![[@NaukriEngineering] Apache Spark](https://static.fdocuments.us/doc/165x107/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)
Enabling Exploratory Analysis of Large Data with Apache Spark and R
26
Enabling Exploratory Data Science with Apache Spark and R Hossein Falaki (@mhfalaki)
-
Upload
databricks -
Category
Technology
-
view
1.149 -
download
0
Transcript of Enabling Exploratory Analysis of Large Data with Apache Spark and R

Enabling Exploratory Data Science with Apache Spark and R
Hossein Falaki (@mhfalaki)

About the speaker: Hossein Falaki
Hossein Falaki is a software engineer at Databricksworking on the next big thing. Prior to that, he was a data scientist at Apple’s personal assistant, Siri. He graduated with Ph.D. in Computer Science from UCLA, where he was a member of the Center for Embedded Networked Sensing (CENS).
2

About the moderator: Denny Lee
Denny Lee is a Technology Evangelist with Databricks; he is a hands-on data sciences engineer with more than 15 years of experience developing internet-scale infrastructure, data platforms, and distributed systems for both on-premises and cloud.
3

We are Databricks, the company behind Apache Spark
Founded by the creators of Apache Spark in 2013
Share of Spark code contributed by Databricksin 2014
75%
4
Data Value
Created Databricks on top of Spark to make big data simple.

Why do we like R?
5
• Open source• Highly dynamic• Interactive environment• Rich ecosystem of packages• Powerful visualization infrastructure• Data frames make data manipulation convenient• Taught by many schools to stats and computing students

What would be ideal?
Seamless manipulation and analysis of very large data in R• R’s flexible syntax• R’s rich package ecosystem • R’s interactive environment• Scalability (scale up and out)• Integration with distributed data sources / storage
6
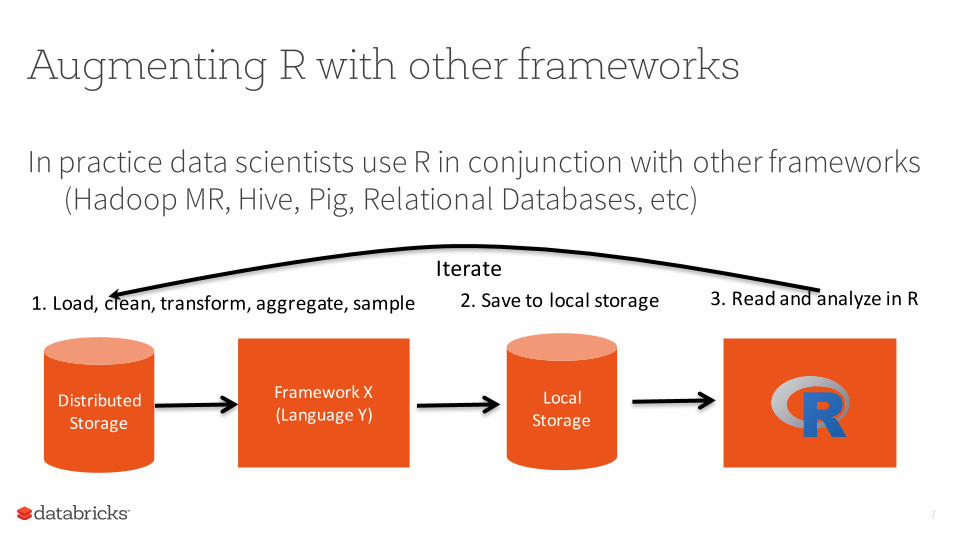
Augmenting R with other frameworks
In practice data scientists use R in conjunction with other frameworks (Hadoop MR, Hive, Pig, Relational Databases, etc)
7
FrameworkX(LanguageY)
DistributedStorage
1.Load,clean,transform,aggregate,sample
LocalStorage
2.Saveto localstorage 3.ReadandanalyzeinRIterate

What is SparkR?
An R package distributed with Apache Spark:• Provides R frontend to Spark• Exposes Spark Dataframes (inspired by R and Pandas)• Convenient interoperability between R and Spark DataFrames
8
+distributed/robust processing,datasources,off-memorydatastructures
Spark
Dynamicenvironment, interactivity,packages,visualization
R

How does SparkR solve our problems?
No local storage involved Write everything in RUse Spark’s distributed cache for interactive/iterative analysis at
speed of thought9
LocalStorage
2.Saveto localstorage 3.ReadandanalyzeinR
FrameworkX(LanguageY)
DistributedStorage
1.Load,clean,transform,aggregate,sample
Iterate

Example SparkR program
# Loading distributed datadf <- read.df(“hdfs://bigdata/logs”, source = “json”)
# Distributed filtering and aggregationerrors <- subset(df, df$type == “error”)counts <- agg(groupBy(errors, df$code), num = count(df$code))
# Collecting and plotting small dataqplot(code, num, data = collect(counts), geom = “bar”, stat = “identity”) + coord_flip()
10

SparkR architecture
11
SparkDriver
R JVM
RBackend
JVM
Worker
JVM
Worker
DataSources

Overview of SparkR API
IO• read.df / write.df• createDataFrame / collect
Caching• cache / persist / unpersist• cacheTable / uncacheTable
Utility functions• dim / head / take • names / rand / sample / ...
12
ML Lib• glm / kmeans /
DataFrame APIselect / subset / groupByhead / showDF /unionAllagg / avg / column / ...
SQLsql / table / saveAsTableregisterTempTable / tables

Overview of SparkR API :: SQLContext
SQLContext is your interface to Spark functionality in Ro SparkR DataFrames are implemented on top of SparkSQL tableso All DataFrame operations go through a SQL optimizer (catalyst)
13
sc <- sparkR.init()sqlContext <- sparkRSQL.init(sc)
From now on, you don’t need Spark Context (sc) any more.

Moving data between R and JVM
14
R JVM
RBackend
JVM
Worker
JVM
Worker
HDFS/S3/…
read.df()write.df()

Moving data between R and JVM
15
R JVM
RBackendSparkR::collect()
SparkR::createDataFrame()

Overview of SparkR API :: Caching
16
Controls cashing of distributed data:o persist(sparkDF, storageLevel)
o DISK_ONLY o MEMORY_AND_DISKo MEMORY_AND_DISK_SERo MEMORY_ONLYo MEMORY_ONLY_SERo OFF_HEAP
o cache(sparkdF) == persist(sparkDF, “MEMORY_ONLY”)o cacheTable(sqlContext, “table_name”)

Overview of SparkR API :: DataFrame API
SparkR DataFrame behaves similar to R data.frameso sparkDF$newCol <- sparkDF$col + 1o subsetDF <- sparkDF[, c(“date”, “type”)]o recentData <- subset(sparkDF$date == “2015-10-24”)o firstRow <- sparkDF[[1, ]]o names(subsetDF) <- c(“Date”, “Type”)o dim(recentData)o head(collect(count(group_by(subsetDF, “Date”))))
17

Overview of SparkR API :: SQL
You can register a DataFrame as a table and query it in SQLo logs <- read.df(sqlContext, “data/logs”, source = “json”)o registerTempTable(df, “logsTable”)o errorsByCode <- sql(sqlContext, “select count(*) as num, type from logsTable where type
== “error” group by code order by date desc”)o reviewsDF <- table(sqlContext, “reviewsTable”)o registerTempTable(filter(reviewsDF, reviewsDF$rating == 5), “fiveStars”)
18

Mixing R and SQL
Pass a query to SQLContext and get the result back as a DataFrame
19
# Register DataFrame as a tableregisterTempTable(df, “dataTable”)
# Complex SQL query, result is returned as another DataFrameaggCount <- sql(sqlContext, “select count(*) as num, type, date group by type order by date
desc”)
qplot(date, num, data = collect(aggCount), geom = “line”)

Moving between languages
20
R Scala
Spark
df <- read.df(...)
wiki <- filter(df, ...)
registerTempTable(wiki, “wiki”)
val wiki = table(“wiki”)
val parsed = wiki.map {Row(_, _, text: String, _, _)
=>text.split(‘ ’)}
val model = Kmeans.train(parsed)

Demo21

How to get started with SparkR?
• On your computer1. Download latest version of Spark (2.0)2. Build (maven or sbt)3. Run ./install-dev.sh inside the R directory4. Start R shell by running ./bin/sparkR
• Deploy Spark on your cluster • Sign up for Databricks Community Edition:
https://databricks.com/try-databricks
22

Community Edition Waitlist
23

Summary
1. SparkR is an R frontend to Apache Spark2. Distributed data resides in the JVM3. Workers are not running R process (yet)4. Distinction between Spark DataFrames and R data frames
24

25

Thank you


















