
HMM-based speech synthesis: the new generation of artificial voices
53
14/03/22 HMM-based speech synthesis: the new generation of artificial voices Thomas Drugman [email protected]
-
Upload
danilo-sousa -
Category
Education
-
view
77 -
download
1
Transcript of HMM-based speech synthesis: the new generation of artificial voices

15/04/2315/04/23
HMM-based speech synthesis: the new
generation of artificial voices
Thomas [email protected]

22Drugman ThomasDrugman Thomas
TCTS Lab
« Laboratoire de Théorie des Circuits et de Traitement du Signal »
25 people : 3 Profs, 10 PhD Students
Audio& Speech
Image& Video
NumericalArts
TCTS Lab

33
Content
• Speech synthesis: history
• HMM-based speech synthesis
• Parametric modeling of speech
• Statistical generation
• Conclusions

44
Content
• Speech synthesis: history
• HMM-based speech synthesis
• Parametric modeling of speech
• Statistical generation
• Conclusions

55Drugman ThomasDrugman Thomas
Speech Synthesis
« Hello »Text-to-speech
system
GOAL :
Produce the lecture of an unknown text typed by the user

66Drugman ThomasDrugman Thomas
Challenges
Naturalness
Intelligibility
Cost-effectiveness
Expressivity

77
Challenge 3 : Cost-effectivenessChallenge 3 : Cost-effectiveness
Industry expects Intelligibility + Naturalness + …
Small footprint : a few Megs Small CPU requirements (embedded market) Easy extension to other languages Possibility to create new voices as fast as
possible• Through automatic recording/segmentation
process• Through efficient voice conversion
Possibility to bootstrap an existing TTS voice into any voice
Drugman ThomasDrugman Thomas

88
Challenge 4 (new) : ExpressivityChallenge 4 (new) : Expressivity
=“Emotional speech synthesis” (art!)
1. Being able to render an expressive voice• In terms of prosody• In terms of voice quality
2. Knowing when to do it (yet unsolved)
Today’s holy grail for the industry• Strategic advantage for whoever gets it first• News markets (ebooks?)
Drugman ThomasDrugman Thomas

99Drugman ThomasDrugman Thomas
Methods for Speech Synthesis
Expert-based (rule-based) approach
Corpus-based approach
• Diphone concatenation
• Unit Selection
• Statistical parametric synthesis (“HMM-based synthesis”)

1010Prof. Thierry DutoitProf. Thierry Dutoit
Von Kempelen’s talking machine (1791)
Mouth
Nostrils
Main bellows
Small bellows
'S' pipe
'Sh' pipe
'Sh' lever'S' lever

1111Prof. Thierry DutoitProf. Thierry Dutoit
Omer Dudley’s Voder (Bell Labs, 1936)
NoiseSource
Oscillator
Resonnance Control Amplifier
106 7 8
9
"Quiet"
t-dp-b
k-g
Energy switchwrist bar
VoderConsoleKeyboard
12 3 4
5
Pitch-controlpedal
UV
V

And other developments in articulatory synthesis
Work by :K. Stevens, G. Fant, P. Mermelstein, R. Carré (GNUSpeech), S. Maeda, J. Shroeter & M. Sondhi…
More recently : O. Engwall, S. Fels (ArtiSynth), Birkholz and Kröger, A. Alwan & S. Narayanan (MRI)…
1212Prof. Thierry DutoitProf. Thierry Dutoit

1313Prof. Thierry DutoitProf. Thierry Dutoit
Rule-based synthesis
Intelligibility Naturalness Mem/CPU/Voices Expressivity

1414Drugman ThomasDrugman Thomas
Methods for Speech Synthesis
Expert-based (rule-based) approach
Corpus-based approach
• Diphone concatenation
• Unit Selection
• Statistical parametric synthesis (“HMM-based synthesis”)

1515
Diphone concatenation
Intelligibility Naturalness~ Mem/CPU/Voices Expressivity

1616
Unit selection
Intelligibility Naturalness Mem/CPU/Voices ~ Expressivity ~

1717
Content
• Speech synthesis: history
• HMM-based speech synthesis
• Parametric modeling of speech
• Statistical generation
• Conclusions

1818
Statistical Parametric Speech Synthesis
DATABASESpeech
Parameters
SpeechParameters
SPSSynthesizer
SpeechProcessing
SpeechAnalysis
StatisticalModeling
StatisticalGeneration
TRAININGSYNTHESIS
Hello!« Hello !»

1919
HMM-based speech synthesis
Intelligibility Naturalness ? Mem/CPU/Voices Expressivity ?
http://hts.sp.nitech.ac.jp/

2020
TRAININGOF THE HMM-BASED
SYNTHESIZER

2121
Parameter extraction

2222
Parameter extraction
Pulsetrain
White noise
Filter SyntheticSpeech

2323
Labels

2424
Labels
Labels consist of phonetic environment description
Contextual factors:
-Phone identity-Syntaxical factors-Stress-related factors-Locational , …

2525
Labels
Example

2626
HMM training

2727
System architecture
Contextual factors may affect duration, source and filter
differently
Context Oriented Clusteringusing Decision Trees

2828
State DurationModel
HMM forSource and Filter
Decision treesfor Filter
Decision treesfor Source
Decision treefor
State Duration
System architecture

2929
Training decision trees
An exhaustive list of possible questions is first drawn up
QS "LL-Nasal" {m^*,n^*,en^*,ng^*}QS "LL-Fricative" {ch^*,dh^*,f^*,hh^*,hv^*,s^*,sh^*,th^*,v^*,z^*,zh^*}QS "LL-Liquid" {el^*,hh^*,l^*,r^*,w^*,y^*}QS "LL-Front" {ae^*,b^*,eh^*,em^*,f^*,ih^*,ix^*,iy^*,m^*,p^*,v^*,w^*}QS "LL-Central" {ah^*,ao^*,axr^*,d^*,dh^*,dx^*,el^*,en^*,er^*,l^*,n^*,r^*,s^*,t^*,th^*,z^*,zh^*}QS "LL-Back" {aa^*,ax^*,ch^*,g^*,hh^*,jh^*,k^*,ng^*,ow^*,sh^*,uh^*,uw^*,y^*}QS "LL-Front_Vowel" {ae^*,eh^*,ey^*,ih^*,iy^*}QS "LL-Central_Vowel" {aa^*,ah^*,ao^*,axr^*,er^*}QS "LL-Back_Vowel" {ax^*,ow^*,uh^*,uw^*}QS "LL-Long_Vowel" {ao^*,aw^*,el^*,em^*,en^*,en^*,iy^*,ow^*,uw^*}QS "LL-Short_Vowel" {aa^*,ah^*,ax^*,ay^*,eh^*,ey^*,ih^*,ix^*,oy^*,uh^*}QS "LL-Dipthong_Vowel" {aw^*,axr^*,ay^*,el^*,em^*,en^*,er^*,ey^*,oy^*}QS "LL-Front_Start_Vowel" {aw^*,axr^*,er^*,ey^*}
Example :
Total: about 1500 questions

3030
Training decision trees
Decision trees are trained using a Maximum Likelihood criterion
Example :

3131
Emission likelihood and training
Finally, each leaf is modeled by a Gaussian Mixture Model (GMM)
Training is guided by the Viterbi and Baum-Welch re-estimation
algorithms

3232
SYNTHESISBY THE HMM-BASED
SYNTHESIZER

3333
Text analysis

3434
Parameters generation

3535
Parameters generation
Given the sequence of labels, durations are determined by
maximizing the state sequence likelihood
A trajectory through context-dependent HMM states is known !

3636
Parameters generation
Using this trajectory, source and filter parameters are generated by maximizing the output probability
Dynamic features evolution more realistic and smooth

3737
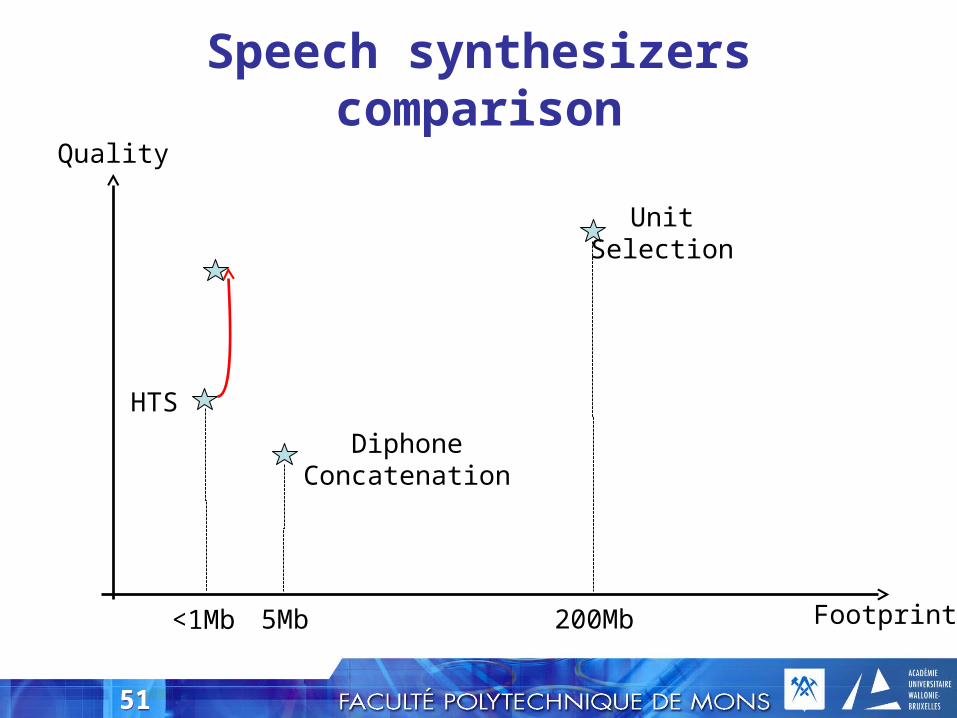
Speech synthesizers comparison

3838
Speech synthesizers comparison
UnitSelection
DiphoneConcatenation
HTS
<1Mb 5Mb 200Mb
Quality
Footprint

3939
Content
• Speech synthesis: history
• HMM-based speech synthesis
• Parametric modeling of speech
• Statistical generation
• Conclusions

4040
Problem positioning
Parametric speech synthesizersgenerally suffer from a typical
buzziness as encountered in LPC-like vocoders
Source–Filter approach:
Enhance the excitation signal
Pulsetrain
White noise
Filter SyntheticSpeech

4141
Proposed solutionSOURCE
FILTER
T.Drugman, G.Wilfart, T.Dutoit, « A Deterministic plus Stochastic Model of the Residual Signal for Improved Parametric Speech Synthesis », Interspeech09
4242
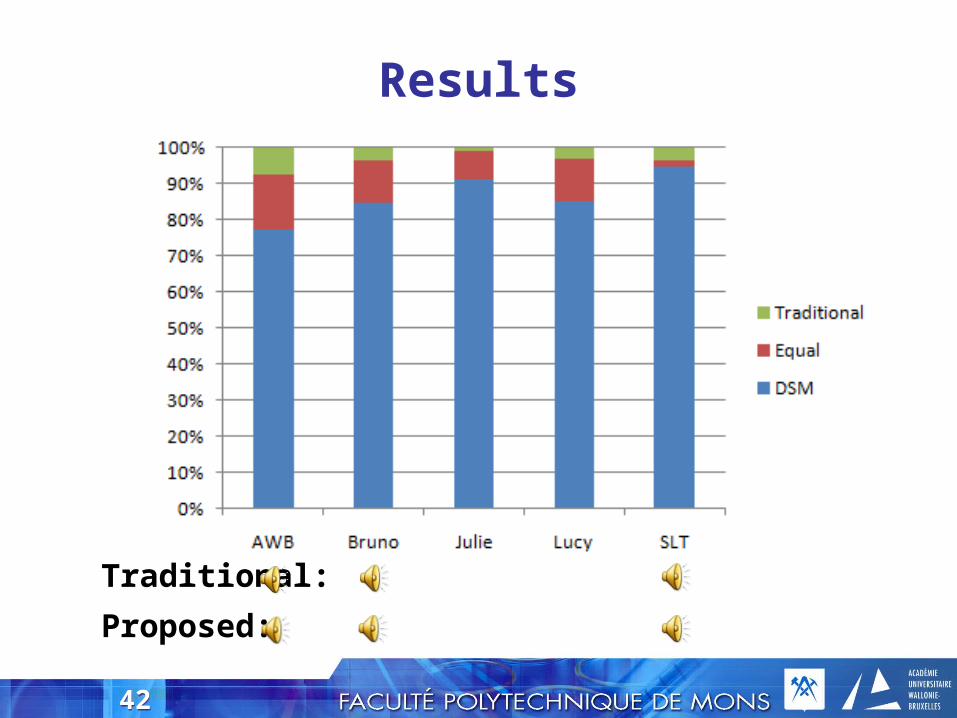
Results
Traditional:
Proposed:

4343
Content
• Speech synthesis: history
• HMM-based speech synthesis
• Parametric modeling of speech
• Statistical generation
• Conclusions

4444Drugman ThomasDrugman Thomas
Problem of oversmoothing

4545Drugman ThomasDrugman Thomas
Compensation of oversmooting

4646Drugman ThomasDrugman Thomas
Global Variance

4747Drugman ThomasDrugman Thomas
Global Variance

4848Drugman ThomasDrugman Thomas
Results

4949
Content
• Speech synthesis: history
• HMM-based speech synthesis
• Parametric modeling of speech
• Statistical generation
• Conclusions

5050
Speech synthesizers comparison
Intelligibility Naturalness ? Mem/CPU/Voices Expressivity ?
Intelligibility Naturalness Mem/CPU/Voices Expressivity
Intelligibility Naturalness~ Mem/CPU/Voices Expressivity
Intelligibility Naturalness Mem/CPU/Voices ~ Expressivity ~
Rule-based synthesis
Diphone concatenation
Unit selection
HMM-based speech synthesis
5151
Speech synthesizers comparison
UnitSelection
DiphoneConcatenation
HTS
<1Mb 5Mb 200Mb
Quality
Footprint

5252
Future Works
Voice Conversion
Expressive/emotional synthesis
Better parametric representation
Real-time speech synthesis

5353
Questions ?


















