
From R&D to production-ready predictive apps - Christophe Bourguignat & Yann Barraud, AXA
12
FROM R&D TO PRODUCTION-READY PREDICTIVE APPS: IT ARCHITECTURE CHALLENGES IN LARGE ORGANIZATIONS PAPIs.io’14 / Barcelona
-
Upload
papisio -
Category
Technology
-
view
281 -
download
0
Transcript of From R&D to production-ready predictive apps - Christophe Bourguignat & Yann Barraud, AXA

FROM R&D TO PRODUCTION-READY PREDICTIVE APPS:
IT ARCHITECTURE CHALLENGES IN LARGE ORGANIZATIONS
PAPIs.io’14 / Barcelona

A team fully dedicated to Applied Data Science and R&D
Yann Barraud : Data Architect, Engineering Team
Christophe Bourguignat : Data Scientist, Engineering Team
Who We Are / AXA Data Innovation Lab
2 |
Software Engineering Machine Learning
Data Business Data IT architecture
@DaFellow - @chris_bour - #papis2014

Your predictive model is
cool…
… but how can I use it ?

Batch Mode (already in production / out of scope today)
“Send me each day the list of the customers that xxx.”
Real-Time Mode 1 : Decision, machine-triggered
“Do that each time xxxx happens. Quickly.”
“Tell me what to do next.”
Real-Time Mode 2 : On demand, human-triggered
“Recompute last prediction update about xxxx. Now.”
“If available, please tell me what you know about xxx and
predict”
Uses Cases
What We Forsee
4 | @DaFellow - @chris_bour - #papis2014

Don’t sterilize R&D
Let them use their tools, and try to be flexible
Example : support Pythton, R and Spark MLlib models
Performance matters
In engineering context, not only accuracy performance, but also
response time performance !
Work with a fragmented, and legacy IT
Example : ubiquity of Java for corporate apps
But under transformation !
Working under constraints : R&D VS Production
5 | @DaFellow - @chris_bour - #papis2014

Technical bulding blocks
6 |
+ -
PMML Easy model export
Doesn’t support some types of
models
Doesn’t solve complex data
preparation
Openscoring Off the shelf. Open source Not distributed
Hadoop Streaming Already in production. Distributed Batch only
Spark MLLib Distributed / up to date Not compatible with Python
and R ML libs
In House development Can virtually fit any of our custom
needs Time to market, maintainability
Third-party commercial tools Time to market Adaptability. Adherence
@DaFellow - @chris_bour - #papis2014

The « predict » is not the problem. It’s more the data transformation :
complex in production
E.g. : parsing (dates, …), One Hot Encoding, impact coding, …
Do we recode the R&D models ? Downgrade / simplify for production
(performance matters)
Recode everything but the core ML “predict” part
Do we make engineering team work with R&D at early stage ?
Make R&D team make some production code as a delivery ?
Questions We Are Facing
7 | @DaFellow - @chris_bour - #papis2014

Architecture : step 1
8 |
Rserve RDA models
Live features
transformation
Bottle.py
scikit-learn Pickle models
Live features
transformation
REST
JSON
REST
JSON
TCP
connexion
{
raw features
}
« raw »
features
10 %
90 %
{
raw features
}
@DaFellow - @chris_bour - #papis2014
Services on top of custom
Java Framework
Connectivity (TCP, HTTP REST, …)
SparkML Serialized model
Live features
transformation
Features transformation
breakdown

Prediction code skeleton
9 | @DaFellow - @chris_bour - #papis2014
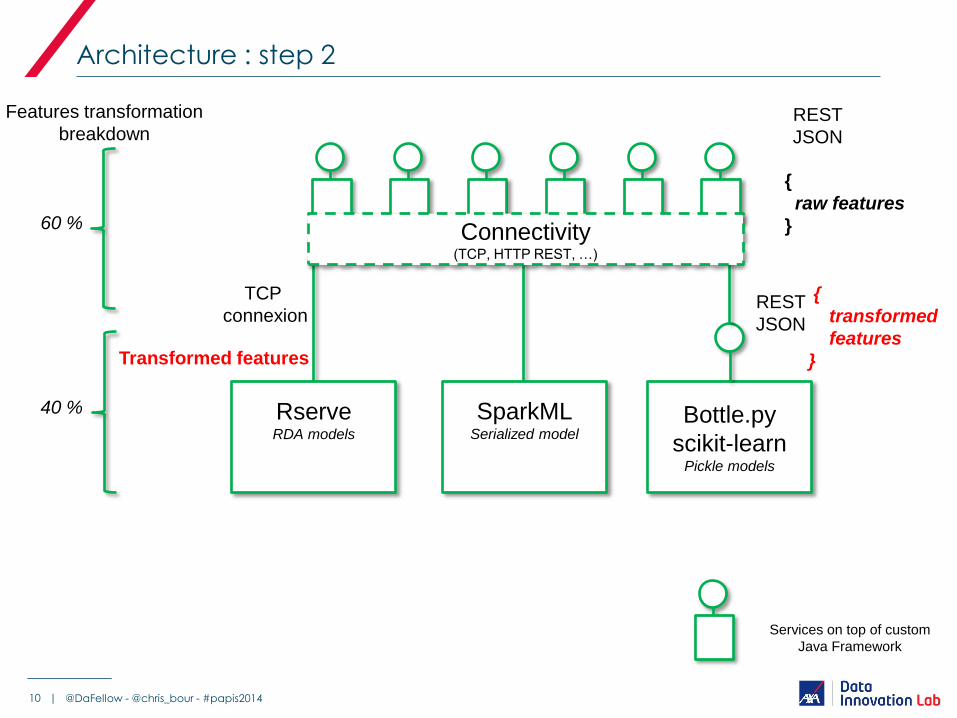
Architecture : step 2
10 |
Rserve RDA models
Bottle.py
scikit-learn Pickle models
REST
JSON
REST
JSON
TCP
connexion
{
raw features
}
Transformed features
60 %
40 %
{
transformed
features
}
@DaFellow - @chris_bour - #papis2014
SparkML Serialized model
Connectivity (TCP, HTTP REST, …)
Features transformation
breakdown
Services on top of custom
Java Framework

Architecture : step 3
11 |
Rserve RDA models
Bottle.py
scikit-learn Pickle models
REST
JSON
REST
JSON
TCP
connexion
{
raw features
}
Transformed
features
60 %
40 %
{
transformed
features
}
@DaFellow - @chris_bour - #papis2014
SparkML Serialized model
Connectivity (TCP, HTTP REST, …)
Hadoop
Data Lake
Batch features
transformation
Impala ?
Hbase ?
Services on top of custom
Java Framework
Features transformation
breakdown

Thank You
we’re hiring in Paris ! (just saying ….)





![Axa Magnet - Presentasi AXA Magnet [ Maestro Global Network ] Terbaru](https://static.fdocuments.us/doc/165x107/55d2ed27bb61ebdd398b462f/axa-magnet-presentasi-axa-magnet-maestro-global-network-terbaru.jpg)












