
Generate Affy.dat file Hyb. cRNA Hybridize to Affy arrays Output as Affy.chp file Text Self...
30
Generate Affy.dat file Hyb. cRNA Hybridize to Affy arrays Output as Affy.chp file Text Self Organized Maps (SOMs) Functiona l annotatio n Pathway assignment Co- ordinate regulation Promoter motif commonalities Tissue Flow chart of Affymetrix from sample to information
-
Upload
horatio-kelly -
Category
Documents
-
view
215 -
download
1
Transcript of Generate Affy.dat file Hyb. cRNA Hybridize to Affy arrays Output as Affy.chp file Text Self...

Generate Affy.dat fileHyb.
cRNA
Hybridize to Affy arrays
Output as Affy.chp file
Text
Self Organized Maps (SOMs)
Functional annotationPathway assignment
Co-ordinate regulation
Promoter motif commonalities
Tissue
Flow chart of Affymetrix from sample to
information

Microarray Data AnalysisMicroarray Data Analysis
Data preprocessing and visualizationData preprocessing and visualization Supervised learningSupervised learning
Machine learning approachesMachine learning approaches Unsupervised learningUnsupervised learning
Clustering and pattern detectionClustering and pattern detection Gene regulatory regions predictions Gene regulatory regions predictions
based co-regulated genesbased co-regulated genes Linkage between gene expression data Linkage between gene expression data
and gene sequence/function databasesand gene sequence/function databases ……

Data preprocessingData preprocessing
Data preparation or pre-Data preparation or pre-processingprocessing NormalizationNormalization Feature selectionFeature selection
Base on the quality of the signal Base on the quality of the signal intensityintensity
Based on the fold changeBased on the fold change T-testT-test
……

NormalizationNormalization
Need to scale the red sample so that the Need to scale the red sample so that the overall intensities for each chip are equivalent overall intensities for each chip are equivalent
Experiment1
Control
Experiment2
Control

NormalizationNormalization To insure the data are comparable, To insure the data are comparable,
normalization attempts to correct the normalization attempts to correct the following variables:following variables: Number of cells in the sampleNumber of cells in the sample Total RNA isolation efficiencyTotal RNA isolation efficiency Signal measurement sensitivitySignal measurement sensitivity ……
Can use simple mathCan use simple math Normalization by global scaling (bring each Normalization by global scaling (bring each
image to the same average brightness) image to the same average brightness) Normalization by sectorsNormalization by sectors Normalization to housekeeping genesNormalization to housekeeping genes ……
Active research areaActive research area

Basic Data AnalysisBasic Data Analysis Fold change (relative change in intensity for each gene)Fold change (relative change in intensity for each gene)
Mn-SOD
Annexin IV
Aminoacylase 1

Microarray Data AnalysisMicroarray Data Analysis
Data preprocessing and visualizationData preprocessing and visualization Supervised learningSupervised learning
Machine learning approachesMachine learning approaches Unsupervised learningUnsupervised learning
Clustering and pattern detectionClustering and pattern detection Gene regulatory regions predictions Gene regulatory regions predictions
based co-regulated genesbased co-regulated genes Linkage between gene expression data Linkage between gene expression data
and gene sequence/function databasesand gene sequence/function databases ……

Microarrays: An ExampleMicroarrays: An Example Leukemia: Acute Lymphoblastic (ALL) vs Leukemia: Acute Lymphoblastic (ALL) vs
Acute Myeloid (AML), Golub et al, Acute Myeloid (AML), Golub et al, ScienceScience, , v.286, 1999v.286, 1999 72 examples (38 train, 34 test), about 7,000 72 examples (38 train, 34 test), about 7,000
probesprobes well-studied (CAMDA-2000), good test examplewell-studied (CAMDA-2000), good test example
ALL AML
Visually similar, but genetically very different

Feature selectionFeature selection
……
0.0220.022
0.2360.236
0.9630.963
0.0220.022
0.9410.941
0.6260.626
0.1780.178
0.2600.260
0.3320.332
0.00260.0026
0.4870.487
0.2430.243
p-valuep-value
……
5174.65174.6
5617.65617.6
4245.74245.7
565.2565.2
193.9193.9
2192.22192.2
3211.83211.8
12.912.9
132.5132.5
89.889.8
205.6205.6
1283.51283.5
ALL3ALL3
……
470.9470.9
2396.82396.8
9520.69520.6
56.956.9
3.23.2
2848.52848.5
1283.71283.7
3439.83439.8
721.5721.5
2303.02303.0
31.031.0
55.055.0
AML2AML2
……
83.383.3
385.4385.4
1813.71813.7
65.265.2
367367
212.6212.6
10871087
774.5774.5
241.8241.8
2148.72148.7
605605
170.7170.7
AML1AML1
……
3272.53272.5
419.3419.3
3853.13853.1
434.0434.0
629.4629.4
260.5260.5
14691469
556556
66.166.1
49.249.2
441.7441.7
5.55.5
ALL1ALL1
……
52.352.3
363.7363.7
2404.32404.3
29.629.6
661.7661.7
236.2236.2
1372.11372.1
614.3614.3
77.277.2
1915.51915.5
629.2629.2
43.743.7
AML3AML3
…………
3379.63379.6U86635_g_atU86635_g_at
6191.96191.9AB017912_g_atAB017912_g_at
6039.46039.4AB017912_atAB017912_at
719.4719.4L19998_g_atL19998_g_at
151151L19998_atL19998_at
2650.92650.9L14936_atL14936_at
4611.74611.7M81855_atM81855_at
14.414.4J03960_atJ03960_at
107.3107.3L03294_g_atL03294_g_at
96.396.3D25543_atD25543_at
95.395.3D25233cds_atD25233cds_at
807.9807.9D21869_s_atD21869_s_at
ALL2ALL2ProbeProbe

Hypothesis TestingHypothesis Testing
Null hypothesisNull hypothesis is an hypothesis about a is an hypothesis about a population parameter. population parameter.
Hypothesis testing is to test the viability of Hypothesis testing is to test the viability of the null hypothesis for a set of the null hypothesis for a set of experimental dataexperimental data
Example:Example: Test whether the time to respond to a tone is Test whether the time to respond to a tone is
affected by the consumption of alcoholaffected by the consumption of alcohol Hypothesis : µ1 - µ2 = 0 Hypothesis : µ1 - µ2 = 0
µ1 is the mean time to respond after consuming µ1 is the mean time to respond after consuming alcohol alcohol
µ2 is the mean time to respond otherwiseµ2 is the mean time to respond otherwise

Z-testZ-test TheoremTheorem: If : If xxii has a normal distribution with has a normal distribution with
mean mean and standard deviation and standard deviation 22, , ii=1,…,=1,…,nn, then , then UU== aai i xxii has a normal distribution with a mean has a normal distribution with a mean E(E(UU)=)= aai i and standard deviation D(and standard deviation D(UU)=)=22 aai i
22.. xxi i /n /n ~ N(~ N(, , 22/n)./n).
Z test : H: µ = µZ test : H: µ = µ00 (µ (µ00 and and 00 are known, assume are known, assume = = 00))
What would one conclude about the null hypothesis that a What would one conclude about the null hypothesis that a sample of N = 46 with a mean of 104 could reasonably sample of N = 46 with a mean of 104 could reasonably have been drawn from a population with the parameters of have been drawn from a population with the parameters of
µµ = 100 and = 100 and = 8? Use = 8? Use
Reject the null hypothesis.

HistogramHistogram
Set 1
Set 2

T-test

William Sealey Gosset William Sealey Gosset (1876-1937)(1876-1937)
(Guinness Brewing Company)

Project 3Project 3
A training data set A training data set (38 samples, 7129 probes, 27 ALL, 11 AML)(38 samples, 7129 probes, 27 ALL, 11 AML)
A testing data setA testing data set (35 samples, 7129 probes, 22 ALL, 13 AML)(35 samples, 7129 probes, 22 ALL, 13 AML)
Lab today: pick the Lab today: pick the top probestop probes that that can differentiate the two sub types and can differentiate the two sub types and process the testing data setprocess the testing data set

Feature 2
Fea
ture
1L
L
L
L
L
LL
MM
M
M
M
M
K Nearest Neighbor K Nearest Neighbor ClassificationClassification
= AML
= ALL
= test sample
M
L
Feature 2
Fea
ture
1L
L
L
L
L
LL
MM
M
M
M
M
Feature 2
Fea
ture
1L
L
L
L
L
LL
MM
M
M
M
M
= AML
= ALL
= test sample
M
L

Distance measuresDistance measures
Euclidean distance
Manhattan distance
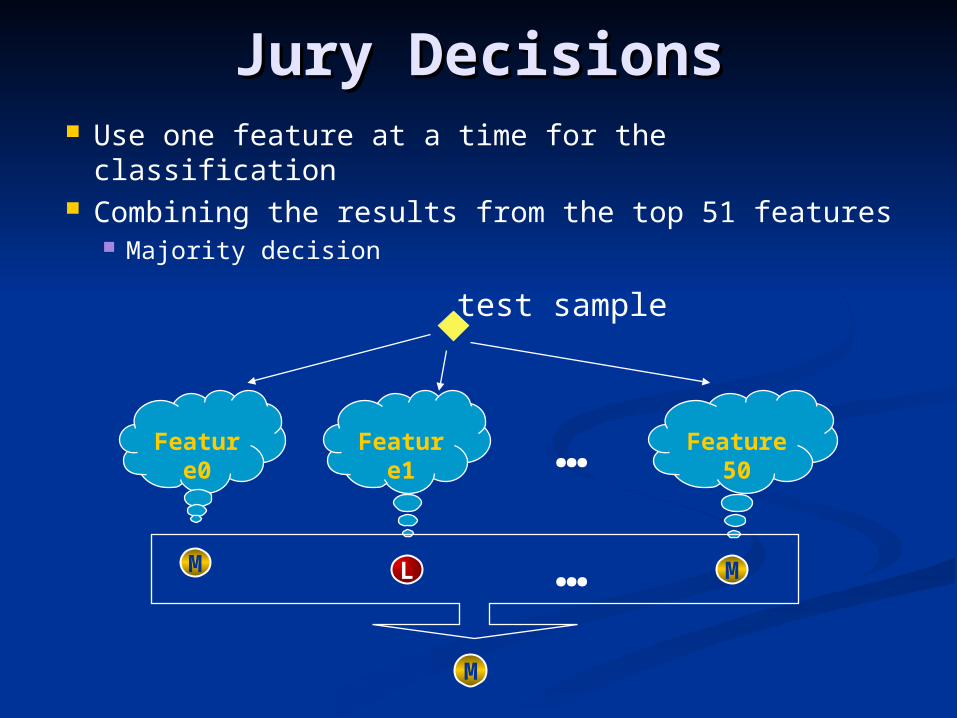
Jury DecisionsJury Decisions Use one feature at a time for the classification Combining the results from the top 51 features
Majority decision
Feature0
Feature1
Feature50…
M L M…
M
test sample

False DiscoveryFalse Discovery Two possible errors in making a decision
about the null hypothesis.
1. We could reject the null hypothesis when it is actually true, i.e., our results were obtained by chance. (Type I error).
2. We could fail to reject the null hypothesis when it is actually false, i.e. our experiment failed to detect the true difference that exists. (Type II error)
We set at a level which will minimize the chances of making either of these errors.

False DiscoveryFalse Discovery Type I error: False DiscoveryType I error: False Discovery False Discovery Rate (FDR) is equal to the p-False Discovery Rate (FDR) is equal to the p-
value of the t-test value of the t-test XX the number of genes in the number of genes in the arraythe array For a p-value of 0.01 For a p-value of 0.01 10,000 genes 10,000 genes
= 100 false “different” genes = 100 false “different” genes You cannot eliminate false positives, but by You cannot eliminate false positives, but by
choosing a more stringent p-value, you can keep choosing a more stringent p-value, you can keep them manageable (try p=0.001)them manageable (try p=0.001)
The FDR must be smaller than the number of The FDR must be smaller than the number of real differences that you find - which in turn real differences that you find - which in turn depends on the size of the differences and depends on the size of the differences and variability of the measured expression valuesvariability of the measured expression values

RCC subtypesRCC subtypes Clear Cell RCC (70-Clear Cell RCC (70-
80%)80%)
Papillary (15-20%)Papillary (15-20%)
Chromoprobe (4-5%)Chromoprobe (4-5%)
Collecting duct Collecting duct
Oncocytoma Oncocytoma
Saramatoid RCCSaramatoid RCC
Goal: Goal:
Identify a panel Identify a panel of discriminator of discriminator genesgenes
??
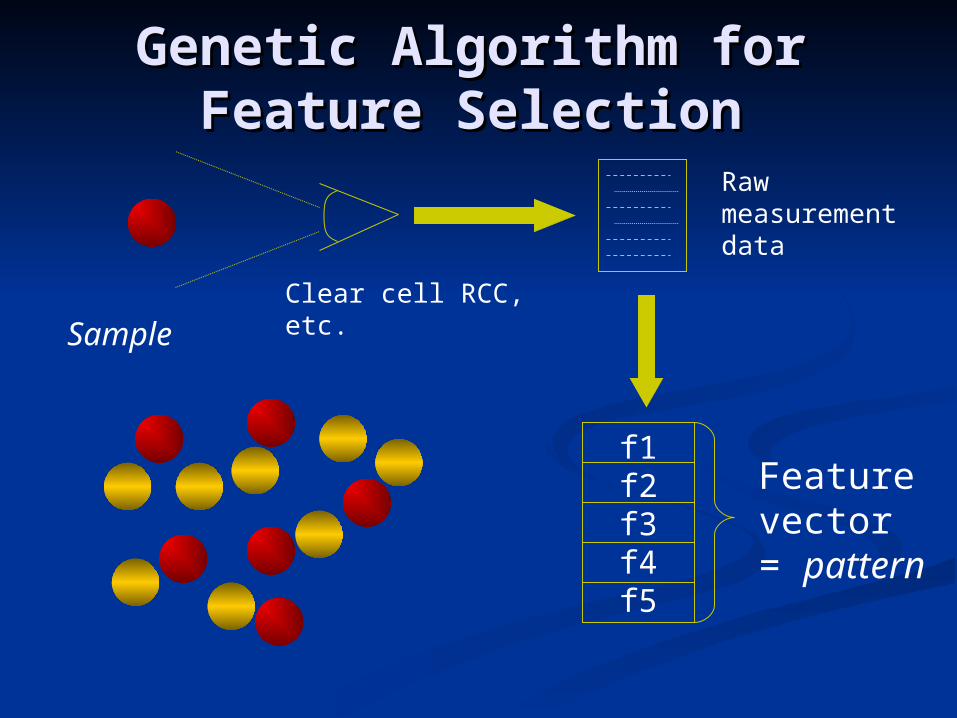
Genetic Algorithm for Genetic Algorithm for Feature SelectionFeature Selection
SampleClear cell RCC,etc.
Rawmeasurementdata
f1f2f3f4f5
Featurevector= pattern

Why Genetic Algorithm?Why Genetic Algorithm? Assuming 2,000 relevant genes, 20 Assuming 2,000 relevant genes, 20
important discriminator genes (features).important discriminator genes (features). Cost of an exhaustive search for the optimal Cost of an exhaustive search for the optimal
set of features ?set of features ?C(n,k)=n!/k!(n-k)!C(2,000, 20) = 2000!/(20!1980!) ≥ (100)^20
= 10^40If it takes one femtosecond (10-15 second) to evaluate a set of features, it takes more than 310^17 years to find the optimal solution on the computer.

Evolutionary MethodsEvolutionary Methods
Based on the mechanics of Based on the mechanics of Darwinian Darwinian evolutionevolution The evolution of a solution is loosely based on The evolution of a solution is loosely based on
biological evolutionbiological evolution
PopulationPopulation of competing candidate solutions of competing candidate solutions Chromosomes (a set of features)Chromosomes (a set of features)
Genetic operatorsGenetic operators (mutation, recombination, (mutation, recombination, etc.) etc.) generate new candidate solutions generate new candidate solutions
Selection pressureSelection pressure directs the search directs the search those that do well those that do well survive (selection)survive (selection) to form the to form the
basis for the next set of solutions.basis for the next set of solutions.

A Simple Evolutionary A Simple Evolutionary AlgorithmAlgorithm
SelectionGeneticOperators
Evaluation
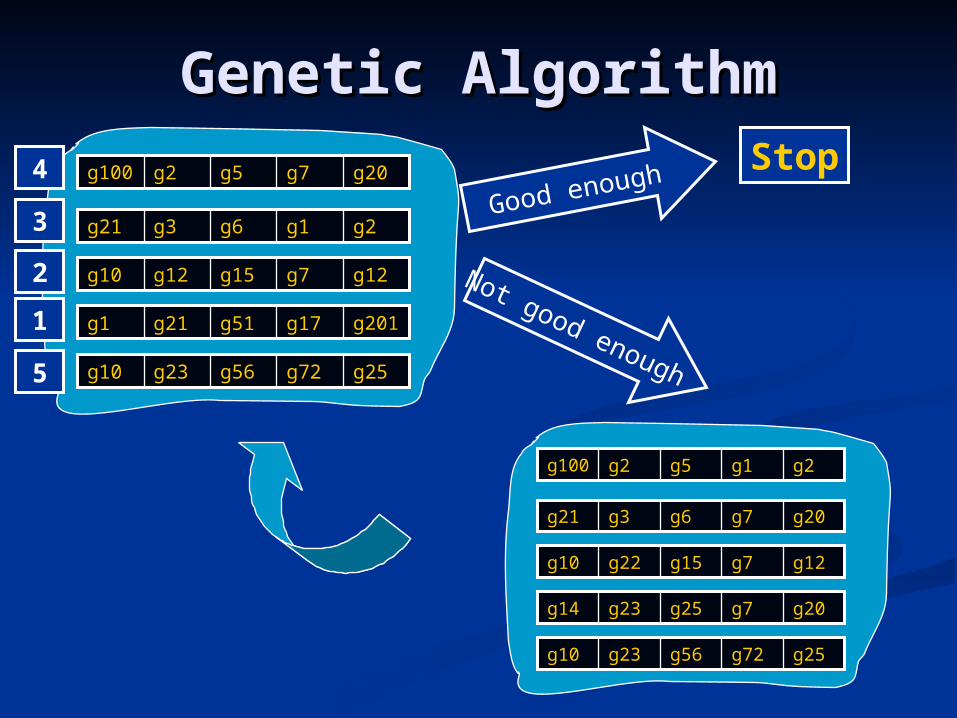
Genetic AlgorithmGenetic Algorithm
g2g2g1g1g6g6g3g3g21g21
g201g201g17g17g51g51g21g21g1g1
g12g12g7g7g15g15g12g12g10g10
g25g25g72g72g56g56g23g23g10g10
g20g20g7g7g5g5g2g2g100g100
Good enough Stop
g20g20g7g7g6g6g3g3g21g21
g20g20g7g7g25g25g23g23g14g14
g12g12g7g7g15g15g22g22g10g10
g25g25g72g72g56g56g23g23g10g10
g2g2g1g1g5g5g2g2g100g100
Not good enough5
2
1
4
3

EncodingEncoding
Most difficult, and important part of Most difficult, and important part of any GAany GA
Encode so that illegal solutions are not Encode so that illegal solutions are not possiblepossible
Encode to simplify the “evolutionary” Encode to simplify the “evolutionary” processes, e.g. reduce the size of the processes, e.g. reduce the size of the search spacesearch space
Most GA’s use a binary encoding of a Most GA’s use a binary encoding of a solution, but other schemes are solution, but other schemes are possiblepossible

GA FitnessGA Fitness At the core of any optimization At the core of any optimization
approach is the function that measures approach is the function that measures the quality of a solution or optimization.the quality of a solution or optimization.
Called:Called: Objective functionObjective function Fitness functionFitness function Error functionError function measuremeasure etc.etc.

Genetic OperatorsGenetic Operators
Crossover
10 30 50 70
20 40 60 80
Randomly SelectedCrossover Point
10 30
50 7020 40
60 80
Mutation
10 30 62 80
Randomly Selected Mutation Site
Recombination is intended to produce promising individuals.
Mutation maintains population diversity, preventing premature convergence.

Genetic Algorithm/K-Nearest Genetic Algorithm/K-Nearest NeighborNeighbor Algorithm Algorithm
Classifier(kNN)
Feature Selection(GA)
MicroarrayDatabase


















