
Efficient User-Level Networking in Java Chi-Chao Chang Dept. of Computer Science Cornell University...
38
Efficient User-Level Efficient User-Level Networking in Java Networking in Java Chi-Chao Chang Dept. of Computer Science Cornell University (joint work with Thorsten von Eicken and the Safe Language Kernel group)
-
date post
19-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of Efficient User-Level Networking in Java Chi-Chao Chang Dept. of Computer Science Cornell University...

Efficient User-Level Networking Efficient User-Level Networking in Javain Java
Chi-Chao ChangDept. of Computer Science
Cornell University
(joint work with Thorsten von Eicken and the Safe Language Kernel group)

GoalGoal
2
High-performance cluster computing with safe languages parallel and distributed applications communication support for operating systems
Use off-the-shelf technologies User-level network interfaces (UNIs)
direct, protected access to network devices inexpensive clusters U-Net (Cornell), Shrimp (Princeton), FM (UIUC), Hamlyn (HP) Virtual Interface Architecture (VIA): emerging UNI standard
Java safe: “better C++” “write once run everywhere” growing interest for high-performance applications (Java Grande)
Make the performance of UNIs available from Java JAVIA: a Java interface to VIA

Why a Java Interface to UNI?Why a Java Interface to UNI?
3
Different approach for providing communication support for Java
Traditional “front-end” approach pick favorite abstraction (sockets, RMI,
MPI) and Java VM write a Java front-end to custom or
existing native libraries good performance, re-use proven code magic in native code, no common solution
Javia: exposes UNI to Java minimizes amount of unverified code isolates bottlenecks in data transfer
1. automatic memory management
2. object serialization
RMI, RPC
Sockets
Active Messages, MPI, FM
UNI
Networking Devices
Apps
Java
C

Contribution IContribution I
PROBLEMlack of control over object lifetime/location due to GC
EFFECT conventional techniques (data copying and buffer pinning) yield 10% to 40% hit in array throughput
SOLUTION jbufs: explicit, safe buffer management in Java
SUPPORTmodifications to GC
RESULT BW within 1% of hardware, independent of xfer size
4
Array Throughput
0
20
40
60
80
0 8 16 24 32
Kbytes
MB/s
rawconv tech 1conv tech 2conv tech 3conv tech 4
Array Throughput with Jbufs
0
20
40
60
80
0 8 16 24 32
Kbytes
MB/s
raw
jbufs

Contribution IIContribution II
PROBLEMlinked, typed objects
EFFECT serialization >> send/recv overheads (~1000 cycles)
SOLUTION jstreams: in-place object unmarshaling
SUPPORTobject layout information
RESULT serialization ~ send/recv overheads
unmarshaling overhead independent of object size
5
readObject
0
5000
10000
15000
20000
25000
30000
35000
Object Size (Bytes)
Pe
r-O
bje
ct O
verh
ead
(cy
cle
s)
Serial (MS JVM5.0)Serial (Marmot)jstream/Javajstream/C

OutlineOutline
Background UNI: Virtual Interface Architecture Java Experimental Setup
Javia Architecture Javia-I: native buffers (baseline) Javia-II: jbufs (buffer management) and jstreams
(marshaling)
Summary and Conclusions
6

VVV
OS
VVV
OS
VVV
OS
NI
VVV
OS
NI
UNI in a NutshellUNI in a Nutshell
Traditional all communication via OS
VIA connections between virtual
interfaces (Vi) apps send/recv through Vi, simple
mux in NI OS only involved in setting up Vis
Generic Architecture implemented in hardware,
software or both
7
Enabling technology for networks of workstations direct, protected access to networking devices

VI StructuresVI Structures
Key Data Structures user buffers buffer descriptors < addr, len>:
layout exposed to user send/recv queues: only through
API calls
Structures are pinned to physical memory address translation in adapter
8
recvQsendQ
Adapter
DoorbellsDMA
Application Memory
Librarybuffers
descr
DMA
Key Points direct DMA access to buffers/descr in user-space application must allocate, use, re-use, free all buffers/desc alloc&pin, unpin&free are expensive operations, but re-use is cheap

Java Storage SafetyJava Storage Safety
class Buffer {
byte[] data;
Buffer(int n) { data = new byte[n]; }
}
No control over object placementBuffer buf = new Buffer(1024);
cannot pin after allocation: GC can move objects
No control over de-allocationbuf = null;
drop all references, call or wait for GC;
Result: additional data copying in communication path
9

Java Type SafetyJava Type Safety
Cannot forge a reference to a Java object e.g. cannot cast between byte arrays and objects
No control over object layout field ordering is up to the Java VM objects have runtime metadata
casting with runtime checks
Object o = (Object) new Buffer(1024) /* up cast: OK */
Buffer buf = (Buffer) o; /* down cast: runtime check */ array bounds check
for (int i = 0; i < 1024; i++) buf.data[i] = i;
Result: expensive object marshaling
10
byte[] vtablelock obj
1024012...
Buffer vtablelock obj
buf

MarmotMarmotJava System from Microsoft Research
not a VM static compiler: bytecode (.class) to x86 (.asm) linker: asm files + runtime libraries -> executable (.exe) no dynamic loading of classes most Dragon book opts, some OO and Java-specific opts
Advantages source code good performance two types of non-concurrent GC (copying, conservative) native interface “close enough” to JNI
11

Example: Cluster @ CornellExample: Cluster @ Cornell
Configuration 8 P-II 450MHz, 128MB RAM 8 1.25 Gbps Giganet GNN-1000 adapter one Giganet switch total cost: ~ $30,000 (w/university discount)
GNN1000 Adapter mux implemented in hardware device driver for VI setup VIA interface in user-level library (Win32 dll) no support for interrupt-driven reception
Base-line pt-2-pt Performance 14s r/t latency, 16s with switch over 100MBytes/s peak, 85MBytes/s with switch
12

OutlineOutline
Background
Javia Architecture Javia-I: native buffers (baseline) Javia-II: jbufs and jstreams
Summary and Conclusions
13

Javia: General ArchitectureJavia: General Architecture
Java classes + C library
Javia-I baseline implementation array transfers only no modifications to Marmot native library: buffer mgmt +
wrapper calls to VIA
Javia-II array and object transfers buffer mgmt in Java special support from Marmot native library: wrapper calls to VI
14
Javia C library
Java (Marmot)
Javia classes
Giganet VIA library
GNN1000 Adapter
Apps Apps

Javia-I: Exploiting Native BuffersJavia-I: Exploiting Native Buffers
Basic Asynch Send/Recv buffers/descr in native library Java send/recv ticket rings mirror VI
queues # of descr/buffers == # tickets in ring
Send Critical Path get free ticket from ring copy from array to buffer free ticket
Recv Critical Path obtain corresponding ticket in ring copy data from buffer to array free ticket from ring
15
send/recv ticket ring
send/recvqueue
descriptor
buffer
Java
C
byte array ref
Vi
GC heap
VIA

Javia-I: VariantsJavia-I: VariantsTwo Send Variants: Sync Send + Copy
goal: bypass send ring one ticket array -> buffer copy wait until send completes
Sync Send + Pin: goal: bypass send ring, avoid copy pin array on the fly waits until send completes unpins after send
One Recv Variant: No-Post Recv + Alloc
goal: bypass recv ring allocate array on the fly, copy data
16
send/recv ticket ring
send/recvqueue
descriptor
buffer
Java
C
byte array ref
Vi
GC heap
VIA

Javia-I: PerformanceJavia-I: Performance
17
0
100
200
300
400
0 1 2 3 4 5 6 7 8
Kbytes
s rawcopy(s)pin(s)copy(s)+alloc(r) pin(s)+alloc(r)
0
20
40
60
80
0 8 16 24 32
Kbytes
MB/s
rawcopy(s)pin(s)copy(s)+alloc(r)pin(s)+alloc(r)
Basic Costs:VIA pin + unpin = (10 + 10)us
Marmot: native call = 0.28us, locks = 0.25us, array alloc = 0.75us
Latency: N = transfer size in bytes16.5us + (25ns) * N raw
38.0us + (38ns) * N pin(s)
21.5us + (42ns) * N copy(s)
18.0us + (55ns) * N copy(s)+alloc(r)
BW: 75% to 85% of raw, 6KByte switch over between copy and pin

jbufsjbufsLessons from Javia-I
managing buffers in C introduces copying and/or pinning overheads
can be implemented in any off-the-shelf JVM
Motivation eliminate excess per-byte costs in latency improve throughput
jbuf: exposes communication buffers to Java programmers1. lifetime control: explicit allocation and de-allocation of jbufs
2. efficient access: direct access to jbuf as primitive-typed arrays
3. location control: safe de-allocation and re-use by controlling whether or not a jbuf is part of the GC heap
18

jbufs: Lifetime Control jbufs: Lifetime Control
1. jbuf allocation does not result in a Java reference to it cannot directly access the jbuf through the wrapper object
2. jbuf is not automatically freed if there are no Java references to it free has to be explicitly called
19
public class jbuf {
public static jbuf alloc(int bytes);/* allocates jbuf outside of GC heap */
public void free() throws CannotFreeException; /* frees jbuf if it can */
}
jbuf
GC heap
C pointer

jbufs: Efficient Access jbufs: Efficient Access
3. (Memory Safety) jbuf remains allocated as long as there are array references to it when can we ever free it?
4. (Type Safety) jbuf cannot have two differently typed references to it at any given time when can we ever re-use it (e.g. change its reference type)?
20
public class jbuf {
/* alloc and free omitted */
public byte[] toByteArray() throws TypedException;/*hands out byte[] ref*/
public int[] toIntArray() throws TypedException; /*hands out int[] ref*/
. . .
}
jbuf
GC heap
Java byte[]
ref

jbufs: Location Control jbufs: Location Control
Idea: Use GC to track references
unRef: application claims it has no references into the jbuf jbuf is added to the GC heap GC verifies the claim and notifies application through callback application can now free or re-use the jbuf
Required GC support: change scope of GC heap dynamically
21
public class jbuf {
/* alloc, free, toArrays omitted */
public void unRef(CallBack cb); /* app intends to free/re-use jbuf */
}
jbuf
GC heap
Java byte[]
ref
jbuf
GC heap
Java byte[]
ref
jbuf
GC heap
Java byte[]
ref
unRef callBack

jbufs: Runtime Checksjbufs: Runtime Checks
Type safety: ref and to-be-unref states parameterized by primitive type
GC* transition depends on the type of garbage collector non-copying: transition only if all refs to array are dropped before GC copying: transition occurs after every GC
22
Unref ref<p>
to-beunref<p>
to<p>Array
to<p>Array, GC
unRef
to<p>Array, unRef
GC*
alloc
free

Javia-II: Exploiting jbufsJavia-II: Exploiting jbufs
Send/recv with jbufs explicit pinning/unpinning of jbufs tickets point to pinned jbufs critical path: synchronized access to rings,
but no copies
Additional checks send posts allowed only if jbuf is in ref<p>
state recv posts allowed only if jbuf is in unref or
ref<p> state no outstanding send/recv posts in to-be-
unref<p> state
23
send/recv ticket ring
send/recvqueue
descriptor
jbuf
Java
C
Vi
state
GC heap
array refs
VIA

Javia-II: PerformanceJavia-II: Performance
24
Basic Costsallocation = 1.2us, to*Array = 0.8us, unRefs = 2.5 us
Latency (n = xfer size)16.5us + (0.025us) * n raw
20.5us + (0.025us) * n jbufs
38.0us + (0.038us) * n pin(s)
21.5us + (0.042us) * n copy(s)
BW: within margin of error (< 1%)
0
100
200
300
400
0 1 2 3 4 5 6 7 8
Kbytes
s raw
jbufs
copy
pin
0
20
40
60
80
0 8 16 24 32
Kbytes
MB/s
raw
jbufs
copy
pin

Parallel Matrix MultiplicationParallel Matrix Multiplication
25
Goal: validate jbufs flexibility and performance in Java apps
matrices represented as array of jbufs (each jbuf accessed as array of doubles)
A, B, C distributed across processors (block columns)
comm phase: processor sends local portion of A to right neighbor, recv new A from left neighbor
comp phase: Cloc = Cloc + Aloc * Bloc’
Preliminary Results no fancy instruction scheduling in Marmot no fancy cache-conscious optimizations single processor, 128x128: only 15 Mflops cluster, 128x128
comm time about 10% of total time
Impact of Jbufs will increase as #flops increase
+=
C
*
A B
p0 p1 p2 p3 p0 p1 p2 p3 p0 p1 p2 p3
1
2
3
4
5
6
7
8
1 2 3 4 5 6 7 8
Procs
linear
jbufs
copy
pin

Active MessagesActive Messages
26
Goal: Exercise jbuf mgmt
Implemented subset of AM-II over Javia+jbufs: maintains a pool of free recv
jbufs when msg arrives, jbuf is passed
to the handler AM calls unRef on jbuf after
handler invocation if pool is empty, either alloc more
jbufs or invoke GC no copying in critical path,
deferred to GC-time if needed
class First extends AMHandler {
private int first;
void handler(AMJbuf buf, …) {
int[] tmp = buf.toIntArray();
first = tmp[0];
}
}
class Enqueue extends AMHandler {
private Queue q;
void handler(AMJbuf buf, …) {
int[] tmp = buf.toIntArray();
q.enq(tmp);
}
}

AM: Preliminary NumbersAM: Preliminary Numbers
27
0
100
200
0 1 2 3 4 5 6 7 8Kbytes
s
raw
Javia+jbufs
AM
Javia+copy
0
20
40
60
80
0 8 16 24 32
Kbytes
MBps
raw
Javia+jbufs
Javia+copy
AM
Summary AM latency about 15 us higher than Javia
synch access to buffer pool, endpoint header, flow control checks, handler id lookup
room for improvement AM BW within 5% of peak for 16KByte messages

jstreamsjstreamsGoal: efficient transmission of arbitrary objects
assumption: optimizing for homogeneous hosts and Java systems
Idea: “in-place” unmarshaling defer copying and allocation to GC-time if needed
jstream R/W access to jbuf through object stream API no changes in Javia-II architecture
28
writeObject
“typical” readObject
“in-place” readObject
NETWORK

jstream: Implementationjstream: ImplementationwriteObject
deep-copy of object, breadth-first deals with cyclic data structures replace object metadata (e.g. vtable) with 64-bit class descriptor
readObject depth-first traversal from beginning of stream swizzle pointers, type-checking, array-bounds checking replace class descriptors with metadata
Required support some object layout information (e.g. per-class pointer-tracking info)
Minimal changes to existing stub compilers (e.g. rmic) jstream implements JDK2.0 ObjectStream API
29

jstreams: Safetyjstreams: Safety
30
UnrefUnre
f w/obj
to-be unref
writeObject
writeObject, GC
clearRead
readObject
GC*
Ref
readObject
readObject, GC
clearWrite
readObject
alloc
free
Only recv posts allowedOnly send posts allowed
No outstanding send/recv postsNo send/recv posts allowed
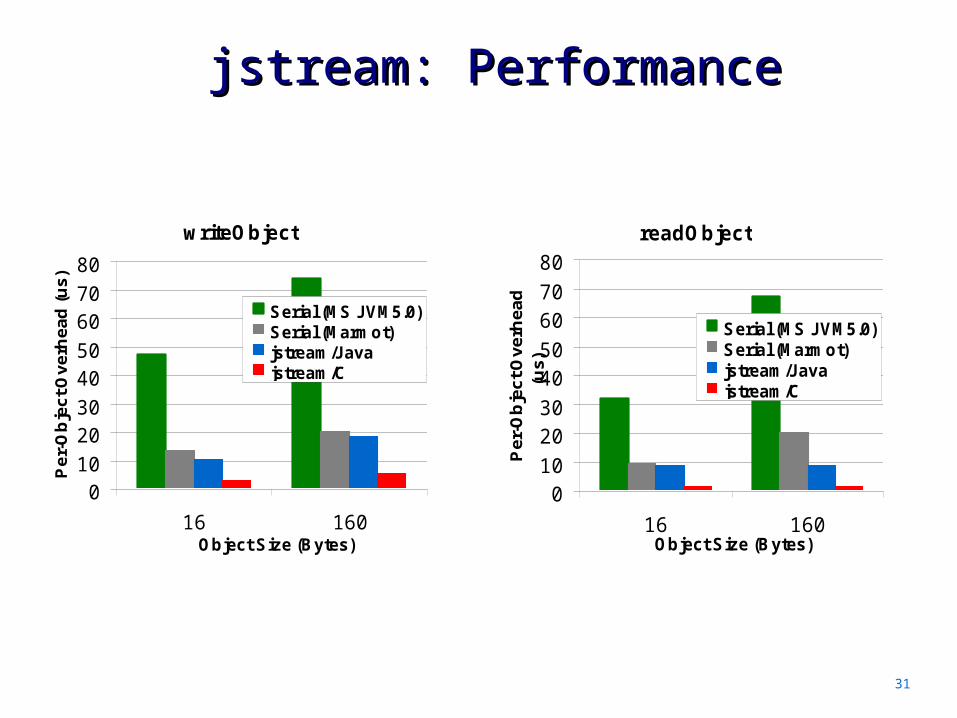
jstream: Performancejstream: Performance
31
writeObject
010
2030
4050
6070
80
16 160Object Size (Bytes)
Pe
r-O
bje
ct
Ov
erh
ea
d (
us
)
Serial (MS JVM5.0)Serial (Marmot)jstream/Javajstream/C
readObject
010
2030
4050
6070
80
16 160Object Size (Bytes)
Pe
r-O
bje
ct
Ov
erh
ea
d
(us
)
Serial (MS JVM5.0)Serial (Marmot)jstream/Javajstream/C

StatusStatusImplementation Status
Javia-I and II complete jbufs and jstreams integrated with Marmot copying collector
Current Work finish implementation of AM-II full implementation of Java RMI integrate jbufs and jstreams with conservative collector more investigation into deferred copying in higher-level protocols
32

Related WorkRelated WorkFast Java RMI Implementations
Manta (Vrije U): compiler support for marshaling, Panda communication system
34 us null, 51 Mbytes/s (85% of raw) on PII-200/Myrinet, JDK1.4 KaRMI (Karlsruhe): ground-up implementation
117 us null, Alpha 500, Para-station, JDK1.4
Other front-end approaches Java front-end for MPI (IBM), Java-to-PVM interface (GaTech)
Microsoft J-Direct “pinned” arrays defined using source-level annotations JIT produces code to “redirect” array access: expensive
Comm System Design in Safe Languages (e.g. ML) Fox Project (CMU): TCP/IP layer in ML Ensemble (Cornell): Horus in ML, buffering strategies, data path
optimizations33

SummarySummary
High-Performance Communication in Java: Two problems buffer management in the presence of GC object marshaling
Javia: Java Interface to VIA uses native buffers as baseline implementation jbufs: safe, explicit control over buffer placement and lifetime,
eliminates bottlenecks in critical path jstreams: jbuf extension for fast, in-place unmarshaling of
objects
Concluding Remarks building blocks for Java apps and communication software should be integral part of a high-performance Java system
34

Javia-I: InterfaceJavia-I: Interface
package cornell.slk.javia;
public class ViByteArrayTicket {
private byte[] data; private int len, off, tag;
/* public methods to set/get fields */
}
public class Vi { /* connection to remote Vi */
public void sendPost(ViByteArrayTicket t); /* asynch send */
public ViByteArrayTicket sendWait(int timeout);
public void recvPost(ViByteArrayTicket t); /* async recv */
public ViByteArrayTicket recvWait(int timeout);
public void send(byte[] b, int len, int off, int tag); /* sync send */
public byte[] recv(int timeout); /* post-less recv */
}
35

Javia-II: InterfaceJavia-II: Interface
package cornell.slk.javia;
public class ViJbuf extends jbuf {
public ViJbufTicket register(Vi vi); /* reg + pin jbuf */
public void deregister(ViJbufTicket t); /* unreg + unpin jbuf */
}
public class ViJbufTicket {
private ViJbuf buf; private int len, off, tag;
}
public class Vi {
public void sendBufPost(ViJbufTicket t); /* asynch send */
public ViBufTicket sendBufWait(int usecs);
public void recvBufPost(ViJbufTicket t); /* async recv */
public ViBufTicket recvBufWait(int usecs);
}
36

Jbufs: ImplementationJbufs: Implementationalloc/free: Win32 VirtualAlloc, VirtualFree
to{Byte,Int,...}Array:no alloc/copying
clearRefs: modification to stop-and-copy Cheney scan GC clearRef adds a jbuf to that list after GC, traverse list to invoke callbacks, delete list
37
Stack + Global
to-space
unref’d jbufs
from-space
Stack + Global
from-space
ref’djbufs
to-space
Before GC After GC
array body
vtablelock
length
baseAddr
native desc ptr

State-of-the-Art Matrix MultiplicationState-of-the-Art Matrix Multiplication
38
332 Mhz PowerPC 604e
0
50
100
150
200
250
300
350M
FL
OP
S
plainnocheckblockingunrollingscalarfmaC++ESSL
4.9
199.9
314.2
Courtesy: IBM Research


















