
Geographically Distributed Multi-Master MySQL Clusters
29
© 2014 VMware Inc. All rights reserved. Geographically Distributed Multi-Master MySQL Clusters Featuring VMware Continuent Jeff Mace 2/10/2015
-
Upload
vmware-continuent -
Category
Technology
-
view
144 -
download
1
Transcript of Geographically Distributed Multi-Master MySQL Clusters

© 2014 VMware Inc. All rights reserved.
Geographically Distributed Multi-Master MySQL Clusters Featuring VMware Continuent
Jeff Mace 2/10/2015

VMware Continuent Quick Introduction History Products
VMware Continuent
Industry-leading clustering and replication for open source DBMS Clustering – Commercial-grade HA, performance scaling and data management for MySQL Replication – Flexible, high-performance data movement
2004 Continuent established in USA
2009 3rd Generation Continuent Tungsten (aka VMware Continuent) ships
2014 100+ customers running business critical applications
Oct 2014 Acquisition by VMware: Now part of the vCloud Air Business Unit
Oct 2015 Continuent solutions available through VMware sales

VMware Continuent Facts
Business Critical Deployment Examples High Availability for MySQL
Largest cluster deployment performs 800M+ transactions/day on 275 TB of relational data
Business Continuity Cross-site cluster topologies widely deployed including Primary/DR and Multi-Master
High Performance Replication
Largest installations transfer billions of transactions daily using high speed, parallel replication
Heterogeneous Integration
Customers replicate from MySQL to Oracle, Hadoop, Redshift, Vertica and others
Real-time Analytics Optimized data loading for data warehouses with deployments of up to 200 MySQL masters feeding Hadoop

Select VMware Continuent Customers

The Case For Many Sites

Registering and Updating Distributed Devices • There are many handheld and portable devices that move between
cities and regions.
• These devices need constant access to pull data or updates. • DNS routes the user to an available site with the lowest latency
• Each site has full access to modify data for the user
• Benefit: Transactions are always processed at the fastest location
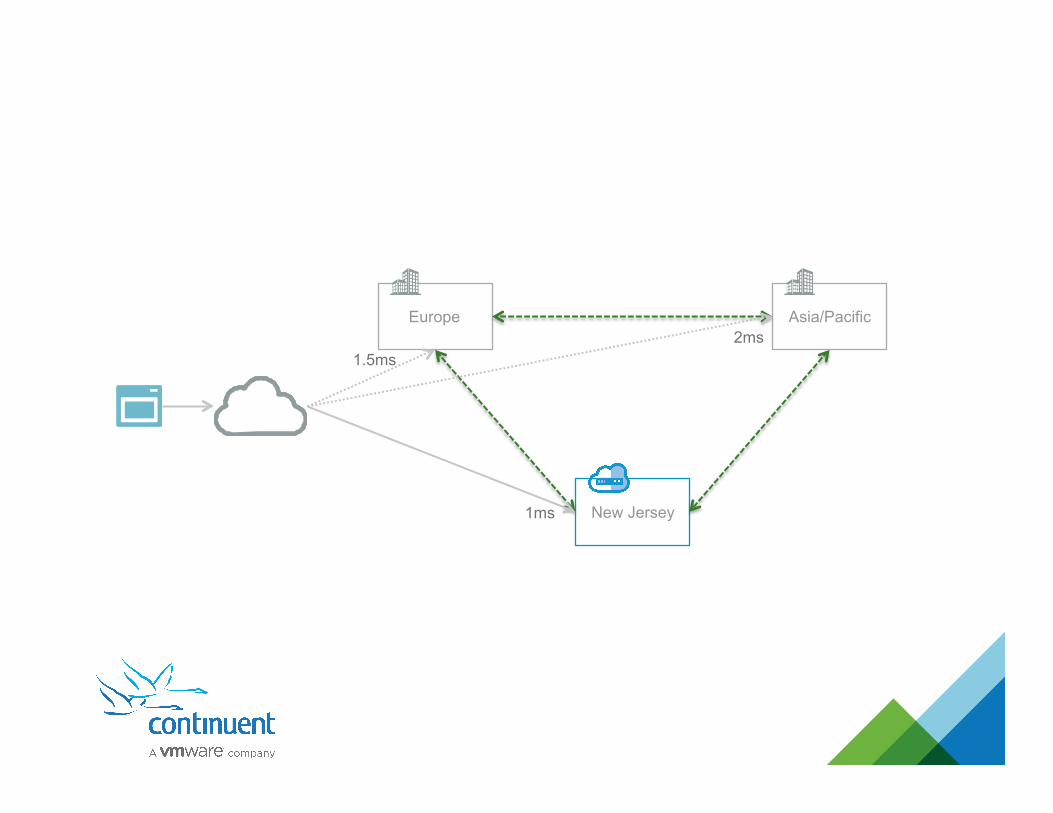
Europe Asia/Pacific
New Jersey 1ms
2ms 1.5ms

Credit Card Transaction Processing • Application connectivity to a particular location isn’t guaranteed • Processing apps use a list of potential sites
• Connectivity to each site is attempted until successful • The application proceeds as normal with the successful site
• Benefit: Automatic failover to any data center by the application

Europe Asia/Pacific
New Jersey 3
2 1

Remote Office Connectivity • Local sites potentially subject to prolonged outages • Business processing continues at other sites
• Replication resumes when connectivity is restored • Benefit: Each data center is able to run independently

Europe Asia/Pacific
New Jersey

Introducing Multi-Site Multi-Master (MSMM)

CROSS-REGION REPLICATION
Public Internet or VMware NSX Secure Gateway
vCLOUD AIR VIRTUAL DATA CENTER
ON-PREMISES DATA CENTER
DB2.CA
SLAVE
DB1.CA
MASTER
DB3.CA
SLAVE
Continuent Connector Continuent Connector
DB2.NJ
SLAVE
DB1.NJ
MASTER
DB3.NJ
SLAVE
Continuent Connector Continuent Connector
Asynchronous Multi-Master
MSMM Topology

MSMM Components • Each location runs an independent master/slave cluster. • The cluster is responsible for ensuring local availability.
• An additional replicator is installed on every server. • The additional replicator replicates data from one or more remote
locations to the local server.
• Replication data is never written to the slave binary log.

MSMM Replication
• Each node runs an additional replicator to apply data from remote data centers.
• Each cluster should run with 3 nodes (1 is hidden).
vCLOUD AIR VIRTUAL DATA CENTER
DB2.NJ
DB1.NJ
CA NJ
CA NJ
NJ
MASTER
ON-PREMISES DATA CENTER
DB2.CA
DB1.CA CA NJ
CA NJ
CA
MASTER

Local Failover
ON-PREMISES DATA CENTER
DB2.CA
SLAVE
DB1.CA
MASTER
DB3.CA
SLAVE
Continuent Connector Continuent Connector
X• The master has failed. • The manager on a remaining server identifies the failure.

Local Failover
ON-PREMISES DATA CENTER
DB2.CA
MASTER
DB1.CA
SHUNNED
DB3.CA
SLAVE
Continuent Connector Continuent Connector
X• The failed server is shunned. • One of the slaves is promoted to master. • The connectors send writes to the new master.

Local Failover
ON-PREMISES DATA CENTER
DB2.CA
MASTER
DB1.CA
SLAVE
DB3.CA
SLAVE
Continuent Connector Continuent Connector
• An administrator checks the failed server and corrects the issue. • They run a recover command to reintroduce the server.

MSMM Replication After Failover
• Each node runs an additional replicator to apply data from remote data centers.
• Each cluster should run with 3 nodes (1 is hidden).
vCLOUD AIR VIRTUAL DATA CENTER
DB2.NJ
DB1.NJ
CA NJ
CA NJ
NJ
MASTER
ON-PREMISES DATA CENTER
DB2.CA
DB1.CA CA NJ
CA NJ
CA
MASTER
X

Demo

The Case Against Many Sites • It is difficult. • The application, database and operations teams must all build with
multi-site multi-master in mind. • The topology implies that no site will ever be fully consistent with all
locations. There will always be pending transactions.

Successful MSMM

Application Design • Shard users/locations into different schemas if possible • Design the application with heavy INSERT workloads
• Avoid UPDATE/DELETE statements of the same data from different locations
• Move batch operations to a single location
• Limit the size of commits for batch operations

Database Design • Use InnoDB or another ACID compliant table engine • Use truly unique primary keys like auto_increment or UUID
• Enable auto_increment_increment and auto_increment_offset to prevent conflicts between sites
• Limit the use of triggers or prepare them for row-based replication with Tungsten Replicator.
• Use NTP and consistent time zones on every server

Operations Plan • Handle DNS management with a global DNS system • Configure 24/7 monitoring of all sites
• Schedule regular runs of pt-table-checksum – Expect some level of differences due to the nature of MSMM – Monitor results for an increasing number of differences
• Schedule regular backups in each location

Wrapping Up

Synchronous Clustering Fails Over Distance • Synchronous replication adds server performance drag (Daniel Abadi,
Yale University)
• Global locks create exploding deadlock problems (Jim Gray, Microsoft) • Strong consistency between DBMS requires some/all regions to stop
when network fails (CAP proof by Nancy Lynch, MIT)

Multi-Master is Best for Multi-Site Operation
Europe Asia/Pacific
New Jersey
Optimized performance
for users
SQL transaction processing
in any region
Local high-availability
in any region
Continuous updates across
regions

For more information: Eero Teerikorpi Sr. Director, Strategic Alliance [email protected] +1 (408) 431 3305
Robert Noyes Alliance Manager, USA & Canada [email protected] +1 (650) 575-0958
Philippe Bernard Alliance Manager, EMEA & APAC [email protected] +41 79 347 1385


















