

Hadoop Usage at Yahoo!
30
Transcript of Hadoop Usage at Yahoo!

About Me
• Parallel Programming since 1989
• High-Performance Scientific Computing 1989 - 2005, Data-Intensive Computing 2005 - ...
• Hadoop Solutions Architect @ Yahoo!
• Contributor to Hadoop since 2006
• Training, Consulting, Capacity Planning

History
• 2004-2005: Hadoop prototyped in Apache Lucene
• January 2006: Hadoop becomes subproject of Lucene
• January 2008: Hadoop becomes top-level Apache Project
• Latest Release: 0.21
• Stable Release: 0.20.x (+ Strong Authentication)

Hadoop Ecosystem
•HBase, Hive, Pig, Howl, Oozie, Zookeeper, Chukwa, Mahout, Cascading, Scribe, Cassandra, Hypertable, Voldemort, Azkaban, Sqoop, Flume, Avro ...

Hadoop at Yahoo!
• Behind Every Click !
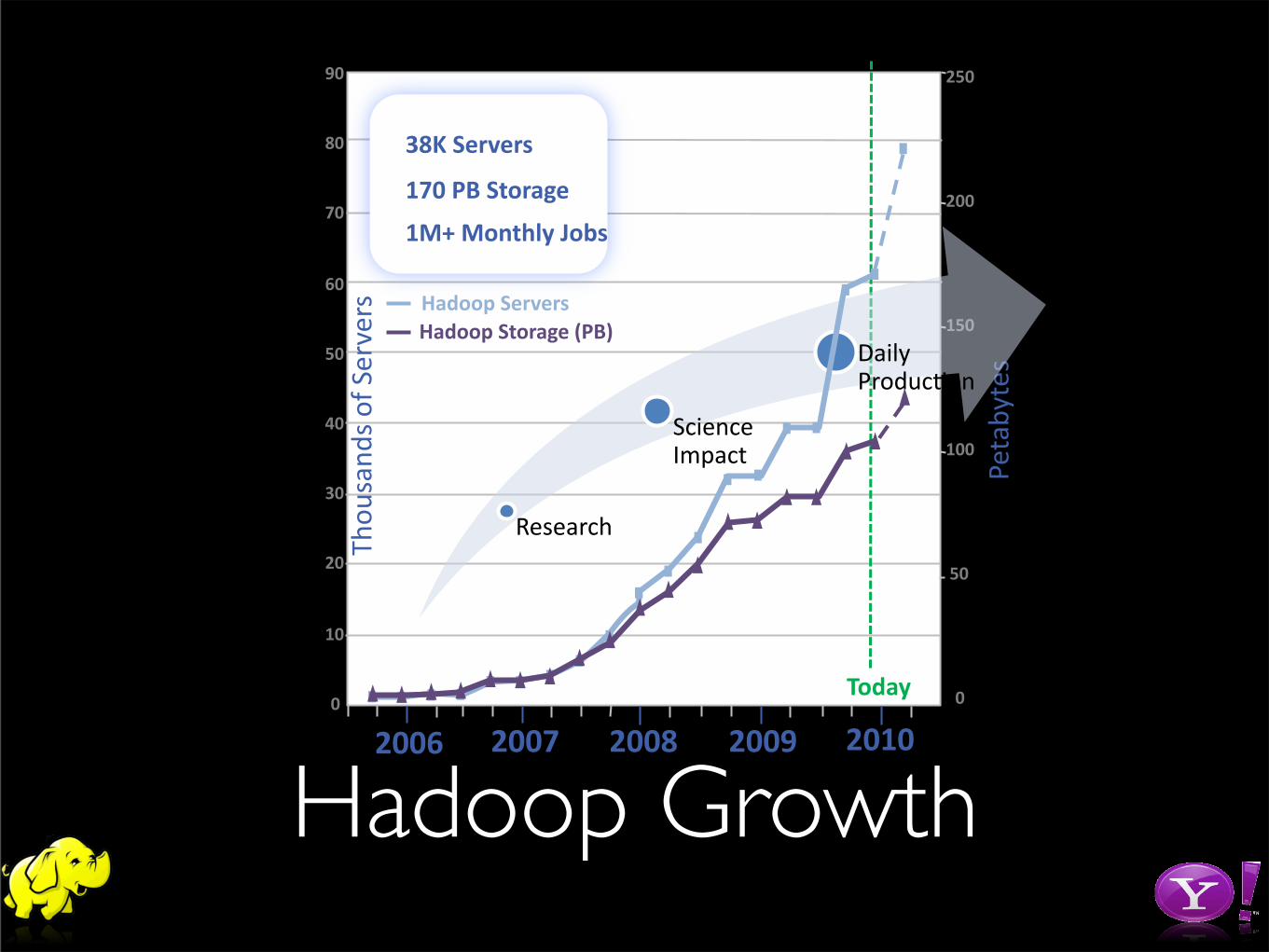
• 38,000+ Servers
• Largest cluster is 4000+ servers
• 1+ Million Jobs per month
• 170+ PB of Storage
• 10+ TB Compressed Data Added Per Day
• 1000+ Users
!"#
$"#
%"#
&"#
'"#
("#
)"#
*"#
+"#
"#
*'"#
*""#
+'"#
+""#
'"#
"#
*""&# *""%# *""$# *""!# *"+"#
,-./0#
)$1#2345346#
+%"#78#29-4/:3#
+;<#;-=9>?0#@-A6#
!"#$%&'(%)#*)+,-.,-%)
/,0&120,%)
3,%,&-4")
+45,'4,)678&40)
9&5:2)/-#($4;#')
B/.--C#2345346#
B/.--C#29-4/:3#D78E#
Hadoop Growth

Hadoop Clusters
• Hadoop Dev, QA, Benchmarking (10%)
• Sandbox, Release Validation (10%)
• Science, Ad-Hoc Usage (50%)
• Production (30%)

Sample Applications
• Science + Big Data + Insight = Personal Relevance = Value
• Log processing: Analytics, Reporting, Buzz
• User Modeling
• Content Optimization, Spam filters
• Computational Advertising
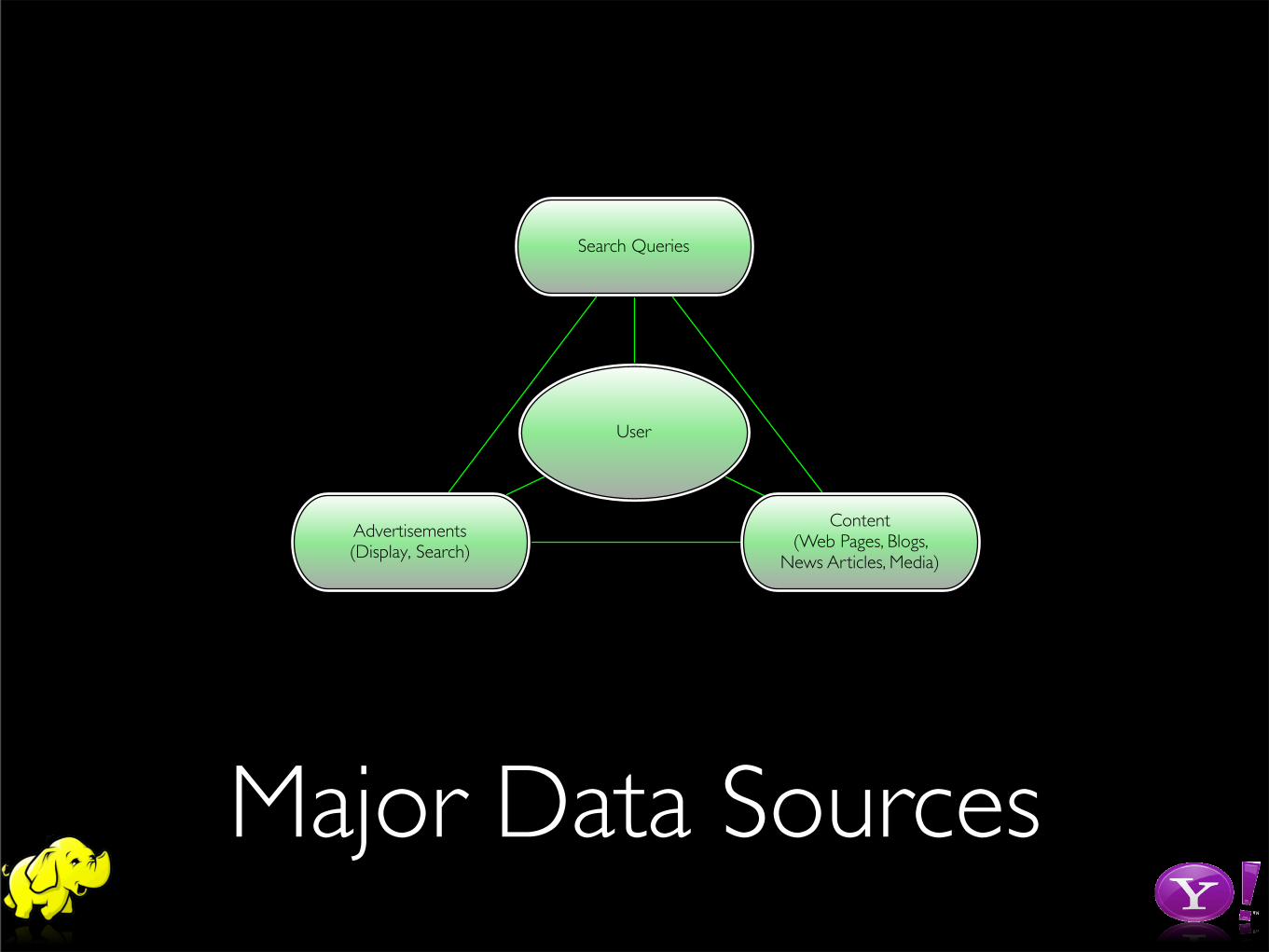
Content(Web Pages, Blogs,
News Articles, Media)
Search Queries
Advertisements(Display, Search)
User
Major Data Sources

Web Graph Analysis
• 100+ Billion Web Pages
• 1+ PB Content
• 2 Trillion links
• 300+ TB of compressed output
• Before Hadoop: 1 Month
• With Hadoop: 1 Week
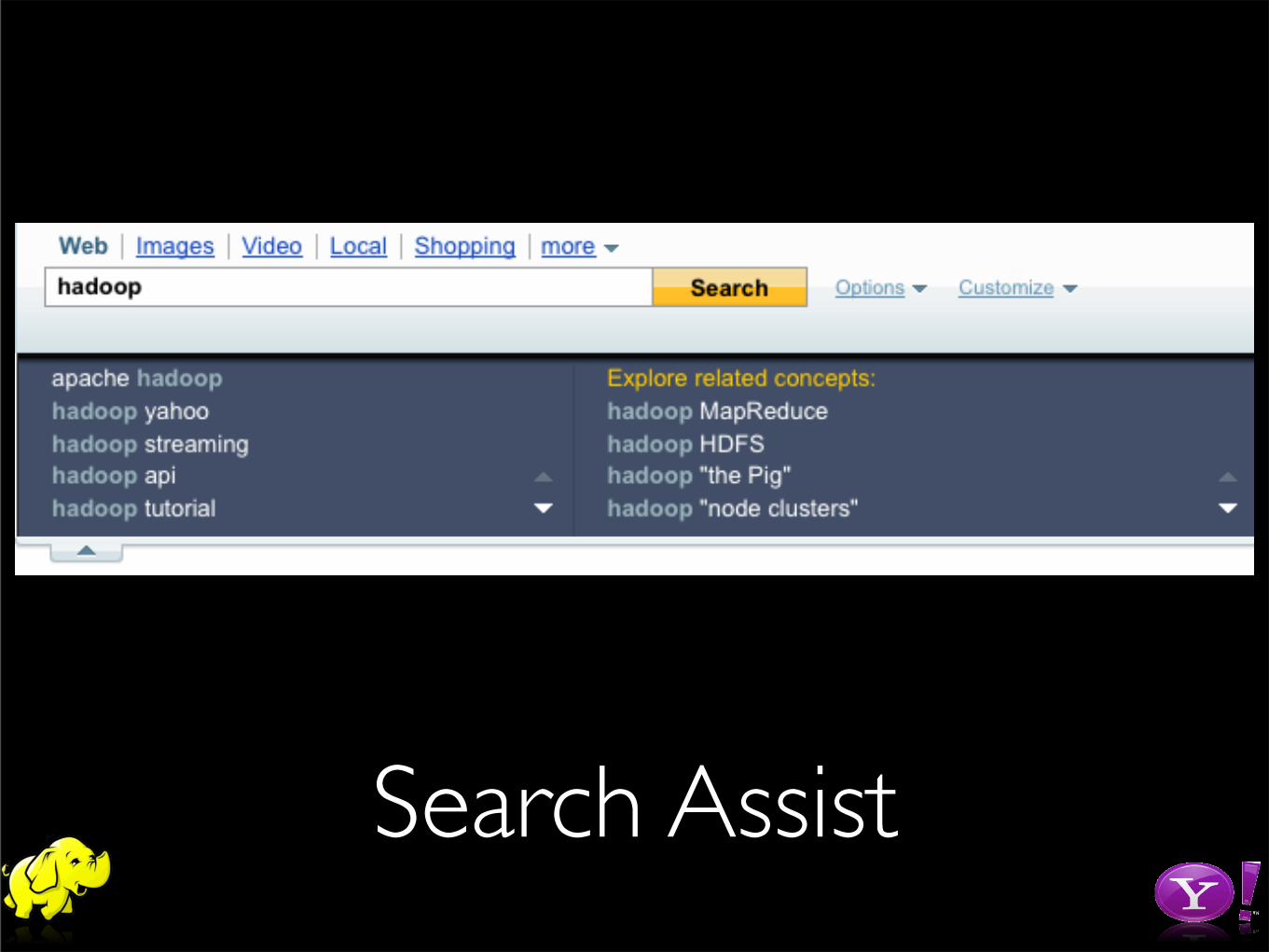
Search Assist

Search Assist
• Related concepts occur closer together
• 3 years of query logs, sessionized per user
• 10+ Terabytes of Natural Language Text Corpus
• Build Dictionaries with Hadoop & Push to Serving
• Before Hadoop: 4 Weeks
• With Hadoop: 30 minutes

Mail Spam Filtering
• Challenge: Scale
• 450+ Million mailboxes
• 5+ Billion deliveries per day
• 25+ Billion connections
• Challenge: User feedback is often late, noisy, inconsistent

Data Factory
• 40+ Billions of Events Per Day
• Parse & Transform Event Streams
• Join Clicks & Views
• Filter out Robots
• Aggregate, Sort, Partition
• Data Quality Checks

User Modeling
• Objective: Determine User-Interests by mining user-activities
• Large dimensionality of possible user activities
• Typical user has sparse activity vector
• Event attributes change over time

User Activities
Attribute Possible Values Typical Values Per User
Pages
Queries
Ads
1+ Million 10-100
100+ Millions 10s
100+ Thousands 10s

User-Modeling Pipeline
• Sessionization
• Feature and Target Generation
• Model Training
• Offline Scoring & Evaluation
• Batch Scoring & Upload to serving

Data AcquisitionUser Time Event Source
U0 T0 Visited Yahoo! Autos Web Server logs
U0 T1 Searched for “Car Insurance”
Search Logs
U0 T2 Browsed stock quotes Web Server Logs
U0 T3 Saw ad for “discount brokerage”, did not click
Ad Logs
U0 T4 Checked Yahoo! Mail Web Server Logs
U0 T5 Clicked Ad for “Auto Insurance”
Ad Logs, Click Logs
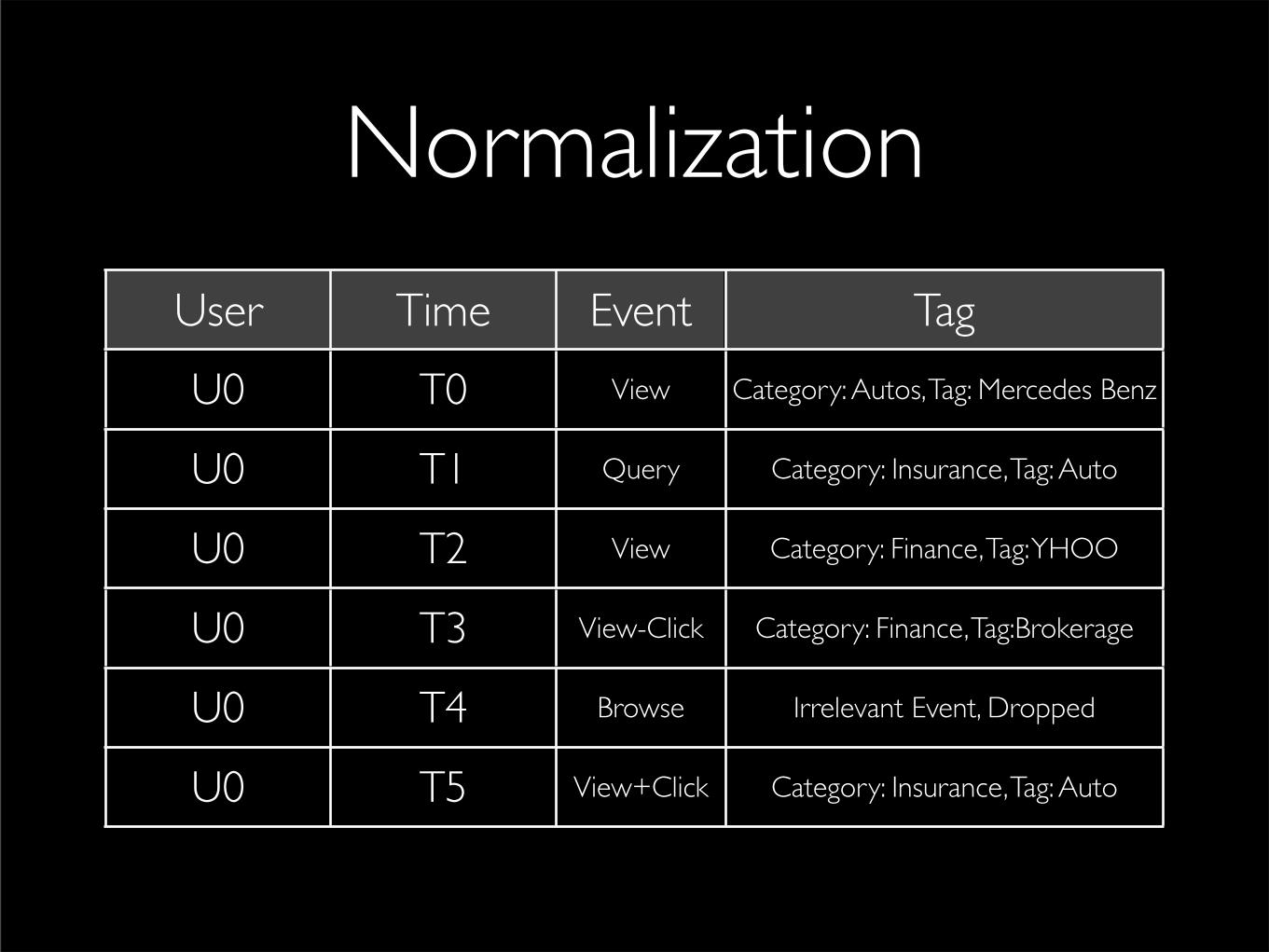
NormalizationUser Time Event Tag
U0 T0 View Category: Autos, Tag: Mercedes Benz
U0 T1 Query Category: Insurance, Tag: Auto
U0 T2 View Category: Finance, Tag: YHOO
U0 T3 View-Click Category: Finance, Tag:Brokerage
U0 T4 Browse Irrelevant Event, Dropped
U0 T5 View+Click Category: Insurance, Tag: Auto
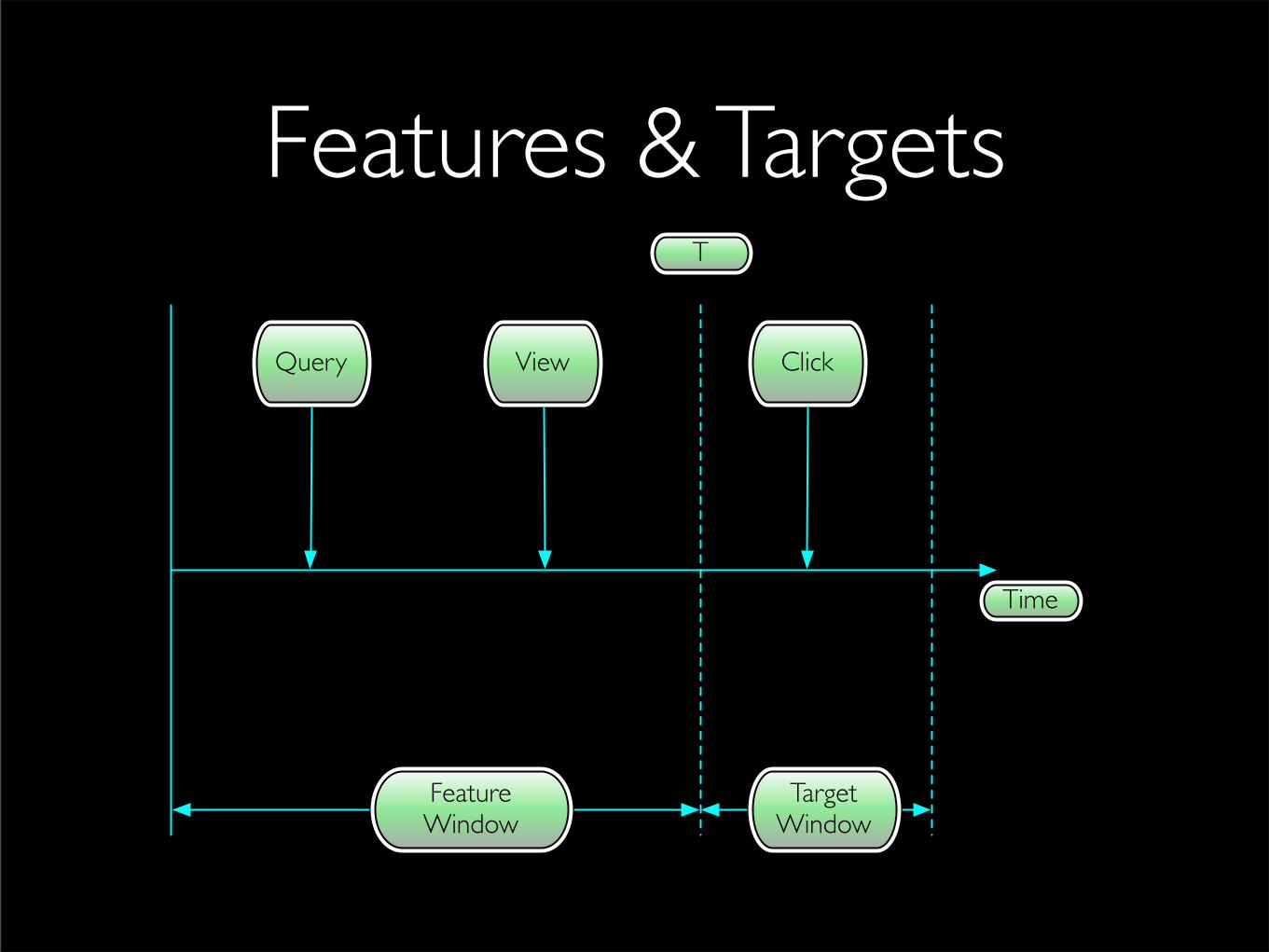
Features & Targets
Time
Query View Click
T
Feature Window
Target Window

Targets
• User-Actions of Interest
• Clicks on Ads & Content
• Site & Page visits
• Conversion Events
• Purchases, Quote requests
• Sign-Up for membership etc

Features
• Summary of user activities over a time-window
• Aggregates, moving averages, rates over various time-windows
• Incrementally updated

Joining Targets & Features
• Target rates very low: 0.01% ~ 1%
• First, construct targets
• Filter user activity without targets
• Join feature vector with targets

Model Training
• Regressions
• Boosted Decision Trees
• Naive Bayes
• Support Vector Machines
• Maximum Entropy modeling
• Constrained Random Fields

Model Training
• Some algorithms are difficult/inefficient to implement in Map-Reduce
• Require fine-grain iterations
• Different models in parallel
• Model for each target response in parallel

Offline Scoring & Evaluation
• Apply model weights to features
• Pleasantly parallel
• Janino Embedded Compiler
• Sort by scores and compute metrics
• Evaluate metrics

Batch Scoring
• Apply models to features from all user activity
• Upload scores to serving systems

User Modeling Pipeline
Component Data Volume Time
Data Acquisition
Feature & Target Generation
Model Training
Scoring
1 TB 2-3 Hours
1 TB * Feature Window Size 4-6 Hours
50 - 100 GB 1-2 Hours for 100s of Models
500 GB 1 Hour

Acknowledgements
• Vijay K Narayanan
• Vishwanath Ramarao
• Nitin Motgi
• And Numerous Hadoop Application Developers at Yahoo!

Questions ?















![Hadoop: A View from the Trenches...Founding member of Hadoop team at Yahoo! [2005-2010] ! Contributor to Apache Hadoop since v0.1 ! Built and led Grid Solutions Team at Yahoo! [2007-2010]](https://static.fdocuments.us/doc/165x107/5ec5ee22e9422601c50f805b/hadoop-a-view-from-the-trenches-founding-member-of-hadoop-team-at-yahoo-2005-2010.jpg)


