
Embedded System Design Center ARM7TDMI Microprocessor Data Processing Instructions Sai Kumar...
35
Embedded System Design Center ARM7TDMI Microprocessor ARM7TDMI Microprocessor Data Processing Instructions Data Processing Instructions Sai Kumar Devulapalli
-
Upload
logan-homan -
Category
Documents
-
view
219 -
download
0
Transcript of Embedded System Design Center ARM7TDMI Microprocessor Data Processing Instructions Sai Kumar...

Embedded System Design Center
ARM7TDMI MicroprocessorARM7TDMI Microprocessor
Data Processing InstructionsData Processing Instructions
Sai Kumar Devulapalli

2 of 35
Objectives
• Detailed understanding of ARM Data processing instructions
• Understanding the instruction encoding formats
• Understanding the general format with which data processing instructions can be conditionally executed and to set the status flags
• Use of immediate operand in the data processing operations
• Understand the use of shifter operations for second operand
• Understand the operation of multiplication instructions

3 of 35
Data processing Instructions
• Largest family of ARM instructions, all sharing the same instruction format.
• Contains:• Arithmetic operations• Comparisons (no results - just set condition codes) • Logical operations• Data movement between registers
• Remember, this is a load / store architecture• These instruction only work on registers, NOTNOT memory.
• They each perform a specific operation on one or two operands.
• First operand always a register - Rn• Second operand sent to the ALU via barrel shifter.
• We will examine the barrel shifter shortly.

4 of 35
Arithmetic AND logical Instructions: General Format
Opcode{Cond}{S} Rd,Rn,Operand 2
{Cond} - Conditional Execution of instruction
– E.g. GT=GREATER THAN,LT = LESS THAN
{S} - Set the bits in status register after execution.
{Operand 2}- various form of the instruction� immediate/register/shifting
• you can easily check all the combinations in the quick references of ARM.

5 of 35
Instruction format
31 28 27 26 25 24 21 20 19 16 15 12 11 0
Cond 0 0 # opcode S Rn Rd operand 2
Opcode: Arithmetic / Logic Function
S : Set condition code
Rn : First operand (ARM Register)
Rd : Destination operand (ARM Register)

6 of 35
32 bit immediate
If # (I) = 1 then operand 2 field will be
#rot 8-bit immediate
11 8 7 0
The actual immediate value is formed by rotating right the 8-bit immediate value by the even positions (#rot * 2) in a 32 bit word.
If #rot = 0 (when immediate value is less than 0xFF – 8 bit) then carry out from the shifter will be indicated in C flag.
Because of this all 32 bit immediate are not legitimate. Only those which can be formed.
7 of 35
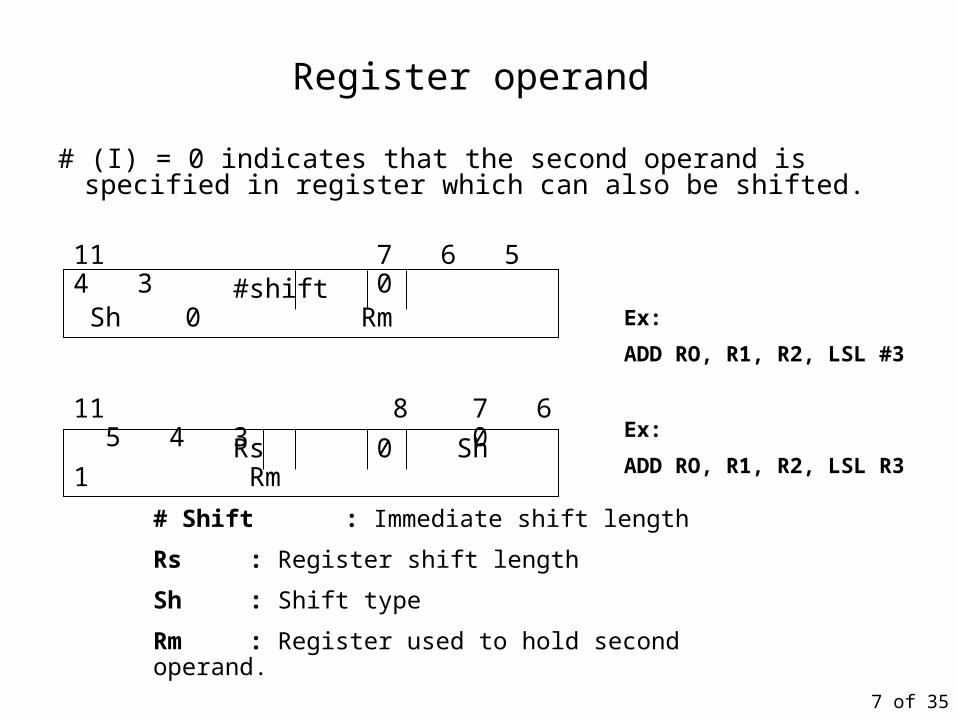
Register operand
# (I) = 0 indicates that the second operand is specified in register which can also be shifted.
#shift Sh 0 Rm11 7 6 5 4 3 0
# Shift : Immediate shift length
Rs : Register shift length
Sh : Shift type
Rm : Register used to hold second operand.
Rs 0 Sh 1 Rm
11 8 7 6 5 4 3 0
Ex:
ADD RO, R1, R2, LSL #3
Ex:
ADD RO, R1, R2, LSL R3

8 of 35
Shift operations
Guided by “Sh” field in the format
• Sh = 00 Logical Shift Left : LSL Operation
• Sh = 01 Logical Shift Right : LSR Operation
• Sh = 10 Arithmetic Shift Right : ASR Operation
• Sh = 11 Rotate Right : ROR Operation
• With Sh = 11 and #shift = 00000 (similar to ROR #0) is used for RRX operation.
9 of 35
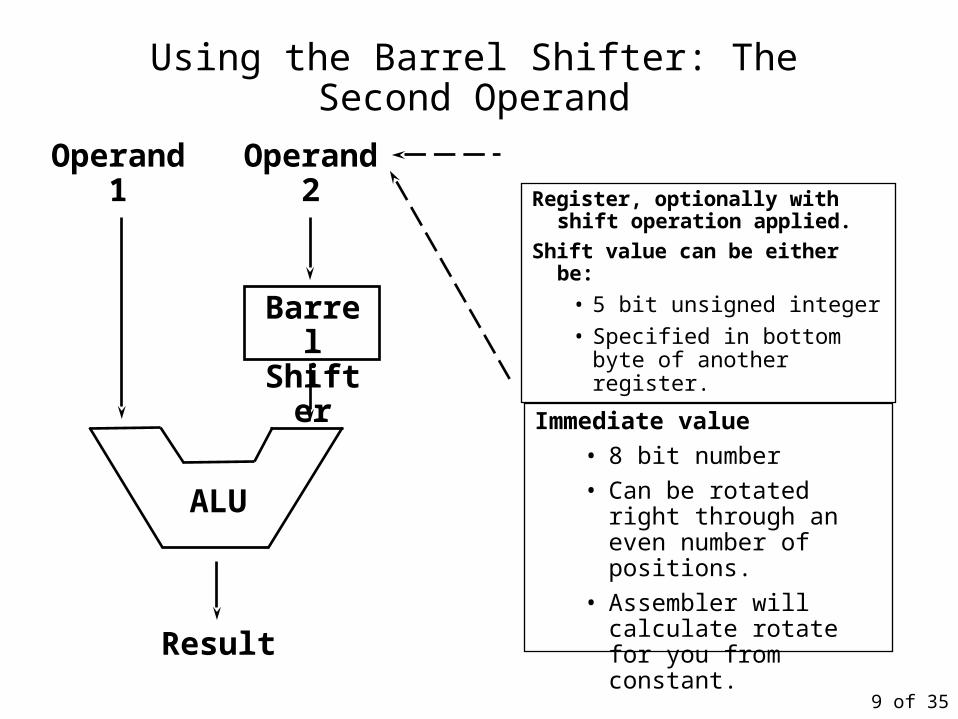
Immediate value
• 8 bit number
• Can be rotated right through an even number of positions.
• Assembler will calculate rotate for you from constant.
Register, optionally with shift operation applied.
Shift value can be either be:
• 5 bit unsigned integer
• Specified in bottom byte of another register.
Operand 1
Result
ALU
Barrel Shifter
Operand 2
Using the Barrel Shifter: The Second Operand
10 of 35
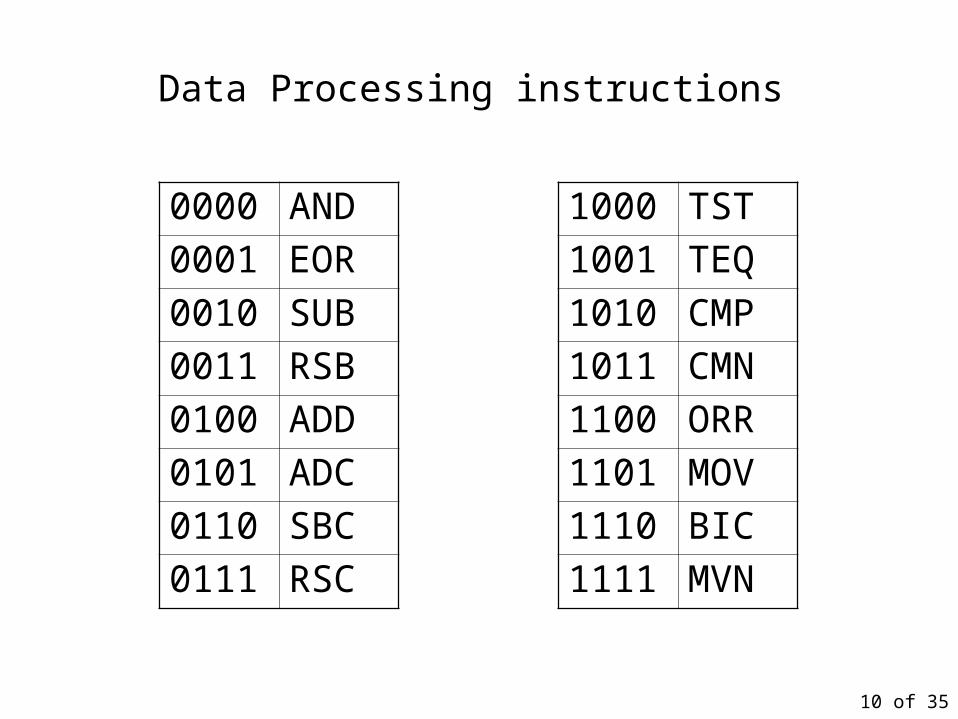
Data Processing instructions
0000 AND
0001 EOR
0010 SUB
0011 RSB
0100 ADD
0101 ADC
0110 SBC
0111 RSC
1000 TST
1001 TEQ
1010 CMP
1011 CMN
1100 ORR
1101 MOV
1110 BIC
1111 MVN

11 of 35
Arithmetic Operations
• Operations are:• ADD operand1 + operand2• ADC operand1 + operand2 + carry• SUB operand1 - operand2• SBC operand1 - operand2 + carry -1 <Sub. with C>• RSB operand2 - operand1 <Reverse Sub>• RSC operand2 - operand1 + carry – 1 <Rev.Sub.with C>
• Syntax:• <Operation>{<cond>}{S} Rd, Rn, Operand2
• Examples• ADD r0, r1, r2• SUBGT r3, r3, #1• RSBLES r4, r5, #5

12 of 35
Logical Operations
• Operations are:
• AND operand1 AND operand2
• EOR operand1 EOR operand2
• ORR operand1 OR operand2
• BIC operand1 AND NOT operand2 [ie bit clear]
• Syntax:
• <Operation>{<cond>}{S} Rd, Rn, Operand2
• Examples:
• AND r0, r1, r2
• BICEQr2, r3, #7
• EORS r1, r3, r0

13 of 35
Comparisons
• The only effect of the comparisons is to
• UPDATE THE CONDITION FLAGS. Thus no need to set S bit.
• Operations are:
• CMP operand1 - operand2, but result not written
• CMN operand1 + operand2, but result not written
• TST operand1 AND operand2, but result not written
• TEQ operand1 EOR operand2, but result not written
• Syntax:
• <Operation>{<cond>} Rn, Operand2

14 of 35
Comparisons
Examples:
• CMP r0, r1
• CMP R1,Operand2 e.g. CMP R1,R2
– [R1] - [R2]
– Set the N Z C V in CPSR register.
• TSTEQ r2, #5
• TST R1, Operand2 e.g. TST R1,R2
– [R1] AND [R2]

15 of 35
Data Movement
• Operations are:
• MOV Rd, operand2
• MVN Rd, (NOT) operand2
Note that these make no use of operand1.
• Syntax:
• <Operation>{<cond>}{S} Rd, Operand2
• Examples:
• MOV r0, r1
• MVN r0, r1
• MOVS r2, #10
• MVNEQ r1, #0

16 of 35
Quiz
Start
Stopr0 = r1?
r0 > r1?
r0 = r0 - r1 r1 = r1 - r0
Yes
No Yes
No
* Convert the GCD algorithm given in this flowchart into
1)“Normal” assembler,where only branches can be conditional.
2)ARM assembler, where all instructions are conditional, thus improving code density.
* The only instructions you need are CMP, B and SUB.

17 of 35
Quiz - Sample Solutions
“Normal” Assembler
gcd cmp r0, r1 ;reached the end? beq stop blt less ;if r0 > r1 sub r0, r0, r1 ;subtract r1 from r0 bal gcdless sub r1, r1, r0 ;subtract r0 from r1 bal gcdstop
ARM Conditional Assembler
gcd cmp r0, r1 ;if r0 > r1 subgt r0, r0, r1 ;subtract r1 from r0 sublt r1, r1, r0 ;else subtract r0 from r1 bne gcd ;reached the end?

18 of 35
The Barrel Shifter
• The ARM doesn’t have actual shift instructions.
• Instead it has a barrel shifter which provides a mechanism to carry out shifts as part of other instructions.
• So what operations does the barrel shifter support?

19 of 35
Shifts left by the specified amount (multiplies by powers of two) e.g.
LSL #5 = multiply by 32
Barrel Shifter - Left Shift
Logical Shift Left (LSL)
DestinationCF 0

20 of 35
Logical Shift Right
•Shifts right by the specified amount (divides by powers of two) e.g.
LSR #5 = divide by 32
Arithmetic Shift Right
•Shifts right (divides by powers of two) and preserves the sign bit, for 2's complement operations. e.g.
ASR #5 = divide by 32
Barrel Shifter - Right Shifts
Destination CF
Destination CF
Logical Shift Right
Arithmetic Shift Right
...0
Sign bit shifted in

21 of 35
Barrel Shifter - Rotations
Rotate Right (ROR)
•Similar to an ASR but the bits wrap around as they leave the LSB and appear as the MSB.
e.g. ROR #5
•Note the last bit rotated is also used as the Carry Out.
Rotate Right Extended (RRX)
• This operation uses the CPSR C flag as a 33rd bit.
•Rotates right by 1 bit. Encoded as ROR #0.
Destination CF
Rotate Right
Destination CF
Rotate Right through Carry

22 of 35
Second Operand: Shifted Register
• The amount by which the register is to be shifted is contained in either:
• the immediate 5-bit field in the instruction – NO OVERHEAD – Shift is done for free - executes in single cycle.
• the bottom byte of a register (not PC)– Then takes extra cycle to execute– ARM doesn’t have enough read ports to read 3 registers
at once.– Then same as on other processors where shift is
separate instruction.• If no shift is specified then a default shift is applied: LSL #0
• i.e. barrel shifter has no effect on value in register.

23 of 35
• Using a multiplication instruction to multiply by a constant means first loading the constant into a register and then waiting a number of internal cycles for the instruction to complete.
• A more optimum solution can often be found by using some combination of MOVs, ADDs, SUBs and RSBs with shifts.
• Multiplications by a constant equal to a ((power of 2) ± 1) can be done in one cycle.
• Example: r0 = r1 * 5Example: r0 = r1 + (r1 * 4)
ADD r0, r1, r1, LSL #2• Example: r2 = r3 * 105
Example: r2 = r3 * 15 * 7Example: r2 = r3 * (16 - 1) * (8 - 1) RSB r2, r3, r3, LSL #4 ; r2 = r3 * 15
RSB r2, r2, r2, LSL #3 ; r2 = r2 * 7
Second Operand:Using a Shifted Register

24 of 35
Loading full 32 bit constants
• Although the MOV/MVN mechanism will load a large range of constants into a register, sometimes this mechanism will not generate the required constant.
• Therefore, the assembler also provides a method which will load ANY 32 bit constant:
• LDR rd,=numeric constant• If the constant can be constructed using either a MOV or MVN then this
will be the instruction actually generated.• Otherwise, the assembler will produce an LDR instruction with a PC-
relative address to read the constant from a literal pool.• LDR r0,=0x42 ; generates MOV r0,#0x42• LDR r0,=0x55555555 ; generate
LDR r0,[pc, offset to lit pool]• As this mechanism will always generate the best instruction for a given
case, it is the recommended way of loading constants.

25 of 35
Multiplication Instructions
The Basic ARM provides two multiplication instructions.
• Multiply
• MUL{<cond>}{S} Rd, Rm, Rs ; Rd = Rm * Rs
• Multiply Accumulate - does addition for free
• MLA{<cond>}{S} Rd, Rm, Rs, Rn ; Rd = (Rm * Rs) + Rn
Restrictions on use:
• Rd and Rm cannot be the same register
– Can be avoid by swapping Rm and Rs around. This works because multiplication is commutative.
• Cannot use PC.
These will be picked up by the assembler if overlooked.
• Operands can be considered signed or unsigned
• Up to user to interpret correctly.

26 of 35
Instructions are
• MULL which gives RdHi,RdLo:=Rm*Rs
• MLAL which gives RdHi,RdLo:=(Rm*Rs)+RdHi,RdLo
However the full 64 bit of the result now matter (lower precision multiply instructions simply throws top 32bits away)
• Need to specify whether operands are signed or unsigned
Warning : Unpredictable on non-M ARMs.
Syntax:
UMULL/UMLAL{cond} {S} RdLo, RdHi, Rm, Rs
SMULL/SMLAL{cond} {S} RdLo, RdHi, Rm, Rs
Multiply-Long and Multiply_Accumulate Long

27 of 35
Instruction Format
000 MUL Rd := (Rm * Rs)
001 MLA Rd := (Rm * Rs) + Rn
100 UMULL RdHi : RdLo := Rm * Rs
101 UMLAL RdHi : RdLo += Rm * Rs
110 SMULL RdHi : RdLo := Rm * Rs
111 SMLAL RdHi : RdLo += Rm * Rs
31 28 27 24 23 21 20 19 16 15 12 11 8 7 4 3 0 Cond 0 0 0 0 mul S Rd/RdHi Rn/RdLo Rs 1 0 0 1 Rm

28 of 35
Example: C assignments
• C: x = (a + b) - c;
• Assembler:ADR r4,a ; get address for aLDR r0,[r4] ; get value of aADR r4,b ; get address for b, reusing r4LDR r1,[r4] ; get value of bADD r3,r0,r1 ; compute a+bADR r4,c ; get address for cLDR r2[r4] ; get value of cSUB r3,r3,r2 ; complete computation of xADR r4,x ; get address for xSTR r3[r4] ; store value of x

29 of 35
Example: C assignment
• C:y = a*(b+c);
• Assembler:ADR r4,b ; get address for bLDR r0,[r4] ; get value of bADR r4,c ; get address for cLDR r1,[r4] ; get value of cADD r2,r0,r1 ; compute partial resultADR r4,a ; get address for aLDR r0,[r4] ; get value of aMUL r2,r2,r0 ; compute final value for yADR r4,y ; get address for ySTR r2,[r4] ; store y

30 of 35
Example: C assignment
• C:z = (a << 2) | (b & 15);
• Assembler:ADR r4,a ; get address for aLDR r0,[r4] ; get value of aMOV r0,r0,LSL 2 ; perform shiftADR r4,b ; get address for bLDR r1,[r4] ; get value of bAND r1,r1,#15 ; perform ANDORR r1,r0,r1 ; perform ORADR r4,z ; get address for zSTR r1,[r4] ; store value for z

31 of 35
Example: FIR filter
• C:
for (i=0, f=0; i<N; i++)
f = f + c[i]*x[i];
• Assembler
; loop initiation code
MOV r0,#0 ; use r0 for I
MOV r8,#0 ; use separate index for arrays
ADR r2,N ; get address for N
LDR r1,[r2] ; get value of N
MOV r2,#0 ; use r2 for f

32 of 35
FIR filter, cont’.d
ADR r3,c ; load r3 with base of c
ADR r5,x ; load r5 with base of x
; loop body
loop LDR r4,[r3,r8] ; get c[i]
LDR r6,[r5,r8] ; get x[i]
MUL r4,r4,r6 ; compute c[i]*x[i]
ADD r2,r2,r4 ; add into running sum
ADD r8,r8,#4 ; add 1 word offset to array index
ADD r0,r0,#1 ; add 1 to i
CMP r0,r1 ; exit?
BLT loop ; if i < N, continue

33 of 35
Barrel Shifter executing Fixed Point Arithmetic

34 of 35
Summary
• All data processing operations work only on internal registers, immediate operands and NOT on memory.
• Data processing instructions
• Arithmetic – ADD, ADC, SUB, SBC, RSB, RSC
• Comparison – CMP, CMN, TST, TEQ
• Logical – ORR, AND, EOR, BIC
• Data Movement – MOV, MVN
• Shifter Operations – LSL, LSR, ASR, ROR, RRX
• Multiplication Instructions – MUL, MLA, MULL, MLAL

35 of 35
Thank You, Any Questions ?


















