
Ein Modell deutscher Intonation : eine experimentell ...
161
Ein Modell deutscher Intonation : eine experimentell- phonetische Untersuchung nach den perzeptiv relevanten Grundfrequenzänderungen in vorgelesenem Text Citation for published version (APA): Adriaens, L. M. H. (1991). Ein Modell deutscher Intonation : eine experimentell-phonetische Untersuchung nach den perzeptiv relevanten Grundfrequenzänderungen in vorgelesenem Text. Technische Universiteit Eindhoven. https://doi.org/10.6100/IR350593 DOI: 10.6100/IR350593 Document status and date: Gepubliceerd: 01/01/1991 Document Version: Uitgevers PDF, ook bekend als Version of Record Please check the document version of this publication: • A submitted manuscript is the version of the article upon submission and before peer-review. There can be important differences between the submitted version and the official published version of record. People interested in the research are advised to contact the author for the final version of the publication, or visit the DOI to the publisher's website. • The final author version and the galley proof are versions of the publication after peer review. • The final published version features the final layout of the paper including the volume, issue and page numbers. Link to publication General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal. If the publication is distributed under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license above, please follow below link for the End User Agreement: www.tue.nl/taverne Take down policy If you believe that this document breaches copyright please contact us at: [email protected] providing details and we will investigate your claim. Download date: 24. Nov. 2021
Transcript of Ein Modell deutscher Intonation : eine experimentell ...

Ein Modell deutscher Intonation : eine experimentell-phonetische Untersuchung nach den perzeptiv relevantenGrundfrequenzänderungen in vorgelesenem TextCitation for published version (APA):Adriaens, L. M. H. (1991). Ein Modell deutscher Intonation : eine experimentell-phonetische Untersuchung nachden perzeptiv relevanten Grundfrequenzänderungen in vorgelesenem Text. Technische Universiteit Eindhoven.https://doi.org/10.6100/IR350593
DOI:10.6100/IR350593
Document status and date:Gepubliceerd: 01/01/1991
Document Version:Uitgevers PDF, ook bekend als Version of Record
Please check the document version of this publication:
• A submitted manuscript is the version of the article upon submission and before peer-review. There can beimportant differences between the submitted version and the official published version of record. Peopleinterested in the research are advised to contact the author for the final version of the publication, or visit theDOI to the publisher's website.• The final author version and the galley proof are versions of the publication after peer review.• The final published version features the final layout of the paper including the volume, issue and pagenumbers.Link to publication
General rightsCopyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright ownersand it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights.
• Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal.
If the publication is distributed under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license above, pleasefollow below link for the End User Agreement:www.tue.nl/taverne
Take down policyIf you believe that this document breaches copyright please contact us at:[email protected] details and we will investigate your claim.
Download date: 24. Nov. 2021


Ein Modell deutscher Intonation
Eine experimentell-phonetische Untersuchung nach den perzeptiv relevanten
Grundfrequenzänderungen in vorgelesenem Text
Proefschrift
ter verkrijging van de graad van doctor aan de Technische Universiteit Eindhoven,
op gezag van de Rector Magnificus Prof. dr. J .H. van Lint, voor een commissie aangewezen door het College van Dekanen
in het openbaar te verdedigen op 23 april 1991 om 16.00 uur
door
Léon Marie Henri Adriaens
geboren te Schaesberg

Dit proefschrift is goedgekeurd door de promotoren:
Prof. dr. S.G. Nooteboom en Prof. dr. H. Bouma

Inhalt
Definitionen V
1 Einleitung 1 1.1 Zielsetzung 1 1.2 Hintergründe . . . 1 1.3 Die !PO-Methode . 4 1.4 Gliederung der Arbeit 5
2 Phonetische Untersuchungen zur deutschen Intonation 7 2.1 Impressionistisch bestimmte Tonhöhenverläufe 7 2.2 Gemessene Grundfrequenzkurven . 2.3 Künstliche Grundfrequenzverläufe 2.4 Schlu6folgerungen ..... .. . .
3 Grundfrequenzkurven und Kopiekonturen 3.1 Die Kopiekontur . ............. . 3.2 Von der Grundfrequenzkurve zur Kopiekontur .
3.3 Die Relevanz der Kopiekontur . . . . . . . . 3.4 Akustik versus Perzeption der Kopiekontur 3.5 Die perzeptive Evaluierung
3.5.1 Zielsetzung .. . 3.5.2 Methode ... . . . .
3.5.2.1 Stimuli ..
3.5.2.2 3.5.2.3
Versuchspersonen Testverfahren . . .
3.5.3 Ergebnisse . ... . . . .. . 3.5.4 Diskussion und SchluBfolgerungen
13 17 30
33 33 34 38 39 43 43 43 43 44 44 46 48

II lnhalt
4 Ein melodisches Modell 63 4.1 Grundlagen . . . . . . . . . . . . 53 4.2 Kategorisierung und Standardisierung 54 4.3 Das melodische Modell . . . . . . . 56
4.3.1 Die Bauelemente einer Kontur 58 4.3.1.1 Standardisierte Deklinationslinien 59 4.3.1.2 Standardisierte Tonhöhenbewegungen 61
4.3.2 Sequentielle Regeln . . . . . . . . . . . . 67 4.3.2.1 Die Intonationsblöcke . . . . . . 67 4.3.2.2 Kombinationen der lntonationsblöcke 70
4.3.3 Zusammenfassung . . . . . 4.4 Perzeptive Evaluierung: Akzeptabilität .
4.4.1 Zielsetzung .. 4.4.2 Methode . . .... .
4.4.2.1 Stimuli . .. . 4.4.2.2 4.4.2.3
Versuchspersonen Testverfahren . . .
4.4.3 Ergebnisse . . ... . . 4.4.4 Diskussion und SchluBfolgerungen
4.5 Zusammenfassung des melodischen Modells
77 78 78 78 78 83 83 84 88 91
6 Diskussion 93 5.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . 93 5.2 Diskussion der Literatur . . . . . . . . . . . . . . . . . . . 93 5.3 Deutsche, niederländische, englische Intonation im Kon-
trast . . . . . . . . . . . . . 96 5.3.1 Deklination . . . . . . 98 5.3.2 5.3.3
Ebenen .. . . . .. . . . Tonhöhenbewegungen . . 5.3.3.1 Dauer und Frequenzumfang . 5.3.3.2 Position in der Silbe
5.3.4 Konturen ...... . . . . . 5.3.5 Die wichtigsten Unterschiede
5.4 Anwendungen ... . . . . . 5.4.1 Ein lntonationskurs 5.4.2 Das DS-System ... 5.4.3 Das SPICOS-System
100 100 101 102 103 105 107 107 107 112

lnhalt
5.5 Offene Fragen .
Anhang A
Anhang B
Literatur
Zusammenfassung
Summary
Samenvatting
Dankwoord
Curriculum vitae
III
114
117
123
131
137
139
141
143
146

IV Inhalt

Definitionen
Im folgenden werden einige Begriffe definiert, die in der vorliegenden Arheit häufig vorkommen.
AKZENT: Eine deutlich hörbare Tonhöhenänderung, durch die eine Silbe hervorgehoben wird. Akzentuierte Silben sind für die Wahrnehmung prominenter als nicht-akzentuierte Silben.
DEKLINATION: Das Phänomen, daB der durchschnittliche Wert der Grundfrequenz im Verlauf einer Äu6erung abnimmt. Die Deklination stellt ein konstituierendes Element des melodischen Eindrucks dar. Sie kann aus einer Stilisierung nicht entfernt werden, ohne daB eine deutliche melodische Veränderung eintritt. Die Deklination hat also einen perzeptiv relevanten Charakter. Sie wird nièht zu den im weiteren definierten "perzeptiv relevanten Tonhöhenbewegungen" gerechnet, weil in der vorliegenden Arbeit angenommen wird, daB die Deklination - physiologisch bedingt - automatisch heim Sprechvorgang auftritt.
GRUNDFREQUENZ (F0 ): Die Periodizität/Wiederholungsfrequenz eines (komplexen) Sprachsignals. Die Grundfrequenz wird ausgedrückt in Hertz (Hz). (Siehe FuBnote S. 1.)
HALBTON: Einheit, in der Tonhöhenunterschiede ausgedrückt werden. Die wahrgenommene lntervallgröBe einer Tonhöhenbewegung wird nicht durch den Unterschied zwischen Anfangs- und Endfrequenz bestimmt, sondern ist vom Verhältnis der beiden Frequenzwerte abhängig. So stellt ein Frequenzunterschied zwischen 50 und 100 Hz für den Hörer dieselbe IntervallgröBe dar wie zwischen 200 und 400Hz (12 Halbtöne). Dies wird aus den Hertz-Werten nicht ersichtlich. In dies er Arbeit wird die Grundfrequenz logarithmisch skaliert, wei! gleiche Frequenzverhältnisse durch
V

VI Definitionen
gleiche Distanzen repräsentiert werden. Ein Halbton entspricht einem Frequenzunterschied von etwas weniger als 6% oder 1/12 Oktave.
INTONATION: DieTonhöhenänderungen, die im Verlauf einer ÄuBe-.. rung auftreten.
KONTUR: Ein stilisierter, vis u el! durch gerade Linien gebildeter Grundfrequenzverlauf.
KOPIEKONTUR: Eine Stilisierung, die perzeptiv nicht von einem Originalverlauf zu unterscheiden ist und dabei aus einer Mindestanzahl gerader Linien besteht. Kopiekontur und Original sind perzeptiv gleich.
KURVE: Der natürliche, kontinuierlich variierende Verlauf der Grundfrequenz in einer Äullerung.
MIKRO-INTONATION: Zur Mikro-lntonation werden die durch Stilisierung eines natürlichen Grundfrequenzverlaufs entfernten Grundfrequenzänderungen gerechnet. Sie tragen nicht zum melodischen Eindruck bei; sie sind perzeptiv irrelevant. Mikro-intonative Grundfrequenzänderungen entstehen durch die segmentellen Eigenschaften des Sprachsignals.
PERZEPTIV RELEVANTE TONHÖHENBEWEGUNGEN: Die durch Stilisierung eines natürlichen Grundfrequenzverlaufs ermittelten Grundfrequenzänderungen, die entscheidend zum melodischen Eindruck beitragen und die nicht zur Deklination gerechnet werden. Diese stilisierten Grundfrequenzänderungen entsprechen also tatsächlich wahrgenommenen Tonhöhenbewegungen, sie sind perzeptiv relevant. Es wird angenommen, daB perzeptiv relevante Tonhöhenbewegungen der kognitiven Steuerung durch den Sprecher unterliegen. Von diesen "perzeptiv relevanten Tonhöhenbewegungen" unterscheiden sich "Deklination" und "Mikro-Intonation".
STANDARDKONTUR: Eine Kontur, deren Deklination und Tonhöhenbewegungen mit Standardspezifizierungen versehen sind.

Definitionen vn
STILISIERUNG: Eine Vereinfachung einer natürlichen Grundfrequenzkurve durch miteinander verbundene gerade Linien.
TONHÖHE: Das perzeptive Korrelat der Grundfrequenz. Perzeptiv relevante Grundfrequenzänderungen interpretiert der Hörer als Tonhöhenänderungen.

VIII Delinitionen

1
Einleitung
1.1 Zielsetzung
Gegenstand der varliegenden Arbeit ist die deutsche Intonation. "lntonation" definieren wirals die Tonhöhenä.nderungen, die im Verlauf einer ÄuBerung auftreten. Akustisch manifestieren sich die Tonhöhenä.nderungen, die der Hörer wahrnimmt, als Grundfrequenzä.nderungen1•
Die varliegende Arbeit untersucht, welche Grundfrequenzänderungen in vorgelesenem Text für die Wahrnehmung eines Tonhöhenverlaufs im Deutschen relevant sind, mit dem Ziel, ein melodisches Modell für das Deutsche zu erstellen.
1.2 Hintergründe
Traditionell stützen sich Beschreibungen der Intonation entweder auf die wahrgenommene Tonhöhe (a) oder auf die gemessene Grundfrequenz (b). Sowohl mit einer impressionistischen (a) als auch mit einer akustischen Analyse (b) sind typische Probleme verbunden. So hat sich gezeigt, daB eine impressionistische Transkription eines Tonhöhenverlaufs unzuverlässig ist. Wenn geschulte Hörer denselben Tonhöhenverlauf transkribieren sollen, kommen sie zu unterschiedlichen Ergebnissen.
Eine gemessene Grundfrequenzkurve dagegen gibt ein zuverlässigeres Bild der Intonation als eine impressionistische Transkription. Sie zeigt,
1 Üblicherweise wird die Grundfrequenz oder Fo als akustisch es Korrelat dor aubjektiv empfundenen Tonhöhe betraehtet. Eine Tonhöhe von beispielsweise 100 Hs wird jedoch auch wahrgenommen, wenn der enteprechende Grondton objektiv fehlt und das Spektrum nur aus einigen Harmonischen {etwa 300, 400, 600 und 600 Hz) beateht. Daraus geht hervor, daB nicht die Grundfrequens, sondorn vielmehr die Periodisität des komplexen Signals für die Tonhöhenwahrnehmung verantwortlich iat.

2 1. EinJeitung
wie die Grundfrequenz in einer ÄuBerung als Funktion der Zeit va,riiert. Eine Grundfrequenzkurve ist jedoch so komplex, sie enthält so viele Einzelheiten, daB Regularitäten kaum erkennbar sind.
Aus der Literatur ist bekannt, daB der Hörer die akustische Grundfre-. quenzinformation nicht so exakt analysiert, wie man auf Grund der visuellen Wiedergabe einer Grundfrequenzkurve vielleicht annehmen könnte. In natürlich gesprochener Sprache gibt es Grundfrequenzänderungen, die zwar me6bar, aber für den Hörer belanglos sind. Wenn diese perzeptiv irrelevanten Grundfrequenzänderungen entfernt werden, erhalten wir einen Verlauf, der ausschlieBlich perzeptiv relevante, also für die Wahrnehmung der Sprachmelodie wichtige Grundfrequenzänderungen enthält. Durch die Stilisierung kann eine Kurve auf die für die Wahrnehmung relevanten Merkmale reduziert werden. Durch die Reduktion gibt die Stilisierung einen deutlicheren Einblick in die Regularitäten der Intonation als eine natürliche Kurve.
Ein sokher vereinfachter, stilisierter Grundfrequenzverlauf kann als ein Abbild der intonativen Formvorstellungen des Hörers betrachtet werden.
Die zentrale Frage ist, welche Grundfrequenzänderungen für den Hörer relevant und welche irrelevant sind. Urn die perzeptiv relevanten Grundfrequenzänderungen zu erfassen, gehen wir nach einer experimentellen Methode vor, wie sie am "Instituut voor Perceptie Onderzoek" (IPO) in Eindhoven/Niederlande entwiekelt worden ist. Diese Methode verbindet die Stilisierung eines natürlichen Grundfrequenzverlaufs mit einer perzeptiven Überprüfung. Mit dieser Methode wird Intonation perzeptiv modelliert.
Untersuchungen für das Niederländische (Cohen und 't Hart, 1967; Collier und 't Hart, 1971; Collier, 1972; 't Hart und Cohen, 1973; 't Hart und Collier, 1975) und das britische Englisch (de Pijper, 1983; Willems, Collier und 't Hart, 1988) zeigen, daB die perzeptiv relevanten Merkmale von lntonation mit einem beschränkten lnventar prototypischer Tonhöhenbewegungen beschrieben werden können. Jede Steigung und Senkung im lnventar der perzeptiv relevanten Tonhöhenbewegungen wird visuell als eine gerade Linie in einem logarithmisch skalierten Frequenzbereich dargestellt, definiert durch jeweils drei Parameter: Dauer, Frequenzumfang und Position in der Silbe.
An Hand von Regeln, können aus diesen Tonhöhenbewegungen hörbare

1.2. Hintergründe 3
Konturen gebildet werden. ÄuBerungen mit einer sokhen vereinfachten, aus geraden Linien aufgebauten künstlichen Intonation vermitteln einen völlig natürlichen Höreindruck, vorausgesetzt die Tonhöhenbewegungen haben die für die jeweilige Sprache zutreffende Spezifizierung.
Jeder Tonhöhenverlauf im Niederländischen und im Englischen kann a.lso auf perzeptiv adäquate Weise als eine geregelte Abfolge diskreter Tonhöhenbewegungen hesebrieben werden. Das heiBt, daB die intonative Struktur in einem Modell erfaBt werden ka.nn, das aus einem Inventar prototypischer Tonhöhenbewegungen und einem Regelsatz besteht. In diesem Regelsatz ist festgelegt, welche Kombinationen von Steigungen und Senkungen erlaubt sind.
Zu einem solchen Modell ist folgendes zu bemerken.
1. Es handelt sich urn ein rein melodisches Modell. Das bedeutet, daB die funktionalen Aspekte der Intonation unberücksichtigt bleiben. Dieses Modell bietet aber einen guten Ausgangspunkt, um die Beziehungen zwischen Formaspekten der lntonation und Textmerkmalen zu untersuchen.
2. Die intonativen Hypothesen, die dieses melodische Modell zusammenfa.Bt, sind nicht a.usschlieBlich deskriptiv, sondern können auch akustisch realisiert werden. Daher sind diese Hypothesen überprüfbar. Dazu beurteilen Hörer die Akzeptabilität natürlich gesproehener ÄuBerungen, die mit synthetischen Konturen versehen sind. Aus den Hörerurteilen geht hervor, ob die intonativen Hypothesen perzeptiv adäquat sind. So sind Aussagen über die Validität des melodischen Modelis möglich.
Untersuchungen, in denen künstliche lntonation erzeugt wird, gibt es für eine Reihe von Sprachen, beispielsweise für das Dänische (Thorsen, 1980), das Deutsche (Isacenko und Schädlich, 1964; Zingle, 1982; Adriaens, 1984; Kohier, 1988), das amerikanische Englisch {Maeda, 1976; Pierrehumbert, 1981), das britische Englisch (Mattingly, 1966; Witten, 1978; Willems, 1982; de Pijper, 1983; Willems, Collier und 't Hart, 1988), das Französische (Vaissière, 1971), das Japanische (Fujisaki und Nagashima., 1967; Fujisaki und Hirose, 1982), das Niederländische (Cohen und 't Hart, 1967; Collier, 1972; 't Hart und Cohen, 1973; 't Hart und

4 1. Einleitung
Collier, 1975), das Russische (Odé, 1989) und das Schwedische (Öhman, 1967; Bruce, 1977).
Die Intonation dieser Sprachen ist entweder unter dem Aspekt der Produktion oder der Perzeption untersucht worden. In der vorliegenden Untersuchung der deutschen Intonation entscheiden wir uns für eine perzeptive Analyse, da nicht alle Grundfrequenzänderungen, die in einem natürlichen lntonationsverlauf auftreten, für die Wahrnehmung erheblich sind. Es ist deshalb auch wenig sinnvoll, alle Grundfrequenzänderungen, die in der Produktion auftreten, zu modellieren.
1.3 Die !PO-Methode
Die !PO-Methode ist ausführlich dargesteUt in 't Hart, Collierund Cohen (1990). In diesem Abschnitt beschreiben wir das methodische Vorgehen, wie a.us na.türlichen Grundfrequenzkurven nach perzeptiven Kriterien ein melodisches Modell ersteUt werden kano.
Eine natürliche Grundfrequenzkurve kann nur dann stilisiert werden, wenn die Grundfrequenz getrennt von den anderen akustischen Eigenschaften des Sprachsignals verfügbar ist. Am IPO wird dazu ein Verfabren angewendet ('t Hart, Nooteboom, Vogten und Willems, 1982; Vogten, 1983), das zunächst ein digitalisierles Sprachsignal nach dem Prinzip der "Linear Prädiktiven Kodierung" (LPC) analysiert. Im IPOSystem wird nach dieser Methode alle 10 ms die spektrale Hüllkurve errechnet. Danach wird - ebenfalls in Schritten von 10 ms - der Verlauf der Grundfrequenz gemessen, beziehungsweise die Non-Periodizität des Signals bestimmt. Eventuelle MeBfehler werden manuell korrigiert.
Die Grundfrequenz ist jetzt von den spektralen Merkmalen des Sprachsignals getrennt. Die Grundfrequenzkurve2 kano graphisch auf einem Computerbildschirm wiedergegeben werden, und der gemessene Verlauf kann mit Hilfe eines Cursors interaktiv stilisiert werden. Die ursprüngliche Kurve wird im IPO-Ansatz durch eine Kontur ersetzt, die aus geraden Linien besteht. Die natürliche ÄuBerung kann mit der künstlichen Intonation resynthetisiert, das heiBt, erneut hörbar gemacht werden.
In einem ersten Schritt der Modellbildung werden die gemesseoen
'In der vorliegenden Arbeil iet die Grnndfrequena, ausgedrückt in Hert1 (Hs), in grapbischen Darsleiluogen logaritbmisch skaliert. Siehe Definition des Begriffs "Halbton", Seite V-VI.

1.4. Gliederung der Arbeit 5
Grundfrequenzkurven natürlich gesprachener ÄuBerungen mit Hilfe eines Computers so vereinfacht, daB die Stilisierung denselben Höreindruck vermittelt wie das Original. lndem wir Original und Stilisierung auditiv ständig miteinander vergleichen, kann die Stilisierung ausschlieBlich auf die Grundfrequenzänderungen reduziert werden, die für die Wahrnehmung relevant sind. Die Stilisierung, die nur die perzeptiv relevanten Grundfrequenzänderungen berücksichtigt und sich perzeptiv nicht von dem Original unterscheiden läBt, nennen wir eine "Kopiekontur" (Kapitel 3).
Die Kopiekonturen bilden die Grundlage unseres Modells. Zunächst repräsentiert jede Kopiekontur nur die für die Wahrnehmung relevanten Merkmale einer spezifischen Kurve. Der Vergleich der Kopiekonturen untereinander macht es aber möglich, gemeinsame Merkmale der Kopiekonturen aufzudecken. Durch Standardisierung versuchen wir dann zu Generalisierungen zu kommen. Diese Hypothesen werden in Form eines melodischen Modells formuliert, das aus einem beschränkten Inventar diskreter, standardisierter Steigungen und Senkungen bestebt sowie aus Kombinationsregeln. Diese Regeln legen fest, wie diese Steigungen und Senkungen zu Konturen kombiniert werden können. Eine Stilisierung, die aus standardisierten Steigungen und Senkungen besteht, nennen wir eine "Standardkontur" . Die Validität der melodischen Hypothesen wird in einem Perzeptionsexperiment überprüft (Kapitel 4).
1.4 Gliederung der Arbeit
In Kapitel 2 geben wir eine Übersicht über die Methoden, die bislang bei der Untersuchung der deutschen lntonation angewendet wurden und deren Ergebnisse.
In Kapitel 3 werden natürliche Grundfrequenzverläufe durch Stilisierung auf die perzeptiv relevanten Aspekte reduziert. Es wird eine Stilisierung erstellt, die sich perzeptiv nicht von dem Original unterscheiden läBt und aus so wenig wie möglich geraden Linien besteht (Kopiekontur). In einem Experiment wird die perzeptive Gleichheit von Original und Kopiekontur überprüft. Ferner gehen wir auf die Hintergründe dieser Stilisierung ein.
In Kapitel 4 wird auf der Grundlage der Kopiekonturen ein melodi-

6 1. Einleitung
sches Modell entwickelt. Das Modell bestebt aus einem lnventar stándardisierter perzeptiv relevanter Tonhöhenbewegungen und aus Kombinationsregeln. Dieses Modell beschreibt die intonative Struktur des Deutschen. In einem Perzeptionsexperiment wird die Validität dieses Modells. nachgeprüft. Dazu wird die Akzeptabilität deutscher Standardkonturen einerseits mit Kopiekonturen und andererseits mit niederländischen und englischen Standardkonturen verglichen.
Kapitel 5 betrachtet die Ergebnisse unter versebiedenen Gesichtspunkten. Zunächst diskutieren wir die Ergebnisse. AnschlieBend vergleichen wir die Beschreibungen der deutschen, niederländischen und britisch englischen Intonation miteinander. Ferner nennen wir einige Anwendungen der Ergebnisse dieser Arbeit. SchlieBlich machen wir Vorschläge für weitere Forschungen.

2
Phonetische Untersuchungen zur deutschen Intonation
In diesem Kapitel hesprechen. wir eine repräsentative Auswahl aus der phonetischen Literatur zur deutschen Intonation. Die hesproehenen Untersuchungen sind folgendermaBen geordnet. Ahschnitt 2.1 giht die Ergehnisse impressionistisch orientierter Arheiten wieder, Ahschnitt 2.2 hetrachtet die Resultate akustischerUntersuchungen, Abschnitt 2.3 geht auf einige Modelle ein, nach denen künstliche Grundfrequenzverläufe erzeugt werden können.
2.1 Impressionistisch bestimmte Tonböhenverläufe
Bei einer impressionistischen Analyse wird ein wahrgenommener Tonhöhenverlauf mit Worten hesebrieben oder graphisch dargestellt.
Eine erste Charakterisierung der deutschen Intonation gibt von Helmholtzin "Die Lehre vonden Tonempfindungen" (1870):
"Das Ende eines bejahenden Satzes var einem Punkt pfiegt dadurch bezeichnet zu werden, daB man van der mittleren Tonhöhe urn eine Quarte fällt. Der fragende Schlufi steigt empor, oft urn eine Quinte über den Mittelton. ( ... ) Akzentuierte Worte werden ebenfalls dà.durch hervo~gehoben, daB man sie etwa einen Ton höher legt als die übrigen usf."
Von Helmholtz beschreiht hier den Tonhöhenverlauf am Ende von ÄuBerungen (Aussage- und Fragesätzen), und er macht genaue Angaben zur IntervallgröBe der hesebriebenen Tonhöhenbewegungen. Auflerdem
7

8 2. Phonetische Untersuchungen zur deutschen lntonation
ist an diesem Zitat bemerkenswert, daB von Helmholtz bereits die Bedeutung der Tonhöhe für die Akzentuierung, die Hervorhebung einer Silbe, erkennt.
Klinghardt (1923) legt eine detailliertere Untersuchung vor und stellt den Tonhöhenverlauf schematisch dar. Er gibt den Tonhöhenverlauf in einer ÄuBerung wieder, indem er für jede Silbe die relative Tonhöhe festlegt. Dabei verzichtet er auf quantitative Angaben hinsichtlich der In_. tervallgröBe: "( ... ) unsere Untersuchung gilt ausschlieBlich der Auf- und Abbewegung der Stimme, nicht den Intervallen( .. . )". Silben werden laut Klinghardt (im Gegensatz zu von Helmholtz) nicht durch die Tonhöhe hervorgehoben, sondern durch den Atemdruck. In der Transkription werden druckstarke (akzentuierte) Silben durch groBe Punkte markiert, kleine Punkte reprä.sentieren druckschwache Silben. Klinghardt nennt die graphische Wiedergabc eines Tonhöhenverlaufs, die sich bieraus ergibt, ein "Punktbild". In Abbildung 2.1 ist ein solches Punktbild dargestellt .
••• •• • • • •••
• • ___ · ._. ·-(·• .. ;. )-Abbildung 2.1: Punktbild eines weiterweisenden und emes abschliejJenden Taktes {in Klammern). Die relative Tonhöhe J·eder Bilbe wird als Punkt dargestellt. Druckstarke Bilben werden durch . grofte Punkte markiert, kleine Punkte geben druckschwache Bilben wieder. Die ÄujJerung lautet: "(. . .) dajJ die LIEbe in solchen TAgen ihre Eigenen WEge ging, (wird NIEmanden verWUNdern)". Akzentuierte Bilben werden durch GrojJbuchstaben wiedergegeben. Aus: Klinghardt, 1923.
Den Tonhöhenverlauf einer ÄuBerung teilt Klinghardt in Phrasierungseinheiten ein. Er unterscheidet dabei weiterweisende und abschlieBende Sprechtakte.
Die Silben innerhalb eines Sprechtakts weisen einen gleichmäBigen Ahfall der Tonhöhe auf, wobei die erste druckstarke Silbe am höchsten

2.1. Impressionistisch bestimmte Tonhöhenverläufe 9
liegt. Sie bildet den sogenannten "Taktkopf''. Die Beohachtung, daB die Tonhöhe im Verlauf eines Taktes abnimmt, deutet auf ein Phä.nomen hin, daB später unter dem Namen "Deklination" diskutiert wird.
Ein abschlieBender Takt (in Abbildung 2.1 in Klammern dargestellt) kennzeichnet sich "( ... ) durch einen deutlich. wahrnehmbaren Sprung der letzten Drucksilbe nach unten". Für einen weiterweisenden Takt (geht in Abbildung 2.1 dem abschlieBenden Takt voran) ist die Steigung amEnde charakteristisch. Dabei "( ... ) hebt sich der Ton der letzten Drucksilbe mit einem ( ... ) höchst auffä.lligen Sprung weit über die Stimmlage sogar des Taktkopfes hinaus".
Fragesä.tze mit Fragewort haben laut Klinghardt die Intonation eines Aussagesatzes (eines abschlie6enden Takts), Fragesätze ohne Fragewort enden mit einem weiterweisenden Takt.
In dieser impressionistischen Beschreibung versucht Klinghardt die charakteristischen Formmerkmale der deutschen Intonation zu erfassen, indem er für jede Silbe die relative Tonhöhe festlegt. Für die Akzentuierung oder Hervorhebung einer Silbe ist in Klinghardts Auffassung in erster Linie der Atemdruck ma6gebend. SchlieBlich betont Klinghardt die Bedeutung der melodischen Gliederung einer ÄuBerung und unterscheidet eine entsprechende weiterweisende Tonhöhenbewegung.
Grimme untersucht in zwei Veröffentlichungen (1925a, 1925b) die Frage, wie sich die unterschiedlichen Tonhöhen in einem Intonationsverlauf erklären lassen . Dazu stellt er seine Beschreibung auf eine syntaktische Grundlage. Seine Hypothese lautet, daB jedes Satzglied, wie Subjekt, Verb, direktes Objekt usw., eine spezifische Tonhöhe hat. Die syntaktische Struktur eines Satzes spiegele sich demnach in der Intonation. Grimme interessiert die Frage, "( ... ) was dem Hörer mit den sprachmusikalischen Nuancen an Hindeutungen auf syntaktische Begriffe geboten wlrd."
Bei norrnatem Sprechen unterscheidet Grimme neun Tonstufen. Mit "x" wird der Grundton, die niedrigste Stufe bezeichnet, die für das Satzende vorgesehen ist. Darüber befinden sich die übrigen acht Tonstufen; Tonstufe 8 ist die höchste. Zur Bestimmung der Tonstufen sagt Grimme: "Am reinsten kommt jede dieser 8 Tonstufen bei der Hauptsilbe der Satzglieder zum Gehör; nach dieser richtet sich die Tonalitä.t der Vor- und

10 2. Phonetische Untersuchungen zur deutschen Intonation
Nachsilben ( ... )." Die jeweiligen Tonstufe eines Satzgliedes wird über der "Hauptsilbe" notiert. Für das nicht modal gefärbte Prädikat beispielsweise ist Stufe 1 vorgesehen, für das Subjekt liegt die relative Tonhöhe bei Stufe 2 und Stufe 5.entspricht dem Adverb und dem Verbzusatz. Ein . Beispiel aus Grimroe (1925a):
2 1 5 5 x Die Son ne ging strah lend un ter
Für Grimroe stellen also die durch die Satzglieder bedingten Unterschiede in der Tonhöhe die entscheidenden intonativen Merkmale des Deutschen dar. In dieser Darstellung ist der Intonationsverlauf soweit reduziert, daB in der Transkription nur eine einzige Tonhöhe pro Satzglied angegeben wird.
Von Essen baut in seiner Arbeit "Grundzüge der hochdeutschen Satzintonation" (1964) auf Klinghardts Untersuchung auf. Zur Zielsetzung seiner Arbeit schreibt von Essen: "Sie wil! eine Klärung der Intonationsfragen des Hochdeutschen erstreben und besonders dem Studierenden, der Deutsch als Fremdsprache lernt, eine Hilfe zur Erlernung der auf Bühne und Kanzel, in Vortrag und Rede landesüblichen Melodie bieten." Dazu gibt von Essen Tonhöhenverläufe in schematisierten Melodiebildern wieder, damit der Lernende das "Typische" der Intonation erkenne. Von Essen verzichtet ausdrücklich auf eine visuelle Wiedergabe von gemesaenen Grundfrequenzverläufen. Ein Beispiel eines Tonhöhenverlaufs in von Essens Transkription ist in Abbildung 2.2 dargestellt.
Zu von Essens Transkription sind einige Erläuterungen erforderlich. In dieser schematisierten Darstellung eines Tonhöhenverlaufs berück
sichtigt von Essen Druckunterschiede zwischen einzelnen Silben. Druckschwache (unbetonte) Silben werden durch Punkte wiedergegeben, Striche repräsentieren die durch Druck hervorgehobenen (betonten) Silben. Die auffallendste der betonten Silben bekomrot zusätzlich einen Akut. Im allgemeinen betrifft es hier den letzten Akzent.
Striche und Punkte können in vier Tonhöhenstufen verwendet werden: tief, gehoben-tief, mittel und hoch. Die unbetonten Silben vor dem ersten Akzent liegen in der Tonstufe gehoben-tief oder mittel, die Akzente 'liegen

2.1. Impressionistisch bestimmte Tonhöhen verläufe 11
Eigner Herd ist Goldes wert. - . - .
.!. • •
Abbildung 2.2: Beispiel eines Tonhöhenverlaufs in von Essens Transkription. Druckschwache (unbetonte) Bilben werden durch Punkte wiedergegeben. Btriche repräsentieren die durch Druck hervorgehobenen (betonten) Bilben. Die auffallendste der druckstarken Bilben (meistens die letzte) bekommt zusätzlich ein Akzentzeichen in Form eines Akuts. Aus: von Essen, 1964.
in der Stufe hoch. Der erste Akzent liegt immeram höchsten, die nachfolgenden Akzente weisen einen stuCenweisen Abstieg der Tonhöhe auf. Unbetonte Silben nach dem letzten Akzent erreichen die Stufe "tier'.
Trotz Notierung auf der selben Höhe verlolgen alle Silben meist eine leicht absteigende Richtung. Auch hier finden wir einen Hinweis auf die Deklination.
Von Essen weist ferner darauf hin, übrigens genau wie Klinghardt, daB Akzente nicht ohne weiteres aneinander gereiht werden können, sondern daB längere Sätze sich aufgliedern. Diese Phrasierungseinheiten werden durch den Melodieverlauf gekennzeichnet. "Weiterweisende Aussprüche" haben als Merkmal, daB die Tonhöhe am Ende nicht die "Lösungstiefe" erreicht, sondern in einer "Schwebehaltung" bleibt oder etwas ansteigt.
Fragen können laut von Essen sowohl die Intonation einer Aussage aufweisen (Abbildung 2.2), als auch durch eine Steigung am Ende der ÄuBerung markiert werden. Von Essen weist darauf hin, daB diese Steigung nicht identisch mit der Weiterweisung ist, weil die Fr~ge im allgemeioen wesentlich höher endet.
Zur IntervallgröBe macht von Essen folgende Angaben. Zwischen den Tonstufen hoch und tief kann eine Quint bis eine Sext (7 bis 9 Halbtöne) angenommen werden.
lm Vergleich zu Klinghardt benutzt von Essen ein anderes Notationssystem, er unterscheidet versebiedene Tonhöhenstufen und macht explizite Angaben zur IntervallgröBe.

12 2. Phonetische Unteisuchungen zur deutschen Intonation
In den drei oben erwähnten Untersuchungen wird der wahrgenommene Tonhöhenverlauf in schematisierter Form wiedergegeben. Dabei haben wir drei Notationen kennengelernt. Zu diesen impressionistischen Transkriptionen ist folgendes zu bemerken.
Jeder Hörer kann bestätigen, da6 in einer Äu6erung Tonhöhenänderungen auftreten. Wie ein solcher wahrgenommener Tonhöhenverlauf jedoch genau aussieht, lä6t sich nicht ohne weiteres bestimmen. So zeigen die Daten von Zwirner und Zwirner (1937) beispielsweise, daB Versuchspersonen einen Tonhöhenverlauf nicht übereinstimmend transkribieren. Uneinigkeit bestebt sogar darüber, ob eine Steigung odereine Senkung der Tonhöhe vorliegt.
Auch Ergebnisse von Lieberman (1965) bestätigen, daB eine auditive, impressionistische Analyse keine zuverlässige lnformation über den tatsächlichen Verlauf der Tonhöhe in gesprachener Sprache bietet. In seiner Untersuchung machen Hörer über den Verlauf der Tonhöhe in einer ÄuBerung widersprüchliche Aussagen.
Diese Ergebnisse zeigen, daB impressionistisch fundierte Transkriptionen eines Tonhöhenverlaufs kein einheitliches Bild ergeben, nicht reproduzierbar sind. Deshalb liegt der Schlu6 nahe, daB diese Art der Analyse nicht dazu geeignet ist, die Formmerkmale der Intonation zu erfassen. Jones (1962, 1. Aufl.age 1918) ist sich dieser Prohiernatik bewuBt. Das Manko der impressionistischen Methode liegt seiner Meinung nach darin, daB der Hörer den ganzen Tonhöhenverlauf auf einmal transkeibieren mu6. Er schlägt deshalb vor, einen Tonhöhenverlauf in kleinen Schritten abzuhören. Dazu soli beim Abspielen einer Schaliplatte dieNadel in den stimmhaften Teilen der ÄuBerung an versebiedenen Stellen aus der Rille genommen werden. Die Tonhöhe des letzten gehörten Fragments kann der Hörer laut Jones gut identifizieren. Wenn eine ganze ÄuBerung auf diese Weise analysiert wird, ergibt sich ein zuverlässigeres Bild des Tonhöhenverlaufs.
In diesem Zusaromenhang ist au eh die "Gating"-Technik von 't Hart und Cohen (1964) zu erwähnen. Das Sprachsignal wird in Schritten von 30 ms abgehört. Die wahrgenommene Tonhöhe wird in diesem Ansatz jedoch nicht impressionistisch festgelegt, sondern mit dem einstellbaren Signaleines Vokalgenerators verglichen. Auf diese Weise kann ein Grundfrequenzverlauf ermittelt werden, der das akustische Korrelat des wahr-

2.2. Gemessene Grundfrequenzkurven 13
genommenen Tonhöhenverlaufs darstellt. Ein weiteres Problem einer impressionistisch fundierten Transkription
stellt ihre lnterpretation dar. Wer an Hand einer schematischen Darstellung den ursprünglichen Tonhöhenverlauf rekonstruieren will, muS eine erhebliche interpretative Leistung erbringen: Denn für jede Silbe ist nur eine einzige relative Tonhöhe angegeben. Es bleibt also dem Sprecher überlassen, wo er in der Silbe eine Tonhöhenbewegung realisiert oder wie lange eine Tonhöhenbewegung dauert. Da der Sprecher entscheidende Informationen ergänzen muB, ist keine eindeutige Interpretation der Transkription möglich. Der ursprüngliche Tonhöhenverlauf kann also nicht zuverlässig rekonstruiert werden.
Eine Alternative zu den hier oben geschilderten problematischen Ergebnissen einer impressionistischen Beschreibung ist die akustische Analyse.
2.2 Gemessene Grundfrequenzkurven
Bei einer akustischen Analyse wird gemessen, wie die Grundfrequenz (Fo) im Sprachsignal als Funktion der Zeit variiert. Die Grundfrequenz ist das akustische Korrelat der Tonhöhe. Im Gegensatz zu der subjektiven, impressionistischen Beschreibung eines Tonhöhenverlaufs, stellt eine Grundfrequenzkurve einen Intonationsverlauf objektiv dar.
Es gibt eine Vielzahl an Methoden, nach derien die Grundfrequenz bestimmt werden kann. Eine Übersicht gibt beispielsweise Hess (1983).
Die ersten akustischen Untersuchungen sind vor allem am Frequenzumfang der Tonhöhenbewegungen in akzentuierten Silben interessiert.
Pollak (1910) konstruiert vier Sätze, in denen dieselben oder ähnliche Lautgruppen sowohl am Anfang als am Ende des Satzes in akzentuierten Silben vorkommen, zum Beispiel "HAsen liefen urn die V Asen". Die Sätze wurden von zwei Versuchspersonen gesprochen. In den ÄuBerungen werden nur die (betonten) Stammsilben untersucht. Pollak gibt seine Messungen ( mit einem Kymographion) in Form von Tabellen und daraus abgeleiteten Grundfrequenzkurven wieder. Er kommt zu dem SchluB, daB "( ... ) die Vokale in Wörtern gleicher sinnhafter Betonung am Satzanfang stets einen höheren Ton tragen als am Satzende." Auch hier finden wir wiederurn einen Hinweis auf die Deklination.

14 2. Pbonetische Untersuchungen zur deutschen lntonation
Pollak stellt ferner fest, "( ... ) daB die Stimme gegen das Satzende zu urn ein Intervall fällt, das zwischen der verminderten Quint und der kleinen Septim, zwischen der gro6en Terz und der kleinen Sext liegt." In Halbtönen ausgedrückt, liegt die lntervallgröBe heim ersten Sprecher. zwischen 6 und 10 Halbtönen, beim zweiten Sprecher findet Pollak Werte, die zwischen 4 und 8 Halbtönen variieren.
Eine spätere Untersuchung von Kuhlmann (1931) bestä.tigt und erweitert die beobachtete Variabilität. Aus seiner Untersuchung geht hervor, daB die Intervallgrö6e deutscher Tonhöhenbewegungen zwischen 13 und 19 Halbtönen liegt.
Diese Ergebnisse zeigen, welcher Variabilität die Intervallgrö6e von Tonhöhenbewegungen amEnde einer ÄuBerung unterliegt und wie schwierig es deshalb ist, bieraus einen allgemein verbindlichen Wert, einen charakteristischen Frequenzumfang abzuleiten.
Delattre, Poenack und Olsen (1965) untersuchen a.n Hand spektrographischer Messungen zwei funktional unterschiedliche Grundfrequenzverläufe im Deutschen. Sie geben:
1. eine Beschreibung des Grundfrequenzverlaufs der "continuation", ein Melodieverlauf, der angibt, daB die ÄuBerung fortgesetzt wird. Für die "continuation" verwenden wir im weiteren den Begriff "Kontinuierung",
2. eine Beschreibung des Grundfrequenzverlaufs in der letzten betonten Silbe einer ÄuBerung. Die Funktion dieser terminalen, abschlieBenden Intonation bezeichnen Delattre et al. mit "finality", die wir als "Finalität" bezeichnen werden.
In ihrer Untersuchung unterscheiden Delattre et al. eine sogenannte groBe Kontinuierung (major continuation) mit einem relativ groBen Frequenzumfang (etwa 8 Halbtöne) und eine kleine Kontinuierung (minor continuation) mit einem entsprechend kleinen Frequenzumfang (etwa 4 Halbtöne).
Delattre et al. untersuchen spontan produzierte ÄuBerungen von vier Sprechern des (Nord-)deutschen sowie einen vorgelesenen Text. Das deutsche Material vergleichen sie mit Beispielen amerikanischer Intonation,

2.2. Gemessene Grundfrequenzkurven 15
urn so die für den Lemenden wichtigen intonativen Kontraste zu ermitteln.
Den Grundfrequenzverlauf einer Kontinuierung im Deutschen vergleichen Delattre et al. mit dem Profil eines singenden Vogels. Dieses Bild wird noch weiter differenziert:
"Having the bird picture in mind, it will be convenient to divide the pattern into a tail (dip, falling pitch), a back ( depression, fall-and-rise pitch), a neck (rising pitch in tilted S-shape), a head (high pitch plateau), and a beak (prolongation of high plateau for unstressed syllables) - a duck's beak is perhaps the most appropriate image here."
Abbildung 2.3 zeigt eine schematische Darstellung des hier oben beschriebenen Grundfrequenzverlaufs.
1 4 5 ;:--' 2 ~
Abbildung 2.3: Schematische Darstellung des Grundfrequenzverlaufs einer Kontinuierung. Delattre et al. vergleichen diesen Verlauf mit dem Profil eines singenden Vogels. Dieses Muster wird in fünf Abschnitte aufgegliedert: (1} tail, (2} back, (9} neck, (4) head und (5} beak. Aus: Delattre, Poenack und Olsen, 1965.
Zunächst fällt auf, daB in den ersten beiden Teilen der Kontinuierung ("tail" und "back") die Grundfrequenz sinkt. Laut Delattre et al. ist dieses Merkmal charakteristisch für das Deutsche.
Zur Position einer Kontinuierung in bezug auf eine akzentuierte Silbe geben Delattre et al. an, daf3 "back" und "neck" in der betonten Silbe liegen, so daB eine Kontinuierung im Deutschen als steigend charakterisiert werden kann.
Aus den Beobachtungen von Delattre et al. geht ferner hervor, daB eine groBe Kontinuierung in eine terminale lntonation ( "finality") übergehen kann, wenn der letzte Abschnitt des Grundfrequenzverlaufs (der

16 2. Phonetische Untersuchungen zur deutschen Intonation
ubeak") nicht hoch bleibt, sondern stark abfällt. Der Unterschied zwischen Kontinuierung und Finalität wird also erst relativ spät im Grundfrequenzverlauf deutlich.
Hier oben haben wir gesehen, daB sich die frühen akustischen Untersuchungen zunächst auf die lntervallgröBe der Tonhöhenbewegungen in akzentuierten Silben konzentrierten. Diese Untersuchungen ergeben, daB die IntervallgröBe eine beachtliche Variabilität aufweist.
Abgesehen vonder Unterscheidung zwischen einer groBen (8 Halbtöne} und einer kleinen (4 Halbtöne) Kontinuierung sind Delattre et al. nicht an der IntervallgröBe von Tonhöhenbewegungen interessiert, sondern untersuchen den Verlauf der Grundfrequenz in Tonhöhenbewegungen, die mit bestimmten Funktionen verbunden werden.
Den Grundfrequenzverlauf der Kontinuierung und der satzfinalen Intonation geben Delattre et al. in Form einer schematisierten Darstellung wieder, diesicheng an den akustischen Messungen orientiert (siehe Abbildung 2.3). lm Vergleich zu von Essens Transkription, die doch sehr stark von den akustischen Merkmalen abstrahiert - nur die relative Tonhöhe der einzelnen Silbe wird berücksichtigt -, gibt diese Darstellung einen Einblick in einen sehr viel konkreteren Verlauf der Grundfrequenz in gesprochener Sprache.
Zu einer Beschreibung der Intonation, die auf gemesaenen Grundfrequenzkurven beruht, ist folgendes zu bemerken. Betrachten wir dazu zunächst in Abbildung 2.4 die visuelle Wiedergabe einer Grundfrequenzkurve.
Ein typisches Merkmal einer sokhen Kurve ist, daB sich die gemesaenen Grundfrequenzwerte kontinuierHeb ändern. Durch diese Fülle der Variabilität ist die Beschreibung der Formmerkmale einer sokhen Intonationskurve kaum möglich, Regularitäten sind nicht ohne weiteres erkennbar. Eine Beschreibung ist also nut möglich, wenn dieser Verlauf stilisiert, vereinfacht dargestellt wird. Die entscheidende Frage dabei ist, nach wekhen Kriterien Vereinfachungen vorgenommen werden können. Eine ausschlieBlich visuelle Stilisierung, wie Delattre et al. sie vornehmen, reiebt nicht aus. Dies kann folgendermaBen begründet werden.
Die Ergebnisse experimenteller Untersuchungen zeigen (siehe Abschnitt 2.3), daB nicht alle Grundfrequenzänderungen für die Wahrnehmung im

2.3. Künstliche Grundfrequenzverläufe 17
> ::> 500
400
300
-;:; 200 E
0 u.
100 ······ ... ···· .. ·· ....... .
50 0.0 0.~ 0 . 8 1.2 1.6 2.0
t (sl
Abbildung 2.4: Die Grundfrequenzkurve der ÄujJerung: "Am Zaun steht eine Regentonne". Waagerecht die Zeit in Sekunden (s) und senkrecht die Grundfrequenz in Hertz (Hz}, logarithmisch skaliert. Die stimmlosen Anteile des Signals werden in der Zeile UV (unvoiced) abgebildet.
gleichen MaBe wichtig sind. Wir können zwischen perzeptiv relevanten und perzeptiv irrelevanten Grundfrequenzänderungen unterscheiden. Urn einen natürlichen Grundfrequenzverlauf sinnvoll interpretieren zu können, ist esalso erforderlich, daB diefür die Wahrnehmung irrelevanten Aspekte entfernt werden. Deshalb kann nur die Perzeption für die Stilisierung maBgebend sein.
lm folgenden Abschnitt bespreehen wirvier Untersuchungen, in denen künstliche, stilisierte Grundfrequenzverläufe hesebrieben werden.
2.3 Künstliche Grundfrequenzverläufe
Wie wir bereits in Abschnitt 2.2 gesehen haben, ergeben Messungen an der Grundfrequenz in natürlich gesproehenen ÄuBerungen einen kontinuierlich variablen Verlauf. Dieser Verlauf ist auf Grund seiner Komplexität sehr schwer zu interpretieren. Vereinfachte, künstliche Grundfrequenzverläufe dagegen geben einen deutlicheren Einblick in die Intonation. Die Voraussetzung ist aber, da.B die Stilisierungen perzeptiv adäquat sind.
Im folgenden bespreehen wir zunächst eine grundlegende Untersuchung von Isatenko und Scbädlich.
Isa~enko und Schä.dlich (1964) sind die ersten, die auf experinientellem

18 2. Phonetische Untersuchungen zur deutscben Intonation
Wege versuchen, für die Hörer relevante Formmerkmale deutscher Grundfrequenzverläufe zu ermitteln. Ihr Ziel ist es dabei ausdrücklich nicht, "( ... ) natürliche lntonationen ( ... ) möglichst naturgetreu nachzuahmen ( ... )". Vielmehr geht es ihnen darum, die Formmerkmale natürlicher. Intonation auf die akustischen Aspekte zu reduzieren, die dem Hörer bestimmte Funktionen signalisieren. So untersuchen sie zum Beispiel, wie groS das Intervall einer Grundfrequenzänderung mindestens sein muB, damit der Hörer die entsprechende Silbe deutlich als betont wahrnimmt.
Die Grundlage von Isacenko und Schädlichs Untersuchungen bilden natürliche, auf Band gesproebene Äu6erungen. Diese ÄuBerungen werden mit Hilfe eines Vocoders auf zwei versebiedene Frequenzen monotonisiert, das heiBt, daB die Grundfrequenz im Verlauf der ÄuBerung konstant bleibt. Aus diesen beiden Versionen einer ÄuBerung IäBt sich qurch Schneiàen und Kieben der Bandaufnahmen eine beliebige künstliche lntonation herstellen.
Abbildung 2.5 zeigt am Beispiel der Äu6erung "Die Vorbereitungen sind getroffen, alles ist bereit" eiu mögliches Ergebnis dieses Verfahrens. Die ursprüngliche Äu6erung ist dab ei auf 150 Hz bzw. 160 Hz monotonisiert worden. Der Unterschied zwischen beiden Frequenzen beträgt 1.1 HT.
160 Hza ~orbereitungen sind g~ lalles ist b4 150 Hza ldie I ffiroffen ~
Abbildung 2.5: Beispiel emer künstlichen Intonation, nach dem Ver/ahren von Isalenko und Schädlich. Die Äu.Perung "Die Vorbereitungen sind getroffen, alles ist bereit" ist auf 150 Hz bzw. 160 Hz monotonisiert worden. Durch Schneiden und Kleben der Bandaufnahmen entsteht ein künstlicher Grundfrequenzverlauf, der zwei diskrete Frequenzebenen berücksichtigt. Die Übergänge sind diskontinuierlich. Aus: lsalenko und Schädlich, 1964.
Die simulierte Intonation berücksichtigt also zwei diskrete Frequenzebenen, wobei die Übergänge diskontinuierHeb sind. Aus diesem Grund nennen lsacenko und Schädlich diese Übergänge "Tonbrüche".

2.3. Künstliche Grundfrequenzverläufe 19
Mit dieser extremen Vereinfachung des natürlichen Grundfrequenzverlaufs nebmen Isacenko und Schädlich in Kauf, daB sich die künstliche lntonation "( ... ) rnanebmal sogar sehr 'unnatürlich' ( ... )" anhört, aber dennoch können Hörer zu bestirnrnten Funktionen der Intonation eindeutige Aussagen rnachen. Auf einige Ergebnisse gehen wir irn fotgenden ein.
An Hand von Perzeptionstests zeigen Isacenko und Schädlich in ersten Versuchen beispielsweise, daB Testpersonen bestirnrnte sirnulierte Intonationsrnuster problernlos als "Aussage", "Frage", "Kontrast" oder "Weiterweisung" identifizieren können. So wird die ÄuBerung rnit folgendern Verlauf von 94,9% der Versuchspersonen als "Frage" gehört (Abbildung 2.6).
1~1
Abbildung 2.6: Beispiel einer simulierten "Frage"-lntonation. In einem Perzeptionstest bewerten 94.9% der Versuchspersonen diesen Verlauf als "Frage". Aus: lsacenko und Schädlich, 1964.
Die entsprechende natürliche Intonation wird von 95% der Versuchspersonen als "Frage" identifiziert. Dieses Ergebnis zeigt laut Isacenko und Schädlich, daB die künstliche Intonation "( ... ) offenbar die notwendigen akustischen Anhaltspunkte (cues) enthält, die es dern Hörer gestatten, diese 'unnatürlich' gesproehenen Sätze einern bestimrnten Typ natürlicher deutscher Sätze zuzuordnen."
In einern weite.ren Experiment erforschen Isacenko und Schädlich die IntervallgröBe zwischen den Tonstufen, bei der eine Silbe im Urteil der Hörer als "betont" gilt. Dazu wird die ÄuBerung "Er gibt uns einen guten Rat" rnit einer sirnulierten Intonation versehen, wo bei nur die Silbe Jgu-/ durch die Grundfrequenz hervorgehoben wird. Die Tonbrüche erfolgen unrnittelbar vor, bzw. nach der Silbe. Abbildung 2.7 zeigt den künstlichen Verlauf.
Es werden jeweils drei Versionen hergestellt, die sich nur hinsichtlich der IntervallgröBe des Akzents unterscheiden. Ausgehend von einern konstanten Tiefton von 150 Hz betragen die untersuchten lntervalle (a) 3 Hz, (b) 6 Hz und (c) 9 Hz. Das letzte Intervan entspricht etwa einem

20 2. Phonetische Untersuchungen zur deutschen Intonation
Ier gibt uns einen ~en Rat I
Abbildung 2.7: Künstlicher Grundfrequenzverlauf der Testäujlerung: "Er gibt uns einen guten Rat", in der nur die Silbe j-guj mit einem Tonhöhenakzent versehen wird; Aus: Isaéenko und Schädlich, 1964.
Halbton. Die Aufgabe von 50 Versuchspersonen bestebt darin, die betonte Silbe
zu identifizieren . In der ersten Version können die Versuchspersonen keine "Hervorhebung" ausmachen, in der zweiten Version geben 38% /gu-/ als betonte Silbe an, in der dritten Version erhöht sich die Übereinstimmung auf 98%.
Isal:enk<i und Schädlich schlieBen aus diesen Ergebnissen, daB eine optimale Unterscheidungsmöglichkeit betonter Silben erst bei einem Halbtonintervall gewährleistet ist .
Ferner untersuchen Isacenko und Schädlich die Bedeutung von Tonstufenwechsel für die Gliederung einer ÄuBerung. Dazu wird die ohne Pausen gesproebene Äu6erung "Johann brachte diese Bücher einer Freundin seiner Schwester" auf zwei Frequenzebenen monotonisiert (Tiefton 150 Hz, Hochton 178,6 Hz). Hieraus werden zwei Konturen hergestellt (siehe Abbildung 2.8) .
ieae Eneher einer F.re
Abbildung 2.8: Zwei künstliche Grundfrequenzverläufe, die eine tmterschiedliche Gliederung der Äujlerung "Johann brachte diese Bücher einer Freundin seiner Schwester" hervorrufen. Weitere Erläuterungen im Text. Aus: Isaéenko und Schä.dlich, 1964.
15 Versuchspersonen sollen für jede Version die Frage beantworten "Wem bringt Johann diese Bücher?" Für Version (a) lautet die übereinstimmende Antwort: "einer Freundin". Im zweiten Fall (b) antworten 10 von 15 Versuchspersonen: "seiner Schwester". lsal:enko und Schädlich

2.3. Künstliche Grundfrequenzverläufe 21
nebmen diese Ergebnisse als Bestätigung dafür, daB eine ÄuBerung auch ohne Pausen durch bestimmte Tonhöhenkonfi.gutationen gegliedert werden kano.
Isal:enko und Schädlich verwenden in ihren Untersuchungen zwei diskrete, monotonisierte Frequenzebenen mit .diskontinuierlichen Übergängen. Die Ergebnisse zeigen auf überzeugende Weise, daB der Hörer auch in einem solchen stark vereinfachten Verlauf bestimmte Funktionen, wie beispielsweise Akzentuierung oder Phrasierung ohne weiteres wiedererkennt.
Wie wir hier oben gesehen haben, geht es Isacenko und Schädlich ausdrücklich nicht darum, daB sich ihre Stilisierungen natürlich anhören. In späteren Veröffentlichungen, wie etwa Zingle (1982) oder Kohier (1988), auf die wir in den nächsten Abschnitten noch zurückkommen, zeigt sich aber, dafi gerade der Natürlichkeit künstlicher Intonation groBe Bedeutung beigemessen wird, vor allem m Hinblick auf die Anwendung in Sprachsynthesesystemen.
Zingle (1982) beschreibt ein Modell, wie die Intonation in dem Sprachsynthesesystem SAMT-4 der Deutschen Bundespost automatisch gesteuert werden kann. Wir beschränken uns hier auf die Beschreibung einiger Verläufe.
Für jede ÄuBerung ist eine Deklinationslinie vorgesehen, die in Zingles Beispielen bei 123Hz anfängt. Der Abfall der Grundfrequenz beträgt 1.5 Halbtöne pro Sekunde. Auf dieserLinie werden Grundfrequenzbewegungen superponiert, etwa zur Markierung eines Akzents.
Abhängig vonder Vokaldauer unterscheidet Zingle zwei akzentuierende Grundfrequenzverläufe (oder "motifs") in Form einer Glocke. Abbildung 2.9 (a) zeigt den Verlauf der Grundfrequenz für kurze akzentuierte Vokale (V'[-L]). Die Dauer der Steigung beträgt 160 ms; sie fängt 80 ms vor dem Vokaleinsatz an. Das Fa-Maximum wird am Ende des Vokals erreicht und liegt einen Halbton über dem Anfangswert der Steigung. Danach fällt die Grundfrequenz urn einen Halbton in 80 ms. Die Gesamtdauer dieses Verlaufs beträgt 240 ms.
In Abbildung 2.9 (b) ist der Grundfrequenzverlauf für lange akzentuierte Silben (V'[+L]) dargestellt. In diesem Fall dauert die Steigung 190 ms. Die Steigung setzt 80 ms vor dem Vokalanfang ein und erreicht ihr Fa-Maximum im zweiten Drittel des Vokals, einen Halbton über dem

22
--,-1
2. Phonetische Untersuchungen zur deutschen lntonation
Anfangswert. Von diesem Punkt an sinkt die Grundfrequenz in 80 ms urn einen Halbton. Dieser Verlauf dauert insgesamt 270 ms.
a
-1.5 demi-ton par seconde
b
F0 max
160 ms
+1 demi-ton
80 ms
' ' \ \
. ~· ' . ! - -'--..::;..'"..,: .. .:.:..·:..:.:·.::.:··~ ·.:..: -~ -..:?·-:...-_-.:-
-80 ms 80 ms
F0 max
190 ms +1 demi-ton
! 80 ms ~ )
i i \ i -1.5 demi-ton
par seconde I ----- i '.i r- .............. --:... :.:·..:.-.:.--:.-:.::·.:.:·.:.:·=·-·::·:-_-_-_-.::
-80 ms 160 ms
Abbildung 2.9: Zwei akzentuierende Grundfrequenzverläufe m Zingles Modell für Kurzvokale (a) und Langvokale (b) . Anfang und Ende der Vokale werden durch zwei durchgezogene senkrechte Linien markiert. Nach der Senkung mit einer Dauer von 80 ms wird die ursprüngliche Deklinationslinie ( gestrichelte Linie) nicht mehr erreicht. Weitere Erläuterungen im Text. Aus: Zingle, 1982.
Es ist zu beachten, daB nach der Senkung die ursprüngliche Deklinationslinie nicht mehr erreicht wird. Urn eine terminale Intonation zu

2.3. Künstliche GrundfrequenzverJäufe 23
simulieren, ist es deshalb laut Zingle notwendig, eine zusätzliche, nichtakzentuierende Senkung amEnde der ÄuBerung einzuführen (siehe Abbildung 2.10). Vom letzten Vokal der ÄuBerung an sinkt die Grundfrequenz mit einer Geschwindigkeit von einem Halbton pro 80 ms.
-~----G a r - -t e n """ i m
Abbildung 2.10: Realisierung der terminalen Intonation in Zingles Modell. Nach dem .Akzent auf der Silbe "Gar-" wird die ursprüngliche Deklinationslinie nicht mehr erreicht, so daP eine zusätzliche Senkung am Ende der Äufterung erforde~lich ist. Vom letzten Vokal an sinkt die Grundfrequenz mit einer Geschwindigkeit von einem Halbton pro 80 ms. Aus: Zingle, 1982.
In seinem melodischen Modell unterscheidet Zingle ferner progrediente, exklamative und interrogative Verläufe. Insgesamt umfaBt das lnventar unter Berücksichtigung einiger Varianten 15 Grundfrequenzverläufe.
Die Ergebnisse seiner intonativen Untersuchungen beurteilt Zingle a.ls "( ... ) entièrement satisfaisants à. l'audition". Es werden jedoch keine Perzeptionsexperimente erwähnt, in denen die Akzeptabilität der vorgeschlagenen Konturen überprüft wird.
In seiner "Modellskizze für die deutsche lntonation" (1983} entwirft Bannert einen Algorithmus, der ausgehend von phonologischen Strukturen einen (zunächst nur auf dem Papier existierenden) Grundfrequenzverlauf generiert. Urn die wichtigsten Charakteristiken der deutschen Intonation zu ermitteln, untersucht Bannert natürliche Grundfrequenzverläufe in ausgewählten ÄuBerungen, die von drei Sprecherinnen produziert wurden. Er analysiert drei Satztypen: Aussage, lnformationsfrage und Echofrage. Die gemesseoen Grundfrequenzkurven werden stilisiert wiedergegeben, indem zwischen Maxima und Minima linear interpoliert wird.

24 2. Phonetische Untersuchungen zur deutschen Intonation
Aus dem Vergleich dieser stilisierten Grundfrequenzverläufe ergeben sich die charakteristischen Formmerkmale der einzelnen Akzente sowie der Satzintonation im allgemeinen.
An Hand von zwei Beispielen, einer Aussage sowie einer lnformationsfrage, beschreiben wir im folgenden, wie in diesem Modell auf der Basis prosodischer Merkmale ein Grundfrequenzverlauf generiert werden kann.
Für jeden Satz sowie für einzelne Silben werden prosodische Merkmale festgelegt, die teilweise vom Kontext abhängig sind. Wir beschränken uns hier auf die tonalen Merkmale, die für die beiden Beispiele notwendig sind.
Mit "+AKZ" werden akzentuierte Silben markiert. Ein weiteres Merkmal betrifft den prosodischen Satztyp. Bei einer Frage steigt die Tonhöhe gegen Ende der ÄuBerung an ( markiert durch "-ABG"), in einer Aussage fällt die Tonhöhe ( angegeben durch "+ ABG").
Die Eingabe sieht für eine Aussage und eine lnformationsfrage (mit jeweils vier Tonhöhenakzenten) wie folgt aus (Abbildung 2.11):
EINGABE Au.ssage
[ +AKZ +AKZ +AKZ +AKZ J Der Müller in Lingen will die Männer immer Lümmel nennen + ABG
lnformationsfrage
[ +AKZ +AKZ +AKZ +AKZ J Will der Müller in Lingen die Männer immer Lümmel nennen -ABG
Abbildung 2.11: Beispiel einer Eingabe für eine Aussage und eine Jnformationsfrage, jeweils mit vier Tonhöhenakzenten. Aus: Bannert, 1989.
Die phonologische Komporrente überführt diese tonalen prosodischen Merkmale in, wie Bannert es formuliert, "( ... ) tonale Werte von Punkten oder Ebenen Hoch (H) bzw. Tief (T) ( ... )". Dabei gelten folgende Regeln:
1. +AKZ ~ H, wenn final in Aussage, sonst immer T. Beidesim Vokal.
2. +ABG ~Tin letzter Silbe (letztem Vokal).
3. -ABG ~ H in letzter Silbe (letztem Vokal) .

2.3. Künstliche Grundfrequenzverläufe 25
Nach Anwendung dieser Regeln ergeben sich für die Aussage und die Informationsfrage aus Abbildung 2.11 phonologische Strukturen (Abbildung 2.12).
PHONOLOGISCHE KOMPONENTE Aussage
[ T T T H TJ Der Müller in Lingen wilt die Männer immer Lümmel nennen
lnformationsfrage
[ T T T T HJ Will der Müller in Lingen die Männer immer Lümmel nennen
Abbildung 2.12: Bei8piele phonologischer Strukturen einer Aussage und einer Informationsfrage mit ieweils vier Tonhöhenakzenten. Aus: Bannert, 1983
Auf diese phonologischen Strukturen wird der lntonationsalgorithmus angewendet. Die einzelnen Schritte, die für die Aussage und Informationsfrage in obigem Beispiel (vier Akzente) zu einer entsprechenden Grundfrequenzkontur führen, sind in Abbildung 2.13 (a-e) dargestellt.
Zu dieser graphischen Darstellung sind einige Erläuterungen erforderlich. Zunächst ist es laut Bannert notwendig, "( .. . ) gewisse tonale Ebenen oder tonale Richtwerte zu bestimmen, urn den Rahmen für den Grundfrequenzverlauf der ÄuBerung zu fixieren" . Dazu werden vier Eckwerte im Frequenzbereich definiert. Drei Werte beziehen sich auf F0-Minima (T), eine Angabe betrifft das F0-Maximum (H) der Frageintonation:
1. Letztes "T" der Aussage -+ Fo-Mina: das absolute Fo-Minimum, der tiefste Punkt am Ende der Aussage,
2. Ietztes·"T" derFrage -+ F0-Min1: das finale F0-Minimum, der tiefste Punkt des letzten Akzents bei der Frage,
3. erstes "T" in Aussage und Frage: -+ F0-Min;: das initiale F0-
Minimum, der tiefste Punkt des ersten Akzents,
4. (letztes) "H" der Frage -+ F0- Ma x,: das finale Fo~ Maximum, der höchste Punkt am Ende von Fragen.

26 2. Phonetische Untersuchungen zur deutschen Intonation
Diese (nicht näher quantifizierten) Grundfrequenzwerte sind auf der Ordinatenachsein Abbildung 2.13 (a) für Aussage und InformaÜonsfrage angegeben. Die vier Akzente der obigen Beispielsätze werden auf der Abszisse durch schwarze Kästchen markiert.
Die Grundfrequenzwerte der übrigen "T" werden in den beiden Beispielen so festgelegt, daB zwischen den einzelnen "T" in etwa die gleiche IntervallgröBe liegt. Bis auf das Merkmal "H" in der Aussage sind jetzt alle "H" und "T" in Grundfrequenzwerte umgesetzt, wie (b) zeigt. Die "T"-Grundfrequenzwerte ergeben in beiden Beispielen einen absteigenden Verlauf, den Bannert "Tallinie" nennt.
Ausgehend vonden ermittelten Grundfrequenzwerten werden in einem dritten Schritt ( c) Grundfrequenzänderungen (Tonhöhenbewegungen) eingeführt. Zunächst werden alle F0-Minima - mit Ausnahme des F0-
Minimums am Ende der Aussage - mit einer Steigung versehen. Wie aus Bannerts Beobachtungen hervorgeht, ist der Frequenzumfang der Tonhöhenbewegung im ersten Akzent gröf3er als die übrigen.
Die Senkung im letzten Akzent der Aussage wird folgendermaBen ermittelt. Das Merkmal "H" wird in einen Grundfrequenzwert überführt, der dem Endwert der vorangehenden Steigung entspricht. Dieser Grundfrequenzwert bildet den Anfangspunkt der Senkung; der Frequenzumfang der Senkung entspricht dem der vorangehenden Steigung.
In einem vierten Schritt ( d) wird der Grundfrequenzverlauf vor dem ersten Akzent bestimmt. In der Aussage entspricht die Anfangsfrequenz dem Wert von Fo-Min;. Das heiBt, daB der Verlauf monoton ist.
Für die Frage wird die Anfangsfrequenz etwa in der Mitte des Intervalls zwischen F0-Min; und F0-M axh angesiedelt. Die interpolierte Grundfrequenz ergibt in diesem Fall eine Senkung.
In einem letzten Schritt (e) wird die Kontur vervollständigt. Dazu wird die Grundfrequenz zwischen den übrigen Punkten linear interpoliert. Bannert weist noch darauf hin, daB die Verbindung der tragenden Punkte der Grundfrequenzkontur auch nach einer Kosinusfunktion vorgenommen werden kann.
Bannert versucht in seiner ausführlichen Darstellung zu zeigen, wie man ausgehend von Akzentverteilungen in einem Satz einerseits und Erkenntnisse über wesentliche Aspektedes Grundfrequenzverlaufs andererseits zu einer künstlichen Intonationskontur gelangen kann.

2.3. Künstliche Grundfrequenzver/äufe
fo a Maxt ~
b
c
Min1 ~ Mint Mina~
~ 0
AUSSAGE
.I I /\ d
e
27
INFORMATIONSFRAGE
I 1 ! I
Abbildung 2.13: Graphische Darstellung der einzelnen Bchritte (a) bis {e}, die Bannerts Intonationsalgorithmus für eine Aussage und eine Informationsfrage durchläuft. Senkrecht ist die Grundfrequenz {Fo} abgebildet, waagerecht sind einzelne Segmente der Beispieläuflerungen dargestellt. Akzente werden durch schwarze Kästchen markiert. Nähere Erläuterungen im Text. Aus: Bannert, 1983.

28 2. Phonetische Untersuchungen zur deutschen lntonation
Was den Grundfrequenzverlauf betrifft, so nimmt Bannert in seinem Modell Vereinfachungen vor, die wohl ausschlieB!ich visuell motiviert sind. Eine akustische Realisierung und eine perzeptive Überprüfung seiner Konturen werden jedenfalls nicht erwähnt. Zu den vorgeschlagenen Konturen hei6t es: "Bei einem Vergleich der F0-Kurven, die das Modell generiert, mit den gemesaenen Kurven der Produktion ( ... ) läBt sich eine gute Übereinstimmung feststellen." DieFrageist aber, was eine gute visuelle Übereinstimmung zwischen einer Kurve und einer Kontur über die Relevanz einer auf dem Papier vorgenommenen Stilisierung aussagt. Vielmehr ist von entscheidender Bedeutung, ob diese Stilisierung auch perzeptiv adäquat ist. Dazu muB eine künstliche Kontur hörbar gemacht und auf ihre perzeptive Legitimität hin untersucht werden.
Kohier (1988) beschreibt ein lntonationsmodell für das Deutsche, wie es im INFOVOX Sprachsynthesesystem implementiert worden ist (Carlson und Granström, 1976; Carlson, Granström und Hunnicutt, 1982) .
Den Ausgangspunkt in Kohlers Model! bilden Sätze, die in Phrasen zerlegt werden. Innerhalb jeder Phrase werden nach phonologischen Regeln die akzentuierten Silben bestimmt. Im folgenden gehen wir auf einige Aspekteder Grundfrequenzsteuerung näher ein.
Für eine akzentuierte Silbe (au6er der letzten einer Phrase) werden zwei Frequenzwerte (90 und 130Hz für einen männlichen Sprecher) festgelegt, zwischen denen die Grundfrequenz linear interpoliert wird.
Die tiefste Grundfrequenz liegt am Silbenanfang, beispielsweise im ersten Konsonanten; die Position des höchsten Frequenzwertes wird durch die phonologische Quantität (lang versus kurz) und durch die Qualität des Vokals (offen versus geschlossen) bestimmt. Je länger der Vokal ist, desto weiter liegt der höchste Frequenzwert im Vokal.
Der Grundfrequenzverlauf im letzten akzentuierten Vokal einer Phrase wird durch drei Punkte im Zeit-/Frequenzbereich bestimmt. Am Ende einer Phrase kann die Grundfrequenz fallen oder steigen. Kohier unterscheidet dabei drei Verläufe:
1. Terminaier Fall: Die beiden ersten Punkte liegen bei 90 und 130 Hz. Diese Werte entsprechen den Angaben für eine akzentuierte Silbe hier oben. Der dritte Frequenzwert beträgt 80Hz und folgt dem vor-

2.3. K ünstliche Grundfrequenzverläufe 29
angehenden Gipfel nach einem konstanten Zeitintervall. Das Ende einer ÄuBerung wird durch einen Frequenzwert von 70Hz angegeben.
2. Kontinuierung (Steigung): Am Anfang der akzentuierten Silbe beträgt der Frequenzwert 85 Hz, der nächste Wert liegt bei 100 Hz und steigt weiter bis 120 Hz am Ende des stimmhaften Teils vor der Phrasengrenze.
3. Fragesteigung: Der Anfangswert in der akzentuierten Silbe liegt bei 90 Hz, der nächste Wert im Vokal beträgt 100 Hz und der F0-Gipfel am Ende des stimmhaften Teils vor der Phrasengrenze beträgt 200 Hz.
In jeder Phrase werden Akzente gebildet durch Steigungen und Senkungen. Die Gipfel, die sich aus diesen Kombinationen ergeben, werden innerhalb einer Phrase abgestuft, indem jeder Gipfel einen Halbton niedriger als der vorangehende positioniert wird. In jeder neuen Phrase erhält der erste Gipfel wiederurn den ursprünglichen Wert, wonach die Abstufung erneut anfängt. Die unterste Grenze der Gipfelabsenkung beträgt 95 Hz.
Die hier oben spezifizierten Kombinationen von Steigungen und Senkungen sind so positioniert, daB der Gipfel etwa in der Mitte des akzentuierten Vokals liegt. Kohier unterscheidet noch zwei weitere Positionen:
1. früh: Der hohe Frequenzwert ist nach links bis zum Anfang der akzentuierten Silbe verschoben, der erste niedrige Frequenzwert liegt 100 ms vor dem höchsten Punkt. Der niedrige Punkt nach dem Gipfel entspricht der ursprünglichen Position des höchsten Frequenzwertes.
2. spät: Die niedrigste Anfangsfrequenz versebiebt sich nach rechts zur ursprünglichen Position des höchsten Frequenzwertes, der sich urn 150 ms nach rechts verschiebt. Der niedrige Endpunkt liegt 100 ms binter dem Gipfelwert.
Wenn ein früher Gipfel einem mittleren oder späten Gipfel folgt, so wird die Grundfrequenz zwischen beiden Gipfelwerten interpoliert.
Ferner gibt Kohier einige Regeln für den Grundfrequenzverlauf in Abhängigkeit von segmentellen Merkmalen. So wird beispielsweise der Gipfelwert in einem geschlossenen Vokal urn einen Faktor 1.08 erhöht.

30 2. Phonetische Untersuchungen zur deutschen Intonation
Die im INFOVOX Sprachsynthesesystem erzeugte Intonation beurteilt Kohier als "quite natura!". Das implementierte Modell stützt sich jedoch nicht auf Perzeptionsexperimente, in denen die Akzeptabilität der vorgeschlagenen Konturen überprüft wird.
Hier oben haben wir die Ergebnisse von vier Untersuchungen zusammengefaBt, in denen künstliche Grundfrequenzverläufe hesebrieben werden.
Isacenko und Schädlich (1964) konnten nachweisen, dafi Hörer in natürlich gesproehenen Äufierungen, diemit einem extrem vereinfachten künstlichen Grundfrequenzverlauf versehen sind, bestimmte intonative Funktionen, wie Akzentuierung oder Phrasierung problemlos wiedererkennen. Natürliche Grundfrequenzverläufe lassen sich also relativ stark vereinfachen, ohne dafi funktionale Aspekteder Intonation dadurch beeinträchtigt werden.
In diesen Experimenten ging es ausdrücklich nicht darum, eine natürlich klingende Intonation zu erzeugen.
Bannert (1983) erstellt ein melodisches Model!, dessen Grundfrequenzverläufe aber nicht explizit genug sind, urn sie akustisch zu realisieren. Es bleiben Stilisierungen auf dem Papier.
Spätere Untersuchungen (Zingle, 1982; Kohier, 1988) sind anwendungsbezogen und zielen darauf ah, in Sprachsynthesesystemen eine Intonation zu generieren, die natürlich klingt. Die Frage, inwiefern die erzeugte Intonation einem natürlichen Höreindruck entspricht, wird jedoch nur unzureichend beantwortet. In beiden Untersuchungen werden nur informelle Qualitätsurteile erwähnt. Ergebnisse formeller Perzeptionsexperimente, in denen Versuchspersonen künstliche Grundfrequenzverläufe auf ihre Akzeptabilität hin beurteilen, liegen nicht vor. Daher ist die Validität von Zingles und Kohlers intonativen Beschreibungen unsicher.
2.4 SchluBfolgerungen
In den vorigen Abschnitten haben wir beschrieben, wie und mit welchen Ergebnissen die deutsche lntonation bislang untersucht worden ist, manehmal auch verbunden mit Fragen der Akzentuierung. Selbstverständlich

2.4. SchluBfolgerungen 31
stellen die hier hesproehenen Untersuchungen nur einen Bruchteil der umfangreichen Literatur zur deutschen Intonation dar. Aber dennoch geben diese Arbeiten einen guten Überblick über die bisherigen Erkenntnisse und über die vorliegenden Probleme.
So hat es sich gezeigt, daB impressionistische Beschreibungen unzuverlä.ssig sind, weil ein Tonhöhenverlauf sehr unterschiedlich transkribiert wird. AuBerdem sind impressionistische Transkriptionen der Intonation oft wenig explizite, so daB der Sprecher eine gro6e interpretative Leistung erbringen muB, urn den intendierten Intonationsverlauf zu rekonstruieren. Dabei ist nicht gewährleistet, da6 das Ergebnis dem ursprünglichen Verlauf entspricht.
Eine akustische U ntersuchung der Intonation hingegen bietet ein sehr explizites und detaillierles Bild eines Grundfrequenzverlaufs. Gleichzeitig ist die Kurve so komplex, sie weist so viel Variabilität auf, daB eine Beschreibung kaum möglich ist. Regularitäten sind in einem natürlichen Verlauf nicht ohne weiteres erkennbar.
SchlieBlich haben wir Beschreibungen künstlicher lntonation kennengelernt, in denen ein Grundfrequenzverlauf einfacher dargesteUt wird. In zwei Untersuchungen (Zingle, 1982 und Kohier, 1988) wird der Anspruch erhoben, daB sich die künstliche lntonation natürlich anhört. Diese Behauptung beruht in beiden Fällen nur auf informellen Qualitätsurteilen und wird nicht durch ein Perzeptionsexperiment bestätigt. Aus diesem Grund ist die Frage der Validität dieser Beschreibungen noch weitgebend unbeantwortet.
In dem Modell der deutschen lntonation, das wir im weiteren entwikkeln, spielt der Aspekt der Evaluierung eine wesentliche Rolle. Denn eine perzeptive Überprüfung der intonativen Hypothesen ist unerläBlich, urn die Validität des melodischen Modelis zu bestimmen (siehe Kapitel 4).

32 2. Phonetische Untersuchungen zur deutschen Intonation

3
Grundfrequenzkurven und Kopiekonturen
3.1 Die Kopiekontur
Wie wir gesehen haben, enthält die natürliche Intonation sowohl für die Wahrnehmung relevante als irrelevante Grundfrequenzänderungen. De Pijper (1983) bat eine Stilisierung entwickelt, mit der die perzeptiv relevanten Aspekte einer Grundfrequenzkurve von perzeptiv irrelevanten Merkmalen getrennt werden können. Dazu wird der natürliche Grundfrequenzverlauf (logarithmisch skaliert) mit Hilfe gerader Linien zunächst so stilisiert, daB sich das Ergebnis genauso anhört wie das Original. Stilisierung und Original sind also perzeptiv gleich. Damit gewährleistet ist, daB nur die für die Perzeption relevanten Grundfrequenzä.nderungen erfaBt werden, ist es erforderlich, daB für die Stilisierung so wenig wie möglich gerade Linien benutzt werden.
Die Stilisierung einer Grundfrequenzkurve, die sich perzeptiv nicht von dem Original unterscheidet und dabei aus einer Mindestanzahl von geraden Linien besteht, nennen wir eine "Kopiekontur". (De Pijper verwendet hierfür den Terminus "close-copy stylization" .)
Der Begriff "Kontur" bezieht sich in dieser Arbeit ausschlieBlich auf einen stilisierten Grundfrequenzverlauf; eine "Kurve" hingegen gilt als niclit-stilisiert. Der Terminus "Kopiekontur" drückt also aus, daB der Grundfrequenzverlauf zwar stilisiert, vereinfacht worden ist, daB dieser Eingriff jedoch ohne perzeptive Konsequenzen bleibt. Das heiBt, daB die SÜ!isierung im Urteil des Hörers als Kopie gilt.
In diesem Kapitel überprüfen wirdie perzeptive Gleichheit von Origi-
33

34 3. Grundfrequenzkurven und Kopiekonturen
nalintonation und Kopiekontur an Hand eines Experimentes (siehe Abschnitt 3.5).
Doch bevor wir zur Besprechung dieses Experimentes kommen, beschreiben wir zunächst, wie aus einer natürlichen Grundfrequenzkurve. eine Kopiekontur entsteht (Abschnitt 3.2) und welche Bedeutung der Kopiekontur bei der Modellbildung zukommt (Abschnitt 3.3). In Abschnitt 3.4 gehen wir auf die Akustik und Perzeption der Kopiekontur näher ein.
3.2 Vonder Grundfrequenzkurve zur Kopiekontur
Hier schildern wir das Stilisierungsverfahren, das von einem gemessenen, natürlichen Grundfrequenzverlauf zur Kopiekontur führt.
Voraussetzung für die Stilisierung ist, daB die ÄuBerung in LPC-analysierter Form mit separat gemesseoer Grundfrequenz vorliegt (sieh~ Abschnitt 1.3).
Zur Stilisierung wird die Grundfrequenzkurve auf einem Computerbildschirm graphisch dargestellt. Abbildung 3.1 zeigt zum Beispiel den gemesaenen Grundfrequenzverlauf der ÄuBerung "Gib mir hitte die Butter". Die Grundfrequenzwerte werden in Schritten von 10 ms auf einer logarithmischen Skala als Funktion der Zeit wiedergegeben.
> ::>
500
•oo 300
-;:, 200 ~ · ..... ·
0 LL.
100
50 0.0 0.3 0.6 0 . 9 1.2 1.5
t (s)
Abbildung 3.1: Die Grundfrequenzkurve der Äujlerung: "Gib mir bitte die Butter". Waagerecht die Zeit in Sekunden (s) und senkrecht die Grundfrequenz (Fo) in Hertz (Hz), logarithmisch skaliert. Die stimmlosen Anteile des Signals werden in der Zeile UV (unvoiced} abgebildet.

3.2. Von der Grundfrequenzkurve zur Kopiekontut 35
Mit Hilfe eines Bildschirmcursors kann jeder MeBpunkt der Kurve interaktiv mit einem anderen F0- Wert zwischen 50 Hz und 500 Hz versehen werden. Da jeder einzelne MeBpunkt verändert werden kann, ist es möglich, aus einem gemessenen Grundfrequenzverlauf eine willkürliche andere Kontur herzustellen. Nach Resynthese kann die ursprüngliche ÄuBerung mit der neuen Kontur hörbar gemacht werden.
Für die Erstellung einer Kopiekontur orientieren wir uns am Originalverlauf. Wir versuchen den Originalverlauf zu vereinfachen, indem wir Abschnitte der Kurve durch gerade Linien ersetze. Diese Abschnitte werden durch Wendepunkte in der Kurve begrenzt. Die geraden Linien entstehen, indem wir zwischen zwei Wendepunkten linear interpolieren.
Stilisierung und Original können sowohl ganz als auch in Abschnitten bis zu 10 ms hörbar gemacht werden. Zunächst verglekhen wir beide Versionen in kleinen Schritteli, etwa zwischen zwei Wendepunkten, auditiv miteinander, ob sie perzeptiv gleich sind. Ist ein Unterschied hörba.r, so wird die Stilisierung mit Hilfe des Cursors am Bildschirm korrigiert, bis sie sich genauso anhört wie das Original.
Das Ergebnis dieser ersten Schritte ist in Abbildung 3.2 da.rgestellt. Die perzeptiv gleiche Stilisierung bestebt jetzt aus 12 geraden Linien.
> ::l
500
400
300
'N 200 ~
0 u.
tOO
eo~--------------~--~------------~--~-------------4 0.0 0 . 3 0 . 6 0.9 1.2 1.5
t (s)
Abbildung 3.2: Die Grundfrequenzkurve (gepunktete Linie) und eine perzeptiv gleiche Stilisierung (durchgezogene Linie} der Äufterung: "Gib mir bitte die Butter". Waagerecht die Zeitin Sekunden {s} und senkrecht die Grundfrequenz {Fo) in Hertz {Hz), logarithmisch skaliert. Die stimmlosen Anteile des Signals werden in der Zeile UV {unvoiced} abgebildet.

36 3. Grundfrequenzkurven und Kopiekonturen
Urn etwaige perzeptiv irrelevante Grundfrequenzänderungen aus dieser Stilisierung zu entfernen, verringem wir die Anzahl der geraden Linien und überprüfen, ob Original und Stilisierung noch perzeptiv gleich sind. Beide Versionen werden jetzt in gröBeren Schritten, auch zwischen zwei Wendepunkten, miteinander verglichen.
Es zeigt sich im Falie unserer BeispieläuBerung, daB die Stilisierung auf fünf gerade Linien reduziert werden kann (Abbildung 3.3), ohne daB ein Unterschied zum Original hörbar wird. Die übrigen Grund- . frequenzänderungen, wie sie im Original sichtbar werden, können als "Mikro-Intonation" betrachtet werden.
> :::>
500
~00
300
'N 200 ~
0 ~
lOO
&0~--------~--~----~--~------~------------~----~ 0 . 0 0.3 0 . 6 0.9 1.2 1.5
t (s)
Abbildung 3.3: Die Grundfrequenzkurve (gepunktete Linie) und eine Kopiekontur ( durchgezogene Linie) der Ä ujJ erung: "Gib mir bitte die Butter". Waagerecht die Zeitin Sekunden {s) und senkrecht die Grundfrequenz {Fo) in Hertz {Hz), logarithmisch skaliert. Die stimmlosen Anteile des Signals werden in der Zeile UV {unvoiced) abgebildet.
Wenn wir versuchen, die Anzahl der geraden Linien weiter zu reduzieren, treten sofort deutlich hörbare Unterschiede auf.
Nur die Stilisierung, die aus 5 geraden Linien (perzeptiv relevante Grundfrequenzänderungen) besteht, erfüllt die beiden Kriterien einer Kopiekontur: (1) Die Stilisierung und das Original sind perzeptiv gleich, zwischen der resynthetisierten Stilisierung und dem resynthetisierten Original ist kein Unterschied hörbar. (2) Die Stilisierung bestebt aus einer Mindestanzahl von Grundfrequenzänderungen, repräsentiert durch gerade Linien.

3.2. Von der Grundfrequenzkurve zur Kopiekontur 37
Jede dieser Grundfrequenzänderungen wird durch ihre Anfangsfrequenz, ihre Endfrequenz sowie ihre Dauer bestimmt. Die entsprechenden Parameterwerte sind in Tabelle 3.1 wiedergegeben.
Ta belle 3.1: Die drei Parameterwerte der fünf perzeptiv relevanten Grundfrequenzänderungen aus Abbildung 3.3: die Anfangsfrequenz; die Endfrequenz sowie die Dauer.
Grundfrequenz- Anfangs- End- Dauer änderung frequenz {Hz) frequenz {Hz) (ms)
1 139 172 160 2 172 120 450 3 120 159 80 4 159 74 220 5 74 67 70
Aus diesendrei Parametern können für jede perzeptiv relevante Grundfrequenzänderung der Frequenzumfang und die Geschwindigkeit errechnet werden (Tabelle 3.2) .
Tabelle 3.2: Der Frequenzumfang und die Geschwingkeit der perzeptiv relevanten Grundfrequenzänderungen aus Abbildung 3.3 errechnet an Hand der Parameterwerte in Tabelle 3.1.
Grundfrequenz- Frequenz- Geschwindig-änderung umfang (HT) · keit (HT /s)
1 3.7 23.0 2 -6.2 -13.8 3 4.9 60.9 4 - 13.2 - 60.2 5 -1.7 - 24.6
Nach dem hier oben hesebriebenen Verfahren kann aus einem gemessenen Grundfrequenzverlauf eine Kopiekontur ersteUt werden.
Es gibt jedoch nicht nur einè einzige Kopiekontur eines Grundfrequenzverlaufs. Es ergeben sich akustisch unterschiedliche Kopiekonturen, wenn jemand eine bestimmte Grundfrequenzkurve mehrere Male

38 3. Grundfrequenzkurven und Kopiekonturen
stilisiert. Unterschiede treten auch auf, wenn versebiedene Personen die Stilisierung vornehmen. Bei einer Kopiekontur ist nicht die Anzahl der Wendepunkte sondern die Bestimmung ihrer genauen Position im Zeitals auch Frequenzbereich ein Unsicherheitsfaktor. Kopiekonturen unterliegen deshalb immer einer gewissen Variabilität. Es handelt sich dabei jedoch immer urn Unterschiede, die innerhalb des perzeptiven Toleranzbereichs liegen und somit unhörbar sind.
Da ein Original und die entsprechende Kopiekontur per definitionem gleich sind, umfa.Bt eine Kopiekontur alle perzeptiv relevanten Grundfrequenzänderungen; da die Kopiekontur aus einer Mindestanzahl gerader Linien besteht, umfaBt sie ausschlieBlich perzeptiv relevante Grundfrequenzänderungen.
3.3 Die Relevanz der Kopiekontur
Die Bedeutung einer Kopiekontur liegt darin, daB ein natürlicher Grundfrequenzverlauf auf seine perzeptiv relevanten Eigenschaften reduziert werden kann, ohne daB der Hörer einen Unterschied zum Original feststellt. Diese Stilisierung führt zu einer erheblichen Datenreduktion: Es werden nur die perzeptiv relevanten Grundfrequenzänderungen berücksichtigt, die visuell als gerade Linien dargestellt werden. Gegenüber der Variabilität, die eine Grundfrequenzkurve aufweist, ist eine Kopiekontur einfacher zu interpretieren.
Eine Kopiekontur refiektiert ausschlieBlich die perzeptiv relevanten Merkmale eines spezifischen Grundfrequenzverlaufs. Sie ist daher immer ein Unikat. Über die allgemeinen Merkmale der Intonation sagt eine Kopiekontur folglich nichts aus. Eine Beschreibung der intonativen Struktur des Deutschen ist hingegen an den rekurrenten Merkmalen interessiert. Erst aus dem Vergleich einer Anzahl von Kopiekonturen lassen sich Gemeinsamkeiten extrahieren. Auf dieser Grundlage sind durch Standardisierung Generalisierungen möglich und es lassen sich Hypothesen aufstellen, in Form eines melodischen Modells. Kopiekonturen stellen dabei also einen ersten Schritt dar. In Kapitel 4 gehen wir auf die Standardisierung und das melodische Model! ein.
Doch zunächst wenden wir uns im folgenden Abschnitt derFrage zu, weshalb eine Grundfrequenzkurve stilisiert werden kann.

3.4. Akustik versus Perzeption der Kopiekontur 39
3.4 Akustik versus Perzeption der Kopiekontur
Laut Flanagan und Saslow (1958) sind Hörer in der Lage, Grundfrequenzunterschiede zwischen künstlichen Vokalen bis zu 0.3% wahrzunehmen. In Halbtönen ausgedrückt beträgt dieser Unterschied 0.05 HT. Lehiste (1970) nennt eine Genauigkeit von 1 Hz. Bei 100 Hz entspricht dies einem Unterschied von 0.17 HT und bei 200 Hz 0.09 HT.
Im Fall einer Kopiekontur dagegen verhält sich die menschliche auditive Wahrnehmung anders. Obwohl die Unterschiede zwischen der Stilisierung und dem gemesseoen Grundfrequenzverlauf häufig bedeutend über den hier oben genannten Schwellenwerten liegen, können Hörer diese Unterschiede nicht wahrnehmen.
Wie läBt sich diese auffällige Diskrepanz erklären? lm oben genannten Experiment verwendeten Flanagan und Saslow künstliche Vokale mit einer konstanten Grundfrequenz als Stimuli. In natürlich gesproeheoer Sprache dagegen ändern sich die Grundfrequenzwerte fortwährend. Nebmen wir nun einmal an, daB die Mengeder Tonhöheninformationen den Hörer überfordert und ihn zu einer Datenreduktion zwingt. Dann bedeutet dies, daB der Hörer nur die globalen Aspekte der Tonhöhe, die "Gestalt" des natürlichen Verlaufs hebalten kann. Bestimmte Unterschiede zwischen einer kontinuierlich variablen Grundfrequenzkurve und einer Kopiekontur können dann nicht entdeckt werden.
Ferner spielt heim Vergleichen einer Grundfrequenzkurve mit einer Kopiekontur möglicherweise das Kurzzeitgedächtnis eine Rolle. Denn der Hörer muB der Eindruck der ersten Version hebalten bis zum Ende der zweiten Version und anschlieBend beide miteinander vergleichen.
Für die Beurteilung, ob eine Grundfrequenzkurve und eine entsprechende Kopiekontur tatsächlich perzeptiv gleich sind, vergleiebt der Hörer beide Versionen jedoch nicht nur global. Wie wir heim Stilisieren feststellen konnten, sind lokal die Gipfelwerte und die Endfrequenz kritisch. Hier genügen bereits sehr kleine Unterschiede, urn festzustellen, daB die beiden intonativen Versionen voneinander abweichen. Offensichtlich kann der Hörer diese Grundfrequenzwerte wiederurn sehr genau bestimmen und etwaige Unterschiede in seinem Urteil berücksichtigen.
Wie aus Abbildung 3.3 hervorgeht, sind an manchen Stellen der Kopiekontur gröBere Abweichungen vom Originalverlauf erlaubt, während die

40 3. Grundfrequenzkurven und Kopiekonturen
Stilisierung anderswo dem Original genau folgen muB. Die Gründe dafür werden deutlich, wenn wir im Vergleich der Kopiekontur mit der Originalkurve den Verlauf der Amplitude berücksichtigen (siehe Abbildung 3.4).
> :::> eoo 400
300
'N 200 E
0 IJ.. --r~~
100 1 2
eo
I
0 . 0 0.3 0.6 0.9 1.2 1.5
t (sl
Abbildung 3.4: Drei Parameter der Äufterung: "Gib mir bitte die Butter". Waagerecht ist die Zeit in Sekunden (s) dargestellt. Senkrecht ist zunächst die Grundfrequenz {Fo) in Hertz {Hz} wiedergegebenfür d'ie Originalkurve (gepunktete Linie) und für eine Kopiekontur (durchgezogene Linie). Die stimmlosen Anteile des Signals werden in der Zeile UV abgebildet, darüber ist der Verlauf der relativen Amplitude {G) des Sprachsignals wiedergegeben. Die Bereiche, in denendie relative Amplitude niedrig ist und wo der Verlauf der Kopiekontur stark von der Originalkurve abweicht, sind durch Pfeile {1-2} markiert.
Abbildung 3.4 zeigt, daB gröBere Abweichungen vom Verlauf der Grundfrequenz nur dann auftreten, wenn die Amplitude im Verhältnis zur Umgebung gering ist. Diese Bereiche sind in Abbildung 3.4 durch zwei

3.4. Akustik versus Perzeption der Kopiekontur 41
Pfeile gekennzeichnet. Die Abweichungen betragen im einzelnen 2.1 Halbtöne (1) und 2.4 Halbtöne (2). Eine lokal niedrige Amplitude kann also recht erhebliche Frequenzunterschiede kaschieren. Dadurch können wir in einer Stilisierung mit weniger geraden Linien auskommen, als auf Grund einer visuellen Analyse des natürlichen Grundfrequenzverlauf zu erwarten wäre. Es zeigt sich also, daB die Art und Weise, wie ein Grundfrequenzverlauf stilisiert werden kann, eng mit dem Amplitudenverlauf zusammenhängt.
Im vorigen Abschnitt haben wir bereits darauf hingewiesen, da.6 eine Kopiekontur durch perzeptive Toleranzen akustisch unterschiedlich spezifiziert sein kann. Wie wir hier oben bereits gesehen haben, liegt ein möglicher Grund für diese Tolera.nzen in der variableu Amplitude im Verlauf einer Äu6erung. In Bereichen mit niedriger Amplitude, in denen das Signa! schlechter hörbar ist, maskiert wird, nimmt die Freiheit der akustischen Spezifizierung zu. Betrachten wir dazu Abbildung 3.5 (dieselbe Äu6erung wie in Abbildung 3.4). Wegen der niedrigen Amplitude (angegeben durch einen Pfeil) kann die Steigung (A-B) der Kopiekontur weniger steil verlaufen als die entsprechende Steigung aus Abbildung 3.4. Zwischen beiden Versionen ist kein Unterschied hörbar.
Die Bedeutung der Amplitude für die Tonhöhenwahrnehmung erfordert noch eine genauere psycho-akustische Untersuchung. Innerhalb der varliegenden Arbeit können wir auf diese Frage jedoch nicht weiter eingehen.
Neben einem möglichen Einflu6 der Amplitude sind andere Gründe für die perzeptiven Toleranzen beka.nnt. So können Versuchspersonen in SprachäuBerungen Unterschiede im Frequenzumfang einer Grundfrequenzänderung erst ab 1.5 bis 2 Halbtöne unterscheiden ('t Hart, 1981).
Auch was die Geschwindigkeit einer Grundfrequenzänderung (das Verhältnis zwischen Frequenzumfang und Dauer) betrifft, sind Hörer nicht sehr empfiridlich. Auf Grund der Daten von Pollack (1968) bereehnet 't Hart (1976) das Verhältnis zwischen zwei gerade wahrnehmbaren Geschwindigkeiten. 't Hart findet Werte zwischen 1.4 für schnelle (64 HT / s), grö6ere ( 400 ms) Grundfrequenzänderungen und 6 für Iangsame (1 HT/s), kleinere (50 ros) Grundfrequenzä.nderungen.
Auch Bouma (1979) stützt sich auf Pollacks Ergebnisse. Für Grundfrequenzänderungen, deren Dauer 200 ms überschreitet kommt Bouma.

42 3. Grundfrequenzkurven und Kopiekonturen
> :::> eoo
•oo 300
.... 200 ~
0 u..
100
60~----~------~--------------------------~--~----~ 0.0 0 . 3 0 . 6 0.9 1.2 1.5
t (s)
Abbildung 3.5: Drei Parameter der Äujlerung: "Gib mir bitte die Butter". Waagerecht ist die Zeit in Sekunden (s} dargestellt. Senkrecht ist zunächst die Grundfrequenz (Fo) in Hertz (Hz} wiedergegebenfür die Originalkurve (gepunktete Linie} und für eine Kopiekontur (durchgezogene Linie). Die stimmlosen Anteile des Signals werden in der Zeile UV abgebildet, darüber ist der Verlauf der relativen Amplitude ( G} des Sprachsignals wiedergegeben. Die Steigung (A-B} der Kopiekontur kann weniger steil verlaufen als die entspreekende Steigung aus Abbildung 9.4, weil die Amplitude im Bereich des Anfangs der Steigung (angegeben durch einen Pfeil} niedrig ist.
zu folgender Feststellung: Unterschiede in der Geschwindigkeit zweier Grundfrequenzänderungen sind gerade hörbar, wenn der Quotient beider Geschwindigkeiten 2 beträgt. Bei kürzeren Dauerwerten steigt dieser Faktor auf mindestens 10.
Aus diesenDaten geht hervor, daB die Wendepunkte einer Kopiekontur sowohl im Frequenz- als Zeitbereich sehr unterschiedlich spezifiziert sein

3.5. Die perzeptive Evaluierung 43
können, ohne daB diese Unterschiede hörbar sind. Aus diesem Grund ist es nicht möglich, und auch nicht notwendig die akustischen Merkmale einer Kopiekontur (wie Anfangs- und Endpunkte oder Dauer einer Grundfrequenzä.nderung) strenger festzulegen.
3.5 Die perzeptive Evaluierung
3.5.1 Zielsetzung
Ziel dieses Experimentsist es, nachzuprüfen, ob ein natürlicher Grundfrequenzverlauf und eine entsprechende Kopiekontur tatsä.chlich perzeptiv gleich sind. Die Ergebnisse sind in zweifacher Weise von Bedeutung. Erstens lä.Bt sich auf diese Weise feststellen, ob Konturen, die durch gerade Linien reprä.sentiert werden, prinzipiell dazu geeignet sind, einen natürlichen Höreindruck hervorzurufen, auch im Hinblick auf das spä.tere melodische Modell. Zweitens stellt das Kriterium der perzeptiven Gleiehheit ein MaB für die Qualitä.t der Kopiekonturen dar. Es zeigt, ob die perzeptiv relevanten Farmmerkmale natürlicher Intonation richtig wiedergegeben wurden. Die Vergleichsmöglichkeit zum Original ist wichtig, weil wir aus den Werten für Frequenzumfang, Dauer und Position der Grundfrequenzä.nderungen in Kopiekonturen Hypothesen für die standardisierte Spezifizierung im melodischen Modell ableiten.
Bei der Erstellung einer Kopiekontur entscheidet zunä.chst der Experimentator, ob eine Stilisierung tatsä.chlich als Kopiekontur gelten kann, ob die Kopiekontur und das Original perzeptiv gleich sind. Urn zu einer objektiven Klärung dieser Frage zu kommen, legen wir im folgenden Experiment deutschen Muttersprachlern natürliche Grundfrequenzverläufe und Kopiekonturen zum Vergleich vor.
3.5.2 Methode
3.5.2.1 Stimuli
Das Ausgangsmaterial bildeten 100 Sätze, die von einem Rundfunksprecher vargelesen wurden. Es handelt sich urn die "Sotschek-Sätze", die ursprünglich als Instrument zur Sprachgütemessung im Forschungsinstitut der Deutschen Bundespost in Berlin entwiekelt wurden (Sotschek, 1984).

44 3. Grundfrequenzkurven und Kopiekonturen
Dieses Material schien mir aus zwei Gründen für den Test geeignet zu sem.
Erstens besteht der Sotschek-Korpus aus kurzen Sätzen, die als vorgelesene ÄuBerung eine Dauer von 2 Sekunden nicht überschreiten. Dieser Aspekt ist wichtig, da.mit im direkten Vergleich zwischen Original und Kopiekontur das Kurzzeitgedächtnis des Hörers nicht überfordert wird.
Zweitens lag das Material in einer guten Aufnahmequalität vor. Dies ist vor allem im Hinblick auf die Analyse und spätere Resynthese der ÄuBerungen von Bedeutung. .
Von den 100 Sätzen wurden Kopiekonturen angefertigt. Für den Test ha.ben wir zehn ÄuBerungen ausgewählt (Tabelle 3.3) . Die zehn Konturen entsprechen in etwa. der beobachteten melodischen Va.riabilität.
Die Grundfrequenzkurven und die Kopiekonturen des Testma.terials sind in Anhang A da.rgestellt.
3.5.2.2 Versuchspersonen
An diesem Experiment na.hmen 19 Versuchspersonen (Studenten und Mitarbeiter des lnstituts für Kommunikationsforschung und Phonetik (IKP) der Friedrich-Wilhelms-Universität Bonn) teil. Die Versuchspersonen wurden für ihre Mita.rbeit beza.hlt.
3.5.2.3 Testverfahren
Jede der zehn ÄuBerungen lag in zwei Versionen vor: als (resynthetisiertes) Original (OR) und a.ls Kopiekontur (KK). Für jede ÄuBerung wurden jeweils vier Paare erstellt:
1. OR-OR
2. KK-KK
3. OR- KK
4. KK-OR
Die eine Hälfte der Paare (1 und 2) enthielt physika.lisch identische ÄuBerungen, die andere Hälfte (3 und 4) bestand aus physikalisch verscbiedenen ÄuBerungen.

3.5. Die perzeptive Eva/uierung 45
Für zehn ÄuBerungen haben sich aus diesen Kombinationen 40 Paare ergeben, die die Teststimuli bildeten.
Tabelle 3.3: Zehn ausgewählte Testsätze, ihre Dauer in Sekunden (s) und die Anzahl der Segmente (gerade Linien), aus denen sich die Konturen zusammensetzen.
Satz Dauer (s) Anzahl Segm.
1 Wer trinkt einen Kaffee? 1.1 3 2 Gib mir hitte die Butter. 1.1 5 3 Hier gibt es Konserven. 1.2 4 4 Vater hat den Tisch gedeckt. 1.2 6 5 Hans iBt so gerne Wurst. 1.5 3 6 He u te ist schönes Frühlingswetter. 1.6 5 7 Mu6 der Zucker nicht dort drüben stehen? 1.7 7 8 Vater wil! sich eine Pfeife anzünden. 1.9 5 9 Messer und Gabelliegen neben dem Teller. 1.9 6 10 Der gelbe Küchenofen sorgt für Wärme. 2.0 12
Diese 40 Paare wurden in randomîsierter Reihenfolge jeweils ein Mal dargeboten. Die Aufgabe der Versuchspersonen bestand darin, die beiden ÄuBerungen eines Paares sehr genau miteinander zu vergleichen und in einem Testantwortbogen anzukreuzen, ob sie die Äu6erungen als gleich oder versebieden hörten.
Das Testband wurde den Versuchspersonen in einem Hörsaal des IKP über Lautsprecher auf normaler Lautstärke vorgespielt.
Damit sich die Versuchspersonen mit ihrer Aufgabe vertraut machen konnten, ging dem Test eine Einführung auf Band voran. Gleichzeitig koonten die. Versuchspersonen sich an die resynthetisierte Sprache gewöhnen. Die Qualität dieser Sprache ist zwar schlechter als natürliche Sprache aber dennoch gut verständlich.
Nach der Einführung koonten noch eventuelle Fragen gestellt werden. Dann folgte der Test. (Für den Text der Einführung siehe Anhang A) .
Das Experiment, wie wir es hier oben hesebrieben haben, stellt hohe Anforderungen an die Konzentrat ion der Versuchspersonen. Denn nur in

46 3. Grundfrequenzkurven und Kopiekonturen
50% der Fälle werden ÄuBerungen dargeboten, zwischen denen vielleiebt ein geringfügiger Unterschied hörbar ist. Deshalb läge es auf der Hand, im Text auBerdem Paare anzubieten, deren ÄuBerungen sich in intonativer Hinsicht deutlich voneinander unterscheiden, wie in de Pijper (1983).
Der Nachteil eines sokhen Testaufbaus ist jedoch, daB Versochspersonen angesichts der deutlichen intonativen Unterschiede dazu neigen könnten, wesentlich kleinere Abwèichungen zu unterschlagen. Daruit bliebe die Frage unbeantwortet, ob etwaige Unterschiede zwischen Original und Kopiekontor hörbar sind. In unserem Experiment versuchen wir gerade Versochspersonen für sehr kleine Unterschiede in der Intonation zo sensibilisieren. Aus diesem Grund haben wir auf Kombinationen von ÄoBerungen verzichtet, zwischen denen die Unterschiede deutlich hörbar sind.
3.ó.3 Ergebnisse
Aos diesem Experiment ergaben sich insgesamt 760 Urteile (19 Versochspersonen x 40 Stimuli). Iri Tabelle 3.4 sind die Urteile "gleich" ond "verschieden" nach identischen und verschierlenen Stimulospaaren aufgeteilt.
Tabelle 3.4: Die Urteile "gleich" und "verschieden" nach identischen und verschiedenen Stimuluspaaren aufgeteilt.
URTEILE
glei eh versebieden
identisch 295 85 380 STIMULUS-PAARE
verschieden 274 106 380
569 191 760

3.5. Die perzeptive Eva/uierung 47
In der Analyse der Daten beschränken wir uns auf die Urteile "gleich", da die Urteile "verschieden" keine neue Information enthalten.
Aus Tabelle 3.4 wird ersichtlich, daB 569 Urteile (74.9%) "gleich" lauten. Davon entfallen 295 Urteile auf gleiche Stimuli und 274 auf verschiedene. In Tabelle 3.5 sind die Urteile "gleich" pro Versuchsperson für identische und versebiedene Stimuluspaare wiedergegeben.
Ta belle 3.5: Die Urteile "gleich" pro Versuchsperson für identische und verschiedene Stimuluspaare.
Versuchs- identische verschiedene personen Pa are Paare
1 10 12 2 13 14 3 13 9 4 12 10 5 12 11 6 19 16 7 20 14 8 17 13 9 19 17 10 18 15 11 15 13 12 18 18 13 15 15 14 13 9 15 16 15 16 15 19 17 20 20 18 19 19 19 11 15
Summe 295 274
Ein Wilcoxon-Test zeigt, daB die Anzahl der Urteile "gleich" in beiden Konditionen nicht signifikant voneinander abweichen (T15=31.5, p (einseitig)>.05). Wir können also annehmen, daB die Versuchspersonen

48 3. Grundfrequenzkurven und Kopiekonturen
keine U nterschiede zwischen identischen und versebiedenen Paaren gehört ha ben.
Betrachten wir jetzt die Ergebnisse pro Satz in Tabelle 3.6.
Ta belle 3.6: Die Urteile "gleich" für identische und verschiedene Paare je Satz, der entspreekende Wilcoxon T- Wert und die Wahrscheinlichkeit p {einseitig).
Satz identische Paare versebiedene Paare T p ( einseitig} 1 25 20 12 p = .1075 2 33 31 13.5 p = .2643 3 29 27 14.5 p = .3121 4 32 27 3 p = .0582 5 26 31 10 p = .0694 6 34 30 7 p = .1190 7 33 25 0 p = .0059 8 28 32 22 p = .1635 9 26 27 20.5 p = .4052 10 29 24 37 p = .1660
Bei einem Signifikanzniveau von Q = .05 geht aus Tabelle 3.6 hervor, daB die Verteilung der Urteile "gleich" über identische und versebiedene Paare für die Sätze 1 bis 6 und 8 bis 10 zufällig ist. In diesen Fällen ist der Schlu.B gerechtfertigt, daB die Versuchspersonen keine Unterschiede zwischen identischen und versebiedenen Paaren gehört haben.
Im Falle von Satz 7 bleibt die Wahrscheinlichkeit p weit unter dem angesetzten Signifikanzniveau. Deshalb muB hier die SchluBfolgerung lauten, daB ein Unterschied zwischen identischen und versebiedenen Paaren hörbar war. Die Stilisierung kann also nicht als Kopiekontur geiten.
3.6.4 Diskussion und SchluJlfolgerungen
In diesem Experiment haben wir untersucht , ob Versuchspersonen Unterschiede zwischen natürlichen Grundfrequenzverläufen und Kopiekonturen wahrnehmen.

3.5. Die perzeptive Evaluierung 49
Eine Analyse des Gesamtergebnisse~ (Tabelle 3.5) zeigt zunächst, daS die Versuchspersonen keine Unterschiede zwischen identischen und verscbiedenen Paaren hören. Ein Vergleich der Beurteilung der einzelnen Sätze ergibt ein differenzierteres Bild (Tabelle 3.6). Es zeigt sich, daB nur für neun von zehn Sätzen (1 bis 6 und 8 bis 10} die Stilisierung tatsächlich als Kopiekontur gelten kann. In diesen Fällen hören die Versuchspersonen keine Unterschiede, die Abweichungen der Kopiekontur vom Original liegen innerhalb des perzeptiven Toleranzbereichs.
Die Kopiekontur von Satz 7 ( "MuB der Zucker nicht dort drüben stehen?") weist jedoch eine hörbare Abweichung vom Original auf, wie das Experiment zeigt. In diesem Fall ist die Kopiekontur als perzeptiv gleiche Stilisierung eines natürlichen Grundfrequenzverlaufs miBlungen. Bei einem nachträglichen auditiven Vergleich beider Versionen ist bei genauem Zuhören tatsächlich in der ersten Silbe des Wortes "Zucker" ein Unterschied hörbar. Dieser Unterschied ist auch sichtbar, wenn wir in Abbildung 3.6 die Grundfrequenzkurve (gepunktete Linie} mit der Kopiekontur (durchgezogene Linie} in diesem Bereich vergleichen.
Entscheidend istjedoch, daB am Anfang des Vokals Ju/ in "Zucker" die Amplitude hoch ist. Das heiBt, daB diese Unterschiede zwischen Original und Kopiekontur auch wahrnehmbar sind.
In Abbildung 3.6 ist der Vokaleinsatz (Frame 42} durch eine senkrechte Linie markiert. In Tabelle 3.7 sind für die Frames 42 bis 47 pro Frame die Grundfrequenzwerte für Original und Kopiekontur sowie der Unterschied in Halbtönen wiedergeben. Ein Frame dauert 10 ms.
Es ist anzunehmen, daB die Versuchspersonen durch die hohe Amplitude diese Unterschiede vor allem in den ersten drei Frames hören konnten. Deshalb kann diese Stilisierung nicht als Kopiekontur geiten.
Eine hörbare melodische Abweichung verteilt sich also nicht gleichmässig über alle Sätze, sondern beschränkt sich nur auf einen Satz. Dies zeigt, wie streng die Versuchspersonen geurteilt haben und miSt der Tatsache, daB sie in den Sätzen 1 bis 6 und 8 bis 10 keine Abweichung feststellen konnten, eine noch gröBere Bedeutung bei.
·Auf Grund dieser Ergebnisse ist der SchluB gerechtfertigt, daB Versucbspersonen keine Unterschiede zwischen natürlichen Grundfrequenzverläufen und Kopiekonturen hören können. Dieses Experiment zeigt, daB Hörer bei der Wahrnehmung natürlicher Intonation nicht alle akus-

50 3. Grundfrequenzkurven und Kopiekonturen
tisch meBbaren Grundfrequenzänderungen berücksichtigen, sondern erhebliche Vereinfachungen vornehmen. Diese Vereinfachungen entsprechen der akustischen Spezifizierung einer Kopiekontur.
Da eine Kopiekontur perzeptiv nicht von einem wesentlich kompiexeren natürlichen Grundfrequenzverlauf zu unterscheiden ist, gibt die Stilisierung die für die Wahrnehmung relevanten Tonhöhenbewegungen des Originals korrekt wieder. Dies ist von Bedeutung, weil die Formmerkmale der Kopiekonturen die Grundlage der Hypothesen des melodischen Modells im vierten Kapitel bilden.

3.5. Die perzeptive Evaluierung 51
> ::::>
600r-~~----~~----------------~----------------~~
•oo 300
N 2oo ~
0 "-
tOO ~ ··~· . ~ ~
Zucker 80~--~----~~~--~--------~~~----~--~--~--~
0.0 0.4 0.8 1.2 1.6 2.0
t (s}
Abbildung 3.6: Die Grundfrequenzkurve (gepunktete Linie) und die Kopiekontur (durchgezogene Linie) der Äufterung: "Muft der Zucker nicht dort drüben stehen'?" Der Vokaleinsatz des /u/ in "Zucker" ist durch eine senkrechte Linie markiert.
Tabelle 3.7: Die Grundfrequenzwerte für Original und Kopiekontur (Frames 42 bis 41} der Äufterung aus Abbildung 9.6.
Frame F0 OR (Hz) Fo KK (Hz) Differenz (HT} 42 116 101 2.4 43 116 104 1.9 44 119 106 2.0 45 116 109 1.1 46 115 111 0.6 47 114 114 0

52 3. Grundfrequenzkurven und Kopiekonturen

4
Ein melodisches Modell
4.1 Grundlagen
In diesem Kapitel wird ein experimentell überprüfbares melodisches Modell für das Deutsche beschrieben. Dieses Modell umfaBt die wichtigsten Melodisierungen, die in vorgelesenem Text auftreten.
Die Basis des melodischen Modelis sind natürlich gesproebene ÄuBerungen . In einem ersten Schritt der Modellbildung werden von den gemesseoen Grundfrequenzkurven Kopiekonturen angefertigt. Im vorigen Kapitel wurde ausführlich besprochen, wie aus einer natürlichen Grundfrequenzkurve eine Kopiekontur ermittelt werden kann. Für eine Kopiekontur gelten zwei Kriterien:
l. Die Stilisierung und das Original sind perzeptiv gleich. Das heiBt, daB der Hörer keine Unterschiede zwischen beiden Versionen {eststellen kann.
2. Die perzeptiv gleiche Stilisierung bestebt aus einer kleinst möglichen Anzahl von Grundfrequenzänderungen, visuell wiedergegeben als gerade Linien im Zeit-/(log)Frequenzbereich.
Eine Kopiekontur repräsentiert ausschlieB!ich die perzeptiv relevanten Formmerkmale einer einzigen Grundfrequenzkurve. Daher läBt sich die Spezifizierung der Grundfrequenzänderungen dieser Stilisierung nicht ohne weiteres verallgemeinern. Denn miteinander vergleichbare Grundfrequenzänderungen - wie etwa Steigungen in akzentuierten Silben - sind häufig unterschiedlich spezifiziert, was ihre Position in der Silbe, ihren Frequenzumfang und ihre Dauer betrifft. Dies gilt sowohl innerhalb derselben Kopiekontur, als auch beim Vergleich mehrerer Kopiekonturen.
53

54 4. Ein melodisches Modell
In den Kopiekonturen haben wir es also mit okkurrenten Formmerkmalen zu tun. Eine Beschreibung der intonativen Struktur des Deutschen ist aber an den rekurrenten Formmerkmalen, den Regularitäten interessiert. Deshalb vergleichen wir eine Vielzahl von Kopiekonturen miteinander, urn auf diese Weise die Gemeinsamkeiten der Kopiekonturen zu extrahieren. Durch Kategorisierung und Standardisierung sind Generalisierungen möglich, die zu einem beschränkten lnventar prototypischer Grundfrequenzänderungen führen. Im folgenden gehen wir auf die Kategorisierung und Standardisierung näher ein.
4.2 Kategorisierung und Standardisierung
Die Entwicklung des melodischen Modelis beginnt mit dem Vergleich einer Vielzahl von Kopiekonturen. Aus diesem Vergleich lassen sich Rekurrenzen ableiten, die die Grundlage für die Hypothesen des melodischen Modelis bilden. Dazu werden die Kopiekonturen zunächst in ihre konstituierenden Steigungen und Senkungen zerlegt. Auf diese Weise entsteht ein umfangreiches lnventar perzeptiv relevanter Grundfrequenzänderungen, visuell repräsentiert durch gerade Linien.
Die Aufgabe besteht darin, diese Grundfrequenzänderungen zu kategorisieren und für jede Kategorie durch Standardisierung eine prototypische Grundfrequenzänderung zu ermitteln. Durch die Kategorisierung und Standardisierung ergibt sich aus der Menge der tatsächlich beobachteten Grundfrequenzänderungen ein relativ kleines Inventar prototypischer Steigungen und Senkungen.
Im folgenden gehen wir von einer bereits standardisierten Kontur aus. Es sind zwei Arten von Grundfrequenzänderungen zu unterscheiden. Betrachten wir dazu die Standardkontur in Abbildung 4.1 ("Am ZAUN steht eine REgentonne"), die sich aus fünf diskreten Grundfrequenzänderungen zusammensetzt:
1. Relativ schnelle Grundfrequenzänderungen: Steigung (2-3) und Senkung ( 4-5) sind mit Standardwerten für die Position in der Silbe , den Frequenzumfang und die Dauer versehen. Sie haben lokalen Charakter. Über die Stelle, an der eine solche Grundfrequenzänderung in der ÄuBerung auftritt, entscheidet der Sprecher.
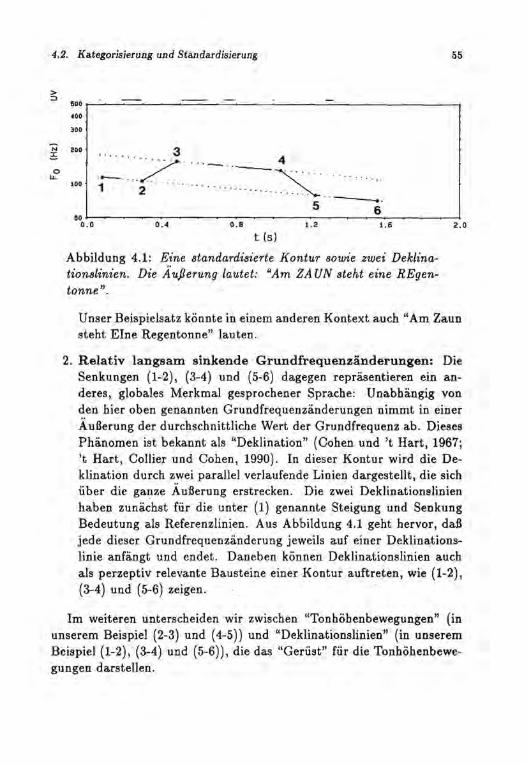
4.2. Kategorisierung und Standardisierung 55
> :::>
'N ~
0 lL
500
•oo 300
200
100
-·~ .... z·- .. ~---- 4 ·· ·· ... ... . . 1 ····2··· . ... . . ...... .. ...... ~ . .. .
······5··----.. 6
50~--------------------------------------~~---------4 0 . 0 0.4 0.8 1.2 1.6
t (s)
Abbildung 4.1: Eine standardisierte Kontur sowie zwei Deklinationslinien. Die Äuflerung lautet: "Am ZA UN steht eine REgentonne".
2.0
Unser Beispielsatz könnte in einem anderen Kontext auch "Am Zaun steht Elne Regentonne" lauten.
2. Relativ langsam sinkende Grundfrequenzänderungen: Die Senkungen (1-2), (3-4) und (5-6) dagegen repräsentieren ein anderes, globales Merkmal gesprochener Sprache: Una.bhängig von den hier oben genannten Grundfrequenzänderungen nimmt in einer ÄuBerung der durchschnittliche Wert der Grundfrequenz ab. Dieses Phänomen ist bekannt als "Deklination" (Cohen und 't Hart , 1967; 't Hart , Collier und Cohen, 1990) . In dieser Kontur wird die Deklination durch zwei parallel verlaufende Linien dargestellt, die sich über die ganze ÄuBerung erstrecken. Die zwei Deklinationslinien ha ben zunächst für die unter (1) genannte Steigung und Senkung Bedeutung als Referenzlinien. Aus Abbildung 4.1 geht hervor, daB jede dieser Grundfrequenzänderung jeweils auf einer Deklinationslinie anfängt und endet. Daneben können Deklinationslinien auch als perzeptiv relevante Bausteine einer Kontur auftreten, wie (1-2), (3-4) und (5-6) zeigen.
Im weiteren unterscheiden wir zwischen "Tonhöhenbewegungen" (in unserem Beispiel (2-3) und (4-5)) und "Deklinationslinien" (in unserem Beispiel (1-2), (3-4) und (5-6)), die das "Gerüst" für die Tonhöhenbewegungen darstellen.

56 4. Ein me/odisches Model/
Ein wesentliches Problem bei der Erstellung eines melodischen Modells ist die Tatsache, daB es keine objektiven Kriterien für die Kategorisierung der Tonhöhenbewegungen gibt. Aus dem Vergleich der einzelrren Steigungen und Senkungen der Kopiekonturen wird zwar deutlich, in welchen Bereichen sich die Position in der Silbe, der Frequenzumfang und die Dauer bewegen, die Kategorisierung bleibt jedoch unsicher. Wie viele Positionen in der Silbe müssen wir für eine Tonhöhenbewegung unterscheiden ader wie viele Frequenzumfänge sind in einem melodischen Modell notwendig? U m auf diese Fragen eine Antwort zu bekommen, ist eine heuristische Arbeitsweise erforderlich. Es werden Hypothesen aufgestellt, informell überprüft und korrigiert. Am SchluB dieses iterativen Prozesses steht ein formales Perzeptionsexperiment, in dem die melodischen Hypothesen getestet werden. Dazu werden deutschen Muttersprachlern standardisierte Konturen zur Beurteilung vorgelegt.
An dieser Stelle sollte darauf hingewiesen werden, daB ein melodisches Modell, das auf diese Weise zustande kommt, nur eine Möglichkeit darstellt, die intonativen Farmmerkmale des Deutschen wiederzugeben. Denn wie wir gesehen haben, läBt sowohl die Erstellung von Kopiekonturen als auch der ProzeB der Kategorisierung und Standardisierung gewisse Freiheitsgrade zu. Eine andere lnterpretation der Daten könnte eine andere Spezifizierung und Kategorisierung der Tonhöhenbewegungen oder eine andere Einteilung der Deklinationslinien ergeben. Ausschlaggebend ist jedoch, daB das melodische Modell, wie es auch immer spezifiziert sein möge, perzeptiv adäquat ist. Denn in der perzeptiven Überprüfung entscheidet sich, ob die melodischen Hypothesen korrekt sind.
4.3 Das melodische Modell
In diesem Abschnitt wird ein Modell deutscher Intonation für vorgelesenen Text vorgestellt. Methodisch odentiert sich dieses Modell an den am IPO ersteilten melodischen Beschreibungen des Niederländischen (Cohen und 't Hart, 1967; Collier und 't Hart, 1971; Collier, 1972; 't Hart und Cohen, 1973; 't Hart und Collier, 1975) sowie des britischen Englisch (de Pijper, 1983; Willems, Collierund 't Hart, 1988).
Das melodische Modell, das wir im weiteren beschreiben, bestebt aus Eauelementen und Regeln. Aus diesen Eauelementen und Regeln können

4.3. Das melodische Modell 57
Konturen gebildet werden. Die Bauelemente bespreehen wir in Abschnitt 4.3.1. In Abschnitt 4.3.2 gehen wir auf die Kombinationsregeln ein.
Eine Kontur, die nach den Vorgaben des Modelis hergestellt wird, nennen wir eine "Standardkontur".
Ein wesentliches Merkmal des IPO-Ansatzes ist, daS die melodischen Hypothesen überprüft werden. Betrachten wir dazu in Abbildung 4.2 zunächst eine Kopiekontur (gepunktete Linie) und eine entsprechende Standardkontur (durchgezogene Linie).
> ::::>
500
400
300
"N 200 3
0 ~ u. 100 •..
A
===~.----Bs• 50
0.0 0 . 4 0 . 8 1.2 1.6 2.0
t (s)
Abbildung 4.2: Die Kopiekontur (gepunktete Linie) und die Standardkontur (durchgezogene Linie) der Auflerung: "Am ZAUN steht eine REgentonne".
Aus dem visuellen Vergleich der beiden Konturen wird ersichtlich, daB die Standardkontur andere akustische Eigenschaften als die Kopiekontur aufweist. Die Unterschiede betreffen sowohl die Tonhöhenbewegungen als auch die Deklination. So erfolgt beispielsweise die Senkung (A-B) in der Standardkontur früher, sie fängt höher an und verläuft steiler als die Senkung (A'-B') in der Kopiekontur. Der wesentliche Unterschied zwischen beiden Konturen liegt in diesem Fall aber in der Deklination. Bei einer gleichen Endfrequenz fängt die Standardkontur höher an und verläuft somit steiler als die Kopiekontur.
Wie wir im vorigen Kapitel gesehen haben, sind Kopiekontur und Original perzeptiv gleich. Eine Standardkontur ist aber akustisch und oft hörbar anders spezifiziert als eine Kopiekontur. Der Hörer kann aber beurteilen, ob die Standardkontur als Nachbildung eines natürlichen

58 4. Ein melodisches Modell
Tonhöhenverlaufs gelungen ist. Dazu muB eine Standardkontur zwei Kriterien genügen:
1. Zunä.Chst muB eine Standardkontur "perzeptiv akzeptabel" sein. Das heiBt, daB sie sich in der Bewertung der Akzeptabilität nicht signifikant von natürlicher lntonation unterscheidet.
2. AuBerdem muB eine Standardkontur "perzeptiv äquivalent" zum Original sein. Dieses Kriterium bedeutet, daB die künstliche Satzmelodie dem Original ähnlich ist. Dennes ist denkbar, eine Kontur zu generieren, die zwar perzeptiv akzeptabel ist, die sich aber vom melodischen Eindruck des Originals unterscheidet.
In der varliegenden Arbeit wird nur die perzeptive Akzeptabilität der Konturen untersucht (siehe Abschnitt 4.4). Die melodische Äquivalenz von Standardkontur und Originalintonation konnte aus zeitlichen Gründen experimenten nicht nachgeprüft werden.
Das Sprachmaterial, das die Grundlage des melodischen Modelis bildete, umfaBt ungefähr 400 ÄuBerungen, die sich über 20 Sprecher verteilen. Die ÄuBerungen wurden danach ausgesucht, daB möglichst viele melodische Möglicbkeiten im Korpus vertreten sind. Die ÄuBerungen variieren in der Dauer zwischen einer halben Sekunde und zehn Sekunden. Es handelt sich entweder urn Studioaufnahmen, die teilweise speziell für die varliegende Untersuchung gemacht wurden, oder urn Mitschnitte deutscher Rundfunk- und Fernsehsender, wie Nachrichtensendungen, Wettervorhersagen, Kommentare usw. In allen Fällen betrifft es vorgelesene Texte.
4.3.1 Die Bauelemente einer Kontur
Konturen setzen sich aus diskreten , perzeptiv relevanten Bauelementen zusammen. Die Bauelemente werden visuell als gerade Linien dargestellt. Das Experiment, in dem Kopiekonturen mit natürlicher lntonation verglichen wird, hat gezeigt, daB dies perzeptiv zulässig ist.
Wie wir gesehen haben, lassen sich zwei Arten von Bauelementen unterscheiden:
1. Ein Inventar der für den Hörer bedeutsamen Tonhöhenbewegungen. Diese diskreten Tonhöhenbewegungen sind mit Standardwerten für die Position, den Frequenzumfang und die Dauer versehen.

4.3. Das melodische Modell 59
2. Ein lnventar standardisierter Deklinationslinien. Für jede Deklinationslinie ist eine feste Anfangs- und Endfrequenz festgelegt.
lm folgenden bespreehen wir zunächst die standardisierten Deklinationslinien.
4.3.1.1 Standardisierte Deklinationslinien
Abbildung 4.3 zeigt eine Grundfrequenzkurve (Punkte) und eine entsprechende Kopiekontur ( durchgezogene Linie).
Aus der Kopiekontur geht hervor, daB die Deklination auf perzeptiv adäquate Weise durch eine gerade Linie (A-E) wiedergegeben werden kano. Diese Linie wird in der Kontur durch zwei Tonhöhenbewegungen (B-C) und (C-D) unterbrochen. Im Abschnitt (B-D) ist die Deklination in der Kontur nicht mehr erkennbar, wei! sie hiervonden Tonhöhenbewegungen überlagert wird.
> ::;)
soo •oo 300 Ge st ern ST ÜRMte es no eh
-;:; 200 .= c 0
lL 100
so
~----~---~ ~ B --- • . ·0 --~
E 0,0 0.3 0.8 0.9 1.2 t.S
t (s)
Abbildung 4.3: Die Grundfrequenzkurve (Punkte) und eine entsprechende Kopiekontur {durchgezogene Linie) der ÄuPerung: "Gestern STÜRMte es noch". Die gerade Linie (A-E) stellt die Deklination dar.
Der Verlauf der Deklination entspricht also einer Linie, die sich über die ganze ÄuBerung erstreckt. Sie entsteht durch lineare Interpolation zwischen einer Anfangs- und einer Endfrequenz in einer Äuflerung.
Die Frage ist jetzt, welche Standardwerte für einen perzeptiv adä.quaten Verlaufder Deklination als verbindlich anzusehen sind.

60 4. Ein melodisches Modell
't Hart et al. (1982) berechnen für das Niederländische den Anfangswert ausgehend von einer festgelegten Endfrequenz an Hand folgender Formeln:
(1) für t<5 s: D = -11/(t+1.5); (2) für t~5 s: D = -8.5/t,
wo bei D die Deklinationsgeschwindigkeit in HT /s darstellt und t die Dauer einer ÄuBerung in Sekunden wiedergibt.
In diesen Formeln kommt zum Ausdruck, daB D bei zunehmender Dauer kleiner wird. Der Verlauf der Deklination wird also zunehmend fl.acher. Für ÄuBerungen, deren Dauer 5 Sekunden oder weniger beträgt, wird diese Tendenz durch eine höhere Anfangsfrequenz teilweise kompensiert. Überschreitet die Dauer den Wert von 5 Sekunden, so bleibt die Anfangsfrequenz konstant.
Es hat sich gezeigt, daB mit diesen Formeln nicht nur der Verlauf der Deklination im Niederländischen vorhergesagt werden kann, sondern daB sich auf diese Weise auch die Deklination im Englischen perzeptiv adäquat berechnen läBt (de Pijper, 1983; Willems, 1983; Willems et al., 1988).
Für die deutschen ÄuBerungen, die wir im Rahmen dieser Arbeit untersucht haben, ist festzustellen, daB die Deklination recht gut bestimmt werden kann an Hand der zweiten Formel. Im deutschen Modell ist es nicht notwendig zwei Dauerkategorien zu unterscheiden.
Bei einer standardisierten Endfrequenz von 70Hz (für männliche Sprecher) ergibt sich aus Formel (2) eine feste Anfangsfrequenz von 114 Hz. Dabei ist es unerheblich, ob die ÄuBerung eine Sekunde oder zehn Sekunden dauert. Der einzige Unterschied bestebt darin, daB die Deklination bei zunehmender Dauer fl.acher wird.
In allen untersuchten ÄuBerungen stellt die Deklination ein perzeptiv relevantea Merkmal dar, Beispielen, in denen Deklination fehlt, sind wir nicht begegnet. Bei umfangreichen ÄuBerungen läBt sich auBerdem oft beobachten, daB die Deklination nach einer wichtigen syntaktischenGrenze erneut bei einer höheren Anfangsfrequenz einsetzt. Dieses Phänomen ist im allgemeinen unter dem Namen "Reset" bekannt. Hierauf kommen wir später noch zurück.

4.3. Das melodische Modell 61
Neben der hier oben hesproehenen Basisdeklination sind noch drei weitere, parallel verlaufende Deklinationslinien notwendig.
In Abbildung 4.4 sind die vier Deklinationslinien des Modelis mit einer Kontur dargestellt. Diese Linien stellen Referenzebenen für die Tonhöhenbewegungen dar. Jede Tonhöhenbewegung beginnt und endet jeweils auf einer Deklinationslinie. Dader Frequenzumfang der Tonhöhenbewegungen in Schritten von 2.5 HT quantisiert wurde, ist auch der Abstand zwischen den einzelnen Deklinationslinien in Schritten von 2.5 HT quantisiert. Der maximale Frequenzumfang umfa6t 12.5 HT.
Die einzelnen Deklinationslinien sind von 0 bis 5 numeriert, wobei die Ebenen 1 und 2 fehlen. Das bedeutet, daB es im Modell keine Tonhöhenbewegung gibt, die auf der Ebene 1 oder 2 anfängt oder endet.
SchlieBlich ist zu beachten, daB nicht in allen Konturen alle Deklinationslinien benutzt werden. Die Ebenen 0 und 3 sind die wichtigsten und werden am meisten verwendet.
70Hz
Abbildung 4.4: Die vier Deklinationslinien des Modelts mit einer Kontur.
Abbildung 4.4 zeigt ferner, daB Deklinationslinien nicht nur Referenzebenen sind. Wenn Tonhöhenbewegungen nicht unmittelbar aufeinander folgen, werden sie durch eine entsprechende Deklinationslinie miteinander verbunden. Eine Deklination(llinie kann also auch ein perzeptiv relevanter Baustein einer Kontur sein.
4.3.1.2 Standardisierte Tonhöhenbewegungen
Jede standardisierte Tonhöhenbewegungen (Steigung oder Senkung) wird durch drei Parameter spezifiziert: 1. die Position in der Silbe, 2. den

62 4. Ein melodisches Modell
Frequenzumfang (in Halbtönen (HT)) und 3. die Dauer (in Millisekunden (ms)).
In Abbildung 4.5 sind die einzelnen Tonhöhenbewegungen und die entsprechenden Parameterwerte dargestellt.
Zu diesem lnventar sind einige Erläuterungen notwendig.
Position Für die Position einer Tonhöhenbewegung scheinen zwei Referenzpunkte sinnvoll zu sein: entweder der Vokalanfang (VA) oder das Ende des stimmhaften Teils (EST) einer (unbetonten) Silbe. In den graphisch dargestellten Tonhöhenbewegungen werden diese Referenzpunkte durch "I" (VA) und "•" (EST) repräsentiert .
In bezug auf den Vokalanfang unterscheiden wir Steigungen in vier Positionen. Der Anfangspunkt der Tonhöhenbewegung kann bei -210 ms (1), -60 ms (2), -30 ms (3) und 0 ms (4) liegen.
Für Senkungen, die sicham Vokalanfang orientieren, nehmen wir auch vier Positionen an. Die Tonhöhenbewegung kann bei 0 ms (5), +60 ms (6), +120 ms (7) und +150 ms (8) anfangen.
Wie wir beobachten konnten, sind Steigungen mit Referenzpunkt EST immer so positioniert, daB sie ihren Gipfel am SchluB des stimmhaften Teilseiner Silbe erreichen (9, 10, lOa) . Abhängig vonder Dauer liegt der Anfangspunkt der Steigung bei -180 ms (9), -300 ms (10) und -120 ms (10a).
Steigung (9) kann innerhalb einer ÄuBerung eine prosodische Grenze markieren. Steigungen (10) und (10a) treten am Ende einer ÄuBerung auf.
Steigung (10a) betrachtenwirals eine Variante von Steigung (10), weil sich die beiden Tonhöhenbewegungen in ihrer Position nicht voneinander unterscheiden. Sie erreichen auch den Gipfel auf derselben Ebene. Der einzige Unterschied besteht im Abschnitt zwischen den Ebenen 0 und 3.
Am Referenzpunkt EST fä.ngt nur eine Senkung an (11). Sie setzt nach einer prosodischen Grenze (Steigung 9) die Kontur fort.
Frequenzumfang In diesem lnventar unterscheiden wir fünf standardisierte Frequenzumfänge, jeweils Vielfache von 2.5 HT: 2.5, 5, 7.5, 10 und 12.5 HT.
Es gibt je eine Tonhöhenbewegung mit einem Frequenzumfang von

4.3. Das melodische Modell 63
2.5 HT (3), 5 HT (10a), 10 HT (6) und 12.5 HT (10). Die übrigen Tonhöhenbewegungen weisen einen Frequenzumfang von 7.5 HT auf.
In der graphischen Darstellung (Abbildung 4.5) ist für jede Tonhöhenbewegung durch Zahlen angegeben, zwischen welchen Deklinationslinien sie sich befindet.
Dauer Der dritte Parameter, durch den eine Tonhöhenbewegung akustisch spezifiziert wird, ist die Dauer.
In den Kopiekonturen lassen sich abrupte Steigungen und Senkungen unterscheiden, die etwa eine Silbe umfassen, und Senkungen, die sich über mehrere Silben erstrecken. Die standardisierten abrupten Steigungen und Senkungen können durch einen festen Dauerwert spezifiziert werden. Für die standardisierten graduellen Senkungen (7 und 11 im Inventar) ist dies nicht möglich, wei! die Anzahl der Silben variabel ist. Der Endpunkt der graduellen Senkung wird durch den Anfang der nächsten Tonhöhenbewegung bestimmt.
Was die Tonhöhenbewegungen mit festen Dauerwerten betrifft, so ist die Dauer in Schritten von 60 ms quantisiert. Im Inventar kommen folgende Dauerwerte vor: 60, 120, 180, 240 und 300 ms.
Zu jeder Dauer gehört immer ein spezifischer Frequenzumfang. Eine Tonhöhenbewegung mit einem Frequenzumfang von 2.5 HT dauert 60 ms (Steigung 3 in Inventar), bei einem Frequenzumfang von 12.5 HT beträgt die entsprechende Dauer 300 ms (Steigung 10 im lnventar). In beiden Fällen ergibt sich eine konstante Geschwindigkeit (42 HT/s), die für alle Tonhöhenbewegungen im lnventar mit einer festen Dauer gilt.
Es ist zu berücksichtigen, daB sich die Geschwindigkeit der Tonhöhenbewegungen geringfügig ändert, wenn sie in einer Kontur auftreten. Da die Tonhöhenbewegungen auf eine Deklination gestellt werden, verläuft eine Steigung weniger steil, eine Senkung steiler als die Standa.rdgeschwindigkeit.

Abbildung 4.5: Inventar der standardisierten Tonhöhenbewegungen. Die Markierung " 11 " in der graphischen Darstellung der Senkungen {7} und {11} weist auf die variabie Dauer hin. Nähere Erläuterungen im Text.

4.3. Das melodische Modell 65
Hier oben haben wir zusammengefaBt, welche Standardwerte wir für die Position in der Silbe, den Frequenzumfang und die Dauer für eine perzeptiv adäquate Spezifizierung deutscher Tonhöhenbewegungen als verbindlich betrachten.
Die Kodierung der Tonhöhenbewegungen Neben einer Numerierung erscheint es sinnvoll, jede Tonhöhenbewegung mit einer Kodierung zu versehen, in der die wichtigsten Charakteristiken wiedergegeben sind. Diese Kodierung orientiert sich grö6tenteils an Willems, Collier und 't Hart (1988).
Eine Steigung wird durch "ST" repräsentiert, eine Senkung durch "SE". Wenn es sich urn eine Tonhöhenbewegung mit einem graduellen Verlaufhandelt, wie (7) oder (11), so wirdein "G" hinzugefügt (beispielsweise "GSE").
Vor diesen Buchstaben wird das Ausgangsniveau der Tonhöhenbewegung angegeben, dabinter wird das Zielniveau genannt. "OST3" bezeichnet beispielsweise eine Steigung zwischen den Ebenen 0 und 3, mit einem Frequenzumfang von 3 x 2.5 = 7.5 HT.
Der Kode OST3 reicht jedoch noch nicht aus, urn alle Tonhöhenbewegungen eindeutig zu spezifizieren. Denn OST3 kann sich auf die Steigungen (1), (2), (4) oder (9) beziehen. Diese drei Tonhöhenbewegungen unterscheiden sich jedoch hinsichtlich ihrer Position in der Silbe (VA und EST) voneinander. In der Kodierung wird die unterschiedliche Synchronisation folgenderma6en wiedergegeben.
Zunächst ist festzustellen, daB mit dem positionellen Unterschied teilweise ein funktioneller Unterschied einhergeht. So gibt es Tonhöhenbewegungen, die sich am Vokal akzentuierter Silben orie.ntieren und damit zur Hervorhebung beitragen. Diese Tonhöhenbewegungen (1 bis 6) und (8) werden durch "A" markiert.
Senkung (7) richtet sich zwar auch nach dem Vokalanfang, aber diese Tonhöhenbewegung erstreckt sich über roeherere Silben. Sie ist deshalb ungeeignet, eine Silbe hervorzuheben. Aus diesem Grund erhält (7) keine "A"-Markierung. Graduelle Senkungen verbinden lediglich Steigungen miteinander.
Neben diesen akzentuierenden Tonhöhenbewegungen gibt es Steigungen und Senkungen, die am Ende des stimmhaften Teils einer Silbe er-

66 4. Ein melodisches Modell
scheinen und so die ÄuBerung gliedern (9) oder ihren nicht-deklarativen Charakter ausdrücken (10 und 10a). Diese Tonhöhenbewegungen werden durch "*" markiert. ·
AuBer dieser funktionalen Unterscheidung ist für die Tonhöhenbewe- · gungen, deren Referenzpunkt der Vokalanfang ist, noch eine zusätzliche Spezifizierung notwendig. Denn beispielsweise "AOST3" kann sich sowohl auf (1), (2) als auf (4) beziehen.
Der Unterschied zwischen diesen Tonhöhenbewegungen liegt im Timing. In Tabelle 4.1 ist der Anfangspunkt jeder dieser drei Steigungen im Vergleich zum Vokalanfang sowie ihre Kodierung wiedergegeben.
Betrachten wir jetzt Steigung (2) als neutra!. Im Vergleich zur Positionierung von (2) fängt (1) früher an und wird deshalb mit dem Zeichen "-" versehen. Steigung (4) erfolgt im Vergleich zu (2) später und bekommt deshalb eine "+"-Markierung.
Ta.belle 4.1: Drei Steigungen aus dem lnventar standardisierter Tonhöhenbewegungen. Für jede Steigung ist der Anfangspunkt im Vergleich zum Vokalanfang {VA} sowie der entsprechende Kode angegeben.
Steigung (1) (2) (4)
Anfangspunkt VA-210 ms VA-60 ms VA
Kode -AOST3
AOST3 + AOST3
Bei den Senkungen (5) und (8) (A3SEO) ist auch eine Disambiguierung notwendig. Hier reiebt es, wenn wir (8) mit einem "+"-Zeichen versehen. Dies zeigt a.n, daB die Senkung (8) ausgehend von dem Vokalanfang später erfolgt als (5).
Das hier oben hesproebene Inventar standardisierter Tonhöhenbewegungen bildet zusammen mit den Deklinationslinien die perzeptiv relevanten Ba.usteine deutscher lntonation, wie sie sich aus dem hier untersuchten Korpus ergeben haben. Mit diesen Eauelementen können Konturen gebildet werden, die einen völlig natürlichen Höreindruck vermitteln. Dabei ist zu bemerken, daB es nicht erlaubt ist, die standardisierten Tonhöhenbewegungen auf willkürliche Weise miteinander zu verbinden.

4.3. Das melodische Modell 67
Es zeigt sich vielmehr, daB die Abfolge von Steigungen und Senkungen in einer Kontur Einschränkungen unterliegt.
4.3.2 Sequentielle Regeln
Die sequentieHen Regeln haben wir in fünf Teil-Diagrammen wiedergegeben. In jedem der fünf Teil-Diagramme werden jeweils die Regeln untergebracht, nach denen melodisch ähnliche Konturen erzeugt werden können. Melodisch ähnliche Konturen bilden zusammen einen "Intonationsblock". Über die "melodische Ähnlichkeit" von Konturen entscheiden die letzten Tonhöhenbewegungen einer Kontur.
Die fünf Intonationsblöcke können nicht nur paradigmatisch, sondern auch syntagmatisch motiviert werden. Diese Einteilung hat sichals praktikabel erwiesen bei der melodischen Beschreibung sowohl einfacher als umfangreicher ÄuBerungen. Komplexe Intonationsverläufe bestehen aus Kombinationen dieser fünf Intonationsblöcke (siehe 4.3.2.2). Im Colgenden gehen wir zunächst auf die einzelnen Blöcke ein.
4 .3.2.1 Die Intonationsblöcke
Die beobachteten Kombinationsmöglichkeiten stellen wir in Anlehnung an Willems et al. (1988) in Form von FluSdiagrammen dar, die verscbiedenen Konturtypen oder Intonationsblöcken entsprechen. Wir unterscheiden fünf Intonationsblöcke (Abbildung 4.6, a-e).
Folgende notationelle Konventionen sind bei dieser Darstellung zu beachten.
Der Anfangs- .und Endzustand jedes FluBdiagramms wird durch das Symbol "I" angegeben. Die Pfeile geben die Richtung an, in der das Diagramm durchlaufen werden kann. Senkrechte Linien stellen gemeinsame End- und/oder Anfangspunkte dar. Tonhöhenbewegungen werden durch die entsprechenden Kodes (siehe Abbildung 4.5) wiedergegeben.
In Abbildung 4.7 ist für jedes FluBdiagramm ein Beispiel einer möglichen Kontur dargestellt. Diese Konturen zeigen, daB zwischen einer Steigung und unmittelbar Colgender Senkung mit einem festen Dauerwert ein kurzes Stück Deklination (30 ms) eingefügt wird. Dadurch verläuft der Übergang von Steigung und Senkung nicht abrupt.

68 4. Ein melodisches Modell
(a)
(b)
(e)
~ Abbildung 4.6: Die beobachteten Kombinationsmöglichkeiten der Btandardisierten Tonhöhenbewegungen, dargeBteUt in Form von FlujJdiagrammen und aufgeteilt nach fünf IntonationBblöcken (a-e). Weitere Erläuterungen im Text.

4.3. Das melodische Modell 69
4 3
0
"3ST4 (b) VA VA VA
3.; 3
0
5 (c) EST
VA l
3
0
(d) VA EST
3
0
(e) EST
----~~~--*-3G_S_E_O-------------------------------------- :
Abbildung 4.7: Fünf Beispielkonturen (a-e), wie sie sich aus den entspreekenden FlufJdiagrammen ergeben. Die Deklination ist hier nicht dargeste Ut.

70 4. Ein melodischllil Modell
Block (a) Diese Konturen werden durch die Tonhöhenbewegungen in der letzten akzentuierten Silbe gekennzeichnet. Am Anfang des entsprechenden Vokals tritt eine Steigung (AOST3 oder A3ST4) auf, die von einer Senkung ( + A3SEO oder A 4SEO) gefolgt wird. Die Konturen dieses Typs zählen höchstens drei Akzente. Es ist zu b.eachten, daB sich die Abfolgen AOST3 & +A3SEO, -"OST3 & A3ST4 & A4SEO und A3ST4 & A4SEO jeweils nur auf eine akzentuierte Silbe beziehen.
Block (b) erzeugt Konturen, die einige Gemeinsamkeiten mit Block (a) aufweisen. Sie unterscheiden sich aber entscheidend in der Realisierung des letzten Akzents. In Konturen des Typs (b) wirdim Vokal der letzten akzentuierten Silbe immer eine Senkung A 3SEO realisiert. Auch diese Konturen weisen maximal drei Akzente auf. Die Abfolge - AOST3 & A 3SEO bezieht si eh nur auf eine akzentuierte Silbe.
Block ( c) umfaBt Kont uren, die mit einer Steigung *3ST5 oder *OST5 enden. In Konturen des Blocks ( c) haben wir maximal einen Akzent beobachtet.
Block { d) wird dadurch charakterisiert, da6 die Konturen dieses Typs auf Ebene 3 enden. Dazu können drei Steigungen als letzte Tonhöhenbewegung vorkommen: in der letzten betonten Silbe eine Steigung AOST3 oder + AOST3 oder in der letzten unbetonten Silbe eine Steigung *OST3. In Konturen des Blocks (d) tritt höchstens ein Tonhöhenakzent auf.
Block { e) umfaBt ausschlieBlich die graduelle Senkung *3GSEO und enthält keinen Tonhöhenakzent.
4.3.2.2 Kombinationen der Intonationsblöcke
Die beobachteten Kombinationsmöglichkeiten der einzelnen Intonationsblöcke sind im folgenden FluBdiagramm (Abbildung 4.8) wiedergegeben. Der Anfangs- und Endzustand des FluBdiagramms wird durch "$" angegeben.

4.3. Das melodische Modell 71
Abbildung 4.8: Die beobackteten Kombination8möglichkeiten der Blöcke (a), {b), {c}, {d} und {e), dargestellt in einem FlujJdiagramm. «R» markiert ein sogenanntes "Deklinationsreset". Weitere Erläuterungen im Text.
Aus Abbildung 4.8 wird ersichtlich, daB (a), (b) und (c) eigenständige Intonationsblöcke sind. Sie können eine beliebige ÄuBerung mit einer adäquaten Kontur versehen. Die Blöcke (d) und (e) hingegen können nur in Kombination rriit (a) und (b) als nicht-letzte Intonationsblöcke auftreten. Block ( d) ( eventuell gefolgt durch Block ( e)) markiert prosodische Grenzen und gliedert somit die ÄuBerung in Intonationsphrasen.
Prosodische Grenzen können auBerdem durch ein sogenanntes "Deklinationsreset" (R) gebildet werden. Ein Deklinationsreset bedeutet, daB im Verlauf einer ÄuBerung die Basisdeklination am Anfang einer neuen Intonationsphrase erneut bei 114 Hz anfängt.
Ferner kann Block (b) Block (a) unmittelbar folgen, wenn zwischen beiden ein Deklinationsreset liegt. Die Blöcke (a) und (b) gehören dann zu unterschiedlichen Phrasen. Die Blöcke (a) und (b) können Block (c) vorangehen ohne Deklinationsreset oder Block (d)(und eventuell Block ( e)) .
Die Blöcke (a) und (b) können eine beliebige ÄuBerung mit einer Kontur versehen, die maximal drei Tonhöhenakzente umfaBt. In den Blöcken (c) und (d) kann höchstens ein Tonhöhenakzent realisiert werden. Block (e) enthält keinen Tonhöhenakzent.
Wenn mehr Akzente in einer ÄuBerung vorkommenals innerhalb eines

72 4. Ein melodisches Modell
Blocks realisiert werden können, werden die Intonationsblöcke zu kompiexen Konturen zusammengefügt. Die in Abbildung 4.8 dargesteUten Regularitäten illustrieren wir imfalgenden an Hand zweier Beispiele. Wir beschrä.nken uns auf Kombinationen der Blöcke (a), (b), (d) und (e) . Block (c) berücksichtigen wir hier nicht, wei! er entweder isoliert oder in Kombinationen nur in letzter Position nach (a) oder (b) varkommen kann.
Betrachten wir zunächst in Abbildung 4.9 die Grundfrequenzkurve (gepunktete Linie) sowie die Standardkontur (durchgezogen Linie) folgender ÄuBerung:
"HANS hat IMmer schon eine VORliebe / für SCHNELle WAgen gehabt".
Die Kontur enthä.lt fünf Tonhöhenakzente. Die entsprecbenden Silben sind durch GroBbuchstaben wiedergegeben. Eine prosodische Grenze, die durch eine Kontinuierung markiert ist, wird mit "/" bezeichnet. In diesem Beispiel gibt es kein Reset.
> ::>
soor-------------------------~--~--------~~----~~4 •oo a d e b 300 1-----------li-------t---t---------1
N 200 c
' 0 "-
100 ~~.:,.·-~
/ "' ,..==..~-~·~, / > ·-
VOR- llebe f für SCHNELie WAgen gebabt' 80~------------------------~--------~~~~----~--4
HANS bat IMmer scbon eine
0.0 0. 7 1.4 2.1 2.8 3.5
t (s)
Abbildung 4.9: Die Grundfrequenzkurve (Punkte) sowie die Standardkontur (durchgezogene Linie} der Äufterung: "HANS hat IMmer schon eine VORliebe / für SCHNELle WAgen gehabt". Die akzentuierten Bilben sind durch GrofJbuchstaben wiedergegeben. Eine Kontinuierung wird durch "/" markiert. Die einzelnen Blöcke, aus denen sich die Kontur zusammensetzt, sind mit (a), (b}, (d} und (e) angegeben.
Wie Abbildung 4.9 zeigt, erscheint an einer geeigneten (syntaktischen) Stelle in der ÄuBerung (bei "VORliebe") eine Kontur des Blocks (d), eine

4.3. Das melodische Modell 73
Kontinuierung. Diese Kontur akzentuiert die Silbe "VOR-" mit Hilfe einer Tonhöhenbewegung, danach bleibt die Grundfrequenz bis zum letzten stimmhaften Frame dieses Wortes hoch. Erst dann folgt eine Senkung (Block (e)). Eine Kontinuierung (Block (d)) gibt an, daB die ÄuBerung noch nicht zu Ende ist, sie markiert eine prosodische Grenze. Durch eine Kontur des Typs (d) wird die ÄuBerung also in zwei Intonationsphrasen a.ufgeteilt. Die ersten zwei Akzente werden durch eine Kontur des Typs (a.) rea.lisiert; eine Kontur des Typs (b) bildet die beiden letzten Akzente.
Die Kontur aus Abbildung 4.9 kann schematisch folgendermaBen wiedergegeben werden:
(4.9): (a)(d)(e)(b)
Dieses Beispiel illustriert eine Regularitä.t deutscher Intonation. Wenn eine ÄuBerung mehr als drei Akzente enthä.lt, so sind mindestens zwei Konturen des Typs (a) undloder (b) notwendig. Diese Konturen folgen nicht unmittelbar aufeinander, sondern werden über eine Kontur des Typs (d)(und eventuell (e)) (oder durch ein Reset) miteinander verbunden.
Kontur (4.9) lä.Bt sich durch eine rekursive Anwendung der Blöcke (a), (b), ( d) und eventuell ( e) erweitern. Durch eine zusä.tzliche Kontur ( d) ( und eventuell ( e)) oderein Reset entsteht eine neue Intonationsphrase, in der wiederurn maximal drei Tonhöhenakzente durch Konturen des Typs (a) oder (b) realisiert werden können. Das Phrasierungsprinzip erlaubt es, Konturen mit einer heliebigen Anzahl prosodischer Grenzen zu generieren.
Eine prosodische Grenze kann auch (zusä.tzlich zu einer Kontinuierung (Block (d)) oder statt einer Kontinuierung) durch ein Deklinationsreset ( R) realisiert werden. lm Falie ei nes Resets folgt Block ( e) nicht auf Block (d) . Betrachten wir dazu die Kontur in Abbildung 4.10.
Die entsprechende Äu6erung lautet:
"Die KLAge des CSU-Ministers I über MANgelnde UnterSTÜTzung und ZAUdern in STREITfragen I R findet der Kanzier I erSTAUNlich, R erklä.rte Regierungssprecher SUDhoff".
In dieser Kontur werden prosodische Grenzen nicht nur durch eine Kontinuierung markiert (/), sondern auch durch zwei Deklinationresets

A
74 4. Ein melodiscbes Modell
> :::> _ .. - - - - - -- - - - . - -·- - - --- --500~--~~~~~~~~~~~~~~~-------------------;
400
300
N 2oo .:s
0 L.I..
> :::>
100 ,;
50 0.0 1.7 3 .•
.."../',, /" !\ .......
~I \
\ \
5.1 6.8 8.5
- - - ·- -·-- --.--B
500 400
300 d e a d d a b
50~--------------------------------------------------~· 0.0 1.7 3 . • 5.1 6.8 8.5
t (s)
Abbildung 4.10: Die Grundfrequenzkurve (A} und die Standardkontur {B} jolgender ÄujJerung: "Die KLAge des CSU-Ministers I über MANgeinde UnterSTÜTzung und ZA Udern in STRE!Tfragen I R findet der Kanzier I erSTA UNlich, R erklärte Regierungssprecher SUDhoff". "I" gibt eine K ontinuierung wieder, uR" markiert ein Deklinationsreset. In dieser ÄujJerung kommen dm' Deklinationslinien vor: A1-E1, A2-E2 und A9-E3. Ferner werden in der Abbildung die verwendeten Intonationsblöcke {a, b, dunde} angegeben. Siehe auch Abbildung 4.11.
(R). Das erste Reset tritt zusätzlich zur Kontinuierung auf, das zweite erscheint isoliert.
lm ersten Fall markiert das Reset die wichtige syntaktische Grenze zwischen einer NP und einer VP, das zweite Reset trennt zwei Sätze voneinander. Ein Satz kann hier als eine syntaktische Einheit mit einem

4.3. Das melodische Modell 75
eigenen Prädikat und Subjekt definiert werden. Durch diese zwei Reaets gibt es für diese ÄuBerung drei Deklinations
linien: Al-El, A2-E2 und A3-E3. Die Anfangsfrequenz jeder dieser drei Linien beträgt 114 Hz. Es ist zu beachten, daB die Endfrequenzen El und E2 der zwei ersten, nicht-äuBerungsfinalen Deklinationslinien bei 80 Hz, also 10Hz höher liegen als die Endfrequenz E3 (70Hz), dieamEnde der ÄuBerung erreicht wird. Die Endfrequenz von Deklinationslinien, die nicht äuBerungsfinal sind, liegt im Modell etwas höher als der normale Wert. Dies könnte darauf hinweisen, daB die Endfrequenz darüber Auf~ achluB geben kann, ob die ÄuBerung abgeschlossen ist. Diese Hypothese muB jedoch noch experimentell überprüft werden.
Die auf Seite 60 vorgeschlagene Deklinationsformel (D = -8.5lt, Endfrequenz 70 Hz) muB für nicht-äuBerungsfinale Deklinationslinien folgendermaBen tnodifiziert werden:
D = -6.llt (Endfrequenz 80Hz)
wo bei D die Deklinationsgeschwindigkeit in HT Is darstellt und t die Dauer der Deklinationslinie in Sekunden wiedergibt.
Da die Anfangs- und Endfrequenz einer Deklinationslinie festliegen, entscheidet die Dauer darüber, wie steil die Deklination verläuft. Betrachten wir dazu die Linien Al-El und A2-E2. Der Unterschied zwischen der Anfangsfrequenz (114 Hz) und der Endfrequenz (80 Hz) beträgt in Halbtönen ausgedrückt 6.1 HT. Die Linie Al-El dauert 4.5 Sekunden. Die Deklination beträgt: 6.1 I 4.5 = 1.4 HT Is.
Linie A2-E2 dauert 2 Sekunden. Hier wird dasselbe Interval! in einer kürzeren Zeit durchlaufen als oben. Entsprechend steiler ist in diesem Fall die Deklination: 6.1 I 2 = 3.0 HT Is.
Das Intervall der Linie A3-E3 (1.6 Sekunden) schlieBlich umfaBt 8.5 HT (114 Hz-70 Hz). Die Deklination beträgt 8.5 I 1.6 = 5.3 HT Is.
Abbildung 4.11 zeigt, wie die ÄuBerung im einzelnen gegliedert ist. Hier ist dargestellt, welche lntonationsphrasen der Sprecher im einzelnen unterscheidet und welche Intonationsblöcke er verwendet. Die Phrasen sind von 1 bis 5 numeriert.
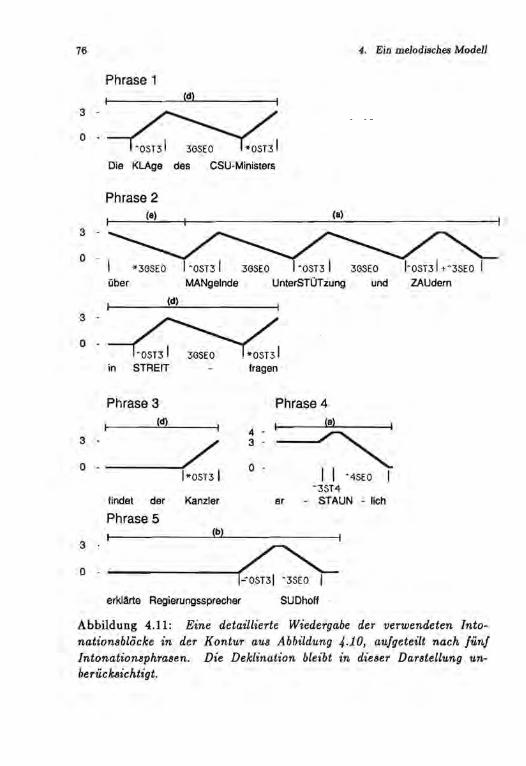
76 4. Ein melodisches Modell
Phrase 1
3
0
Die KLAge des CSU-Ministers
3
0
3
0
Phrase 2 (e)
über
Phrase 3 (d)
MANgainde
::__/ l•osr3l
findat der Kanzier
Phrase 5
3
0
erklärte Regierungssprecher
4 3
0
UnterSTÜTzung und
Phrase 4
I~ I I ' 4SEO I
"3ST4 er - STAUN - lich
SUDhoff
ZAUdem
Abbildung 4.11: Eine detaillierte Wiedergabe der verwendeten Intonationsblöcke in der Kontur aus Abbildung 4.10, aufgeteilt nach fünf lntonationBphrasen. Die Deklination bleibt in dieser Darstellung unberücksichtigt.

4.3. DIIS melodische Model/ 77
Die komplexe Kontur bestebt also aus einer Kombination fotgender Intonationsblöcke:
1 2 a 4 6
(4.10): (d) (e)(a)(d) (a)
Auch in diesem Beispiel zeigt sich, daB Tonhöhenakzente im Deutschen nicht willkürlich aneinandergereiht werden dürfen. Die ÄuBerung wird durch eine Kontur des Typs (d) und/oder durch ein Deklinationsreset in lntonationsphrasen aufgeteilt. Block (d) (Phrasen 1 und 3) kann eine Kontur des Typs (e)(a) vorangehen (Phrase 2) . Die beiden anderen Intonationsphrasen (4 und 5) bestehen aus Block (a) oder (b). Eine lntonationsphrase besteht also aus höchstens drei Intonationsblöcken.
Ferner ist zu beachten, daB die Kontur des Typs (a) in Phrase 4 ohne Reset oder Block (e) auf Block {d) in Phrase 3 folgt, weil dieseVariante des Typs (a) auf derselben Ebene (3) anfängt, auf der Block {d) endet.
An dieser Stelle sollte darauf hingewiesen werden, da6 die Einteilung nach Intonationsblöcken einen hypothetischen Charakter bat.
4.3.3 Zusammenfassung
Hier oben ist ein melodisches Modell für das Deutsche dargestellt. Dieses Modell ist hierarchisch strukturiert. Es bestebt zunächst aus einem beschränkten lnventar standardisierter Tonhöhenbewegungen und Deklinationslinien sowie aus sequentieHen Regeln. Nach diesen Regeln können Konturen gebildet werden. Auf einer höheren Ebene haben wir melodisch ähnliche Konturen zu Intonationsblöcken gruppiert. Diese Blöcke stellen versebiedene Melodisierungen dar, die nach bestimmten Regeln miteinander zu grö6eren Einheiten verbunden werden können.
Das hier präsentierte Modell beruht auf Beobachtungen in vorgelesenem Text. Um die Validität dieses Modelis zu überprüfen, ist eine perzeptive Evaluierung notwendig.

78 4. Ein melodisches Modell
4.4 Perzeptive Evaluierung: Akzeptabilität
4.4.1 Zielsetzung
In diesem Abschnitt untersuchen wir die Validität des oben dargesteilten Modelis im Rinbliek auf die Akzeptabilität von Standardkonturen. Dazu legen wir deutschen Muttersprachlern Beispiele dieser künstlichen Intonation zur Beurteilung vor.
Zu dieser Evaluierung muB folgende Einschränkung gemacht werden. Wir testen nur Standardkonturen, die sich an Kopiekonturen orientieren: Tonhöhenakzente sowie Kontinuierungen werden in denselben Si! ben mit den entsprechenden standardisierten Tonhöhenbewegungen realisiert. Der generatieve Charakter des Modelis wird nicht getestet. So wird nicht geprüft, ob Standardkonturen akzeptabel sind, die durch das Modell generiert werden, aber nicht einer beobachteten Kopiekontur entsprechen.
4.4.2 Methode
4.4.2.1 Stimuli
Für dieses Experiment haben wir 12 ÄuBerungen eines Sprechers ausgewählt (siehe Tabelle 4.2). Es handelt sich hier urn Studioaufnahmen, die nach der Resynthese eine gute Sprachqualität aufweisen. Das Testmaterial stammt - wie in Kapitel 3 - aus dem Sotschek-Korpus. Dieser Korpus umfaBt 100 Sätze, die ursprünglich für die Sprachgütemessung konstruiert wurden (Sotschek, 1984).
Die 12 LPC-resynthetisierten ÄuBerungen wurden zunächst mit einer repräsentativen Auswahl von Standardkonturen versehen, wie sie sich aus dem oben hesebriebenen Modell erge ben. Zunächst wurden Konturen des Typs (a), (b) und (c) in versebiedenen Varianten isoliert dargeboten. Es wurden ferner einige Kombinationen auch mit Konturen des Typs (d)(e) untersucht.
Tabelle 4.2 zeigt die zwölf verwendeten Sätze und die entsprechenden Intonationsblöcke, die im Experiment vertreten waren .
. Jede dieser 12 deutschen Standardkonturen wirdim Experiment durch drei weitere Versionen ergänzt:
1. eine Kopiekontur der ursprünglichen Fo-Kurve,

4.4. Perzeptive Evaluierung: Akzeptabilität 79
2. eine niederländische Standardkontur und
3. eine britisch englische Standardkontur.
Die Kopiekontur repräsentiert hier die natürliche Intonation, die Versionen (2) und (3) stellen Melodisierungen dar, die sich deutlich hörbar vom Deutschen unterscheiden.
Jede der 12 TestäuBerungen wird also mit vier versebiedenen Konturen versehen. Die entsprechenden Konturen sind in Anhang B dargestellt.
Tabelle 4.2: Die zwölf Sätze des Experiments sowie die entspreekenden Intonationsblöcke.
Satz Blöcke 1 Gestern stürmte es noch. (a) 2 Vater will sich eine Pfeife anzünden. (a) 3 Wir wollen heute spazieren gehen. (a) 4 Hier gibt es Konserven. (b) 5 Heute ist schönes Frühlingswetter. (b) 6 Zum SchluB an die Kasse. (b) 7 Wer möchte noch Milch? (c) 8 Wer trinkt einen Kaffee? (c) 9 Wer muil noch Schularbeiten machen? (a)(c) 10 MuB der Zucker nicht dort drüben stehen? (a)(c) 11 Dabinter liegt der Rosengarten. (d)(e)(a) 12 Der gelbe Küchenofen sorgt für Wärme. (a}(d)(eHb)
Aus diesen vier intonativen Versionen ergeben sich interessante Vergleichsmöglichkeiten. Einerseits läBt sich aus den Beurteilungen der natürlichen Intonation und der standardisierten Jntonation schlieBen, ob die hier oben formulierten Hypothesen die perzeptiv relevanten Aspekte deutscher Intonation adäquat wiedergeben. Andererseits zeigt der Vergleich mit der standardisierten niederländischen und britisch englischen Intonation, ob die Versuchspersonen in ihren Beurteilungen kritisch genug gewesen sind. Dabei gehen wir von der Annahme aus, daB die Versucbspersonen in diesen Fällen eine deutliche Abweichung von den Regularitäten der deutschen Intonation feststellen können. Diese Tatsache

80 4. Ein melodisches Modell
müBte dann in einer niedrigeren Bewertung der Akzeptabilität dieser Konturen zum Ausdruck kommen.
Wie wir im dritten Kapitel gezeigt haben, unterscheiden sich Kopiekonturen perzeptiv nicht von Grundfrequenzkurven. Beide können als gleichwertige Repräsentanten natürlicher Intonation geiten. In diesem Experiment verwenden wirKopiekont uren, weil dann alle vier intonativen Versionen durch gerade Linien stilisiert sind. Damit ist das Testmaterial in akustischer Hinsicht homogen.
Die niederländischen Konturen wurden nach den Regeln angefertigt, wie 't Hart und Collier (1975) sie formuliert haben; die Spezifizierung der englischen Stilisierungen wurde Willems et al. (1988) entnommen.
Zu diesen Stimuli ist folgendes zu bemerken: Die Dauer der ÄuBerungen in diesem Experiment liegt zwischen 1.0
und 2.0 Sekunden. Wie wir vorhin gesehen haben, wird in diesen Fällen sowohl im niederländischen als auch im englischen Modell die Anfangsfrequenz der Deklination abhängig von der Dauer berechnet. Ausgehend von einer festen Endfrequenz von 70 Hz beträgt die Anfangsfrequenz einer ÄuBerung mit einer Dauer von einer Sekunde 91 Hz, bei einer Dauer von zwei Sekunden beträgt sie 101 Hz.
Im Deutschen dagegen liegen sowohl die Anfangsfrequenz (114Hz) als auch die Endfrequenz (70Hz) fest. Die Anfangsfrequenz ist im Deutschen also nicht von der Dauer abhängig.
Ein wesentlicher Unterschied zwischen den niederländischen und englischen Standardkonturen einerseits und den deutschen Standardkonturen andererseits besteht also im Deklinationsverlauf. Damit vermieden wird, daB etwaige Unterschiede in der Bewertung dieser Stimuli auf einen unterschiedlichen Deklinationsverlauf zurückgeführt werden können, haben wir für die niederländischen und englischen Konturen dieselbe Deklina.tion verwendet wie im Deutschen. Die Standardkonturen unterscheiden sich damit ausschlieBlich in der Spezifizierung der Tonhöhenbewegungen.
In Abbildung 4.12 ist als Beispiel die ÄuBerung "HEUte ist schönes FRÜHlingswetter" in den vier intonativen Versionen dieses Experiments dargestellt: die Kopiekontur (KK), die deutsche Standardkontur (SD), die niederländische (SN) und die englische Standardkontur (SE) . Die ÄuBerung enthält zwei Tonhöhenakzente.

4.4. Perzeptive Evaluierung: Akzeptabilität 81
-;::; e
Q ....
> ::>
-;::; e
0 ....
> ::>
-;::; e
0 ....
> ::>
-;::; e
0 ....
500~----~--~==~--~==~------==~--~--~--~----~ 400
300 HE U te ist sch önes FRÜH lings wet ter KK 200
100 /-- -- ~ - -50
0.0 0 . 4 0.8 1.2 1.6 2.0
500
••• 300 SD
zoo
100
··· ;;--·-.:....:...:...· · · · ········ ·· ···· · · · · · ·· / ~· · · ··· · ··· · · ·· ·
- ~· · ···· · · · · · · · ··~ · · ······ · ~· · ·· . . . A - ·· -
50 0.0 0 . 4 0.8 1.2 1.6 2.0
500
••• 30Ó SN
200
100
;r--····· ·· ·· ········ ··· ···=.···, . .. .... ... ..... .. . . . A .. ... ~ A .. .. _ .. _
50 0.0 0 . 4 0 . 8 1.2 1.6 2 . 0
500
••• 300 SE 200
100 ~.·.---:.·.··. •. •. ·.~· ····. ··.·~ =··~ ' 50
0.0 0 . 4 0.8 1.2 1.6 2 . 0
t (sl
Abbildung 4.12: Vier intonative Versionen der Äufterung "Heute ist schönes Frühlingswetter": Die Kopiekontur {KK), die deutsche {SD ) , niederländische {SN} und englische Standardkontur(SE).

82 4. Ein melodisches Modell
An Hand dieser Abbildung gehen wir kurz auf die wichtigsten Unterschiede zwischen den drei Standardkonturen ein.
Zunächst fällt auf, daB die deutsche und die niederländische Kontur in diesem Fall zwei Deklinationslinien verwenden. Für die englische Stilisierung sind drei Deklinationslinien notwendig. Die Kontur fängt auf der mittleren Ebene an und erreicht erst nach der letzten Senkung die unterste Ebene.
Ein weiterer Unterschied besteht darin, wie die Steigung des ersten Akzents mit der Senkung des zweiten Akzents (beide markiert durch Pfeile) verbunden wird. In der niederländischen Kontur erfolgt dies über eine hohe Deklinationslinie, in der deutschen und englischen Kontur werden als Verbindung zwei Tonhöhenbewegungen verwendet: eine graduelle Senkung gefolgt von einer Steigung.
Betrachten wir jetzt die Unterschiede in der Spezifizierung der Steigung des ersten Akzents (Tabelle 4.3) und der Senkung des zweiten Akzents (Tabelle 4.4).
Tabelle 4.3: Die Spezifizierung der Steigung im ersten Akzent tn den Konturen SD, SN und SE aus Abbildung 4.12.
STEIGUNG SD SN SE
Position VA-60 ms VA-70 ms VA-40 ms Umfang (HT) 7.5 6 6 Dauer (ms) 180 120 80 Geschwindig-keit {HT/s) 42 50 75
Aus Tabelle 4.3 geht hervor, daB sich die drei Steigungen hinsichtlich Position un.d Frequenzumfang nur geringfügig voneinander unterscheiden. Die Unterschiede in der Dauer sind deutlicher. Im Deutschen erreicht die Steigung den Gipfel erst 120 ms nach dem Vokalanfang. Diese Gipfelwerte betragen im Niederländischen +50 ms und im Englischen +40 ms. Eine Steigung in einem akientuierten Vokal wird im Deutschen also durch einen späten Gipfel charakterisiert.
Die Geschwindigkeit einer Tonhöhenbewegung wird durch das Verhältnis zwischen Frequenzumfang und Dauer bestimrnt. Tabelle 4.3 zeigt,

4.4. Perzeptive Eva/uierung: Akzeptabilität 83
daB Tonhöhenbewegungen im Englischen wesentlicher steiler sind als im Deutschen. Niederländisch nimmt in dieser Hinsicht eine Zwischenposition ein.
Tabelle 4.4: Die Spezi.fizierung der Senkung im zweiten Akzent in den Konturen SD, SN und SE aus Abbildung 4.12.
SENKUNG SD SN SE
Position VA VA-20 ms VA+40 ms Umfang (HT) 7.5 6 12 Dauer (ms) 180 120 160 Geschwindig-keit (HT/s) 42 50 75
Der Vergleich der drei Senkungen (Tabelle 4.4) zeigt, daB es deutliche Unterschiede in der Position gibt. Die Anfangspunkte der Senkung im Niederländischen und im Englischen liegen 60 ms auseinander. Ferner ist der Frequenzumfang einer englischen Senkung erheblich gröBer (12 HT) als die entsprechenden Werte im Deutschen und Niederländischen (jeweils 6 HT). Was die Geschwindigkeit dieser Tonhöhenbewegungen betrifft, so gelten hier dieselben Feststellungen wie für die Steigungen.
Für jede der 12 TestäuBerungen gibt es also vier versebiedene Stilisierungen. Insgesamt ergeben sich auf diese Weise 4 x 12 = 48 Stimuli.
4.4.2.2 Versuchspersonen
An diesem Experiment nahmen 9 Versuchspersonen teil, Studenten der Friedrich- Wilhelms-Universität Bonn. Das Experiment fand im "lnstitut für Kommunikationsforschung und Phonetik" (IKP) statt. Die Versucbspersonen wurden für ihre Mitarbeit bezahlt.
4.4.2.3 Testverfahren
Jeder der 48 Stimuli wurde zweimal dargeboten, getrennt durch eine Pause von 500 ms. AnschlieBend hatten die Versuchspersonen drei Sekunden Zeit, ihre Entscheidung zu treffen. Ihre Aufgabe bestand darin, auf

84 4. Ein melodisches Modell
einer Skala von 1 (sehr schlecht) bis 10 (sehr gut) die Akzeptabilität zu beurteilen.
Vor jedem Stimuluspaar hörten die Versuchspersonen ein kurzes Signa!. Die 48 Stimuli wurden im Experiment noch einmal wiederholt. Insgesamt lagen also 96 Stimuli zur Beurteilung vor.
Dem Test ging eine Einführung voran (siehe Anhang B). Danach koonten die Versuchspersonen noch eventuelle Fragen stellen. Damit die Versucbspersonen sich einhören konnten, folgten noch acht Übungsstimuli, die in etwa der Breite der melodischen Variabilität im Experiment entsprechen.
Das Testband wurde den Versuchspersonen über Lautsprecher bei normaler Lautstärke vorgespielt.
4.4.3 Ergebnisse
In diesem Experiment wurden 12 Sätze (Tabelle 4.2) in vier Versionen zweimal zur Beurteilung dargeboten. Zunächst wurde die Zuverlässigkeit der Bewertungen untersucht. Dazu wurde über die Paareder ersten und zweiten Darbietung ein Pearson Korrelationskoeffizient berechnet. Beide Bewertungen korreHeren stark miteinander (r = .91). Die Versuchspersonen sind also sehr konsistent in ihren Urteilen. Die Daten bilden deshalb eine zuverlässige Grundlage für eine weitere Analyse.
In Tabelle 4.5 sind die durchschnittlichen Bewertungen und in Klammern die entsprechenden Standardabweichungen der 12 Sätze (9 Versucbspersonen x 2 Darbietungen) in den vier Versionen dargestellt. Für die vier Versionen sowie für die 12 Sätze wurden auch Mittelwerte und Standardabweichungen errechnet. Die Mittelwerte und Standardabweichungen wurden über zwei Darbietungen errechnet.
In Abbildung 4.13 sind die vier Mittelwerte der 12 Sätze aus Tabelle 4.5 graphisch dargeste!Jt. Zunächst sind die KK-Versionen nach abnehmendem Mittelwert von 1 bis 12 geordnet. Für jeden Satz wurden zusätzlich die drei anderen Mittelwerte eingezeichnet.
Diese Daten geben AnlaB zu folgenden Fragen:
• Konnten die Versuchspersonen bei der Beurteilung der Akzeptabilität signifikante Unterschiede zwischen den vier intonativen Versionen feststellen?

4.4. Perzeptive Evaluierung: Akzeptabilität 85
• Unterscheiden sich die Beurteilungen je Satz signifikant voneinander?
• Gibt es eine Wechselwirkung zwischen der Version und dem Satz?
Tabelle 4.5: Die durchsehnittliehen Bewertungen und in Klammern die entspreekenden Standardabweichungen der 12 Testsätze (9 Versuchspersonen x 2 Darbietungen) in den 4 Versionen. Aueh für die vier Versionen sowie für die zwölf Sätze sind die entspreekenden Mittelwerte und Standardabweichungen angegeben.
Satz Block KK SD SN SE y (u) 1 (a) 8.8 (0.6) 8.6 (0.4) 8.0 (0.9) 6.2 (1.6) 7.9 (0.7) 2 (a) 7.6 (0.8) 8.2 (0.7) 5.4 (0.8) 3.4 (0.7) 6.1 (0.3) 3 (a) 8.3 (0.7) 7. 7 (0.5) 5.4 (1.1) 4.1 (1.0) 6.4 (0.6) 4 (b) 6.8 (0.4) 7.4 (0.6) 5.6 (0.6) 3.9 (1.3) 5.9 (0.6) 5 (b) 8.1 (0.8) 7.7 (1.0) 6.1 (0.9) 4.2 (1.1) 6.5 (0.5) 6 (b) 8.2 (1.2) 7.7 (1.6) 7.9 {1.5) 4.9 (1.3) 7.2 {1.2) 7 (c) 4.8 (0.5) 5.3 (1.0) 4.7 {1.0) 4.2 (1.6) 4.8 (0.8) 8 (c) 8.2 (0.6) 7.1 (0.7) 5.9 (1.2) 4.0 (1.0) 6.3 (0.7) 9 (a)(c) . 7.9 (0.6) 8.4 (0.6) 6.9 (1.0) 5.2 (1.1) 7.1 (0.4) 10 (a)(c) 7.6 (0.9) 7.7 (0.9) 5.9 (1.1) 4.2 (1.2) 6.3 (0.7) 11 (d)(e)(a) 8.7 (0.8) 8.1 (0.6) 5.6 (1.2) 5.2 (0.8) 6.9 (0.6) 12 (a)(d)(e)(b) 8.4 (1.1) 7.3 (0.9) 5.0 (1.2) 4.2 (1.2) 6.2 (0.7)
x (u) 7.8 (1.3) 7.6 (1.2) 6.0 (1.4) 4.5 (1.3)
Ein Cochran-Test zeigt, daB eine wichtige Voraussetzung für eine Varianzanalyse (homogene Varianz) erfüllt ist (C = 0.3061, p = 0.132).
Auf Grund einer zweifachen Varianzanalyse (mit "Version" und "Satz" als Faktoren) kommen wir zu folgenden Ergebnissen:
1. Es gibt einen signif!kanten Effekt des Faktors "Version" (F(3,384) = 128.90, p<.0001).
Ein paarweiser a posteriori Vergleich der vier Versionen (Scheffé) zeigt, daB die Kopiekonturen (KK) keine signifikanten Unterschiede

86 4. Ein melodisches Modell
zu den deutschen Standardkonturen (SD) aufweisen. (p>.05). Dagegen unterscheiden sich diese beiden Versionen (KK und SD) signifikant von den niederländischen (SN) und englischen (SE) Standardkonturen (p<.05). SchlieSlich unterscheiden sich auch die Versionen SN und SE signifikant voneinander. Hörer teilen also die vier Versionen in drei intonative Gruppen ein.
Aus Abbildung 4.13 geht hervor, daB bis auffünf Ausnahmen (Satz 9, 2, 10, 4 und 7) die Kopiekontur am besten beurteilt wird. Dann folgen die Versionen SD, SN und SE. Nur in einem Fall (Satz 6) wird die Version SN besser beurteilt als SD.
2. Es gibt einen signifikanten Effekt des Faktors "Satz" (F(u,384) = 13.05, p< .0001). Demnach bören die Versuchspersonen deutliche Unterschiede zwischen den einzelnen Sätzen. Die Mittelwerte der Sätze variieren zwischen 7.9 (1) und 4.8 (7) .
3. Es gibt auch eine Wechselwirkung zwischen den beiden Faktoren "Version" und "Satz" (F(33,384) = 6.66, p<.0001) . Das heiBt, daB die Beurteilung der Version vom Satz abhängig ist.
Wie Abbildung 4.13 zeigt, kommt in allen Sätzen (bis auf die Sätze 6 und 7) der Effekt der Konditionen in der Bewertung zum Ausdruck. In Satz 7 liegen die Bewertungen der vier Konditionen viel näher beieinander als in den anderen Sätzen. Alle Versionen von Satz 7 werden niedrig beurteilt. In diesem Fall wird der Effekt der Version durch den Faktor Satz neutralisiert.
Auch in Satz 6 läSt sich eine Interaktion beobachten. Hier liegen die Bewertungen der drei Versionen KK, SD und SN sehr nah beieinander. Die beobachtete lnteraktion zwischen den Faktoren Version und Satz kann also zu einem GroSteil auf die Sätze 6 und 7 zurückgeführt werden.

4.4. Perzeptive Evaluierung: Akzeptabilität 87
9
8
7 Cl) t:: Cl)
~6 --:::E 5
4
3
1 11 12 3 6 8 5
Sätze
e KK 0 SD • SN D SE
9 2 10 4 7
Abbildung 4.13: Graphische Darstellung der vier Mittelwerte der 12 Sätze aus Tabelle ./.5. Die Verbindungslinien zwischen den Mittelwerten sind ausschlie.Plich als graphische Hilfslinien zu betrachten. Weitere Erläuteru.ngen im Text.

88 4. Ein melodisches Modell
4:.4.4 Diskussion und Schlu6folgerungen
In diesem Kapitel wurde ein hierarchisch strukturiertes Intonationsmodell für das Deutsche entwickelt. Es bestebt aus einem beschränkten lnventar diskreter, standardisierter Tonhöhenbewegungen und Deklinationslinien. An Hand von Kombinationsregeln werden diese Bauelemente zu wohlgeformten Konturen verbunden. Auf einer höheren Ebene werden melodisch ähnliche Konturen zu lntonationsblöcken gruppiert. Durch weitere Regeln können diese intonativen Blöcke dann zu komplexen Konturen kombiniert werden.
Zu diesem Modell sind einige Einschränkungen zu machen.
1. Das vorliegende Modell wurde hier nur hinsichtlich der Akzeptabilität einzelner Konturen überprüft. Die Frage nach der perzeptiven Äquivalenz von Standardkonturen und natürlicher Intonation bleibt also unbeantwortet.
2. Die hier vorgelegten Ergebnisse beschränken sich nur auf melodische Strukturen, wie sie in vorgelesenem Text auftreten. AuBerdem ist zu beachten, daB hier nur die Akzeptabilität einer kleinen Anzahl von Standardkonturen in einzelnen, unzusammenhängenden kurzen Sätzen überprüft wurde. Hieraus lassen sich keine Schlüsse ziehen, wie die künstliche Intonation in Texten beurteilt wird.
Wenden wir uns jetzt den Ergebnissen zu. Das Perzeptionsexperiment zeigt, daB die untersuchten deutschen Standardkonturen für Hörer genauso akzeptabel sind wie Kopiekonturen. Das beiBt, daB die Konturen, die sich aus dem melodischen Modell ergeben, die für den Hörer relevanten Formmerkmale der deutschen lntonation perzeptiv adäquat wiedergeben. Dieses Ergebnis wird noch zusätzlich durch die Tatsache unterstützt, daB die niederländiscben und englischen Konturen als deutlich abweichend gehört werden . .
Auch die Ergebnisse von de Pijper (1983) und Willems et al. {1988) zeigen, daB Hörer sehr genau feststellen können, ob eine Kontur zum Intonationssystem ihrer Muttersprache gehört. In den beiden genannten Untersucbungen bewerteten englische Versuchspersonen niederlä.ndische Konturen signifikant niedriger als Beispiele englischer Intonation.

4.4. Perzeptive Evaluierung: Akzeptabilität 89
Betrachten wir jetzt zwei auffällige Ergebnisse etwas näher.
1. In unserem Perzeptionsexperiment wurden deutsche Konturen mit niederländischen und englischen Tonhöhenbewegungen nachgebildet. Hörer identifizieren diese Imitatiooen deutlich als abweichend. Ein Grund für die geringere Akzeptabilität dieser Konturen liegt in einer anderen Spezifizierung der Tonhöhenbewegungen. Ein weiterer Grund könnte die lange Dauer einer hohen Deklinationslinie sein, die für deutsche Hörer nicht akzeptabel ist.
Betrachten wir zunächst in Abbildung 4.14 folgende zwei deutsche Kont uren, Varianten des Typs (b).
A B
(1)
A B
(2)
Abbildung 4.14: Zwei Varianten des Typs (b).
In dem untersuchten Korpus kommt Kontur (1) nur dann vor, wenn die Dauer zwischen dem Ende der Steigung (A) und dem Ende der Senkung (B) kleiner als etwa 400 ms ist. Beträgt der Abstand zwischen den Punkten A und B jedoch mehr als 400 ms, dann kann eine graduelle Senkung (mindestens 180 ms) und eine folgende Steigung {180 ms) realisiert werden, wie in Kontur (2) dargestellt. Bei der Wahl einer dieser beiden Varianten entscheidet also das Zeitkriterium. Wenn die Dauer es zuläBt, muB zwischen den Punkten A und B die niedrige Deklinationslinie erreicht werden.
lm deutschen Modell gibt es also zwei Möglichkeiten, die Verbindung

90 4. Ein melodisches Model/
zwischen den Punkten A und B zu gestalten, wenn in der letzten akzentuierten Silbe eine frühe Senkung auftritt .. In diesem Fall unterscheidet das niederländische Modell nur die Möglichkeit, die Kontur (1} entspricht, also die Verbindung derPunkteA und B über die hohe Deklinationslinie.
Im Experiment gibt es drei niederländische Konturen dieser Art. In Tabelle 4.6 ist die Dauer zwischen den Punkten A und B sowie die Bewertung der niederländischen Konturen wiedergegeben.
Tabelle 4.6: Die Dauer zwischen den Punkten A und B (siehe Abbildung ..j.14} in drei niederländischen Versionen sowie ihre Bewertung.
Satz Dauer A-B Bewertung 4 650 ms 5.6 5 6
770 ms 220 ms
6.1 7.9
In den Sätzen 4 und 5 erwarten deutsche Hörer keine hohe Deklination, wei! die Dauer zu gro6 ist. Folglich fällt die Bewertung niedrig aus. In Satz 6 hingegen entspricht eine hohe Deklination der Erwartung, Jo daB hier die Akzeptabilität relativ hoch ist, sogar etwas höher als die der deutschen Kontur.
Diese Ergebnisse legen nahe, da6 die Kontur, die im Niederländischen am häufigsten vorkommt, das sogenannte "Hutmuster", im Deutschen nur bedingt verwendet werden kann. Diese Variante ist im Deutschen nur zulässig, wenn aus Zeitgründen die niedrige Deklinationslinie nicht mehr erreicht werden kann.
Englische Konturen fangen in diesem Experiment auf der mittleren Deklinationslinie an. Sie entspricht der niederländischen hohen Deklinationslinie. Bei den englischen Stimuli überschreitet die Dauer dieser mittleren Deklinationslinie in einem Fall die kritische Grenze von 400 ms. In Satz 4 dauert dieser Abschnitt 620 ms. Entsprechend niedrig ist die Bewertung: 3.9.
2. Betrachten wir zum Schlu6 den Unterschied in der Bewertung zwischen der niederländischen Version von Satz 1 (Typ (a), ein Akzent, 8.0} und Satz 2 (Typ (a), zwei Akzente, 5.4) . Satz 2 wird in diesem Fall deutlich

4.5. Zusammenfassung des melodischen Modells 91
niedriger bewertet. Ein möglicher Grund für diesen Unterschied liegt in der Position des Gipfels des Tonhöhenakzents im Verhältnis zur Dauer des akzentuierten Vokals.
In Satz 1 dauert der akzentuierte Vokal in "STÜRMte" 100 ms. In Satz 2 dauert der erste akzentuierte Vokal ("VAter") 120 ms, der zweite ("PFEife") umfaBt 170 ms.
Der Gipfel der niederländischen Kontur liegt in Satz 1 50 ms nach dem Vokalanfang, also etwa in der Mitte des Vokals. Diese Position ist für deutsche Hörer offensichtlich akzeptabel. In der deutschen Version wird der Gipfel 120 ms nach dem Vokalanfang erreicht.
In Satz 2 liegt der Gipfel im ersten akzentuierten Vokal auch in der Mitte, wie in Satz 1. lm zweiten akzentuierten Vokal dagegen wird der Gipfel bereits im ersten Drittel erreicht. In der deutschen Version liegt der Gipfel immer in der zweiten Hälfte des Vokals (120 ms nach dem Vokalanfang). Die Unterschiede in der Positionierung zwischen Deutsch und Niederländisch manifestieren sich vor allem in langen Vokalen. Dies weist darauf hin, daB die Gipfelposition im Verhii.ltnis zur Vokaldauer einen deutlichen Unterschied zwischen beiden Sprachen darstellt.
4.5 Zusammenfassung des melodischen Modells
In diesem Kapitel haben wir ein melodisches Modell für das Deutsche entwiekelt, das aus einem lnventar diskreter Bauelemente sowie aus Regeln besteht, nach denen wohlgeformte Konturen gebildet werden können.
In einem Experiment wurde untersucht, ob Konturen, die auf Grund dieses Modelis gebildet wurden, perzeptiv akzeptabel sind. Die Ergebnisse zeigen, daB Hörer diese Konturen hinsichtlich ihrer Akzeptabilität nicht von natürlicher Intonation unterscheiden können. Niederländische und englische Konturen dagegen werden von den Versuchspersonen im allgemeinen deutlich als abweichend erkannt. Dieses Ergebnis bestätigt die SchluBfolgerung, daB die Hörer keine Unterschiede in der Akzeptabilität deutscher Standardkonturen und natürlicher Intonation wahrnehmen können.
Ein wesentlicher Unterschied zwischen dem deutschen und dem niederländischen Intonationssystem ist, daB die Verwendung einer hohen Deklinationslinie im Deutschen temporalen Restriktionen unterliegt. AuBer-

92 4. Ein melodisches Modell
dem ist die abweichende Positionierung einer Steigung in einer akzentuierten Silbe im niederländischen Modell für deutsche Hörer vor allem in langen Silben hörbar falsch.

5
Diskussion
5.1 Einleitung
Die vorliegende Arbeit setzte sich zum Ziel, für das Deutsche ein melodisches Modell zu entwickeln, das aus einem lnventar perzeptiv relevanter Tonhöhenbewegungen sowie aus Kombinationsregeln besteht. In diesem abschlie6enden Kapitel betrachten wirdie Ergebaisse unter versebiedenen Gesichtspunkten.
Zunächst diskutieren wir die Ergebnisse der in Kapitel 2 hesproehenen phonetischen Untersuchungen der deutschen Intonation vor dem im vorigen Kapitel entwiekelten melodischen Modell (Abschnitt 5.2). Ferner vergleichen wir die perzeptiv relevanten Merkmale der deutschen latonation mit den entsprechenden Charakteristiken der niederländischen und der englischen lntonation. Auf diese Weise erhalten wir Einblick in die melodischen Übereinstimmungen und Unterschiede zwischen diesen drei germanischen Sprachen (Abschnitt 5.3). In Abschnitt 5.4 beschreiben wir drei praktische Anwendungen des melodischen Modells. Zum Schlu6 dieser Arbeit gehen wir in Abschnitt 5.5 auf einige offene Fragen ein.
5.2 Diskussion der Literatur
In diesem Abschnitt vergleichen wir die wichtigsten Erkenntnisse der in Kapitel 2 hesproehenen Untersuchungen mit dem im vorigen Kapitel entwiekelten melodisclien Modell. Wir diskutieren drei Aspekte: die Deklination, den Frequenzumfang der Tonhöhenbewegungen und die Phrasie-
93

94 5. Diskussion
rung.
1. Deklination In dem im vorigen Kapitel hesebriebenen Modell ist die Deklination ein unverzichtbarer Bestandteil einer jeden Kontur. Bereits Klinghardt (1923) und später auch von Essen (1964) haben mit ihrer Beobachtung, daB die Tonhöhe im Verlauf einer ÄuBerung abfällt, auf ein perzeptiv relevantes Merkmal natürlicher Intonation hingewiesen. Auch in den Modellen von Zingle (1982), Bannert (1983) und Kohier (1988)1 ist die Abnahme der Tonhöhe im Verlauf einer ÄuBerung von wesentlicher Bedeutung. In Isacenko und Schädlichs Untersuchung (1964) bleibt die Deklination unberücksichtigt, wei[ sie mit monotonisierten SprachäuBerungen gearbeitet haben.
Die Berücksichtigung der Deklination in unserem Modell ist also in guter Übereinstimmung mit den Ergebnissen früherer Untersuchungen.
2. Frequenzumfang Die in unserem Model! vorgeschlagenen Werte für den Frequenzumfang sind in guter Übereinstimmung mit von Essens (1964) Angaben. Von Essen unterscheidet die Tonstufen "hoch" und "tief' . Das Intervall zwischen beiden Stufen kann zwischen 7 und 9 HT liegen.
In unserem Modell weisen Tonhöhenbewegungen zwischen den Ebenen 0 und 3 einen Frequenzumfang von 7.5 HT auf. Das lntervall zwischen den Ebenen 0 und 4 beträgt 10 HT.
Ein terminaler Fall hat in Kohlers Modell (1988) einen Frequenzumfang von 6.4 HT, eine Kontinuierung umfaBt 6 HT.
In den Experimenten von Isacenko und Schädlich (1964) liegen die Frequenzumfänge zwischen 1 und 3 HT. In Zingles Modell (1982) liegt der Gipfel 1 HT über der Anfangsfrequenz. Möglicherweise ist dieser geringe Frequenzumfang auf die Aussage von Isacenko und Schädlich zurückzuführen, daB 1 HT ausreiche, urn eine Silbe als "betont" zu identifizieren. Diese Feststellung ist unabhängig davon, weicher Frequenzumfang in einer Sprache üblich ist.
Zur Steigung am Ende einer Frage2 bemerkt Von Essen (1964), daB in diesem Fall der Frequenzumfang auffallend gröBer ist als die genannten
1 ln Kohlers Modell werden statt Deklination die Akzentgipfel abgestuft. 2 An dieser Stelle iot darauf hinznweisen, daB nicht jede Frage durch eine Steigung arn Ende der
Äullernng charakterioiert wird. Ebensowenig iot eine ÄuBernng mit einu Sleigong am Ende immer ale Frago einsuetufen.

5.2. Diskussion der Literatur 95
7 bis 9 HT und nicht identisch ist mit der "Weiterweisung". In dem im vorigen Kapitel beschriebenen lnventar der Tonhöhenbewegungen gibt es eine Steigung (*OST5) die mit 12.5 HT wesentlich gröBer ist als die anderen Tonhöhenbewegungen.
Auch von Helmholtz (1870) hat sich zur Frage geä.uBert: "Der fragende SchluB steigt empor, oft urn eine Quinte über den Mittelton." Tatsä.chlich gibt es im lnventar die Steigung *3ST5 mit einem Frequenzumfang von 5 HT, 2 HT weniger als die von Helmholtz angegebene Quinte.
Wie von Helmholtz ferner ausführt, liegt das Ende eines Aussagesatzes eine Quarte (5 HT) unter der "mittleren Tonhöhe". Zusammen mit der hier oben genannten Quinte liegt das Ende der Frage also 12 HT über dem tiefsten Wert in einer Aussage. Der Frequenzumfang der Steigung *OST5 im Modell beträgt 12.5 HT.
Die "Frage"-Steigung in Kohlers Modell (1988) weist einen Frequenzumfang von 13.8 HT auf.
Die Werte des Frequenzumfangs, die wir in unserem Modell vorschlagen, weichen nicht erheblich von früheren Beobachtungen ah.
3. Phrasierung Klinghardt (1923) betont die Notwendigkeit, eine ÄuBerung in "Sprechtakte" aufzugliedern. Am Ende eines Sprechtakts bleibt die Tonhöhe nach der letzten betonten Silbe hoch (siehe Abbildung 2.1, S. 8). Diesen Verlauf haben wirbei Delattre, Poenack und Olsen (1965) als Kontinuierung kennengelernt (siehe Abbildung 2.3, S. 15). Diese Art der Kontinuierung entspricht den Tonhöhenbewegungen AOST3 oder + AOST3 in unserem Modell. AuBerdem unterscheiden wir auch noch die Steigung *OST3.
Auch von Essen (1964) weist darauf hin, daB längere Sätze in Phrasen aufgeteilt werden. Jede Phrase wird durch einen spezifischen Tonhöhenverlauf, eine "Weiterweisung" gekennzeichnet.
Auch in unserer Untersuchung hat sich gezeigt, daB die Phrasierung mit Hilfe eines typischen Tonhöhenverlaufs von entscheidender Bedeutung ist. Die entsprechenden Konturen sind in Typs (d) zusammengefaBt. Die Tonhöhenbewegungen dieses Typs haben alle denselben Frequenzumfang (7.5 HT). In unserer Untersuchung haben wir keinen AnlaB gefunden zwischen einer "kleinen" (4 HT) und einer "groBen" (8 HT) Kontinuierung zu unterscheiden, wie Delattre et al. es tun.
Zum SchluB kommen wir auf das Experiment von lsa.Cenko und Schä.d-

96 5. Diskussion
lich (1964) zurück, in dem abhängig vom Grundfrequenzverlauf eine ÄuBerung unterschiedlich gegliedert wird (siehe S. 20) . In Abbildung 5.1 sind die entsprechenden künstlichen Grundfrequenzverläufe aus Abbildung 2.8 noch einmal dargestellt.
e diese Eneher einer F.re
Abbildung 5.1: Zwei künstliche Grundfrequenzverläuje, die eine unterschiedliche Gliederung der Äuj/erung "Johann brachte diese Bücher einer Freundin seiner Schwester" hervorrufen. Weitere Erläuterungen im Text. Aus: Isacenko und Schädlich, 1964 .
Die unterschiedliche Bedeutung der beiden intonativen Versionen ist darauf zurückzuführen, daB in beiden Varianten an versebiedenen Stellen eine Kontinuierung auftritt. In unserem Modell kann eine Kontinuierung . dadurch realisiert werden, daB die Grundfrequenz nach der Steigung in der betonten Silbe bis zur letzten stimmhaften Silbe hoch bleibt und danach auf die unterste Deklinationslinie zurückfä.llt. Dieser Verlauf tritt in Version (a) in "Bücher" auf, in Version (b) begegnen wir diesem Verlauf in "Freundin". Durch die unterschiedliche Phraseneinteilung, die dies zur Folge bat, kann das Ergebnis dieses Experiments erklä.rt werden.
Was die Phrasierung angeht, können wirdie Beobachtungen von Klinghardt, von Essen, lsa.Cenko und Schädlich sowie Delattre, Poenack und Olsen bestä.tigen.
5.3 Deutsche, niederländische, englische Intonation im Kontrast
In diesem Abschnitt bespreehen wir die wichtigsten intonativen Unterschiede und Übereinstimmungen zwischen Deutsch und Niederländisch einerseits und Deutsch und Englisch andererseits, soweit sie sich auf vorgelesenen Text beziehen. Dazu vergleichen wir die intonativen Systeme dieser drei Sprachen, wie sie für das Deutsche im vorigen Kapitel,

5.3. Deutsche, niederländische, englische Intonation im Kontrast 97
für das Niederlä.ndische in 't Hart und Collier (1975) und für das Englische in Willeros et al. (1988) hesebrieben sind.
Diese drei lntonationsmodelle haben als gemeinsames Merkmal, daB sie auf der Grundlage der !PO-Methode ersteUt worden sind. Nur die perzeptiv relevanten Grundfrequenzä.nderungen der Intonation werden in der Beschreibung berücksichtigt. Sie werden visuell durch gerade Linien dargestellt, logarithmisch skaliert.
In diesem Ansatz, wie er am IPO entwiekelt worden ist, umfaBt ein Intonationsmodell drei Teile:
1. parallel verlaufende Deklinationslinien,
2. ein beschrä.nktes lnventar prototypischer, standardisierter Tonhöhenbewegungen und
3. Kombinationsregeln, nach denen lntonationskonturen gebildet werden können.
Auf diese Aspekte gehen wir im weiteren in einem Vergleich der jeweiligen Modelle nä.her ein. Doch zunächst charakterisieren wir kurz die drei intonativen Systeme.
Abbildung 5.2 zeigt den Intonationsverlauf einer ÄuBerung, diemit einer deutschen (a), einer niederlä.ndischen (b) und einer englischen Kontur ( c) versehen ist.
Der Vergleich zeigt, daB sich die drei Konturen aus parallelen Deklinationslinien zusammensetzen, zwischen denen sich die Tonhöhenbewegungen befinden. Die wichtigsten Unterschiede betreffen folgende Punkte:
1. Das Deutsche und das Niederländische stellen sich im wesentlichen als ein zweistufiges System dar, das Englische hingegen unterscheidet hauptsä.chlich drei Stufen. Im deutschen Modell sind die Deklinationslinien 0 und 3 am wichtigsten, weil die Konturen ausschlieBlîch auf diesen beiden Ebenen anfangen können. Ebene 4 kommt nur in einer Variante des Typs (a) vor, Ebene 5 tritt nur in Konturen des Typs ( c) auf.
2. Der Abstand zwischen der höchsten und der niedrigsten Deklinationslinie ist im Englischen (12 HT) erheblich gröBer als im Deutschen (7.5 HT) und im Niederlä.ndischen (6 HT).

98 5. Diskussion
3. Die deutschen und die niederländischen Tonhöhenbewegungen ( 42 HT/s und 50 HT/s) sind weniger steil als im Englischen (75 HT/s).
Insgesamt erscheinen die Unterschiede zwischen dem Deutschen und dem Niederländischen geringer als zwischen dem Deutschen und dem Englischen. Im folgenden gehen wir auf die melodischen Unterschiede näher ein.
6.3.1 Deklination
In allen drei untersuchten Sprachen bat sich gezeigt, daB die Deklination, die Abnahme der durchschnittlichen Grundfrequenz im Verlauf einer ÄuBerung, ein perzeptiv relevantes Merkmal natürlicher Intonation ist. Im IPO-Ansatz wird die Deklination durch eine langsam sinkende gerade Linie dargestellt, die sich über die ganze ÄuBerung erstreckt. Urn eine Kontur zu erzeugen, wird diese Basislinie urn eine oder mehrere parallel verlaufende Deklinationslinien ergänzt, zwischen denen sich die Tonhöhenbewegungen befinden (Abbildung 5.2) .
Wie aus Abbildung 5.2 hervorgeht, ist der Verlauf der Basisdeklination in den drei Sprachen nicht gleich. Die Endfrequenz ist im deutschen Modell festgelegt auf 70 Hz, im niederländischen auf 75 Hz und im englischen Modell auf 65 Hz. Bei einer Dauer von 1.6 s beträgt die Anfangsfrequenz im Deutschen 114 Hz, · im Niederländischen 105 Hz und im Englischen 91 Hz. Somit verläuft die deutsche Deklination in diesem Beispiel steiler (-5.6 HT/s) als die niederländische und die englische (-3.7 HT/s).
Wie wir im vorigen Kapitel gesehen haben, ist die Anfangsfrequenz im deutschen Modell unabhängig von der Dauer der ÄuBerung. Sie beträgt 114 Hz. Im niederländischen und englischen Modell steigt jedoch mit zunehmender Dauer (bis 5 s) auch die Anfangsfrequenz (siehe S. 61). Bei einer Dauer von 5 Sekunden beträgt sie im Niederländischen 123 Hz und im Englischen 106Hz. ÄuBerungen mit einer Dauer länger als 5 s weisen im Niederländischen und Englischen feste Anfangsfrequenzen auf: 123Hz und 106 Hz. Ab einer Dauer von 5 s liegen in allen drei Sprachen sowohl die Anfangs- als auch die Endfrequenz fest.
Die Deklination weist in den drei Sprachen unterschiedliche Verläufe auf.

5.3. Deutsche, niederländische, englische Intonation im Kontrast 99
> ::I
~00
••• DEUTSCH lOO
-;:; 200 : 0 ... --------100
~0 0 . 0 0.4 0.8 1.2 1.6 2.0
t (s)
> ::I
500
••o NIEDERLÄNDISCH 300
N 200 : 0 ...
100
~· 0 . 0 0.4 O.B 1.2 1.6 2.0
t (sl
> ::I
500
400 ENGLISCH 300
.... 200 : -----0 .... 100
50 . 0.0 0.4 0.1 1.2 1.6 2.0
t (sl
Abbildung 5.2: Beispiel einer deutschen, niederländischen und englischen K ontur, die zwei Tonhöhenakzente enthält. Die ieweiligen Deklinations-linien sind eingezeichnet.

100 5. Diskussion
6.3.2 Ebenen
Wie wir hier oben bereits gesehen haben, verfügen das Deutsche und das Niederländische über ein zweistufiges Intonationsmodell. Der Abstand zwischen diesen beidenEbenen umfaBt im Deutschen 7.5 HT und im Niederländischen 6 HT. Das Englische dagegen kennt ein dreistufiges System. Hier beträgt der Abstand zwischen zwei aufeinander folgenden Ebenen jeweils 6 HT (wie im Niederländischen). Zwischen der höchsten und der niedrigsten Ebene liegen somit 12 HT oder eine Oktave.
Deklinationslinien sind in bezug auf Tonhöhenbewegungen als Referenzlinien zu betrachten. Die obigen Beispiele zeigen, daB Anfa.ng und Ende einer Steigung oder Senkung immer auf einer dieser Linien liegen. Somit bestimmt die Anzahl der Deklinationslinien oder Ebenen, die in einem intonativen System unterschieden werden, die Abstufungsmögliehkeiten der Tonhöhenbewegungen.
Im Deutsehen und im Niederländischen bewegen sieh die Steigungen und Senkungen zwischen zwei parallel verlaufenden Deklinationslinien, die in einem bestiroroten Abstand zueinander verlaufen. Dadureh ist der Frequenzumfang der Tonhöhenbewegungen immer derselbe. In einem dreistufigen System wie dem Englisehen hingegen gibt es Tonhöhenbewegungen mit einem Frequenzumfang von 12 HT und 6 HT. AuBerdem treten die Tonhöhenbewegungen mit halhem Frequenzumfang sowohl im unteren als im oberen Bereich auf.
Das Deutsehe weist also dureh die Zweistufigkeit (Konturen können nur auf zwei Ebenen (0 und 3) anfangen) eine deutliehe Übereinstimmung mit dem Niederländisehen auf, auch wenn die Distanz zwisehen beiden Ebenen im Deutschen urn 1.5 HT gröBer ist. Das Englisehe weiebt in dieser Hinsicht stark ab, da das lntonationssystem dreistufig ist und es somit Tonhöhenbewegungen mit ganzem und halhem Frequenzumfang unterseheidet.
6.3.3 Tonhöhenbewegungen
Tonhöhenbewegungen (Steigungen und Senkungen) werden als gerade Linien dargesteUt und dureh drei Parameter definiert: Dauer, Frequenzumfang und Position in der Silbe. Im fotgenden vergleichen wir, wie diese Parameter in den versebiedenen Spraehen spezifiziert sind.

5.3. Deutsche, niederländische, englische Intonation im Kontrast 101
5.3.3.1 Dauer und Frequenzumfang
In Tabelle 5.1 sind die Standardwerte für Dauer und Frequenzumfang sowie die entsprechende Geschwindigkeit einer Tonhöhenbewegung im Deutschen, Niederländischen und Englischen wiedergegeben.
Für die Dauer und den Frequenzumfang im Englischen werden zwei Werte genannt. Die erste Angabe bezieht sich auf die "ganze" Tonhöhenbewegung, der Wert hinter dem Schrägstrich gilt für die "halbe" Tonhöhenbewegung. Die Geschwindigkeit bleibt in beiden Fällen unverändert.
Tabelle 5.1: Die Dauer, der Frequenzumfang und die Geschwindigkeit der Tonhöhenbewegungen im deutschen, niederländischen und engliseken Modell.
Dauer Frequenz- Geschwindig-(ms) umfang (HT) keit (HT /s)
Deutsch 180 7.5 42 Niederländisch 120 6 50 Englisch 160/80 12/6 75
Aus dem Vergleich geht hervor, daB eine Tonhöhenbewegung im Deutschen 60 ms länger dauert als im Niederländischen und dabei einen urn 1.5 HT gröBeren Frequenzumfang aufweist. Die Geschwindigkeit ist etwas geringer als im Niederländischen.
Die deutsch-englischen Unterschiede sind gröBer. Bei einer in etwa gleichen Dauer ist der Frequenzumfang im Englischen 4.5 HT gröBer als im Deutschen. Dies manifestiert sich auch in der Geschwindigkeit. Eine englische Tonhöhenbewegung ist erheblich steiler als eine deutsche.
Im Deutschen kann am Ende einer ÄuBerung eine Steigung mit einem Frequenzumfang von 12.5 HT auftreten. Dieser Wert weicht von dem im Deutschen üblichen Frequenzumfang (7.5 HT) erheblich ah. Er entspricht eher dem Frequenzumfang einer Tonhöhenbewegung im Englischen. Dabei muB jedoch berücksichtigt werden, daB die Dauer in diesem Fall 300 ms beträgt, alsofast doppeltso lang ist wie im Englischen.
Es zeigt sich also, daB im Rinbliek auf die Dauer einer Tonhöhenbewegung die U nterschiede zwischen Deutsch und Englis eh relativ gering sein

102 5. Diskussion
können (180 ms- 160 ms) oder sehr groB (180 ms- 80 ms). Die Unterschiede in der Dauer zwischen deutschen und niederländischen Tonhöhenbewegungen sind weder sehr groB noch sehr klein (180 ms - 120 ms).
Was den Frequenzumfang betrifft, so sind die Unterschiede zwischen Deutsch und Niederländisch relativ gering. (7.5 HT - 6 HT). Der Unterschied zwischen Deutsch und Englisch kann in dieser Hinsicht relativ gering sein (7.5 HT- 6 HT) oder erheblich gröBer (7.5 HT- 12 HT).
5.3.3.2 Position in der Silbe
In den drei Sprachen werden Tonhöhenbewegungen nicht willkürlich mit der segmentalen Ebene synchronisiert, sondern sie richten sich nach zwei Referenzpunkten: (a) dem Vokalanfang einer akzentuierten Silbe oder (b) dem Ende des stimmhaften Teils einer (betonten oder unbetonten) Silbe. Diese zwei Referenzpunkte sind in den Modellen der drei Sprachen diesel ben.
Im allgemeinen unterscheidet die Steigung in den drei Sprachen drei Positionen in bezug auf den Vokalanfang der akzentuierten Silbe (Referenzpunkt (a)):
1. Früh: das Ende der Steigung entspricht in etwa dem Vokalanfang. Diese Tonhöhenbewegung kommt im niederländischen lnventar nicht vor.
2. Mitte: Der Vokalanfang liegt etwa in der Mitte der Steigung.
3. Spät: Die Steigung fängt ungefähr beim Vokalanfang an.
Die Senkung unterscheidet zwei Positionen in bezug auf den akzentuierten Vokal:
1. Früh: Die Senkung fängt in etwa beim Vokalanfang an.
2. Spät: Die Senkung folgt auf eine vorangehende Steigung in der Position "Mitte" oder "Spät". Letztere Kombination einer "späten" Steigung mit einer unmittelbar folgenden Senkung gibt es im Deutschen nicht.

5.3. Deutsche, niedecliindische, englische lntonation im Kontcast 103
Was den zweiten Referenzpunkt (b) angeht, so sind in den drei Sprachen die Steigungen so positioniert, da.B der Gipfel dem Ende des stimmhaften Teils einer Silbe entspricht. Auch anschliel3ende Senkungen orientieren sich an diesem Referenzpunkt. Solche Senkungen gibt es im Englischen nicht.
Diese kurze Übersicht zeigt, daB die Tonhöhenbewegungen dieser drei Sprachen in bezug auf den Vokalanfang ähnlich positioniert sind. Abhängig von den jeweiligen Werten für die Dauer und den Frequenzumfang werden die Tonhöhenbewegungen jedoch sehr unterschiedlich realisiert.
lm folgenden Abschnitt bespreche ich, wie sich die unterschiedliche Spezifizierung der Tonhöhenbewegungen in Konturen manifestiert.
6.3.4 Konturen
Urn Konturen zu erzeugen, werden Steigungen und Senkungen an Hand von Regeln miteinander verbunden. Wie wir in Kapitel 4 gesehen haben, lassen sich dabei unterschiedliche melodische Konfigurationen oder Intonationsblöcke ermitteln. Jede Konfiguration hat ein spezifisches melodisches Merkmal, wodurch sie sich von anderen Konfigurationen unterscheidet. Die Anzahl dieser melodischen Grundeinheiten ist beschränkt: Niederländisch und Englisch unterscheiden sechs solcher Konfigurationen, im deutschen Model! unterscheiden wir fünf.
Aus einem Vergleich der Muster geht hervor, daB es in den drei Sprachen ähnliche Melodisierungen gibt. Nur die Ausprägung einerkonkreten Kontur ist anders, wei! für jede Sprache spezifische Werte für Dauer, Position und Frequenzumfang geiten.
Abbildung 5.3 zeigt, wie eine sehr oft verwendete Konfiguration in den einzelnen Sprachen realisiert wird. In 5.3a sind eine deutsche (D) und eine niederländische (N) Kontur dargestellt, Abbildung 5.3b gibt eine deutsche und eine englische (E) Kontur wieder. Jede Kontur enthält zwei Tonhöhenakzente. Die Vokalanfänge der entsprechenden Silben sind durch VA 1 und VA 2 markiert. Die Deklination wird hier nicht berücksichtigt.
Für die Steigungen in diesen Konturen gibt Tabelle 5.2 die sprachspezifischen Werte für Dauer, Frequenzumfang und Position in bezug auf den Vokal der akzentuierten Silbe wieder.

104 5. Diskussion
a
VA1 VA2
VA1 VA2
Abbildung 5.3: Eine deutsche (D) und eine niederländische {N} Kontur (a}; eine deutsche (DJ und eine englische {E) Kontur'(b). Jede Kontur enthält zwei Tonhöhenakiente. Die Vokalanfänge der akzentuierten Silben sind durch VA 1 und VA 2 markiert. Die Deklination ist nicht dargestellt.
Tabelle 5.2: Die Dauer, die Position und der Frequenzumfang der Steigung, die sich am Vokalanfang einer akzentuierten Silbe orientiert, in den drei melodischen Modellen {siehe Abbildung 5.3). Die Position ist spezifiziert durch den infangspunkt der Steigung {in ms) vor dem Vokalanfang und den Endpunkt (auch in ms) nach dem Vokalanfang.
Dauer (ms) Position Frequenzumfang {HT) Deutsch 180 - 60, +120 7.5 Niederländisch 120 - 70, +50 6 Englisch (1. Akz.) 80 -40, +40 6 Englisch (2. Akz.) 80 - 80, 0 6

5.3. Deutsche, niederländische, englische Intonation im Kontrast 105
Der Teil der Steigung, der vor dem Vokalliegt, wird mit "-" markiert, der Teil nach dem Vokalanfang erhält ein "+"-Zeichen. Für das Englische werden zwei Positionen angegeben (erster und zweiter Akzent), da die Position der zwei Steigungen versebieden ist.
Vergleichen wir zunächst die deutsche und die niederländische Kontur (Abbildung 5.3a). In beiden Sprachen wird der zweite Akzent so gebildet, wie der erste: eine Steigung, ein kurzes Stück hoher Deklination und eine Senkung. Aus der Tabelle geht hervor, daB die Steigungen im Deutschen und im Niederländischen etwa gleichzeitig anfangen. Das Niederländische erreicht den Gipfel bereits 50 ms nach dem Vokalanfang. lm Deutschen liegt der Gipfel weitere 70 ms später, also 120 ms nach dem Vokalanfang. Dementsprechend fängt die nachfolgende Senkung später an und erreicht, auch wegen der gröBeren Dauer, die untere Deklinationslinie erheblich später (130 ms) als im Niederländischen.
lm deutsch-englischen Vergleich (Abbildung 5.3b) fällt zunächst auf, daB die englische Kontur auf der mittleren Ebene anfängt. Der Gipfel liegt deshalb bei einem Frequenzumfang von 6 HT urn 4.5 HT höher als im Deutschen. AuBerdem liegen Steigung und Senkung des zweiten Akzents früher in der Silbe als im ersten Akzent.
Im Unterschied zum Deutschen fängt die Steigung des ersten Akzents später an und erreicht den Gipfel früh in der Silbe, 40 ms nach dem Vokalanfang. Im Deutschen tritt der Gipfel später auf und er ist auBerdem niedriger.
Der zweite Akzent der englischen Kontur verstärkt den Unterschied in Gipfelposition. In diesem Fall fängt die Steigung so früh an (- 80 ms), daB ihr Ende dem Vokalanfang entspricht.
Ein wesentlicher Unterschied zwischen Deutsch einerseits und Niederländisch und Englisch anderseits ist somit, daB in den beiden letzteren Sprachen der Gipfel eines Tonhöhenakzents relativ früh in der Silbe erreicht wird, während im Deutschen der Gipfel später auftritt.
6.3.5 Die wichtigsten Unterschiede
Die wichtigsten Unterschiede, diewirhier oben im Vergleich zwischen den melodischen Modellen für das Deutsche, Niederländische und Englische gesehen haben, betreffen folgende Punkte:

106 5. DiskUBSion
• Für jede Sprache gibt es einen spezifischen Deklinationsverlauf.
• Das englische Intonationssystem unterscheidet drei Stufen gegenüber zwei Ebenen im Deutschen und Niederlä.ndischen.
• Im Englischen sind die Tonhöhenbewegungen steiler (75 HT /s) als im Niederlä.ndischen (50 HT/s) und im Deutschen (42 HT/s).
• Die Tonhöhenbewegungen haben unterschiedliche Dauerwerte (im Deutschen 180 ms, im Niederlä.ndischen 120 ms und im Englischen 80 ms / 160 ms).
• Die Tonhöhenbewegungen haben unterschiedliche Frequenzumfä.nge (im Deutschen 7.5 HT, im Niederlä.ndischen 6 HT und im Englischen 6 oder 12 HT).
• Der Tonhöhengipfel in akzentuierten Silben tritt im Deutschen spä.ter auf (circa 70 ms) als im Niederlä.ndischen und im Englischen.
Wie wir bereits im vorigen Kapitel gezeigt habe, ergeben sich aus den unterschiedlichen akustischen Spezifizierungen einer Kontur auch Konsequenzen für die Perzeption. Hörer beurteilen deutsche ÄuBerungen, die mit einer deutschen Kontur versehen sind, signifikant besser als dieselbe ÄuBerung mit einer niederlä.ndischen oder englischen Kontur.
Bei der Beurteilung im Experiment können die oben genannten akustischen Unterschiede in mehr oder minderem MaBe eine Rolle gespielt haben, bis auf zwei Faktoren:
1. Im Experiment waren die drei Standardkonturen SD, SN und SE mit derselben Deklination versehen.
2. Die unterschiedlichen Geschwindigkeiten der Totihöhenbewegungen dürften perzeptiv kaum ins Gewicht fallen, da diese Unterschiede nicht wahrnehmbar sind (siehe S. 41/42).
Für die wahrgenommenen Unterschiede scheint mir die jeweilige Position des Gipfels von besonderer Bedeutung zu sein. In den Modellen der drei Sprachen gibt es Tonhöhenbewegungen, die sich nur in bezug auf die Position (manchmal nur geringfügig) voneinander unterscheiden. Im

5.4. Anwendungen 107
deutschen Modell liegen die Steigungen AOST3 und + AOST3 beispielsweise nur 60 ms auseinander. Wenn nun innerhalb der einzelnen Sprachen die Notwendigkeit besteht, solche subtile, aber wahrnehmbare Unterschiede zu berücksichtigen, dann können auch die Unterschiede in der Positionierung des Gipfels (50 ms) bei der Beurteilung der Akzeptabilität eine wesentliche Rolle gespielt haben.
5.4 Anwendungen
Die vorliegende Untersuchung beschreibt die für die Wahrnehmung relevanten Grundfrequenzä.nderungen der deutschen Intonation in vorgelesenem Text und, darauf aufbauend, ein Modell, das zeigt, wie das Deutsche in intonativer Hinsicht strukturiert ist. In diesem Abschnitt gehen wir auf einige Anwendungen des Intonationsmodells ein.
6.4.1 Ein Intonationskurs
Die melodische Beschreibung des Deutschen in Form gerader Linien könnte die Grundlage für einen Intonationskurs bilden. Einen sokhen Kurs gibt es bereits für das Niederlä.ndische (Collier und 't Hart, 1981), Vararbeiten zu einem kontrastiven Intonationskurs Niederländisch-Englisch hat Willems (1982) bereits geleistet.
In einer Beschreibung der perzeptiv relevanten Merkmale der Intonation ist genau festgelegt, wie die einzelnen Tonhöhenbewegungen spezifiziert sind und wie die wichtigsten Konturen aussehen. Damit sind intanative Merkmale graphisch einfach darsteilbar und expliziter und leichter verstä.ndlich zu formulieren.
Eine zusätzliche Hilfe heim Erlernen der Intonation einer Sprache könnte in einer visuellen Rückmeldung bestehen. Der Lernende könnte seine eigene Melodiekurve mit einer vorgegebenen Kontur vergleichen und so seine Leistung korrigieren (de Bot, 1982).
6.4.2 Das DS-System
Eine weitere Anwendung der varliegenden melodischen Bescbreibung liegt auf dem Gebiet der Sprachsynthese. Dieses lntonationsmodell generiert

108 5. DÎllkussion
eine Vielzahl von natürlich klingenden Intonationskonturen, die akustisch vollständig und eindeutig spezifiziert sind. Im Beurteilungsexperiment aus Kapitel 4 haben wir die Konturen unter natürlich gesproebene Äu6erungen gelegt. Es ist aber auch möglich, eine synthetisch erzeugte Äu6erung, die aus diskreten Bausteinen wie ABophonen oder Diphonen besteht, auf diese Weise mit einer künstlichen aber natürlich klingenden Intonation zu versehen.
Im folgenden beschreiben wir an Hand zweier Beispiele, wie das hier präsentierte Intonationsmodell bei der Erzeugung künstlicher Sprache angewendet wird. Zum Schlu6 nennen wirnoch weitere Anwendungsmöglichkeiten.
Mit dem am IPO entwiekelten Programm DS ("Diphone Speech"), kann in drei Sprachen (Deutsch, Niederländisch und Englisch) mit Hilfe von Diphonen künstliche Sprache erzeugt werden (van Rijnsoever, 1988).
Das Programm ist ein Text-to-Speech-System, mit dem jeder beliebige Text hörbar gemacht werden kann. Dazu wird orthographischer Text (Grapheme) in eine Lautrepräsentierung (Phoneme) umgesetzt. Zu den Pbonemen werden die entsprechenden Lautbausteine (in diesem Fall LPCDiphone) gesucht und aneinandergereiht. Ein Dipbon wird aus natürlich gesprochenem Material geschnitten und reiebt etwa von der Hälfte des ersten Lautes bis zur Hälfte des zweiten Lautes. Durch diese Segmentierung wird der Lautübergang mit im Dipbon abgespeichert. Für die Synthese werden die entsprechenden Diphone konkateniert.
Für Deutsch, Niederländisch und Englisch gibt es eine oder mehrere Diphonbibliotheken, mit denen männliche Stimmen synthetisiert werden können. Für das Deutsche existiert au6erdem ein Diphoninventar, mit dem eine Frauenstimme erzeugt werden kann.
Nach der Konkatenierung wird die Zeitstruktur der aneinandergereihten Diphone angepaBt. Schlie6lich wird die geeignete Intonation hinzugefügt. In Abbildung 5.4 sind die einzelnen Schritte an Hand eines Beispiels veranschaulicht.

5.4. Anwendu.ngen
GRAPHEME
t PHONEME
t Dl PHONE
t ZE I T AN PASS U NG
INTONATION
AUSGABE
109
eine 'Stilisierung
SI \ GS * AI N E \ SCH T IE L IE ' Z * IE R U NQ \ SI
si1gs1 gs1ai1 ai1n1 n1el e1sch1 sch1t1 t1ie1 ie111 11ie1 ie1z1 z1ie1 ie1r1 r1u1 ulnq1 nq1si1
Phonem SI GS AI N E SCH T IE L IE z IE R u NO SI
Re1ativ(\) 167
33 37 55 56 41 43 31 18 36 48 57 20 67 61
200
Absolut(ms) 100
20 132
82 83
103 65 68 41 72 82
107 34
107 104 100
1-. -...... ]'... )'..
Abbildung 5.4: Die einzelnen Bchritte bei der Umsetzung von Text m gesprockene Sprache im Programm DS.

110 5. Diskussion
Im weiteren beschränken wir uns auf unseren Beitrag zum System, die lntonationssteuerung im Deutschen.
Die lntonationssteuerung im Deutschen Urn eine DS-ÄuBerung mit einer passenden Intonationskontur ZU versehen, muS der Benutzer im orthographischen Text intonative Markierungen anbringen. Dazu stehen ihm drei Zeichen zur Verfügung:
1. Ein Anführungszeichen (') generiert in der Kontur einen Tonhöhenakzent.
2. Ein Komma(,) markiert eine prosodische Grenze durch eine Kontinuierung.
3. Ein Fragezeichen (?) ruft am Ende einer ÄuBerung eine Steigung hervor.
An Hand dieser Zeichen wird für jede ÄuBerung automatisch die entspreebende Kontur errechnet. Im folgenden bespreche ich, wie diese Intonationsmarkierungen in konkreten Konturen realisiert werden.
1. Wenn die ÄuBerung ausschlieBlich Akzentmarkierungen enthält, werden Konturen generiert wie in Abbildung 5.5.
Bei zwei und drei Akzenten sind jeweils zwei Varianten abgebildet. Welche Kontur realisiert wird , ist vom Abstand zwischen den beiden Akzenten abhängig. Beträgt der Abstand weniger als 400 ms so wird Variante (a) angewählt, ist der Abstand gröBer, fällt die Wahl auf Kontur (b).
2. Sollen in einer ÄuBerung eine oder mehrere prosodische Grenzen vorkommen, so muB der Benutzer ein Komma eingeben. Akzentmarkierungen vor einem Komma werden immer als Steigung mit einer folgenden graduellen Senkung realisiert (Abbildung 5.6) .
Nach einem Komma wird auBerdem eine Pause von 250 ms eingefügt. Ferner erfolgt ein Deklinationsreset. Das heiBt, daB die Kontur auf der Anfangsfrequenz der ÄuBerung fortgesetzt wird.
Ein Komma teilt einen Satz in Phrasen auf. Die obige Beschreibung gilt für jede Phrase, die mit einem Komma endet. Die letzte Phrase endet

5.4. Anwendungen
1 Akzent
2 Akzente
3 Akzente ... . . . . . . . . ......
lll
Abbildung 5.5: Konturen, die in DS generiert werden, wenn die ÄujJerung ausschliejllich Akzentmarkierungen enthält. Die Deklination ist nicht dargestellt.
Abbildung 5.6: Beispiel einer Kontur, die zwei Tonhöhenakzente enthält und mit einer Kontinuierung endet. Die Deklination ist nicht dargestellt.
jedoch nicht mit einem Komma. In diesem Fall werden die Akzentmarkierungen realisiert wie unter (1.), vorausgesetzt amEnde des Satzes steht kein Fragezeichen.
3. Wird eine ÄuBerung mit einem "?" abgeschlossen, so tritt am Ende der ÄuBerung eine Steigung mit einem Frequenzumfang von 12.5 HT auf. Akzentmarkierungen werden durch eine Steigung mit anschlieBender gradueller Senkung bis zur nächsten Steigung realisiert (Abbildung 5.7).

112 5. Diskussion
Abbildung 5.7: Beispiel einer Kontur mit emem Tonhöhenakzent und einer Steigung amEnde der ÄujJerung. Die Deklination ist nicht :dargestellt.
In den Abbildungen dieser Konturen ist die Deklination nicht berücksichtigt worden. In konkreten Konturen beträgt die Anfangsfrequenz der Männerstimme 114 Hz und die Endfrequenz 70 Hz. Die Kontur der Frauenstimme liegt etwa eine Oktave höher.
Mit diesen drei lntonationsmarkierungen kann nur ein Teil der melodischen Möglichkeiten, die wir im vorigen Kapitel hesebrieben haben, realisiert werden. Urn alle vorkommenden Variantengenerieren zu können, ist eine Erweiterung der lntonationsmarkierungen notwendig.
Im folgenden gehen wir auf eine weitere Anwendung ein.
6.4.3 Das SPICOS-System
"SPICOS" ist ein gemeinsames Projekt von Siemens München, Philips Hamburg und Brüssel sowie dem IPO. In diesem Projekt wird am Beispiel des Deutschen untersucht, wie Spracheingabe und -ausgabe in der Kornmunikation mit einem Computer eingesetzt werden können. Dazu wurde ein experimentelles System entwickelt, das eine gesproebene Frage erkennt, die entsprechende Aowort sucht, und sie mit Hilfe der hier oben hesebriebenen Dipbonsynthese hörbar macht. Die Fragen, die gestellt werden können, beziehen sich ausschlieBiich auf das Projekt. Das System kann auch Rückfragen stellen, wenn es eine zusätzliche lnformation vom Benutzer braucht.
Hier beschränken wir uns auf die Sprachsynthese, deren erste Ergebnisse in van Hemert, Adriaens-Porzig und Adriaens (1987) veröffentlicht wurden.
Die Sprachausgabe im SPICOS-Projekt erfolgt auf der Grundlage eioer Diphonsynthese. In der SPI COS-Version werden die Intonationsmarkierungen automatisch gesetzt. Dazu werden versebiedene Informa:.

5.4. Anwendungen 113
tionen benötigt. Für die Tonhöhenakzente greift SPICOS auf ein Lexikon zurück, in dem die Akzentsilben aller Inhaltsworte gespeichert sind. Wenn eine Antwort mit "ja" oder "nein" anfängt, so wird nach diesem Einleitungswort eine Kontinuierung mit anschlieBender Pause {250 ms) realisiert. Eine Rückfrage {mit einer Steigung am Ende der Äuf3erung) stellt das System, wenn es im Dialogteil Ambiguitäten begegnet.
Auf die Frage: "Hat Höge an Nooteboom geschrieben?" antwortet das System beispielsweise: "Ja, Höge hat an Nooteboom geschrieben." (Abbildung 5.8). Diese Antwort kann sowohl mit einer männlichen als auch mit einer weiblichen Stimme ausgegeben werden. Im folgenden ist die Intonationskontur dieser Antwort dargestellt. Für die Synthese wurde die Frauenstimme verwendet.
/ V t- r- _"....... -/ -r- ~ ~"" 1---
JA, 'HOEGE BAT AN 'NOOTEBOOM GE'SCBRIEBEN
t (s)
Abbildung 5.8: Beispiel einer Intonationskontur, wie sie im SPICOSSystem generiert wird. Die Äujlerung enthält eine Kontinuierung und drei Tonhöhenakzente . Die senkreekten Linien stellen Dipkongrenzen dar.
In der Kontur erscheint auf "ja" eine Kontinuierung und Tonhöhenakzente auf "Höge", "Nooteboom" und "geschrieben".
Zur Akzentuierung ist folgendes zu bemerken. Zunächst entspricht die Strategie, die alle Inhaltsworte berücksichtigt, wohl nicht dem, was Sprecher machen. SPICOS erzeugt rnanebmal zuviele Akzente. Im System sind semantische und syntaktische Informationen vorhanden, so daB es Möglichkeiten gibt, aufgrund dieser Informationen die Anzahl der Akzente zu reduzieren.
Kontrastakzente werden in bestimmten Satzkonfigurationen verwendet, wie zum Beispiel in "Es GIBT keine Briefe".

114 5. Diskussion
5.5 Offene Fragen
Aus der hier präsentierten melodischen Beschreibang des Deutschen ergibt sich eine Reihe von offenen Fragen. Einige nennen wir im folgenden:
• Die Untersuchung bezieht sich auf vorgelesenen Text. Das hei6t, daB etwaige intonative Charakteristiken des Deutschen, die typisch für spontane Sprache sind, nicht erfaBt werden. Wie kann beispielsweise die Rufintonation perzeptiv adäquat im Deutschen charakterisiert werden?
• Die ÄuBerungen, die wir im Perzeptionsexperiment in Kapitel 4 verwendet haben sind relativ kurz. Zwar wurden auch lange und komplexe Äu6erungen in der Untersuchung berücksichtigt, sie wurden aber nicht einer perzeptiven Evaluierang unterzogen. Es ist also noch zu klären, ob dieses Intonationsmodell auch in langen Äu6erungen problemlos angewendet werden kann.
• Im Experiment in Kapitel4 wurden nur einzelne ÄuBerungen getestet. Somit bleibt ungeklärt, wie sich dieses Intonationsmodell in einem Text verhält. Kann beispielsweise in jeder Äu6erung eines Textes dieselbe Deklination verwendet werden? Die Frage ist also, ob es so etwas wie eine "Textintonation" gibt, die von einer "Satzintona.tion" abweicht. Wenn ja, worin bestehen dann für das Deutsche die Anpassungen?
• lm Experiment in Kapitel 4 haben wir Standardkonturen getestet. Diese Konturen orientieren sich an Kopiekonturen von in der Wirklichkeit beobachteten Grundfrequenzkurven. Es ist noch zu prüfen, ob Standardkonturen, die das Modell generiert, die aber nicht beobachteten Kopiekonturen entsprechen, auch akzeptabel sind. Ebenso ist zu .untersuclien, ob es im Deutschen akzeptabele Konturen gibt, die das Modell nicht generieren kann.
• Die vorliegende Untersuchung beschränkte sich ausschlie6lich auf die Beschreibang der perzeptiv relevanten Grundfrequenzänderungen im Deutschen. Selbstverständlich muS ein umfassendes Intonationsmodell einen integrativen Charakter haben und auch linguïstische Aspekte berücksichtigen. Dazu gehören Fragen wie:

5.5. Offfine Fragen 115
• N ach welchen Regularitäten richtet si eh die Akzentuierung im Satz?
• Welche Phrasengrenzen werden durch Tonhöhenbewegungen markiert und welche werden durch Resets angegeben?
• Welche Funktionen sind mit bestimmten Tonhöhenbewegungen oder Konturen verbunden und welche Faktoren bestimmen ihre Auswahl?
In der vorliegenden Arbeit wurden die für die Wahrnehmung relevanten Grundfrequenzä.nderungen in vorgelesenem Text untersucht und dara.uf aufba.uend ein melodisches Modell entwickelt. Dieses Modell bietet die Grundlage für die Erforschung der obenstehenden Fragen.

116 5. D~skuBBion

Anhang A
In Kapitel 3 wurde untersucht, ob natürliche Grundfrequenzkurven und Kopiekonturen als perzeptiv gleich gelten können.
In Anhang Al ist der Text der Einführung wiedergegeben, die dem Experiment voranging. In Anhang A2 sind die Grundfrequenzkurven und die entsprechenden Kopiekonturen der verwendeten Äu6erungen visuell dargestellt.
Al Einführung zum Vergleichstest
Im folgenden Experiment geht es urn künstliche Sprache, das hei6t, Sprache, wie sie von einem Computer produziert wird. Künstliche Sprache weist im Vergleich zu natürlicher Sprache zwar einen erheblichen Qualitätsunterschied auf, sie ist aber durchaus verständlich. Urn die Unterschiede aufzuzeigen, hören Sie zwei Beispiele. Zunächst hören Sie den Satz "Vater wil! sich eine Pfeife anzünden" als natürliche Äu6erung und anschlie6end die synthetische Version.
• "Vater will sich eine Pfeife anzünden" (2x)
Wiederholung:
• "Vater wil! sich eine Pfeife anzünden" (2x)
Als zweites Beispiel hören Sie den Satz "Gestern stürmte es noch", zuerst natürlich, dann künstlich.
• "Gestern stürmte es noch" (2x)
Wiederholung:
• "Gestern stürmte es noch" (2x)
117

118 An.bang A
Im folgenden Test werden deutsche ÄuBerungen pa.a.rweise präsentiert. Beide ÄuBerungen sind entweder völlig gleich oder weisen geringe Unterschiede auf. Dabei handelt es sich immer urn intonative Unterschiede, das heiBt, daB die Tonhöhenverläufe der ÄuBerungen versebieden sind. Urn Ihnen einen Eindruck zu vermitteln, was Intonation ist, hören Sie die ÄuBerung "Hier gibt es Konserven" zunächst mit natürlicher lntonation, dann ohne jegliche Tonhöhenänderung, also monoton.
• "Hier gibt es Konserven" (2x)
Wiederholung:
• "Hier gibt es Konserven" (2x)
Als weiteres Beispiel hören Sie die ÄuBerung "Hans iBt so gerne Wurst" zunächst mit dem ursprünglichen Tonhöhenverlauf, anschlieBend mit einer etwas höheren lntonation.
• "Hans iBt so gerne Wurst" (2x)
Wiederholung:
• "Hans iBt so gerne Wurst" (2x)
Im folgenden Beispiel "Heute ist schönes Frühlingswetter" sind die Unterschiede so klein, daB Sie sie vielleiebt gar nicht hören.
• "Heute ist schönes Frühlingswetter" (2x)
Wiederholung:
• "Heute ist schönes Frühlingswetter" (2x)
Im AnschluB an diese Einführung folgt der Test. Sie hören 80 ÄuBerungen, die in 40 Pa.a.ren dargeboten werden. Bitte vergleichen Sie jeweils die zwei ÄuBerungen und kreuzen Sie im Testantwortbogen an, ob Sie einen Unterschied gehört haben oder nicht. Denken Sie daran, daB etwaige Unterschiede nur die lntonation betreffen.
Eine Sekunde vor jedem Paar hören Sie ein kurzes Signa!. Nach jedem Paar haben Sie etwa 7 Sekunden Zeit für lhre Antwort. Den Text der ÄuBerungen finden Sie im Testantwortbogen, damit Sie sich besser auf die Intonation konzentrieren können.
Sollte noch etwas unklar sein, dann zögern Sie hitte nicht, jetzt zu fragen.
Viel Erfolg und vielen Dank für Ihre Mitarbeit!

AnhangA
A2 Grundfrequenzkurven und Kopiekonturen
Im Experiment wurden folgende zehn ÄuBerungen verwendet:
1 Wer triokt einen Kaffee? 2 Gib mir hitte die Butter. 3 Hier gibt es Konserven. 4 Vater hat den Tisch gedeckt. 5 Hans iBt so gerne Wurst. 6 Heute ist schönes Frühlingswetter. 7 MuB der Zucker nicht dort drüben stehen? 8 Vater will sich eine Pfeife anzünden. 9 Messer und Gabelliegen neben dem Teller. 10 Der gelbe Küchenofen sorgt für Wärme.
119
Im folgenden sind für jede TestäuBerung die Grundfrequenzkurve (gepunktete Linie) und die entsprechende Kopiekontur (durchgezogene Linie) wiedergegeben.
> ::>
500
~00
300
-;:; E
200
0 / u. . 100
5~~. 0----------0.-3--------~0~.6~~--~~0~.9~~--~~1.72--------~1.5 t (s)
1 Wer trinkt einen Kaffee?

120 Anhang A
> => soo
•oo 300
"N ~
200
0 ..... 100
so~--------~--~------~--------------------------~------4 0.0 ·0.3 0.6 0.9 1.2 1.5
t (s)
2 Gib mir hitte die Butter.
> => - ----soo
•oo 300
"N ~
200
0 ~ ~ ..... ~ :.r:-:
~w 100
~
50 0.0 0.3 0.6 0.9 1.2 1.5
t (s)
3 Hier gibt es Konserven.
> => soo
•oo 300
"N ~
200
~"---/'>...,
0 ..... ~ 100 ~
'-----so
0.0 0.3 0.6 0.9 1.2 1.5
t (s)
4 Vater bat den Tisch gedeckt.
Anhang A 121
> ::> 500
400
300
-;:; 200 ~
/ ' ~
0 u_
100
50~~----~----~~--~~--~~----~----~----~----------4 0 . 0 0.4 0.8 1.2 1.6
t (s)
ó Hans iBt so gerne Wurst.
> ::>
500
400
300
-;:; ~
200
~ 0 / u_
100
50 0.0 0.4 0.8
t (s)
6 Heute ist schönes Frühlingswetter.
> ::>
-;:; ~
0 u_
500
400
300
200
100 ~ /~ .. ,
1.2 1.6
~ ~
2.0
2 . 0
5~~.-o~----~--0-.4----------o~.~B~--~----~-.2~--------~~~. 6~--~----2~.0
t (s)
7 MuB der Zucker nicht dort drüben stehen?

122
> :::>
&00
•oo 300
'N 200 ~
0 LL.
100
t (s)
8 Vater will sich eine Pfeife anzünden.
> :::>
500
•oo 300
'N ~
200
0 LL. / "-100
. ···.·
50 0 . 0 o.• 0.8 1.2
t (s)
g Messer und Gabelliegen neben dem Teller.
> :::>
'N ~
0 LL.
500
•oo 300
200
'-....( 100
~ .......
~ ~
Anhang A
1.6 2.0
50~----~------~----~------~------------~----~--------~ 0.0 0 . 5 1.0 1.5 2.0 2 . 5
t (s)
10 Der gelbe Küchenofen sorgt für Wärme.

Anhang B
In Kapitel 4 wurde die Akzeptabilität von 12 deutschen Äu6erungen untersucht, jeweils in vier intonativen Versionen. Jede ÄuBerung wurde mit (1) einer Kopiekontur, (2) einer deutschen, (3) niederländischen und (4) englischen Standardkontur versehen.
Dem Experiment ging eine Einführung voran (siehe Anhang B1). In Anhang B2 sind die verwendeten Kopiekonturen sowie die deutschen Standardkonturen graphisch wiedergegeben; die niederländischen und englischen Standardkonturen liegen als Transkription vor.
Bl Einführung zum Akzeptabilitätstest
Im folgenden Experiment geht es urn die intonativen, das heifit die melodischen Merkmale der deutschen Sprache. Sie hören natürlich gesproebene Äu6erungen, die mit Hilfe eines Computers mit versebiedenen Intonationsverläufen versehen wurden.
Ihre Aufgabe besteht darin, auf einer Skala von 1 bis 10 anzugeben, wie gut Ihnen die Intonation einer Äu6erung gefällt.
• 10 bedeutet "sehr gut"
• 1 bedeutet "sehr schlecht"
Jede Äu6erung hören Sie zweimaL Nach jedem Paar haben Sie etwa 3 Sekunden Zeit für lhre Bewertung. Bit te ändern Sie die einmal getroffene Entscheidnog nicht mehr. Eine Sekunde vor jedem Paar hören Sie ein kurzes Signa!. Den Text der Äu6erungen finden Sie im Testantwortbogen.
lch möchte noch darauf hinweisen, daB sich die Qualität der natürlich gesproehenen ÄuBerungen durch die Computermanipulation zum Teil erheblich verschlechtert hat. Diese künstliche Sprache ist aber dennoch gut
123

124 Anhang B
verstä.ndlich. Versuchen Sie hitte NUR die lntonation zu beurteilen und nicht die verschlechterte Sprachqualitä.t der ÄuBerungen.
Damit Sie sich einhören können, spiele ich Ihnen einige Beispiele aus dem Test vor.
Sollte noch etwas unklar sein, dann zögern Sie hitte nicht zu fragen. Viel Erfolg und vielen Dank für Ihre Mitarbeit !
B2 Die Konturen des Akzeptabilitätsexperiments
Folgende 12 ÄuBerungen mit den entsprechenden lntonationsmustern wurden im Experiment verwendet:
1 Gestern stürmte es noch. (a) 2 Vater will sich eine Pfeife anzünden. (a) 3 Wir wollen heute spazieren gehen. (a) 4 Hier gibt es Konserven. (b) 5 Heute ist schönes Frühlingswetter. (b) 6 Zum SchluB an die Kasse. (b) 7 Wer möchte noch Milch? (c) 8 Wer trinkt einen Kaffee? (c) 9 Wer mu6 noch Schularbeiten machen? (a}(c) 10 MuB der Zucker nicht dort drüben stehen? (a)(c) 11 Dabinter liegt der Rosengarten. {d)(e)(a) 12 Der gelbe Küchenofen sorgt für Wä.rme. (a)(d)(e)(b)
Im weiteren ist für jede Testäu6erung die Kopiekontur (gepunktete Linie) und die deutsche Standardkontur {durchgezogene Linie) graphisch dargestellt. Die deutsche Standardkontur (SD) ist zusätzlich in transkribierter Form wiedergegeben. Die niederlä.ndischen (SN) und englischen (SE) Standardkonturen werden nur in der Transkription präsentiert.
Die Kodes der niederländischen Tonhöhenbewegungen stammen aus 't Hart und Collier (1975), die Kodes der englischen Tonhöhenbewegungen wurden Willeros et al. (1988) entnommen.
Akzentuierte Silben werden durch Gro6buchstaben angegeben, eine Kontinuierung wird durch "/" markiert.

AnhangB 125
> :::>
"N ~
0 LL
> :::>
"N ~
0 LL
500
400
300
200
~
100
50 0.0
1 Gestern SD SN SE
500
400
300
200
:.:.:.:.:..:..:
0.3 0 . 6 0.9
t (s)
STÜRMte es noch . AOST3 +A3SEO
lA -2R4 AFO
/~"""" --....... 100
1.2 1.5
50~--~--~------~------~~--~--------------~~ 1.2 1.6 2 . 0 0 . 0
2 SD SN SE
0.4
VAter will sich eine AOST3 3GSEO
1 D ~2R4 FF2
0.8
t (s)
PFEife anzünden. ~ OST3 +A 3SEO
lA -R4 ~FO
126
> ::>
500
•oo lOO
-;:; 200 E
0 ... 100
50 0 . 0
3 SD SN SE
> :::>
500
•oo lOO
-;:; 200 E
0 ... 100
60 0.0
.. ··· ..
~-
0.4
Wir WOLlen AOST3 3GSEO
lD A2R4 FF2
········ ·
0 . 3
~ '
'
0.8 1.2
t (s)
HE U te spaZIEren AOST3 A3ST4 A4SEO
1 5A A2R4 FF2 +R5 A+FO
~~ ······ .. ~ ..
0 . 6 0.9
t (sl
· 4 Hier gibt es KonSERven. SD - A OST3 A 3SEO SN A SE -2R4 AFO
Anbang B
1.6 2.0
gehen.
1.2 1.5

Anhang B
> ::>
'N ~
0 u.
> ::>
'N ~
0 u.
500
400
300
200
/' 100
50 0.0
~
0.4 0.8
~· .. ~
t (s) !.2
5 HEUte ist schönes FRÜHiingswetter. SD AOST3 3GSEO -AOST3 A3SEO SN 1 A SE A2R4 FF2 -R4 AFO
500
400
300
200
/ =..... ·~
~ -100 .
·.
50 0.0 0 . 3 0.6 0.9
t (s)
6 Zum SCHLUSS an die KASse. SD AOST3 A3SEO SN 1 A SE AOR2 AFO
127
!.6 2 . 0
~
!.2 !.5

128 Anhang B
> :::>
500
400
300
"N 200 e 0
LL ~ 100
&0 0.0 0.3 0.6 0.9 1.2 1.5
t (s)
7 Wer möchte noch Milch? SD *OST5 SN 2 SE AOR2 *R4
> :::>
500
400
300
·····
"N 200 E
~~ ~ 0 ~ LL .
100 --- ·····
60 0.0 0 .3 0.6 0.9 1.2 1 . 5
t (s)
8 WER triokt einen Kaffee? SD AOST3 3GSEO *OST5 SN 1 D 2 SE OR2 AFO *R4

Anhang B 129
> ::>
-;:; ~
0 I.L
> ::J
500
400
300
200
~ ----····· 100
50 0 . 0 0.3 0.6 0.9 1.2 1.5
t (s)
9 WER mu6 noch SCHULarbeiten mach en? SD 4 0ST3 4 3ST4 4 4SEO *OST5 SN 1 5A 2 SE 4 2R4 FF2 +R5 4 +FO *R4
500 ,...-~~-~~-~~~-~~-~~~-~--~~"1
400
300
N 200 ~
0 I.L
/. 0 .····· -........ ~ ·· ... 100
50~--~------~---------~-------------~ 0.0 0 . 4 0 . 8 1. 2 1.6 2 . 0 '
10 SD SN SE
Mu6 der ZUCker 4 OST3 +A 3SEO
1 2R4 AF2
t (s)
nicht dort DRÜben stehen? AOST3 *3ST5
D 3 D 2 - R4 AFO *R4

130
> :::>
-;:; 3
0 ...
> :::>
-;:; 3
0 ...
Anhang B
~00
400
300
200
100 ~~~ ......... .. ç<~··. .... ·· ~--- = .. ·········· -50
0 . 0 0.~ 0 . 8 1.2 1.6 2.0
t (s)
11 DaRINter I liegt der ROsengarten. SD +AOST3 •3GSEO AOST3 +A3SEO SN 3 B lA SE AOR4 -2R4 AF O
!00 ,__.....:..--.=...-=:............~-=:....._-=--...:._=-~~~--~~~-l
400
soo
200
. 100
50~--~~--~----------~----~----~~~~----~ o.o 0 . 5 1.0 1.5 2.0 2.5
12 Der SD SN SE
GELbe AOST3
1 A2R4 FF2
t (s)
KÜchen- ofen I sorgt für W ÄRme. A3ST4 A4SEo •osT3 *3GSEo -AOST3 A3SEo
5A 2 B lA +R5 AFO ·R4 -2R4 AFO

Literatur
Adriaens, L.M.H. (1984) "A preliminary description of German intonation", !PO Annual Progress Report 19, 36~41.
Bannert, R. (1983) "Modellskizze für die deutsche lntonation", Zeitschr. f. Literaturwissenschaft und Linguistik 52, 9-34.
de Bot, C.L.J. (1982) Visuele feedback van intonatie, Dissertation, Universität Nijme~en.
Bouma, H. (1979) "Perceptual functions", in: Handbook of psychonomics, herausgegeben von J.A. Michon, E.G.J. Eijkman und L.F.W. de Klerk (North-Holland, Amsterdam), 427-531.
Bruce, G. (1977) Swedish word accentsin sentence perspective (Gleerup, Lund).
Carlson, R. und B. Granström (1976) "A text-to-speech system based entirely on rules", Proc. IEEE ICASSP, Philadelphia, 686-688.
Carlson, R., B. Granström und S. Hunnicutt (1982) "A multi-language text-to-speech module", Proc. IEEE ICASSP, Paris, 1604-1607.
Cohen, A. und J. 't Hart (1967) "On the anatomy of lntonation", Lingua 19, 177-192.
Collier, R. (1972) From pitch to intonation, Dissertation, Universität Leuven.
Collier, R. und J. 't Hart (1971} "Perceptual experiments on Dutch in-
131

132 Literatur
tonation", Proc. of the Seventh ICPhS, Montreal, 880-884.
Collier, R. und J. 't Hart (1981) Cursus Nederlandse Intonatie (Acco, Leuven).
Delattre, P., E. Poenack und C. Olsen (1965) "Some characteristics of German intonation for the expression of continuity and finality", Phonetica 13, 134-161.
von Essen, 0 . (1964) Grundzüge der hochdeutschen Satzintonation (Henn Verlag, Rat in gen).
Flanagan, J.L. und M.G. Saslow (1958) "Pitch discrimination for synthetic vowels", J. Acoust. Soc. Am. 30, 435-442.
Fujisaki, H. und S. Nagashima (1967) "A model for the synthesis of pitch contours of connected speech", Annual Report, Eng. Res. Inst. Faculty of Engineering University of Tokyo 28, 53- 60.
Fujisaki, H. und Hirose, K. (1982) "Modelling the dynamic characteristics of voice fundamental frequency with application to analysis and synthesis of intonation", Proc. of the XIIIth Intern. Congress of Linguists, 57-70.
Grimme, H. (1925a) "Neuhochdeutsche Sprachmelodik als Grundlage der Syntax I", Germanisch- Romanische Monatsschrift 8, 274- 285.
Grimme, H. (1925b) "Neuhochdeutsche Sprachmelodik als Grundlage der Syntax 11", Germanisch-Romanische Monatsschrift 8, 328-350.
't Hart, J . (1976) "Psychoacoustic Backgrounds of Pitch Contour Stylisation", IPO Annual Progress Report 11, 11-19.
't Hart, J. (1981) "Differential sensitivity to pitch distance, particularly in speech", J. Acoust. Soc. Am. 69, 811-821.

Literatur 133
't Hart, J. und A. Cohen (1964) "Gating Techniques as an Aid in Speech Analysis", Lang. Speech 1, 22-39.
't Hart, J. und A. Cohen (1973) "Intonation by rule: a perceptual quest", J. Phon. 1, 309-327.
't Hart, J. und R. Collier (1975) "lntegrating different levels of intonation analysis", J. Phon. 3, 235-255.
't Hart, J ., R. Collierund A. Cohen (1990) A perceptual study of intonation: An experimental-phonetic approach to speech melody (Cambridge University Press, Cambridge).
't Hart, J., S.G. Nooteboom, L.L.M. Vogten und L.F. Willeros (1982) "Manipulations with speech sounds", Philips Techn. Rev. 40 (5), 134-145.
von Helmholtz, H. (1870) Die Lehre vonden Tonempfindungen (Vieweg, Braunschweig).
van Hemert, J.P., U. Adriaens-Porzig, L.M.H. Adriaens (1987) "Speech Synthesis in the SPICOS-project", in: Analyse und Synthese gesprachener Sprache, herausgegeben von H. G. Tillmann und G. Willée (Georg Olms Verlag, Rildesheim- Zürich- New York) , 34- 39.
Hess, W. (1983) Pitch Determination of Speech Signals (Springer Verlag, Berlin).
Isacenko, A.V. und H.J. Schädlich (1964) Untersuchungen über die deutsche Satzintonation (Akademie-Verlag, Berlin).
Jones, D. (1962) An outline of English phonetics (Heffer, Cambridge).
Klinghardt, H. (1923) Spreekmelodie und Spreektakt (N.G. Elwert'sche Verlagsbuchhandlung, Mar burg).

134 Literatur
Kohier, K. (1988) "An intonation model for a German text-to-speech system", Proc. 7th FASE Symposium, Edinburgh, 1241-1247.
Kuhlmann, W. (1931) Die Tonhöhenbewegung des Aussagesatzes (Carl Winters Universitätsbuchhandlung, Heidel berg).
Lehiste, I. (1970) Suprasegmentals (the M.I.T. Press, Cambridge, MALondon, England).
Lieberman, P. (1965) "On the acoustic basis of the perception of intanation by Jinguists", Word 21, 40-54.
Maeda, S. (1976) A characterisation of American English intonation, Dissertation, M.I.T., Cambridge, MA.
Mattingly, I. (1966) "Synthesis by rule of prosodie features", Lang. Speech 9, 1-13.
Odé, C. (1989) Russian lntonation: A Perceptual Description (Rodopi, Amsterdam- Atlanta, GA).
Öhman, S. (1967) "Word and sentence intonation: A quantitative model", STL-QPSR 2-3, 20- 54.
Pierrehumbert, J. (1981) "Synthesizing intonation", J. Acoust. Soc. Am. 70, 985-995.
de Pijper, J.R. (1983) Modelling British English lntonation (Foris, Dordrecht - Cinnaminson, RI).
Pollack, I. (1968) "Detection of rate of change of auditory frequency", J. Exp. Psych. 77, 535-541.
Pollak, H. W. (1910) "Zur SchluBkadenz im deutschen Aussagesatz", Sitzungsberichte der Philosphisch-Historischen Klasse der Kaiserlichen Akademie der Wissenschaften in Wien, 164, 1-62.

Literatur 135
van Rijnsoever, P.A. (1988) "A multilingual text-to-speech system", /PO Annual Progress Report 23, 34-40.
Siegel, S. (1956) Nonparametrie Statistics for the behaviaral sciences (Me Graw Hili Kogakusha, Tokyo) .
Sotschek, J. (1984) "Sätze für Sprachgütemessungen und ihre phonologischen Anpassungen an die deutsche Sprache", Tagungsband DAGA: Fortsckritte der Akustik, Darmstadt, 873-876.
Thorsen, N. (1980) "A study of the perception of sentence intonationevidence from Danish", J. Acoust. Soc. Am. 51, 1014-1030.
Vaissière, J. (1971) Contribution à la synthèse par règles du Français, Dissertation, Université de Grenoble.
Vogten, L.L.M. (1983) Analyse, zuinige codering en resynthese van spraakgeluid, Dissertation, TH Eindhoven.
Willems, N.J. (1982) English intonation from a Dutch Point of View (Foris, Dordrecht- Cinnaminson, RI).
Willems, N. , R. Collier und J. 't Hart (1988) "A synthesis scheme for British English intonation", J. Acoust. Soc. Am. 84, 1250- 1261.
Witten, LH. (1978) "A flexible scheme for assigning timing and pitch to synthetic speech", Lang. Speech 20, 240-260.
Zingle, H. (1982) Traitem ent de la prosodie allemande dans un système de synthèse de la parole, Thèse pour le Doctorat d'Etat, Université de Strasbourg 11.
Zwirner, E. und K. Zwirner (1937) "Über Hören und Messen der Sprachmelodie", Archiv für vergleichende Phonetik 1, 35-47.

136 Literatur

Zusammenfassung
Eines der auffallendsten Merkmale gesprochener Sprache ist, daB sich im Verlauf einer ÄuBerung die Tonhöhe fortwährend ändert. Akustisch manifestieren sich die Tonhöhenänderungen, die der Hörer wahrnimmt, als Grundfrequenzänderungen. Die vorliegende Arbeit untersucht, welche Grundfrequenzänderungen in vorgelesenem deutschem Text für die Wahrnehmung von Bedeutung sind. Die Ergebnisse werden in Form eines melodischen Modelis wiedergegeben.
Kapitell beschreibt die Methode. In einem ersten Schritt wird von einer Grundfrequenzkurve eine Kopiekontur angefertigt. Eine Kopiekontur und die entsprechende Originalkurve sind perzeptiv gleich, wo bei eine Kopiekontur aus der kleinst möglichen Anzahl perzeptiv relevanter Grundfrequenzänderungen besteht, repräsentiert durch gerade Linien. Aus dem Vergleich einer Vielzahl von Kopiekonturen wird ein melodisches Modell entwickelt.
Kapitel 2 gibt einen Überblick über die phonetische Literatur zur deutschen Intonation. In dieser Übersicht werden die wichtigsten Ergebnisse zusammengefaBt, gleichzeitig werden typische Probieroe diskutiert, die mit den versebiedenen Methoden der Intonationsforschung verbunden sind.
Kapitel 3 geht auf die Frage ein, wie aus einer Grundfrequenzkurve eine Kopiekontur ermittelt werden kann und welche Bedeutung ihr bei der Entwicklung eines melodischen Modelis zukommt. Ein Abschnitt befaBt sich mit der Perzeption der Kopiekontur und den versebiedenen Möglichkeiten ihrer Spezifizierung.
In einem Perzeptionsexperiment werden Grundfrequenzkurven und Kopiekonturen direkt miteinander verglichen. Es stellt sich heraus, daB Hörer die akustisch vorhandenen Unterschiede nicht wahrnehmen können. Eine Kopiekontur und die entsprechende Grundfrequenzkurve sind also tatsächlich perzeptiv gleich.
137

138 Zusammenfassung
Kapitel4 beschreibt ein melodisches Modell des Deutschen. Es bestebt aus standardisierten Deklinationslinien und standardisierten Tonhöhenbewegungen, sowie aus sequentiellen Regeln. Nach diesen Regeln können Standardkonturen gebildet werden .
In einem Experiment wird die Validität des melodischen Modelis überprüft. Dazu beurteilen deutsche Hörer die Akzeptabilität deutscher ÄuBerungen, die mit einer Kopiekontur sowie einer deutschen, niederländischen und englischen Standardkontur versehen sind. Die Ergebnisse zeigen, daB deutsche Hörer in bezug auf die Akzeptabilität keine Unterschiede zwischen den Kopiekonturen und den deutschen Standardkonturen wahrnehmen. Unterschiede zu den niederländischen und englischen Konturen sind signifikant. Der SchluB ist also gerechtfertigt, daB das Modell die für den Hörer relevanten Merkmale deutscher Intonation perzeptiv adäquat wiedergibt.
In Kapitel 5 werden die Ergebnisse der vorliegenden Arbeit den Erkenntnissen aus der phonetischen Literatur gegenübergestellt. Ferner wird das Modell der deutschen Intonation mit den entsprechenden Modellen des Niederländischen und des Englischen verglichen. Es werden Anwendungen des deutschen Modelis hesebrieben und einige offene Fragen diskutiert.

Summary
One of the most striking features of speech is that the pitch changes continuously in the course of an utterance. The pitch changes perceived by the listener correspond to changes of the fupdamental frequency in the acoustical signa!. This thesis investigates which changes of the fundamental frequency in read out German text are relevant to perception. The results are presented in a melodical model.
Chapter 1 describes the metbod used in this research. Taking a roeasured pitch curve as a starting point, a copy contour is made as a first step. A copy contour is perceptually equal to the original curve and consists of the least possible number of perceptually relevant pitch movements, visually represented as straight lines. On the basis of the comparison of a large amount of copy contours a melodical model is developed.
Chapter 2 gives an overview of the phonetic literature on Germa.n intonation and discusses typica.l probieros related to different methods of intonation research.
Cha.pter 3 describes how a. copy contour is made on the basis of a pitch curve a.nd considers its relevanee for the development of a melodical model. Furthermore the perception of the copy contour a.nd the different possibilities of its acoustical specification are discussed.
In a perception experiment pitch curves and copy contours are compared directly. The experiment shows that listeners are not able to detect the acoustically existing differences. Therefore we can conclude that a copy contour is indeed perceptually equal to a natura! pitch curve.
Chapter 4 proposes a melodical model for German. It consiste of standardized declination lines, standardized pitch movements and rules of sequence. Pitch contours cao be formed according to these rules.
In an experiment the validity of the model is investigated. German listeners judge the acceptability of German utterances. Each utterance is provided ~ith a. copy contour or a sta.ndardized Germa.n, Dutch and En-
139

140 Summary
glish intonation contour. The results show that listeners cannot hear any difference in acceptability between the copy contour and the standardized German version. Dutch and English contours arejudged significantly lower. From this we can conclude that the model correctly reflects the perceptually relevant features of German intonation.
Chapter 5 compares the results of this research with the findings reported in the phonetic literature. Also, a comparison is made between the German model and similar models for Dutch and English. Applications of the proposed model are described and, finally, some open questions are discussed.

Samenvatting
Een van de opvallendste eigenschappen van spraak is dat in het verloop van een uiting de toonhoogte voortdurend verandert. De toonhoogteveranderingen die de luisteraar waarneemt, komen overeen met veranderingen van de grondtoon in het akoestisch signaal. In dit proefschrift wordt onderzocht welke veranderingen van de grondtoon in voorgelezen Duitse tekst voor de waarneming van belang zijn. De resultaten worden in de vorm van een melodisch model weergegeven.
In hoofdstuk 1 wordt de gebruikte methode beschreven. In een eerste stap wordt van een toonhoogtecurve een kopiecontour gemaakt. Een kopiecontour is perceptief gelijk aan de originele curve en bestaat uit het kleinst mogelijke aantal perceptief relevante toonhoogtebewegingen, weergegeven door rechte lijnen. Aan de hand van een vergelijking van een groot aantal kopiecontouren wordt een melodisch model opgesteld.
Hoofdstuk 2 geeft een overzicht van de fonetische literatuur met betrekking tot Duitse intonatie. In dit overzicht worden de belangrijkste resultaten samengevat. Tevens wordt ingegaan op typische problemen van de verschillende methoden van intonatie-onderzoek.
Hoofstuk 3 behandelt de vraag hoe op basis van een toonhoogtecurve een kopiecontour gemaakt kan worden en welke betekenis een kopiecontour heeft voor het ontwikkeling van een melodisch model. Voorts wordt ingegaan op de perceptie van de kopiecontour en de verschillende mogelijkheden van specificatie.
In een perceptie-experiment worden toonhoogtecurven en kopiecontouren direkt met elkaar vergeleken. Het blijkt dat luisteraars de akoestisch aanwezige verschillen niet kunnen waarnemen. Een kopiecontour is dus inderdaad perceptief gelijk aan een natuurlijke toonhoogtecurve.
Hoofdstuk 4 beschrijft een melodisch model voor het Duits. Het bestaat uit gestandaardiseerde declinatielijnen, gestandaardiseerde toonhoogtebewegingen en sequentiële regels. Volgens deze regels kunnen con-
141

142 Samenvatting
touren worden gevormd. In een experiment wordt de validiteit van het melodisch model on
derzocht. Daartoe beoordelen Duitse luisteraars de acceptabiliteit van Duitse uitingen, die elk van een kopiecontour en een gestandaardiseerde Duitse, Nederlandse en Engelse contour worden voorzien. De resultaten laten zien dat Duitse luisteraars met betrekking tot de acceptabiliteit geen verschil horen tussen de kopiecontouren en de gestandaardiseerde Duitse contouren. De Nederlandse en Engelse contouren worden signifikant lager beoordeeld. De conclusie is dus gerechtvaardigd dat het model de voor de luisteraar relevante vormeigenschappen van Duitse intonatie perceptief adequaat weergeeft.
In hoofstuk 5 worden de resultaten van dit onderzoek vergeleken met de bevindingen die in de fonetische literatuur zijn gerapporteerd. Voorts wordt een vergelijking gemaakt tussen het Duitse model en overeenkomstige modellen voor het Nederlands en het Engels. Er worden enkele toepassingen van het Duitse model beschreven en tot slot worden enkele open vragen besproken.

Dankwoord
Voor hun opbouwende kritiek en waardevolle suggesties zowel tijdens het onderzoek als het schrijven van deze dissertatie ben ik zeer veel dank verschuldigd aan prof. dr. S.G. Nooteboom, prof. dr. H. Bouma en J . 't Hart.
Verder ben ik prof. Bouma in zijn hoedanigheid van directeur van het Instituut voor Perceptie Onderzoek erkentelijk dat ik van de faciliteiten van het instituut gebruik heb kunnen maken.
Voorts dank ik prof. dr. D.G. Bouwhuis en drs. G.W.G. Spaai voor hun hulp bij de statistische analyse van de experimentele data.
Prof. dr. W. Hess en dr. W.F. Sendlmeier van het Institut für Kommunikationsforschung und Phonetik te Bonn dank ik voor hun steun bij de uitvoering van de perceptie-experimenten.
Schaesberg, maart 1991
143


Curriculum vitae
Léon M.H. Adriaens werd op 16 augustus 1957 te Schaesberg te geboren. In 1976 behaalde hij het diploma Gymnasium f3 aan het Coriovallum College te Heerlen. Van 1976 tot 1982 studeerde hij Duitse taal- en letterkunde aan de Rijksuniversiteit te Leiden (afstudeerrichting taalkunde) met als bijvak fonetiek.
In 1980 was hij enkele maanden verbonden aan de vakgroep Duitse taal- en letterkunde van de Rijksuniversiteit te Leiden als adjunct-wetenschappelijk ambtenaar en werkzaam op het gebied van de taalverwerving.
In 1982 en 1983 was hij werkzaam als leraar Duits aan verschillende scholen.
Va~ 1983 tot 1989 was hij als wetenschappelijk medewerker verbonden aan de sectie Germaanse Filologie van de Vrije Universiteit Brussel en voornamelijk werkzaam op het gebied van de Duitse taalkunde.
Van 1984 tot 1990 voerde hij het in dit proefschrift beschreven onderzoek uit aan het Instituut voor Perceptie Onderzoek te Eindhoven.
145

Stellingen behorende bij het proefschrift
Ein M odell deutscher Intonation
van Léon M.H. Adriaens

I
De veronderstelling dat de regels voor Nederlandse en Duitse intonatie grotendeels met elkaar overeenkomen (ten Ca.te, Jordens en van Lessen Kloeke, 1976) is voor wat betreft de vormeigenschappen onjuist.
ten Cate, A.P., P. Jordens en W.U.S. van Lessen Kloeke (1076) De..Uche Phonetik (Wolters-Noordhoff, Groningen).
n
Het aantal segmenten dat noodzakelijk is voor een "close-copy"stilering (de Pijper, 1983} is mede afhankelijk van het verloop van de amplitude.
de Pijper, J.R. (1083) Modelling Bn'tüh Eng/üh lntonation (Foris, Dordrecht - Cinnaminson, RI) .
m lsalenko en Schädlich (1964} gebruiken in hun experimenten met kunstmatige intonatie een excursie die tussen 1 en 3 semitonen ligt. Deze geringe excursie is vooral een gevolg van de gebruikte techniek om intonatie te simuleren.
lsalenko, A.V. en H.J. Schä.dlich (1064) Untersuchungen iiber die deut.sche Satzintonation (Akademie-Verlag, Berlin).
IV
De uitspraak van de Nederlandse diftongen /ei/ en /ui/ door Duitstaligen kan met behulp van een eenvoudige instructie aanzienlijk worden verbeterd.

V
De PSOLA-techniek (Charpentier en Moulines, 1989) maakt het mogelijk prosodische veranderingen in natuurlijke spraakuitingen aan te brengen zonder dat de spraakkwaliteit noemenswaardig achteruit gaat. Het is echter niet aan te nemen dat met de PSOLAtecbniek de essentiële problemen opgelost kunnen worden die in LPC-difoonspraak optreden.
Charpentier, F. en E. Moulines (1989) "Pitch-Synchronous Waveform Processing Techniques for Text-to-Speech Synthesis using Diphones•, Proc. EUROSPEECH 89, ooi. f, 13-19.
VI
De gehoorde verschillen in duur tussen corresponderende Nederlandse en Duitse klinkers kunnen onvoldoende verklaard worden door verschillen in gemeten duur (van Dommelen, 1980). Het is waarschijnlijk dat de specifieke eigenschappen van de Nederlandse en Duitse intonatie de waargenomen klinkerduur beïnvloeden.
van Dommelen, W. (1980) Temporale Fa/doren bei atUländüchem Akunt, dissertatie, Rijksuniversiteit Leiden.
VII
De voortgang van wetenschappelijk onderzoek is vergelijkbaar met de Springprocessie van Echternach.



















