
Electronic Supplementary Material - Home | Genetics S3. Proteins used in the alignment Protein...
27
Electronic Supplementary Material
Transcript of Electronic Supplementary Material - Home | Genetics S3. Proteins used in the alignment Protein...

Electronic Supplementary
Material

Electronic Supplementary
Material
Figure S1
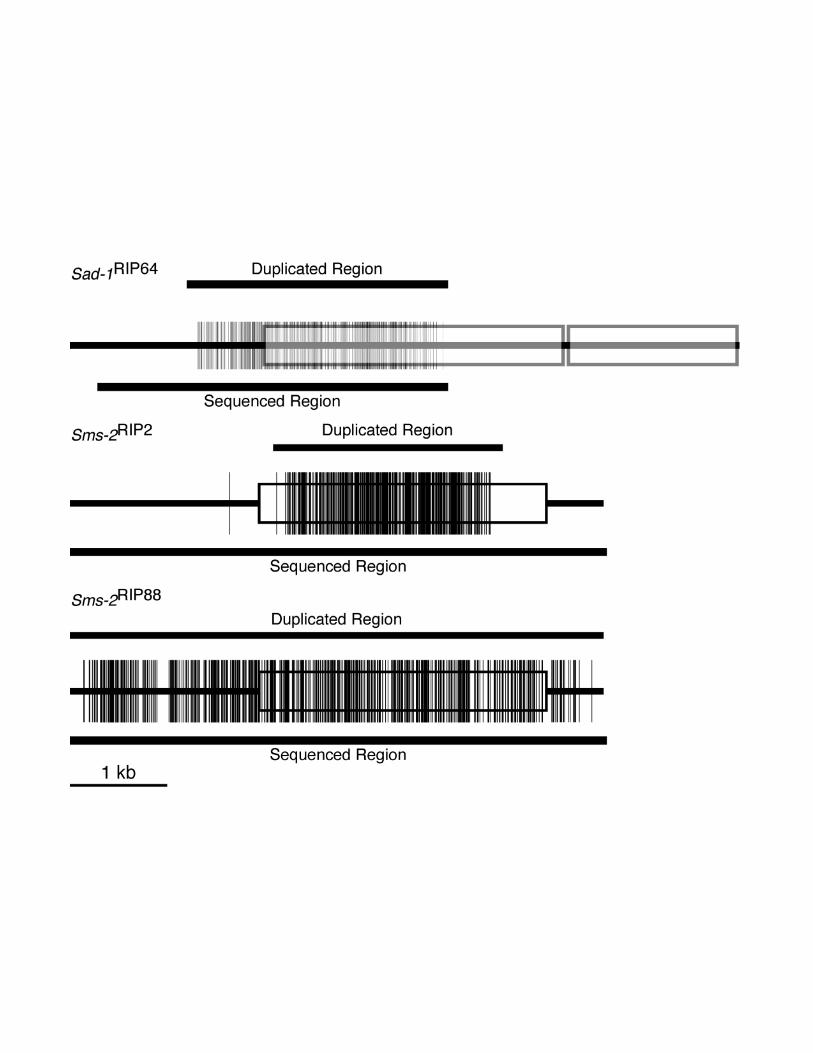

Electronic Supplementary
Material
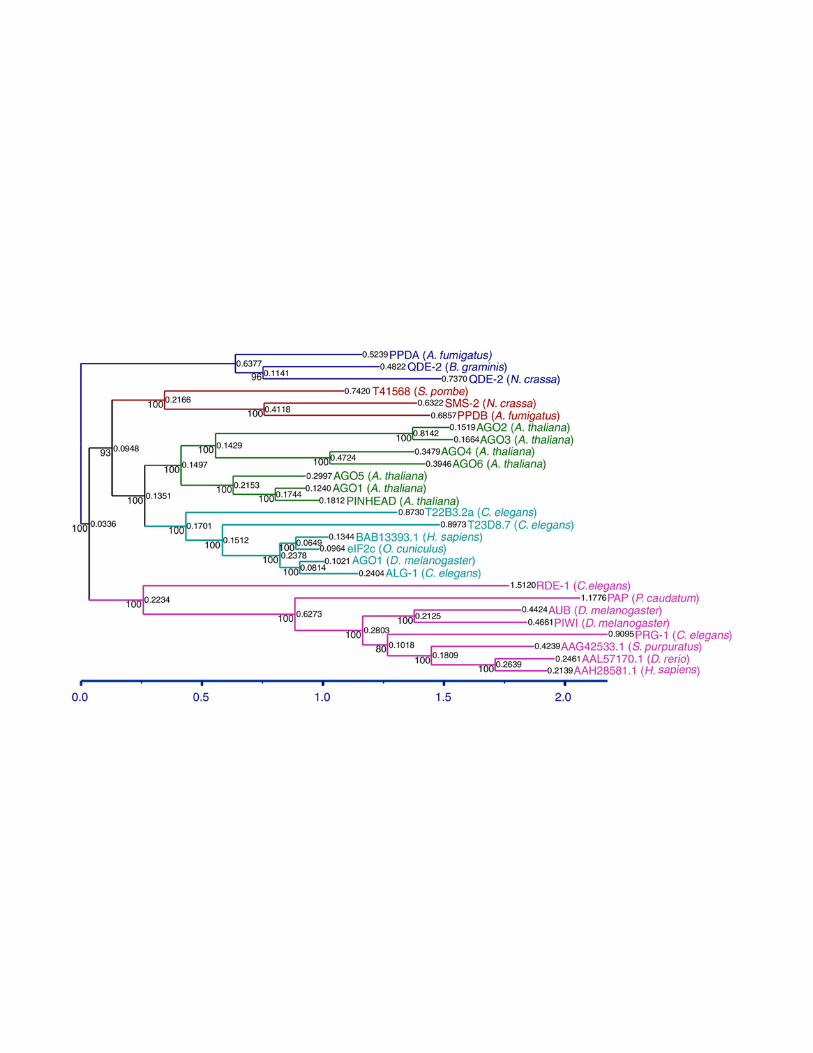
Figure S2




Electronic Supplementary
Material
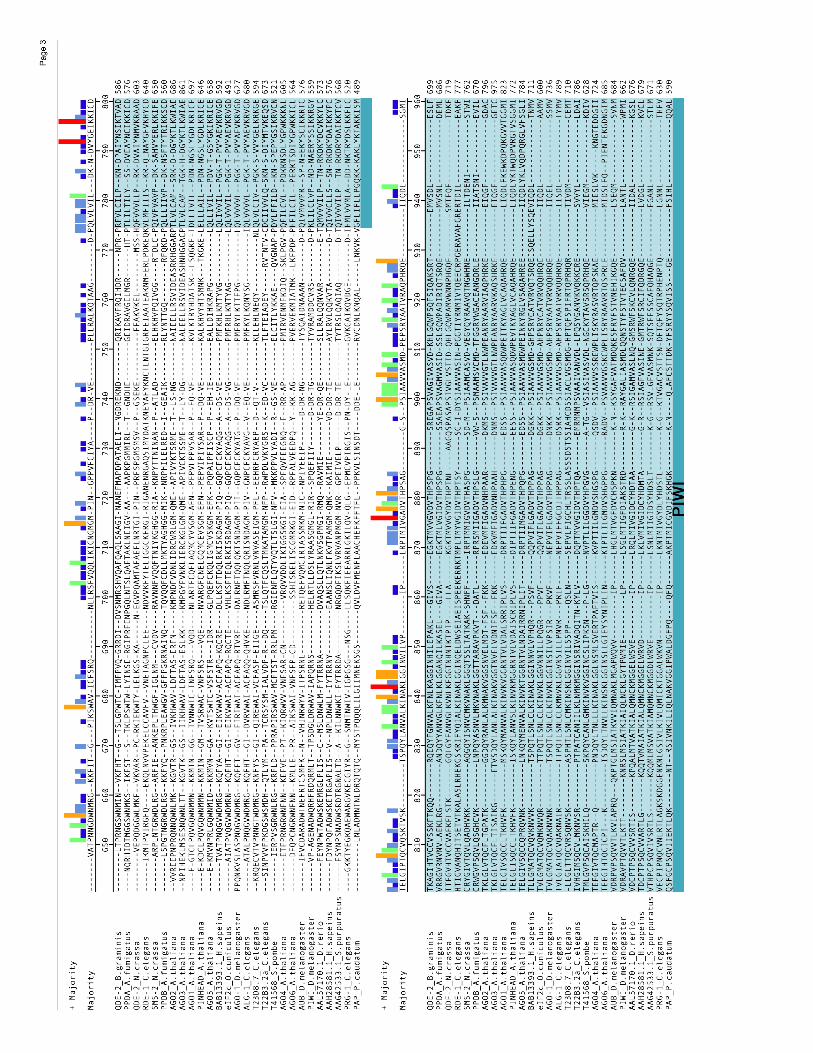
Figure S3

Electronic Supplementary
Material
Table S1

Table
S1.
Olig
onucl
eotid
es
use
d in t
his
stu
dy
Nam
eS
equence
OD
LA
M131
5’-
CC
AG
GA
GA
CG
CA
AA
GT
TC
-3’
OD
LA
M137
5’-
TG
CT
TG
AA
TT
GT
CC
AT
AC
-3’
OD
LA
M138
5’-
GA
CC
CT
AC
GA
AC
CT
AA
GC
-3’
OD
LA
M141
5’-
CC
CA
AT
AC
AC
AT
AA
GA
CA
-3’
OD
LA
M149
5’-
GC
TT
GG
GG
AA
AA
TA
AT
CA
-3’
OD
LA
M157
5’-
TT
AC
CG
AC
TT
TC
TT
TA
CC
-3’
OD
LA
M158
5’-
AC
TA
TA
GT
CA
GC
GA
GG
AG
-3’
OD
LA
M159
5’-G
TC
GA
AT
TC
TC
AA
GC
CC
AT
CA
AT
CA
TC
AA
TC
GG
TC
AA
-3’
OD
LA
M160
5’-
AA
GG
GA
TC
CT
GG
AG
GC
GC
GA
TT
TA
GG
GG
TG
CT
GT
TA
C-3
’Q
DE
-2LD
5’-
AG
GG
GA
TC
CT
GC
CG
TT
CT
TG
TC
TC
CC
CT
GT
C-3
’Q
DE
-2LU
5’-
AG
GG
GA
TC
CC
CC
GG
TC
AG
GC
TC
GC
TC
CA
AC
T-3
’R
3IID
5’-
AG
GG
GA
TC
CC
GC
AT
CA
TA
TC
GC
CT
GT
CA
AA
T-3
’R
3IIU
5’-
AG
GG
GA
TC
CC
AA
CC
GG
CA
GA
AG
AA
GG
AA
GA
A-3
’

Electronic Supplementary
Material
Table S2
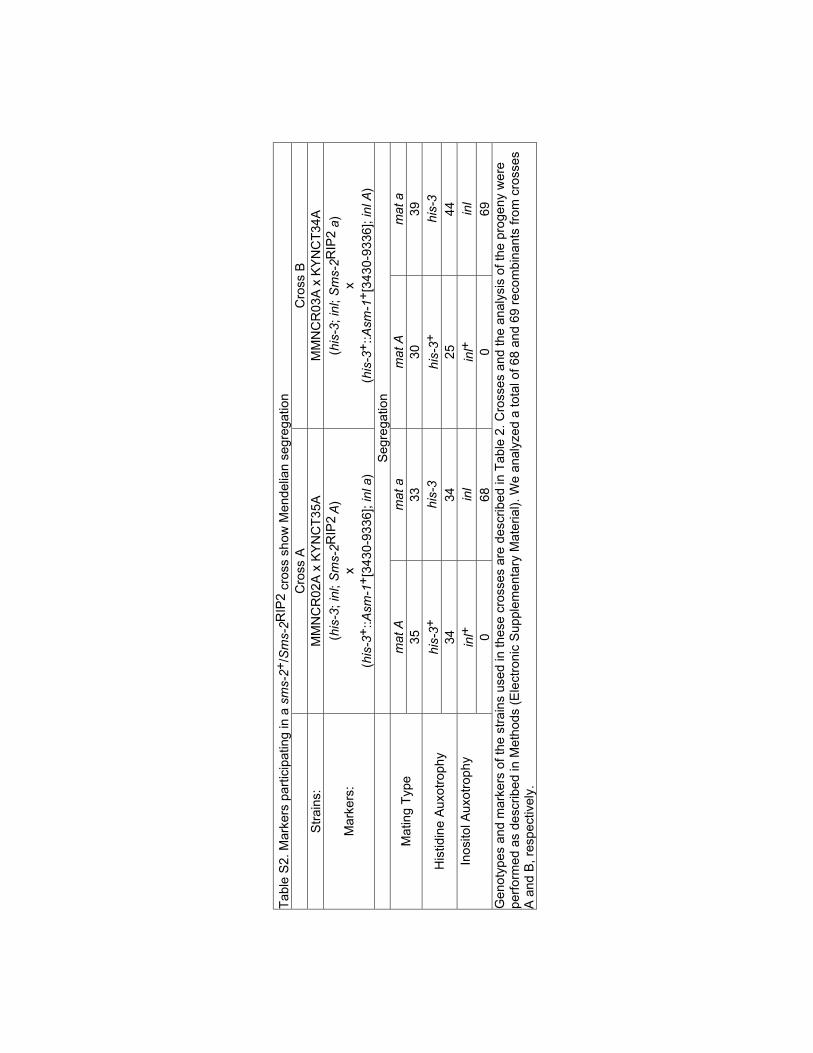
Tab
le S
2. M
arke
rs p
artic
ipat
ing
in a
sm
s-2+
/Sm
s-2R
IP2
cros
s sh
ow M
ende
lian
segr
egat
ion
Cro
ss A
Cro
ss B
Str
ains
:M
MN
CR
02A
x K
YN
CT
35A
MM
NC
R03
A x
KY
NC
T34
A
Mar
kers
:(h
is-3
; inl
; Sm
s-2R
IP2
A)
x(h
is-3
+::A
sm-1
+[3
430-
9336
]; in
l a)
(his
-3; i
nl; S
ms-
2RIP
2 a)
x(h
is-3
+::A
sm-1
+[3
430-
9336
]; in
l A)
Seg
rega
tion
mat
Am
at a
mat
Am
at a
Mat
ing
Typ
e35
3330
39
his-
3+hi
s-3
his-
3+hi
s-3
His
tidin
e A
uxot
roph
y34
3425
44
inl+
inl
inl+
inl
Inos
itol A
uxot
roph
y
068
069
Gen
otyp
es a
nd m
arke
rs o
f the
str
ains
use
d in
thes
e cr
osse
s ar
e de
scrib
ed in
Tab
le 2
. Cro
sses
and
the
anal
ysis
of t
he p
roge
ny w
ere
perf
orm
ed a
s de
scrib
ed in
Met
hods
(E
lect
roni
c S
uppl
emen
tary
Mat
eria
l). W
e an
alyz
ed a
tota
l of 6
8 an
d 69
rec
ombi
nant
s fr
om c
ross
esA
and
B, r
espe
ctiv
ely.

Electronic Supplementary
Material
Table S3
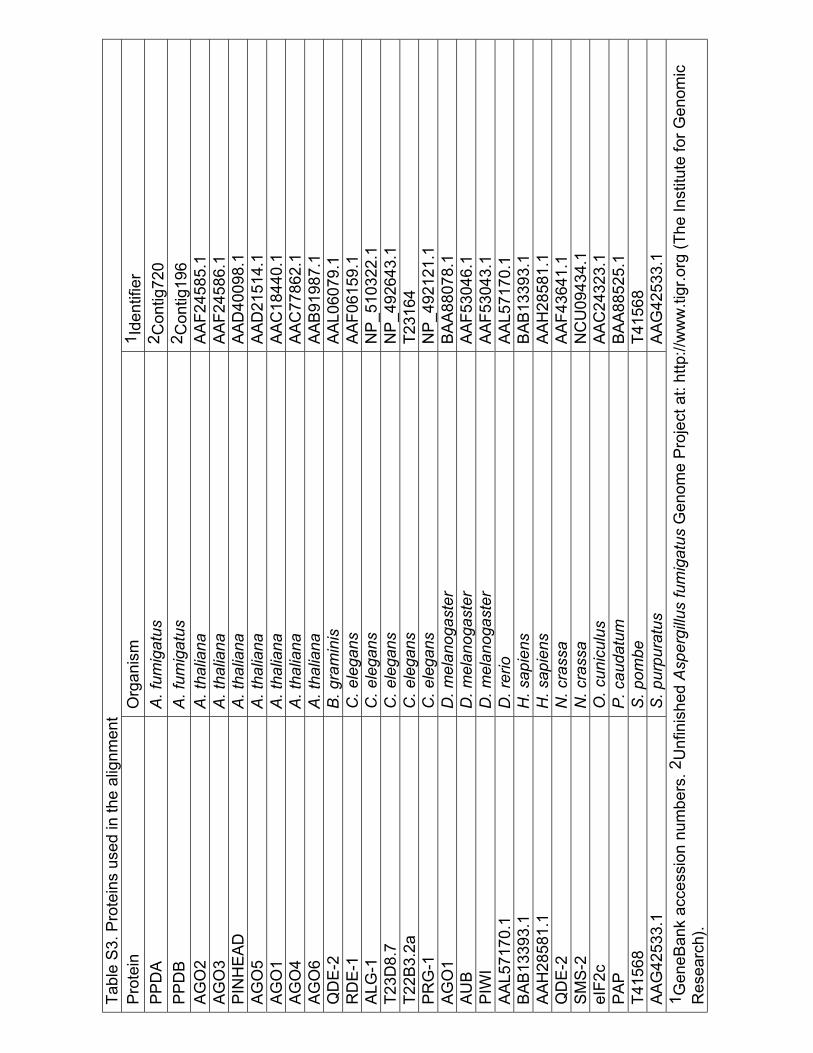
Table
S3. P
rote
ins
use
d in
the a
lignm
ent
Pro
tein
Org
anis
m1
Identif
ier
PP
DA
A. fu
mig
atu
s2
Contig
720
PP
DB
A. fu
mig
atu
s2
Contig
196
AG
O2
A. th
alia
na
AA
F24585.1
AG
O3
A. th
alia
na
AA
F24586.1
PIN
HE
AD
A. th
alia
na
AA
D40098.1
AG
O5
A. th
alia
na
AA
D21514.1
AG
O1
A. th
alia
na
AA
C18440.1
AG
O4
A. th
alia
na
AA
C77862.1
AG
O6
A. th
alia
na
AA
B91987.1
QD
E-2
B. gra
min
isA
AL06079.1
RD
E-1
C.
ele
gans
AA
F06159.1
ALG
-1C
. ele
gans
NP
_510322.1
T23D
8.7
C.
ele
gans
NP
_492643.1
T22B
3.2
aC
. ele
gans
T23164
PR
G-1
C.
ele
gans
NP
_492121.1
AG
O1
D.
mela
nogast
er
BA
A88078.1
AU
BD
. m
ela
nogast
er
AA
F53046.1
PIW
ID
. m
ela
nogast
er
AA
F53043.1
AA
L57170.1
D.
rerio
AA
L57170.1
BA
B13393.1
H. sa
pie
ns
BA
B13393.1
AA
H28581.1
H. sa
pie
ns
AA
H28581.1
QD
E-2
N.
crass
aA
AF
43641.1
SM
S-2
N.
crass
aN
CU
09434.1
eIF
2c
O.
cunic
ulu
sA
AC
24323.1
PA
PP
. ca
udatu
mB
AA
88525.1
T41568
S. pom
be
T41568
AA
G42533.1
S. purp
ura
tus
AA
G42533.1
1G
eneB
ank
acc
ess
ion n
um
bers
. 2
Unfin
ished A
sperg
illus
fum
igatu
s G
enom
e P
roje
ct a
t: h
ttp://w
ww
.tig
r.org
(T
he Inst
itute
for
Genom
icR
ese
arc
h).

Electronic Supplementary
Methods

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 1
Methods
Procedures for DNA extraction from Neurospora crassa, Southern blot analysis, and
other nucleic acid manipulations were performed as described (Pratt and Aramayo
2002). Similarly, growth conditions, conidial spheroplast preparation, fungal
transformation, homokaryon purification, female fertility/sterility determinations, and
genetic crosses were performed as described (Pratt and Aramayo 2002). The formulas
for the Vogel’s Medium N, the Westergaard’s Medium, and the sugar mixture of
Brockman and de Serres have been described by Davis and de Serres (1970).
Strain Description. Strains of N. crassa are described in Table 2. Escherichia coli K12
XL1-Blue MR (Stratagene, La Jolla, CA, USA) was the host for all our bacterial
manipulations. When non-methylated DNA was needed for enzyme digestions, either
GM2163--an E. coli K12 derivative containing, among others markers, a dam13::Tn9
(CamR) and a dcm-6 mutations (New England BioLabs (NEB), Beverly, MA, USA), or
JM110--an E. coli K12 derivative containing, among others, dam and dcm mutations
(Yanisch-Perron et al. 1985), was used.
A Note About the Integration at his-3 Locus. Due to the nature of the his-3
integration vectors used in this study (Aramayo and Metzenberg 1996), the
lysophospholipase, (lpl) gene, located downstream of the his-3 gene was deleted during
the integration of our constructs. Arbitrarily defining the HindIII restriction site present in
the coding region of his-3 as position 1, the region deleted during the gene replacement

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 2
spans from position 5192 to position 6046. We include this deletion (lpl∆(5192-6046)) as
part of the genotype of all our strains containing integrations at the his-3 locus (Table 2),
to distinguish them from strains containing integrations at the his-3 locus obtained with a
third generation of his-3-integration vectors (Margolin et al. 1997). The genome
sequence of the histidine-3 (his-3+) locus can be found on contig 3.165 (Release 3,
Whitehead Institute--http://www-genome.wi.mit.edu/annotation/fungi/neurospora/).
A Note About Strains Containing the Asm-1∆∆∆∆(3430-9336)::hph+::mcl-1 Deletion
Allele of Asm-1. In these strains, the region deleted encompassed a region predicted
to direct the transcription of a gene that we call myosin chain-like-1 (mcl-1+, Figure 1),
based on its weak homology to myosin-chain-like genes in other organisms (data not
shown). Strains containing a disruption in this predicted gene are viable and do not
have any detectable developmental or metabolic phenotypes.
DNA Sequencing. The Sad-1RIP64 allele (Suppressor of ascus dominance-1 [RIP64])
was sequenced using oligonucleotides ODLAM131, ODLAM137, ODLAM138,
ODLAM141, ODLAM149, ODLAM157, and ODLAM158 (Table S1) as primers, from a
2,711 bp PCR-amplified fragment (coordinates 1239 to 3950) from DLNCR64A
chromosomal DNA using oligonucleotides R3IIU and R3IID (Table S1). We used the
BigDye™ Terminator Cycle Sequencing Ready Reaction Kit with AmpliTaq DNA
polymerase (PEBiosystems, Foster City, CA, USA). Sequencing of Sad-1RIP64
revealed, among the many GC to AT transition mutations typical of RIP (see Electronic
Supplementary Material, Figure S1), an ATG to an ATA mutation at the translation-start

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 3
codon. Thus no SAD-1 polypeptide should be synthesized by this allele. The GenBank
Accession Number corresponding to the Sad-1RIP64 allele is AF500110.
Plasmids pDLAM102 (suppressor of meiotic silencing-2--Sms-2RIP2 allele) and
pDLAM103 (Sms-2RIP88 allele) were sequenced using both the GeneJumper Primer
Insertion Kit (Invitrogen, Carlsbad, CA, USA) and the BigDye™ Terminator Cycle
Sequencing Ready Reaction Kit with AmpliTaq DNA polymerase (PEBiosystems). The
GenBank Accession Numbers corresponding to the sms-2+, Sms-2RIP2 and Sms-
2RIP88 alleles are AF508210, AF508211 and AF508212, respectively.
Sequences were generated on an Applied Biosystems Model 377 or 373 automated
DNA sequencer at GeneTechnologies Laboratory (Institute of Developmental and
Molecular Biology—IDMB, Texas A&M University, College Station, TX, USA).
Plasmid Construction. The Sad-1 locus is contained on contig 3.102 (Release 3,
Whitehead Institute--http://www-genome.wi.mit.edu/annotation/fungi/neurospora/). We
arbitrarily defined as position 1 the SphI site located 2,031 bp upstream of the
translational initiation signal (ATG) for SAD-1 (NCU02178.1).
The genome sequence of the Ascospore maturation-1 (Asm-1) locus is contained on
contig 3.56 (Release 3, Whitehead Institute--http://www-
genome.wi.mit.edu/annotation/fungi/neurospora/). We arbitrarily defined as position 1
the HindIII site located 6,126 bp upstream of the translational initiation signal (ATG) for

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 4
ASM-1 (Aramayo et al. 1996). Following this convention the HindIII fragment contained
in pRAUW44 (Aramayo et al. 1996) maps from coordinates 1 to 12425.
The genome sequence of the Sms-2 locus is contained on contig 3.602 (Release
3, Whitehead Institute--http://www-genome.wi.mit.edu/annotation/fungi/neurospora/).
We arbitrarily defined as position 1 the sequence corresponding to the 5’-most base
located downstream of the EcoRI site present in the ODLAM159 oligonucleotide
(coordinates 5507 to 5534, Table S1). Position 1 is located 1,951 bp upstream of the
translational initiation signal (ATG) for SMS-2 (NCU09434.1).
Plasmids pOKE76 and pNNAid both were generously provided by Robert L.
Metzenberg. Plasmid pOKE76 consists of the 3,363 bp PvuII-SphI fragment from the
mat a-1 idiomorph of N. crassa, cloned into the HincII-SphI sites of pGEM3Zf(+)
(Promega, Madison, WI, USA), whereas plasmid pNNAid consists of the 5,758 bp NdeI-
NsiI fragment of the mat A-1 idiomorph inserted into the NdeI-NsiI sites of pGEM5Zf(-)
(Promega).
The following plasmids were constructed following standard procedures (Ausubel et al.
1987; Sambrook et al. 1989):
pDLAM092. Constructed by inserting the 5,534 bp PCR product amplified from
RANCR06A chromosomal DNA using ODLAM159 (coordinates 5507 to 5534) and
ODLAM160 (coordinates 1 to 28, Table S1) as primers into EcoRI-BamHI sites of

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 5
pRAUW122 (Aramayo and Metzenberg 1996). The PCR product was digested with
EcoRI and BamHI prior to ligation.
pDLAM102. Constructed by ligating the 5,534 bp PCR product amplified from
MMNCR03A chromosomal DNA using ODLAM159 (coordinates 5507 to 5534) and
ODLAM160 (coordinates 1 to 28, Table S1) as primers into EcoRI-BamHI sites of
pBluescript II SK(+) (Stratagene). The PCR product was digested with EcoRI and
BamHI prior to ligation.
pDLAM103. Constructed by ligating the 5,534 bp PCR product amplified from
DLNCR88A chromosomal DNA using ODLAM159 (coordinates 5507 to 5534) and
ODLAM160 (coordinates 1 to 28, Table S1) as primers into EcoRI-BamHI sites of
pBluescript II SK(+) (Stratagene). The PCR product was digested with EcoRI and
BamHI prior to ligation.
pKYAM001. Constructed by cloning the 2,472 bp EcoRI-KpnI fragment (coordinates
958 to 3430) from pRAUW63 (Aramayo et al. 1996) into the EcoRI-KpnI sites of
pGEM3Zf(+) (Promega).
pKYAM002. Constructed by cloning the 1.4 kb HpaI fragment containing the hph+ gene
from pCB1004 (Carroll et al. 1994) into the SmaI site of pKYAM001.
pKYAM003. Constructed by cloning the 3,089 bp XbaI-HindIII fragment (coordinates
9336 to 12425) from pRAUW44 (Aramayo et al. 1996) into the XbaI-HindIII sites of
pKYAM002.
pKYAM006. Constructed by cloning the 1,241 bp KpnI fragment (coordinates 3430 to
4671) from pRAUW44 (Aramayo et al. 1996) into the KpnI site of pBCKS(+)

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 6
(Stratagene). asm-1+ and lacZ+ have the opposite direction of transcription in this
plasmid.
pKYAM005. Constructed by cloning the 4,727 bp EcoRI-XbaI fragment (coordinates
4615 to 9336) from pRAUW44 (Aramayo et al. 1996) into the EcoRI-XbaI sites of
pRAUW122 (Aramayo and Metzenberg 1996).
pKYAM011. Constructed by cloning the 1,242 bp EcoRI fragment from pKYAM006 into
the EcoRI site of pKYAM005.
pKYAM052. Constructed by cloning the 3,610 bp EcoRI fragment containing the mat a-
1+ idiomorph of N. crassa from pOKE76 into the EcoRI site of pKYAM003.
pKYAM055. Constructed by cloning the 1,687 bp ScaI-EcoRI fragment from pNNAid,
containing the mat A-1+ gene of N. crassa into the HindIII site of pKYAM003. The ScaI-
EcoRI fragment from pNNAid (see above) and the HindIII fragment from pKYAM003
were both treated with Klenow polymerase (NEB) in the presence of dNTPs prior to
their ligation.
pQde-2l. Constructed by inserting a 2,374 bp PCR product amplified from RANCR06A
DNA using QDE-2LU (coordinates 4447 to 4468) and QDE-2LD (coordinates 2095 to
2116, Table S1) as primers into BamHI site of pRAUW122 (Aramayo and Metzenberg
1996). The PCR product was digested with BamHI prior to ligation.
pRdRP3. Constructed by cloning the 2,711 bp PCR-amplified fragment (coordinates
1239 to 3950, GeneBank AF500110) from wild-type genomic DNA (RANCR06A) using
R3IIU and R3IID as primers (Table S1), into the BamHI site of pRAUW122 (Aramayo
and Metzenberg 1996). The PCR product was digested with BamHI prior to ligation.

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 7
Bioinformatics of SMS-2. SMS-2 homologs listed in Table S3 were aligned with T-
Coffee v1.37 using the fast_pair method and the Vasiliky simulation matrix (Notredame
et al. 2000). The poorly aligned N-terminal region was removed and the sequences
unaligned. The trimmed sequences were then aligned with DiAlign2
(http://www.genomatix.de/cgi-bin/dialign/dialign.pl) (Morgenstern et al. 1996;
Morgenstern et al. 1998), ClustalX (using the Gosset series matrix) (Jeanmougin et al.
1998), PIMA (using the maximal linkage and sequential branching cluster methods;
http://searchlauncher.bcm.tmc.edu:9331/multi-align/multi-align.html) (Smith and Smith
1990; Smith and Smith 1992), and the slow_pair method of T-Coffee v1.39 (using the
Vasiliky simulation matrix) (Notredame et al. 2000). T-Coffee v1.39 was then used to
create a consensus alignment from these five alignments. The consensus alignment
was manually edited. Bayesian, or most posterior probability trees were generated with
MrBayes v2.01 (Huelsenbeck and Ronquist 2001; Huelsenbeck et al. 2001) using the
“Jones” substitution model, 100,000 generations, building an “all compatible” type tree
consensus and “burning” (ignoring) the trees from the first 10,000 generations with
sampling every 10 generations. Protein domains were identified by submitting SMS-2 to
the SMART database (http://smart.embl-heidelberg.de/) (Letunic et al. 2002; Schultz et
al. 1998) and the Pfam database (Bateman et al. 2002; Bateman et al. 2000;
Sonnhammer et al. 1997) by clicking this option at the SMART website.

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 8
References.
Aramayo, R., and R. L. Metzenberg, 1996 Gene replacements at the his-3 locus of
Neurospora crassa. Fungal Genetics Newsletter 43: 9-13.
Aramayo, R., Y. Peleg, R. Addison and R. Metzenberg, 1996 Asm-1+, a Neurospora
crassa gene related to transcriptional regulators of fungal development. Genetics
144: 991-1003.
Ausubel, F. M., R. Brent, R. E. Kingston, D. D. Moore, J. A. Smith et al. (Editors), 1987
Current Protocols in Molecular Biology. John Wiley and Sons, New York.
Bateman, A., E. Birney, L. Cerruti, R. Durbin, L. Etwiller et al., 2002 The Pfam protein
families database. Nucleic Acids Research 30: 276-280.
Bateman, A., E. Birney, R. Durbin, S. R. Eddy, K. L. Howe et al., 2000 The Pfam protein
families database. Nucleic Acids Research 28: 263-266.
Carroll, A. M., J. A. Sweigard and V. Valent, 1994 Improved vectors for selecting
resistance to hygromycin. Fungal Genetics Newsletter 41: 22.
Davis, R. H., and F. J. de Serres, 1970 Genetic and microbiological research
techniques for Neurospora crassa, pp. 79-143 in Metabolism of Amino Acids and
Amines, edited by S. P. Colowick and N. O. Kaplan. Academic Press, New York
and London.
Huelsenbeck, J. P., and F. Ronquist, 2001 MRBAYES: Bayesian inference of
phylogenetic trees. Bioinformatics 17: 754-755.

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 9
Huelsenbeck, J. P., F. Ronquist, R. Nielsen and J. P. Bollback, 2001 Bayesian
inference of phylogeny and its impact on evolutionary biology. Science 294:
2310-2314.
Jeanmougin, F., J. D. Thompson, M. Gouy, D. G. Higgins and T. J. Gibson, 1998
Multiple sequence alignment with Clustal X. Trends in Biochemical Sciences 23:
403-405.
Letunic, I., L. Goodstadt, N. J. Dickens, T. Doerks, J. Schultz et al., 2002 Recent
improvements to the SMART domain-based sequence annotation resource.
Nucleic Acids Research 30: 242-244.
Margolin, B. S., M. Freitag and E. U. Selker, 1997 Improved plasmids for gene targeting
at the his-3 locus of Neurospora crassa by electroporation. Fungal Genetics
Newsletter 44: 34-36.
Morgenstern, B., A. Dress and T. Werner, 1996 Multiple DNA and protein sequence
alignment based on segment-to-segment comparison. Proceedings of the
National Academy of Sciences of the United States of America 93: 12098-12103.
Morgenstern, B., K. Frech, A. Dress and T. Werner, 1998 DIALIGN: finding local
similarities by multiple sequence alignment. Bioinformatics 14: 290-294.
Notredame, C., D. G. Higgins and J. Heringa, 2000 T-Coffee: A novel method for fast
and accurate multiple sequence alignment. Journal of Molecular Biology 302:
205-217.
Pratt, R. J., and R. Aramayo, 2002 Improving the efficiency of gene replacements in
Neurospora crassa: a first step towards a large-scale functional genomics
project. Fungal Genetics and Biology 37: 56-71.

Lee, Dong W., Pratt, Robert J., McLaughlin, Malcolm and Aramayo, RodolfoPage 10
Sambrook, J., E. F. Fritsch and T. Maniatis (Editors), 1989 Molecular cloning: a
laboratory manual. Cold Spring Harbor Laboratory Press, N. Y.
Schultz, J., F. Milpetz, P. Bork and C. P. Ponting, 1998 SMART, a simple modular
architecture research tool: identification of signaling domains. Proceedings of the
National Academy of Sciences of the United States of America 95: 5857-5864.
Smith, R. F., and T. F. Smith, 1990 Automatic generation of primary sequence patterns
from sets of related protein sequences. Proceedings of the National Academy of
Sciences of the United States of America 87: 118-122.
Smith, R. F., and T. F. Smith, 1992 Pattern-induced multi-sequence alignment (PIMA)
algorithm employing secondary structure-dependent gap penalties for use in
comparative protein modelling. Protein Engineering 5: 35-41.
Sonnhammer, E. L., S. R. Eddy and R. Durbin, 1997 Pfam: a comprehensive database
of protein domain families based on seed alignments. Proteins 28: 405-420.
Yanisch-Perron, C., J. Vieira and J. Messing, 1985 Improved M13 phage cloning
vectors and host strains: nucleotide sequences of the M13mp18 and pUC19
vectors. Gene 33: 103-119.




![(ALDER(GREY, ALMOND, ASPERGILLUS FUMIGATUS, BAHIA … · 2019-11-06 · [ ]adult comprehensive allergy panel (alder(grey, almond, aspergillus fumigatus, bahia grass, bermuda grass,](https://static.fdocuments.us/doc/165x107/5fb12d57752ad135660a561b/aldergrey-almond-aspergillus-fumigatus-bahia-2019-11-06-adult-comprehensive.jpg)













