
Finding the Sites with Best Accessibilities to Amenities Qianlu Lin, Chuan Xiao, Muhammad Aamir...
21
Finding the Sites with Best Accessibilities to Amenities Qianlu Lin , Chuan Xiao, Muhammad Aamir Cheema and Wei Wang University of New South Wales, Australia
-
Upload
andrew-dawn -
Category
Documents
-
view
213 -
download
0
Transcript of Finding the Sites with Best Accessibilities to Amenities Qianlu Lin, Chuan Xiao, Muhammad Aamir...

Finding the Sites with Best Accessibilities to Amenities
Qianlu Lin, Chuan Xiao, Muhammad Aamir Cheema and Wei Wang
University of New South Wales, Australia

Application
Find an apartment that is closest to restaurant, bus stop and zoo
‘Closeness’ is measured by a monotonic scoring function
Apartment
Restaurant
Bus Stop
Zoo
2

Problem Definition
3
•Given a set of query points S = {s1, s2, … sm}
•Given n sets of data points T1, T2, … Tn
•Find k query points in S, whose aggregated distances to T1, T2, … Tn are smallest:
Distance(sj, {T1, T2, … Tn})
= f(d(sj, NN(sj, T1)), d(sj, NN(s
j, T2)), … d(sj, NN(s
j, Tn)))
where NN(sj, Ti) is the nearest neighbour of sj in Ti
d(sj, NN(sj, Ti) is the distance from sj to its nearest neighbour in Ti
* For simplicity, we use:
d(x, y) is Euclidean Distance
f(x1, x2, ...xm) =sum(x1, x2, …, xm)

Related Literature
KNN – K Nearest Neighbour Given a query point q and a set of data points I, find k
data points in I that are nearest neighbour of q
RNN – Reverse Nearest Neighbour Given a query point q and a set of data points I, find k
data points of which q is the nearest neighbour
ANN – All Nearest Neighbour Given a set of query points Q and a set of data points I,
find nearest neighbour in I for each query point in Q (Y.Chen, ICDE2007) Efficient evaluation of all-nearest-
neighbor queries In solving our problem, we can retrieve ANN in each type
and find top k queries
4

Our Contribution
We introduced the problem of finding the sites with best accessibilities to amenities
We proposed two algorithms to find top-k accessible sites among a set of possible locations
We performed experiments on several real datasets
5
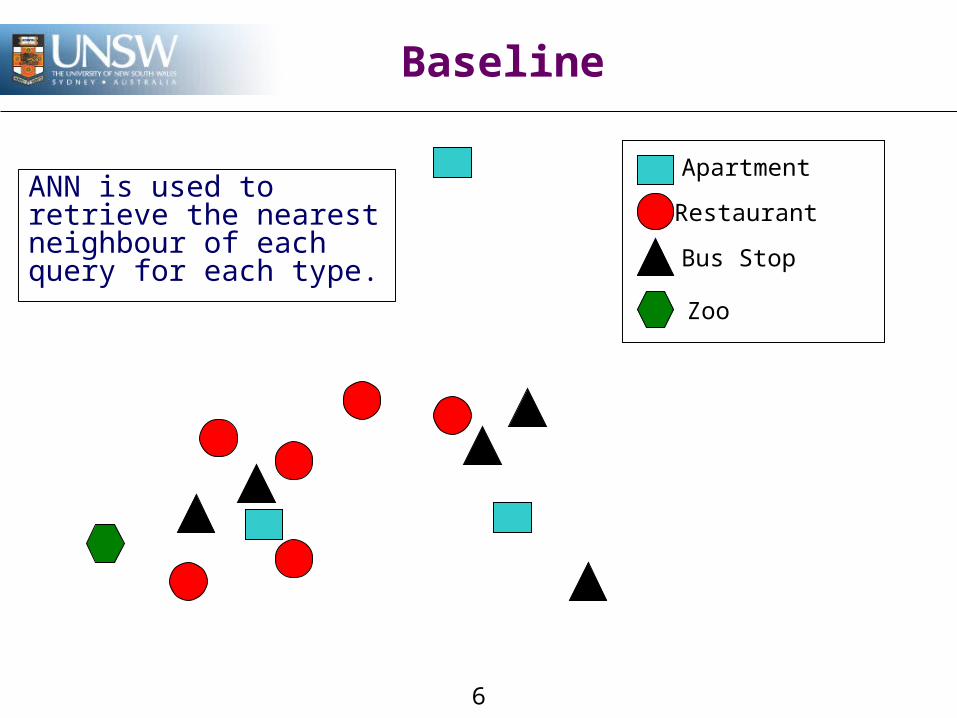
Baseline
Apartment
Restaurant
Bus Stop
Zoo
6
ANN is used to retrieve the nearest neighbour of each query for each type.

Baseline - Disadvantage
I/O time Query data will be accessed n times, n is the
number of types of index objects
Memory usage Need find NN for all the query points Need to maintain a list of nearest neighbours
of each type of each query
7

Separate Tree (Index Construction)
Apartment
Restaurant
Bus Stop
Zoo
Q1
Q2 Q3 Q4Z1
Query Tree
Index Tree
Z1
R1
R2
R3
R4
R1
R2 R3 R4
R1B1
B2
B3
B4
B1
B2 B3 B4
Q1Q2
Q4Q3
8

Separate Tree (Query Processing)
Q1
Q1 Z1R1B1
MAXD={30, 305, 309}
MIND={30, 0, 0} LBD=30
UBD=644
current_k_best = 644
9
R1 B1
Apartment
Restaurant
Bus Stop
Zoo
Z1
Z1
R1R1B1
Q1Q2
Q4Q3 MAXDMaximum distance from Q1 to all the nodes in the list
MINDMinimum distance from Q1 to all the nodes in the list
UBDUpper bound of the summed distance
LBDLower bound of the summed distance

Separate Tree (cont’d)
current_k_best = 190
10
Apartment
Restaurant
Bus Stop
Zoo
Z1
R1
R2
R3
R4
R1B1
B2
B3
B4
Q1Q2
Q4Q3
Z1 R1
R2 R3 R4
B1
B2 B3 B4
Q1
Q2 Q3 Q4
Q3 Z1R4B2
MAXD={30, 100, 60}MIND={30, 0, 0} LBD=30
UBD=190
R3
Q4 Z1R4B3
MAXD={300, 150, 60}
MIND={300, 60, 30}
B4
LBD=360
UBD=510

More Improvement?
Data points from different type can be put into one bounding box
– To reduce I/O cost
11
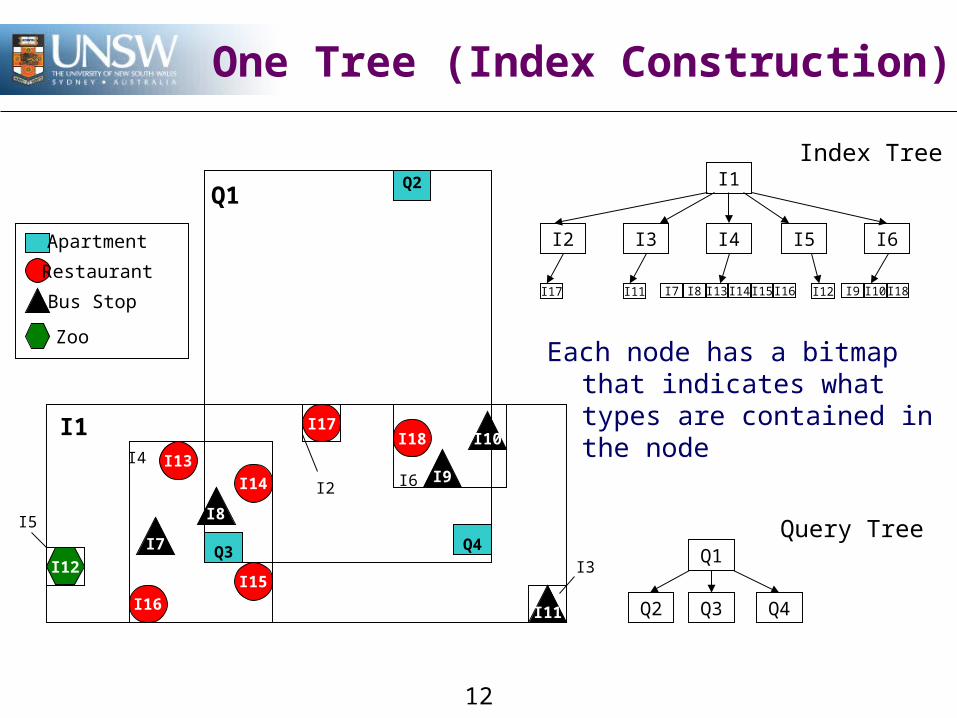
One Tree (Index Construction)
Apartment
Restaurant
Bus Stop
Zoo
I1
I2 I6
I3
I4
I5
I1
I2 I3 I4 I5 I6
Q1
Q2 Q3 Q4
I17
I17I18
I12
I9
I10
I11
I12I11 I7 I8 I13 I14 I15 I16 I9 I10 I18
I16I15
I8
I14I13
I7Query Tree
Index Tree
12
Q1Q2
Q4Q3
Each node has a bitmap that indicates what types are contained in the node

One Tree (Query Processing)
Apartment
Restaurant
Bus Stop
Zoo
Q1
I1
I1 Q1
Q1 I1
MAXD={309, 309, 309}
MIND={0, 0, 0}
LBD=0
UBD=309*3=927
current_k_best = 972
13

One Tree (cont’d)
Apartment
Restaurant
Bus Stop
Zoo
Q1 Q2
Q3 Q4
I1
I2 I6
I3
I4
I5
I1
I2 I3 I4 I5 I6
Q1
Q2 Q3 Q4
Q3 I4 I5
Q4 I6 I5
MIND={0, 0, 30} MAXD={50, 50, 30}LBD=30 UBD=130
MIND={30, 30, 140} MAXD={50, 50, 140}LBD=100 UBD=240
current_k_best = 130
14

Experiments
15
DataSet:San Francisco Road Network (SF) & Road Network of
North America (NA)Spatial query dataset, 2 dimensionsIndex: ~174k points (totally)Query: ~17k points
Algorithm:BaselineSeparate TreeOne Tree
Measurement:CPU timeNumber of leaf nodes access (I/O time)
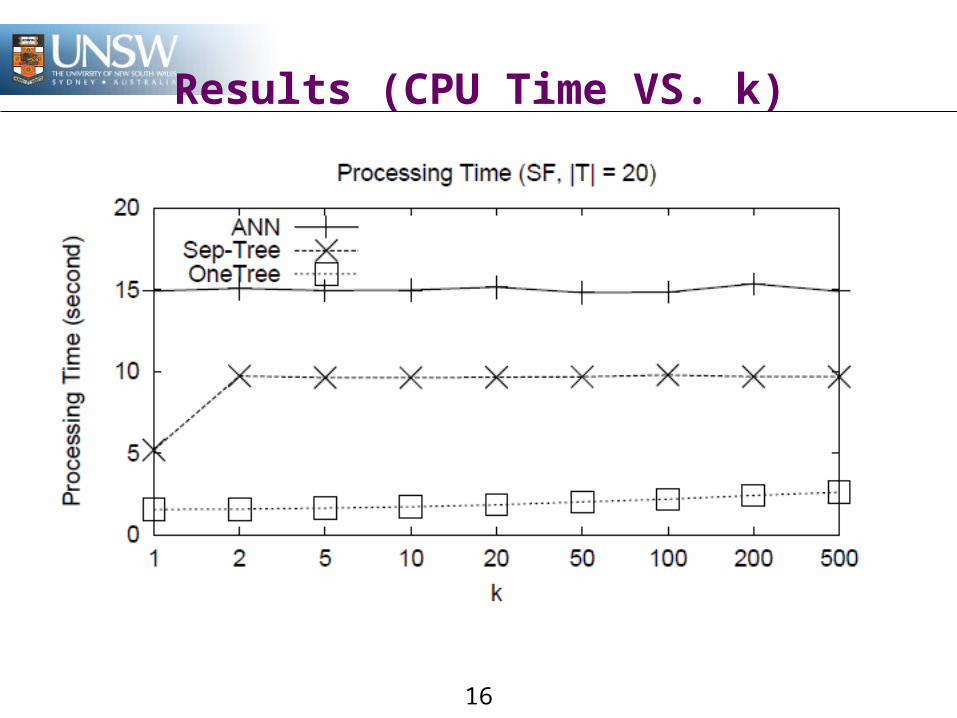
Results (CPU Time VS. k)
16

Results (CPU Time VS. |T|)
17
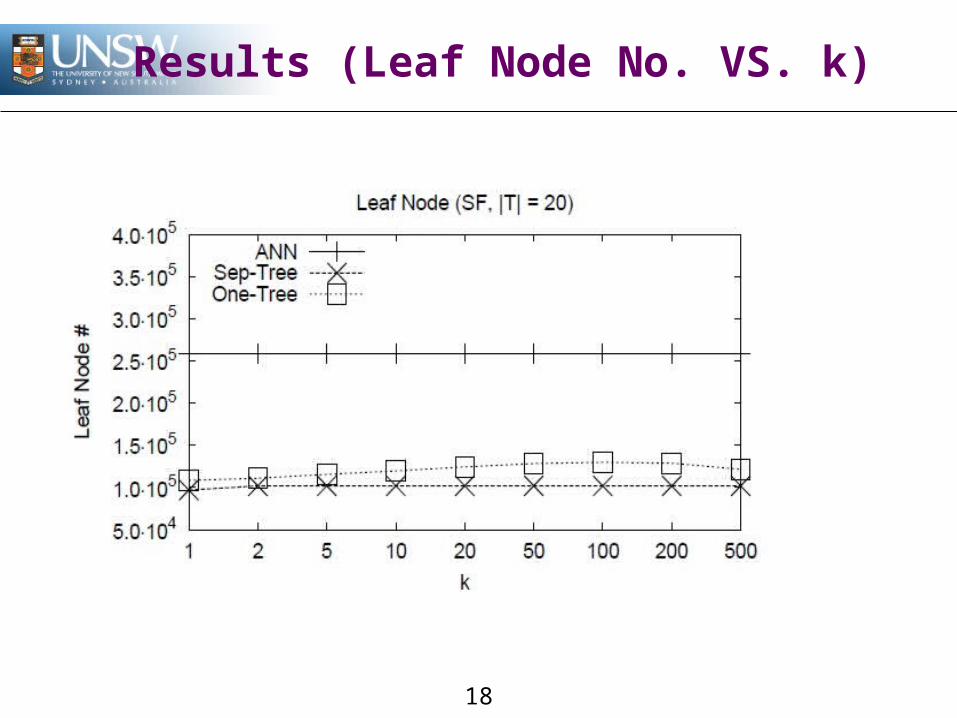
Results (Leaf Node No. VS. k)
18
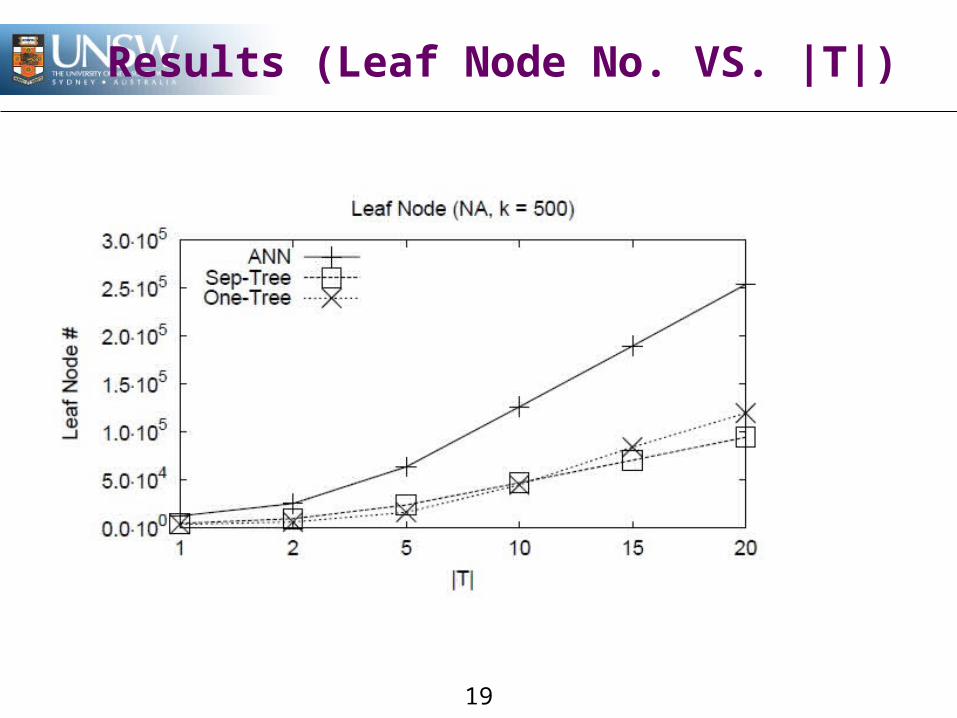
Results (Leaf Node No. VS. |T|)
19

Conclusion
We proposed two algorithms:Separate tree: creates indexes for different
types of points in separate R-treesOne tree: indexes all the points in a single R-
tree Both algorithms outperform the baseline
algorithm with a speed-up up to 5.7 times Also, both algorithms only need access the Query
tree once, which reduces I/O cost on accessing Query tree
20

21
Thank you!
Questions?







![Muhammad Aamir Cheema · ers (Muhammad Omer Cheema, Muhammad Umair Cheema and Muhammad Ammar Cheema) who are my nearest surrounders2 [LLL06] and have provided me with a strong love](https://static.fdocuments.us/doc/165x107/5fb9ea326d6c7a5c8c32d214/muhammad-aamir-ers-muhammad-omer-cheema-muhammad-umair-cheema-and-muhammad-ammar.jpg)










