

Effects of partial measurement (non)invariance on manifest composite differences across groups
21
Effects of partial measurement (non)invariance on manifest composite differences across groups Holger Steinmetz Dep. of Work and Organizational Psychology University of Giessen / Germany Peter Schmidt Institute for Political Science University of Giessen / Germany
-
Upload
arthur-england -
Category
Documents
-
view
50 -
download
0
description
Effects of partial measurement (non)invariance on manifest composite differences across groups. Holger Steinmetz Dep. of Work and Organizational Psychology University of Giessen / Germany Peter Schmidt Institute for Political Science University of Giessen / Germany. Introduction. - PowerPoint PPT Presentation
Transcript of Effects of partial measurement (non)invariance on manifest composite differences across groups

Effects of partial measurement (non)invariance on manifest composite differences across groups
Holger Steinmetz
Dep. of Work and Organizational Psychology
University of Giessen / Germany
Peter Schmidt
Institute for Political Science
University of Giessen / Germany

Introduction
Importance of analyses of mean differences
For instance:- gender differences on wellbeing, self-esteem, abilities, behavior- differences between leaders and non-leaders on intelligence and personality traits
- differences between cultural populations on psychological competencies, values, wellbeing
Usual procedure: t-test or ANOVA with observed composite scores
Latent variables vs. observed variables
Observed mean = indicator intercept + factor loading * latent mean
Research question: Effects of unequal intercepts and/or factor loadings across groups on composite differences

Relationship between latent and observed means
iiix
x1
x4
x2
x3

Relationship between latent and observed means
iiiix
xi
i
i
x1
x4
x2
x3

Relationship between latent and observed means
)()()( iiii EExE
xi
i
i
x1
x4
x2
x3

Relationship between latent and observed means
x1
x4
x2
x3
iiixM )(
xi
i
i
M(xi)

Group differences in intercepts and factor loadings
xi
M(xi)M(xi)
M(xi)
x1
x4
x2
x3
x1
x4
x2
x3
Group A Group B

Group differences in intercepts and factor loadings
xi
M(xi)M(xi)
M(xi)
x1
x4
x2
x3
x1
x4
x2
x3
Group A Group B

Group differences in intercepts and factor loadings
xi
M(xi)M(xi)
M(xi)
x1
x4
x2
x3
x1
x4
x2
x3
Group A Group B

Meaning of (unequal) intercepts
Associated terms used in the literature- Item bias- Differential item functioning- Measurement/factorial invariance („metric invariance", "scalar invariance")
Meaning- Response style (acquiescence, leniency, severity)- Response sets (e.g., social desirability)- Connotations of items- Item specific difficulty

The study
Partial invariance: Some loadings / intercepts are allowed to differ
Research question: Is partial invariance enough for composite mean difference testing?
- Pseudo-differences
- Compensation effects
Procedure (Mplus):
- Step 1: a) Specification of two-group population models with varying differences in latent mean, intercepts and loadings
b) 1000 replications, raw data saved
- Step 2: Creation of a composite score
- Step 3: Analysis of composite differences
- Step 4: Aggregation (-> sampling distribution)

The study
Population model:- Two groups- One latent variable
Conditions:- 4 vs. 6 indicators- Latent mean difference: 0 vs. .30- Intercepts: equal vs. one vs. two intercepts unequal in varying directions (-.30 vs. +.30)
- Loadings: equal (‘s = .80) vs. one vs. two loadings = .60- Sample size: 2x100 vs. 2x300
Dependent variables- Average composite mean difference - Percent of significant composite differences
Group A Group B
x1
x4
x2
x3
x1
x4
x2
x3
x5
x6
x5
x6
=.00
=-.30
=.80
=.60
=.30
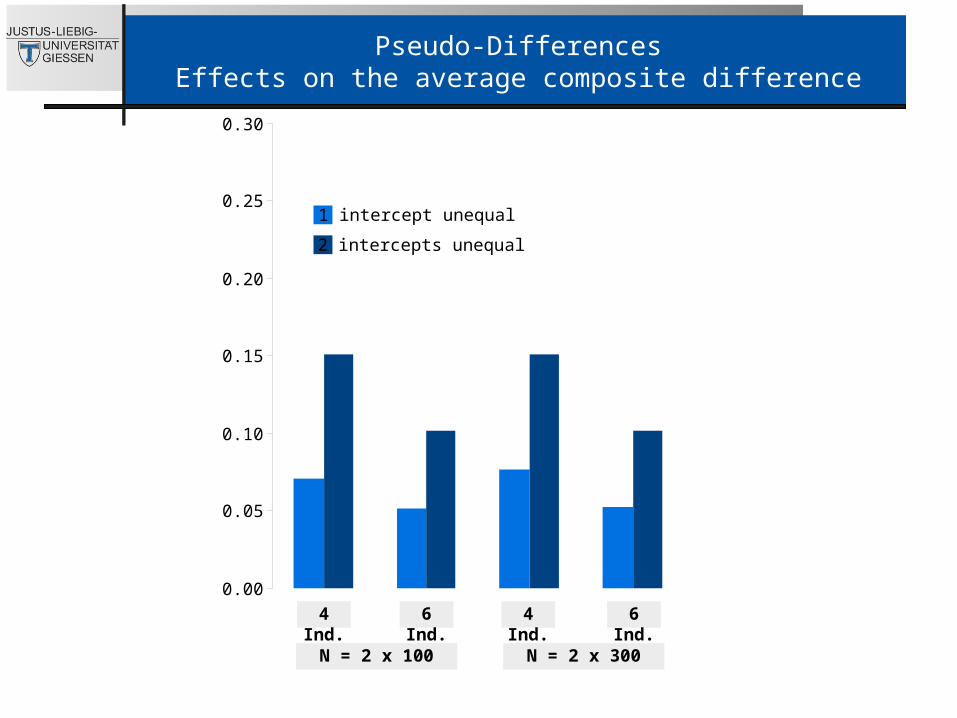
Pseudo-DifferencesEffects on the average composite difference
4 Ind. 6 Ind.
N = 2 x 300
4 Ind. 6 Ind.
0.00
0.05
0.10
0.15
0.20
0.25
0.30
1 intercept unequal
2 intercepts unequal
N = 2 x 100

Pseudo-DifferencesEffects on the probability of significant differences (Type
I error)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
4 Ind. 6 Ind.
1 intercept unequal
2 intercepts unequal
All intercepts equal
N = 2 x 100

Pseudo-DifferencesEffects on the probability of significant differences (Type
I error)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
4 Ind. 6 Ind. 4 Ind. 6 Ind.
1 intercept unequal
2 intercepts unequal
All intercepts equal
N = 2 x 300N = 2 x 100

Compensation effectsEffects on the average composite differences
1 intercept unequal
2 intercepts unequal
All intercepts equal
Loadingsequal
1 Loadingunequal
4 Indicators
2 Loadingsunequal
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Effect of unequal loadings
Effect of unequal intercepts

Compensation effectsEffects on the average composite differences
1 intercept unequal
2 intercepts unequal
All intercepts equal
Loadingsequal
1 Loadingunequal
4 Indicators
2 Loadingsunequal
Loadingsequal
1 Loadingunequal
6 Indicators
2 Loadingsunequal
0.00
0.05
0.10
0.15
0.20
0.25
0.30

Compensation effectsEffects on the probability of significant differences
(Power)
Loadingsequal
1 Loadingunequal
N = 2x300 / 6 Indicators
2 Loadingsunequal
1 intercept unequal
2 intercepts unequal
All intercepts equal
Loadingsequal
1 Loadingunequal
N = 2x100 / 4 Indicators
2 Loadingsunequal
0.00
0.10
0.20
0.30
0.40
0.60
0.90
0.50
0.70
0.80

Summary
Pseudo-differences- Even one unequal intercept increases the risk to find spurious composite differences
- High sample size increases risk (up to 60% with two unequal intercepts)
- Unequal factor loadings have only a low influence- Number of indicators reduces the risk – but not substantially
Compensation effects- Just one unequal intercept reduces the size of the composite difference to 50%
- With a “small” sample size little chance to find a significant composite difference (power = .25 - .40)
- Two unequal intercepts drastically reduce the composite difference: The power in the „best“ condition (2x300, 6 Ind.) is only .50

Conclusons
Most comparisons of means rely on traditional composite difference analysis
These methods make assumptions that are unrealistic (i.e., full invariance of intercepts and loadings)
Even minor violations of these assumptions increase the risk of drawing wrong conclusions
Advantages of SEM:- Assumptions can be tested- Partial invariance implies no danger- Greater power even in small samples


















