
Feb. 19, 2008 Multicore Processor Technology and Managing Contention for Shared Resource Cong Zhao...
24
Feb. 19, 2008 Multicore Processor Technology and Managing Contention for Shared Resource Cong Zhao Yixing Li
-
Upload
melanie-tyler -
Category
Documents
-
view
218 -
download
0
Transcript of Feb. 19, 2008 Multicore Processor Technology and Managing Contention for Shared Resource Cong Zhao...

Feb. 19, 2008
Multicore Processor Technology
and Managing Contention for Shared Resource
Cong Zhao Yixing Li

Moore’s Law Transistors per integrated circuit would double every 2
years. Power requirements in relation to transistor size would
double in 1-2 years. Density at minimum cost per transistor, and so on……
Integrated circuits would double in performance every 18 months(By David House)
For Single-Core, the only way to improve the performance is increasing the clock frequency.
2

Why Multi-Core?There are many reasons :•Difficult to make single-core clock frequencies even higher •Deeply pipelined circuits:
– heat problems– speed of light problems– difficult design and verification– large design teams necessary
•Many new applications are multithreaded
3

Why Multi-Core?
4
But the leading reason is:To continue the raw performance growth that customers have come to expect from Moore’s law scaling without being overwhelmed by the growth in power consumption.
As single core designs were pushed to ever higher clock speeds, the power required grew at a faster rate than the frequency, and lead to designs that were complex, power hungry, and unmanageable !!!

Why Multi-Core?
5

What is Multi-Core?A single computing component with two or more independent actual central processing units(called "cores")
Attributes:Application ClassPower/PerformanceProcessing ElementsMemory SystemEtc.
6

Application Class There are two broad classes of processing into which an
application can fall: data processing dominated and control dominated.
Data Processing Dominated A sequence of operations on a stream of data with little or
no data reuse. Image processing, audio processing, and wireless baseband
processing. Control Dominated Often need to keep track of large amounts of state and
often have a high amount of data reuse. file compression/decompression, network processing.
7

Power/Performance In the past decade, power has joined performance as a first
class design. Many applications and devices have strict performance and power requirements.
Mobile phone, Laptop, Server “cloud” computing (warehousescale computers)
8
These cloud computing centers are now consuming more energy than heavy manufacturing in the United States.

Processing ElementsArchitecture and MicroarchitectureArchitecture:Instruction set architecture (ISA), defines the hardware softwareinterface. Reduced instruction set computer(RISC) Complex instruction set computer (CISC). Microarchitecture:The microarchitecture is the implementation of the ISA.In-order processing element.Out-of-order processing element.SIMD, VLIW
9

Memory System In uniprocessor designs, the memory system was a rather
simple component, consisting of a few levels of cache to feed the single processor with data and instructions.
In Multi-core design: Consistency model. Cache configuration. Cache coherence support. Intrachip interconnect. All of these determine how cores communicate impacting
programmability, parallel application performance, and the number of cores that the system can adequately support.
10
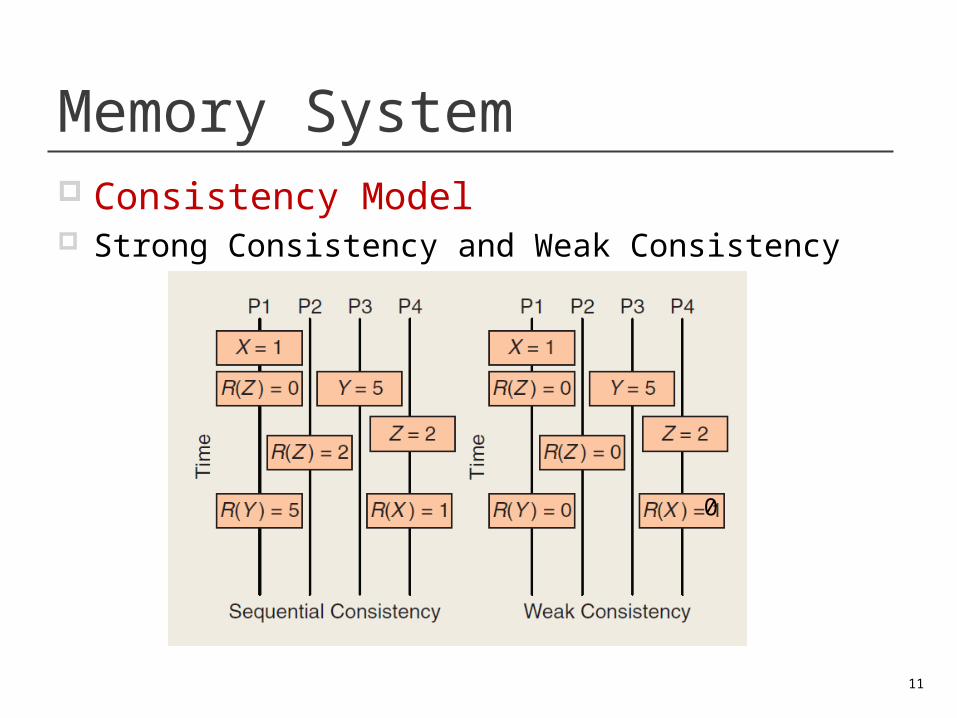
Memory System Consistency Model Strong Consistency and Weak Consistency
11
0

Memory System Cache Configuration Caches give processing elements a fast, high bandwidth local
memory to work with. Caches can be tagged and managed automatically by
hardware or be explicitly managed local store memory. The amount of cache re quired is very application dependent. The first level of cache (L1)is usually rather small, fast, and
private to each processing element. Subsequent levels (L2)can be larger, slower, and shared among processing elements.
12

Memory System Intrachip interconnect. Bus, Crossbar, Ring, and Network-on-chip (NoC) Cache coherence Broadcast based and Directory based.
13

14
Architecture of A Multicore System
Fig2-1. Schematic of a Multicore System with Two Memory Domains
Compete for the shared resources!
Problems?

15
Cache Contention
Thread A request a line not in the cache (a cache miss) and the cache is full
Some data must be evicted to free up a line The evicted line might belong to B or A itself
Hurt the performance
Thread A Thread B

16
Cache Miss Frequency
Temporal locality
Reuse frequency
Miss frequency
A. Mcf Rather poor Low High
B. Povray Excellent High → 0
C. Milc Poor Very low Very high
Fig2-2. Example Memory-Reuse Profiles from SPEC CPU2006 Suite

17
Pain Metrix
Pain(A|B) = SA * ZB Pain(B|A) = SB * ZA Pain(A,B) = Pain(A|B) + Pain(B|A)
Performance degradation of A when A runs with B relative to running solo
S Sensitivity, measures how much a thread suffers whenever it shares the cache with other threads
Z Intensity, measures how much a thread hurts other threads

18
Evaluation of Pain Model

19
Evaluation of Pain Model
Fig2-3. Performance of Estimated Best Schedules Compared with Actual Best Schedules

20
Evaluation of Pain Model
Fig2-4. Worst-Case Performance under DIO Relative to the Default Linux Scheduler
·Average performance improvement: 11%·High-miss-rate applications must be kept apart

21
Problem of Pain Model
2 memory domain 2 cores per domain
8 memory domain 2 cores per domain
What about?
Example shows..
22
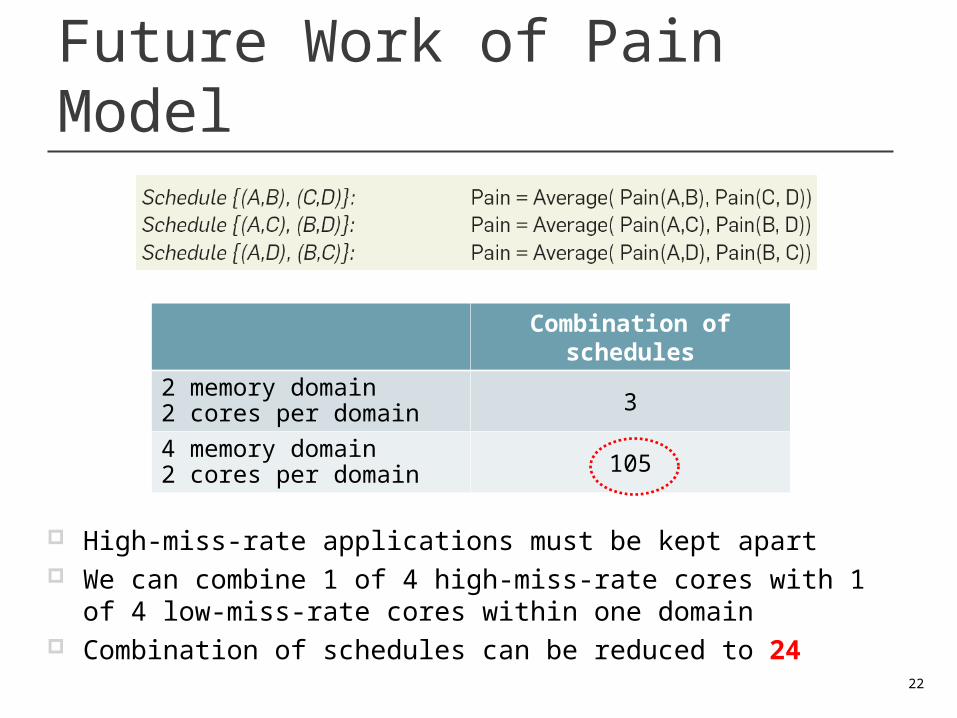
Future Work of Pain Model
Combination of schedules
2 memory domain2 cores per domain 3
4 memory domain2 cores per domain 105
High-miss-rate applications must be kept apart We can combine 1 of 4 high-miss-rate cores with 1 of 4 low-
miss-rate cores within one domain Combination of schedules can be reduced to 24

23
Conclusions The main advantage to multicore systems is that
raw performance increase can come from increasing the number of cores rather than frequency, which translates into a slower growth in power consumption. However, this approach represents a significant gamble because parallel programming science has not advanced nearly as fast as our ability to build parallel hardware.

24
Thank you


















