
Facial Emotion Recognition using Deep...
12
Indian Institute of Technology Kanpur Facial Emotion Recognition using Deep Learning Ankit Awasthi (Y8084) CS 676:Computer Vision Supervisor: Dr. Amitabha Mukerjee , Department of Computer Science Engineering, IIT Kanpur Dr. P Guha, TCS Labs, Delhi,India
Transcript of Facial Emotion Recognition using Deep...

Indian Institute of Technology Kanpur
Facial Emotion Recognition using DeepLearning
Ankit Awasthi (Y8084)
CS 676:Computer Vision
Supervisor:
Dr. Amitabha Mukerjee , Department of Computer Science Engineering, IIT Kanpur
Dr. P Guha, TCS Labs, Delhi,India

ABSTRACT
Facial emotion recognition is one of the most important cognitive functions that our brain
performs quite efficiently. State of the art facial emotion recognition techniques are mostly
performance driven and do not consider the cognitive relevance of the model. This project
is an attempt to look at the task of emotion recognition using deep belief networks which
is cognitively very appealing and at the same has been shown to perform very well for digit
recognition (Hinton et.al. 2006). We look at the effects of varying number of hidden layers
and hidden units on the performance of the model and attempt to develop important insights
into the features learnt by the model. Also we observe that as found various psychological
findings our model finds lower spatial frequency more useful for recognizing facial expressions
than higher spatial frequency data.
1

Contents
1 Introduction 3
2 Motivation 4
3 Restricted Boltzmann Machine 4
4 Deep Belief Networks 5
5 JAFFE Dataset 5
6 Results 5
6.1 First Hidden Layer Features . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
6.2 Effect of Number of Layers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
6.3 Effect of Number of Hidden Units . . . . . . . . . . . . . . . . . . . . . . . . 8
6.4 Effect of Image Size . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
7 Discussion and Future Work 10
8 References 11
2

1 Introduction
Facial expression are important cues for non verbal communication among human beings.
This is only possible because humans are able to recognize emotions quite accurately and
efficiently. An automatic facial emotion recognition system is an important component in
human machine interaction. Apart from the commercial uses of an automatic facial emotion
recognition system it might be useful to incorporate some cues from the biological system
in the model and use the model to develop further insights into the cognitive processing of
our brain.
State of the art approaches in facial emotion recognition use Active Appearance Mod-
els(AAMs), FACS labels or some other sophisticated feature extraction scheme. AAMs can
be learned from a set of training images and can be fitted on a new face to generate the land-
mark positions which can further be used to design features. Thus, in an automatic setting
either the availability of landmark point on face images is assumed or can be obtained by
fitting the model. FACS labels attempt to decompose human emotions in terms of Action
Units(AUs) which correspond to specific muscle movements. FACS coding system is used
in psychology and animation to classify facial expressions in a consistent and systematic
manner.But as of now FACS labels can only be given by experts or trained individuals.
One problem with ad hoc feature extraction schemes is that we need to design separate
feature extraction mechanism foe each visual task to be perfomed. Moreover,it is known
that only some of the filters in the retina are hardcoded and the other units in the V1,V2
and higher areas of visual processing are learned.Hubel and Wiesel showed that irreversible
damage was produced in kittens by sufficient visual deprivation during the so called ”criti-
cal period”. Therefore,it makes much more sense to have generic scheme for learning what
transformations in the input space may lead to good features for performing a particular task.
There is ample evidence that our visual processing architecture is organized in different
levels. Each level transforms the input in a manner that facilitates the visual task to be
performed. Another appealing feature of deep learning models is that there can be feature
or sub-feature sharing. Computationally also, it has been shown that unsufficiently deep
architectures can be exponentially ineffiecient. Deep Learning was revolutionized by Hinton
et.al.[1] when they came up with a very efficient method for training multilayer neural net-
works.
3

2 Motivation
Deep Learning methods have performed very well in MNSIT digit recognition dataset[1].
Our setting is very similar to the task of digit recognition. Corresponding to the digit
labels we have emotion labels. But emotion recognition is much more complicated because
digit images are much simpler than face images depicting various expressions. Moreover
the variability in the images due to different identities hampers the performance. Human
accuracy in facial exression recognition is not as good as in digit recognition and is also aided
by other modes of information such as context,prior experience,speech among others.
3 Restricted Boltzmann Machine
The restricted Boltzmann machine(RBM) is a two-layer, undirected graphical model in which
there are no lateral connections. One layer of nodes is called the visible layer v,and the other
layer of nodes is called the hidden layer h. Each of these nodes are stochastic binary units
and each configuration of visible and hidden nodes is characterized by a energy which is
given by the following function
E(v, h) = −∑
i,j viWijhj −∑
j bjhj −∑
i civi
Probabilistically,this is interprated as follows:
P (v, h) = exp(−E(v,h)Z
If the visible units are real, energy function is defined as follows
E(v, h) = 12
∑i v
2i −
∑i,j viWijhj −
∑j bjhj −
∑i civi
The hidden nodes are conditionally independent given the visible layer and vice versa.
In particular, the conditional probabilities are as follows
P (v|h; θ) = Πip(vi|h) , P (h|v; θ) = Πjp(hj|v)
p(hj = 1|v) = sigmoid(∑
iWijvi + bj) For binary visible layer,
p(vj = 1|h) = sigmoid(∑
iWijhi + cj)
p(hj = 1|v) = sigmoid(∑
iWijvi + bj) For real valued visible layer, we have,
p(vj = 1|h) = N(∑
iWijhi + cj, sigma)
The parameters of the RBM can be learned by maximizing the log-likelihood of training
4

data using gradient ascent. But the exact gradient of the log-likelihood is intractable,thus
contrastive divergence is used which works fairly well in practice.The exact gradient is in-
tractable which is approximated by
exact gradient : ∂logp(v)∂Wij
= < vihj >0 −< vihj >
∞
CD approximation: ∂logp(v)∂Wij
= < vihj >0 −< vihj >
n
4 Deep Belief Networks
RBMs are only intersting because they can be efficiently stacked up layer by layer to form
a deep network. First an RBM is trained on the visible layer.Once trained the weights are
frozen and the hidden layer activations act as the input for the next RBM. Thus a DBN
with any number of layers can be formed by stacking RBMs as mentoined above. It has
also been shown [1] that increasing the number improves the variational lower bound on the
probability of the training data. RBM acts as a fundamental unit in the whole DBN. There
are other models that can be used instead of RBMs such autoencoders(sparse),denoising
autoencoders.Details about sparse autoencoder can be found in [5]. Once the layer by layer
model has been trained a final supervised fine tuning step which adjusts the weights to im-
prove the performance on the particular task in hand
5 JAFFE Dataset
Japanese Female Facial Expression (JAFFE) Database - The database contains 213 images
of 7 facial expressions (6 basic facial expressions + 1 neutral) posed by 10 Japanese female
models. Each image has been rated on 6 emotion adjectives by 60 Japanese subjects. Some
of the emotions (fear) have been reported to not have been expressed very well. But in this
project we are working with all the six emotions rather a reduced set of emotions.
6 Results
In this project , we experimented with a lot of different settings of the model hyperarameters
to find how they affect the performance. Few variants to the conventionall DBNs were tried
such as sparse DBNs and stacking up sparse autoencoders but the results did not show any
improvement and hence corresponding results have not been reported. In all the results,
the models were trained using 150 training images and tested on the remaining 63 images.
5

Figure 1: features learned by the first layer of DBN, image size: 24 x 24, hidden layer: 50
units
Deep Belief Networks typically require large amount of data but in our case we have only 213
images. Thus the results may change significantly if a larger dataset is used.The experiments
were performed at three resolutions: 100 X 100, 50 X 50 ,25 X 25. The results for various
experiments are stated as follows and would be discussed in the next section.
6.1 First Hidden Layer Features
Figure 1, 2, 3 show the features learned by the first hidden layer. It can be observed the when
the images are large it is difficult to the features learned are not of good quality. Moreover
the number of epochs required to get any meaningful features increases with the image size.
Although there is no quantitative way of discriminating between these features other than
the recognition task itself (which is also an indirect method), visually the features for smaller
image sizes appear to be better than that in case of bigger image size. Projection of higher
layer features on the input space is a non-trivial task and has not been dealt with here.
6.2 Effect of Number of Layers
Figure 4 shows how the performance varies over the number of epochs of supervised fine
tuning step for 24x24 image size. Figure 5, 6 show the performance for image sizes 50x50
and 100x100 respectively. As shown in the figures, increase in the number of layers resulted
6

Figure 2: features learned by the first layer of DBN, image size: 50 x 50,hidden layer: 100
units
Figure 3: features learned by the first layer of DBN, image size:100 x 100,hidden layer: 500
units
7
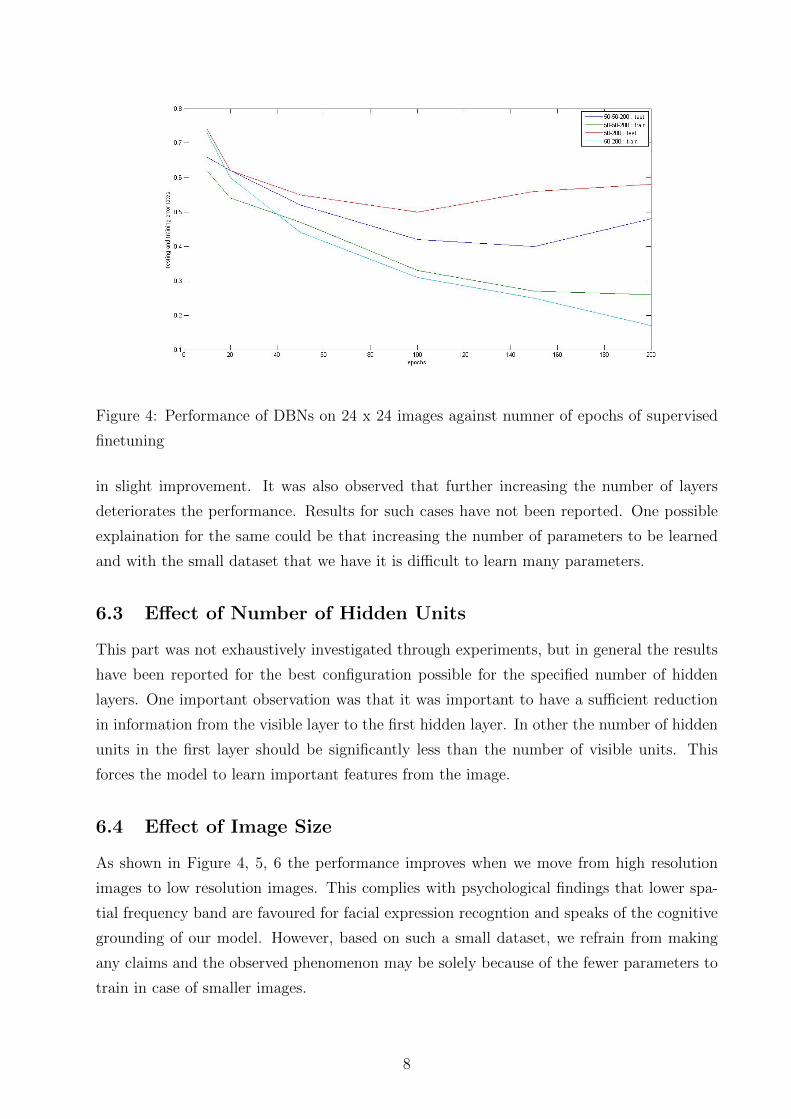
Figure 4: Performance of DBNs on 24 x 24 images against numner of epochs of supervised
finetuning
in slight improvement. It was also observed that further increasing the number of layers
deteriorates the performance. Results for such cases have not been reported. One possible
explaination for the same could be that increasing the number of parameters to be learned
and with the small dataset that we have it is difficult to learn many parameters.
6.3 Effect of Number of Hidden Units
This part was not exhaustively investigated through experiments, but in general the results
have been reported for the best configuration possible for the specified number of hidden
layers. One important observation was that it was important to have a sufficient reduction
in information from the visible layer to the first hidden layer. In other the number of hidden
units in the first layer should be significantly less than the number of visible units. This
forces the model to learn important features from the image.
6.4 Effect of Image Size
As shown in Figure 4, 5, 6 the performance improves when we move from high resolution
images to low resolution images. This complies with psychological findings that lower spa-
tial frequency band are favoured for facial expression recogntion and speaks of the cognitive
grounding of our model. However, based on such a small dataset, we refrain from making
any claims and the observed phenomenon may be solely because of the fewer parameters to
train in case of smaller images.
8
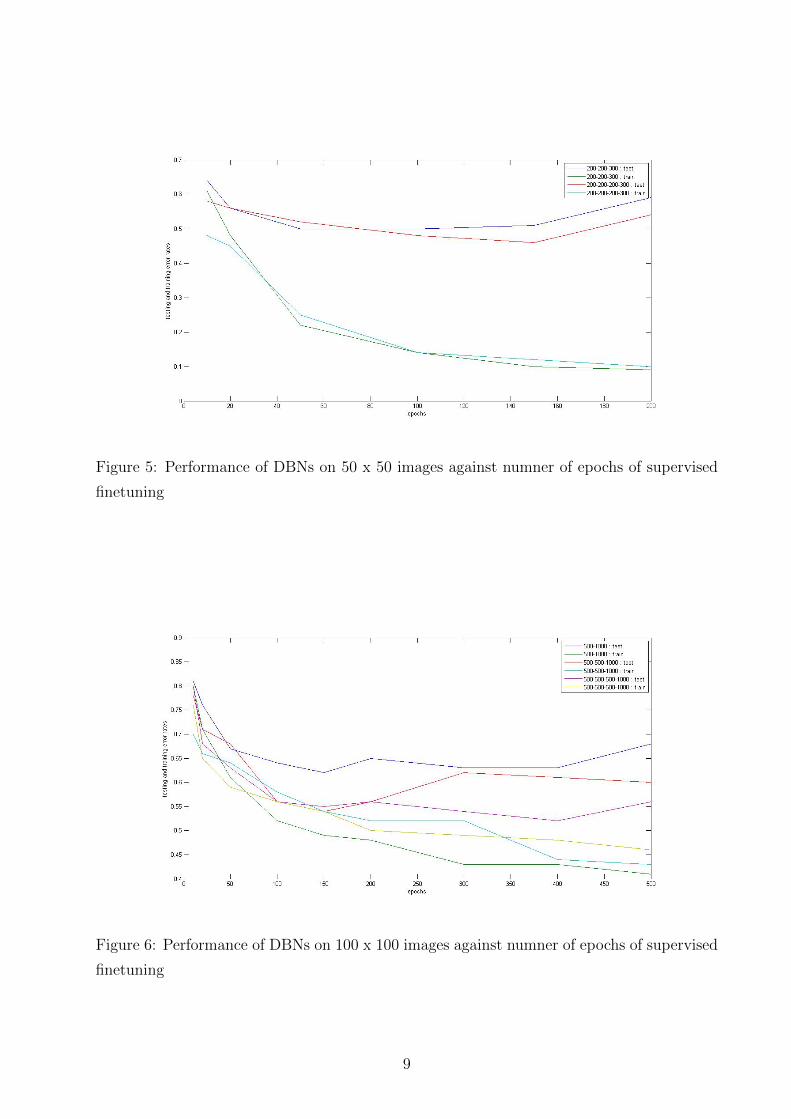
Figure 5: Performance of DBNs on 50 x 50 images against numner of epochs of supervised
finetuning
Figure 6: Performance of DBNs on 100 x 100 images against numner of epochs of supervised
finetuning
9

7 Discussion and Future Work
Accuracy of state of state of the art facial emotion recognition systems is much better than
arrived at in the project. Considering that the algorithm takes raw images rather landmark
points or FACS labels as input, it performs fairly well. The dataset used in the project was
quite small and prohibits any general claim about the success or failure of deep learning
methods. It is expected that a larger dataset would improve the accuracy of the algorithm
and better features would be learned. This comprises a major portion of our future work in
this project
. Observing the features one may say that algorithm is able to extract some meaningful
features. In the absence of any principled way of discrminating the receptive fields learned
by the model it becomes difficult to argue about the ’goodness’ or’badness’ of a feature other
than evaluating the classfication accuracy that the feature facilitates.
As observed increasing number of hidden layers resulted in a slight improvement in classifi-
cation, but further increase in hidden layers however deteriorated the results. The number
of hidden units in each layer was one of the hyperparameters which wasnt satisfactorily in-
vestigated but an important and somewhat counter-intuitive observation that came up was
that the number of hidden units in the first layer should be less than the number of visible
units which in other words means that there should be a significant redcution in the amount
of information from the visible layer to the first hidden layer. This is appealing because
soemhing very similar happens in our visul system where a lot of information is thrown out
in successive layers of processing. What this does is that it forces the hidden units to learn
the most important features. Led by this observation,we thought that sparsity constraints
might lead to even better features and accuracy but as it turned out that there was not any
improvement. Again, this might be attributed to the small dataset we are working with.
One of the imortant results coming out of this project is the observation that low resolution
images had better classification accuracy than higher resolution images. Various psycholog-
ical experiments done on human beings suggest that we make use of mid spatial frequency
band for recognizing emotions rather than thehigh spatial frequency band. Although here,we
do not present any quantitative similarities for spatial frequency versus classification accu-
racy, the few experiments that we performed suggest that lower spatial frequency informa-
tion is more useful for recognizing emotions which speaks for the cognitive relevance of the
model.In our future work we would like to work quantitative ways of evaluating cognitive
imporatnce of features which would help argue for DBNs as a very good model of our visual
system.
10

8 References
References
[1] Geoffrey E. Hinton, Yee-Whye Teh and Simon Osindero, A Fast Learning Algorithm for
Deep Belief Nets. Neural Computation, pages 1527-1554, Volume 18, 2008.
[2] Susskind, J.M. and Hinton, G.E. and Movellan, J.R. and Anderson, A.K., Generat-
ing facial expressions with deep belief nets, Affective Computing, Emotion Modelling,
Synthesis and Recognition, pages 421-440,2009
[3] Michael J. Lyons, Shigeru Akamatsu, Miyuki Kamachi & Jiro Gyoba , Coding Facial
Expressions with Gabor Wavelets,Proceedings, Third IEEE International Conference on
Automatic Face and Gesture Recognition,pp 200-205, 1-19.April 14-16 1998
[4] Geoffrey E. Hinton (2010). A Practical Guide to Training Restricted Boltzmann Ma-
chines,Technical Report,Volume 1
[5] Andrew Ng. (2010). Sparse autoencoder(lecture notes).
[6] Honglak Lee, Chaitanya Ekanadham, Andrew Y. Ng, Sparse deep belief net model for
visual area V2NIPS,2007
11







![Integration of Driver Behavior into Emotion Recognition ... · [2] Unimodal Facial Emotion Recognition. 6 70.2% [3] Unimodal Speech Emotion Recognition 3 88.1% [4] Unimodal Speech](https://static.fdocuments.us/doc/165x107/5f082e657e708231d420be2a/integration-of-driver-behavior-into-emotion-recognition-2-unimodal-facial.jpg)










