Experience-Based Chess Play Robert Levinson Machine Intelligence Lab University of California, Santa...
71
Experience-Based Experience-Based Chess Play Chess Play Robert Levinson Robert Levinson Machine Intelligence Lab Machine Intelligence Lab University of University of California, California, Santa Cruz Santa Cruz Stanford ML Seminar March 16, 2005
-
date post
20-Dec-2015 -
Category
Documents
-
view
216 -
download
1
Transcript of Experience-Based Chess Play Robert Levinson Machine Intelligence Lab University of California, Santa...

Experience-Based Experience-Based Chess PlayChess Play
Robert LevinsonRobert LevinsonMachine Intelligence LabMachine Intelligence LabUniversity of California,University of California,
Santa CruzSanta Cruz
Stanford ML Seminar
March 16, 2005

OutlineOutline
1. Review of State-of-the-art in Games2. Review of Computer Chess Method3. Blindspots and Unsolved Issues================== 4. Morph 4a. Philosophy and Results 4b. Patterns/Evaluation 4c. Learning * Td-learning * Neural Nets * Genetic Algorithms

Why Chess?Why Chess?
• Human/computer approaches very different• Most studied game• Well-known internationally and by public• Cognitive studies available• Accurate, well-defined rating system !• Complex and Non-Uniform• John McCarthy, Alan Turing, Claude
Shannon, Herb Simon and Ken Thompson and….• Game theoretic value unknown• Active Research Community/Journal

State of the artState of the art

State of the art (2)State of the art (2)

State of the art (3)State of the art (3)

Kasparov vs. Deep BlueKasparov vs. Deep Blue• 1. Deep Blue can examine and evaluate up to 200,000,000 chess positions per
second• Garry Kasparov can examine and evaluate up to three chess positions per second• 2. Deep Blue has a small amount of chess knowledge and an enormous amount of
calculation ability.• Garry Kasparov has a large amount of chess knowledge and a somewhat smaller
amount of calculation ability.• 3. Garry Kasparov uses his tremendous sense of feeling and intuition to play world
champion-calibre chess.• Deep Blue is a machine that is incapable of feeling or intuition.• 4. Deep Blue has benefitted from the guidance of five IBM research scientists and one
international grandmaster.• Garry Kasparov is guided by his coach Yuri Dokhoian and by his own driving passion
to play the finest chess in the world.• 5. Garry Kasparov is able to learn and adapt very quickly from his own successes and
mistakes.• Deep Blue, as it stands today, is not a "learning system." It is therefore not capable
of utilizing artificial intelligence to either learn from its opponent or "think" about the current position of the chessboard.
• 6. Deep Blue can never forget, be distracted or feel intimidated by external forces (such as Kasparov's infamous "stare").
• Garry Kasparov is an intense competitor, but he is still susceptible to human frailties such as fatigue, boredom and loss of concentration.

Recent Man vs. Machine Recent Man vs. Machine MatchesMatches
• Garry Kasparov versus Deep Junior, January 26 - February 7, 2003
in New York City, USA. Result: 3 - 3 draw.
• Evgeny Bareev versus Hiarcs-X, January 28 - 31 , 2003 in Maastricht, Netherlands. Result: 2 - 2 draw.
• Vladimir Kramnik versus Deep Fritz, October 2 - 22, 2002 in Manama, Bahrain. Result: 4 - 4 draw.

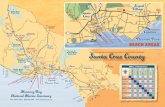
Minimax ExampleMinimax Example
Min
4 7 9 6 9 8 8 5 6 7 5 2 3 2 5 4 9 3
terminal nodes: values calculated from some evaluation function
Max
Max
Max
Min
Min
4 7 9 6 9 8 8 5 6 7 5 2 3 2 5 4 9 3
4 7 6 2 6 3 4 5 1 2 5 4 1 2 6 3 4 3
other nodes: values calculated via minimax algorithm

Max
Max
Min
Min
4 7 9 6 9 8 8 5 6 7 5 2 3 2 5 4 9 3
4 7 6 2 6 3 4 5 1 2 5 4 1 2 6 3 4 3
7 6 5 5 6 4

Max
Max
Min
Min
4 7 9 6 9 8 8 5 6 7 5 2 3 2 5 4 9 3
4 7 6 2 6 3 4 5 1 2 5 4 1 2 6 3 4 3
7 6 5 5 6 4
5 3 4
Max
Max
Min
Min
4 7 9 6 9 8 8 5 6 7 5 2 3 2 5 4 9 3
4 7 6 2 6 3 4 5 1 2 5 4 1 2 6 3 4 3
7 6 5 5 6 4
5 3 4
5
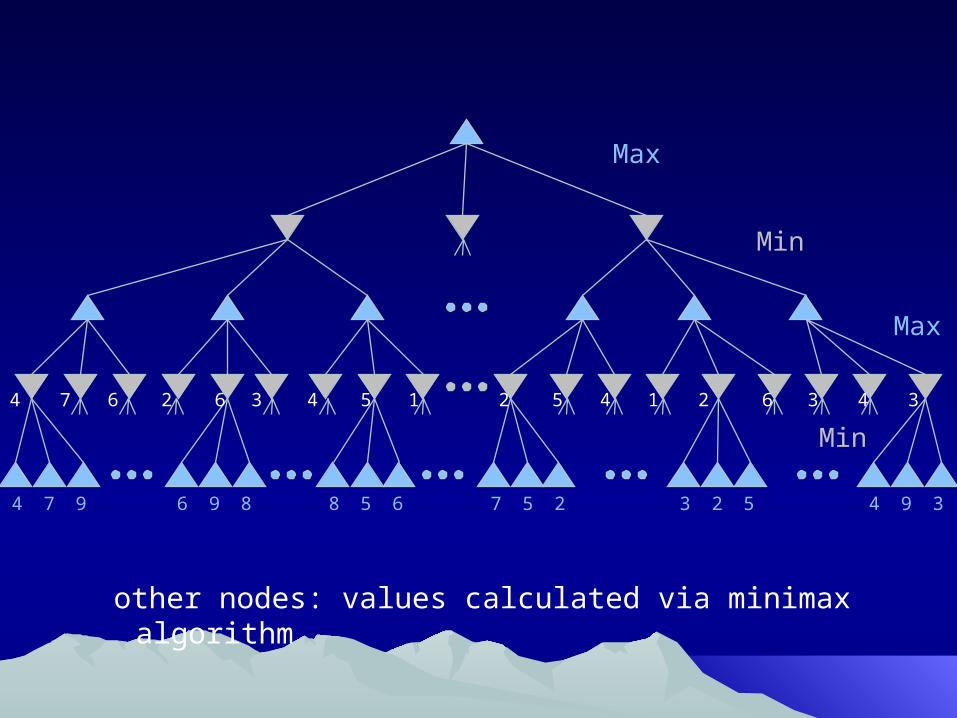
Max makes first move down the left hand side of the tree, in the expectation that countermove by Min is now predicted. After Min makes move, tree will need to be regenerated and the minimax procedure re-applied to new tree
Actual move made by Max
Possible later moves

Max
Max
Min
Min
4 7 9 6 9 8 8 5 6 7 5 2 3 2 5 4 9 3
4 7 6 2 6 3 4 5 1 2 5 4 1 2 6 3 4 3
7 6 5 5 6 4
5 3 4
5

Computer chessComputer chess
Let's say you start with a chess board set up for the start of a game. Each player has 16 pieces. Let's say that white starts. White has 20 possible moves:
•The white player can move any pawn forward one or two positions.
•The white player can move either knight in two different ways.
The white player chooses one of those 20 moves and makes it. For the black player, the options are the same: 20 possible moves. So black chooses a move.
Now white can move again. This next move depends on the first move that white chose to make, but there are about 20 or so moves white can make given the current board position, and then black has 20 or so moves it can make, and so on.
Chess complexityChess complexity
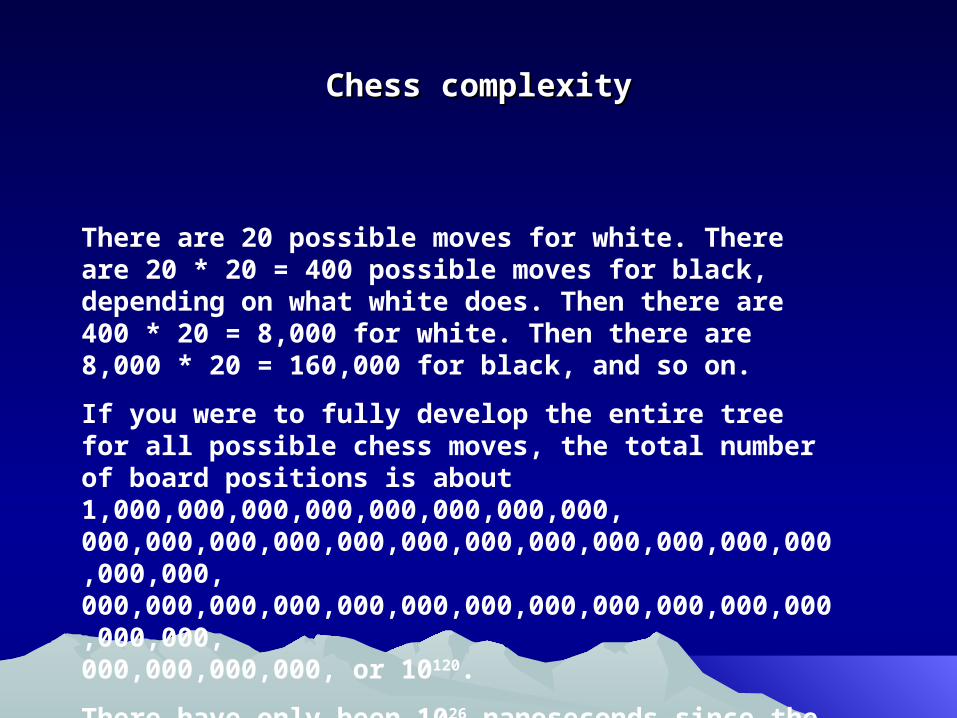
There are 20 possible moves for white. There are 20 * 20 = 400 possible moves for black, depending on what white does. Then there are 400 * 20 = 8,000 for white. Then there are 8,000 * 20 = 160,000 for black, and so on.
If you were to fully develop the entire tree for all possible chess moves, the total number of board positions is about 1,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000, or 10120.
There have only been 1026 nanoseconds since the Big Bang. There are thought to be only 1075 atoms in the entire universe.

How computer chess worksHow computer chess works
No computer is ever going to calculate the entire tree. What a chess computer tries to do is generate the board-position tree five or 10 or 20 moves into the future.
Assuming that there are about 20 possible moves for any board position, a five-level tree contains 3,200,000 board positions.
A 10-level tree contains about 10,000,000,000,000 (10 trillion) positions. The depth of the tree that a computer can calculate is controlled by the speed of the computer playing the game.

Is computer chess intelligent?Is computer chess intelligent?
The minimax algorithm alternates between the maximums and minimums as it moves up the tree.
This process is completely mechanical and involves no insight. It is simply a brute force calculation that applies an evaluation function to all possible board positions in a tree of a certain depth.
What is interesting is that this sort of technique works pretty well. On a fast-enough computer, the algorithm can look far enough ahead to play a very good game. If you add in learning techniques that modify the evaluation function based on past games, the machine can even improve over time.
The key thing to keep in mind, however, is that this is nothing like human thought. But does it have to be?

Leaf Nodes examined based on search depth
1
10
100
1000
10000
100000
1000000
1 2 3 4 5
Depth
Le
af
No
de
s E
xa
min
ed
wit
hin
Alp
ha
-Be
ta
Nimbus 2003 Version 3.0
Best Case
Worst Case
Leaf nodes examined
Search Depth

Hmmm. What to do?Hmmm. What to do?
• Black is to move:

……Ra5!Ra5!
• White to move:



What is strategy?What is strategy?•the art of devising or
employing plans or stratagems toward a goal where favorable.

Chess isChess isMulti-LevelMulti-Level

ScienceScience
Would you say a traditional chess program'schess strength is based mainly on a firm
axiomatic theory about the strengths and balances of competing differential semiotic trajectory units in
a multiagent hypergeoemetric topological manifold-like zero-sum dynamic environment
or simply because it is an accurate short-term calculator??!

Morph PhilosophyMorph Philosophy
Reinforcement Learning
Mathematical View of Chess
Don’t Cheat!!!

Cheating!Cheating!#define DOUBLED_PAWN_PENALTY 10#define ISOLATED_PAWN_PENALTY 20#define BACKWARDS_PAWN_PENALTY 8#define PASSED_PAWN_BONUS 20#define ROOK_SEMI_OPEN_FILE_BONUS 10#define ROOK_OPEN_FILE_BONUS 15#define ROOK_ON_SEVENTH_BONUS 20
• /* the values of the pieces */• int piece_value[6] = 100,300,350,500,900,0
•

White-Queen-square tableWhite-Queen-square table

Goal: ELO 3000+Goal: ELO 3000+
2800+ World Champion2600+ GM2400+ IM2200+ FM (> 99 percent)2000 Expert1600 Median (> 50 percent)1543 Morph1000 Novice (beginning tournament player)555 Random

MilestonesMilestones
• MorphI: 1995. Graph Matching Draws GnuChess every 10 games. 800
rating• Morph II: 1998. Plays any game, compiles neural net based on First Order Logic rules. Optimal Tic-Tac-Toe, NIM.• Morph IV : 2003. Neural Neighborhoods + Improved
Eval Reaches 1036.• Summer 2004: 1450 (improved implementation)• Today : 1558 (neural net +pattern variety + genetic
alg.)• Next: genetically selected patterns and nets.

Total Information = Diversity + Total Information = Diversity + SymmetrySymmetry
• Diversity corresponds to Comp Sci “Complexity” = resources required.
• Diversity can often only be resolved with Combinatorial Search

Exploit Symmetry !! Exploit Symmetry !!
“Invariant with respect to transformation.”
“Shared information between objectsor systems or their representations.”
AB+AC = A(B+C).

Symmetry SynonymsSymmetry Synonyms
• similarity• commonality• structure• mutual information• relationship• pattern• redundancy

NovicesExperts

Levels of LearningLevels of Learning
Levels: 0. None – Brute Force It 1. Empirically –Statistical Understanding - Inductive 1a. Supervise b. Reward/Punish + TD Learning c. Imitate 2. Analytically – Mathematical -
Deductive
But Must Be Efficient!

Chess and Stock TradingChess and Stock Trading
Technical Analysis: Forecasting market activity based on the study of price charts, trends and other technical data.
Fundamental Analysis: Forecasting based on analysis of economic and geopolitical data.
A Trading plan is formulated and executed only after a thorough and systematic Technical and Fundamental analysis.
All trading plans incorporate Risk Management procedures.
Patterns and their interpretation

Trade Example I: GBP/USDTrade Example I: GBP/USD

THE MORPH ARCHITECTURETHE MORPH ARCHITECTUREPattern-based!
INTUITIVELYBESTMOVE
INTUITIVELYBESTMOVE
ADB
WEIGHTS
Pattern Processor& Matcher
4-6 PLYSearch
COMPILED MEMORY
CHESS GAMES NEW POSITION

MORPHMORPH
Reply
Patterns
Weights4-Ply Search
PositionsChess

Morph patternsMorph patterns
• graph patterns – both nodes, edge labeled– direct attack, indirect attack, discovered
attack
• material patterns• Piece/square tables• (later : graph patterns realized as
neural networks)

The game of Chess – The game of Chess – exampleexample
White has over 30 possible moves
If black’s turn – can capture pawn at c3 and check (also fork)



Exploiting Graph Exploiting Graph IsomorphismIsomorphism

Pattern weight formulation Pattern weight formulation of search knowledgeof search knowledge
• weights– real number within the reinforcement value
range, e.g {0,1}– expected value of reinforcement given that
the current state satisfied the pattern
• pws : <p1, .7>– the states that have p1 as a feature are more
likely to lead to a win than a loss
• advantage– low-level of granularity and uniformity

Evaluation Scheme
64 Neighborhood Values are
Computed and
Then Combined

Morph - evaluation functionMorph - evaluation function
KEY: Use product rather than sum!!
WHY?
Makes risk adverse……..

Morph - evaluation asMorph - evaluation asproductproduct
x1 x2 x1*x2.5 .5 0.25.2 .8 0.16.2 .5 0.10.8 .5 0.40.8 .8 0.64.2 .2 0.04.1 .8 0.08.2 .9 0.181 .8 0.800 .2 0.00

Learning IngredientsLearning Ingredients
• Graph Patterns• Neural Networks• Temporal Difference Learning• Simulated Annealing• Representation Change• Genetic Algorithms

1. each state in the sequence of states that proceeded the reinforcement value is assigned a new value using temporal difference learning: W B W B W (assume W won) old: 0.6 0.35 0.70 0.3 0.8 new: 0.675 0.25 0.85 0.0* 1.0*
2. the new value assigned to each state is propagated down to the patterns that matched the state
Modifying Modifying the weight of patternsthe weight of patterns

Difference between Morph and traditional TD learning:1. the feature set changes throughout the learning process2. use a simulated annealing type scheme to give the weight of each pattern its own learning rate3. the more a pattern gets updated,
the slower its learning rate becomes…

simulated annealingDB comprises a complex system of many particlesoptimal configuration : each weight has its proper valueThe average error serves as a the objective evaluation
functionaverage error : the difference between APS's
prediction of a state's value and that provided by temporal-difference learning
1-kn
new*k1)-(n*WeightWeight
1-nn

Neural NetworksNeural Networks
Perhaps not so dumb?Perhaps not so dumb?
Morph’s neighborhood network is a
NON-LINEAR PERCEPTRON!

Biological inspirationsBiological inspirations
• Some numbers…– The human brain contains about 10 billion
nerve cells (neurons)– Each neuron is connected to the others
through 10000 synapses
• Properties of the brain – It can learn, reorganize itself from experience– It adapts to the environment – It is robust and fault tolerant

Biological neuronBiological neuron
• A neuron has– A branching input (dendrites)– A branching output (the axon)
• The information circulates from the dendrites to the axon via the cell body
• Axon connects to dendrites via synapses– Synapses vary in strength– Synapses may be excitatory or inhibitory

What is an artificial neuron ?What is an artificial neuron ?
• Definition : Non linear, parameterized function with restricted output range
x1 x2 x3
w0
y

Activation functionsActivation functions
0 2 4 6 8 10 12 14 16 18 200
2
4
6
8
10
12
14
16
18
20
-10 -8 -6 -4 -2 0 2 4 6 8 10-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
-10 -8 -6 -4 -2 0 2 4 6 8 10-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Linear
Logistic
Hyperbolic tangent

Feed Forward Neural Feed Forward Neural NetworksNetworks
• The information is propagated from the inputs to the outputs
• Computations of non linear functions from input variables by compositions of algebraic functions
• Time has no role (NO cycle between outputs and inputs)
x1 x2 xn…..
1st hidden layer
2nd hiddenlayer
Output layer

Recurrent Neural NetworksRecurrent Neural Networks
• Can have arbitrary topologies
• Can model systems with internal states (dynamic ones)
• Delays are associated to a specific weight
• Training is more difficult• Performance may be
problematic– Stable Outputs may be
more difficult to evaluate– Unexpected behavior
(oscillation, chaos, …)
x1 x2
1
010
10
00

Properties of Neural Properties of Neural NetworksNetworks
• Supervised networks are universal approximators (Non recurrent networks)
• Theorem : Any limited function can be approximated by a neural network with a finite number of hidden neurons to an arbitrary precision

Multi-Layer PerceptronMulti-Layer Perceptron
• One or more hidden layers
• Sigmoid activations functions
1st hidden layer
2nd hiddenlayer
Output layer
Input data

StructureTypes of
Decision RegionsExclusive-OR
ProblemClasses with
Meshed regionsMost GeneralRegion Shapes
Single-Layer
Two-Layer
Three-Layer
Half PlaneBounded ByHyperplane
Convex OpenOr
Closed Regions
Abitrary(Complexity
Limited by No.of Nodes)
A
AB
B
A
AB
B
A
AB
B
BA
BA
BA
Different non linearly Different non linearly separable problemsseparable problems
Neural Networks – An Introduction Dr. Andrew Hunter

Perceptron UpdatePerceptron Update
We employ :• Gradient descent: w0+w1x1+w2x2 +…w17x17• Exponential gradient: w0+w1e^-x1+..w17e^-
x17• Non-linear terms: w0+w12x1x2 +…• Triples: w0+w123x1x2x3 + …• Soon: some higher order terms: w0 + w1457x1x4x5x7 +…. ***genetically selected***…

Genetic AlgorithmsGenetic Algorithms
May Help Supervise Training and Development of the Neural Net structure!
BONUS:
We believe use of diversity in weight updating is underated!!

CharlesCharles Darwin (1809-Darwin (1809-1882)1882)
• Botanist, Zoologist, Geologist, General Man of Science
• Sailed on the Beagle for about 5 years.
• 1859 Wrote “Origins of Species” a very popular scientific treatise
• Goal: Develop an A.I. learning method using principles of Darwin’s amazing Beagle trip and subsequent theories of biological evolution

Genetic Genetic Algorithms Algorithms
(GA)(GA)
• John Holland, father of Genetic Algorithms: “Computer programs that "evolve" in ways that resemble natural selection can solve complex problems even their creators do not fully understand “
• GA allows A.I. knowledge discovery not yet known to humans or machines
• Adaptable to complex domains where human knowledge is limited, or sufficient domain knowledge cannot be easily provided
• New hypotheses are generated by mutating and recombining current hypotheses
• At each step we have a population of hypotheses from which we select the most fit
• GA does parallel search over different parts of the hypothesis space

Blondie24: A GA Blondie24: A GA Rock Star Success ??Rock Star Success ??
• David Fogel’s Neural Net/GA Checker Playing Program• Final rating: 2045.85 (Master Level) Better than 95% of all
checkers players• Neural Network: 2 hidden layers with 40 and 10 nodes
respectively, fully connected • Initial: 15 randomly-weighted NN• Each of the 15 NNs produce 1 offspring (using mutation),
total of 30 NNs• Each player plays against 5 randomly-selected opponents
using depth 4 alphabeta• Top 15 performers retained• 250 generations (time taken about 1 month)

Morph GA Morph GA Fitness, Selection & VariationFitness, Selection & Variation
• Initial Experiment: 20 Nan (2-Tuple) Brains play Round Robin each Generation, for several hundred Generations
• Fitness: +1 point given for game won, -1 for game lost. Draw receives no points. Points totalled for each Nan-Brain at Generation end
• Selection: Ten highest scoring Brains are selected for survival, remaining Brains eliminated .
• Variation: 10-50% of wgts are randomly mutated using a Box Mueller algorithm for Normal Distribution & a Sigmoid Function
• Initial Results: 300+ ELO Points gained from initial 555 (Random) ELO using Nan (2-Tuple) Neighborhood Knowledge Representation Schema

Future ExperimentsFuture Experiments
• We are confident we can achieve higher ELO rating levels using GA but it is important we do not cheat (provide specific chess knowledge)
• Variations upon the Knowledge Representation, including X-Tuple Neighborhood Networks
• Evolving meta-parameters using Genetic Algorithms e.g. range of mutating weights, size of knowledge representation, # ofbrains competing
• Lamarckian Evolution: Learning during a generation (not just selection/mutation alone) i.e., TD updating
• Using GA with alternative Knowledge Representations including various Neural Net configurations

Grandmaster DatabaseGrandmaster DatabaseDatabase: all (507,734 games)Report: 1.d4 Nf6 2.Bg5 Ne4 3.h4 (173 games)ECO: A45s [Trompowsky: Raptor Variation]Generated by Scid 3.0, 2001.11.15
1. STATISTICS AND HISTORY-------------------------
1.1 Statistics
Games 1-0 =-= 0-1 Score----------------------------------------------------------- All report games 173 61 44 68 47.9%
Both rated 2600+ 0 0 0 0 0.0% Both rated 2500+ 17 8 5 4 61.7% Both rated 2400+ 33 16 9 8 62.1% Both rated 2300+ 67 26 21 20 54.4%
![Stefano Profumo UC Santa Cruz Santa Cruz Institute for Particle Physics T.A.S.C. [Theoretical Astrophysics in Santa Cruz] TeV Particle Astrophysics 2009.](https://static.fdocuments.us/doc/165x107/56649d805503460f94a63a80/stefano-profumo-uc-santa-cruz-santa-cruz-institute-for-particle-physics-tasc.jpg)