
Goal Support “green field” profiling by providing a browsable, uniform representation of all...
54
-
Upload
cora-atkinson -
Category
Documents
-
view
214 -
download
0
Transcript of Goal Support “green field” profiling by providing a browsable, uniform representation of all...
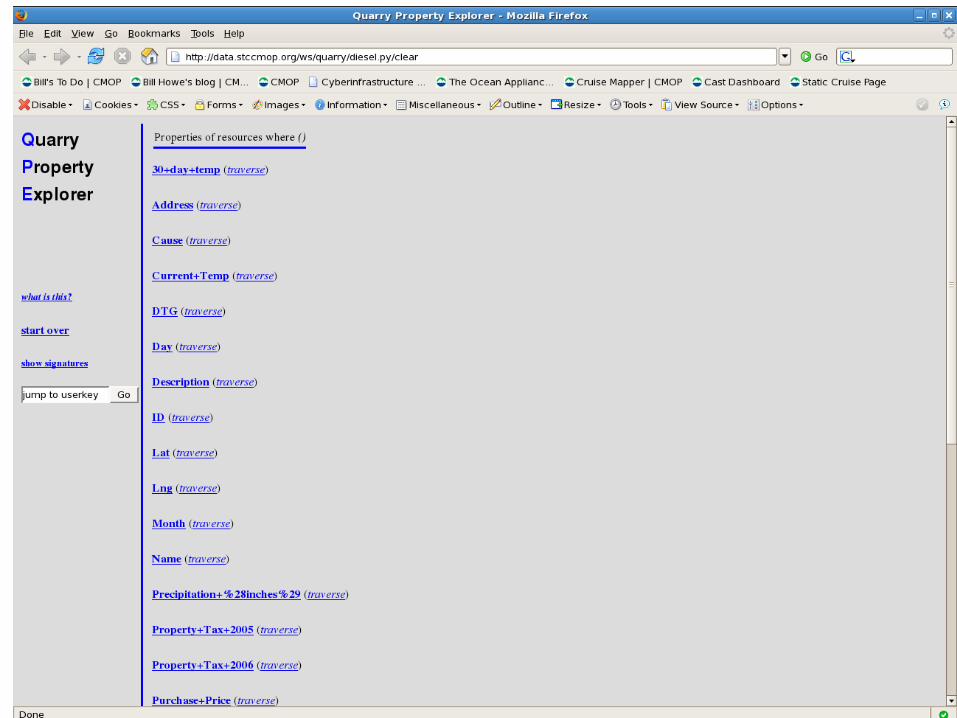


Goal
Support “green field” profiling by providing a browsable, uniform representation
of all data
Strategy
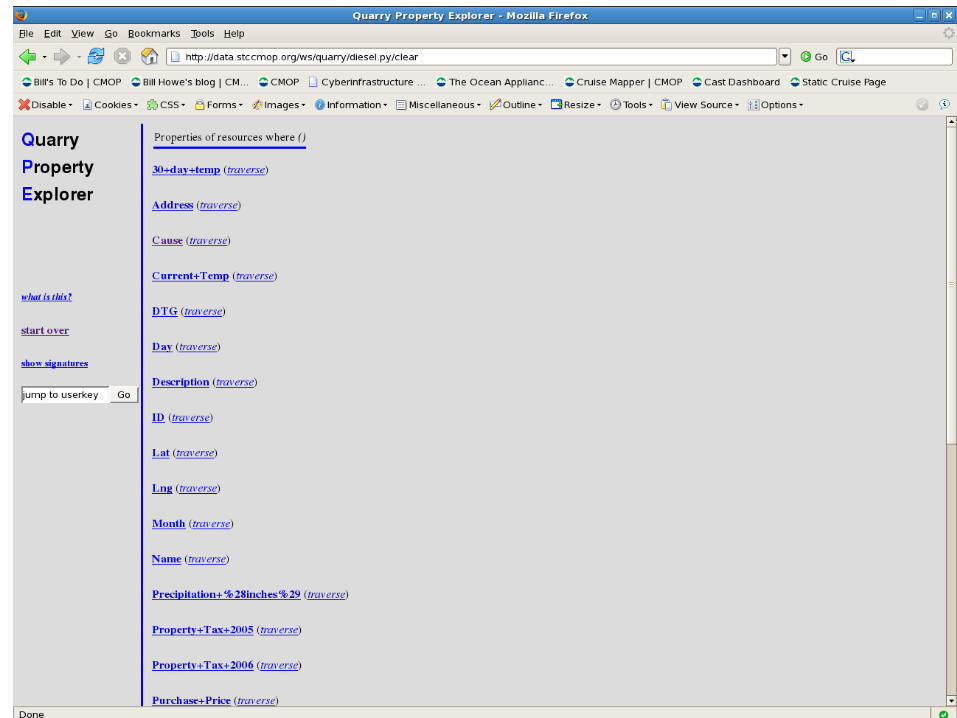
Shred any source automatically using heuristics, conventions
Output is a set of <resource, property, value> triples (near-RDF)
Automatically ingest, cluster, and index these triples
Worry about coverage/completeness, but not cleanliness or semantics (yet)

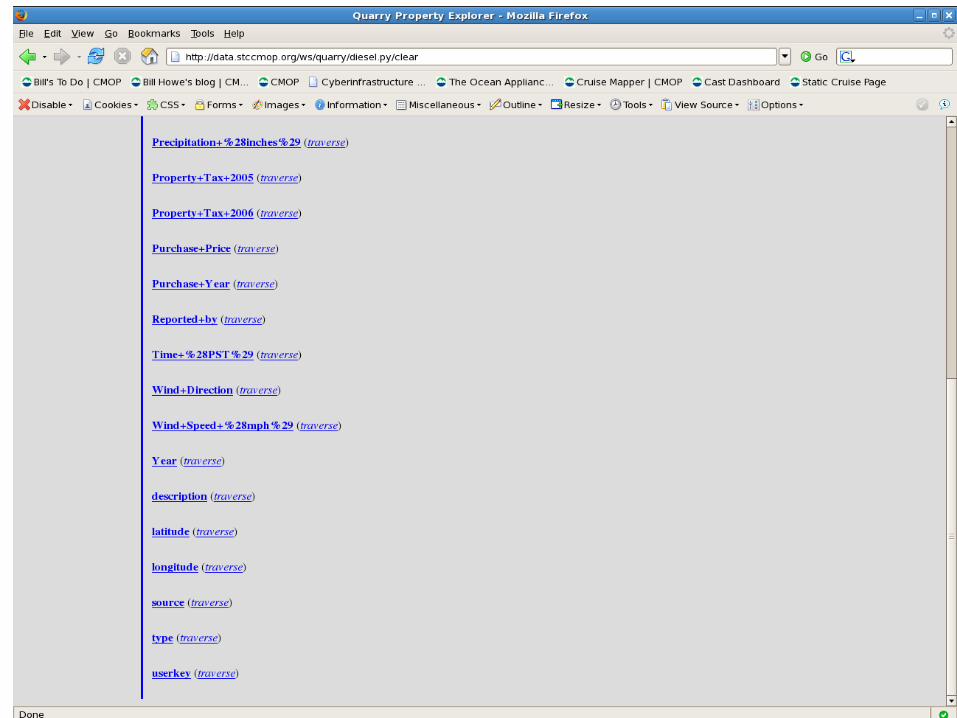
Shred "tabular" XML as <nodeid, tag, value>
Examples:
<current_events.xml.1002, longitude, -117.68>
<current_events.xml.1002, latitude, 33.68>
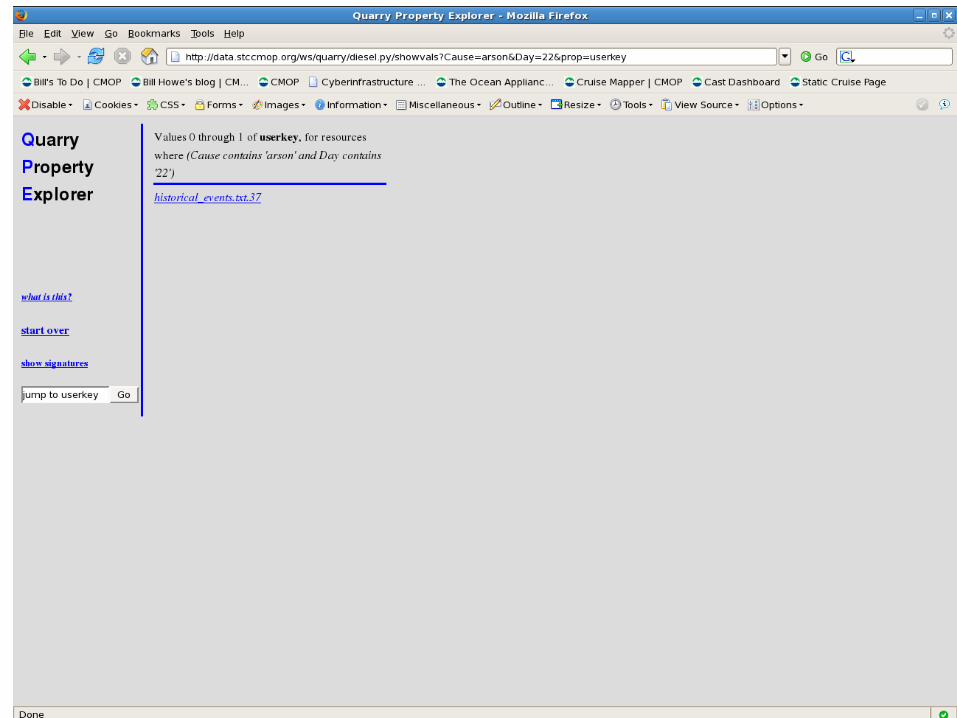
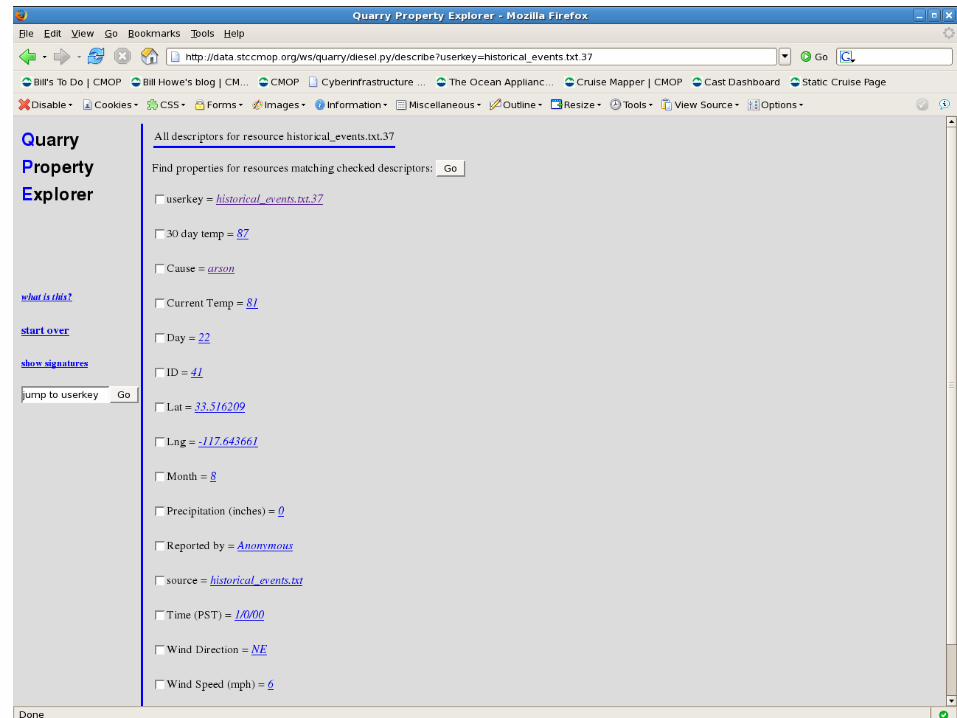
Shred text records as <recordid, attribute, value>
Examples:
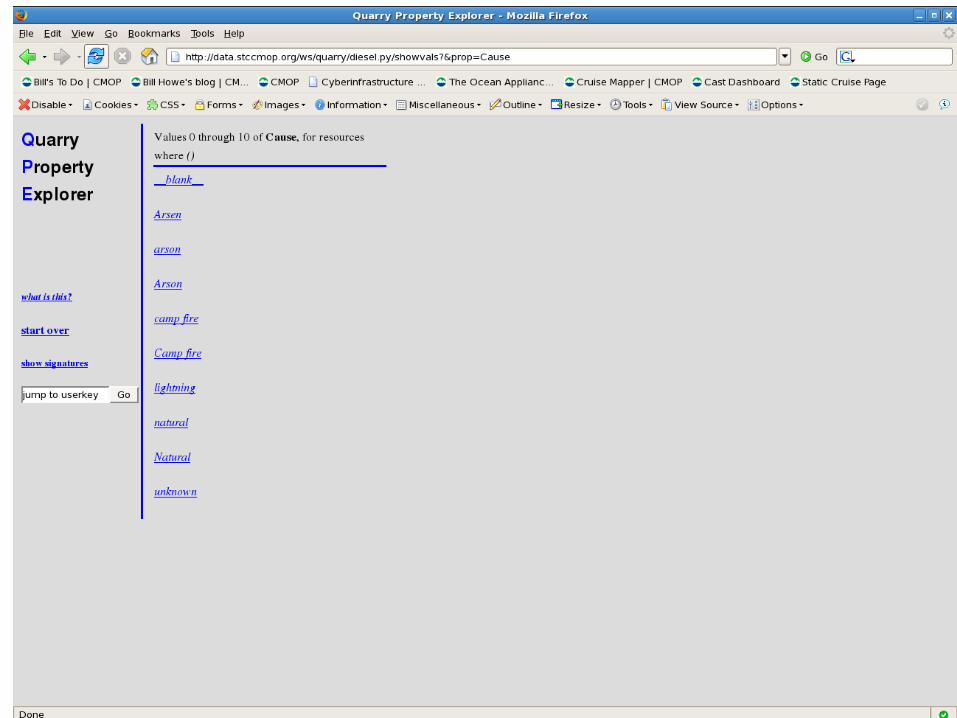
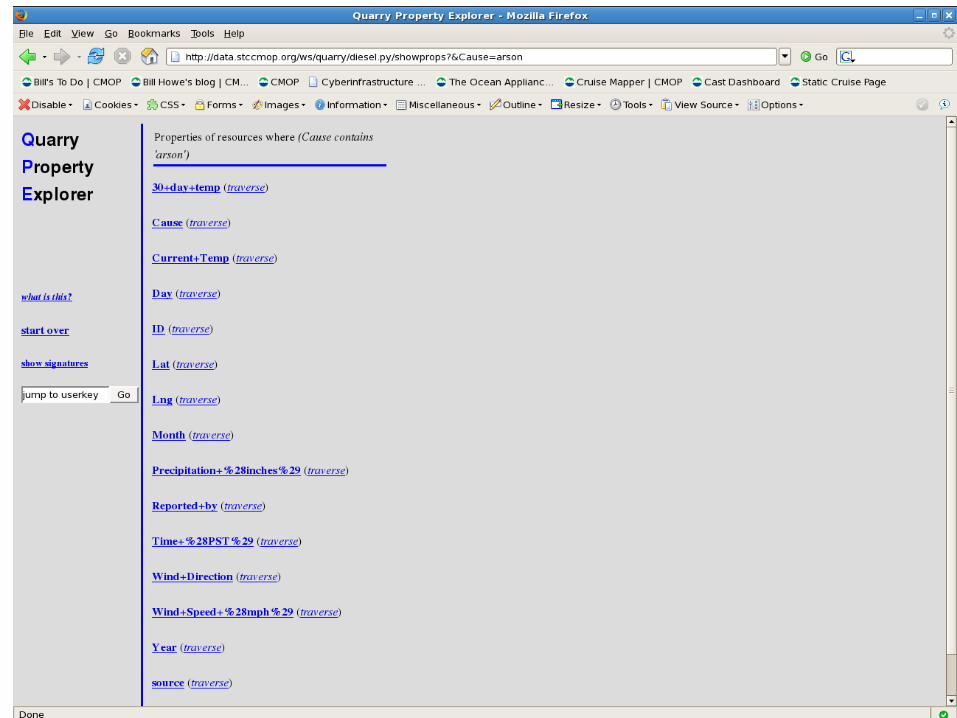
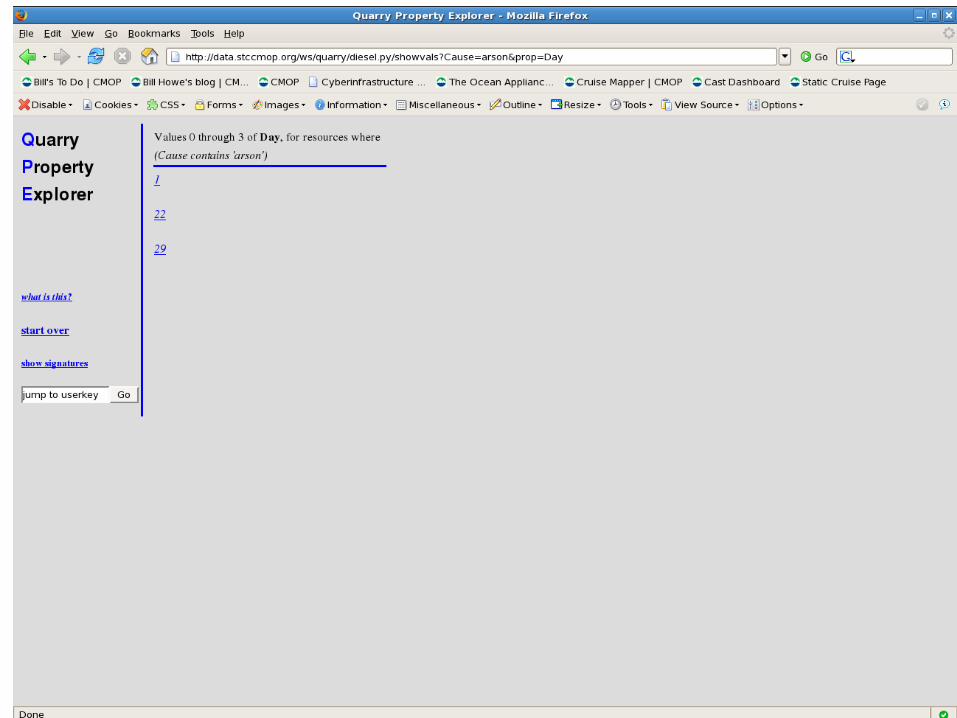
<historical_events.txt.37, Cause, arson>
<historical_events.txt.37, Reported by,
anonymous>
<People_info.txt.3, Name, Jack Smith>
<People_info.txt.3, Property Tax 2005, $6,200.00>

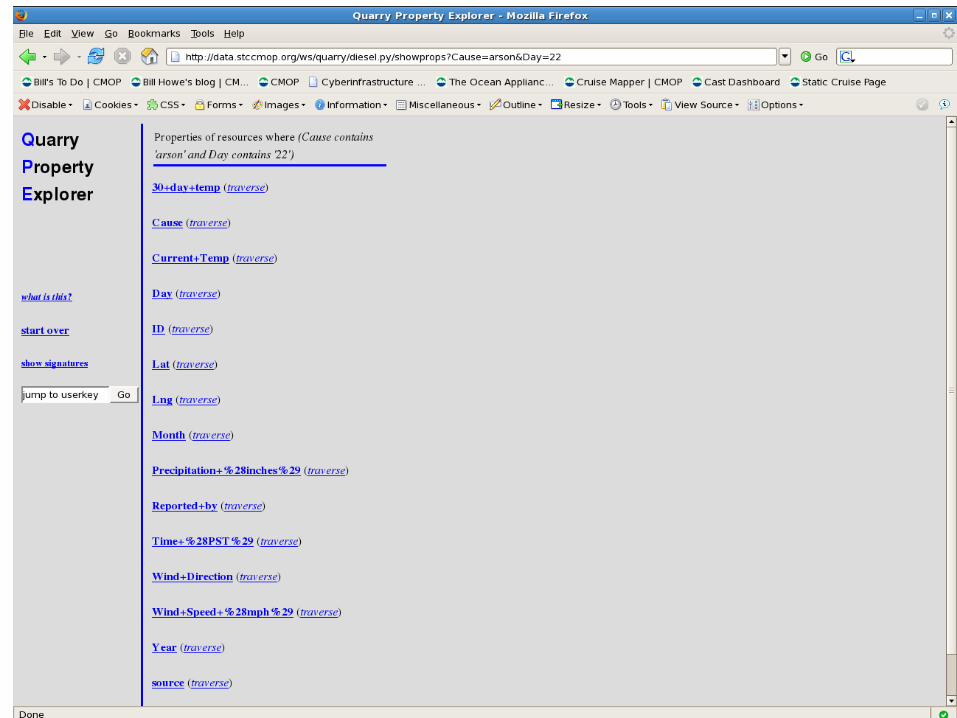
What can we do with the shredded data?
• Browse Online– Interactive performance required
• Query – Simple API for rapid app development -- not full SPARQL
• Customize– Add, modify, clean the metadata
• Do Stuff– Interact with the outside world with Behaviors

Customization
• Add a property to a set of resources
• Collapse a path
• (not yet available)

Behaviors
• Browse to the set of resources you're interested, then do something with them
– "Draw a map of all those resources that have a latitude and longitude"
– "For each resource that has an email address, send a message"
– "Draw a plot of all resources that have an 'x' property and a 'y' property"
– "Export the current set of resources to Excel/MS Access/Postgresql"
• In General:
– Call f(r) for each resource r in the working set that express properties p0, p1, ...,
– Call g(R) on the set of resources R in the working set that express properties p0, p1, ...,
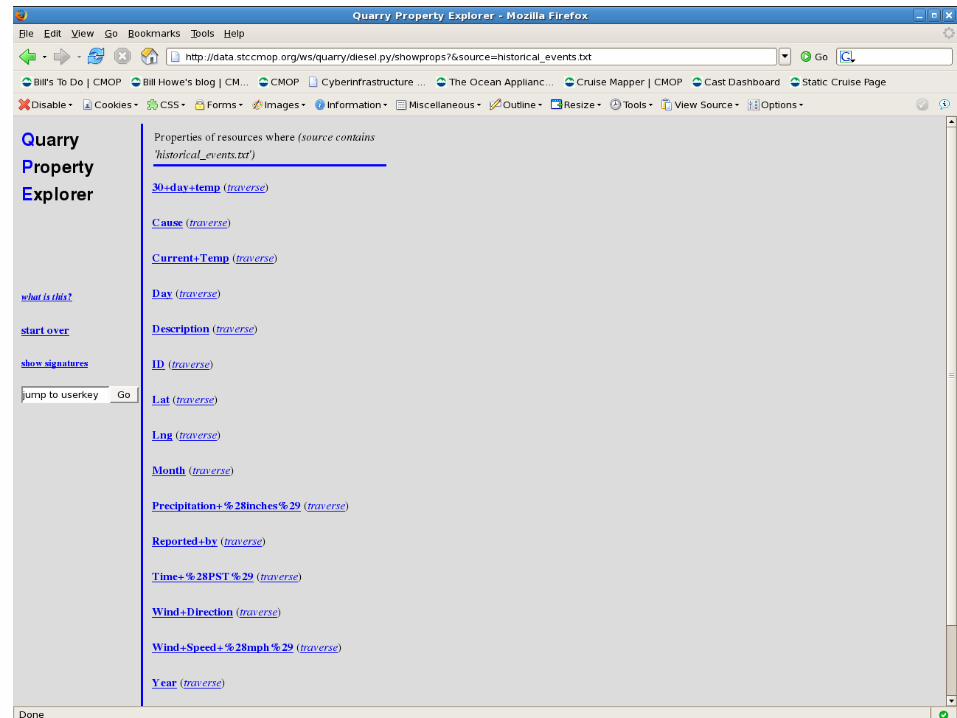
Back to the “source” property
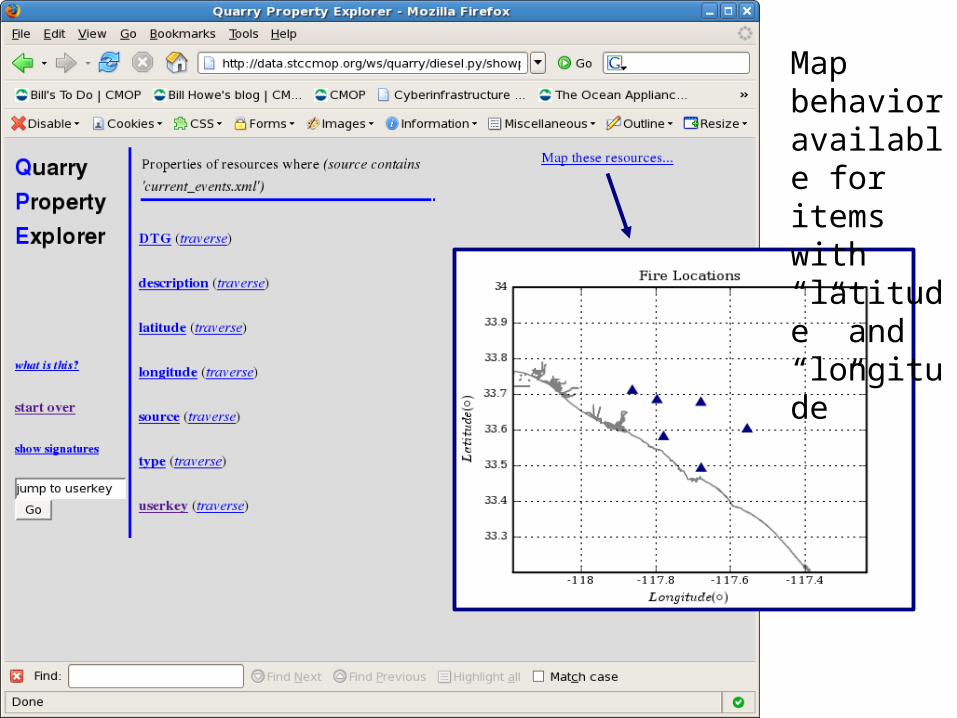
Map behavior available for items with “latitude” and “longitude”
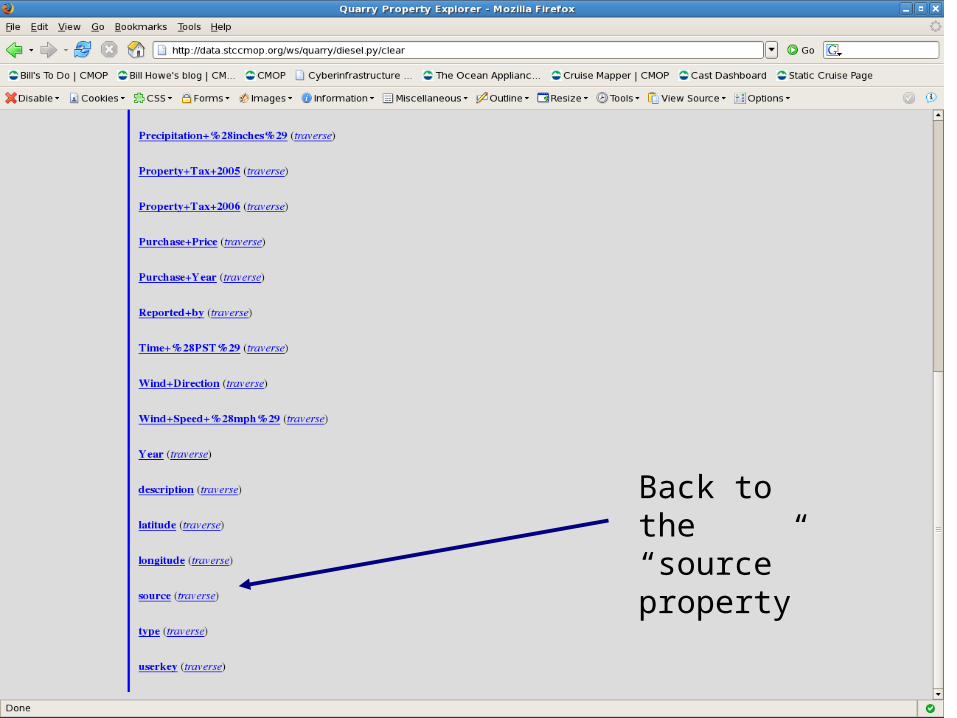
Back to the “source” property
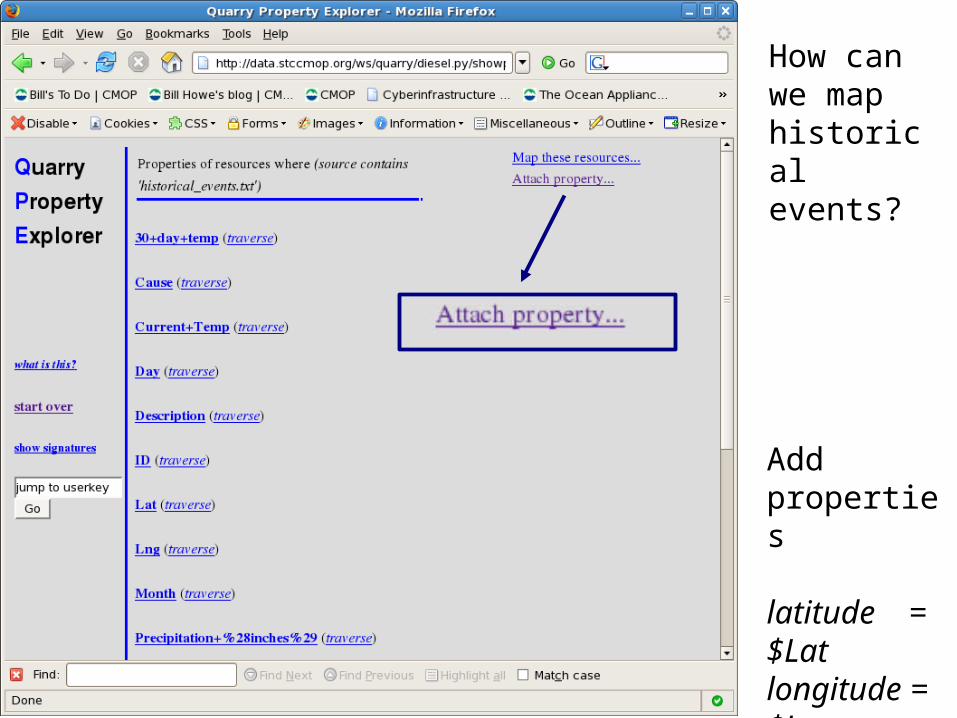
How can we map historical events?
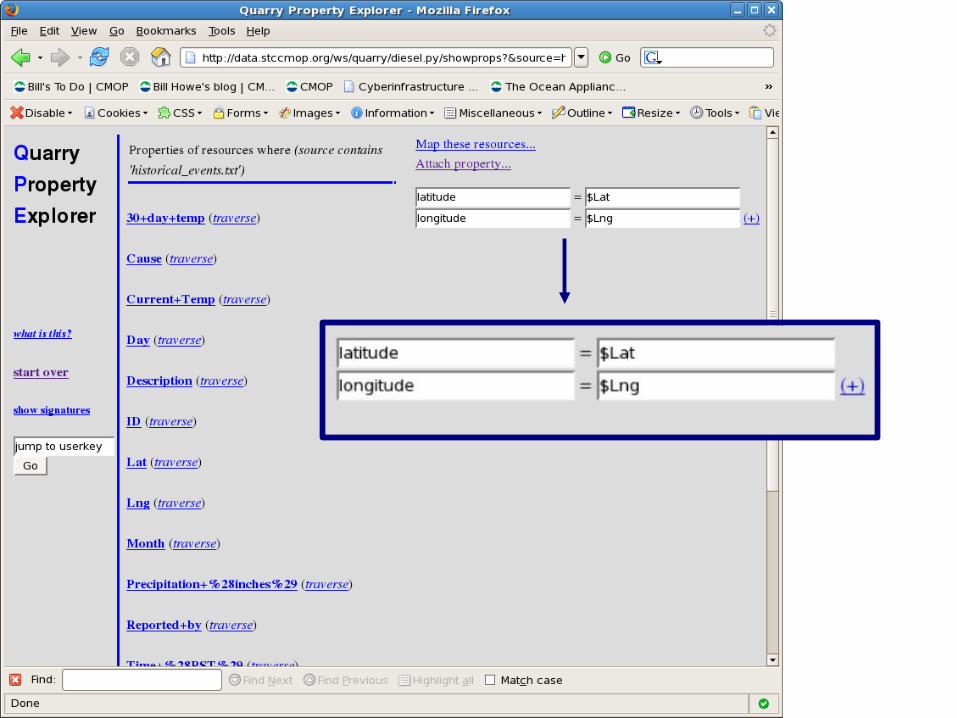
Add properties
latitude = $Latlongitude = $Lng
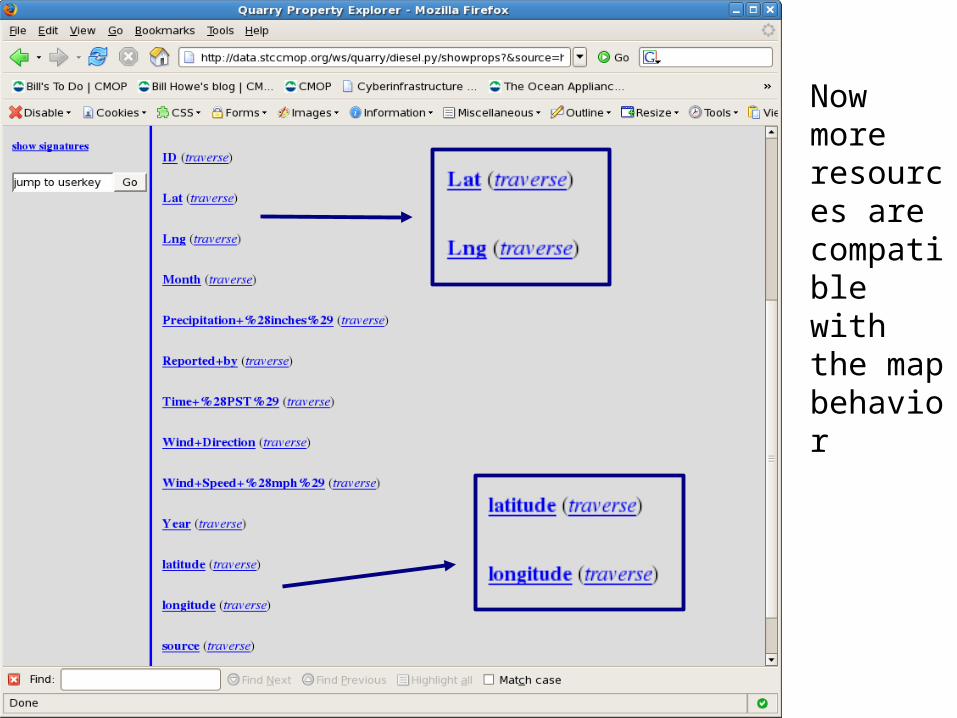
Now more resources are compatible with the map behavior
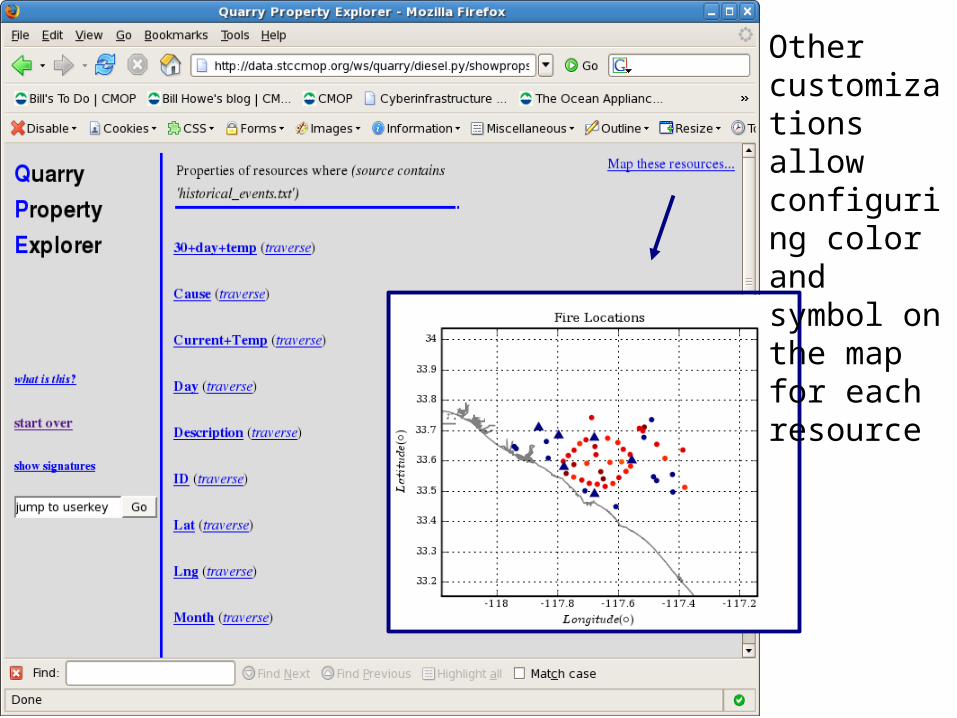
Other customizations allow configuring color and symbol on the map for each resource
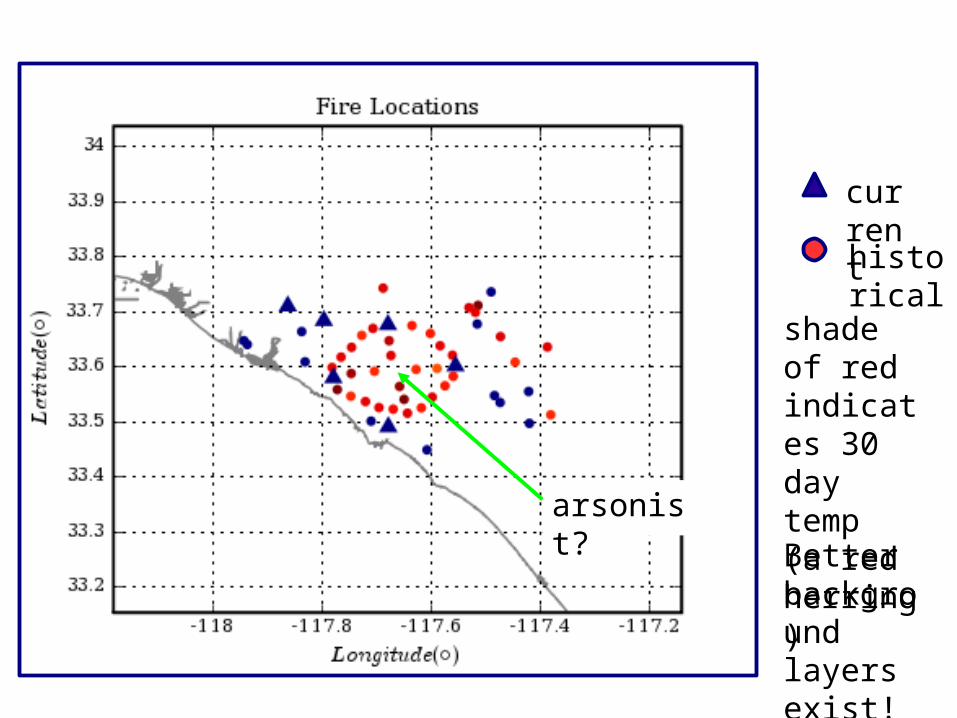
currenthistorical
shade of red indicates 30 day temp (a red herring)
arsonist?
Better background layers exist!


Profiling with InfoSonde
• User proposes candidate property, such as FD or partitioning predicates
• System tests hypothesis– Confirmed: offers appropriate structural
enhancement– Disconfirmed: displays violations, offers cleaning
options

Example: FD-based Normalization
• current_events.xml first converted to relation (eventType, DTG, latitude, longitude, description)
• eventType appears to use a controlled vocabulary
• InfoSonde verifies DTG → eventType
• However, DTG is also a key
• Instead of normalization, InfoSonde offers to create an index

Enhancing Current Events Data
• Candidate property: fire descriptions include the place of origin, size, and damage estimate in a delimited string
eventType in (‘Fire’, ‘WildFire’) ↔ description like ‘Fire started at *;* Acres;* Destroyed’
• Enhancement: promote substructure to schema
• Expected result: geocoding place names allows mapping origins along with current positions
• Unexpected result: apparent misalignment of provided descriptions for two most recent fires
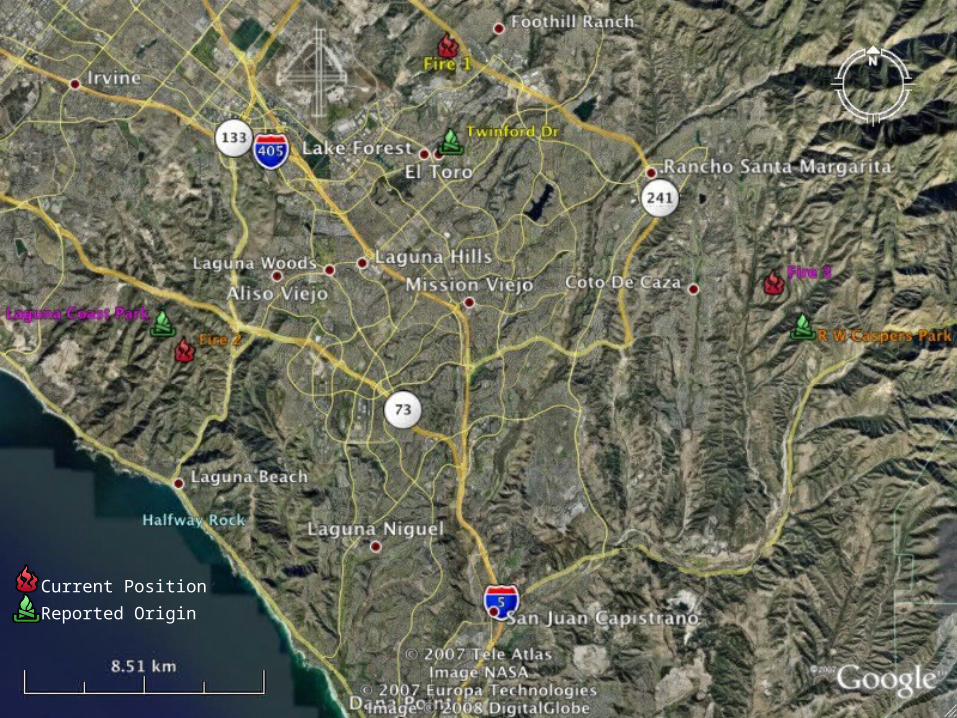
Current Position
Reported Origin
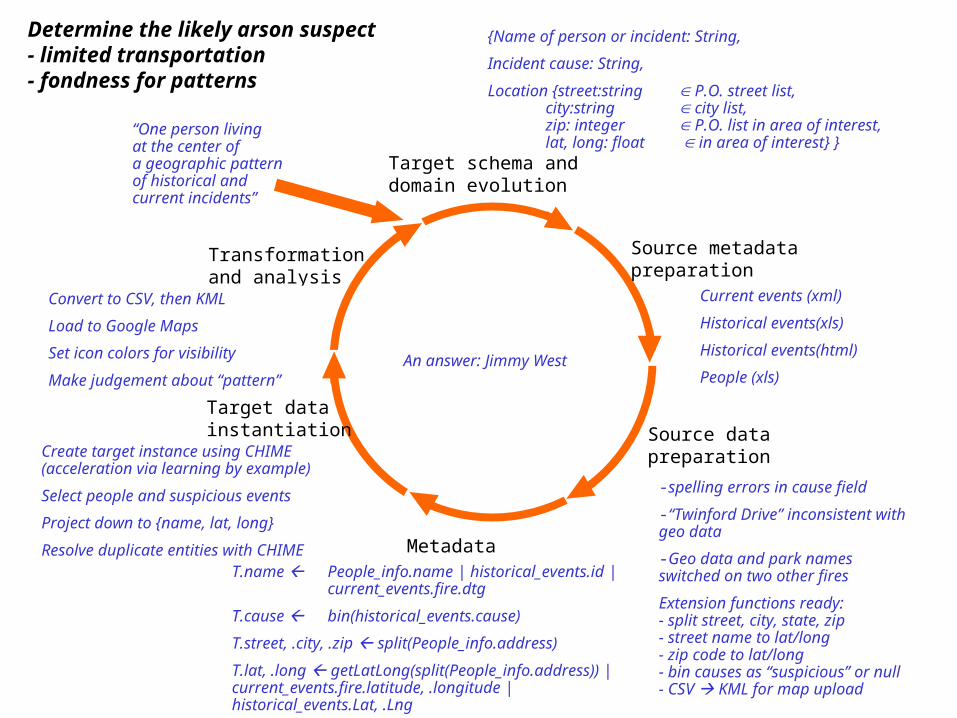
Target schema anddomain evolution
Source metadatapreparation
Source datapreparation
Metadata matching
Target datainstantiation
Transformationand analysis
Hypothesisformation
Determine the likely arson suspect- limited transportation- fondness for patterns
“One person livingat the center ofa geographic patternof historical and current incidents”
Guess a task-specificschema
{Name of person or incident: String,
Incident cause: String,
Location {street:string P.O. street list, city:string city list, zip: integer P.O. list in area of interest, lat, long: float in area of interest} }
Find sources to fill in target
Familiarization
Clarify semantics and domains
Current events (xml)
Historical events(xls)
Historical events(html)
People (xls)
Data assessment and profiling
Find or build extension functions
-spelling errors in cause field
-“Twinford Drive” inconsistent with geo data
-Geo data and park names switched on two other fires
Extension functions ready:- split street, city, state, zip- street name to lat/long- zip code to lat/long- bin causes as “suspicious” or null- CSV KML for map upload
Map source schemas to target
Fill in target relation, learning by exampleRemove extraneous data by projection De-duplicate entities & attributes
VisualizationMapping of “inexpressible” data Theory formulationVerificationIdentify missing pieces
T.name People_info.name | historical_events.id |
current_events.fire.dtg
T.cause bin(historical_events.cause)
T.street, .city, .zip split(People_info.address)
T.lat, .long getLatLong(split(People_info.address)) |current_events.fire.latitude, .longitude |historical_events.Lat, .Lng
Create target instance using CHIME(acceleration via learning by example)
Select people and suspicious events
Project down to {name, lat, long}
Resolve duplicate entities with CHIME
Convert to CSV, then KML
Load to Google Maps
Set icon colors for visibility
Make judgement about “pattern”
An answer: Jimmy West
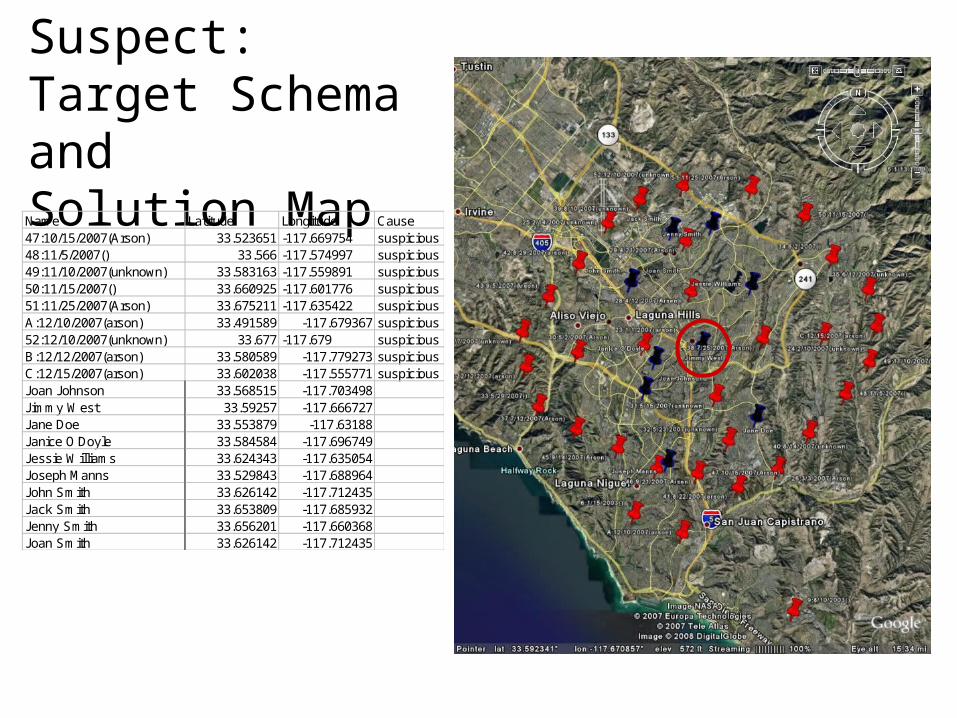
Arson Suspect:Target Schema andSolution MapName Latitude Longitude Cause47:10/15/2007(Arson) 33.523651 -117.669754 suspicious48:11/5/2007() 33.566 -117.574997 suspicious49:11/10/2007(unknown) 33.583163 -117.559891 suspicious50:11/15/2007() 33.660925 -117.601776 suspicious51:11/25/2007(Arson) 33.675211 -117.635422 suspiciousA:12/10/2007(arson) 33.491589 -117.679367 suspicious52:12/10/2007(unknown) 33.677 -117.679 suspiciousB:12/12/2007(arson) 33.580589 -117.779273 suspiciousC:12/15/2007(arson) 33.602038 -117.555771 suspiciousJoan Johnson 33.568515 -117.703498Jimmy West 33.59257 -117.666727Jane Doe 33.553879 -117.63188Janice O'Doyle 33.584584 -117.696749Jessie Williams 33.624343 -117.635054Joseph Manns 33.529843 -117.688964John Smith 33.626142 -117.712435Jack Smith 33.653809 -117.685932Jenny Smith 33.656201 -117.660368Joan Smith 33.626142 -117.712435
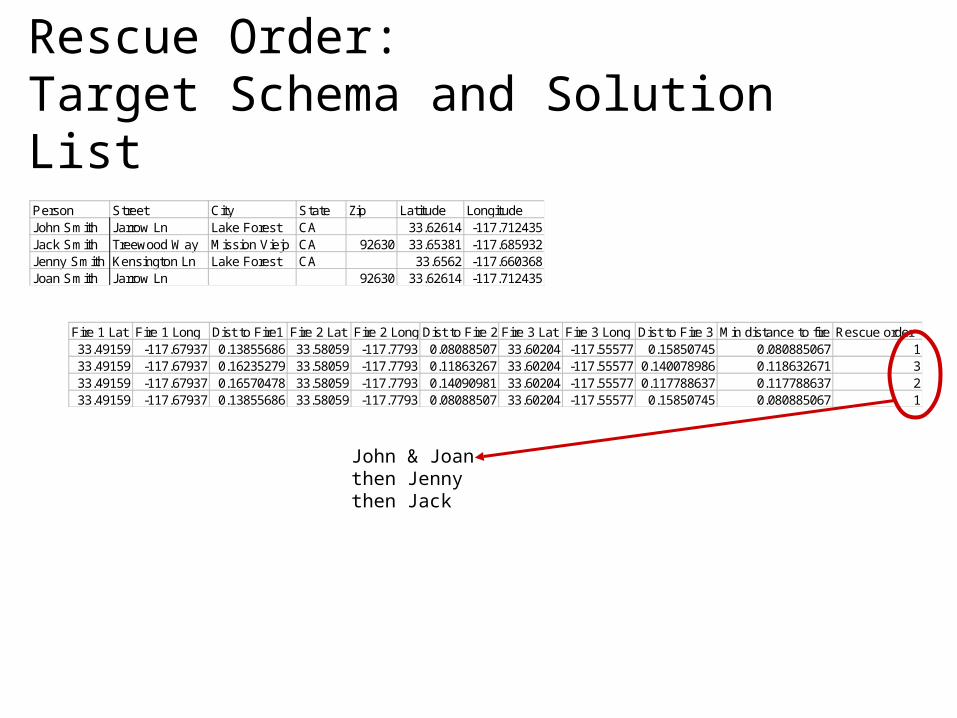
Rescue Order:Target Schema and Solution List
Person Street City State Zip Latitude LongitudeJohn Smith Jarrow Ln Lake Forest CA 33.62614 -117.712435Jack Smith Treewood Way Mission Viejo CA 92630 33.65381 -117.685932Jenny Smith Kensington Ln Lake Forest CA 33.6562 -117.660368Joan Smith Jarrow Ln 92630 33.62614 -117.712435
Fire 1 Lat Fire 1 Long Dist to Fire1 Fire 2 Lat Fire 2 Long Dist to Fire 2 Fire 3 Lat Fire 3 Long Dist to Fire 3 Min distance to fire Rescue order33.49159 -117.67937 0.13855686 33.58059 -117.7793 0.08088507 33.60204 -117.55577 0.15850745 0.080885067 133.49159 -117.67937 0.16235279 33.58059 -117.7793 0.11863267 33.60204 -117.55577 0.140078986 0.118632671 333.49159 -117.67937 0.16570478 33.58059 -117.7793 0.14090981 33.60204 -117.55577 0.117788637 0.117788637 233.49159 -117.67937 0.13855686 33.58059 -117.7793 0.08088507 33.60204 -117.55577 0.15850745 0.080885067 1
John & Joanthen Jennythen Jack
Target schema anddomain evolution
Source metadatapreparation
Source datapreparation
Metadata matching
Target datainstantiation
Transformationand analysis
Hypothesisformation
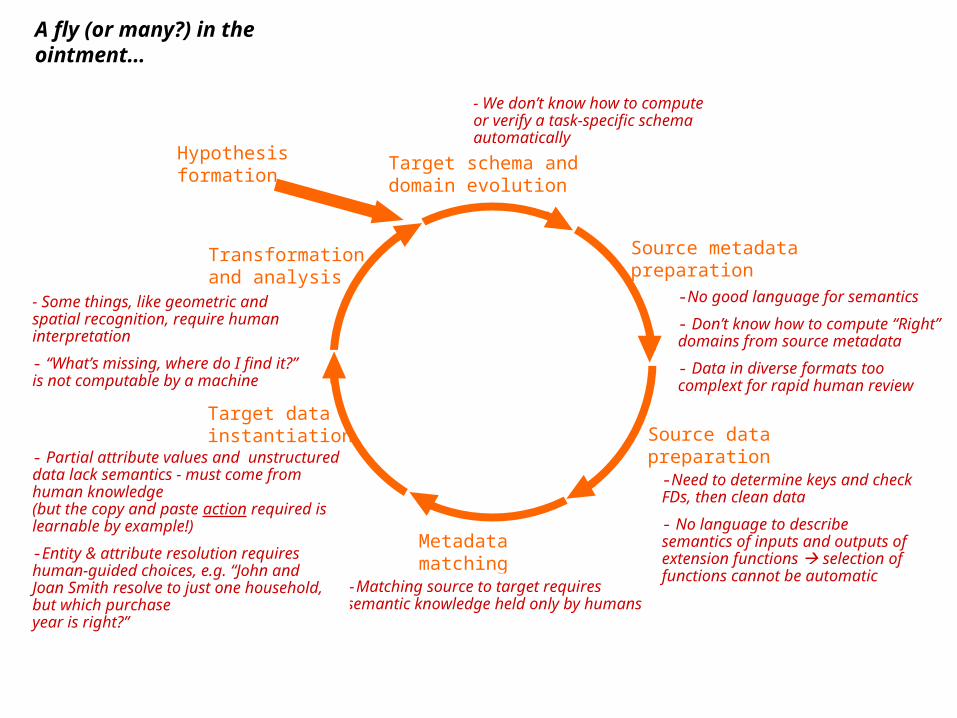
A fly (or many?) in the ointment…
Guess a task-specificschema
- We don’t know how to computeor verify a task-specific schemaautomatically
Find sources to fill in target
Familiarization
Clarify semantics and domains
Data assessment and profiling
Find or build extension functions
Map source schemas to target
Fill in target relation, learning by exampleRemove extraneous data by projection De-duplicate entities & attributes
VisualizationMapping of “inexpressible” data Theory formulationVerificationIdentify missing pieces
-Matching source to target requiressemantic knowledge held only by humans
- Partial attribute values and unstructured data lack semantics - must come from human knowledge(but the copy and paste action required is learnable by example!)
-Entity & attribute resolution requires human-guided choices, e.g. “John andJoan Smith resolve to just one household, but which purchaseyear is right?”
- Some things, like geometric and spatial recognition, require human interpretation
- “What’s missing, where do I find it?” is not computable by a machine
-No good language for semantics
- Don’t know how to compute “Right” domains from source metadata
- Data in diverse formats too complext for rapid human review
-Need to determine keys and check FDs, then clean data
- No language to describe semantics of inputs and outputs of extension functions selection of functions cannot be automatic

• Our approach:– Assist users in
• data familiarization• data assessment and profiling• Mapping• entity/attribute resolution
– Let human judgment make the call– Accelerate human effort via “learn-by-example”
• Our integration research projects– Quarry– Infosonde– CHIME

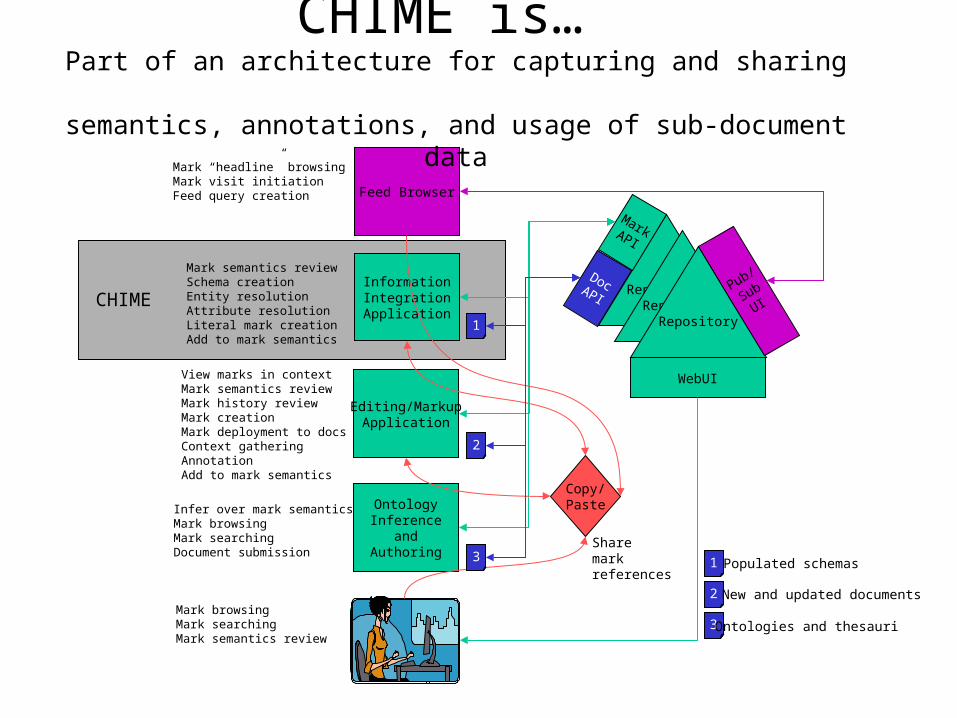
CHIME is…an information integration application to capture
evolving human knowledge about task-specific data
• Evolving task-specific schema and entity sets
• Mapping diverse data to correct attributes and entities
• Learning by example to speed integration where possible
• Resolving entities and attributes, and recording user choices
• Navigating and revising the history of integration decisions made in a dataset
InformationIntegrationApplication
RepositoryRepository
Repository
Pub/
SubUI
MarkAPI
WebUI
Editing/MarkupApplication
Feed Browser
OntologyInference
andAuthoring
Mark semantics reviewSchema creationEntity resolutionAttribute resolutionLiteral mark creationAdd to mark semantics
Copy/Paste
Mark “headline” browsingMark visit initiationFeed query creation
View marks in contextMark semantics reviewMark history reviewMark creationMark deployment to docsContext gatheringAnnotationAdd to mark semantics
Infer over mark semanticsMark browsingMark searchingDocument submission
1
2
3
3
2
1 Populated schemas
New and updated documents
Ontologies and thesauriMark browsingMark searchingMark semantics review
DocAPI
Sharemarkreferences
CHIME
CHIME is… Part of an architecture for capturing and sharing
semantics, annotations, and usage of sub-document data

Metrics
• Scale-up improvement• Scale-out improvement• % of target schema successfully integrated• % of identified user tasks automated or assisted• % of data discrepancies detected, corrected
automatically• “cold-start” to “warm-start” time-to-solution ratio

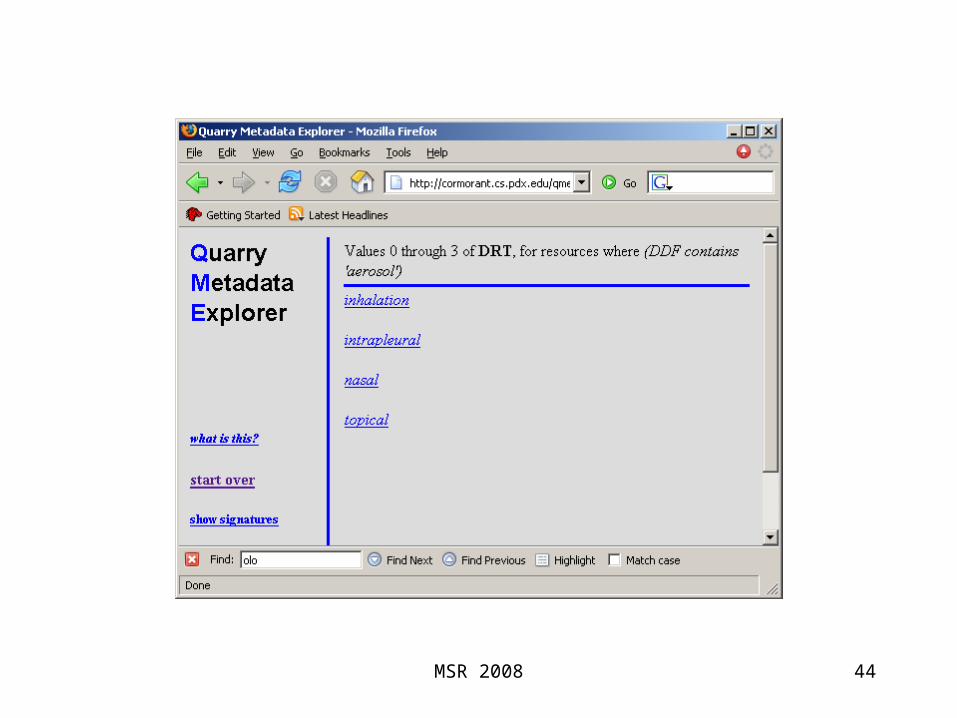
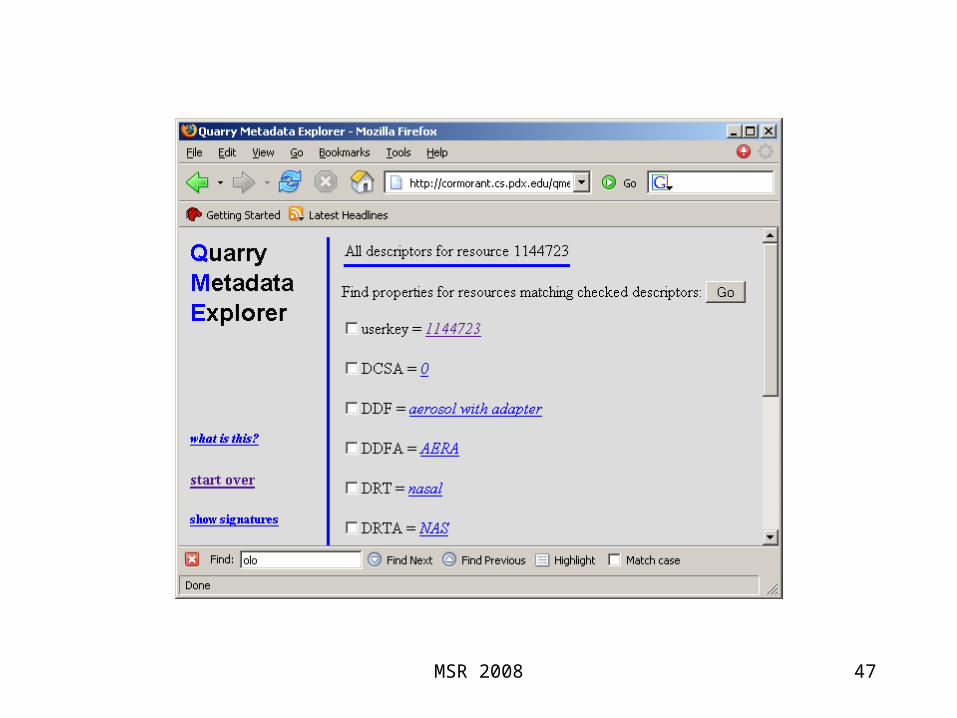
Quarry Data Model
• resource, property, value– (subject, predicate, object) if you prefer
• no intrinsic distinction between literal values and resource values
• no explicit types or classes
38MSR 2008
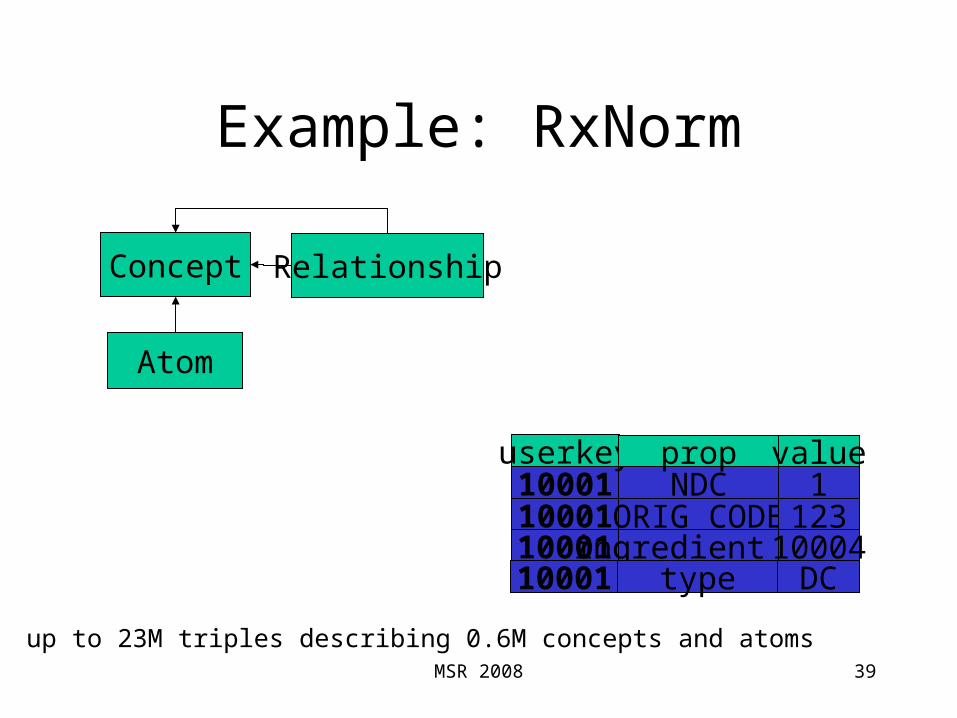
Example: RxNorm
39
Concept
Atom
Relationship
up to 23M triples describing 0.6M concepts and atoms
10001 NDC 110001ORIG_CODE 123
userkey prop value
10001 ingredient_of1000410001 type DC
MSR 2008

Example: Metadata for Scientific Data Repository
40
7.5M triples describing 1M files
…/anim-sal_estuary_7.gifdepth 7…/anim-sal_estuary_7.gifvariable salt
path prop value
…/anim-sal_estuary_7.gifregionestuary…/anim-sal_estuary_7.giftype anim
Region = “Estuary”
Variable = “Salinity”
Type = “Animation”
Depth = “7”
…/anim-sal_estuary_7.gif
MSR 2008
41SKIP MSR 2008
42MSR 2008
43MSR 2008
44MSR 2008

45MSR 2008

46MSR 2008
47MSR 2008

48MSR 2008
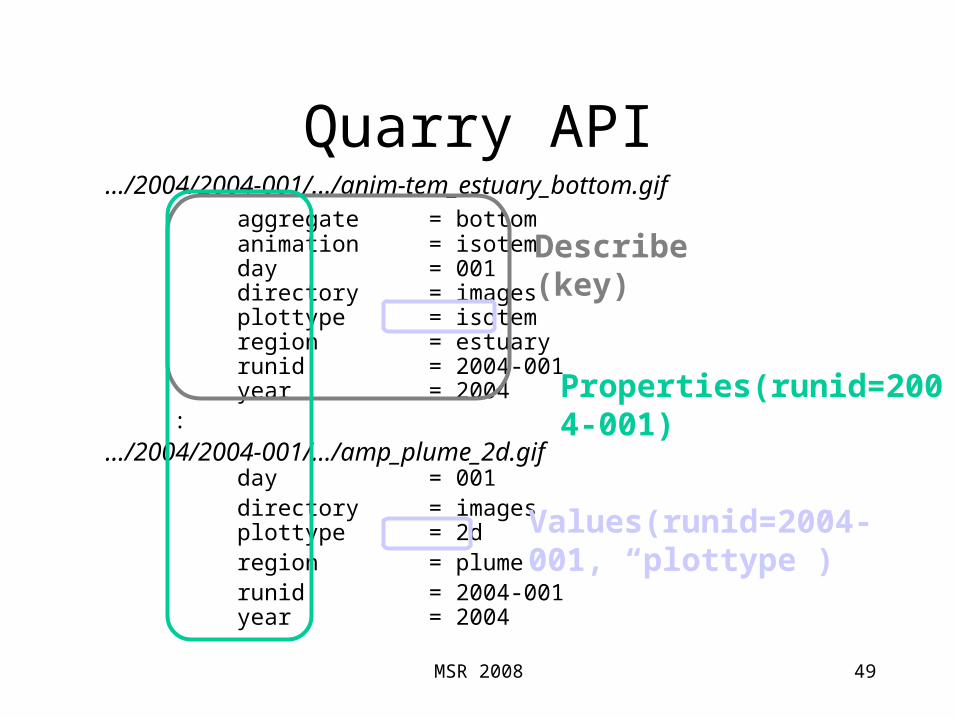
Quarry API
49
…/2004/2004-001/…/anim-tem_estuary_bottom.gifaggregate = bottomanimation = isotemday = 001directory = imagesplottype = isotemregion = estuaryrunid = 2004-001year = 2004
:
…/2004/2004-001/…/amp_plume_2d.gifday = 001directory = imagesplottype = 2dregion = plumerunid = 2004-001year = 2004
Describe(key)
Values(runid=2004-001, “plottype”)
Properties(runid=2004-001)
MSR 2008

API Clients
Applications use sequences of Prop and Val calls to explore the Dataspace
50
runidyearweekregion | plume | far | surface runid year | 2003 | 2004 | 2005 show products… week region | estuaryplottypevariable
region
year
| surface
MSR 2008

Behind the Scenes
Signatures– resources possessing the same properties
clustered together
– Posit that |Signatures| << |Resources|
– Queries evaluated over Signature Extents
51MSR 2008

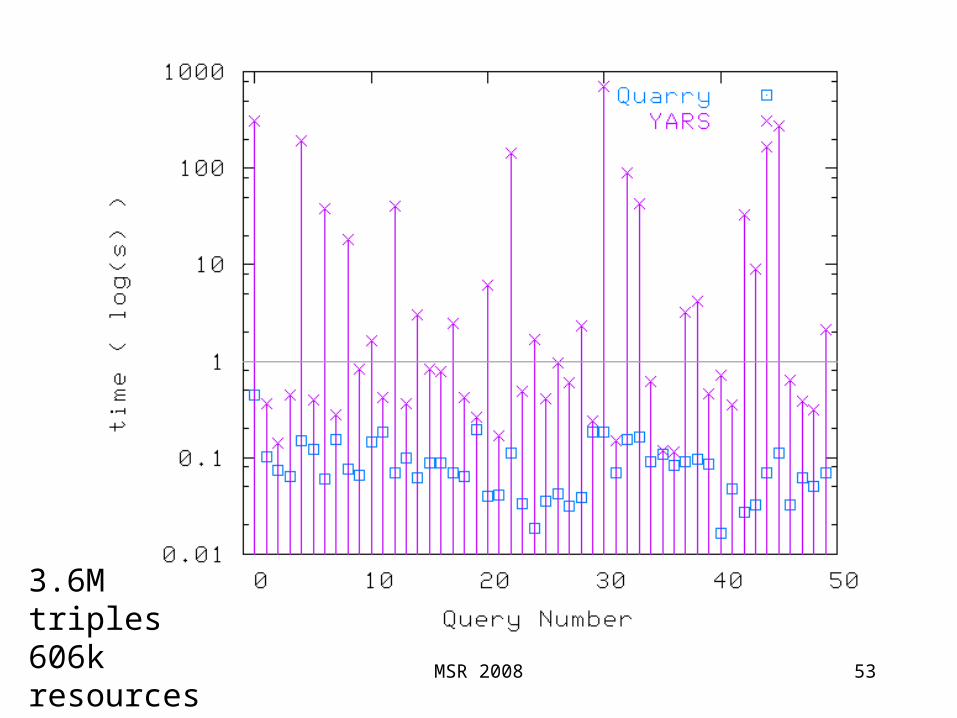
Experimental Results
• Yet Another RDF StoreSeveral B-Tree indexes to support
• spo, po s, os p, etc.
• ~3M triples
• We looked at multi-term queries
52
?s <p0> <o0>?s <p1> <o1>:?s <pn> <on>
MSR 2008
Experimental Results: Queries
53
3.6M triples606k resources149 signatures MSR 2008

Hands-off Operation
Feed it triples– Calculates signatures– Computes signature extents
Working on incremental facility for insertions– Resource can change signatures– New signatures can be created
API doesn’t name tables
54MSR 2008


















