
Efficient Approximate Thompson Sampling for Search Query Recommendation in SAC'15
38
Efficient Approximate Thompson Sampling for Search Query Recommendation Chu-Cheng Hsieh 1
-
Upload
ebay-inc -
Category
Technology
-
view
68 -
download
0
Transcript of Efficient Approximate Thompson Sampling for Search Query Recommendation in SAC'15

Efficient Approximate Thompson Sampling
for Search Query Recommendation
Chu-Cheng Hsieh
1

2
Nov.
13
Dec.
13
Jan.
13
Feb.
13
Training Date
Training Data

3
What’s wrong?

4
Resource is limited

5
Before vs. After Xmas

6
Multi-arm bandit
Problem (MAB)Thompson Sampling
Query recommendation
Experiments

The k-arm Bandit Problem
7
A
B
C

8
Play the right slot machine
that maximize your profit
#Goal#

9
1. 30% (play each evenly)
2. 70% play the best one
#Simple Strategy#

10
Related Search => MAB problem (M=1)
A B C D E

11
Multi-arm bandit Problem
Thompson (TS)
SamplingQuery recommendation
Experiments

12
Exploration
(learn)
(earn)
Exploitation
x = random.random() #0<=x<1
y = 0.49
if (x < y):
return true
else:
return false
(Observed)
13
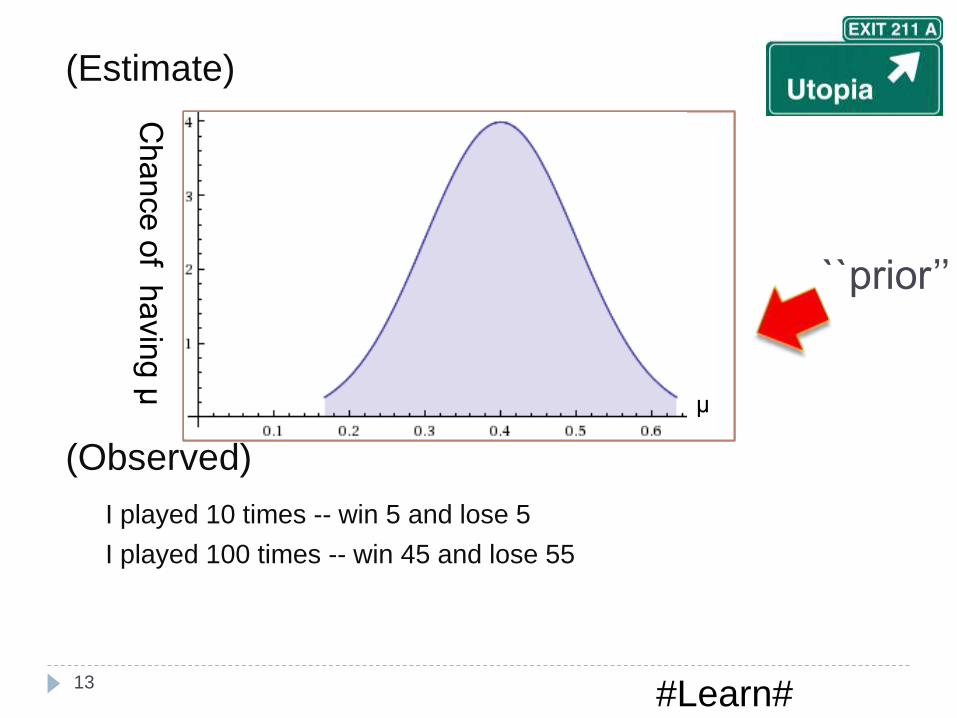
(Estimate)
I played 10 times -- win 5 and lose 5
I played 100 times -- win 45 and lose 55
#Learn#
Chance o
f havin
g μ
μ
``prior’’

14
Data Observed
Action (Machine)
(Refienments being displayed)
Reward (Win/Loss)(CTR, BBOWA, ...)

15
#Question#
Learn or Earn?
Red
19 win
9 lose
Blue
59 win
39 lose

16
Thompson Sampling
Selecting a candidate based on the following formula:
Assuming:

0.0 0.2 0.4 0.6 0.8 1.0
0.6
0.8
1.0
1.2
1.4
x
PD
F
17
Beta(0+1,0+1)
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
2.0
2.5
x
PD
F
18
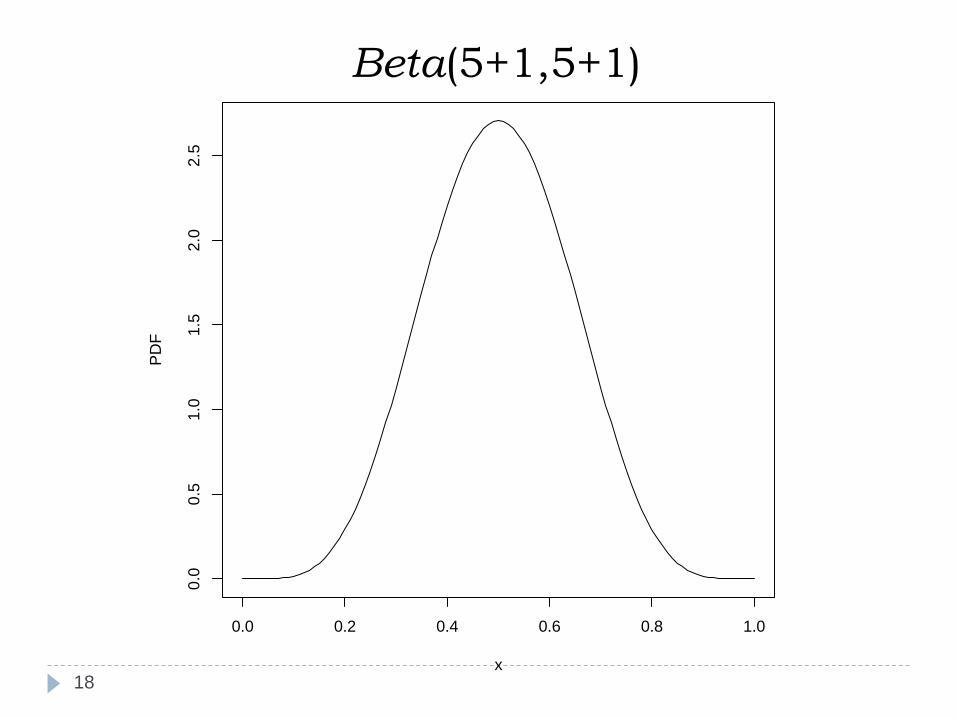
Beta(5+1,5+1)

0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
19
Beta(45+1,55+1)

20
#Example#
Learn or Earn?
Red
19 win
9 lose
Blue
59 win
39 lose
75% 25%

0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
The motivation of Thompson-S (2)
21
Beta(20,10)
Beta(60,40)
See a
good one;
“learn more”

0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
Intuition
(Underdog, but worth to learn)
22
Beta(4,6)
Beta(60,40)

0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
The motivation of Thompson-S (1)
23
Beta(10,15)
Beta(60,40)
avoid exploring
“low potential” arm
early on

Intuition (Equal exploration)
24 0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
0.0 0.2 0.4 0.6 0.8 1.0
02
46
8
x
PD
F
Beta(40,60) Beta(60,40)

25
Init: a=1, b=1, Sx=Fx=0 for all x
each arm corresponds to Beta(Sx+a, Fx+b) prior
1. Draw a random number from each arm
based on Beta(Sx+a, Fx+b)
2. Play the arm (x’) with the highest number
3. If (see a reward)
Sx’ += 1
else
Fx’ += 1
Algorithm

26

27
Multi-arm bandit Problem
Thompson Sampling
Query RecommendationExperiments

28
Ugly truth #1
M > 1 (M=5 here)

29

Ugly truth # 2
No response => failure ?

31

32
Multi-arm bandit Problem
Thompson Sampling
Query Recommendation
Experiments

33
#Experiments#
Target: popular 100 (queries)
Date: 2 weeks (Nov. 2013)
Goal: identify top M
Measurement: Regret
->
Best
->
Picked

34
M=1M=2
#Goal#
Identify top M quickly.

35
M=1,2,3 and γ=0.02

36
M=2, γ=0~2

37 Chu-Cheng Hsieh

38
Hsieh, C. Neufeld, J. Holloway King, T. Cho, J.J.
Efficient Approximate Thompson Sampling for
Search Query Recommendation The 30th
ACM/SIGAPP Symposium On Applied Computing
(SAC 2015)
About the author & download:
http://oak.cs.ucla.edu/~chucheng/

















![Efficient Discovery of Approximate Dependencies - vldb.org · tems [7,13,19,24,42]. Furthermore, approximate dependen-cies can help to improve poor cardinality estimates of query](https://static.fdocuments.us/doc/165x107/5b3994377f8b9a310e8e87c8/efcient-discovery-of-approximate-dependencies-vldb-tems-713192442.jpg)
