
GraphM sc'19
28
SC 2021
Transcript of GraphM sc'19

SC 2021

LCCG: A Locality-Centric Hardware Accelerator for High Throughput of Concurrent Graph Processing
Jin Zhao1, Yu Zhang1, Xiaofei Liao1, Ligang He2, Bingsheng He3, Hai Jin1, Haikun Liu1
1 SCTS/CGCL, Huazhong University of Science and Technology, China
2 University of Warwick, UK3 National University of Singapore, Singapore

• Background and Challenges
• Locality-centric Accelerator
• Hardware Design
• Experimental Results
• Conclusion
Outline

customer segmentation
…
Applications of Concurrent Graph Processing
• The example applications
computing the landmark labeling
computing the network
community profile
random
walk
k-core
friend suggestion
BFS
PageRankWCC
social information monitoring

Existing Hardware-software Solutions
• Existing general-purpose many-core processor
under-utilization of cache and memory bandwidth
serious cache thrashing and intense resource contention
• Specific hardware accelerators
designed to serve a single job
inefficient for resolving the uncoordinated CGP jobs
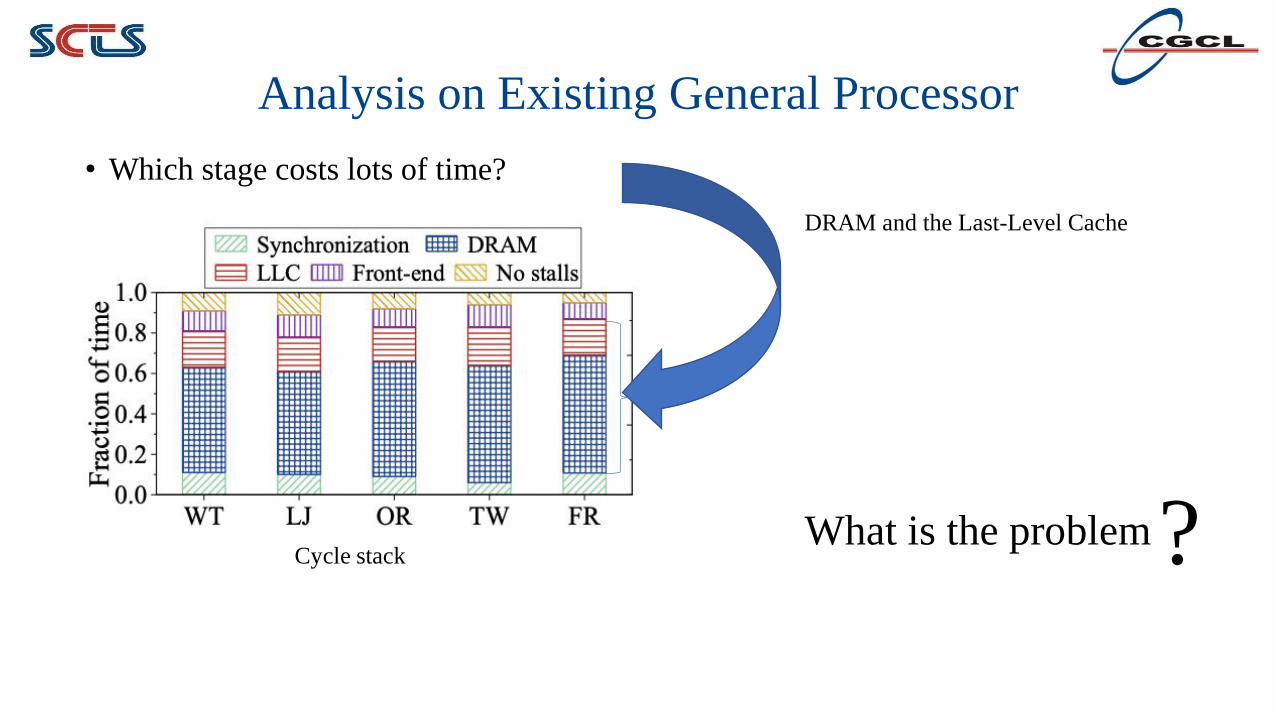
Analysis on Existing General Processor
• Which stage costs lots of time?
Cycle stack
DRAM and the Last-Level Cache
What is the problem?

Challenges: Irregular Graph Traversal
• Example: two BFS jobs
Such irregular graph traversals of the jobs cause redundant memory traffic among these jobs.
c. Memory access pattern of two BFS jobs wthin the second itertion
b. Execution of two BFS jobs on the grapha. An example graph
d. Ratio of fetched graph structure data
shared by different nums of jobs

Challenges: Intense Resource Contention
Ratio of the fetched useful vertex state data
to all fetched vertex state data
• Example: Multiple jobs executed concurrently
Low ratio of the useful vertex state data implies ineffective use of the cache and
memory bandwidth.

Motivations: Inter-job Locality of the CGP Jobs
Inter-job temporal locality
Inter-job spatial locality
b. Execution of two BFS jobs on the graph
c. Real experiment: CGP jobs on Ligra-M
reduce the memory traffic
achieve higher utilization of the
cache and memory bandwidth
a. An example graph

• Background and Challenges
• Locality-centric Accelerator
• Hardware Design
• Experimental Results
• Conclusion
Outline

Topology-aware Execution
• Topology-aware Regularization of Data Accesses
BFS 1 and BFS 2 traverse the same graph structure separately
from different graph vertices
common traverse path:
BFS 2 BFS 1 and BFS 2
common traverse path:
BFS 1 and BFS 2 BFS 1 and BFS 2
the active vertices of BFS 1 and BFS 2 are E、G
……
cycles
Topology-aware Regularization of Data Accesses
the active vertices of BFS 1 and BFS 2 are B、F
Mining the temporal locality of concurrent graph analysis task data access to maximize the
sharing rate of loaded graph data

When BFS1 accesses its own state of B, the
state of B for BFS2 can also be fetched into
the LLC for BFS2's execution.
The data structure used to maintain and index
the hot vertices' states.
Mining concurrent graphs to analyze the spatial locality of task data access, improving
cache and bandwidth utilization, and minimizing resource competition
• Vertex States Coalescing
Topology-aware Execution
Common traversal paths
Extra instructions ?

LCCG Design
• System architecture
Runtime system for high-concurrency graph analysis service
Existing Software Graph Processing Framework
PageRank BFS SSSP
...
Shared graph structure data & state data of each task graph vertex
memory
WCC
concurrent graph jobs
CPU
LCCG Architecture

• Background and Challenges
• Locality-centric Accelerator
• Hardware Design
• Experimental Results
• Conclusion
Outline

TATR: Topology-Aware Traversal Regularization
• Key Data Structures
activa_all array
Intermediate_queue array
WorkList array

TATR: Topology-Aware Traversal Regularization
Microarchitecture of the TATR unit
• Exploration of Common Traversal Paths.

TATR: Topology-Aware Traversal Regularization
• Enhancement of Traversal Parallelism.
TATR uses multiple pipelines to explore the
common traversal paths.
The completed pipeline steals half of the remaining
unvisited vertices from other pipeline for balanced
load.Microarchitecture of the TATR unit

TATR: Topology-Aware Traversal Regularization
• Partition Organization
Enabling the loaded graph data to be reused by these CGP jobs.
Count the number of edges of the vertices
Microarchitecture of the TATR unit

PI: Prefetching and Indexing
• Key Data Structures
The Consolidated states array
The Job offset array
State offset arrays
𝛼 × |𝑉|
𝜎
|V | is the total number σ of verticesσ is set to 0.75 by default

PI: Prefetching and Indexing
• Prefetching of Graph Data
Microarchitecture of the PI unit

PI: Prefetching and Indexing
• State Indexing of Hot Vertices.
Microarchitecture of the PI unit
A job need to access the state of a vertex v
1. checks if this vertex is a hot vertex(thresshold T).
2. adds hot vertex information into the Consolidated
states table -> the access to it can be efficient.
3. partition synchronous control -> avoid cache
thrashing.
Achieving higher utilization of the cache and memory bandwidth

• Background and Challenges
• Locality-centric Accelerator
• Hardware Design
• Experimental Results
• Conclusion
Outline

• Platform
- Zsim
• Typical graph processing algorithms
- PageRank(PR), Random Walk(RW), Weakly Connected
Component(WCC), Maximal Independent Sets(MIS), Label Propagation(LP), k-core, Single Source Shortest Path(SSSP), Breadth-First Search(BFS)
• Datasets
- 5 real world datasets
• Evaluation Methodology
Experiment Setup
- baseline software system: Ligra-M
- ours: software-only LCCG(LCCG-S)and hardware implemented LCCG(LCCG-H), LCCG-T is that only TATR is enable in LCCG-H
- state-of-the-art: HATS, Minnow, PHI

Evaluation: Overall Performance
LCCG-S outperforms Ligra-M slightly.
LCCG-S incurs high bookkeeping cost,
which impedes its overall efficiency.
LCCG-H improves the throughput by
11.3∼23.9 times over Ligra-M.
Normalized execution time
Memory accesses breakdown
Through regularized graph traversal and
memory shared, both LCCG-S and LCCG-H
significantly reduce the memory accesses.
LCCG-H reduces the accesses to memory by
82.3% compared to Ligra-M
• Comparison with Software Approaches

Evaluation: Overall Performance
• Comparison with Hardware Accelerators
LCCG-H improves the throughput of HATS,
Minnow, and PHI by 4.7 ~ 10.3, 5.5 ~ 13.2,
and 3.8 ~ 8.4 times
Normalized execution time
Main Memory accesses
Less memory traffic is generated by LCCG-
H for handling multiple jobs compared to
three state-of-the-art hardware accelerators
(HATS, Minnow, and PHI ).

• Background and Challenges
• Locality-centric Accelerator
• Hardware Design
• Experimental Results
• Conclusion
Outline

Conclusion
➢What LCCG brings for Graph Processing?
• Regularizing the graph traversals
• Consolidating the storage and accesses of the graph data
• A locality-centric programmable accelerator LCCG
• Minimize the data access cost for the execution of the CGP jobs and also achieve higher utilization of the cores
➢ Future work
• How to integrate some existing hardware techniques into LCCG to get better performance
• How to avoid the leaking of some private information of the jobs for the LCCG

THANK YOU!
Service Computing Technology and System Lab., MoE (SCTS)
Cluster and Grid Computing Lab., Hubei Province (CGCL)









![IN THE SUPREME COURT OF NEW ZEALAND SC 19/2005 …img.scoop.co.nz/media/pdfs/0609/SC_19_2005_Chambe… · · 2006-09-10IN THE SUPREME COURT OF NEW ZEALAND SC 19/2005 [2006] NZSC](https://static.fdocuments.us/doc/165x107/5aee06c07f8b9a662590c36a/in-the-supreme-court-of-new-zealand-sc-192005-imgscoopconzmediapdfs0609sc192005chambe2006-09-10in.jpg)








