


1 Rated Aspect Summarization of Short Comments Yue Lu, ChengXiang Zhai, and Neel Sundaresan.
Upload
whitney-carrCategory
view
216download
0
Generating Impact-Based Summaries for Scientific
LiteratureQiaozhu Mei, ChengXiang Zhai
University of Illinois at Urbana-Champaign
1

Motivation
• Fast growth of publications– >100k papers in DBLP; > 10 references per paper
• Summarize a scientific paper– Author’s view: Abstracts, introductions
• May not be what the readers received• May change over time
– Reader’s view: impact of the paper• Impact Factor: numeric• Summary of the content?
Author’s view: Proof of xxx;
new definition of xxx;apply xxx technique
State-of-the-art algorithm;
Evaluation metricReader’s view 20 years
later 2

Citation Contexts Impact, but…
• Describes how other authors view/comment on the paper– Implies the impact
• Similar to anchor text on web graph, but:
• Usually more than one sentences (informative).
• Usually mixed with discussions/comparison about other papers (noisy).
… They have been also successfully used in part of speech tagging [7], machinetranslation [3, 5], information retrieval [4, 20], transliteration [13] and text summarization [14]. ... For example, Ponteand Croft [20] adopt a language modeling approach to information retrieval. …
4

Our Definition of Impact Summary
Solution: Citation context infer impact; Original content summary
Abstract:….Introduction: …..
Content: ……
References: ….
… Ponte and Croft [20] adopt a language modeling approach to information retrieval. …
… probabilistic models, as well as to the use of other recent models [19, 21], the statistical properties …
Author picked sentences: good for summary, but doesn’t reflect the impact
Reader composed sentences: good signal of impact, but too noisy to be used as summary
Citation Contexts
Target: extractive summary (pick sentences) of the impact of a paper
5

Rest of this Talk
• An Feasibility study:• A Language modeling based approach
– Sentence retrieval
• Estimation of impact language models• Experiments• Conclusion
6

Language Modeling in Information Retrieval
d1
d2
dN
Doc LMDocuments
1dθ
2dθ
Ndθ
qqθ)θ||D(θ-1dq
Query LM
)θ||D(θ-1dq
)θ||D(θ-1dq
Rank with neg. KL Divergence
CθSmooth using collection LM
7

Impact-based Summarization as Sentence Retrieval
s1
s2
sN
Sent LMSentences
1sθ
2sθ
Nsθ
DIθ)θ||D(θ-
1sI
Impact LM
)θ||D(θ-2sI
)θ||D(θ- sI N
Rank with neg. KL Divergence
Dc1
c2
cM
Dθ
Use top ranked sentences as a summary
Key problem: estimate θI
8

Estimating Impact Language Models
• Interpolation of document language model and citation language model
Dc1
c2
cM
Iθ DθCθ
)|()|()1()|( CdI wpwpwp
c
CcI d
wpdwcwp
||
)|(),()|(
Constant coefficient:
Dirichlet smoothing:
M
jCj
j j
C jwpwp
1
)|(1
)|(
1Cθ
2Cθ
MCθ
Set λj with features of cj : ...)()()( 321 jjjj cfcfcf
f1(cj) = |cj|, and…9

Specific Feature – Citation-based Authority
• Assumption: High authority paper has more trustable comments (citation context)
• Weight more in impact language model
• Authority pagerank on the citation graph
d1
d2
)|()(2 dcdPgcf jj
ddd doutDeg
dPg
NdPg
',' )'(
)'(1)1()(
10

Specific Feature – Citation Context Proximity
• Weight citation sentences according to the proximity to the citation label
• • k distance to
the citation label
… There has been a lot of effort in applying the notion of language modeling and its variations to other problems. For example, Ponte and Croft [20] adopt a language modeling approach to information retrieval. They argue that much of the difficulty for IR lies in the lack of an adequate indexing model. Instead of making prior parametric assumptions about the similarity of documents, they propose a non-parametric approach to retrieval based probabilistic language modeling. Empirically, their approach significantly outperforms traditional tf*idf weighting on two different collections and query sets. …
kjj ccf1
)Pr()(3
11

Experiments
• Gold standard: – human generated summary– 14 most cited papers in SIGIR
• Baselines:– Random; LEAD (likely to cover abs/intro.); – MEAD – Single Doc; – MEAD – Doc + Citations; (multi-document)
• Evaluation Metric: – ROUGE-1, ROUGE-L
(unigram cooccurrence; longest common sequence)
12

Basic Results
Length Metric Random LEAD MEAD-Doc
MEAD-Doc +Cite
LM (KL-Div)
3 R-1 0.163 0.167 0.301 0.248 0.323 (+7.3%)
3 R-L 0.144 0.158 0.265 0.217 0.299 (+12.8%)
5 R-1 0.230 0.301 0.401 0.333 0.467 (+16.5%)
5 R-L 0.214 0.292 0.362 0.298 0.444 (+22.7%)
10 R-1 0.430 0.514 0.575 0.472 0.649 (+12.9%)
10 R-L 0.396 0.494 0.535 0.428 0.622 (+16.2%)
15 R-1 0.538 0.610 0.685 0.552 0.730 (+6.6%)
15 R-L 0.499 0.586 0.650 0.503 0.705 (+8.5%)
13
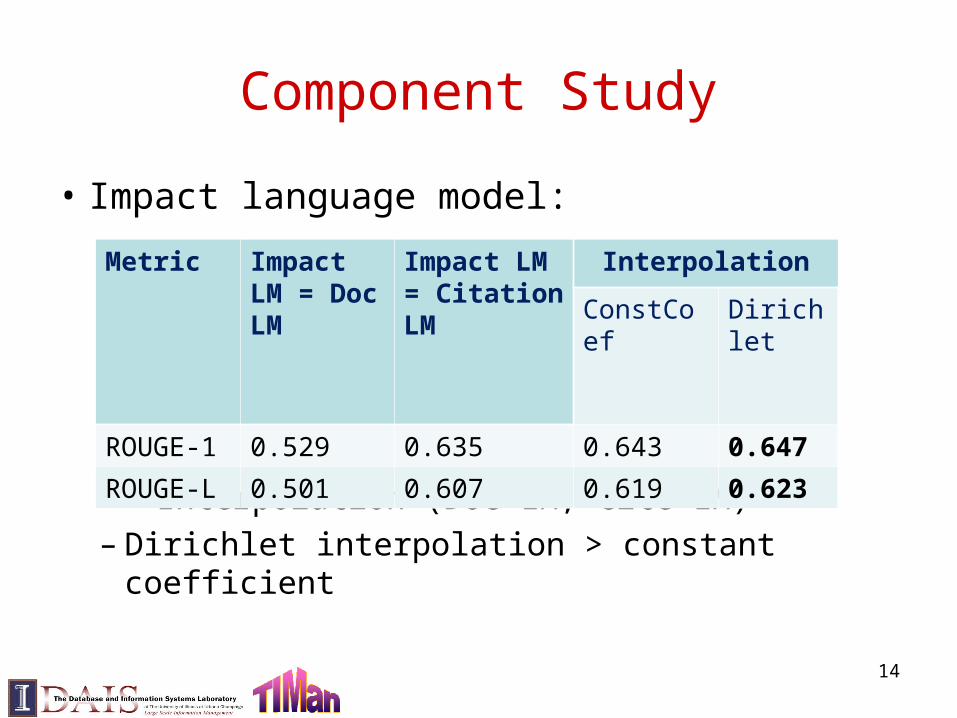
Component Study
• Impact language model:
– Document LM << Citation Context LM
<< Interpolation (Doc LM, Cite LM)– Dirichlet interpolation > constant coefficient
14
Metric Impact LM = Doc LM
Impact LM = Citation LM
Interpolation
ConstCoef Dirichlet
ROUGE-1 0.529 0.635 0.643 0.647
ROUGE-L 0.501 0.607 0.619 0.623

Component Study (Cont.)
• Authority and Proximity– Both Pagerank and Proximity improves– Pagerank + Proximity improves marginally– Q: How to combine pagerank and proximity?
15
PageRank Proximity = Off Pr(s) = 1/αk
Off 0.685 0.711
On 0.708 0.712

Non-impact-based SummaryPaper = “A study of smoothing methods for language
models applied to ad hoc information retrieval”
1. Language modeling approaches to information retrieval are attractive and promising because they connect the problem of retrieval with that of language model estimation, which has been studied extensively in other application areas such as speech recognition.
2. The basic idea of these approaches is to estimate a language model for each document, and then rank documents by the likelihood of the query according to the estimated language model.
3. On the one hand, theoretical studies of an underlying model have been developed; this direction is, for example, represented by the various kinds of logic models and probabilistic models (e.g., [14, 3, 15, 22]).
16
Good big picture of the field (LMIR),
but not about contribution of the paper (smoothing in LMIR)

Impact-based Summary
Paper = “A study of smoothing methods for language models applied to ad hoc information retrieval”
1. Figure 5: Interpolation versus backoff for Jelinek-Mercer (top), Dirichlet smoothing (middle), and absolute discounting (bottom).
2. Second, one can de-couple the two different roles of smoothing by adopting a two stage smoothing strategy in which Dirichlet smoothing is first applied to implement the estimation role and Jelinek-Mercer smoothing is then applied to implement the role of query modeling
3. We find that the backoff performance is more sensitive to the smoothing parameter than that of interpolation, especially in Jelinek-Mercer and Dirichlet prior.
17
Specific to smoothing LM in IR;
especially for the concrete smoothing techniques (Dirichlet and JM)

Related Work
• Text summarization (extractive)– E.g., Luhn ’58; McKeown and Radev ’95; Goldstein et al. ’99; Kraaij et
al. ’01 (using language modeling)
• Technical paper summarization– Paice and Jones ’93; Saggion and Lapalme ’02; Teufel and Moens ’02
• Citation context– Ritchie et al. ’06; Schwartz et al. ’07
• Anchor text and hyperlink structure• Language Modeling for information retrieval
– Ponte and Croft ’98; Zhai and Lafferty ’01; Lafferty and Zhai ’01
18

Conclusion
• Novel problem of Impact-based Summarization• Language Modeling approach
– Citation context Impact language model– Accommodating authority and proximity features
• Feasibility study rather than optimizing • Future work
– Optimize features/methods– Large scale evaluation
19

Feature Study
21
• What we have explored:– Unigram language models - doc; citation context;– Length features– Authority features;– Proximity features;– Position-based re-ranking;
• What we haven’t done: – Redundancy removal (Diversity);– Deeper NLP features; ngram features;– Learning to weight features;

Scientific Literature with Citations
… They have been also successfully used in part of speech tagging [7], machinetranslation [3, 5], information retrieval [4, 20], transliteration [13] and text summarization [14]. ... For example, Ponteand Croft [20] adopt a language modeling approach to information retrieval. …
… While the statistical properties of text corpora are fundamental to the use of probabilistic models, as well as to the use of other recent models [19, 21], the statistical properties …
paper
Citation
paper
paper
Citation
Citation context22

Language Modeling in Information Retrieval
• Estimate document language models– Unigram multinomial distribution of words
– θd: {P(w|d)}
• Ranking documents with query likelihood– R(doc, Q) ~ P(q|d), a special case of
– negative KL-divergence: R(doc, Q) ~ -D(θq || θd)
• Smooth the document language model– Interpolation-based (p(w|d) ~ pML(w|d) + p(w|REF))
– Dirichlet smoothing empirically performs well
23


















