
How Ceph performs on ARM Microserver Cluster
27
How CEPH Performs in ARM-based Microserver Cluster ? 1 AARON JOUE
-
Upload
aaron-joue -
Category
Technology
-
view
160 -
download
2
Transcript of How Ceph performs on ARM Microserver Cluster

How CEPH Performs in ARM-based Microserver Cluster ?�
1
AARONJOUE

Agenda � About Ambedded � What is the Issues of Using Single Server Node with Multiple Ceph
OSD? � 1 Microserver vs. 1 x OSD architecture � The benefits � The basic High Availability Ceph Cluster � Scale it Out � Why Network matter? � How fast it can self-heal a failed OSD on this architecture � How much we save the energy � Easy way to run a ceph cluster
2

About Ambedded Technology
Y2013
Y2016
Y2015
Y2014
Founded in Taiwan Taipei, Office in National Taiwan University Innovative Innovation Center
Launch Gen 1 microserver architecture Storage Server Product Demo in ARM Global Partner Meeting UK Cambridge.
Partnership with European customer for the Cloud Storage Service. Installed 1800+ microservers & 5.5PB in operating since 2014
• Launch the 1st ever Ceph Storage Appliance powered by Gen 2 ARM microserver
• Awarded as the 2016 Best of INTEROP Las Vegas Storage product. Defeat VMware virtual SAN.
3

Issues of Using Single Server Node with Multiple Ceph OSDs
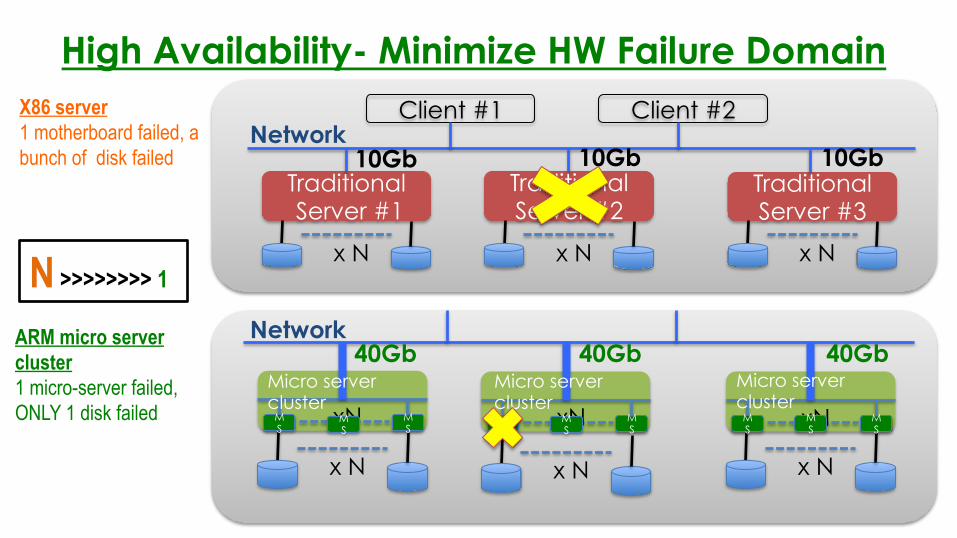
• The smallest failure domain is the OSDs inside a server. One Server fail causes many OSD down.
• CPU utility is 30%-40% only when network is saturated. The bottleneck is network instead of computing.
• The power consumption and thermal heat eat your money
4
x N x N x N
Network
MS
MS
xN MS
MS
xN MS
MS
xN MS
MS
MS
40Gb 40Gb 40Gb Micro server cluster
Micro server cluster
Micro server cluster
ARM micro server cluster 1 micro-server failed, ONLY 1 disk failed
Traditional Server #1
Traditional Server #2
Traditional Server #3
x N x N x N
Client #1 Client #2 Network
10Gb 10Gb 10Gb
X86 server 1 motherboard failed, a bunch of disk failed
High Availability- Minimize HW Failure Domain�
N >>>>>>>> 1

The Benefit of Using One to One Architecture
• True no single point of failure. • The smallest failure domain is one OSD • The MTBF of a micro server is much higher than a all-in-
one mother board • Dedicate H/W resource to get stable OSD service • Aggregate network bandwidth with failover • Low power consumption and cooling cost • OSD, MON, gateway are all in the same boxes. • 3 units form a high availability cluster
6

The Basic High Availability Cluster
7
1x MON
1x MON
1x MON
7x OSD
7x OSD
7x OSD
Basic Configuration
Scale Out the cluster
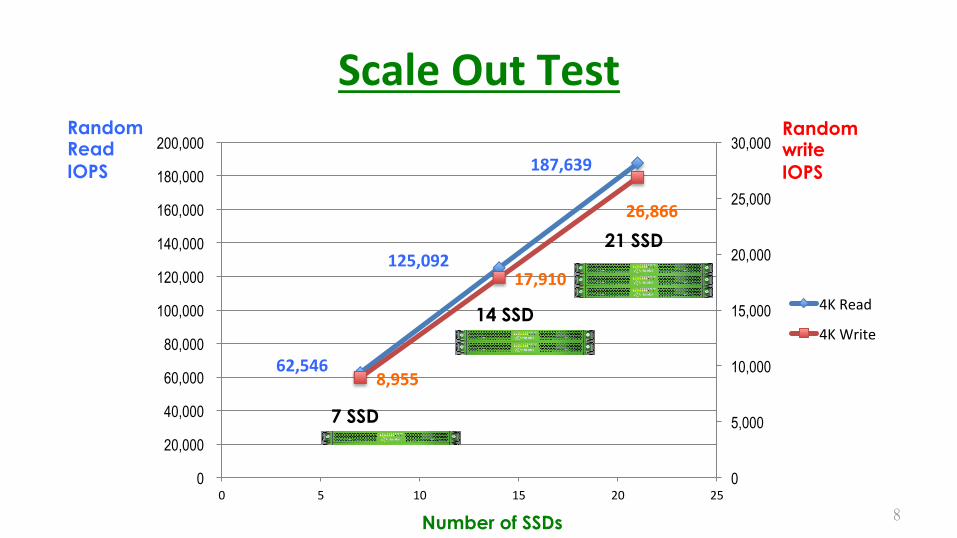
ScaleOutTest�
62,546
125,092
187,639
8,955
17,910
26,866
0
5,000
10,000
15,000
20,000
25,000
30,000
0
20,000
40,000
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
0 5 10 15 20 25
4KRead
4KWrite
Number of SSDs
7 SSD
14 SSD
21 SSD
Random Read IOPS
Random write IOPS
8

9 Capacity �
Performance�
Scale Out Unified Virtual Storage More OSDs, More Capacity, More Performance
3x Mars 200 -HDD
6x Mars 200 - HDD
5x Mars 200 -HDD
4x Mars 200 –HDD
3x Mars 200 -SSD
5x Mars 200 -SSD
4x Mars 200 –SSD
6x Mars 200 -SSD ALL Flash�
ALL HDD�

Network does Matter! HGST He 10T
16x OSD
20Gb uplink 40Gb Uplink Increase
BW IOPS BW IOPS �
4K Write 1 Client 7.2 1,800 11 2,824 57%
4K Write 2 Client 13 3,389 20 5,027 48%
4K Write 4 Client 22 5,570 35 8,735 57%
4K Write 10 Client 39 9,921 60 15,081 52%
4K Write 20 Client 53 13,568 79 19,924 47%
4K Write 30 Client 63 15,775 90 22,535 43%
4K Write 40 Client 68 16,996 96 24,074 42%
The purpose of this test is to know how much improvement if the uplink bandwidth is increased from 20Gb to 40Gb. Mars 200 has 4x 10Gb uplinks ports. The test result shows 42-57% improvement on IOPS.
10
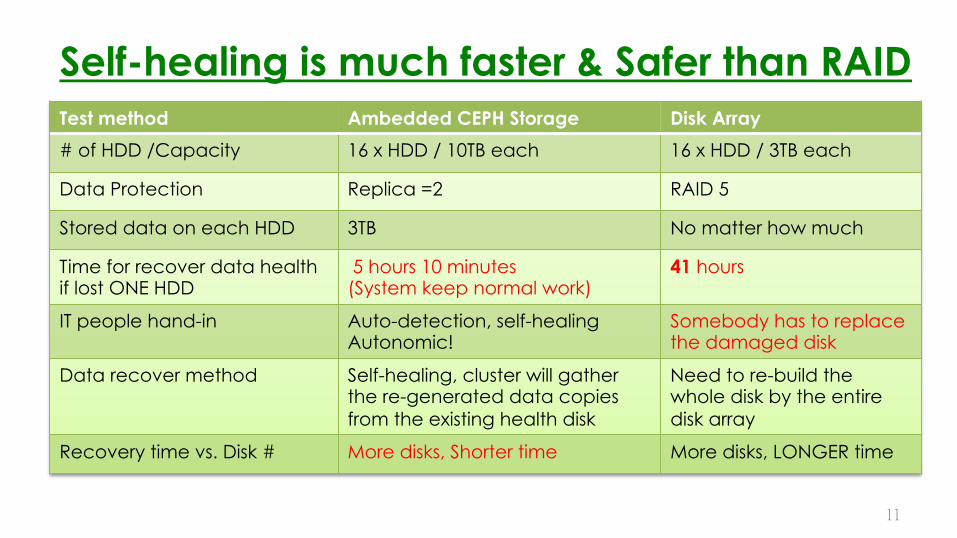
Self-healing is much faster & Safer than RAID�
11
Test method� Ambedded CEPH Storage � Disk Array�
# of HDD /Capacity� 16 x HDD / 10TB each� 16 x HDD / 3TB each�
Data Protection� Replica =2� RAID 5�
Stored data on each HDD� 3TB� No matter how much�
Time for recover data health if lost ONE HDD�
5 hours 10 minutes (System keep normal work)
41 hours�
IT people hand-in� Auto-detection, self-healing Autonomic!�
Somebody has to replace the damaged disk�
Data recover method� Self-healing, cluster will gather the re-generated data copies from the existing health disk
Need to re-build the whole disk by the entire disk array�
Recovery time vs. Disk #� More disks, Shorter time� More disks, LONGER time�

Mars 200: 8-Node ARM Microserver Cluster 8x 1.6GHz ARM v7 Dual Core hot swappable microserver - 2G Bytes DRAM - 8G Bytes Flash - 5 Gbps LAN - < 5 Watts power consumption
Storage - 8x hot swappable SATA3 HDD/SSD - 8x SATA3 Journal SSD
300 Watts Redundant power supply
OOB BMC port
Dual hot swappable uplink switches - Total 4x 10 Gbps - SFP+/10G Base-T Combo
12

(320W-60W) x 24h x 365 days /1000 x $0.2 USD x 40 units X 2 (power & Cooling) = USD 36,000/rack/YR This electricity cost is based on TW rate, it could be double or triple in Japan or Germany Note: SuperMicro server 6028R-WTRT with 8x3.5” HDD bay
13
Green Storage Saving More in Operation

AMBEDDED UNIFIED VIRTUAL STORAGE (UVS) MANAGER
Easy Use the Ceph Cluster
14

What You Can do with UVS Manager
• Deploy OSD, MON, MDS • Create Pool, RBD image, iSCSI LUN, S3 user • Support replica (1- 10) And Erasure Code (K+M) • OpenStack back storage management • Create CephFS • Snapshot, Clone, Flatten image • Crush Map configuration • Scale out your cluster
15
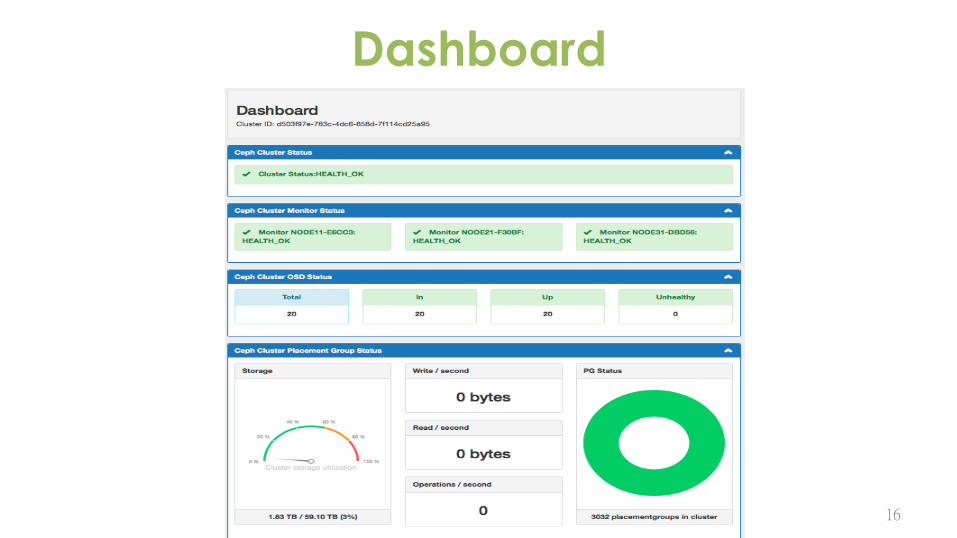
Dashboard
16
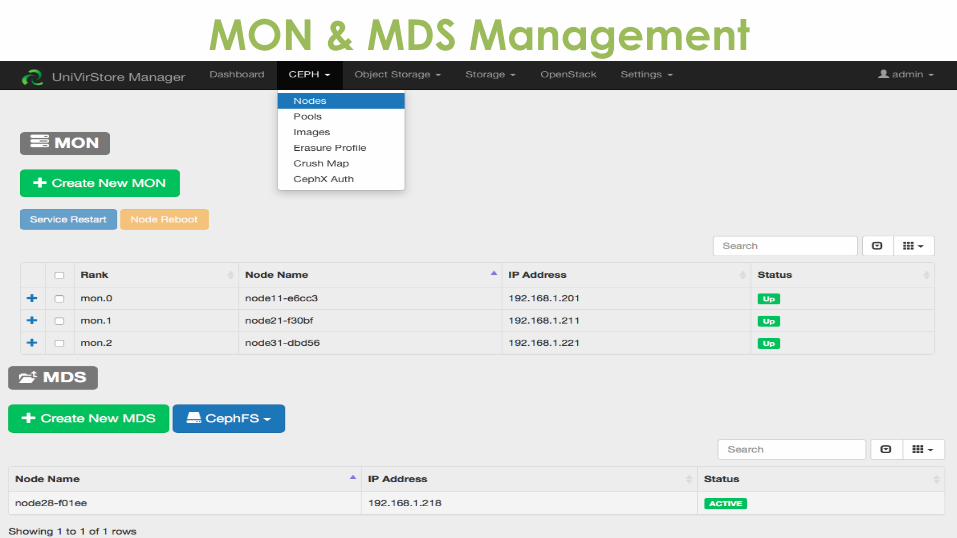
MON & MDS Management
17
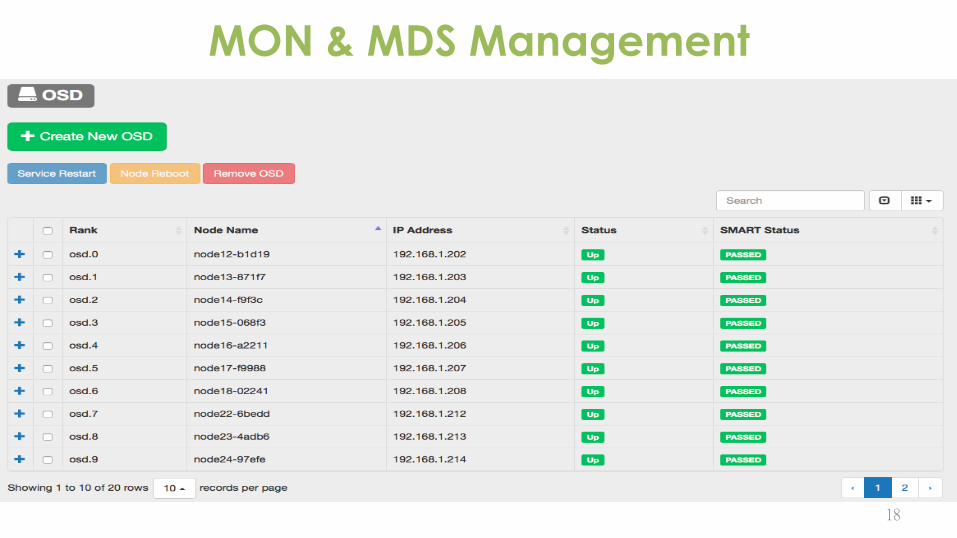
18
MON & MDS Management

Pool Management
19
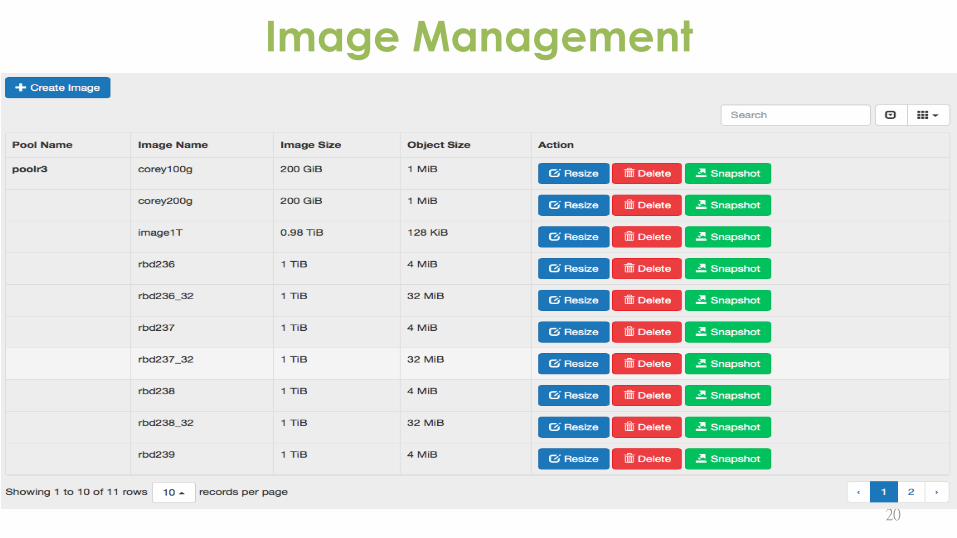
Image Management
20

Crush Map
21
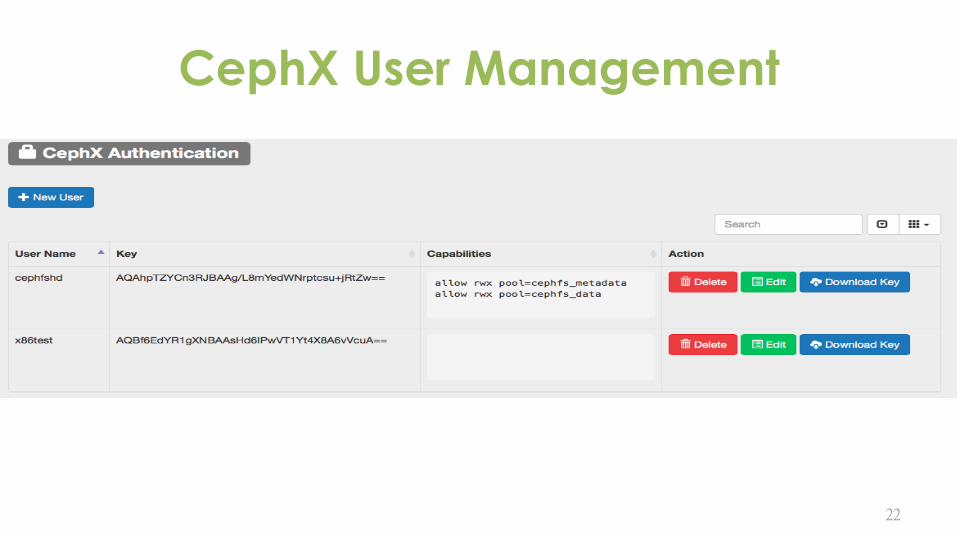
CephX User Management
22
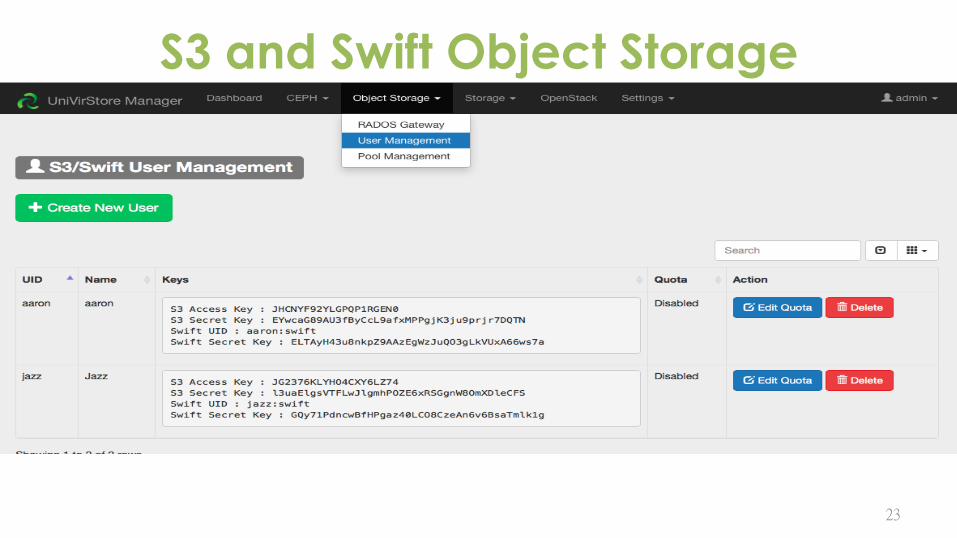
S3 and Swift Object Storage
23
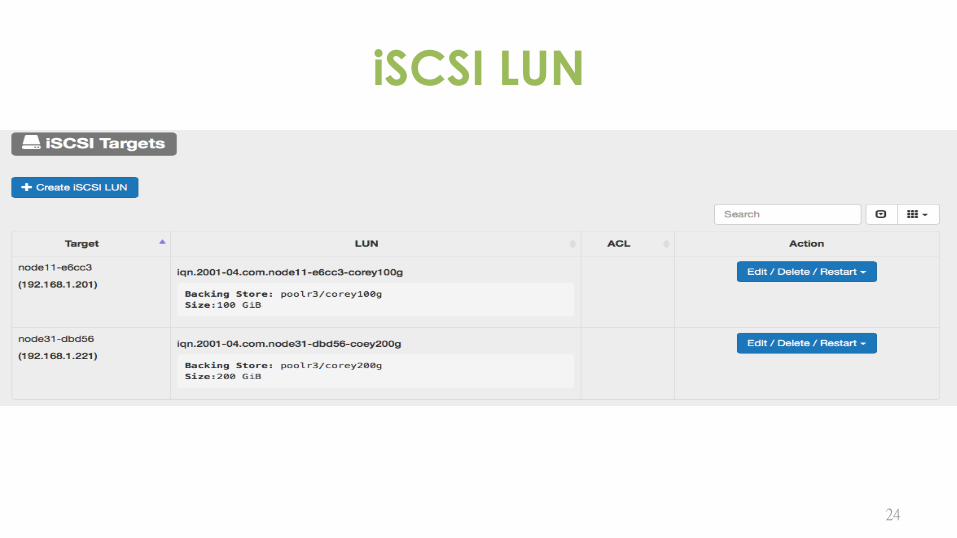
iSCSI LUN
24
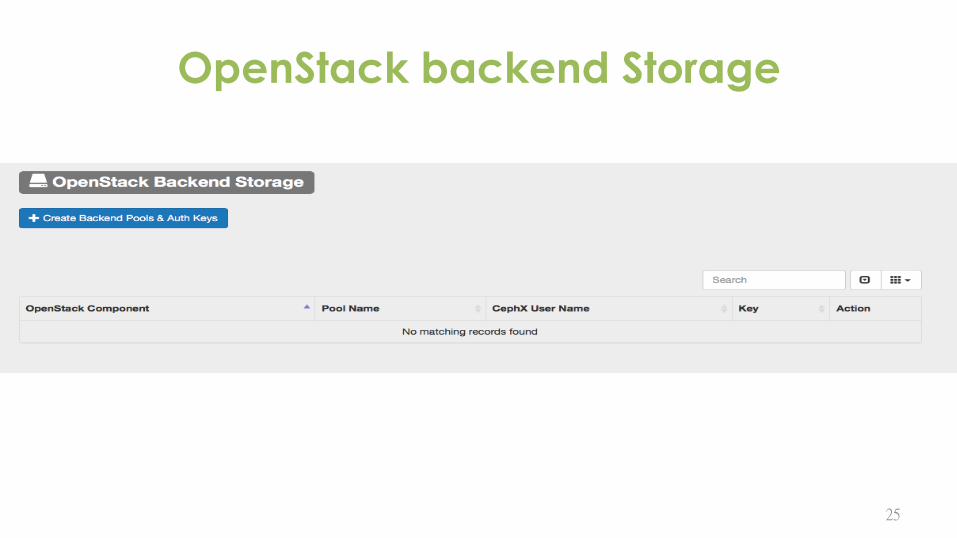
OpenStack backend Storage
25
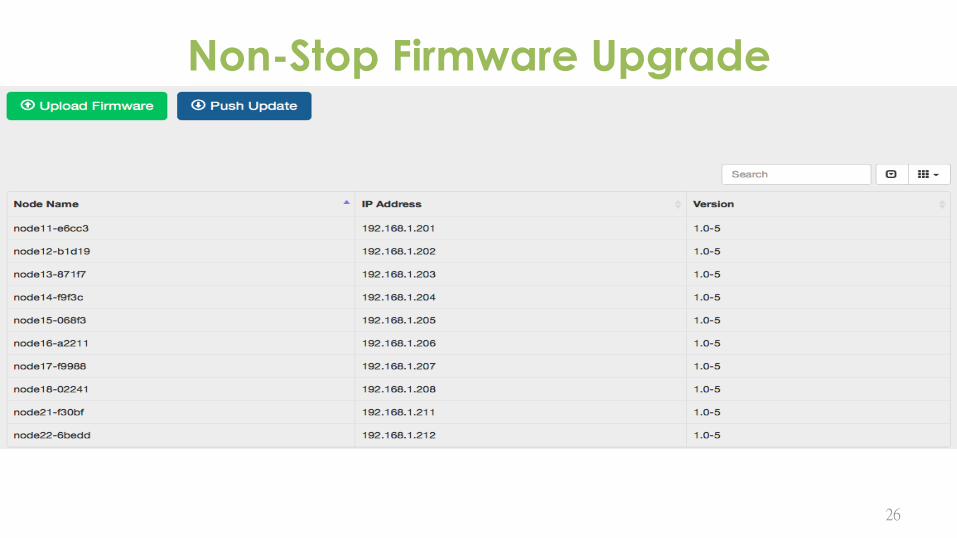
Non-Stop Firmware Upgrade
26

THANK YOU�Ambedded Technology http://www.ambedded.com.tw TEL: +886-2-23650500 Email : [email protected]
27


















