premises
NAT is running on
a single instance,
which could fail!
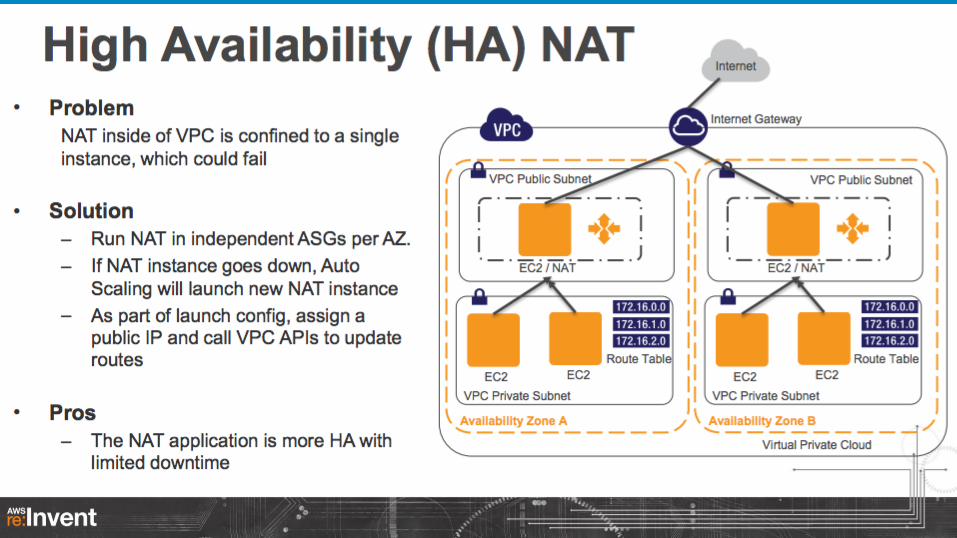
daily backup
On-premise
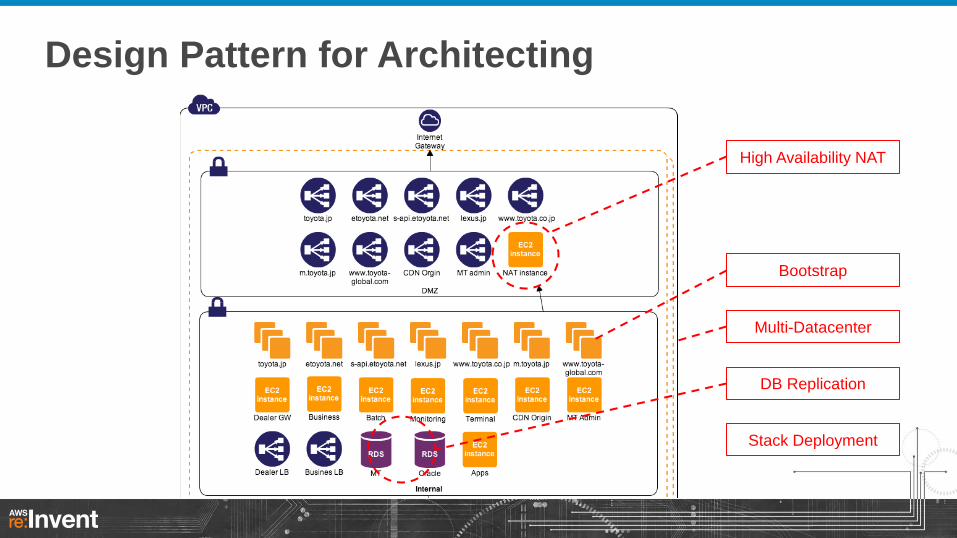
Design Pattern for Architecting
DB Replication
Stack Deployment
High Availability NAT
Multi-Datacenter
Bootstrap

In Real World Cases...
• For situations that traditional Auto Scaling can’t
handle, optimize provisioning by using load
testing similar to the real access environment – You can do scheduled Auto Scaling too if necessary
• Multi-regional disaster recovery is now possible
if necessary and can be done quickly
Please give us your feedback on this
presentation
As a thank you, we will select prize winners
daily for completed surveys!
ARC213


















