
Goal-Directed Feature Learning Cornelius Weber and Jochen Triesch
21
Goal-Directed Feature Learning Cornelius Weber and Jochen Triesch Frankfurt Institute for Advanced Studies (FIAS) IJCNN, Atlanta, 17 th June 2009
-
Upload
ardelle-york -
Category
Documents
-
view
18 -
download
0
description
Goal-Directed Feature Learning Cornelius Weber and Jochen Triesch Frankfurt Institute for Advanced Studies (FIAS) IJCNN, Atlanta, 17 th June 2009. for taking action, we need only the relevant features. y. z. x. unsupervised learning in cortex. actor. state space. reinforcement - PowerPoint PPT Presentation
Transcript of Goal-Directed Feature Learning Cornelius Weber and Jochen Triesch

Goal-Directed Feature Learning
Cornelius Weber and Jochen Triesch
Frankfurt Institute for Advanced Studies (FIAS)
IJCNN, Atlanta, 17th June 2009
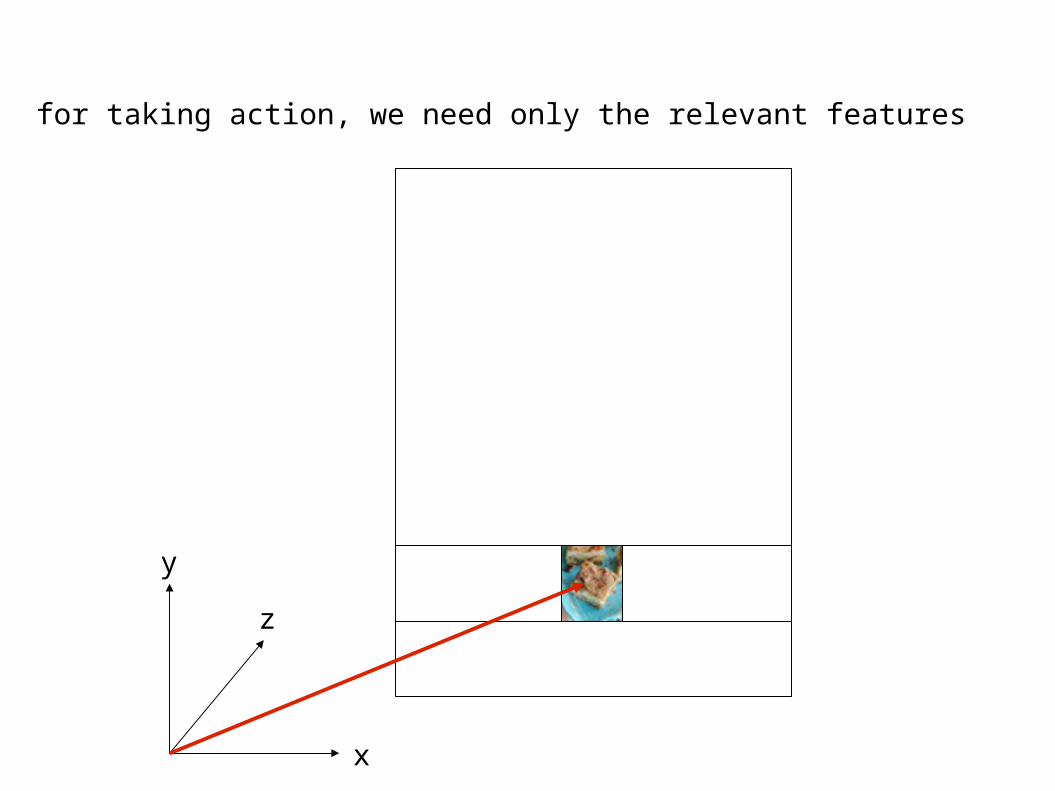
for taking action, we need only the relevant features
x
y
z
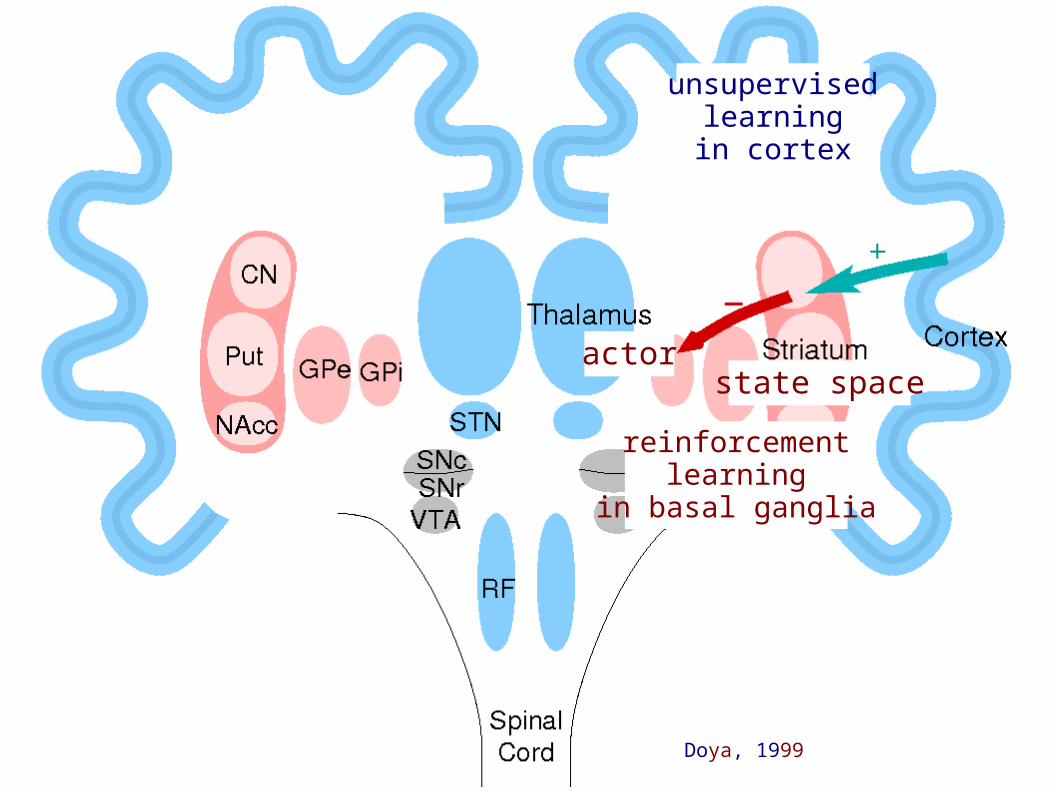
unsupervisedlearningin cortex
reinforcementlearning
in basal ganglia
state spaceactor
Doya, 1999
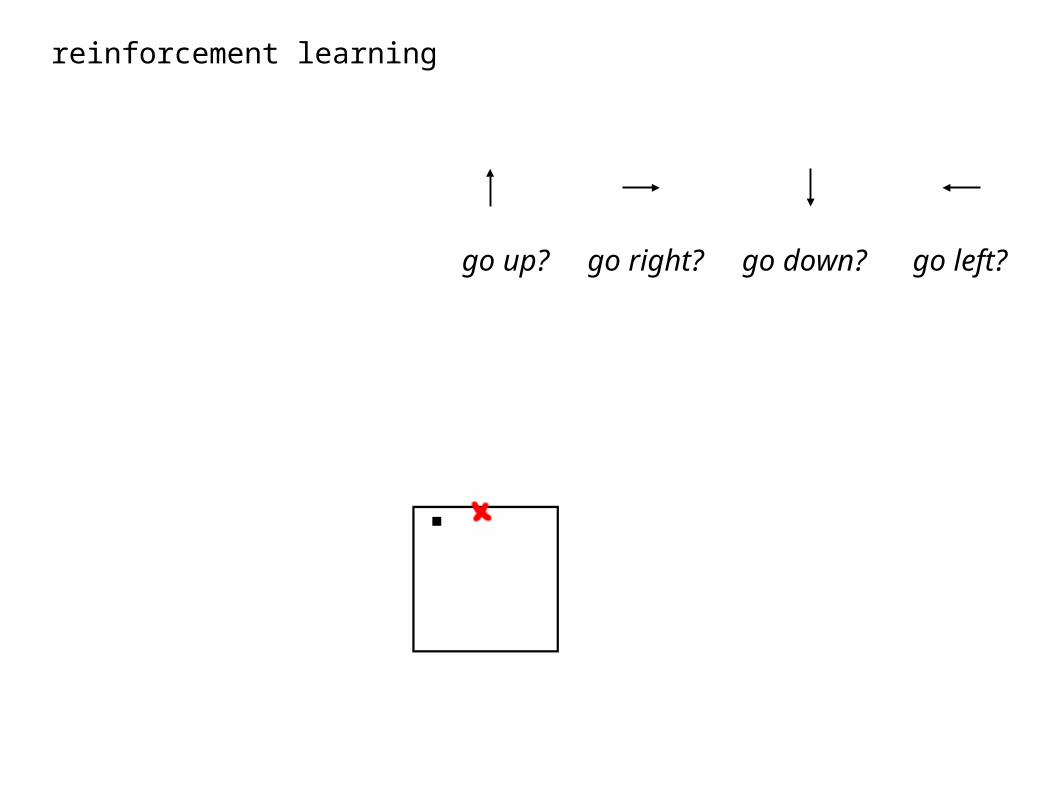
reinforcement learning
go up? go right? go down? go left?

reinforcement learning
input s
action a
weights

action a
reinforcement learning
minimizing value estimation error:
d v(s,a) ≈ 0.9 v(s’,a’) - v(s,a)
d v(s,a) ≈ 1 - v(s,a)
moving target value
fixed at goal
v(s,a) value of a state-action pair(coded in the weights)
repeated running to goal:
in state s, agent performsbest action a (with random),yielding s’ and a’
--> values and action choices converge
input s
weights

actor
go right? go left?
can’t handle this!
simple input
go right!
complex input
reinforcement learning
input (state space)

sensory input
reward
action
complex input
scenario: bars controlled by actions, ‘up’, ‘down’, ‘left’, ‘right’;
reward given if horizontal bar at specific position

need another layer(s) to pre-process complex data
feature detection
action selection
network definition:
s = softmax(W I)P(a=1) = softmax(Q s)
v = a Q s
a action
s state
I input
Q weight matrix
W weight matrix
position of relevant bar
encodes v
feature detector
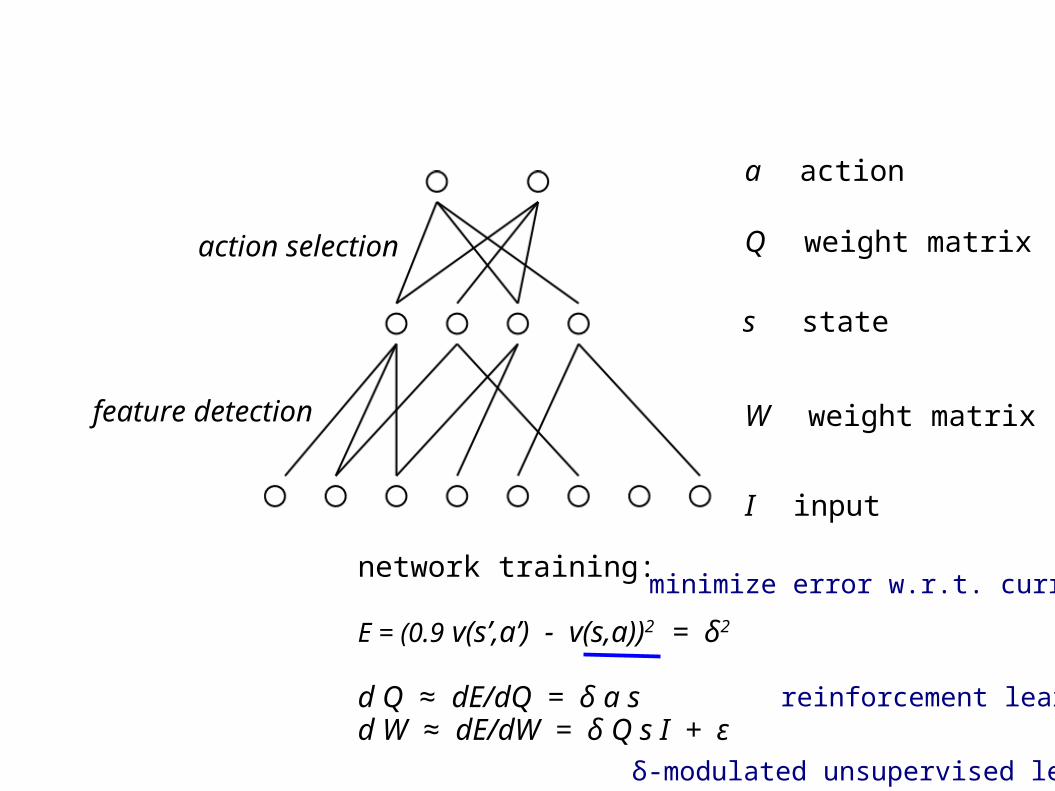
feature detection
action selection
network training:
E = (0.9 v(s’,a’) - v(s,a))2 = δ2
d Q ≈ dE/dQ = δ a sd W ≈ dE/dW = δ Q s I + ε
a action
s state
I input
W weight matrix
minimize error w.r.t. current target
reinforcement learning
δ-modulated unsupervised learning
Q weight matrix

note: non-negativity constraint on weights
network training: minimize error w.r.t. target Vπ
identities used:

SARSA with WTA input layer

RL action weights
feature weights
data
learning the ‘short bars’ data
reward
action

short bars in 12x12 average # of steps to goal: 11

RL action weights
feature weights
input reward 2 actions (not shown)
data
learning ‘long bars’ data

WTAnon-negative weights
SoftMaxnon-negative weights
SoftMaxno weight constraints

models’ background:
- gradient descent methods generalize RL to several layers Sutton&Barto RL book (1998); Tesauro (1992;1995)
- reward-modulated Hebb Triesch, Neur Comp 19, 885-909 (2007), Roelfsema & Ooyen, Neur Comp 17, 2176-214 (2005); Franz & Triesch, ICDL (2007)
- reward-modulated activity leads to input selection Nakahara, Neur Comp 14, 819-44 (2002)
- reward-modulated STDP Izhikevich, Cereb Cortex 17, 2443-52 (2007), Florian, Neur Comp 19/6, 1468-502 (2007); Farries & Fairhall, Neurophysiol 98, 3648-65 (2007); ...
- RL models learn partitioning of input space e.g. McCallum, PhD Thesis, Rochester, NY, USA (1996)

Discussion
- two-layer SARSA RL performs gradient descent on value estimation error
- approximation with winner-take-all leads to local rule with δ-feedback
- learns only action-relevant features
- non-negative coding aids feature extraction
- link between unsupervised- and reinforcement learning
- demonstration with more realistic data still needed
Bernstein FocusNeurotechnology,BMBF grant 01GQ0840
EU project 231722“IM-CLeVeR”,call FP7-ICT-2007-3
Frankfurt Institutefor Advanced Studies,FIAS
Sponsors



Bernstein FocusNeurotechnology,BMBF grant 01GQ0840
EU project 231722“IM-CLeVeR”,call FP7-ICT-2007-3
Frankfurt Institutefor Advanced Studies,FIAS
Sponsors
thank you ...

















