


Effective Sqoop: Best Practices, Pitfalls and Lessons
36
-
Upload
alex-silva -
Category
Data & Analytics
-
view
3.345 -
download
1
Transcript of Effective Sqoop: Best Practices, Pitfalls and Lessons

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Formatting Arguments
Formatting Argument What is it for?
enclosed-by The field enclosing character.
escaped-by The escape character.
fields-terminated-by The field separator character.
lines-terminated-by The end of line char,
mysql-delimiters Default delimiters: fields (,) lines (\n) escaped-by (\) optionally-enclosed-by (')
optionally-enclosed-by The field enclosing character.
The default delimiters are: comma (,) for fields, newline (\n) for records, no quote character, and no escape character.
Copyright 2014 Rackspace
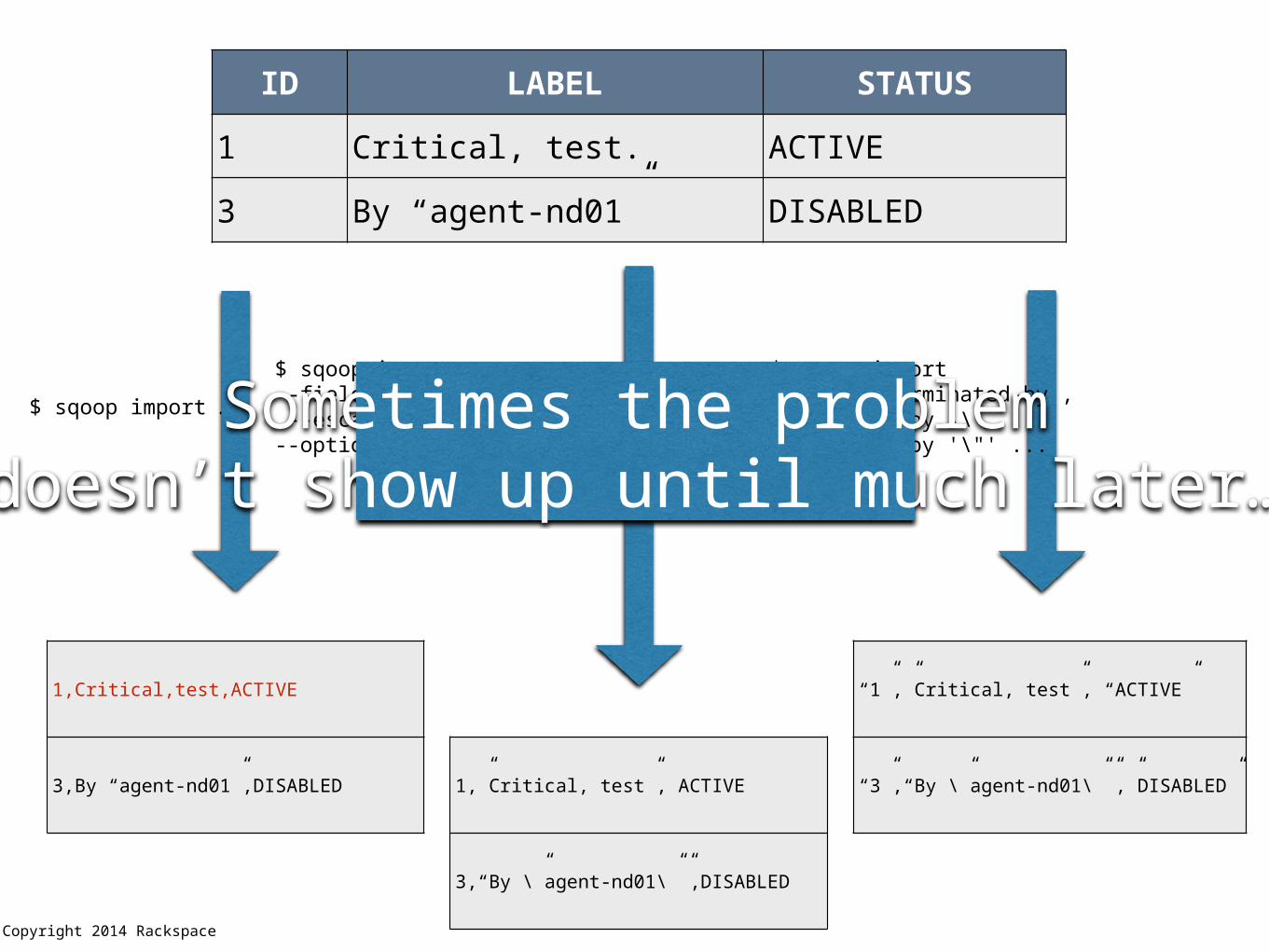
ID LABEL STATUS
1 Critical, test. ACTIVE
3 By “agent-nd01” DISABLED
$ sqoop import …
$ sqoop import --fields-terminated-by , --escaped-by \\ --enclosed-by '\"' ...
“1”,”Critical, test”, “ACTIVE”
“3”,“By \”agent-nd01\””,”DISABLED”1,”Critical, test”, ACTIVE
3,“By \”agent-nd01\””,DISABLED
1,Critical,test,ACTIVE
3,By “agent-nd01”,DISABLED
$ sqoop import --fields-terminated-by , --escaped-by \\ --optionally-enclosed-by '\"' ...
Sometimes the problemdoesn’t show up until much later…
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Taming the Elephant
• Sqoop delegates all processing to Hadoop:
• Each mapper transfers a slice of the table.
• The parameter --num-mappers (defaults to 4) tells Sqoop how many mappers to use to slice the data.
Copyright 2014 Rackspace

How Many Mappers?
• The optimal number depends on a few variables:
• The database type.
• How does it handle parallelism internally?
• The server hardware and infrastructure.
• Overall impact to other requests.
Copyright 2014 Rackspace

Gotchas!• More mappers can lead to faster jobs, but
only up to a saturation point. This varies per table, job parameters, time of day and server availability.
• Too many mappers will increase the load on the database: people will notice!
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Connectors• Two types of connectors: common (JDBC) and
direct (vendor specific batch tools).
Common Connectors
MySQL
PostgreSQL
Oracle
SQL Server
DB2
Generic
Direct Connectors
MySQL
PostgreSQL
Oracle
Teradata
And others
Copyright 2014 Rackspace

Direct Connectors• Performance!
• --direct parameter.
• Utilities need to be available on all task nodes.
• Escape characters, type mapping, column and row delimiters may not be supported.
• Binary formats don’t work.
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Splitting Data• By default, the primary key is used.
• Prior to starting the transfer, Sqoop will retrieve the min/max values for this column.
• Changed column with the --split-by parameter:
• Required in tables with no index columns or multi-column keys.
Copyright 2014 Rackspace

Boundary Queries
What if your split-by column is skewed, table is not indexed or can be retrieved
from another table?
Use a boundary query to create the splits.
select min(<split-by>), max(<split-by>) from <table name>
Copyright 2014 Rackspace

Splitting Free form Queries
• By default, Sqoop will use the entire query as a subquery to calculate max/min: INEFFECTIVE!
• Solution: use a --boundary-query.
• Good choices:
• Store boundary values in a separate table.
• Good for incremental imports. (--last-value)
• Run query prior to Sqoop and save its output in a temporary table.
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Options Files
• Reusable Arguments that do not change.
• Pass it to the command line via --options-file argument.
• Composition: more than one option file is allowed.
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability
7. Use the proper file format for your needs
8. Prefer batch mode when exporting
9. Use a staging table.
10.Aggregate data in Hive
Copyright 2014 Rackspace

File Formats• Text (default):
• Non-binary data types.
• Simple and human-readable.
• Platform independent.
• Binary (AVRO and sequence files):
• Precise representation and with efficient storage.
• Good for Text containing separators.
Copyright 2014 Rackspace

Environment• A combination of text and AVRO files mostly.
• Why Avro?
• Compact, splittable binary encoding.
• Supports versioning and is language agnostic.
• Also used as a container for smaller files.
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Exports• Experiment with batching multiple insert
statements together:
• --batch parameter
• sqoop.export.records.per.statement (100) property.
• sqoop.export.statements.per.transaction (100) property.
Copyright 2014 Rackspace

Batch Exports• The --batch parameter uses the JDBC batch
API. (addBatch/executeBatch)
• However…
• Implementation can vary among drivers.
• Some drivers actually perform worse in batch mode! (serialization and internal caches)
Copyright 2014 Rackspace

Batch Exports• The sqoop.export.records.per.statement
property will aggregate multiple rows inside one single insert statement.
• However…
• Not supported by all databases (most do.)
• Be aware that most dbs have limits on the maximum query size.
Copyright 2014 Rackspace

Batch Exports• The sqoop.export.records.per.transaction: how many insert statements will be issued per transaction.
• However…
• Exact behavior depends on database.
• Be aware of table-level write locks.
Copyright 2014 Rackspace

Which is better?• No silver bullet that applies to all use cases.
• Start with enabling batch import.
• Find out what’s the maximum query size for your database.
• Set the number of rows per statement to roughly that value.
• Go from there.
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Staging Tables are our Friends
• All data is written to staging table first.
• Data is copied to the final destination iff all tasks succeed: all-or-nothing semantics.
• Structure must match exactly: columns and types.
• Staging table must exist before and must be empty. (--clear-staging-table parameter)
Copyright 2014 Rackspace

Ten Best Practices1. It pays to use formatting arguments.
2. With the power of parallelism comes great responsibility!
3. Use direct connectors for fast prototyping and performance.
4. Use a boundary query for better performance.
5. Do not use the same table for import and export.
6. Use an options file for reusability.
7. Use the proper file format for your needs.
8. Prefer batch mode when exporting.
9. Use a staging table.
10.Aggregate data in Hive.
Copyright 2014 Rackspace

Hive• --hive-import parameter.
• BONUS: If table doesn’t exist, Sqoop will create it for you!
• Override default type mappings with --map-column-hive.
• Data is first loaded into HDFS and then loaded into Hive..
• Default behavior is append. (—hive-overwrite.)
Copyright 2014 Rackspace

Hive partitions• Two parameters:
• --hive-partition-key
• --hive-partition-value
• Current Limitations:
• One level of partitioning only.
• The partition value has to be an actual value and not a column name.
Copyright 2014 Rackspace

Hive and AVRO
• Currently not compatible!!
• Workaround is to create an EXTERNAL table.
CREATE EXTERNAL TABLE cs_atom_eventsROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'LOCATION ‘/user/cloud-analytics/snapshot/atom_events/cloud-servers’TBLPROPERTIES (‘avro.schema.url’=‘hdfs:///user/cloud-analytics/avro/cs_cff_atom.avsc');
Copyright 2014 Rackspace
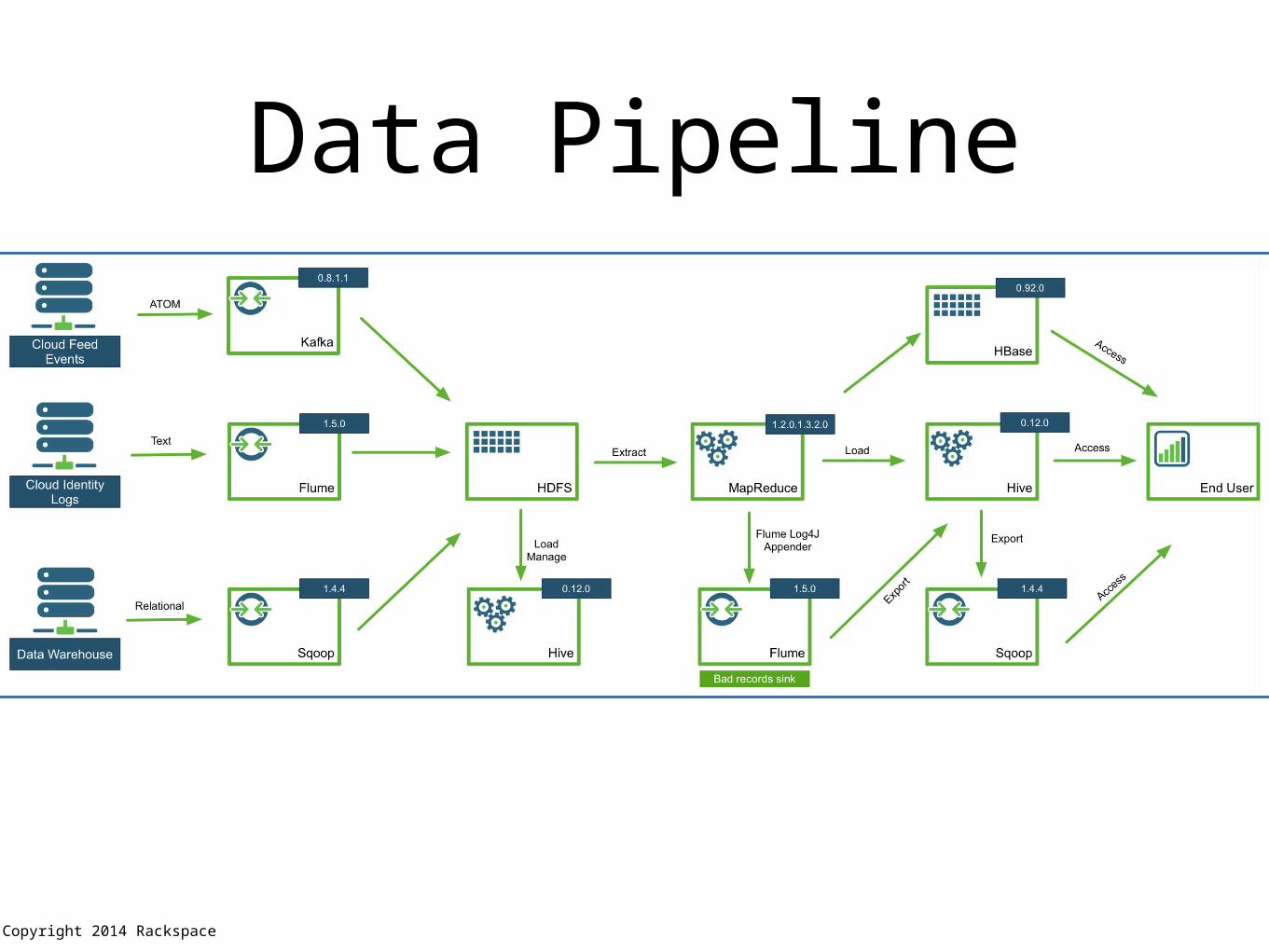
Data Pipeline
Copyright 2014 Rackspace

Call to Action
www.rackspace.com/cloud/big-data
(On-Metal Free Trial)
• Try it out!
• Deploy a CBD Cluster, connect to your RDBMS.
• Extract value from your data!


















