High-Performance DRAM System Design Constraints and Considerations by: Joseph Gross August 2, 2010.
48
High-Performance DRAM System Design Constraints and Considerations by: Joseph Gross August 2, 2010
-
Upload
barnaby-holt -
Category
Documents
-
view
259 -
download
3
description
What is the Problem? Controller performance is sensitive to policies and parameters Real simulations show surprising behaviors Policies interact in non-trivial and non-linear ways 3
Transcript of High-Performance DRAM System Design Constraints and Considerations by: Joseph Gross August 2, 2010.

High-Performance DRAM System Design
Constraints and Considerations
by: Joseph Gross
August 2, 2010

2
Table of ContentsBackground
◦Devices and organizationsDRAM Protocol
◦Operations and timing constraintsPower AnalysisExperimental Setup
◦Policies and AlgorithmsResultsConclusionsAppendix

3
What is the Problem?Controller performance is sensitive to policies and
parametersReal simulations show surprising behaviorsPolicies interact in non-trivial and non-linear ways

4
DRAM Devices – 1T1C Cell
bitline
wordline
Row address is decoded and chooses the wordline
Values are sent across the bitline to the sense amps
Very space-efficient but must be refreshed

5
Organization – Rows and ColumnsCan only read from/write
to an active rowCan access row after it is
sensed but before the data is restored
Read or write to any column within a row
Row reuse avoids having to sense and restore new rows
DRAM Array
Sense Amps
row
active rowcolumn

6
DRAM Operation
Row Latch/
Decoder
Row Latch/
Decoder
Row Latch/
Decoder
Row Latch/
Decoder
Row Latch/
Decoder
Row Latch/
Decoder
Row Latch/
Decoder
Row Latch/
Decoder
CKE
CLK
CS#
WE#
CAS#
RAS#
ADDR
Control Logic
Command Decoder
Mode Register
Refresh Counter DRAM Array
Sense Amps
DRAM Array
Sense Amps
DRAM Array
Sense Amps
DRAM Array
Sense Amps
DRAM Array
Sense Amps
DRAM Array
Sense Amps
DRAM Array
Sense Amps
DRAM Array
Sense Amps
I/O GatingWrite DriversRead Latch
Address Register
Row Address Select
Column Select
Column counter
Bank Controller
Data I/O Gating
DATA
Input Data Register
Output Data Register
1
1-3
2 2
1
3
44

7
Organization
Memory Controller
DIMM 0/front
Channel 0
DIMM 0/back DIMM 1/front DIMM 1/back
Memory Controller 0
Rank 0 Rank 1 Rank 2 Rank 3
DIM
M 0
DIM
M 1
One memory controller per channel
1-4 ranks/DIMM in a JEDEC system
Registered DIMMs at slower speeds may have more DIMMs/channel

8
A Read Cycle
clock
ACT
Bank/sense amp
command Read NOP NOP NOP
tRCD
I/O gating
Pre
Row sense
NOPNOP
time
Bank access Row restore
I/O Gating
datadata data data data
NOP
tCAS tBurst
tRAS
tRC
ACT
Bank precharge
tRP
Activate the row and wait for it to be sensed before issuing the read
Data begins to be sent after tCASPrecharge once the row is restored

9
Command InteractionsCommands must wait for resources to be availableData, address and command buses must be
availableOther banks and ranks can affect timing (tRTRS, tFAW)
tCMD tRCDtRP
tCMD + tRP + tRCD
tCWD
clock
NOP
Bank/sense amp A
command NOP ACT NOP NOP
I/O gating
Write NOP
time
data
NOP NOP
I/O Gating
Bank read
PreRead
Bank/sense amp B
data data data data data data datadata data data data data data data data data
I/O Gating
Data restoreBank precharge Data sense

10
Power ModelingBased on Micron guidelines (TN-41-01)Calculates background and event power
clock
ACTcommand
NOP NOP NOP NOP PreReadACT
time
NOP NOP
current
Activation current Precharge current
Read current

11
Controller Design
CPU/Network 1
CPU/Network 2
CPU/Network 3
CPU/Network n
DRAMsimIIChannel n
Channel 1
BIU
Transaction queue
Refresh queueCommand generator/scheduler
Rank 1Bank n
Command queue
Bank 2
Command queue
Bank 1
Command queue
Rank 2Bank n
Command queue
Bank 2
Command queue
Bank 1
Command queue
Rank nBank n
Command queue
Bank 2
Command queue
Bank 1
Command queue
(row buffer management policy,
address mapping
policy)
(Transaction ordering algorithm,
timing parameters,)
(Command ordering
algorithm)
Decode delay
Address Mapping Policy
Row Buffer Management Policy
Command Ordering Policy
Pipelined operation with reordering

12
Controller DesignDRAMsimII
Transaction queue
Row Buffer Management
Policy
Address Mapping Policy
Refresh queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command Ordering Algorithm
Command/address/data
bus

13
Transaction QueueNot varied in this simulationPolicies
◦Reads go before writes◦Fetches go before reads◦Variable number of transactions may be decoded
Optimized to avoid bottlenecksRequest reordering

14
Row Buffer Management Policy
PreActivate Read
Close PagePreActivate Write PreActivate Read
Activate Read
Open PagePre
Pre
Write WriteActivate Read
Activate Read
Close Page AggressivePreWrite ActivateActivate Read Write
Open Page AggressiveActivate Read PreWrite WriteActivate Read Pre Activate

15
Address Mapping PolicyBurger Base (BBM)
SDRAM High Performance (OPBAS)
SDRAM Base (SDBAS)
Intel 845G (845G)
SDRAM Close Page (CPBAS)
SDRAM Close Page Low Locality (LOLOC)
SDRAM Close Page High Locality (HILOC)
row bank rank column channel Byte addr
row rank bank Column high channel Byte addrColumn low
rank row bank Column high channel Byte addrColumn low
rank row bank column Byte addr
row Column high rank bank channel Byte addrColumn low
Column high row Column low bank rank Byte addrchannel
rank bank channel Column high row Byte addrColumn low
SDRAM Close Page Baseline Optimizedrow high column high rank bank channel Byte addrColumn lowrow low
Chosen to work with row buffer management policy
Can either improve row locality or bank distribution
Performance depends on workload

16
Address Mapping Policy – 433.calculix
Low Locality (~5s) – irregular distribution
SDRAM Baseline (~3.5s) – more regular distribution

17
Command Ordering AlgorithmSecond Level of Command Scheduling
◦FCFS (FIFO)◦Bank Round Robin◦Rank Round Robin◦Command Pair Rank Hop◦First Available (Age)◦First Available (Queue)◦First Available (RIFF)
DRAMsimII
Transaction queue
Row Buffer Management
Policy
Address Mapping Policy
Refresh queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command queue
Command Ordering Algorithm
Command/address/data
bus

18
Command Ordering Algorithm – First AvailableRequires tracking of when rank/bank resources are
availableEvaluates every potential command choice
◦Age, Queue, RIFF – secondary criteria
Time
CASW
CASWOther rank
CAS
tRTRS
tCAS
tBurst
tCWD
tWTR tBursttCWD
CAS

19
Results - Bandwidth

20
Results - Latency

21
Results – Execution Time

22
Results - Energy

23
Command Ordering Algorithms

24
Command Ordering Algorithms

25
ConclusionsThe right combination of policies can achieve good
latency/bandwidth for a given benchmark◦Address mapping policies and row buffer management
policies should be chosen together◦Command ordering algorithms become important as the
memory system is heavily loadedOpen Page policies require more energy than Close
Page policies in most conditionsThe extra logic for more complex schemes helps
improve bandwidth but may not be necessaryAddress mapping policies should balance row reuse
and bank distribution to reuse open rows and use available resources in parallel

26
Appendix

27
Bandwidth (cont.)

28
Row Reuse Rate (cont.)

29
Bandwidth (cont.)

30
Results – Execution Time

31
Results – Row Reuse RateOpen Page/Open Page Aggressive have the greatest
reuse rateClose page aggressive rarely exceeds 10% reuseSDRAM Baseline and SDRAM High Performance work
well with open page429.mcf has very little ability to reuse rows, 35% at
the most 458.sjeng can reuse 80% with SDRAM Baseline or
SDRAM High Performance, else the rate is very low

32
Execution Time (cont.)

33
Row Reuse Rate (cont.)

34
Average Latency (cont.)

35
Average Latency (cont.)

36
Results - BandwidthHigh Locality is consistently worse than othersClose Page Baseline (Opt) work better with Close
Page (Aggressive)SDRAM Baseline/High Performance work better with
Open Page (Aggressive)Greater bandwidth correlates inversely with
execution time – configurations that gave benchmarks more bandwidth finished sooner
470.lbm (1783%), (1.5s, 5.1GB/s) – (26.8s, 823MB/s)458.sjeng (120%), (5.18s, 357MB/s) – (6.24s,
285MB/s)

37
Results - EnergyClose Page (Aggressive) generally takes less energy than
Open Page (Aggressive)The disparity is less for heavy-bandwidth applications like
470.lbm◦Banks are mostly in standby mode
Doubling the number of ranks◦Approximately doubles the energy for Open Page (Aggressive)◦Increases Close Page (Aggressive) energy by about 50%
Close Page Aggressive can use less energy when row reuse rates are significant
470.lbm (424%), (1.5s, 12350mJ) – (26.8s, 52410mJ)458.sjeng (670%), (5.18s, 14013mJ) – (6.24s, 93924mJ)

38
Bandwidth (cont.)

39
Bandwidth (cont.)

40
Results – Average Latency

41
Energy (cont.)

42
Energy (cont.)

43
Average Latency (cont.)

44
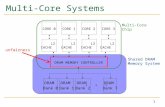
Memory System Organization
Memory Controller
DRAM Array DRAM Array DRAM Array
DRAM Array DRAM Array DRAM Array
DRAM Array DRAM Array DRAM Array
Address bus
Data bus
Command bus

45
Transaction QueueRIFF or FIFOPrioritizes read or
fetchAllows reorderingIncreases controller
complexityAvoids hazards
Incoming Transaction Queue
WRITE
WRITE
WRITE
WRITE
READ
WRITE
WRITE
WRITE
FETCH
READ
READ
FETCH
FETCH
RIFF
FETCH
Incoming Transaction Queue
WRITE
WRITE
WRITE
WRITE
WRITE
READ
FETCH
WRITE
WRITE
FETCH
READ
READ
FETCH
FETCH

46
Transaction Queue – Decode WindowOut-of-order
decodingAvoids queuing
delaysHelps to keep
per-bank queues full
Increases controller complexity
Allows reordering
Incoming Transaction Queue
READ
READ
FETCH
READ
READ
FETCH
READ
WRITE
FETCH
READ
WRITE
WRITE
FETCH
Decode Window
Incoming Transaction Queue
READ
READ
FETCH
READ
READ
READ
WRITE
Decode Window
READ
FETCH
WRITE
FETCH
WRITE
FETCH
Incoming Transaction Queue
FETCH
READ
WRITE
READ
READ
READ
READ
Decode Window

47
Row Buffer Management PolicyClose Page / Close Page Aggressive
Row Buffer Management Policy
Close Page
Rank 1Rank 0
RASCAS+P
ReadTransaction
Close Page Aggressive
RASCAS+P
RAS
CAS
CAS+PBank 4
Address Mapping Policy
or
.
.
.
.
.
.

48
Row Buffer Management PolicyOpen Page / Open Page Aggressive
Row Buffer Management Policy
Rank 1Rank 0
ReadTransaction
Bank 4
Address Mapping Policy
.
.
.
.
.
.
Open Page
PreRASCAS
orCAS
CAS
Pre
Open Page Aggressive
CAS
CAS+P
PreRAS
orPreRASCAS