
Eyeriss: An Energy-Efficient Reconfigurable Accelerator ... · © 2016 IEEE 14.5: Eyeriss: An...
44
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 1 of 43 Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks Yu-Hsin Chen 1 , Tushar Krishna 1 , Joel Emer 1, 2 , Vivienne Sze 1 1 MIT 2 NVIDIA
Transcript of Eyeriss: An Energy-Efficient Reconfigurable Accelerator ... · © 2016 IEEE 14.5: Eyeriss: An...

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 1 of 43
Eyeriss: An Energy-Efficient Reconfigurable Accelerator
for Deep Convolutional Neural Networks
Yu-Hsin Chen1, Tushar Krishna1, Joel Emer1, 2, Vivienne Sze1
1 MIT 2 NVIDIA

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 2 of 43
Future of Deep Learning
Recognition Self-Driving Cars AI
DCNN Accelerator is Crucial • High Throughput for Real-time
Processing • Sub-watt Power/Energy
Consumption
DPM
Accuracy 0.1k – 0.5k OP/Px
DCNN 15k – 300k OP/Px
Computation
• DPM: Deformable Part Model

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 3 of 43
DCNN Explained
Convolution Activation
×
Norm. Pooling
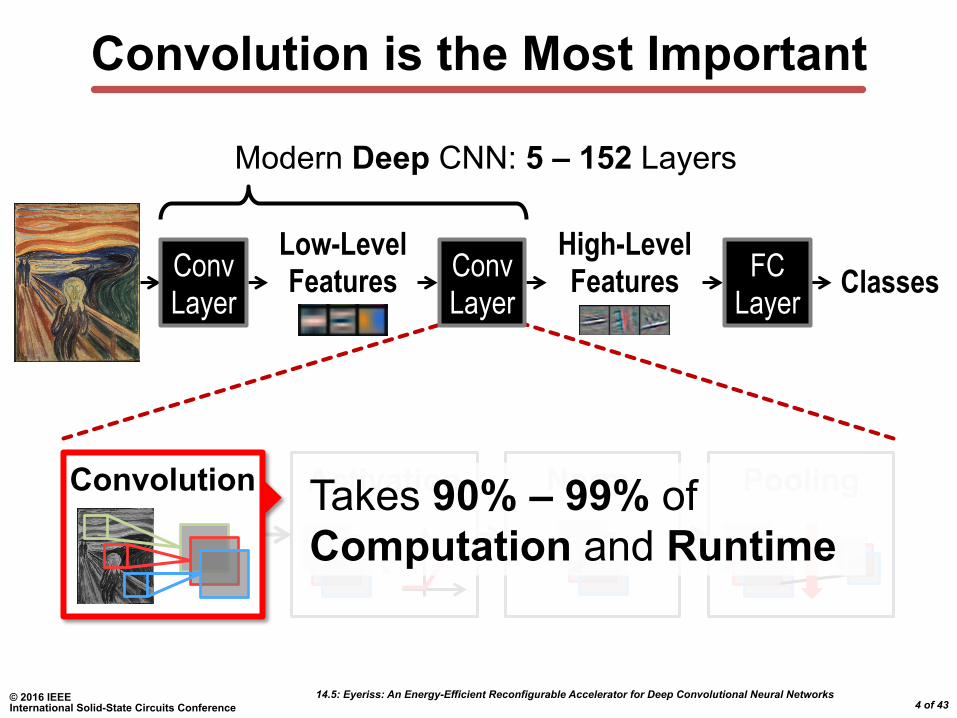
Modern Deep CNN: 5 – 152 Layers
Classes Conv Layer
Conv Layer
FC Layer
Low-Level Features
High-Level Features
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 4 of 43
Convolution is the Most Important
Activation
×
Norm. Pooling
Modern Deep CNN: 5 – 152 Layers
Classes Conv Layer
Conv Layer
FC Layer
Low-Level Features
High-Level Features
Convolution Takes 90% – 99% of Computation and Runtime

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 5 of 43
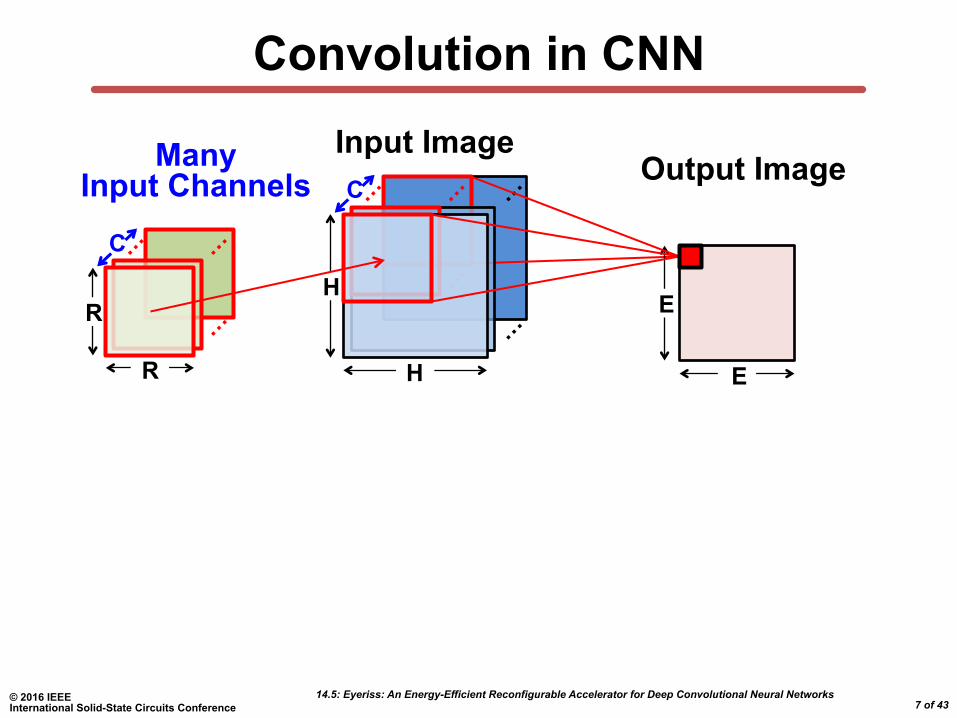
Convolution in CNN
E
E
R
R
H
H
Input Image Output Image Filter

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 6 of 43
Convolution in CNN
E
E
R
R
H
H dot
product partial sum
accumulation
Input Image Output Image Filter
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 7 of 43
Convolution in CNN
E
E
R
R
C
H
H
C Many
Input Channels Input Image
Output Image

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 8 of 43
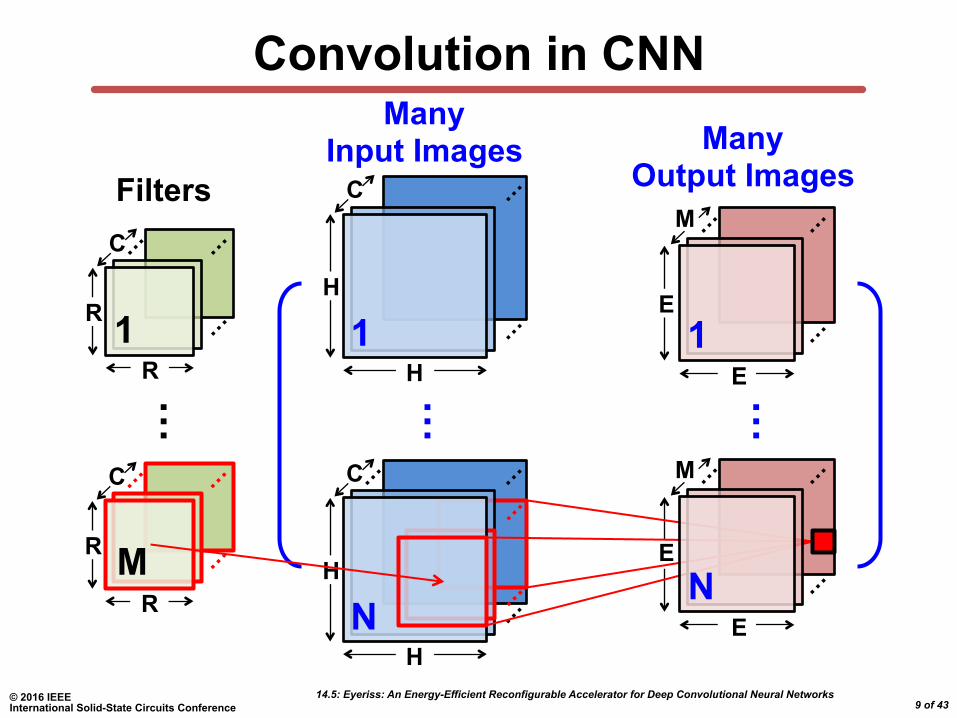
Convolution in CNN
E
Input Image Output Image
R
R
C
H
H
C
R
R
C
E
Many Filters
1
M
Many Output Channels
M
…
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 9 of 43
Convolution in CNN
Filters
R
R
C
H
H
C
…
E
E
M
M
…
R
R
C
H
H
C
1
N
1
M
1
Many Input Images Many
Output Images …
E
E N
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 10 of 43
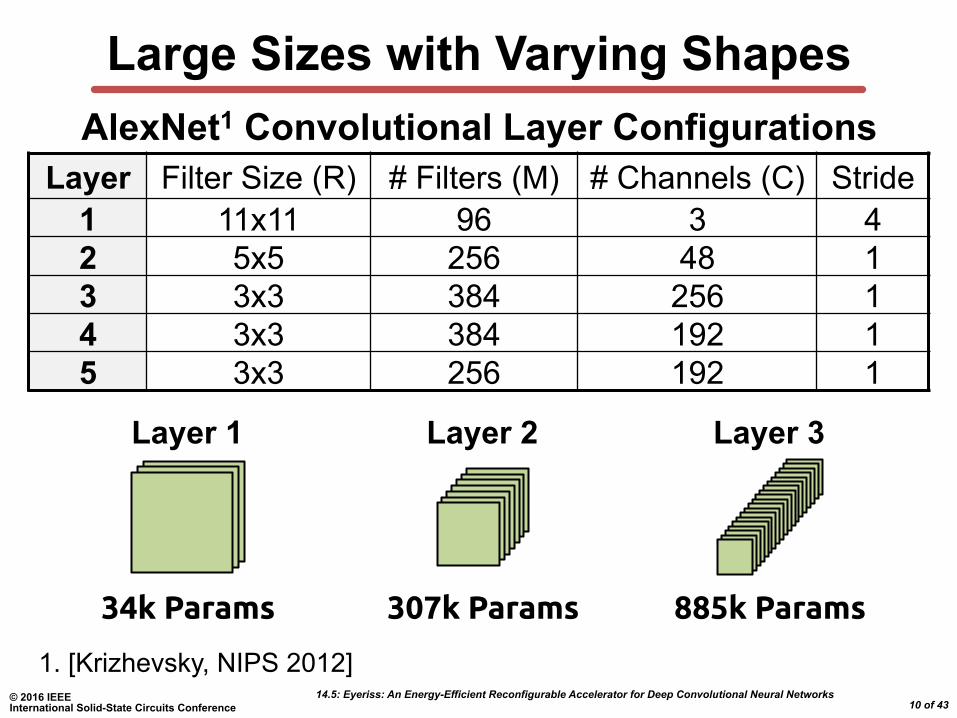
Large Sizes with Varying Shapes
Layer Filter Size (R) # Filters (M) # Channels (C) Stride 1 11x11 96 3 4 2 5x5 256 48 1 3 3x3 384 256 1 4 3x3 384 192 1 5 3x3 256 192 1
AlexNet1 Convolutional Layer Configurations
34k Params 307k Params 885k Params
Layer 1 Layer 2 Layer 3
1. [Krizhevsky, NIPS 2012]
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 11 of 43
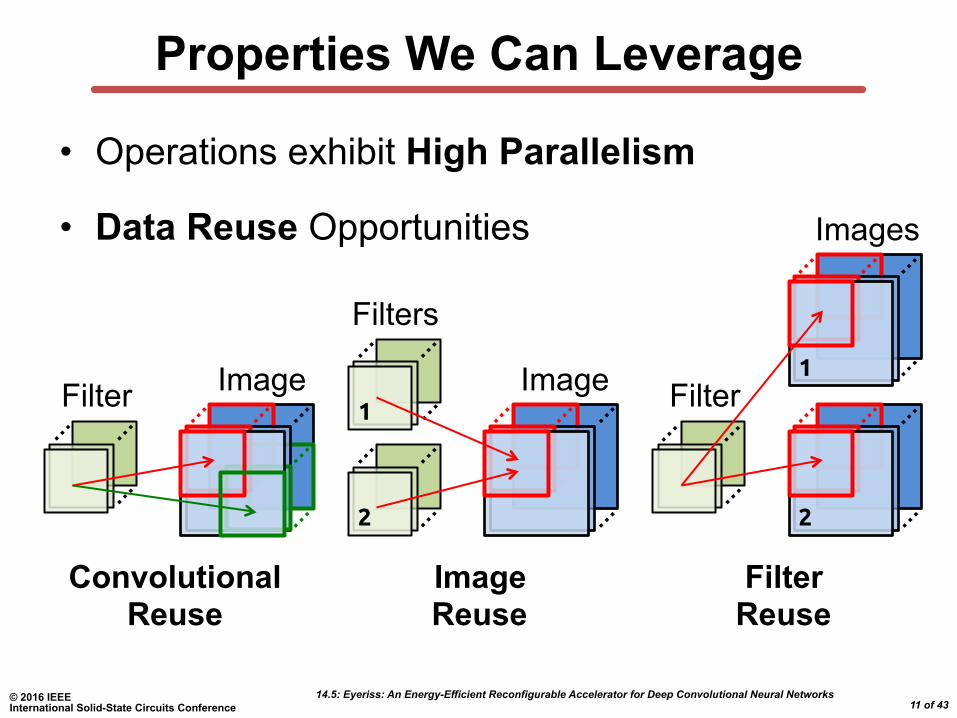
Properties We Can Leverage
• Operations exhibit High Parallelism
• Data Reuse Opportunities
Convolutional Reuse
Filter Image
Image Reuse
2
1
Filters
Image
Filter Reuse
Filter
Images
2
1

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 12 of 43
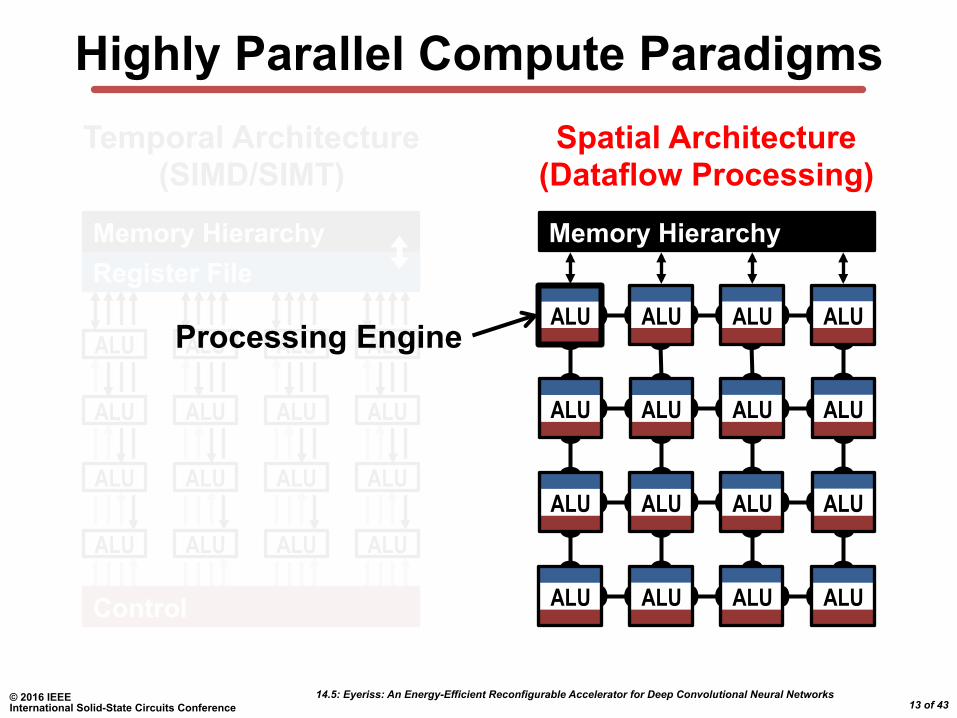
Highly Parallel Compute Paradigms Spatial Architecture
(Dataflow Processing) Temporal Architecture
(SIMD/SIMT)
Register File Memory Hierarchy
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
Control
Memory Hierarchy
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 13 of 43
Highly Parallel Compute Paradigms Spatial Architecture
(Dataflow Processing) Temporal Architecture
(SIMD/SIMT)
Register File Memory Hierarchy
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
Control
Memory Hierarchy
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU Processing Engine

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 14 of 43
Highly Parallel Compute Paradigms Spatial Architecture
(Dataflow Processing) Temporal Architecture
(SIMD/SIMT)
Register File Memory Hierarchy
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
Control
Memory Hierarchy
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
Flexible Configuration with autonomous local control

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 15 of 43
Highly Parallel Compute Paradigms Spatial Architecture
(Dataflow Processing) Temporal Architecture
(SIMD/SIMT)
Register File Memory Hierarchy
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
Control
Memory Hierarchy
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
Flexible Configuration with autonomous local control
Efficient Data Reuse thru. distributed local storage

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 16 of 43
Highly Parallel Compute Paradigms Spatial Architecture
(Dataflow Processing) Temporal Architecture
(SIMD/SIMT)
Register File Memory Hierarchy
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
Control
Memory Hierarchy
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
ALU ALU ALU ALU
Flexible Configuration with autonomous local control
Efficient Data Reuse thru. distributed local storage
Natural Dataflow Mapping in-place data consumption

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 17 of 43
Hardware Architecture • Reduce Data Movement • Exploit Data Statistics

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 18 of 43
The DCNN Accelerator Architecture
Off-Chip DRAM
…
…
…
… …
…
Decomp
Comp ReLU
Input Image
Output Image
Filter Filt
Img
Psum
Psum
Buffer SRAM
108KB
64 bits
DCNN Accelerator
14×12 PE Array
Link Clock Core Clock

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 19 of 43
Hardware Architecture • Reduce Data Movement • Exploit Data Statistics
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 20 of 43
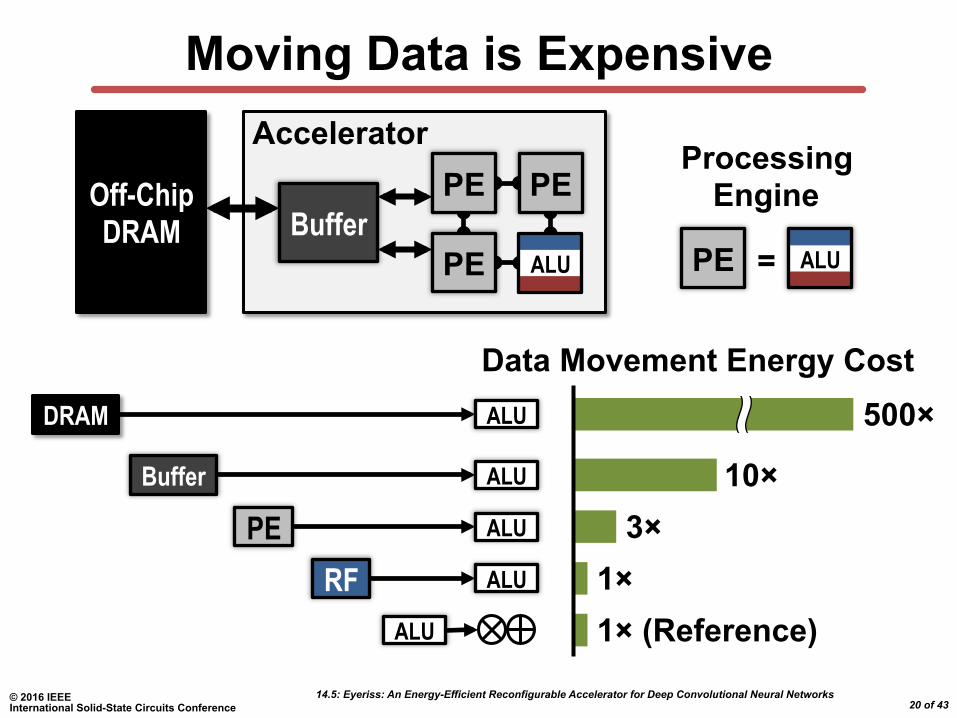
Moving Data is Expensive
DRAM ALU
Buffer ALU
PE ALU
RF ALU
ALU
Data Movement Energy Cost 500×
10× 3×
1× 1× (Reference)
Off-Chip DRAM
ALU = PE
Processing Engine
Accelerator
Buffer PE
PE PE
ALU

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 21 of 43
Maximize Data Reuse within PE Input Image
Filter Output Image
* =

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 22 of 43
Maximize Data Reuse within PE Input Image Row
Filter Row Partial Sums
= *

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 23 of 43
Maximize Data Reuse within PE Input Image Row Filter Row Partial Sums
= * Image Spad
PSum Spad
Filter Spad
Img
Filt 1
0
Input
Psum Output Psum
Processing Engine

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 24 of 43
Maximize Data Reuse within PE Input Image Row Filter Row Partial Sums
= * Image Spad
PSum Spad
Filter Spad
Img
Filt 1
0
Input
Psum Output Psum
Processing Engine

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 25 of 43
Maximize Data Reuse within PE Array
Filter Input Image
Output Image Row 1 Row 2 Row 3
Row 1 Row 2 Row 3 Row 4 Row 5
Row 1 Row 2 Row 3
= *
PE … PE
Map a pair of Filter Row and Image Row to each PE

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 26 of 43
Convolutional Reuse within PE Array
Row 1 Row 2 Row 3
PE PE PE
Row 1 Row 1
PE PE PE
Row 2
Row 2
Row 4 Row 5
PE
Row 3 Row 3
PE PE
Mapping rows from multiple channels and/or multiple filter/images to each PE results in even more reuse
filter weights
input images
partial sums
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 27 of 43
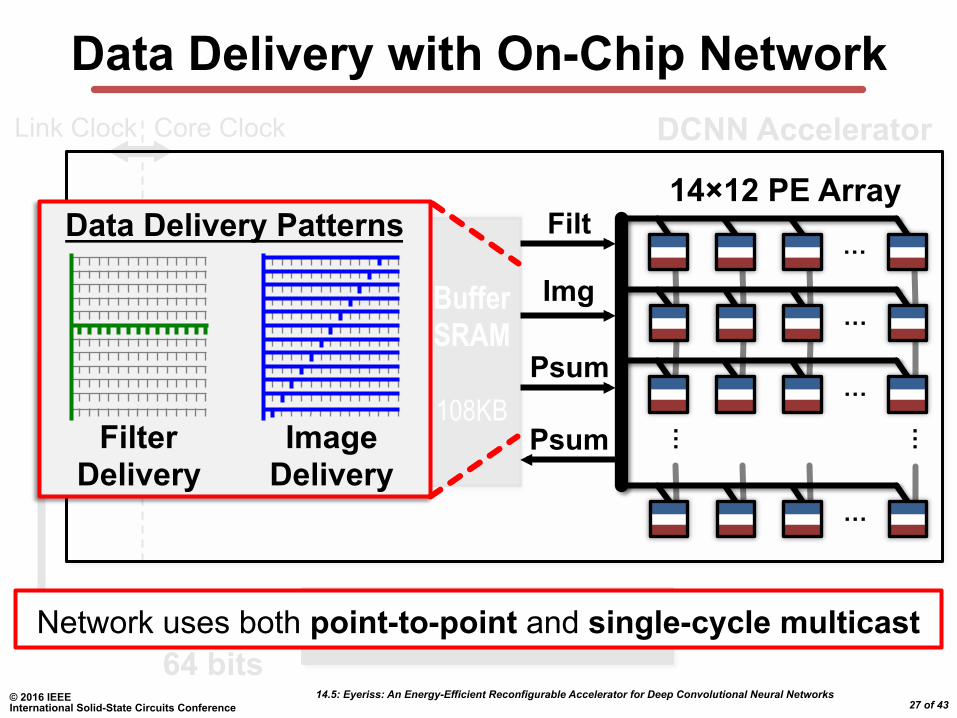
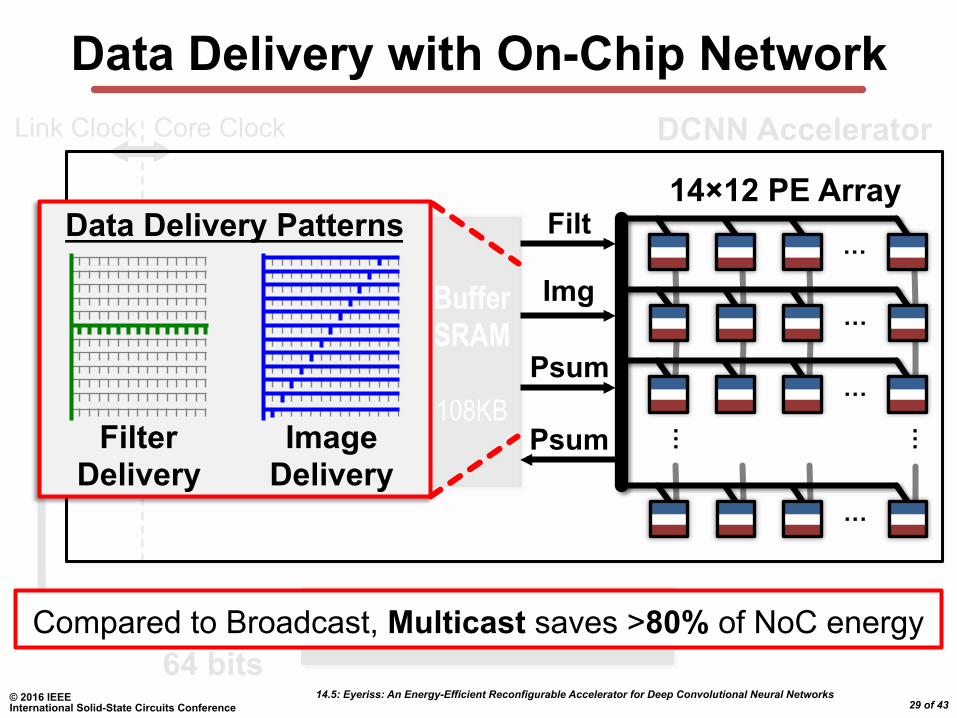
Data Delivery with On-Chip Network
Off-Chip DRAM
Decomp
Comp ReLU
Input Image
Output Image
Filter
Buffer SRAM
108KB
64 bits
DCNN Accelerator
Link Clock Core Clock
…
…
…
… …
…
Filt
Img
Psum
Psum
14×12 PE Array
Filter Delivery
Image Delivery
Data Delivery Patterns
Network uses both point-to-point and single-cycle multicast

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 28 of 43
Multicast Network Design
Buffer
Global Y-Bus
Global X-Bus
Global X-Bus
Local Link
[Data, Col], <Row> [Data], <Col>
[Data]
[Input] <Tag>
Multicast Controller ID (configurable) Output
if (Tag == ID) Output = Input
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 29 of 43
Data Delivery with On-Chip Network
Off-Chip DRAM
Decomp
Comp ReLU
Input Image
Output Image
Filter
Buffer SRAM
108KB
64 bits
DCNN Accelerator
Link Clock Core Clock
…
…
…
… …
…
Filt
Img
Psum
Psum
14×12 PE Array
Filter Delivery
Image Delivery
Data Delivery Patterns
Compared to Broadcast, Multicast saves >80% of NoC energy

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 30 of 43
Logical to Physical Mappings
Replication Folding
..
.. .. ..
..
.. 3
13 AlexNet Layer 3-5
12
14
Physical PE Array
3
3
3
3
13
13
13
13
.. .. .. ..
..
.. 5
27 AlexNet Layer 2
Physical PE Array
12
14
5 14
13 5

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 31 of 43
Logical to Physical Mappings
Replication Folding
..
.. .. ..
..
.. 3
13 AlexNet Layer 3-5
12
14
Physical PE Array
3
3
3
3
13
13
13
13
.. .. .. ..
..
.. 5
27 AlexNet Layer 2
Physical PE Array
12
14
5 14
13 5
Unused PEs are
Clock Gated
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 32 of 43
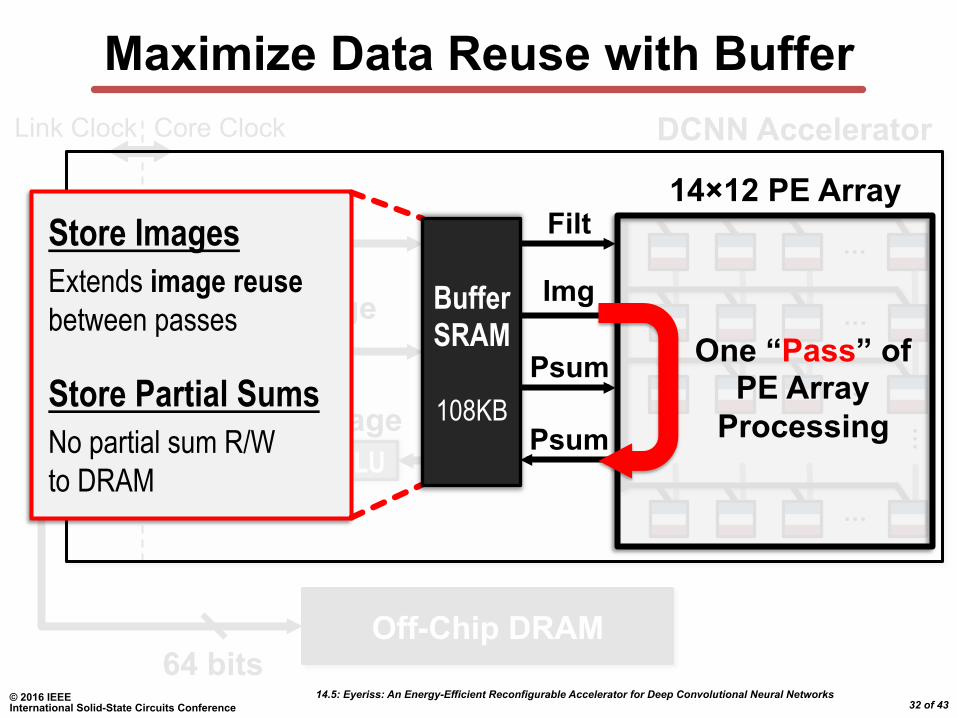
Maximize Data Reuse with Buffer
Off-Chip DRAM
…
…
…
… …
…
Decomp
Comp ReLU
Input Image
Output Image
Filter
64 bits
DCNN Accelerator
Link Clock Core Clock
Filt 14×12 PE Array
One “Pass” of PE Array
Processing
Store Images Extends image reuse between passes
Store Partial Sums No partial sum R/W to DRAM
Buffer SRAM
108KB
Img
Psum
Psum

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 33 of 43
Hardware Architecture • Reduce Data Movement • Exploit Data Statistics

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 34 of 43
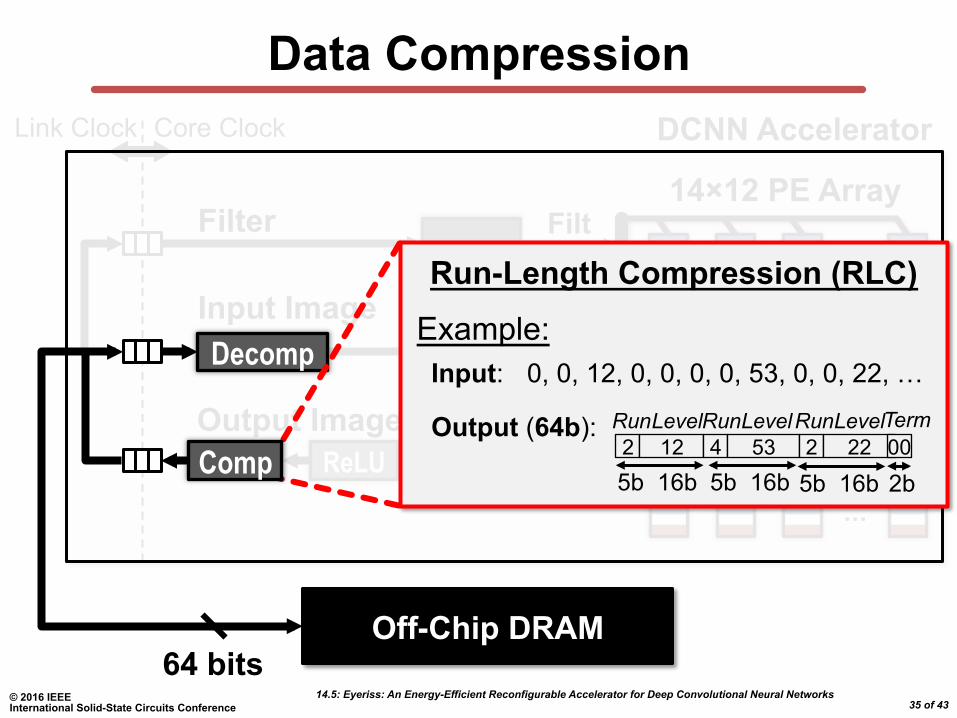
Data Compression
9 -1 -3 1 -5 5 -2 6 -1
Apply Activation (ReLU) on Filtered Image Data ReLU 9 0 0
1 0 5 0 6 0
0
1
2
3
4
5
6
1 2 3 4 5
DRAM
Access(MB)
AlexNetConvLayer
Uncompressed Compressed
1 2 3 4 5 AlexNet Conv Layer
DRAM Access
(MB)
0
2
4
6 1.2×
1.4× 1.7×
1.8× 1.9×
Uncompressed Filters + Images
Compressed Filters + Images
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 35 of 43
…
…
…
… …
…
ReLU
Input Image
Output Image
Filter Filt
Img
Psum
Psum
Buffer SRAM
108KB
DCNN Accelerator
14×12 PE Array
Link Clock Core Clock
Data Compression
Run-Length Compression (RLC)
Example:
Output (64b):
Input: 0, 0, 12, 0, 0, 0, 0, 53, 0, 0, 22, …
5b 16b 2b 5b 16b 5b 16b 2 12 4 53 2 22 00
Run Level Run Level Run Level Term
Off-Chip DRAM 64 bits
Decomp
Comp

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 36 of 43
Data Gating / Zero Skipping
Filter Scratch Pad
(225x16b SRAM)
Partial Sum Scratch Pad
(24x16b REG)
Filt
Img
Input Psum
2-stage pipelined multiplier
Output Psum
0
Accumulate Input Psum
1
0
== 0 Zero Buffer
Enable
Image Scratch Pad
(12x16b REG)
0 1
Skip mult and mem reads when image data is zero.
Reduce PE power by 45%
Reset

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 37 of 43
Results

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 38 of 43
Chip Spec & Measurement Results Technology TSMC 65nm LP 1P9M Core Area 3.5mm×3.5mm Gate Count 1852 kGates (NAND2) On-Chip Buffer 108 KB # of PEs 168 Scratch Pad / PE 0.5 KB Supply Voltage 0.82 – 1.17 V Core Frequency 100 – 250 MHz Peak Performance
33.6 – 84.0 GOPS (2 OP = 1 MAC)
Word Bit-width 16-bit Fixed-Point
Filter Size* 1 – 32 [width] 1 – 12 [height]
# of Filters* 1 – 1024 # of Channels* 1 – 1024
Stride Range 1–12 [horizontal] 1, 2, 4 [vertical] * Natively Supported
4000 µm
4000 µm
On-c
hip
Buffe
r Spatial PE Array

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 39 of 43
Benchmark – AlexNet Performance
Image Batch Size of 4 (i.e. 4 frames of 227x227) Core Frequency = 200MHz / Link Frequency = 60 MHz
Layer Power (mW)
Latency (ms)
# of MAC (MOPs)
Active # of PEs (%)
Buffer Data Access (MB)
DRAM Data Access (MB)
1 332 20.9 422 154 (92%) 18.5 5.0 2 288 41.9 896 135 (80%) 77.6 4.0 3 266 23.6 598 156 (93%) 50.2 3.0 4 235 18.4 449 156 (93%) 37.4 2.1 5 236 10.5 299 156 (93%) 24.9 1.3
Total 278 115.3 2663 148 (88%) 208.5 15.4
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 40 of 43
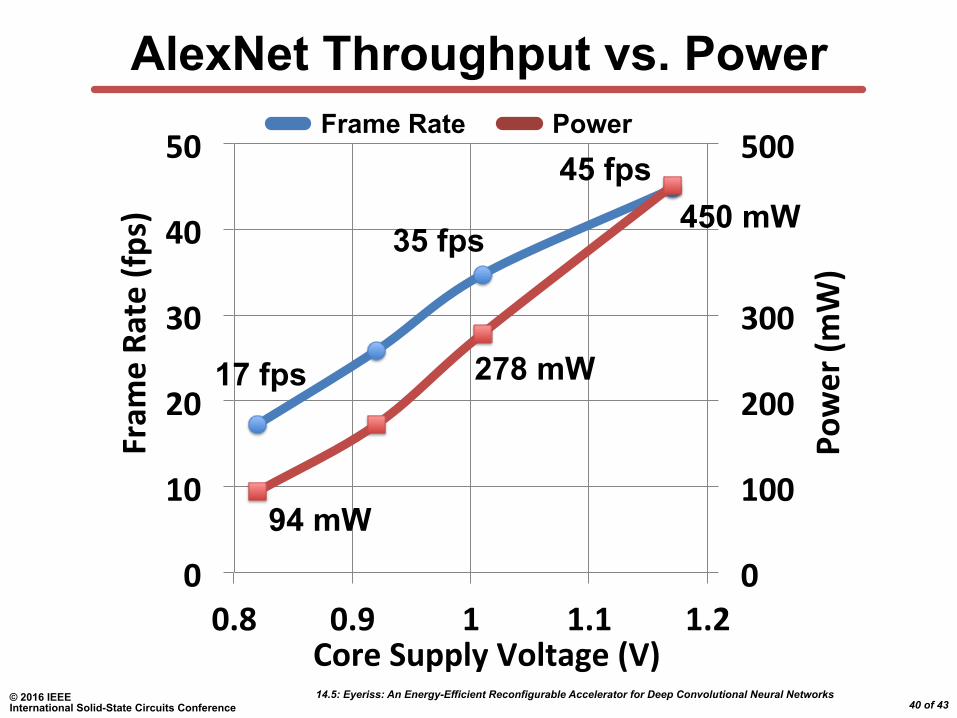
AlexNet Throughput vs. Power
0
100
200
300
400
500
0
10
20
30
40
50
0.8 0.9 1 1.1 1.2
Power(m
W)
Fram
eRa
te(fps)
CoreSupplyVoltage(V)
FrameRate Power
35 fps
45 fps
17 fps 278 mW
94 mW
450 mW
Frame Rate Power
14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 41 of 43
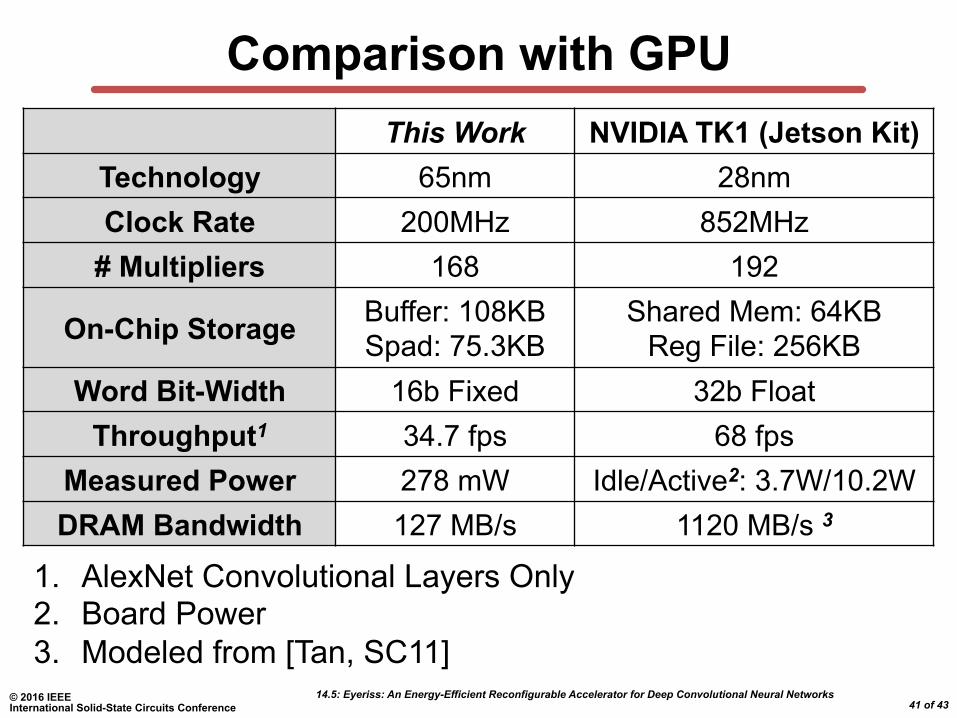
Comparison with GPU This Work NVIDIA TK1 (Jetson Kit)
Technology 65nm 28nm Clock Rate 200MHz 852MHz
# Multipliers 168 192
On-Chip Storage Buffer: 108KB Spad: 75.3KB
Shared Mem: 64KB Reg File: 256KB
Word Bit-Width 16b Fixed 32b Float Throughput1 34.7 fps 68 fps
Measured Power 278 mW Idle/Active2: 3.7W/10.2W
DRAM Bandwidth 127 MB/s 1120 MB/s 3
1. AlexNet Convolutional Layers Only 2. Board Power 3. Modeled from [Tan, SC11]

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 42 of 43
Demo (DS2 Today!)
AlexNet: [Krizhevsky, NIPS 2012]
Video Link: https://vimeo.com/154012013

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 43 of 43
Summary • A 278mW reconfigurable accelerator for
state-of-the-art deep CNNs – A 168-PE spatial architecture that supports an
efficient dataflow to minimize data movement – A configurable multicast NoC that saves energy
compared to a broadcast design • Exploits data statistics for higher efficiency
– Compression to reduce memory bandwidth – Zero-skipping logic to reduce PE power
• Integrated with the Caffe DL framework and demonstrated an image classification system
Acknowledgement: funding by DARPA YFA, MIT CICS and a gift from Intel

14.5: Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks © 2016 IEEE International Solid-State Circuits Conference 44 of 43


















