
ENGS 116 Lecture 41 Instruction Set Design Part II Introduction to Pipelining Vincent H. Berk...
24
ENGS 116 Lect ure 4 1 Instruction Set Design Part II Introduction to Pipelining Vincent H. Berk September 28, 2005 Reading for today: Chapter 2.1 – 2.12, Wulf article Reading for Friday: Chapter A.1 – A.3, Patterson&Ditzel Homework #1 tomorrow
-
Upload
keaton-stickley -
Category
Documents
-
view
224 -
download
0
Transcript of ENGS 116 Lecture 41 Instruction Set Design Part II Introduction to Pipelining Vincent H. Berk...

ENGS 116 Lecture 4 1
Instruction Set Design Part II
Introduction to Pipelining
Vincent H. Berk
September 28, 2005
Reading for today: Chapter 2.1 – 2.12, Wulf article
Reading for Friday: Chapter A.1 – A.3, Patterson&Ditzel
Homework #1 tomorrow

ENGS 116 Lecture 4 2
Projects
• Teams of 2
• Two options:
– Research
– Programming
• Proposal due Wednesday 12th October:
– 2 pages
– Introduction to the problem, objectives
– Approach for solving the problem
– Expected working plan, hypothesis
– References to Literature

ENGS 116 Lecture 4 3
Projects
• Research Project:
– Exhaustive overview study of a particular topic.
– Research paper with a thesis and an argument (15-20 pages)
– Future vision
• Programming Project:
– Produce a simulator or a benchmark
– Use the produced software to test a thesis
– Present experimental results and analysis (Report)

ENGS 116 Lecture 4 4
Review: Instruction Set Design Parameters
• Operand storage in the CPU: Where are operands kept other than in memory?
• Number of explicit operands named per instruction: How many operands are named explicitly in a typical instruction?
• Operand location: Can any ALU operand be located in memory or must some or all of the operands be internal storage in the CPU? If an operand is located in memory, how is the memory location specified?
• Operations: What operations are provided in the instruction set?
• Type and size of operations: What is the type and size of each operand and how is it specified?

ENGS 116 Lecture 4 5
Intel 8086• Not truly general-purpose register machine because nearly every register
has dedicated use
• 16-bit architecture: internal registers are 16 bits
• 20-bit address space, broken into 64-KB fragments
• Variable-length instructions
• 8086 has 14 registers divided into 4 groups: data registers, address registers, segment registers, and control registers
• Addressing modes: absolute (16-bit absolute address), register indirect, based, indexed, and based indexed with displacement
• Operations: data movement, arithmetic and logic, control flow, string
• 80386: 32-bit architecture with 32-bit registers and 32-bit address space, additional addressing modes and additional operations
• 80x86 is most successful instruction set architecture of all time
• Awkward, old architecture is barrier to improvements

ENGS 116 Lecture 4 6Intel 80x86 Integer Registers
80386, 80486, Pentium 8086, 80286
GPR 0
GPR 1
GPR 2
GPR 3
GPR 4
GPR 5
GPR 6
GPR 7
PC
Base Ptr. (for base of stack seg.)
Stack Segment Ptr. (top of stack)
EAX AX AH AL
ECX CX CH CL
EDX DX DH DL
EBX BX BH BL
ESP SP
EBP BP
ESI SI
EDI DI
31 15 87 0
EIP IP
FLAGS
Accumulator
Count Reg: String, Loop
Data Reg: Multiply, Divide
Base Addr. Reg
Stack Ptr.
Index Reg, String Source Ptr.
Index Reg, String Dest. Ptr.
Code Segment Ptr.
Data Segment Ptr.Extra Data Segment Ptr.Data Segment Ptr. 2Data Segment Ptr. 3
Instruction Ptr. (PC)
Condition Codes
CSSSDSESFSGS

ENGS 116 Lecture 4 7
Intel 80x86 Floating PointRegisters
79 0
FPR 0FPR 1FPR 2FPR 3FPR 4FPR 5FPR 6FPR 7
15 0Status
Top of FP Stack, FP Condition Codes

ENGS 116 Lecture 4 8
Length
in b
yte
s
% instructions at each length
0% 10% 20% 30%
1
2
3
4
5
6
7
8
9
10
11
24%
23%
21%
3%
12%
13%
3%
0%
0%
1%
19%
17%
16%
1%
15%
27%
4%
0%
0%
1%
24%
24%
27%
4%
13%
6%
2%
0%
0%
0%
25%
24%
29%
3%
12%
4%
2%
0%
0%
0%
Espresso
Gcc
Spice
NASA7
80x86 Length Distribution

ENGS 116 Lecture 4 9
Current Design Guidelines
• Use general-purpose registers with a load-store architecture
• Support these addressing modes: displacement, immediate, and register deferred
• Use a minimalist instruction set
• Support simple, most-commonly used instructions
• Support standard data sizes and types: 8-, 16-, and 32-bit integers and 64-bit IEEE 754 floating-point numbers
• Use fixed instruction encoding if interested in performance and variable instruction encoding if interested in code size
• Provide at least 16 general-purpose registers plus separate floating-point registers; 32 registers of each highly desirable

ENGS 116 Lecture 4 10
The Big Picture: The Performance Perspective
• Performance of a machine is determined by:
– Instruction count
– Clock cycle time
– Clock cycles per instruction
• Processor design (datapath and control) will determine:
– Clock cycle time
– Clock cycles per instruction

ENGS 116 Lecture 4 11
Pipelining: It’s Natural!
• Laundry Example
• Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold
• Washer takes 30 minutes
• Dryer takes 40 minutes
• “Folder” takes 20 minutes
A B C D

ENGS 116 Lecture 4 12
Sequential Laundry
• Sequential laundry takes 6 hours for 4 loads
• If they learned pipelining, how long would laundry take?
30 40 20 30 40 20 30 40 20 30 40 20Task
Order
A
B
C
D
6 PM 7 8 9 10 11 MidnightTime
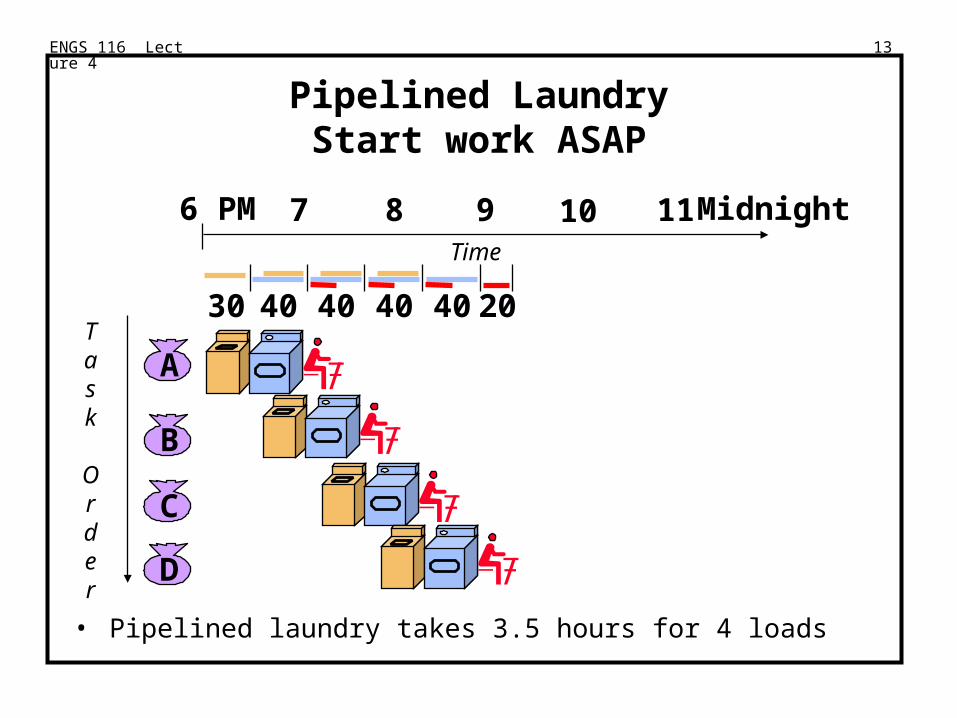
ENGS 116 Lecture 4 13
Pipelined LaundryStart work ASAP
• Pipelined laundry takes 3.5 hours for 4 loads
Task
Order
6 PM 7 8 9 10 11 MidnightTime
20
A
B
C
D
30 40 40 40 40

ENGS 116 Lecture 4 14
Pipelining Lessons
• Pipelining doesn’t help latency of single task, it helps throughput of entire workload
• Pipeline rate limited by slowest pipeline stage
• Multiple tasks operating simultaneously
• Potential speedup = Number pipe stages
• Unbalanced lengths of pipe stages reduces speedup
• Time to “fill” pipeline and time to “drain” it reduces speedup
Task
Order
6 PM 7 8 9Time
20
A
B
C
D
30 40 40 40 40

ENGS 116 Lecture 4 15
Basic MIPS RISC Instruction Set
• All operations on data apply to data in registers
• Only operations that affect memory are load and store operations that move data from memory to a register or to memory from a register
• Instruction formats are few in number with all instructions typically being one size
• 32 registers
• 3 classes of instructions: ALU, Load and Store, Branches and jumps

ENGS 116 Lecture 4 16
Simple Implementation of the MIPS RISC Instruction Set
• Instruction fetch cycle (IF)
–Send PC to memory
–Fetch current instruction from memory
–Update PC
• Instructions decode/register fetch cycle (ID)
– Decode instruction
– Read registers corresponding to register source specifiers from register file (in parallel with decoding)
–Look for branch conditions, act accordingly

ENGS 116 Lecture 4 17
Simple Implementation of the MIPS RISC Instruction Set
• Execution/effective address cycle (EX)
–ALU operates on operands prepared from prior cycle, then performs one of three things…
– Memory reference: ALU adds base register and offset to form effective address
–Register-register ALU instruction: ALU does operation specified by ALU opcode on values read from register file
–Register-immediate ALU instruction in which ALU does operation specified by ALU opcode on first value read from register file + sign extended immediate

ENGS 116 Lecture 4 18
Simple Implementation of the MIPS RISC Instruction Set
• Memory Access (MEM)
– Performs read using effective address if instruction is a load
– Performs write of data from second register read from register file using effective address if instruction is a store
• Write-back Cycle (WB)
– Write to register file for either register-register ALU instruction or load instruction

ENGS 116 Lecture 4 19

ENGS 116 Lecture 4 20
Example
Consider a nonpipelined machine with 5 execution steps of lengths 50 ns, 50 ns, 60 ns, 50 ns, and 50 ns. Due to clock skew and setup, pipelining adds 5 ns of overhead to each instruction stage. Ignoring latency impact, how much speedup in the instruction execution rate will we gain from a pipeline?

ENGS 116 Lecture 4 21
Sequential Execution
5050 50506050505050605050505060
260 260 260
Pipelined Execution
65 65 65 65 65
5 5 5 5 5
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60

ENGS 116 Lecture 4 22
It’s Not That Easy for Computers
• Limits to pipelining: Hazards prevent next instruction from executing during its designated clock cycle
– Structural hazards: Hardware cannot support this combination of instructions
– Data hazards: Instruction depends on result of prior instruction still in pipeline
– Control hazards: Pipelining of branches & other instructions. Common solution is to stall the pipeline until the hazard “bubbles” through the pipeline

ENGS 116 Lecture 4 23
Speed Up Equation for Pipelining
Speedup from pipelining =
=
=
Ideal CPI = CPIunpipelined /Pipeline depth
Speedup =
CPI unpipelined Clock Cycleunpipelined
CPI pipelined Clock Cyclepipelined
CPI unpipelined
CPI pipelined
Clock Cycleunpipelined
Clock Cyclepipelined
Ideal CPI Pipeline depth
CPI pipelined
Clock Cycleunpipelined
Clock Cyclepipelined
Avg. Instr. Time Unpipelined
Avg. Instr. Time Pipelined

ENGS 116 Lecture 4 24
Speed Up Equation for Pipelining
CPI pipelined = Ideal CPI + Pipeline stall clock cycles per instr
Speedup = Ideal CPI x Pipeline depth
Ideal CPI + Pipeline stall CPI
Clock Cycleunpipelined
Clock Cyclepipelined
Speedup = Pipeline depth
1 + Pipeline stall CPI
Clock Cycleunpipelined
Clock Cyclepipelined


















